| Issue |
A&A
Volume 659, March 2022
|
|
|---|---|---|
| Article Number | A132 | |
| Number of page(s) | 11 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202142301 | |
| Published online | 17 March 2022 | |
Statistical strong lensing
III. Inferences with complete samples of lenses
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 CA Leiden, The Netherlands
e-mail: sonnenfeld@strw.leidenuniv.nl
Received:
24
September
2021
Accepted:
15
December
2021
Context. Existing samples of strong lenses have been assembled by giving priority to sample size, but this is often at the cost of a complex selection function. However, with the advent of the next generation of wide-field photometric surveys, it might become possible to identify subsets of the lens population with well-defined selection criteria, trading sample size for completeness.
Aims. There are two main advantages of working with a complete sample of lenses. First, such completeness makes possible to recover the properties of the general population of galaxies, of which strong lenses are a biased subset. Second, the relative number of lenses and non-detections can be used to further constrain models of galaxy structure. The present work illustrates how to carry out a statistical strong lensing analysis that takes advantage of these features.
Methods. I introduce a general formalism for the statistical analysis of a sample of strong lenses with known selection function, and then test it on simulated data. The simulation consists of a population of 105 galaxies with an axisymmetric power-law density profile, a population of background point sources, and a subset of ∼103 strong lenses, which form a complete sample above an observational cut.
Results. The method allows the user to recover the distribution of the galaxy population in Einstein radius and mass density slope in an unbiased way. The number of non-lenses helps to constrain the model when magnification data are not available.
Conclusions. Complete samples of lenses are a powerful asset with which to turn precise strong lensing measurements into accurate statements on the properties of the general galaxy population.
Key words: gravitational lensing: strong / galaxies: fundamental parameters
© ESO 2022
1. Introduction
Strong gravitational lenses have been used extensively to study the structure and late (z < 1) evolution of massive galaxies, both through the detailed study of a small number of systems (see e.g. Sonnenfeld et al. 2012; Barnabè et al. 2013; Smith et al. 2015; Collett et al. 2018; Schuldt et al. 2019) and with the statistical combination of tens of objects (Auger et al. 2010; Bolton et al. 2012; Schechter et al. 2014; Oguri et al. 2014; Sonnenfeld et al. 2015; Oldham & Auger 2018). However, strong lenses are rare systems, and dedicated follow-up observations are usually required to confirm their nature and to obtain all of the necessary information for a successful analysis. For these reasons, past lens-finding campaigns were carried out with the primary goal of maximising sample size while minimising costs in terms of observational time. This approach made it possible, in the past decade, to carry out invaluable investigations of the structure of galaxies. However, at the same time, it made the selection function of the existing samples of lenses a highly non-trivial one.
Let us consider for example the Strong Lensing Legacy Survey (SL2S, Ruff et al. 2011; Gavazzi et al. 2012; Sonnenfeld et al. 2013a,b). SL2S lens candidates were first identified in ground-based imaging data with the automatic lens-finding tool RINGFINDER (Gavazzi et al. 2014), the performance of which was quantified on simulated lenses. Subsequently, lens candidates were visually inspected and ranked on the basis of their likelihood of being strong lenses according to the judgement of strong-lensing experts. A few tens of the most promising lens candidates were followed up with spectroscopic observations from 8 m-class telescopes and with high-resolution imaging data from the Hubble Space Telescope, with greater priority given to lenses with larger photometric redshifts. Finally, the systems for which follow-up observations yielded measurements of the lens and source redshift were used for the science analyses.
The final sample was then the result of a combination of algorithms, human decisions, and the efficiency of obtaining source redshifts from spectroscopic observations. The probability of a strong lens being included in the SL2S sample is, at the very least, a function of Einstein radius, source surface brightness, image configuration, lens–source contrast, source redshift, and source emission line strength. Clearly, it is very difficult to obtain an accurate description of such a high-dimensional probability distribution.
The main problem of working with lens samples with an unknown selection function is that it is difficult to generalise the measurements obtained with them to the population of galaxies from which they are drawn. Strong lens samples are a biased subset of the general galaxy population for two reasons. First, galaxies that are more massive and more compact have a higher cross-section for strong lensing and are therefore more likely to be strong lenses. Second, the probability of a lens being included in a given survey depends on the efficiency of the survey at discovering it and obtaining all of the necessary data for its analysis.
