| Issue |
A&A
Volume 708, April 2026
|
|
|---|---|---|
| Article Number | A262 | |
| Number of page(s) | 17 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202557129 | |
| Published online | 13 April 2026 | |
New classification method for the dynamical state of galaxy clusters with a Gaussian mixture model
1
Departamento de Fisica, Universidad Tecnica Federico Santa Maria, Avenida España, 1680 Valparaíso, Chile
2
Millenium Nucleus for Galaxies (MINGAL)
3
Korea Astronomy and Space Science Institute, Daejeon 34055, Republic of Korea
4
School of Computer Science, University of Birmingham, Edgbaston, Birmingham B15 2TT, UK
5
Astronomy Program, Department of Physics and Astronomy, Seoul National University, 1 Gwanak-ro, Gwanak-gu, Seoul, 08826, Republic of Korea
6
SNU Astronomy Research Center, Seoul National University, 1 Gwanak-ro, Gwanak-gu, Seoul, 08826, Republic of Korea
7
University of Science and Technology (UST), Gajeong-ro, Daejeon 34113, Republic of Korea
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
5
September
2025
Accepted:
1
March
2026
Abstract
Context. Galaxy clusters are the largest gravitationally bound systems, and they continue their growth through mergers in a hierarchical ΛCDM Universe. Therefore, we can describe the merger stage of a cluster as the dynamical state of clusters. Previous studies have investigated this phenomenon, but several limitations remain, including reliance on dichotomous classifications, constraints on the number of indicators used, absence of reliability, and incompatibility of methods between observation and simulation studies.
Aims. To overcome the limitations, we developed an enhanced and observation-applicable cluster dynamical state classification method using the Bayesian classifier with the class-conditional distribution Gaussian mixture model using the N-cluster Run simulation data.
Methods. The Bayesian classifier was designed for two merger stages (merger and relaxed) as well as three merger stages (recent merger, ancient merger, and relaxed) to provide a more detailed interpretation of the merger processes. After the best classifier model was constructed, we applied it to the observation data to test its performance and usability.
Results. In the results, using a larger number of indicators yields better results, with their order of importance being: magnitude difference, center offset, sparsity, Kuiper V statistic, and mirror asymmetry. Additionally, our analyses show that a projected classifier (built on the 6D space, but evaluated on lower dimensional projections) consistently produces better outcomes than non-projected classifiers (i.e., classifiers built directly on the corresponding low dimensional spaces), which means limited observation data can be used to classify with enhanced performance. Furthermore, the new classification method outperforms our previous research.
Conclusions. This new method can suggest a way of overcoming previous limitations and provides new insights by providing the reliability of dynamical state classification results. We expect this enhanced method and its findings can be used in observational studies to better understand the evolution of galaxy clusters and the mass assembly history of the Universe.
Key words: galaxies: clusters: general
© The Authors 2026
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
In the hierarchical structure formation paradigm of the ΛCDM Universe, matter grows from the assembly of small components and consists of large structures through the merger of large systems (Kravtsov & Borgani 2012). Galaxy clusters are the largest gravitationally bound systems in the nearby Universe and continue to experience active mass assembly through mergers. Since mergers create conflict and disturbances among the components of the system, we can understand the process of cluster merger in terms of virialization (or relaxation), which reflects the dynamical state of clusters.
The distribution of galaxy clusters and their dynamical states serves as a direct indicator for estimating the evolution of matter in the Universe. Additionally, it plays a crucial role in understanding the evolution of galaxies in densely populated environments (e.g., Thompson et al. 2015; Zenteno et al. 2020; Aldás et al. 2025). Therefore, measuring the dynamical states of galaxy clusters with large survey data is essential for connecting various studies related to large-scale and small-scale cosmic evolution.
Numerous studies have explored the dynamical state of galaxy clusters; however, there are limitations in accurately describing the continuous transitions of dynamical states and in utilizing large photometric survey data. Due to the limited data available for clusters, criteria for defining dynamical states are often simplistic, classifying them as either relaxed or unrelaxed based on a single criterion. Alternatively, researchers need to combine different observational results across various wavelengths, which can be both costly and time-consuming (Casas et al. 2024). Recent studies have sought to address these limitations by integrating multiple indicators (Zhoolideh Haghighi et al. 2020; Yuan & Han 2020; De Luca et al. 2021; Li et al. 2022; Campitiello et al. 2022; Haggar et al. 2024; Casas et al. 2024). These studies have provided valuable insights for how to improve dynamical state classification methods. However, it is often difficult to quantify the reliability of their classification results and sometimes the definition of the dynamical states was not clearly defined.
In our previous study (Kim et al. 2024), we aimed to develop more steps of criteria for the detailed separation of the dynamical states based on the merger stage of galaxy clusters. We attempted to describe these criteria by analyzing the success rate of separation along a one dimensional axis (1D), which is a rotated axis derived from a multidimensional indicator distribution, used to quantify reliability. This approach successfully classified clusters into recent, ancient, and relaxed merger stages, but it also has some limitations.
We were not able to consider more than four indicators simultaneously due to the constraints of mathematical calculations involved in the rotation matrix, the process required substantial computational time. We were limited to providing 1D recipes, as the method was too complicated for broader application, which lost some part of the information.
To address these limitations, we are exploring a new approach that utilizes the Bayesian classifier with class-conditional Gaussian mixture model (GMM) through machine learning techniques to apply it to a large volume of optical survey data.
This paper is organized as follows. Section 2 introduces our simulation and observational data, along with the merger stage sampling methods for the classification class. In Section 3, we describe six dynamical indicators and the Bayesian classifier with the class-conditional GMM implemented using a machine learning approach. Section 4 presents the explanation of the modeling process, as well as the results of applying the classifier to the observational data. In Section 5, we discuss the dependency of indicators on redshift and mass, compare our current findings with our previous study, and describe potential limitations. We conclude our study in Section 6. The following cosmological parameters are assumed throughout this paper: Ωm = 0.3, ΩΛ = 0.7, Ωb = 0.047, and h = 0.684.
2. Data
2.1. N-cluster Run simulation
Our goal in this work is to develop a practical observation-based method by utilizing realistic stellar component parameters of the brightest cluster galaxy (BCG). To achieve this, we employed simulation data from the N-cluster Run, consistent with previous research (Kim et al. 2024). The N-cluster Run simulation is a cosmological N-body dark matter-only simulation that consists of 64, each 120 Mpc h−1 length cubic boxes. It has 169 snapshots with 100 megayear time resolution from z = 200. Smallest particle mass is 1.07189 × 109 M⊙ h−1. The Gadget3 (Springel 2005) code is used for cosmological N-body/SPH simulations, and the 6D friends-of-friends (FoF) algorithm, ROCKSTAR halo finder (Behroozi et al. 2013), was used to define the halos of galaxies and clusters.
The N-cluster Run simulation is the dark matter-only simulation that uses the assumption of abundance matching to assign stellar masses to halo masses. Abundance matching, by definition, matches the simulated halo mass functions to observed stellar mass functions. By taking this approach, we ensure that ΛCDM simulations will reproduce the observed stellar mass functions over a wide range of redshifts. Our simulation results are comparable with the observations for the specific dynamical state indicators we used.
