| Issue |
A&A
Volume 500, Number 2, June III 2009
|
|
|---|---|---|
| Page(s) | 681 - 691 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/200810372 | |
| Published online | 29 April 2009 | |
Combining weak and strong cluster lensing: applications to simulations and MS 2137
J. Merten1 - M. Cacciato2 - M. Meneghetti3,4 - C. Mignone1,2 - M. Bartelmann1
1 - Institut für Theoretische Astrophysik, Zentrum für Astronomie der Universität Heidelberg, Albert-Ueberle-Str.2, 69120 Heidelberg, Germany
2 -
Max-Planck-Institut für Astronomie, Königstuhl 17, 69117 Heidelberg, Germany
3 -
INAF - Osservatorio Astronomico di Bologna, via Ranzani 1, 40127 Bologna, Italy
4 -
INFN-National Institute for Nuclear Physics, Sezione di Bologna, Viale B. Pichat 6/2, 40127 Bologna, Italy
Received 11 June 2008 / Accepted 28 March 2009
Abstract
Aims. While weak lensing cannot resolve cluster cores and strong lensing is almost insensitive to density profiles outside the scale radius, combinations of both effects promise to constrain density profiles of galaxy clusters well, and thus to allow testing of the CDM expectation on dark-matter halo density profiles.
Methods. We develop an algorithm further that we had recently proposed for this purpose. It recovers a lensing potential optimally reproducing observations of both strong and weak-lensing effects by combining high resolution in cluster cores with the larger-scale information from weak lensing. The main extensions concern the accommodation of mild non-linearity in inner iterations, the progressive increase in resolution in outer iterations, and the introduction of a suitable regularisation term. The linearity of the method is essentially preserved.
Results. We demonstrate the success of the algorithm with both idealised and realistic simulated data, showing that the simulated lensing mass distribution and its density profile are well reproduced. We then apply it to weak and strong lensing data of the cluster MS 2137 and obtain a parameter-free solution which is in good qualitative agreement with earlier parametric studies.
Key words: gravitational lensing - galaxies: clusters: general - galaxies: clusters: individual: MS 2137 - cosmology: theory
1 Introduction
The mass distribution in dark-matter halos and the level of substructure in them are among the central predictions of the CDM paradigm for cosmic structure formation. The density profile should asymptotically fall off
![]() at large radii r and flatten considerably within a radial scale
at large radii r and flatten considerably within a radial scale ![]() (Navarro et al. 1996). The mass distribution should be richly substructured by sublumps of matter with a differential mass function approximated by a power law,
(Navarro et al. 1996). The mass distribution should be richly substructured by sublumps of matter with a differential mass function approximated by a power law,
![]() with a slope slighly shallower than
with a slope slighly shallower than ![]() (Madau et al. 2008; Springel et al. 2008).
(Madau et al. 2008; Springel et al. 2008).
Galaxy clusters should be weakly influenced by baryonic physics, thus their density profiles and mass distributions outside the cooling radius should well reflect those expected for dark matter. Do they? Although tentative answers exist, showing that estimated density profiles do at least not contradict the CDM expectation, accurate constraints are still missing. Due to its insensitivity to the physical state of the matter, gravitational lensing is perhaps the most promising tool for determining matter distributions.
Weak lensing lacks the resolution necessary to constrain the density profile in cluster centres, while strong lensing is confined to the innermost cluster cores. In combination, they may be able to test the CDM predictions on density profiles well.
Several methods have been suggested to combine weak and strong cluster lensing (Diego et al. 2007; Bradac et al. 2005; Cacciato et al. 2006). Among them is our own algorithm aiming at the lensing potential. It is based on minimising a ![]() function comparing observed shear measurements with suitable second derivatives of the potential. Expressing the derivatives in terms of finite differences leads to a system of linear equations whose direct inversion yields the solution.
function comparing observed shear measurements with suitable second derivatives of the potential. Expressing the derivatives in terms of finite differences leads to a system of linear equations whose direct inversion yields the solution.
We extend our earlier work in several ways. First, we no longer use the lowest-order approximation in which measured ellipticities estimate the shear, and introduce the reduced shear instead. The non-linearity accommodated in this way can be resolved into an iterative scheme using linear inversion in each step. Second, we wrap the algorithm into an outer iteration loop in which the grid resolution is progressively enhanced. While this step introduces correlations between adjacent pixels that have to be dealt with, it prepares the insertion of the strong-lensing constraints available in cluster cores. Third, we introduce a regularisation term for the two purposes of avoiding overfitting and smoothly joining the strong- and weak-lensing solutions. Finally, to account for the additional computational time we enabled the code to run on parallel machines.
We investigate the performance of our algorithm using two sets of synthetic data, one idealised and one realistic, before we proceed to apply it to the well-known strong-lensing cluster MS 2137, for which we obtain a high-resolution, parameter-free reconstruction.
A brief summary of the lensing notation in Sect. 2 is followed by an outline of the method in Sect. 3 and a description of its implementation in Sect. 4. We present the results in Sect. 5 and conclude in Sect. 6. Details of the algorithm are given in Appendix A.
2 Lensing formalism
2.1 Basic quantities
We adopt the standard notation introduced to describe isolated lenses in the thin-lens approximation (e.g. Schneider et al. 1992,2006; Narayan & Bartelmann 1996). Two-dimensional, projected lensing mass distributions are covered by angular coordinates
![]() .
The lensing potential
.
The lensing potential
![]() ,
which is the appropriately scaled Newtonian potential projected on the sky, contains all information necessary to describe a single-plane lens. The deflection angle, convergence and shear are derivatives of
,
which is the appropriately scaled Newtonian potential projected on the sky, contains all information necessary to describe a single-plane lens. The deflection angle, convergence and shear are derivatives of
![]() with respect to
with respect to
![]() and
and
![]() ,
,



2.2 Lensing by galaxy clusters
We concentrate on lensing by galaxy clusters. Let us first focus on weak lensing, which means
![]() (see Bartelmann & Schneider 2001, for a review). To first order, shape distortions of background galaxies are determined by the Jacobian matrix of the lens mapping,
(see Bartelmann & Schneider 2001, for a review). To first order, shape distortions of background galaxies are determined by the Jacobian matrix of the lens mapping,

The intrinsic ellipticities of the background galaxies require that their images be averaged to extract the weak-lensing signal from them. We assume that averages over ten or more galaxies are necessary for the uncertainty of an individual ellipticity measurement to fall below 10% of the signal (Cacciato et al. 2006). The expectation value for the measured ellipticity is then

where the reduced shear
 |
(7) |
and the distance weight function
 |
(8) |
appear. In the last equation,
While the probes of weak lensing are slightly distorted background galaxies whose signal needs to be treated statistically, strong lensing is based on greater effects. Another difference from weak lensing is that strong lensing only occurs in galaxy clusters near their cores where the lens becomes critical. Theseregions are typically of the order of 100 kpc in radius. The main observations are
- multiple images of background sources, which all carry the same spectral information of the source, which enables their unambiguous identification through a spectral or colour analysis; and
- highly distorted images of background sources like gravitational arcs or arclets, which lie close to critical curves of clusters.
 |
(9) |
3 Outline of the method
Our non-parametric maximum-likelihood reconstruction method aims at recovering the lensing potential ![]() .