In this study, we expanded the sample size to three times larger than that of the earlier study, using 30 boxes containing a total of 1845 galaxy clusters. The mass range of cluster size halos is from 2.68 × 1013 M⊙ to 1.28 × 1015 M⊙ and the galaxy stellar mass range is 2.3 × 106 M⊙ to 1.59 × 1011 M⊙. Halo mass and stellar mass functions can be checked in Figure 1. Redshift is only considered from 0 to 0.5 (5 Gyr) to reduce the redshift dependency (See in section 5.1). Further details of simulation can be found in these papers (Smith et al. 2021, 2022a,b; Chun et al. 2022; Jhee et al. 2022; Kim et al. 2022; Yoo et al. 2022; Chun et al. 2023; Awad et al. 2023; Dong et al. 2024; Chun et al. 2024; Kim et al. 2024) and on the publically available data archive page1.
 |
Fig. 1. Top: Halo mass function of N-cluster Run simulation. Bottom: Comparison with stellar mass function of the N-cluster Run simulation and other studies. The Orange solid and cyan dashed lines represent the simulation function from the N-cluster Run and the Illustris-TNG 100 simulation (Pillepich et al. 2018). Gray circles and blue triangles are observational function from SDSS (Bernardi et al. 2013) and DESI Y1 data (Wang et al. 2024). |
2.2. Definition of the dynamical states for the classification class
Merger stages for the dynamical states are categorized using the same approach outlined in the previous paper (Kim et al. 2024). We define the beginning of a merger as the moment when the infall halo crosses one virial radius from the main halo. This distance is calculated in 3D space (considering x, y, and z coordinates). The time since infall is measured in one-gigayear increments from the merger start epoch. To avoid confusion from multiple mergers, we only considered a single major merger (mass ratio greater than 1:5) within the redshift range of 0 < z < 0.5 as a disturbed sample. The relaxed state is defined as having a merger mass ratio of less than 1:10 within the same redshift range, which includes minor mergers. Minor mergers are not considered as a separate state in this study because of their weak signal. We find that minor mergers do not have a significant effect on the dynamical state indicators.
We further divided the merger stages into recent and ancient mergers to provide a more detailed description of the dynamical state of clusters. The recent merger stage includes indicators that change at the start of the merger (one gigayear after the merger occurs), while the ancient merger stage encompasses the transitional phase of mergers (beginning three gigayears after the merger occurs). Table 1 summarizes the dynamical states employed in this study.
Summary of the dynamical states used in this study.
In this work, we developed our methods using two dynamical state categories (merger and relaxed) and three dynamical states (recent merger, ancient merger, and relaxed) to compare our results with previous studies and offer a detailed classification of dynamical states. This information was used for training the classifier and testing the performance of the method.
2.3. Observation data
To evaluate the application of our method using observational data, we utilized the Hectospec Cluster Survey catalog (Rines et al. 2013, HeCS). This catalog comprises 211 clusters located in the northern hemisphere, with redshifts ranging from 0 to 0.3 and a mass range of 9.5 × 1013 M⊙ to 6.13 × 1014 M⊙. We chose total 135 clusters, 69 from CIRS (Rines & Diaferio 2006), 25 from HeCS (Rines et al. 2013, HeCS), 8 from HeCS-red (Rines et al. 2018), 29 from HeCS-SZ (Rines et al. 2016), 1 from KYDISC (Oh et al. 2018), 1 from OmegaWINGS (Moretti et al. 2017), and 2 clusters from the NASA/IPAC Extragalactic Database (NED). We excluded some low statistics clusters from the original sample (Smith et al. 2023).
The average number of member galaxies per cluster is 100, with a range from 23 to 1350. Due to observation limitations, membership of clusters tends to contain a higher number of bright red galaxies compared to faint blue galaxies. Nevertheless, the data possesses adequate spectroscopic completeness (comp ≥ 0.5 in r-band ≥ 17.7) to allow for meaningful comparisons with simulation data.
Figure 2 shows the redshift and mass range of the observed and simulated clusters we used in this study. The redshift range of the simulation is much larger than that of the observation data and the sample size is significantly different. This can offer one proof that observation data can serve as a test sample of the simulation data-trained model.
 |
Fig. 2. Top: Mass versus redshift distribution of simulation data and observation data. Dots show median values, and the shaded area shows standard deviation values within redshift bins. Middle: Histogram of redshift for both observation and simulation data. Bottom: Histogram of Mass for both observation and simulation data. |
3. Methods
In this section, we introduce six dynamical state indicators for galaxy clusters and explain their significance. We then describe the Bayesian classifier and class-conditional distribution with the GMM method, which takes into account the 6D covariances to model each dynamical state. In addition, we present the quantification method along with precision, recall, and accuracy metrics.
3.1. Dynamical indicators
Different from our previous study that considered a spectroscopic indicator, we focused solely on photometric dynamical indicators to expand the cluster dataset for this method application. Previously, we utilized four indicators, but we have now introduced two additional indicators based on recent literature. All indicators are affected by the projection effects, which means they are sensitive to the plane of the sky direction. More detailed explanations of the four previously used dynamical indicators can be found in Kim et al. (2024) and the references cited therein. A brief summary of all dynamical indicators is presented in Table 2. Here, we provide brief descriptions of the four established dynamical indicators and detailed explanations of the two new indicators.
Summary of the dynamical states used in this study.
– Sparsity, expressed as
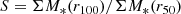 (1)
(1)
where ΣM*(r100) and ΣM*(r50) are total stellar mass within 100% and 50% of the virial radius of cluster, respectively. The BCG location is the central point in observations, while the center of mass is used in simulations. However, both values are similar since the cluster halo center is treated as the BCG in the simulation. The relaxed state of the cluster is expected to have centrally concentrated galaxy distributions, thus the low sparsity means a relaxed state.
– Stellar mass gap, expressed as
 (2)
(2)
where M*, bcg and M*, 2ndbcg are the stellar mass of the BCG and second brightest cluster galaxy, respectively. BCG dominant system means relaxed state, thus the lower value means a relaxed state.
– Center offset, expressed as
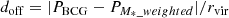 (3)
(3)
where PBCG is the position of the BCG, and PM*_weighted is the stellar mass-weighted center of the cluster member galaxies. For a fair comparison among clusters, we normalize distance with cluster virial radius. Because a merger makes the miscentering of BCG, the small value means the relaxed state.
– Satellite stellar mass fraction, expressed as
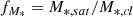 (4)
(4)
where M*, sat and M*, cl indicate member galaxy stellar mass and cluster stellar mass, respectively. A massive clump of mass is added to outskirts of main cluster when a merger happens; thus, a small value is expected for the relaxed state.
In this study, we further include two different types of spatial asymmetry indicators. Previous observational studies have been considered symmetry of matter distribution as the relaxed state and asymmetry as the disturbed state (e.g., Okabe et al. 2010; Zhang et al. 2010; Yuan & Han 2020). We tried to measure these asymmetry features in the galaxy clusters using differences of angular distribution and of mean length from neighbor galaxies.
– Kuiper’s V statistics, used to measure the angular asymmetry of a galaxy distribution based on the difference between the cumulative distribution of a random distribution and a sample distribution, expressed as
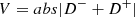 (5)
(5)
where D+ and D− mean maximum and minimum difference between a random cumulative distribution and a sample cumulative distribution, given by
![Mathematical equation: $$ \begin{aligned}&D^-=\max [z_{i}-(i-1)/n],\end{aligned} $$](/articles/aa/full_html/2026/04/aa57129-25/aa57129-25-eq6.gif) (6)
(6)
![Mathematical equation: $$ \begin{aligned}&D^+=\max [i/n-z_{i}] \end{aligned} $$](/articles/aa/full_html/2026/04/aa57129-25/aa57129-25-eq7.gif) (7)
(7)
where f is a continuous cumulative distribution function of x, represented by zi = f(xi).
We measured the angular positions of member galaxies from the BCG by setting north to zero degree and measuring angles clockwise. The cumulative distribution of angles was compared with the random cumulative distribution. The definition and equation are available from Kuiper (1960).
If member galaxies are located homogeneously (relaxed), the difference between the sample cumulative distribution and the random cumulative distribution will be small.
– Mirror symmetry: an indicator that also provide information about the positional asymmetry of member galaxy distribution. It measures the mean distance among member galaxies to check the clumpiness of the distribution, given by
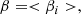 (8)
(8)
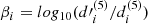 (9)
(9)
where di(5) is the mean distance from galaxy i to the fifth nearest neighbors, and d′i(5) is the same with di(5), but the opposite position of galaxy i through BCG location. If the galaxy distribution is symmetric, the difference between di(5) and d′i(5) is small. Thus, a small β value means a symmetric distribution and also means relaxation. However, this indicator is highly sensitive to the membership and completeness of the data (see Section 5.5). We followed definition and equation from West et al. (1988) and Casas et al. (2024).
The histogram distribution of each indicator from simulation data is shown in the top panels of Figure 3, while the same indicators from observation data are shown in the bottom panels of Figure 3. Merging and relaxed clusters (plotted in different colors) are not well separated in any of the indicators due to projection effects. Although the histogram distributions are not perfectly matched between simulation and observation, this is caused from size difference between two data sets (see Figure 2).
 |
Fig. 3. Histograms of six dynamical state indicators on (Top) N-cluster Run simulation and (Bottom) HeCS observation data. Top: Black empty, red, green, and blue colored histograms exhibit the number of galaxy clusters for total, recent merger, ancient merger, and relaxed dynamical state, respectively. The overlap of the merger and relaxed sample histogram distribution shows the projection effects on each dynamical state indicator. Bottom: Same indicator histograms as the top panels with different colors. Even though there are slight parameter range differences, the overall parameter distribution seems similar to each other. |
3.2. Bayesian classifier and class conditional distributions with a GMM
We utilized a Bayesian classifier where class conditional distributions are estimated through an infinite GMM, to address the limitations of our previous study. In our earlier methods, we were unable to consider parameter spaces larger than four dimensions and could not provide specific probability information for more detailed merger stages. However, with the approach proposed in this section as a classifier, we can model each merger stage in the 6D space of indicators. Additionally, it is possible to project the 6D class-conditional distributions into lower dimensional indicator spaces.
3.2.1. Bayesian classifier
We divided the simulation sample into training and test datasets, using a 70:30 ratio, stratified by class (merger stage). The training data were employed to train and build class-conditional distributions, while the test data were used to assess the classifier’s performance.
The Bayes classifier is based on the estimation of class-conditional distributions p(x|Ck), where the distribution of points belong to class Ck. While generally considered the optimal classifier, its performance relies heavily on the quality of the class-conditional distributions in practice.
The naive implementation of the Bayes classifier assumes conditional independence across features; however, this assumption disregards correlations in the dataset that might be meaningful in informing the classification. However, much more nuanced estimations of the class-conditional distributions might be obtained, given a sufficiently rich dataset. Thus, we did not use the naive implementation in this work.
Given K classes Ck, it is possible to estimate the posterior distribution, the probability that the x is originated from class Ck, p(Ck|x) using the Bayesian rule of
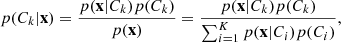 (10)
(10)
where p(x|Ck) is the likelihood of the data given the model for class Ck, p(Ck) the prior over class Ck and the denominator acts as a normalization (often referred to as the model evidence).
Given a new sample x* then, the above equation assigns a probability for that point to have originated from class Ck. If a hard assignment needs to be performed, the parent class (estimated label) is estimated as
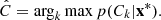 (11)
(11)
Once the Bayesian classifier is adopted, we only need to specify a framework for the estimation of the class-conditional distributions. This is reported in the following section.
3.2.2. Class-conditional distributions
At the core of the proposed methodologies usually lies the GMM.
As it is particularly useful because it leverages the flexibility and regularities of the Gaussian distribution. The probability density function (PDF) of a GMM can be written as
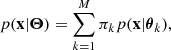 (12)
(12)
where p(x|θk) = 𝒩(θj), probability of x can be described with a normal distribution defined by parameter vector θk = [μk, Σk](i.e., the mean and covariance matrix of mixture component, k, respectively). Here, Θ = [θ1, …, θM] contains parameters of all components. The parameter πk is the mixture coefficient for a component, k, of the mixture and must satisfy
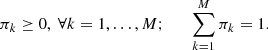 (13)
(13)
When the mixture coefficient for component k is larger than zero and for all k is part of M, the summation of mixture coefficients should be one. In both equations, the number of components in the mixture is M.
When estimating the density of a dataset with GMM, the main hyperparameter to be identified is the number of components, M. Different routines exist to estimate it directly from the data, leveraging information theoretic quantities such as the Bayesian or Akaike information criteria (BIC or AIC). However, estimation of optimal hyperparameter and parameters is a data-intensive process that requires multiple splits of the set, resulting in possible biases.
An alternative to classical GMM is the Infinite GMM (Rasmussen 1999). This is a Bayesian formulation of the GMM that imposes priors on the parameters, Θ, of the mixture components and the corresponding hyperparameters. The net effect of this formulation is that the estimation of the effective number of components in the mixture is delegated to an approximation of a Dirichlet Process.
In practice, only the maximum number of components and the concentration prior of the Dirichlet process need to be specified to constitute hyperparameters for the Dirichlet process-GMM (DP-GMM). Higher values of the concentration prior will enforce a higher number of components with large mixture coefficients and vice versa. It is worth noting that the quality of the obtained density is not necessarily affected by the number of components, but its complexity is. We adopted the version implemented in the python sklearn library (Pedregosa et al. 2011).
In summary, the class-conditional distribution for each merger stage, p(x|θk) has been constructed using a DP-GMM, testing various parameters and identifying the optimal one via out-of-sample likelihood. Using equation (10), we obtained the corresponding posterior p(Ck|x), and we calculated the accuracy by assigning unseen data (test set) to the most likely merger stage (class) via equation (11).
The best model classifier was created for each merger stage, developed for two and three merger stage classifications, and was subsequently applied to the observational data under the same merger stage conditions.
3.2.3. Confusion matrix and classification report
Because we divided the sample into training data and test data, we can judge the performance of the classifier with precision, accuracy, and recall values. We present a brief set of definitions with equations for each quantifying values below. Here, capital letters T, F, N, and P represent true, false, negative, and positive, respectively. True and false represent the actual class of test data, while positive and negative represent the predicted class of test data. These concepts are used to measure the performance of machine-learning classification by combining concepts of actual and predicted classes, such as true-positive (TP), false-positive (FP), and false-negative (FN). For example, when the classifier predicts a cluster as relaxed, when it is actually in a relaxed state, it counts as a TP classification result. However, if it is not an actual relaxed state, it counts as FP and so on.
– Precision: to show how well the model predicts the positive class, we use
 (14)
(14)
– Accuracy: to measure how well the model predicts the results, we use
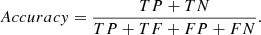 (15)
(15)
– Recall: to measure how often the model correctly identifies true positives from all the actual positive samples, we use
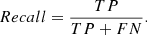 (16)
(16)
Precision can represent completeness of classification, while accuracy indicates the purity of the classified results. Here, we used average per-class accuracy to quantify performance,
 (17)
(17)
By comparing these parameters, we could find the best model classifiers for each merger stage. We selected the training and test data using random bootstrapping resampling to minimize bias from the sample distribution. Thus, the precision, recall, and accuracy values for each model were compared as the mean of the iterated random resampling.