The reasons for this choice are that the lensing potential is much smoother than e.g. the convergence, which renders it much less susceptible to noise, and that both convergence and shear are derivatives of the lensing potential so that no integration is needed to convert one to the other. The method described and applied here develops further and extends those presented in Bartelmann et al. (1996), Seitz et al. (1998), and Cacciato et al. (2006).
.
The reasons for this choice are that the lensing potential is much smoother than e.g. the convergence, which renders it much less susceptible to noise, and that both convergence and shear are derivatives of the lensing potential so that no integration is needed to convert one to the other. The method described and applied here develops further and extends those presented in Bartelmann et al. (1996), Seitz et al. (1998), and Cacciato et al. (2006).
The method takes as input the result of galaxy-shape and strong-lensing measurements, i.e. the two ellipticity parameters per galaxy and the strongly lensed images at their angular positions. As we pointed out before, an ellipticity measurement of a single galaxy image is useless as a weak lensing signal because of the intrinsic source ellipticity. Each data point is thus obtained by averaging over a certain number of background galaxy ellipticities.
We then divide the observed galaxy-cluster field into a grid of N cells, assign an averaged ellipticity to each cell, and thus obtain N data points for our ![]() -minimisation. The ensuing reconstruction will strongly depend on the grid resolution. Furthermore, if a number of M grid cells, which we shall call pixels from now on, contains strongly lensed images, we gain M additional constraints for the reconstruction.
-minimisation. The ensuing reconstruction will strongly depend on the grid resolution. Furthermore, if a number of M grid cells, which we shall call pixels from now on, contains strongly lensed images, we gain M additional constraints for the reconstruction.
Since the weak and strong-lensing constraints are independent of each other, but reflect the same underlying gravitational potential, the overall ![]() becomes the sum of two independent contributions,
becomes the sum of two independent contributions,

Our method is non-parametric in the sense that it does not assume a parameterised model for the mass or potential distribution. It assigns an initially unknown potential value to each grid point and refines the set of potential values on the grid during the
The reconstruction proceeds by minimising ![]() with respect to the potential values
with respect to the potential values ![]() at all grid positions l,
at all grid positions l,

The main advantage of the maximum-likelihood approach is its enormous flexibility. In principle, one can incorporate every additional observable constraint that can be connected in some way to the lensing potential. This is of course not restricted to lensing. One simply has to add separate and independent
3.1 Resolution issues
Before we can start computing the ![]() -functions for our joint lensing reconstruction, we have to address two issues concerning the resolution of our reconstruction grid. The first is related to the weak-lensing regime. If we want to average over at least ten galaxies per pixel, the typical background-galaxy density in the field of a cluster would not allow a higher resolution than
-functions for our joint lensing reconstruction, we have to address two issues concerning the resolution of our reconstruction grid. The first is related to the weak-lensing regime. If we want to average over at least ten galaxies per pixel, the typical background-galaxy density in the field of a cluster would not allow a higher resolution than ![]()
![]() 10 pixels, which is of course way too coarse to see any cluster substructures. In addition, pixels of a homogeneous grid can occur which contain fewer than 10 or even no galaxies because of the inhomogeneous, random galaxy distribution.
10 pixels, which is of course way too coarse to see any cluster substructures. In addition, pixels of a homogeneous grid can occur which contain fewer than 10 or even no galaxies because of the inhomogeneous, random galaxy distribution.
We solve these problems by an adaptive averaging procedure, in which we average galaxy ellipticities within circles around each pixel centre. Their radii are stepwise increased until each circle contains the desired number of galaxies. Different pixels will need different radii, depending on the local galaxy density in that area of the field. On a fine grid, galaxies shared by neighbouring pixels will of course cause these pixels to be correlated (see Fig. 1).
The second issue concerns the strong-lensing regime, in particular the arc positions. Since strong lensing is confined to much smaller scales than weak lensing, essential positional information is lost if the strong-lensing constraints are incorporated at the same resolution as weak lensing. This requires us to refine the grid near cluster centres until it is capable of resolving the exact arc positions (see Fig. 2).
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{0372f01.eps} \includegraphics[width=7.5cm,clip]{0372f02.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img37.png) |
Figure 1:
Top panel: very coarse grid of
|
| Open with DEXTER | |
3.2 Defining maximum likelihood functions
The most important ingredient of our cluster reconstruction is the ![]() -function (Eq. (10)) that we need to minimise. Consider first the weak-lensing term. As discussed before, the weak-lensing grid pixels are correlated because of the adaptive-averaging procedure, and the expectation value of the ellipticity is the reduced shear rather than the shear. Thus we find, for
-function (Eq. (10)) that we need to minimise. Consider first the weak-lensing term. As discussed before, the weak-lensing grid pixels are correlated because of the adaptive-averaging procedure, and the expectation value of the ellipticity is the reduced shear rather than the shear. Thus we find, for ![]() ,
,

where
Equation (12) illustrates the first major improvements in our method since Cacciato et al. (2006). First, we introduce the reduced shear instead of the shear as a reconstruction constraint. Furthermore, we introduce the adaptive averaging technique which adapts to the actual galaxy distribution of the field. Thus, the error in the ![]() -function is quantified by the non-diagonal covariance matrix
-function is quantified by the non-diagonal covariance matrix
![]() ,
which we evaluate now. The standard deviation
,
which we evaluate now. The standard deviation
![]() for each weak lensing pixel is obtained during the averaging process as the standard deviation from the mean. This standard deviation has three contributions assumed independent,
for each weak lensing pixel is obtained during the averaging process as the standard deviation from the mean. This standard deviation has three contributions assumed independent,
| (13) |
which are the noise due to the intrinsic ellipticity
| |
Figure 2:
Zoom into the inner part of the cluster. The left panel illustrates that a coarse, 20 |
| Open with DEXTER | |
Starting from the definition of the covariance matrix,
 |
(14) |
where xi is the ellipticity sample of the pixel with index i and using that the correlation between two pixels due to the averaging process will be proportional to the overlap between the averaging circles attached to them as shown in Fig. 1, we arrive at
The weight factors wij are obtained from the number of galaxies contained in the overlap area of both circles,

where Ni and Nj are the galaxy numbers contained in the circles around pixel centres i and j, and Nij is the number of galaxies contained in their overlap. These weights have the expected properties, i.e. they are unity if i=j and vanish for completely independent and uncorrelated pixels.