4. Analysis and result
In this section, we present the results of our new classification method for both two-merger and three dynamical state classifications. First, we describe the best model condition, show the results from projected classifier applications by different numbers of indicator, and give the best indicator combination results. We also compare the performance of precision, accuracy, and recall results with those from a non-projection model. Finally, we demonstrate the application of this method to observational data and present the classification results.
4.1. Best model analysis
Because the distribution of the merger stage samples of each indicator resembles a shell structure, which makes it difficult to separate subpopulations, we selected the GMM for this highly overlapped class distribution. We made Gaussian models for each merger stage sample, as illustrated in Figures 4 and 5. We then combined the probabilities from each GMM to obtain the class-conditional probability distribution.
 |
Fig. 4. 2D Correlation plots for each indicator distribution by merger sample. The bottom-left corner and top-right corner give the scatter plots of the indicator against the other. The diagonal shows the histogram of individual indicators. In the bottom-left panels, we overplot probability contours (varying probability value in each panel). In the top-right corner, we overplot ellipses indicating the shape of the Gaussian for all components with a weight concentration prior > 0.1. We note that ellipses match the location of the high probability contours. |
 |
Fig. 5. 2D Correlation plots for each indicator distribution by relaxed state sample. Instructions are the same as Figure 4. |
By testing the full covariance matrix, we analyzed the 6D correlations simultaneously. To improve the overall understanding, we visualized this data using 2D correlation plots. Figure 4 and Figure 5 illustrate the 2D distributions for each dynamical indicator across different merger stages. The upper 2D parameter spaces show the position of highly weighted Gaussian components of parameter distributions with purple ellipses, used to model the parameter distribution. The histograms in diagonal panels provide the distribution of each indicator, while the lower 2D parameter spaces show the probability contours derived from the GMM.
To properly and efficiently model the distribution using the Gaussian formula, we need several hyperparameters, including random values for the starting point (e.g., μk, Σk), a tolerance value to exit the loop, and a weight concentration prior parameter to assign weights to the Gaussian distributions. We chose the Dirichlet process for the weight concentration prior type because (while the Dirichlet distribution models probability with a fixed number of components) the Dirichlet process determines the optimal number of components itself. The Dirichlet process modifies the coefficients and gradually reduces the ones that reflect less variance in the data. At the end of the training, due to the Dirichlet process, the number of mixture coefficients that are effectively meaningful for the construction of the model is generally much lower than the total number of components in the mixture. However, when we check the histogram of weights, more than 80% of the weights are valued at less than 0.01. It shows that although the Dirichlet process reduces some of the lowest weight components, our model needs those lower weight components to describe the entire distribution.
We tested all the hyperparameters, along with the number of Gaussians made the most meaningful probability differences. Thus, we mainly tested various combinations of the number of Gaussian fittings to find the best model. Here, we mention that the hyperparameter labeled as the "number of components" is the maximum number of Gaussian components used in the Dirichlet process. Also, Bayesian priors with equal percentages or sample-proportional percentages lead to negligible differences.
The probability contours for each merger stage are displayed in the middle panel of Figure 6. Each probability contour was created based on the distribution of each merger stage, as shown in the left panel of the same figure. The classification results are presented in the right panel.
 |
Fig. 6. Example figures of the classification process and result from the 6-indicator Bayesian classifier. Figures are 2D, but the actual classifier was made in a 6D indicator space. Left: Standardized original simulation data distribution on 2D indicator space. Merger stages are shown with different colors, and check it in the legend. Middle: Probability contours. Red, yellow, and blue lines represent probability contours of recent merger, ancient merger, and relaxed samples. Based on these probability contours, the model classifies the dynamical state as shown in the middle panel. Right: Prediction result of the overall sample distribution. Blue dots show the matched classification, and red dots show the mismatched classification. The center of the blue contour region shows good classification, but the center of the red contour region shows conflict of classifications between the recent merger and the ancient merger classification results. It represents an uncertain region of classification. |
To mitigate specific sample distribution bias, probability contours for each subsample were created with the mean distribution of subsamples from the bootstrap resampling method, even though we used the full sample distribution for the Figure 6. We resampled each merger stage by maintaining the same percentage as the entire merger stage sample ratio.
To compare the performance across models using different numbers of Gaussians, we analyzed the mean values of precision, recall, and accuracy of the models for each subsample. The differences among the resampled subsamples were less than 0.01 in probability values, which is smaller than the 0.1 probability difference identified when varying the number of components.
We evaluated the classifiers based on the average values of precision, recall, and accuracy. The results indicate that the two-merger stage classifier achieves an average performance of 92% in accurately reproducing the true class, while the three-merger stage classifier demonstrates an average performance of 77% in reproducing the true class. The best model conditions for the two and three dynamical state are presented in Table 3.
Six indicator best model precision, recall, and accuracy values by number of merger stages.
4.2. Application on observation data
We applied this cross-conditional probability distribution to the HeCS cluster catalog data. As shown in the left panel of Figure 7, our classifier was modeled with simulation train data (white), then applied to observation data (blue). We applied probability contours (as shown in the middle panel of Figure 6) to the observation data and could get the classification result (as in the right panel of Figure 6). Once the classifier has been modeled, applying it to observational data is quick and straightforward.
 |
Fig. 7. Example figures for a modeled Bayesian classifier application on the observation data. Again, figures are 2D, but the actual classifier was made in a 6D indicator space. Left: Original 2D observation data distribution. Classifier was modeled using simulation data distribution (white), and then the trained classifier is applied to observation data (Blue). Right: classified results of observation data. Each color represents different merger stages, and check it in legend. |
Figure 8 represents the spatial distribution of the dynamical state of HeCS clusters as determined by the three-merger stage classifier. Each class is assigned based on which class has the highest probability relative to the others (see Appendix B). However, each cluster has its own set of probabilities for all merger stages, allowing us to examine these probabilities as percentages.
 |
Fig. 8. Spatial distributions of 135 classified observation clusters. Top-left: Dichotomy classification result. Red, green, and blue circles represent recent merger stage, ancient merger stage, and relaxed state clusters. From the top-right to the bottom of figure, the color gradient shows probabilities of recent merger (red, top-right), ancient merger (green, bottom-left), and relaxed state (blue, bottom-right). |
To display the tendencies, we assigned a dynamical state with the highest probability to each cluster. However, there are many alternative ways to use these probability values to assign a dynamical state. For example, we could define a high confidence sample, where only objects with greater than 90% probability are included. Alternatively, instead of assigning individual objects to specific categories, we can use the probabilities as weights. For instance, measuring specific properties of all the clusters (e.g., the blue fraction), but also weighting their contribution to the measurement by the merger or relaxed probability. This approach fully avoids making an arbitrary choice for how to classify the clusters and it is an especially useful approach when the number statistics of clusters is low and splitting them into separate categories could reduce the number statistic further. Therefore, the fact that the model provides probabilities is flexible and should be considered a strength of the approach. Figure 8 displays the probabilities of each merger stage using different colors. The color bars indicate the magnitude of these probabilities.
Based on the results in Table 4, the two-merger stage classifier identifies a similar number of merger classifications as the three-merger stage classifier, which means our classifier works in a consistent way. Having a large fraction of merging clusters in the observed sample could arise because of the way the sample is selected. The HeCS cluster sample was selected from X-ray dominant and massive clusters. And merging clusters have a tendency towards larger masses than relaxed clusters, following the known mass-dynamical state dependency (Ludlow et al. 2012; Raouf et al. 2019; Seppi et al. 2021).
HeCS cluster classification results from two and three merger stage classifiers.
Although the absolute number and percentage of merger samples are similar for the two classifications, with 116 samples (85%) from the two-merger stage classifier and 110 (58+52) (82%) from the three-merger stage classifier, there is a significant difference in the number of high-probability samples. In particular, there are 105 for the two-merger stage classifier compared to only 30 (18+12) for the three-merger stage classifier.
This discrepancy can be further understood by examining the precision, recall, and accuracy values shown in Table 3. The more specific classification makes detection more challenging due to a reduced training dataset, which results in the three-merger stage classifier having lower precision, recall, and accuracy values, as well as a smaller number of high-probability samples.
4.3. Model projection and number of indicator effects
The Bayesian classifier has the advantage of having class-conditional distributions built in the high dimensional space. In the inference phase, the class-conditional distributions can be projected on the lower dimensional space spanned by the available indicators. The projections are more informative than the GMM built on the corresponding low dimensional space, carrying the high dimensional correlations through the projections. For instance, even with just two indicator variables, we can classify dynamical states using information from six indicator spaces. Therefore, we projected classifiers for two-merger and three-merger stages into the lower number of indicator spaces to evaluate their performance (e.g., train six-indicator information to classify 5, 4, 3, and 2 indicator classification). We compared these results with those from non-projected classifiers, which utilized the same amount of indicator information to train (e.g., trained two-indicator information to classify a two-indicator classification).
Figure 9 presents the results for precision, recall, and accuracy based on different numbers of indicator information used. The shaded area illustrates the variation of values from various indicator combinations, highlighting the largest error value compared to other errors. Notably, the projected classifier results (represented by the solid line) consistently outperform the non-projected classifier results (depicted by the dashed line) in both two- and three-merger stage classifications, which means the projected classifier can provide better classification results.
 |
Fig. 9. Precision, recall, and accuracy changes by number of combined indicators. The upper three plots show results from two merger stage classifications (merger and relax), and the lower three plots show results from three merger stage classifications. From Left to right columns, precision, recall, and accuracy results were shown. Each color of line represents a different merger stage, which can be identified in the legend. The solid line and dashed line indicate the projected classifier and non-projected classifier results, respectively. Shade shows scatter from different indicator combinations. |
In terms of precision, the projected classifier shows an average improvement of 10% over non-projected classifier results. The recall parameter has the largest 40% increase percentage for the relaxed dynamical state sample. Additionally, the accuracy of the projected classifier demonstrates about a 10% better performance, compared to the non-projected results.
In addition, we can revisit the finding that a larger number of indicator combinations leads to better results. As a byproduct of projection analysis, we can get the best combination results for different numbers of indicator combinations. The best combination, based on the number of indicators, is ranked by magnitude difference, center offset, sparsity, Kuiper V, mirror asymmetry, and satellite stellar mass fraction as shown in Table 5. The order of indicators was chosen based on their overall performance in terms of precision, recall, and accuracy in classification. We discuss the importance rank of the indicator in Section 5.3.
Best indicator combination by number of combined indicators.
Additionally, we applied projected classifiers to the HeCS cluster data. Figure 10 illustrates the classification tendencies based on the number of classified clusters. By an increase in the number of indicators, both the two-merger and three-dynamical state classifiers show a decrease in the number of relaxed clusters while indicating an increase in the number of merger clusters. These results appear consistent with the six-indicator classifier result.
 |
Fig. 10. Classification number of cluster tendency by number of combined indicators. Left: Projected model results for two merger stage classifications. Right: Projection model results for three merger stage classifications. Different colors, symbols, and line styles represent different merger stages, and it can be checked in the legend. |
The fraction of recent mergers remains roughly constant, while the curves that vary (and even end up inverted) characterize the relaxed and ancient mergers. This indicates that the ancient mergers represent an intermediate state, which can be mistaken for the relaxed cluster when using only a few components.
5. Discussion
In this section, we discussed indicator dependency by mass and redshift and correlation among the indicators. Furthermore, we present the comparison result with our previous method and this study, the importance rank of indicators, and the systematics from interlopers. Some caveats of Bayesian classification are also discussed here.
5.1. Indicator dependency on mass and redshift
We tested dependencies of dynamical indicators from simulation data by mass and redshift. For the mass dependency test, we divided the cluster mass range 2 × 1013 ∼ 2 × 1015 M⊙ into seven mass bins (see left panel in the Figure 11). All indicators show distinct increasing or decreasing trends and the indicator exhibiting the widest variance was sparsity. It is increased from 1.33 to 1.97, with a change of 0.64. The smallest variance was kuiper_V. It changed from 0.11 to 0.05, decreasing by 0.6. Each indicator was changed to 18% and 11% when those results were compared to their percentage for the entire parameter distribution.
 |
Fig. 11. Left: Mass dependency of six dynamical state indicators. Each color and shape of symbols represent different dynamical state indicators. Sort of indicator can check in the legend. Detailed information of indicators is in section 3.1. X error shows bin size and y error shows standard deviation of values within bin. Right: Redshift dependency of six dynamical state indicators. Features are same with left panel. |
Redshift dependency was tested with four bins from redshift 0 to 0.5. Most of the indicators were changed by less than 0.1 value for the entire range (see right panel in the Figure 11). Besides, some of the indicators do not show any prominent trends by redshift changes. The largest variation was shown in stellar mass ratio, which decreased by 0.08, and the smallest variation was demonstrated in kuiper_V, which decreased by 0.04. Kuiper_V showed the least variation by mass and redshift changes; some indicators used the mass show large changes of mean value by mass and redshift variation.
When we compare the variation by mass and redshift, mass causes more variation than redshift. However, we used clusters having larger than 1014 M⊙, thus dependency is alleviated. It has already been reported that dynamical states dependence on mass of cluster from previous studies (Ludlow et al. 2012; Raouf et al. 2019; Seppi et al. 2021).
5.2. Comparison of performance with previous method
In our previous paper (Kim et al. 2024), we aimed to develop a new linear combination method for dynamical indicators using the rotation matrix. This approach was intended to enhance the separation among different dynamical states. In this study, we compared the performance of our Bayesian classifier with a class-conditional GMM with our earlier method to demonstrate the improvements achieved.
It is important to note that we cannot make direct comparisons due to the different classification and quantification methods employed and the different indicators used. Therefore, we calculated the precision, recall, and accuracy values based on the best linear combination axis in four dynamical indicator spaces of two merger stage classifications in the previous method, using zero as the reference point. These values are presented in Table 6.
Comparison with our previous study and this study using four indicator combination classification.
The results indicate significant improvements in all metrics (precision, recall, and accuracy) for both merger and relaxed state samples. The Bayesian classifier with GMM for class-conditional distribution method exhibits 20%–40% increases in precision, 6%–28% increases in recall, and 32%–41% increases in accuracy compared to the previous method. Notably, the accuracy shows a remarkable enhancement, yielding twice as significant results as before.
Our previous method provides a continuous probability value for each dynamical state along the x-axis. However, it could not provide specific probabilities for individual clusters. This limitation means that when two clusters share the same x-value but differ in y-value, the method cannot distinguish between them based on the y-value (i.e., the accuracy problem). In contrast, this new classification method in this study can provide specific probabilities for each cluster by considering multidimensional covariances. At this point, the new method could significantly improve the accuracy value.
5.3. Importance rank of indicators
In the Bayesian classifier with GMM for a class-conditional distribution classification, it is not possible to measure the importance of individual indicators directly. However, we can infer their relative importance based on the best combination results from the comparisons presented in Section 4.3. The combinations generally appear to be organized and show incremental improvements, suggesting that the indicators have significant differences in their contributions.