The strong-lensing term looks much simpler. By definition, the determinant of the Jacobian vanishes on the critical line. Thus, if we know which pixels are traversed by the critical curve, we can define
 |
(17) |
where the strong-lensing error estimate
 |
(18) |
with the pixel size
To evaluate Eq. (11), we have to connect convergence and shear to the grid values of the potential, which we shall do in the next section.
3.3 Lensing potential and convergence maps
The lensing potential which we are reconstructing is not directly observable, but linear combinations of its second derivatives are. Therefore, we can always add a constant, a linear function in
![]() ,
or a harmonic function to it without changing the observables. Furthermore, if ellipticities are the only quantities measured, the lensing potential is affected by the so-called mass-sheet degeneracy (Falco et al. 1985), which arises because ellipticities are invariant against isotropic scaling of the Jacobian matrix. Note that such transformations also leave the critical curves of a lens unchanged. These degrees of freedom allow the following transformation of the potential (Bradac et al. 2004):
,
or a harmonic function to it without changing the observables. Furthermore, if ellipticities are the only quantities measured, the lensing potential is affected by the so-called mass-sheet degeneracy (Falco et al. 1985), which arises because ellipticities are invariant against isotropic scaling of the Jacobian matrix. Note that such transformations also leave the critical curves of a lens unchanged. These degrees of freedom allow the following transformation of the potential (Bradac et al. 2004):
 |
(19) |
where
This is the reason why the reconstructed, discretised potential may look shifted or distorted. However, this is not a problem because we only need its curvature. We obtain physically meaningful quantities like convergence or shear by simply applying Eqs. (2)-(4) to ![]() .
We shall use the convergence mainly to describe the reconstruction of a galaxy cluster, because it intuitively reflects the cluster's mass distribution through its surface mass density.
.
We shall use the convergence mainly to describe the reconstruction of a galaxy cluster, because it intuitively reflects the cluster's mass distribution through its surface mass density.
Due to the mass-sheet degeneracy (Falco et al. 1985), the convergence is unique only up to the transformations
with
More elaborate methods require observables in the reconstruction which are not invariant under the mass-sheet transformation and depend on potential and convergence. One example is the source magnification, which Bartelmann et al. (1996) suggested to include in the maximum-likelihood approach. Another approach to lift the mass-sheet degeneracy was proposed by Bradac et al. (2005,2004), who proposed to exploit the knowledge of the source-redshift distribution.
Having obtained the convergence, possibly transformed according to the mass-sheet degeneracy, mass estimates are straightforward. If we know the lens redshift and fix the cosmological model, we also know the physical area of one pixel. If we additionally know at least the mean redshift of the sources, we can calculate the surface mass density, which yields an estimate for the total cluster mass after summing over the whole grid. Recall, however, that this returns a distance-weighted integral over the entire mass of cosmic structures along the line-of-sight from the observer to the sources.
4 Implementation
We shall now proceed to the specific implementation and the description of the required numerical methods and algorithms. As we already pointed out we significantly developed our method with the introduction of an adaptive averaging scheme and the use of the reduced shear instead of the shear. The price that we pay for these improvements is correlated reconstruction pixels and a relatively complicated two-level iteration scheme that we will describe in this section. As a result the runtime of our method increased dramatically which made it necessary to increase the speed of the reconstruction algorithm. The most important step towards speeding up the calculations is the parallisation of our code, using the well-known MPI library.
4.1 Preparing weak lensing data
We start with the analysis of the weak lensing data. It is provided in the form of a table containing columns for the position and ellipticity measurement for each distorted background galaxy. It should be noted that the coordinates are arbitrary as long as they all refer to the same coordinate system. We express the coordinates in arcseconds relative to the brightest cluster galaxy (BCG). The reconstruction grid is set up by assigning coordinates to each pixel centre.
The adaptive averaging process proceeds by enlarging circles around each pixel centre until they contain a pre-assigned, constant number of background galaxies. Once this number of galaxies is reached, the average and the standard deviation of the ellipticity are calculated and assigned to the pixel.
The covariance matrix between two pixels is determined by the number of galaxies shared between them. Its final entries are obtained using Eq. (15), because we can now calculate the weightings wij (see Eq. (16)). This procedure has to be done for both ellipticity components, and the resulting covariance matrices must be inverted.
4.2 Preparing strong lensing data
Handling the strong-lensing data, we have to cope with the fact that we cannot observe the critical curves directly. We thus need a good approximation for their locations, which is given by arc positions that can be observed very well. We show in Fig. 3 that arcs follow the position of the critical curves, as long as the resolution of the grid is not extremely high. However, even at the higher resolution of the finely resolved central grid, the difference in the pixel positions between arcs and critical curves is at most two pixels. Cacciato et al. (2006) showed that deviations of this size do not affect the reconstruction significantly.
A more severe problem is that the arcs sample the critical curves only very sparsely. We cannot expect to obtain full knowledge of the critical curve through observations. It will be one aim of future work to use high-resolution observations of cluster fields which tend to show more strongly lensed images and thus allow tracing of the critical curve in more detail. Another possibility would be to rely on critical-curve reconstructions from parametric strong-lensing analyses, and to feed that critical curve into the code. The drawback of this approach is that one gives up the completely non-parametric nature of the reconstruction by using profile assumptions in the critical-curve determination. In either case, the critical curves are characterised by a table listing the approximate positions of critical points.
We finally point out that we are using arcs as approximate indicators for critical-curve locations rather than multiple-image systems as strong-lensing constraints. This is for several reasons, first of all the identification of multiple image systems is not always possible since it requires multi-color observations and the subtraction of cluster members to look for hidden images. Moreover, due to resolution issues the reconstruction cannot be extremely accurate in the cluster centre and as a result we do not expect large changes by using multiple images instead of critical points.
But nevertheless one should use as many constraints as possible, which is the reason why future versions of our method will also contain multiple-image system information, if available, to give an optimal reconstruction result.
| |
Figure 3:
Arc position and estimated position of the critical curves for the real cluster MS 2137. The critical curves were estimated by a parametric strong lensing reconstruction from Comerford et al. (2006). Left panel shows 32 |
| Open with DEXTER | |
4.3 Grid methods
We now proceed to combine lensing theory and the measurements, and to implement the method numerically.
We defined the ![]() -functions in Sect. 3.2 using the discretised lensing-potential values as minimisation parameters. The observable to be reproduced in the case of weak lensing is the reduced shear, and the location of a vanishing determinant of the Jacobian in the case of strong lensing.
-functions in Sect. 3.2 using the discretised lensing-potential values as minimisation parameters. The observable to be reproduced in the case of weak lensing is the reduced shear, and the location of a vanishing determinant of the Jacobian in the case of strong lensing.
In order to minimise the resulting ![]() -function with respect to the lensing potential, we have to write the convergence and the shear in terms of the discrete potential values. The relation between these quantities is given by Eqs. (2)-(4) with the second derivatives replaced by finite-differencing schemes.
-function with respect to the lensing potential, we have to write the convergence and the shear in terms of the discrete potential values. The relation between these quantities is given by Eqs. (2)-(4) with the second derivatives replaced by finite-differencing schemes.
Given a certain grid resolution, we want to obtain the lensing potential at each grid position (x,y) with
![]() ,
,
![]() .
We enumerate these grid positions sequentially line by line and use the central difference quotients for discrete representations of the second derivatives at a given grid position. Our finite differencing scheme is identical to that chosen by Cacciato et al. (2006), and the corresponding coefficients are given in Fig. 4. At the edges and borders of the grid different (one-sided) finite-differencing schemes need to be used.
.
We enumerate these grid positions sequentially line by line and use the central difference quotients for discrete representations of the second derivatives at a given grid position. Our finite differencing scheme is identical to that chosen by Cacciato et al. (2006), and the corresponding coefficients are given in Fig. 4. At the edges and borders of the grid different (one-sided) finite-differencing schemes need to be used.
With our way of enumerating the pixels, we can write the discrete potential
![]() on the N
on the N ![]() M grid in the form of a vector
M grid in the form of a vector
![]() .
This only slightly complicates addressing the correct positions in the vector. Direct left and right neighbours are just separated by
.
This only slightly complicates addressing the correct positions in the vector. Direct left and right neighbours are just separated by ![]() positions in the vector, while top and bottom neighbours are separated by
positions in the vector, while top and bottom neighbours are separated by ![]() positions. The advantage of this enumeration is that the finite differencing becomes a simple matrix multiplication,
positions. The advantage of this enumeration is that the finite differencing becomes a simple matrix multiplication,
Here,
![\begin{figure}
\par\includegraphics[width=17cm,clip]{0372f07.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img71.png) |
Figure 4: Finite differences schemes. Written in the cells are the coefficients in the difference quotients. Left panel: scheme for the convergence; centre panel: scheme for the first shear component; right panel: scheme for the second shear component. |
| Open with DEXTER | |
Using these finite-differencing schemes, ![]() can be minimised by solving the linear system of equations
can be minimised by solving the linear system of equations
| (24) |
where the coefficient matrix
4.4 Regularisation and 2-step-iteration
4.4.1 Regularisation
We now introduce a regularisation term ![]() into the
into the ![]() function Eq. (10) to obtain
function Eq. (10) to obtain

The regularisation term depends on the potential and is defined such as to disfavour unwanted solutions. This is necessary to prevent the reconstruction from following intrinsic noise patterns, which do not reflect intrinsic features of the true underlying potential. Here, we use a simple regularisation term scheme simply comparing the convergence obtained with that found in the preceding iteration,
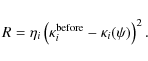
Its amplitude
4.4.2 Inner-level iteration
As the full expressions for the ![]() minimisation show, it is not precisely a linear system, but includes non-linear prefactor terms in the coefficient matrix and the result vector. We solve this problem in the same way as Bradac et al. (2005) did by means of an iterative approach in which the non-linear terms are computed from the preceding iteration. Starting from a first guess for the convergence, we express the corresponding non-linear terms by constant factors, as can be seen in the Appendix.
minimisation show, it is not precisely a linear system, but includes non-linear prefactor terms in the coefficient matrix and the result vector. We solve this problem in the same way as Bradac et al. (2005) did by means of an iterative approach in which the non-linear terms are computed from the preceding iteration. Starting from a first guess for the convergence, we express the corresponding non-linear terms by constant factors, as can be seen in the Appendix.
Bradac et al. (2005) showed that the initial guess of the convergence does not affect the final reconstruction, but at most the number of iterations. We confirm their result, which implies that the initial guess of a flat convergence is appropriate. We minimise ![]() and obtain a solution for the lensing potential. From it, we calculate convergence and shear, which we insert as new guesses into the non-linear terms in the next step of the reconstruction. This yields a convergent iterative process. We control the convergence of the procedure by comparing its results between subsequent iterations. If the change falls below a given threshold, we stop the iteration. The drawback of this method is that we now need several iterations (3-5 in practice) for a complete reconstruction, which takes some time at high resolution.
and obtain a solution for the lensing potential. From it, we calculate convergence and shear, which we insert as new guesses into the non-linear terms in the next step of the reconstruction. This yields a convergent iterative process. We control the convergence of the procedure by comparing its results between subsequent iterations. If the change falls below a given threshold, we stop the iteration. The drawback of this method is that we now need several iterations (3-5 in practice) for a complete reconstruction, which takes some time at high resolution.
4.4.3 Outer-level iteration
The regularisation term also helps in a second type of iteration, which we call outer-level iteration. The background-galaxy density of today's observations allows a resolution of only ![]()
![]() 10 uncorrelated pixels. Higher resolution is desirable at the expense of correlated pixels, which will affect the reconstruction. Also the convergence values in some individual pixels will increase at higher resolution, which renders the initial guess of a vanishing convergence increasingly less accurate, giving rise to many inner-level iterations.