Despite this initial impression, our test revealed that the order of the best combinations can change when varying sample sizes, train-test sample ratios, and resampling numbers. One consistently strong indicator is the stellar mass gap, which generally ranks as the best overall. When considering two indicator combinations, the combination of stellar mass gap and center offset is the strongest one, which remains unchanged.
On the other hand, other indicators seem to have similar importance to each other within the error range and the best combination results change by variable from three to five indicator combinations. This is a consistent result with our previous study, where we suggested that three indicators have comparable importance within the same error range in the different classification methods. However, the analysis methods also affect these results; we discussed it in the appendix A.
Although the best combinations may vary in three to five indicator combinations depending on variables such as the number of samples, the main probability contours remain relatively unchanged. The region representing 90% probability stays consistent. This fact demonstrates the superiority and stability of our method.
5.4. Systematics
In this step, we tested various kinds of systematic errors and their effect on classification results. To mimic the observational systematics error, we tested the indicator distribution with a new cluster galaxy sample by including a different range (1.2, 1.5, 2, 2.5Rvir radius) of line-of-sight interlopers within the three-box samples. In the Table 7, the first table shows the percentages of included interlopers. Naturally, when we considered a longer line-of-sight distance, the sample includes more interlopers.
Systematics error test results from different line-of-sight range interloper samples.
The second table shows classification results by different line-of-sight distances for the interloper sample. When we include more interlopers, fewer consistent classification results are shown, indicating that the fraction of interlopers affects misclassification. This interloper effect is more pronounced during the ancient merger stage. For example, the 1Rvir sample data classified with 45, 22, and 29 clusters for recent merger, ancient merger, and relaxed state. The 1.2Rvir sample classified with 38, 28, and 30 clusters for recent merger, ancient merger, and relaxed state. Among them, 34, 18, and 28 clusters have consistent classification results, and they are about 89, 64, and 93 percent the same as the 1Rvir sample classification. The ancient merger showed the lowest consistency among others. Nevertheless, the consistency of classification is not significantly affected by the interloper fraction and the percentage change is small.
The third table shows the two-sample K-S test p-value changes for each indicator value. For instance, the first low exhibits a two-sample K-S test p-value between the original sample distribution and the 1.2Rvir interloper sample. A small p-value (e.g., < 0.05) indicates that the samples are unlikely to come from the same distribution; most interloper samples differ from the original sample indicator distribution. Although their K-S test p-value of indicator distribution means they are different indicator distributions, their classification results primarily display a good consistency, meaning our classifier also performs consistent classification across different interloper samples. It also means that including interlopers does not significant change the dynamical state classification.
Another possible systematic error is that observed galaxies may suffer confusion when they are projected too close to another galaxy and cannot be separated from the other galaxy. We tested this effect by assigning physical sizes of their stellar disks to the simulated galaxies, following the stellar mass-effective radius relation given in Mowla et al. (2019). We defined confusion as the simulation when a smaller galaxy is totally overlapped by a larger galaxy (the distance between the centers of the two galaxies is smaller than the radius of the larger galaxy minus the radius of the smaller galaxy). From three boxes containing 113 cluster samples, we found that confusion happens very rarely; namely, the average fraction of hidden small galaxies is approximately 0.16% of the member galaxies. This means that this particular systematic error has a negligible impact on the measurement of dynamical state indicators.
5.5. Caveats of the method
While we demonstrated improved performance in classification and ease of application with the Bayesian classification method, there are several assumptions and caveats to consider.
First, some indicator calculations are dependent on the depth of data (≃low magnitude limit) and radial coverage of member galaxies within clusters. Typically, galaxy clusters consist of a small number of massive galaxies and a large number of low-mass galaxies. Mass-based or centrally effective indicators are not significantly affected, but position-based or cluster-wide effective indicators can be heavily influenced by how low-mass galaxies are considered.
Additionally, our method relies on modeling the distribution of indicator values based on simulation data. Although we attempted to eliminate data distribution bias by iteratively resampling the data, our predictions and training model are based on the assumption that our simulation data accurately represents the evolution of galaxy clusters.
Nevertheless, our method can be easily applied to other simulations and observations, and it is also a quick and straightforward process to add more indicators. Spectroscopic or X-ray indicators can be incorporated using hydrodynamical simulation data as long as the data can be adjusted to maintain a consistent depth. Finally, this method can be effectively utilized across various observational datasets.
6. Conclusions
In this work, we developed an improved method for classifying dynamical states by utilizing a Bayesian classifier with GMM for class-conditional distributions applied to the N-cluster Run simulation data. This Bayesian approach allows us to address the limitations of the previous linear combination method for dynamical state indicators, including restrictions on the number of combined indicators and the challenges posed by non-linear decision boundaries across multiple indicator spaces.
Initially, we classified two merger stages (merger and relaxation) and three merger stages (recent merger, ancient merger, and relaxation) based on the merger mass ratio and time since the merger within the simulation data. Subsequently, we calculated six optical indicators on the projected plane to simulate the observational data.
We modeled each sample of merger stages individually using a GMM. Next, we created cross-conditional distributions of probabilities for both two- and three-merger stages (see Figure 4, Figure 5 and Figure 6). The best configuration was determined through comparisons of precision, recall, and accuracy values. This trained Bayesian classifier was then applied to a reduced set of indicator combinations and observation data (see Figure 8).
Our analysis revealed that varying numbers of Gaussian distributions are required to effectively model each merger stage sample. The performances of the best models are as follows: for the two-merger stage classification, the merger and relaxed sample show average values about 0.92. In the case of the three-merger stage, the recent merger, ancient merger, and the relaxed sample exhibit an average value of about 0.77 (see Table 3).
When we applied the best classifier derived from six indicator spaces to the lower number of indicator spaces, the results consistently outperformed those of non-projected classifiers. It means that even if we get a small number of indicators, we can classify them with higher performance by utilizing this new method (See Figure 9).
An increase in the number of indicator combinations leads to improved classification results (See Figure 9). As a byproduct of the projected classifier analysis, we can get the order of rank for important indicators. Order is as follows: magnitude difference, center offset, sparsity, Kuiper V statistic, and mirror asymmetry (see Table 5). The first two indicators were the same as the result of our previous research.
The new GMM method demonstrates enhanced performance compared to our previous results, which utilized a linear combination of indicators via a rotation matrix. In our comparison of four indicator combinations for two-merger stage classification, the GMM method exhibits improvements ranging from 20% to 40% in precision, 6% to 28% in recall, and 32% to 41% in accuracy (see Table 6).
Using this enhanced method and results, we can enlarge our research for the purpose of various future works. In this study, we primarily employed optical indicators; however, we can enhance our methodology by incorporating spectroscopic and X-ray indicators using hydrodynamic and hydromagnetic simulations. Since the inclusion of additional indicators typically improves classification accuracy, we anticipate that the use of spectroscopic indicators will lead to more precise classifications, while X-ray indicators will facilitate a more detailed separation of merger stages.
Furthermore, we aim to create a map of the dynamical states of galaxy clusters by utilizing public photo-z catalogs. Additionally, we will assess the large-scale environmental impact on the dynamical state of these galaxy clusters through this map. This mapping, bolstered by the method and results presented here, will enable us to explore the mass assembly history of the nearby Universe.
This method is available on GitHub2, under a GNU general public license.