10 uncorrelated pixels. Higher resolution is desirable at the expense of correlated pixels, which will affect the reconstruction. Also the convergence values in some individual pixels will increase at higher resolution, which renders the initial guess of a vanishing convergence increasingly less accurate, giving rise to many inner-level iterations.
These problems can easily be avoided by introducing another iteration as follows:
- One begins at the lowest possible resolution, where the pixels are not or almost not correlated. This resolution will be too coarse for fine-structure noise patterns to appear.
- Starting from the initial convergence set to zero, the inner-level iteration is performed until the reconstruction converges.
- The obtained result for the potential is then interpolated by a bicubic spline algorithm to a slightly higher resolution.
- This interpolation is taken as the comparison function in the regularisation and as a new initial guess in the inner-level iteration at the higher resolution.
- This process is repeated until the final resolution is reached.
| |
Figure 5:
Convergence maps of a simulated cluster. Left panel: initial reconstruction starting at a resolution of 15 |
| Open with DEXTER | |
4.5 Strong lensing at high resolution
4.5.1 Interpolation
Even when a weak-lensing reconstruction as described in the previous sections has converged, the grid resolution is far from being fine enough to follow the shape of the critical curves. We deal with the problem by interpolating the lensing potential from the final weak-lensing reconstruction and calculate convergence and shear at that refined resolution. Then, we zoom into the cluster core where the strong-lensing information is available. The interpolation is done by a bicubic spline interpolation routine which is reliable enough to create just a small amount of additional noise. The interpolated result serves as template for the following high-resolution reconstruction.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{0372f10.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img80.png) |
Figure 6: Left panel: complete combined weak and strong lensing reconstruction at low resolution of a simulated cluster. Right panel: zoom into the interpolated cluster core of the low-resolution reconstruction. |
| Open with DEXTER | |
4.5.2 Modified maximum likelihood function
Now, we have to remove the weak-lensing term from the ![]() function,
function,
 |
(27) |
because no weak-lensing data points are available at the high resolution required in the core. The strong-lensing data points, however, are available at high resolution, because the critical points can be determined very accurately. Yet, the weak-lensing reconstruction enters even at this resolution level through the regularisation term. Thus, the result is based on the weak-lensing constraints.
We finish the reconstruction by inserting the high-resolution cluster-core result into the result obtained at a coarser resolution, which consists of the complete cluster field. Due to the regularisation function the strong-lensing result fits nicely into the weak-lensing results since we do not allow that the two different reconstructions differ significantly at pixels where no strong-lensing constraints are available. This is also the last major change in our method compared to Cacciato et al. (2006). The use of the regularisation function as a tool to match results on different scales improves the quality of our reconstructions significantly.
5 Results
5.1 Tests with synthetic data
We first repeat the tests also carried out in Cacciato et al. (2006). We take simulated clusters from the N-body simulations described in Bartelmann et al. (1998) and compute maps of their reduced shear and their critical curves. Based on this information, we try to reconstruct the known potential of the simulated cluster. Since this is an idealised lensing scenario which does not include a realistic background-galaxy distribution or image analysis, it is sufficient to compare the convergence map obtained by the reconstruction with the real convergence map of the simulated cluster. The results confirm the reliability of our method and are shown in Figs. 7 and 8. In particular, Fig. 8 shows how significantly the results are improved when the strong-lensing constraints on a refined grid are added. Otherwise the central density peak is underestimated by almost 20%.
![\begin{figure}
\par\mbox{ \includegraphics[width=4.4cm,clip]{0372f11.eps} \includegraphics[width=4.4cm,clip]{0372f12.eps} }\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img82.png) |
Figure 7:
Left panel: convergence map of the high-resolution reconstruction. As one can see, the resolution is much higher in the inner part of the map. The colour scale is logarithmic and the contours start at
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{0372f13.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img83.png) |
Figure 8:
The radial |
| Open with DEXTER | |
5.2 The lensing simulator
Next, we use the method detailed in Meneghetti et al. (2008) to simulate an observation of another cluster field. The target of this simulated observation is the galaxy cluster g72, described in several previous papers (Meneghetti et al. 2007; Dolag et al. 2005; Puchwein et al. 2005). This cluster was simulated with different physics. For the present work we have used a pure dark matter simulation. The cluster is at redshift
![]() and has a main halo mass of
M200=6.7
and has a main halo mass of
M200=6.7 ![]()
![]() .
It is in the process of merging with a massive substructure of mass
.
It is in the process of merging with a massive substructure of mass
![]()
![]()
![]() .
In the projection chosen for this simulation the subclump is located at
.
In the projection chosen for this simulation the subclump is located at
![]() north of the main clump. A second massive substructure is present at a distance of
north of the main clump. A second massive substructure is present at a distance of
![]() from the cluster centre. The projected density of the cluster is shown in Fig. 10.
from the cluster centre. The projected density of the cluster is shown in Fig. 10.
We mimic a
![]() SUBARU observation of this cluster and of the sky behind it in the R-band assuming an exposure time of 6000 s and an isotropic, Gaussian PSF of
SUBARU observation of this cluster and of the sky behind it in the R-band assuming an exposure time of 6000 s and an isotropic, Gaussian PSF of
![]() FWHM. The distortion field, which is used to lens the background galaxies, is calculated from the cluster mass distribution following the method described in Meneghetti et al. (2007). The background galaxies have realistic morphologies, being drawn from shapelet decompositions of real galaxies taken from the Hubble-Ultra-Deep Field (HUDF). Their luminosity and redshift distributions also reflect those of the HUDF (Coe et al. 2006).
FWHM. The distortion field, which is used to lens the background galaxies, is calculated from the cluster mass distribution following the method described in Meneghetti et al. (2007). The background galaxies have realistic morphologies, being drawn from shapelet decompositions of real galaxies taken from the Hubble-Ultra-Deep Field (HUDF). Their luminosity and redshift distributions also reflect those of the HUDF (Coe et al. 2006).
The weak lensing analysis of the field was carried out by Bellagamba (Univ. of Bologna) using an advanced KSB method (Kaiser et al. 1995). It returned an ellipticity catalogue of 39 788 background sources. For the strong lensing analysis we followed two different approaches. First, we used the known complete critical curves to obtain a result under optimal conditions. In a second reconstruction we choose a kind of worst-case scenario where we used four estimated points of the critical curve. These point were determined following an observational approach. First, we identified in the simulation a few fold arcs. Then, we isolated the brightest knots along the lensed images, which are used to constrain the position of the critical lines passing in between them.
A first qualitative look at the obtained convergence map already shows a very nice agreement in orientation, shape and substructure of the real cluster and the reconstruction. See Fig. 10, where we show the convergence map of the reconstruction which uses only four critical-curve points. In addition we performed a more quantiative analysis, by reconstructing the total mass within a certain radius. Here we used the average redshift of the sources and assumed that the mean convergence vanishes at the borders of the field to correct the mass-sheet degeneracy. The result is shown in Fig. 11, and shows a good agreement with the real cluster mass on all scales. Note that we plot both reconstructions here, which are practically indistinguishable.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{0372f14.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img91.png) |
Figure 9: This figure illustrates how the critical curve estimators are obtained from given multiple lensed images of the simulation. In the bottom-right corner of the plot we show the pixel size of the final, finely resolved iteration. |
| Open with DEXTER | |
![\begin{figure}
\par\mbox{\includegraphics[width=8.8cm,clip]{0372f15.eps}\includegraphics[width=8.8cm,clip]{0372f16.eps} }\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img93.png) |
Figure 10:
Left panel: real convergence map of the simulated cluster. Right panel: convergence map of the high-resolution reconstruction. The colour scale in both maps is linear and the sidelength corresponds to
|
| Open with DEXTER | |
5.3 MS 2137
We finally apply our reconstruction algorithm to the galaxy cluster MS 2137. It is a cluster at redshift
![]() ,
dominated by a bright cD galaxy. It shows a giant tangential arc, a radial arc which was the first to be discovered (see Fort et al. 1992), and three additional arclets. The spectroscopic redshifts of the arcs were determined to be
,
dominated by a bright cD galaxy. It shows a giant tangential arc, a radial arc which was the first to be discovered (see Fort et al. 1992), and three additional arclets. The spectroscopic redshifts of the arcs were determined to be
![]() and
and
![]() (Sand et al. 2002). The tangential arc and two of the arclets belong to the same source. The radial arc also produces one counter image. The cluster has been studied several times before, see Gavazzi et al. (2003), Gavazzi (2005), Comerford et al. (2006), and Sand et al. (2008). All these studies used parametric reconstruction routines differing from our method.
(Sand et al. 2002). The tangential arc and two of the arclets belong to the same source. The radial arc also produces one counter image. The cluster has been studied several times before, see Gavazzi et al. (2003), Gavazzi (2005), Comerford et al. (2006), and Sand et al. (2008). All these studies used parametric reconstruction routines differing from our method.
The weak-lensing analysis is based on an VLT/FORS observation obtained during August 2001. Its results were kindly provided by Gavazzi (IAP, Paris). The field size is
![]()
![]()
![]() .
The ellipticity catalogue was obtained with a KSB-method (Kaiser et al. 1995) and returned 1500 ellipticity measurements on background galaxies. The arc positions were obtained from an HST/WFPC2 exposure using the F702W filter. During the reconstruction, the measured arc redshifts were used. Based on the experience from the tests with simulated data, we averaged over 15 galaxies per reconstruction pixel. The low-resolution reconstruction was performed on a 25
.
The ellipticity catalogue was obtained with a KSB-method (Kaiser et al. 1995) and returned 1500 ellipticity measurements on background galaxies. The arc positions were obtained from an HST/WFPC2 exposure using the F702W filter. During the reconstruction, the measured arc redshifts were used. Based on the experience from the tests with simulated data, we averaged over 15 galaxies per reconstruction pixel. The low-resolution reconstruction was performed on a 25 ![]() 25 pixel grid which was gradually refined to 40
25 pixel grid which was gradually refined to 40 ![]() 40 pixels for a reconstruction which resolves the arcs better (see Fig. 12). Unfortunately, there is a large void in the background-galaxy data in the upper middle part of the field. In this area, the reconstruction is thus unable to resolve any structures.
40 pixels for a reconstruction which resolves the arcs better (see Fig. 12). Unfortunately, there is a large void in the background-galaxy data in the upper middle part of the field. In this area, the reconstruction is thus unable to resolve any structures.
A comparison with former reconstructions is shown in Fig. 13. In the weak-lensing regime we have a close agreement with the Gavazzi (2005) results, which is expected, since we are using the same weak lensing data. In the strong-lensing regime we are in good agreement with the latest reconstructions of Donnarumma et al. (2009) and Comerford et al. (2006), but it tends to prefer a lower central mass than Gavazzi (2005). The reason for this is still unclear, but the reconstructions of Comerford et al. (2006) and Donnarumma et al. (2009) seem to prefer a lower mass in the strong lensing regime. The discrepancy between those works is discussed in Donnarumma et al. (2009).
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0372f17.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img98.png) |
Figure 11: Top panel: the real and the reconstructed total mass of the simulated cluster within a certain radius. Bottom panel: the residuals from the real mass at different scales. Both panels show both reconstructions, based on the full critical-curve knowledge and on only a few points of the critical curve respectively. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0372f18.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img99.png) |
Figure 12:
High resolution reconstruction of MS 2137 on a refined 40 |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{0372f19.eps}
\end{figure}](/articles/aa/full_html/2009/23/aa10372-08/img100.png) |
Figure 13: Comparison of our results with other reconstructions. The plot shows the reconstructed mass within a certain radius. Also indidcated is the transition between the weak and the strong lensing regime by means of the radius, in which all multiple images of the cluster are contained. |
| Open with DEXTER | |
6 Conclusions
We have extended the algorithm proposed by Cacciato et al. (2006) which reconstructs the lensing potential of galaxy clusters on a two-level grid, combining weak and strong-lensing data. Our extensions concern three aspects: first, the shear is replaced by the reduced shear to improve the reconstruction in the mildly non-linear regime. The non-linearity introduced in this way is solved by an inner iteration loop which preserves the linear minimisation of the ![]() function. Second, the spatial resolution of the potential grid is gradually increased in an outer iteration loop. While this step causes correlations between neighbouring pixels, which need to be dealt with using a non-diagonal covariance matrix, it prepares for the introduction of a highly resolved grid covering the strong-lensing observations in the cluster core. Third, we add a regularisation term to the
function. Second, the spatial resolution of the potential grid is gradually increased in an outer iteration loop. While this step causes correlations between neighbouring pixels, which need to be dealt with using a non-diagonal covariance matrix, it prepares for the introduction of a highly resolved grid covering the strong-lensing observations in the cluster core. Third, we add a regularisation term to the ![]() function, avoiding overfitting of noise and allowing a smooth transition from the inner, high-resolution to the outer, coarse-resolution grid.
function, avoiding overfitting of noise and allowing a smooth transition from the inner, high-resolution to the outer, coarse-resolution grid.