Acknowledgments
Here we thank the anonymous referee for useful comments that have improved this paper. Hectospec observations used in this paper were obtained at the MMT Observatory, a joint facility of the Smithsonian Institution and the University of Arizona. This research was supported by the Agencia Nacional de Investigación y Desarrollo (ANID) ALMA grant funded by the Chilean government, ANID-ALMA-31230016. RS acknowledges financial support from FONDECYT Regular 2023 project No. 1230441 and also gratefully acknowledges financial support from ANID – MILENIO NCN2024_112. M.C. was supported by the EPSRC Prosperity Partnerships grant ARCANE, EP/X025454/1. M. C. and P.T. were supported by the EPSRC Prosperity Partnerships grant ARCANE, EP/X025454/1. P.T. was also supported by the and UKRI Horizon Europe Underwriting, EPSRC EP2293110. YLJ acknowledges support from the Agencia Nacional de Investigación y Desarrollo (ANID) through Basal project FB210003, FONDECYT Regular projects 1241426 and 123044, Millennium Science Initiative Program NCN2024_112. HSH acknowledges the support of the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT), NRF-2021R1A2C1094577, and Hyunsong Educational & Cultural Foundation. J.H.S. acknowledges support from the National Research Foundation of Korea grants (No. RS-2025-00516904 and No. RS-2022-NR068800) funded by the Ministry of Science, ICT & Future Planning. K.W.C. was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (2021R1F1A1045622).
References
- Aldás, F., Gómez, F. A., Vega-Martínez, C., Zenteno, A., & Carrasco, E. R. 2025, A&A, 699, A313 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Awad, P., Peletier, R., Canducci, M., et al. 2023, MNRAS, 520, 4517 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardi, M., Meert, A., Sheth, R. K., et al. 2013, MNRAS, 436, 697 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Campitiello, M. G., Ettori, S., Lovisari, L., et al. 2022, A&A, 665, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casas, M. C., Putnam, K., Mantz, A. B., Allen, S. W., & Somboonpanyakul, T. 2024, ApJ, 967, 14 [Google Scholar]
- Chun, K., Shin, J., Smith, R., Ko, J., & Yoo, J. 2022, ApJ, 925, 103 [NASA ADS] [CrossRef] [Google Scholar]
- Chun, K., Shin, J., Smith, R., Ko, J., & Yoo, J. 2023, ApJ, 943, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Chun, K., Shin, J., Ko, J., Smith, R., & Yoo, J. 2024, ApJ, 969, 142 [Google Scholar]
- De Luca, F., De Petris, M., Yepes, G., et al. 2021, MNRAS, 504, 5383 [NASA ADS] [CrossRef] [Google Scholar]
- Dong, K. L., Smith, R., Shin, J., & Peletier, R. 2024, MNRAS, 527, 9185 [Google Scholar]
- Haggar, R., Gray, M. E., Pearce, F. R., et al. 2020, MNRAS, 492, 6074 [NASA ADS] [CrossRef] [Google Scholar]
- Haggar, R., De Luca, F., De Petris, M., et al. 2024, MNRAS, 532, 1031 [Google Scholar]
- Hammer, B., & Villmann, T. 2002, Neural Netw., 15, 1059 [Google Scholar]
- Jhee, H., Song, H., Smith, R., et al. 2022, ApJ, 940, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, Y., Smith, R., & Shin, J. 2022, ApJ, 935, 71 [Google Scholar]
- Kim, H., Smith, R., Ko, J., et al. 2024, ApJ, 970, 165 [Google Scholar]
- Kravtsov, A. V., & Borgani, S. 2012, ARA&A, 50, 353 [Google Scholar]
- Kuiper, N. H. 1960, Indagationes Math. (Proc.), 63, 38 [Google Scholar]
- Li, Q., Han, J., Wang, W., et al. 2022, MNRAS, 514, 5890 [Google Scholar]
- Ludlow, A. D., Navarro, J. F., Li, M., et al. 2012, MNRAS, 427, 1322 [NASA ADS] [CrossRef] [Google Scholar]
- Moretti, A., Gullieuszik, M., Poggianti, B., et al. 2017, A&A, 599, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mowla, L. A., van Dokkum, P., Brammer, G. B., et al. 2019, ApJ, 880, 57 [NASA ADS] [CrossRef] [Google Scholar]
- Oh, S., Kim, K., Lee, J. H., et al. 2018, ApJS, 237, 14 [Google Scholar]
- Okabe, N., Takada, M., Umetsu, K., Futamase, T., & Smith, G. P. 2010, PASJ, 62, 811 [NASA ADS] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pillepich, A., Nelson, D., Hernquist, L., et al. 2018, MNRAS, 475, 648 [Google Scholar]
- Raouf, M., Smith, R., Khosroshahi, H. G., et al. 2019, ApJ, 887, 264 [NASA ADS] [CrossRef] [Google Scholar]
- Rasmussen, C. E. 1999, Proceedings of the 13th International Conference on Neural Information Processing Systems, NIPS’99 (Cambridge, MA, USA: MIT Press), 554 [Google Scholar]
- Rines, K., & Diaferio, A. 2006, AJ, 132, 1275 [Google Scholar]
- Rines, K., Geller, M. J., Diaferio, A., & Kurtz, M. J. 2013, ApJ, 767, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Rines, K. J., Geller, M. J., Diaferio, A., & Hwang, H. S. 2016, ApJ, 819, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Rines, K. J., Geller, M. J., Diaferio, A., Hwang, H. S., & Sohn, J. 2018, ApJ, 862, 172 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., Biehl, M., & Hammer, B. 2009, Neural Comput., 21, 3532 [Google Scholar]
- Seppi, R., Comparat, J., Nandra, K., et al. 2021, A&A, 652, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smith, R., Michea, J., Pasquali, A., et al. 2021, ApJ, 912, 149 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R., Calderón-Castillo, P., Shin, J., Raouf, M., & Ko, J. 2022a, AJ, 164, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R., Shinn, J.-H., Tonnesen, S., et al. 2022b, ApJ, 934, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R., Hwang, H. S., Kraljic, K., et al. 2023, MNRAS, 525, 4685 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Thompson, R., Davé, R., & Nagamine, K. 2015, MNRAS, 452, 3030 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, Y., Yang, X., Gu, Y., et al. 2024, ApJ, 971, 119 [Google Scholar]
- West, M. J., Oemler, A., Jr, & Dekel, A. 1988, ApJ, 327, 1 [Google Scholar]
- Yoo, J., Ko, J., Sabiu, C. G., et al. 2022, ApJS, 261, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, Z. S., & Han, J. L. 2020, MNRAS, 497, 5485 [Google Scholar]
- Zenteno, A., Hernández-Lang, D., Klein, M., et al. 2020, MNRAS, 495, 705 [Google Scholar]
- Zhang, Y.-Y., Okabe, N., Finoguenov, A., et al. 2010, ApJ, 711, 1033 [NASA ADS] [CrossRef] [Google Scholar]
- Zhoolideh Haghighi, M. H., Raouf, M., Khosroshahi, H. G., Farhang, A., & Gozaliasl, G. 2020, ApJ, 904, 36 [Google Scholar]
Appendix A: Comparison of best indicator selection by different methods
In order to estimate the reliability of the learnt indicator importances, we tested the feature (indicator) importance proposed in section 5.3 by performing two additional machine learning algorithms, derived within very different frameworks. Generalized Relevance Learning Vector Quantization (GRLVQ, Hammer & Villmann (2002)) is a prototype-based classification algorithm that compresses dominant properties of the classes into a small set of representative points.
During the learning stage, the relative importance (relevance) of the input features in discriminating between classes (merger stages) is estimated. The framework has been generalized to metric learning, where feature relevances are replaced by full metric tensors, describing the dominant discriminative directions in feature space Schneider et al. (2009).
The restriction of the metric tensor to be diagonal with possibly different diagonal elements collapses to the GRLVQ formulation. While the more general GMLVQ can be considered as a feature construction method, (aggregating features into discriminative directions), its diagonal restriction, GRLVQ, can be interpreted as a feature selection algorithm, because no combination of the input features is performed.
Given the scope of this work, we opted for GRLVQ, as we would like to compare the feature importances directly with the sequence recovered in section 5.3. In this work we adopted the MATLAB implementation available at Michael Biehl’s homepage 3, with 5 prototypes per class, in order to account for non-linear decision boundaries and data sparsity. We perform 500 independent repetitions of the classification over random sub-samples of the training set and only keep the relevance profiles of the top 40%, preserving 200 models in total. The distribution of feature relevances, across the final 200 models is shown in Figure A.1, top panel.
 |
Fig. A.1. Indicator importance test with different methods. Top: Violin plot of indicator relevances from the GRLVQ method. Bottom: Violin plot of indicator importances from the random forest method. |
The second algorithm adopted for feature importance determination in a classification setup relies on fitting a random forest Breiman (2001) model to the data. A random forest is an ensemble model that agglomerates the performance of multiple decision trees by averaging them. The procedure introduces randomness by constructing multiple decision trees over samples of the data and / or a subset of features. Decision trees tend to overfit on the sample, capturing redundant information disjointly. However, when averaging over the predictions, the independent errors can cancel out, stabilizing the results and providing a lower variance estimator. While by design more opaque than the methodologies presented in this work, RF is a commonly used algorithm for feature selection.
The adopted implementation is the one provided in the scikit-learn package, with permutation importance estimation over 200 repetitions, bootstrap over training and 100 base learners (trees). Permutation importance compares the results on any set (we used the full training set) to the model applied on the same set with repeatedly permuted feature. Feature importances are shown in Figure A.1, bottom panel. It is reassuring to verify that both methodologies recover a similar profile for the feature importances over the training set. These are also comparable with the ones discussed in section 5.3 up to noise.
In the figures, the importance of the indicators is clearly illustrated by the median value (represented by a white line) within the violin plots. Consistent with the GMM results, the stellar mass gap (ΔM*, 12) consistently demonstrates the highest level of importance. However, random forest identifies the center offset (doff) as the second most significant indicator, mirroring the findings of the GMM analysis. On the other hand, GRLVQ ranks the sparsity as the second most important indicator. Interestingly, in GRLVQ, the center offset is ranked fourth in importance, which is somewhat unexpected since many other studies have identified it as the second most critical indicator (Raouf et al. 2019; Zhoolideh Haghighi et al. 2020; Haggar et al. 2020).
It is worth noting that there exist other techniques for feature relevance estimation, and their results provide us with different relevance, although the sample is the same.
Appendix B: Probabilities of dynamical states for 135 HeCS clusters
Classification results with probabilities for the 135 HeCS clusters.
Continued
All Tables
Six indicator best model precision, recall, and accuracy values by number of merger stages.
HeCS cluster classification results from two and three merger stage classifiers.
Comparison with our previous study and this study using four indicator combination classification.
Systematics error test results from different line-of-sight range interloper samples.
All Figures
|
Fig. 1. Top: Halo mass function of N-cluster Run simulation. Bottom: Comparison with stellar mass function of the N-cluster Run simulation and other studies. The Orange solid and cyan dashed lines represent the simulation function from the N-cluster Run and the Illustris-TNG 100 simulation (Pillepich et al. 2018). Gray circles and blue triangles are observational function from SDSS (Bernardi et al. 2013) and DESI Y1 data (Wang et al. 2024). |
| In the text | |
|
Fig. 2. Top: Mass versus redshift distribution of simulation data and observation data. Dots show median values, and the shaded area shows standard deviation values within redshift bins. Middle: Histogram of redshift for both observation and simulation data. Bottom: Histogram of Mass for both observation and simulation data. |
| In the text | |
|
Fig. 3. Histograms of six dynamical state indicators on (Top) N-cluster Run simulation and (Bottom) HeCS observation data. Top: Black empty, red, green, and blue colored histograms exhibit the number of galaxy clusters for total, recent merger, ancient merger, and relaxed dynamical state, respectively. The overlap of the merger and relaxed sample histogram distribution shows the projection effects on each dynamical state indicator. Bottom: Same indicator histograms as the top panels with different colors. Even though there are slight parameter range differences, the overall parameter distribution seems similar to each other. |
| In the text | |
|
Fig. 4. 2D Correlation plots for each indicator distribution by merger sample. The bottom-left corner and top-right corner give the scatter plots of the indicator against the other. The diagonal shows the histogram of individual indicators. In the bottom-left panels, we overplot probability contours (varying probability value in each panel). In the top-right corner, we overplot ellipses indicating the shape of the Gaussian for all components with a weight concentration prior > 0.1. We note that ellipses match the location of the high probability contours. |
| In the text | |
|
Fig. 5. 2D Correlation plots for each indicator distribution by relaxed state sample. Instructions are the same as Figure 4. |
| In the text | |
|
Fig. 6. Example figures of the classification process and result from the 6-indicator Bayesian classifier. Figures are 2D, but the actual classifier was made in a 6D indicator space. Left: Standardized original simulation data distribution on 2D indicator space. Merger stages are shown with different colors, and check it in the legend. Middle: Probability contours. Red, yellow, and blue lines represent probability contours of recent merger, ancient merger, and relaxed samples. Based on these probability contours, the model classifies the dynamical state as shown in the middle panel. Right: Prediction result of the overall sample distribution. Blue dots show the matched classification, and red dots show the mismatched classification. The center of the blue contour region shows good classification, but the center of the red contour region shows conflict of classifications between the recent merger and the ancient merger classification results. It represents an uncertain region of classification. |
| In the text | |
|
Fig. 7. Example figures for a modeled Bayesian classifier application on the observation data. Again, figures are 2D, but the actual classifier was made in a 6D indicator space. Left: Original 2D observation data distribution. Classifier was modeled using simulation data distribution (white), and then the trained classifier is applied to observation data (Blue). Right: classified results of observation data. Each color represents different merger stages, and check it in legend. |
| In the text | |
|
Fig. 8. Spatial distributions of 135 classified observation clusters. Top-left: Dichotomy classification result. Red, green, and blue circles represent recent merger stage, ancient merger stage, and relaxed state clusters. From the top-right to the bottom of figure, the color gradient shows probabilities of recent merger (red, top-right), ancient merger (green, bottom-left), and relaxed state (blue, bottom-right). |
| In the text | |
|
Fig. 9. Precision, recall, and accuracy changes by number of combined indicators. The upper three plots show results from two merger stage classifications (merger and relax), and the lower three plots show results from three merger stage classifications. From Left to right columns, precision, recall, and accuracy results were shown. Each color of line represents a different merger stage, which can be identified in the legend. The solid line and dashed line indicate the projected classifier and non-projected classifier results, respectively. Shade shows scatter from different indicator combinations. |
| In the text | |
|
Fig. 10. Classification number of cluster tendency by number of combined indicators. Left: Projected model results for two merger stage classifications. Right: Projection model results for three merger stage classifications. Different colors, symbols, and line styles represent different merger stages, and it can be checked in the legend. |
| In the text | |
|
Fig. 11. Left: Mass dependency of six dynamical state indicators. Each color and shape of symbols represent different dynamical state indicators. Sort of indicator can check in the legend. Detailed information of indicators is in section 3.1. X error shows bin size and y error shows standard deviation of values within bin. Right: Redshift dependency of six dynamical state indicators. Features are same with left panel. |
| In the text | |
|
Fig. A.1. Indicator importance test with different methods. Top: Violin plot of indicator relevances from the GRLVQ method. Bottom: Violin plot of indicator importances from the random forest method. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.