These extensions of the algorithm, especially the introduction of the full ![]() -function and the increased number of iterations made it necessary to drastically increase the numerical performance of the reconstruction routines. This was done with fast, numerical multiplication schemes and the parallelisation of the code to run on MPI machines. Applications of this algorithm to synthetic data show that the known, simulated cluster lenses are accurately reproduced, although intrinsic ellipticities, measurement and shot noise inevitably lead to a considerable noise level of the reconstruction in the case of realistic data. Still, the quantitative analysis of our convergence maps shows a very good agreement with the expected result. An application to the galaxy cluster MS 2137 qualitatively confirms the results of earlier, parametric studies that show an almost axially symmetric, presumably relaxed mass distribution. Although there is still room for potentially important further improvements, our algorithm should now be ready for reliable recoveries of lensing potentials, density distributions and density profiles of real galaxy clusters.
-function and the increased number of iterations made it necessary to drastically increase the numerical performance of the reconstruction routines. This was done with fast, numerical multiplication schemes and the parallelisation of the code to run on MPI machines. Applications of this algorithm to synthetic data show that the known, simulated cluster lenses are accurately reproduced, although intrinsic ellipticities, measurement and shot noise inevitably lead to a considerable noise level of the reconstruction in the case of realistic data. Still, the quantitative analysis of our convergence maps shows a very good agreement with the expected result. An application to the galaxy cluster MS 2137 qualitatively confirms the results of earlier, parametric studies that show an almost axially symmetric, presumably relaxed mass distribution. Although there is still room for potentially important further improvements, our algorithm should now be ready for reliable recoveries of lensing potentials, density distributions and density profiles of real galaxy clusters.
Acknowledgements
This work was supported in part by the Deutsche Forschungsgemeinschaft through the Collaborative Research Centre SFB 439, ``Galaxies in the Young Universe''. J.M. is supported by the Heidelberg Graduate School of Fundamental Physics (HGSFP) and C.M. is supported by the International Max Planck Research School (IMPRS) for Astronomy and Cosmic Physics at the University of Heidelberg. J.M. and M.C. want to thank G. Mamon and R. Gavazzi for useful discussions at IAP. Furthermore, we want to thank F. Bellagamba, M. Radovich and K. Dolag for their contribution to this work.
Appendix A: Linearisation in grid space
The matrix representation of the finite differences (Eqs. (21)-(23)) allows a simplification of the ![]() minimisation. For weak lensing, it reads
minimisation. For weak lensing, it reads
 |
(A.1) |
containing one term each for the two ellipticity components.
Of course, we have to perform the minimisation for both components, but we show only the calculation for one component. Correspondingly, the quantities
![]() represent
represent
![]() and
and
![]() ,
respectively. One
,
respectively. One ![]() contribution is
contribution is
| |
= |  |
|
| = |  |
||
| = | |||
| = | |||
| (A.2) |
where we combined the non-linear factors
Now, we minimise this equation with respect to the potential values ![]() ,
,

The derivative of
 |
= |  |
|
 |
|||
 |
|||
 |
|||
 |
|||
![$\displaystyle \left.
+~ Z_{i}Z_{j}\gamma_{j}\frac{\partial}{\partial\psi_{l}}\gamma_{i}(\psi)
\right].$](/articles/aa/full_html/2009/23/aa10372-08/img121.png) |
(A.4) |
Using
 |
= | ||
| (A.5) |
The last equation shows that we can now write Eq. (A.3) as a linear system of equations,
| (A.6) |
with the coefficient matrix
| |
= | ||
| (A.7) |
and the result vector
![\begin{displaymath}%
\mathcal{V}_{l}=\mathcal{F}_{ij}\left[
\varepsilon_{i}\var...
...athcal{K}_{il}+
\varepsilon_{j}Z_{i}\mathcal{G}_{il} \right].
\end{displaymath}](/articles/aa/full_html/2009/23/aa10372-08/img136.png) |
(A.8) |
We now repeat this exercise for the strong lensing term, where
 |
(A.9) |
Again, we isolate the non-linear terms and take them as constant during each iteration step,
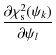 |
= | 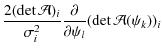 |
|
| = | ![$\displaystyle \frac{2(\det\mathcal{A})_{i}}{\sigma^{2}_{i}}\left[
\frac{\partia...
...^{2}-
\frac{\partial}{\psi_{l}}\vert Z_{i}\gamma_{i}(\psi_{k})\vert^{2}
\right]$](/articles/aa/full_html/2009/23/aa10372-08/img140.png) |
||
| = |  |
||
![$\displaystyle \left.- ~\frac{\partial}{\partial\psi_{l}}\left(
Z^{2}_{i}\gamma^{2}_{1i}(\psi_{k})+Z^{2}_{i}\gamma^{2}_{2i}(\psi_{k})
\right)\right]$](/articles/aa/full_html/2009/23/aa10372-08/img142.png) |
|||
| = | |||
| = | |||
| (A.10) |
This yields another linear system,
| (A.11) |
with the coefficient matrix for strong lensing
 |
(A.12) |
and the result vector
 |
(A.13) |
Also the regularisation term in Eq. (25) has to be minimised,
 |
= |  |
|
| = |  |
||
| = | |||
| = | (A.14) |
which contributes one additional term to the coefficient matrix and the result vector,
 |
(A.15) |
and
 |
(A.16) |
Finally, we collect the results to obtain the solution for Eq. (11), given in terms of a linear system with the following coefficient matrix


and the result vector
| |
= | ||
| (A.18) |
where i, j, n indicate the summation over the complete grid, and m over those pixels which are assumed to be traversed by a critical curve.
References
- Bartelmann, M., & Schneider, P. 2001, Phys. Rep., 340, 291 [NASA ADS] [CrossRef] (In the text)
- Bartelmann, M., Narayan, R., Seitz, S., & Schneider, P. 1996, ApJ, 464, L115 [NASA ADS] [CrossRef] (In the text)
- Bartelmann, M., Huss, A., Colberg, J. M., Jenkins, A., & Pearce, F. R. 1998, A&A, 330, 1 [NASA ADS] (In the text)
- Bradac, M., Lombardi, M., & Schneider, P. 2004, A&A, 424, 13 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Bradac, M., Schneider, P., Lombardi, M., & Erben, T. 2005, A&A, 437, 39 [NASA ADS] [CrossRef] [EDP Sciences]
- Cacciato, M., Bartelmann, M., Meneghetti, M., & Moscardini, L. 2006, A&A, 458, 349 [NASA ADS] [CrossRef] [EDP Sciences]
- Coe, D., Benítez, N., Sánchez, S. F., et al. 2006, AJ, 132, 926 [NASA ADS] [CrossRef] (In the text)
- Comerford, J. M., Meneghetti, M., Bartelmann, M., & Schirmer, M. 2006, ApJ, 642, 39 [NASA ADS] [CrossRef] (In the text)
- Diego, J. M., Tegmark, M., Protopapas, P., & Sandvik, H. B. 2007, MNRAS, 375, 958 [NASA ADS] [CrossRef]
- Dolag, K., Vazza, F., Brunetti, G., & Tormen, G. 2005, MNRAS, 364, 753 [NASA ADS] [CrossRef]
- Donnarumma, A., Ettori, S., Meneghetti, M., & Moscardini, L. 2009 [arXiv:0902.4051] (In the text)
- Falco, E. E., Gorenstein, M. V., & Shapiro, I. I. 1985, ApJ, 289, L1 [NASA ADS] [CrossRef] (In the text)
- Fort, B., Le Fevre, O., Hammer, F., & Cailloux, M. 1992, ApJ, 399, L125 [NASA ADS] [CrossRef] (In the text)
- Gavazzi, R. 2005, A&A, 443, 793 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Gavazzi, R., Fort, B., Mellier, Y., Pelló, R., & Dantel-Fort, M. 2003, A&A, 403, 11 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Kaiser, N., Squires, G., & Broadhurst, T. 1995, ApJ, 449, 460 [NASA ADS] [CrossRef] (In the text)
- Madau, P., Diemand, J., & Kuhlen, M. 2008, ApJ, 679, 1260 [NASA ADS] [CrossRef]
- Meneghetti, M., Argazzi, R., Pace, F., et al. 2007, A&A, 461, 25 [NASA ADS] [CrossRef] [EDP Sciences]
- Meneghetti, M., Melchior, P., Grazian, A., et al. 2008, A&A, 482, 403 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Narayan, R., & Bartelmann, M. 1996 [arXiv:astro-ph/9606001]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [NASA ADS] [CrossRef] (In the text)
- Puchwein, E., Bartelmann, M., Dolag, K., & Meneghetti, M. 2005, A&A, 442, 405 [NASA ADS] [CrossRef] [EDP Sciences]
- Sand, D. J., Treu, T., & Ellis, R. S. 2002, ApJ, 574, L129 [NASA ADS] [CrossRef] (In the text)
- Sand, D. J., Treu, T., Ellis, R. S., Smith, G. P., & Kneib, J.-P. 2008, ApJ, 674, 711 [NASA ADS] [CrossRef] (In the text)
- Schneider, P., Ehlers, J., & Falco, E. E. 1992, Gravitational Lenses (Springer Verlag)
- Schneider, P., Kochanek, C., & Wambsganss, J. 2006, Gravitational Lensing: Strong, Weak and Micro (Springer Verlag)
- Seitz, S., Schneider, P., & Bartelmann, M. 1998, A&A, 337, 325 [NASA ADS] (In the text)
- Springel, V., Wang, J., Vogelsberger, M., et al. 2008, MNRAS, 391, 1685 [NASA ADS] [CrossRef]
All Figures
| |
Figure 1:
Top panel: very coarse grid of
|
| Open with DEXTER | |
| In the text | |
| |
Figure 2:
Zoom into the inner part of the cluster. The left panel illustrates that a coarse, 20 |
| Open with DEXTER | |
| In the text | |
| |
Figure 3:
Arc position and estimated position of the critical curves for the real cluster MS 2137. The critical curves were estimated by a parametric strong lensing reconstruction from Comerford et al. (2006). Left panel shows 32 |
| Open with DEXTER | |
| In the text | |
| |
Figure 4: Finite differences schemes. Written in the cells are the coefficients in the difference quotients. Left panel: scheme for the convergence; centre panel: scheme for the first shear component; right panel: scheme for the second shear component. |
| Open with DEXTER | |
| In the text | |
| |
Figure 5:
Convergence maps of a simulated cluster. Left panel: initial reconstruction starting at a resolution of 15 |
| Open with DEXTER | |
| In the text | |
| |
Figure 6: Left panel: complete combined weak and strong lensing reconstruction at low resolution of a simulated cluster. Right panel: zoom into the interpolated cluster core of the low-resolution reconstruction. |
| Open with DEXTER | |
| In the text | |
| |
Figure 7:
Left panel: convergence map of the high-resolution reconstruction. As one can see, the resolution is much higher in the inner part of the map. The colour scale is logarithmic and the contours start at
|
| Open with DEXTER | |
| In the text | |
| |
Figure 8:
The radial |
| Open with DEXTER | |
| In the text | |
| |
Figure 9: This figure illustrates how the critical curve estimators are obtained from given multiple lensed images of the simulation. In the bottom-right corner of the plot we show the pixel size of the final, finely resolved iteration. |
| Open with DEXTER | |
| In the text | |
| |
Figure 10:
Left panel: real convergence map of the simulated cluster. Right panel: convergence map of the high-resolution reconstruction. The colour scale in both maps is linear and the sidelength corresponds to
|
| Open with DEXTER | |
| In the text | |
| |
Figure 11: Top panel: the real and the reconstructed total mass of the simulated cluster within a certain radius. Bottom panel: the residuals from the real mass at different scales. Both panels show both reconstructions, based on the full critical-curve knowledge and on only a few points of the critical curve respectively. |
| Open with DEXTER | |
| In the text | |
| |
Figure 12:
High resolution reconstruction of MS 2137 on a refined 40 |
| Open with DEXTER | |
| In the text | |
| |
Figure 13: Comparison of our results with other reconstructions. The plot shows the reconstructed mass within a certain radius. Also indidcated is the transition between the weak and the strong lensing regime by means of the radius, in which all multiple images of the cluster are contained. |
| Open with DEXTER | |
| In the text | |
Copyright ESO 2009
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.