In the next few years, upcoming wide-field surveys such as Euclid1, the LSST2, and the Chinese Space Station Telescope (CSST) will enable the discovery of the order of 105 new strong lenses (Collett 2015). However, the first paper of this series (Sonnenfeld & Cautun 2021, hereafter Paper I) showed how a sample of 103 strong lenses can be sufficient to obtain precise and accurate measurements of several important parameters of the structure of galaxies, such as the stellar mass-to-light ratio and the dark matter density profile. This means that, using the full set of 105 Euclid-LSST-CSST lenses as a starting point, there will be ample freedom in determining how such a sample is defined. Depending on the efficiency of the lens-finding algorithms used, it might be possible to define subsamples of the lens population that are complete within a well-defined region in observational space. The goal of the present paper is to illustrate the advantages of working with such a complete subsample of lenses.
When the properties of the background source population are known, there are two benefits in having a complete lens sample. The first is that it is possible to model the mapping between the general population of galaxies and that of the lens sample, thus removing the bias introduced by strong lensing. The second is that the number of non-detections can be used along with the lensing data to further constrain models of galaxy structure. In this work, I illustrate how to take advantage of these features in a statistical strong lensing inference.
Building on past work (Sonnenfeld et al. 2015, 2019), I first introduce a general formalism for inferring the properties of the galaxy population from the analysis of a strong lensing survey with known selection function. I then extend this formalism to incorporate information from the number of non-lenses in the survey. I test this method on a simulated complete set of lenses generated under a series of simplifying assumptions. Although additional work is needed to apply this formalism to real samples of lenses, this is the necessary first step towards enabling accurate inferences of galaxy properties with samples of strong lenses.
The structure of this work is as follows. In Sect. 2, I introduce the theoretical formalism on which this work is based. In Sect. 3, I describe the simulations used to test the analysis method. In Sect. 4, I describe the model that I used to fit the simulated data. In Sect. 5, I show the results of the experiment. I discuss the results in Sect. 6 and draw conclusions in Sect. 7. The Python code used for the simulation and analysis of the lens sample can be found in a dedicated section of a GitHub repository3.
2. Theory
In this section, I introduce the theoretical foundation for the analysis method used in this work. In Sect. 2.1, I define the quantities on which this method is based. In Sect. 2.2, I explain how to infer the properties of a population of galaxies from the observation of a subset of strong lenses drawn from it. In Sect. 2.3, I explain how to combine information from the strong lenses with non-detections.
2.1. Definitions
2.1.1. Parameters and distributions
Let us consider a strong lens survey that searches for lenses among a well-defined population of foreground galaxies and background sources, with a lens selection criterion S. Let us assume that all of the properties of a galaxy that are relevant for determining its probability of being a lens can be summarised with a set of parameters ψg. This set of parameters will include the redshift of the galaxy and quantities describing its mass distribution. Let ψs be a set of parameters that are relevant for determining the probability of a background source to be strongly lensed. These parameters will include the redshift of the source, and quantities describing its surface brightness distribution.
Given a lens-source pair, (ψg, ψs), let Pdet(ψg, ψs|S) be the probability of the two objects to produce a lens that is detected by our survey, given the selection criterion S. Finally, let Pg(ψg) and Ps(ψs) be the probability distribution of the foreground galaxy and background source population, respectively. With these definitions, the (unnormalised) probability distribution of the population of strong lenses resulting from the survey is
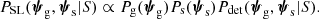
The main quantity of interest is the distribution of the properties of the lens galaxy population, Pg(ψg). However, strong lensing data can only directly constrain the left-hand side term, PSL(ψg, ψs|S). This is, in a broad sense, an inverse problem. As I show in this work, if the background source population Ps(ψs) and the lens detection probability Pdet(ψg, ψs|S) are known, it is possible to effectively invert Eq. (1) and solve for Pg(ψg). Table 1 lists the definitions of all of the quantities introduced in this section, as well as those that are defined later in this paper.
Notations used in this work.
2.1.2. The lensing cross-section
A very important parameter necessary to evaluate the likelihood of strong lensing data is the source position relative to the lens, β. This is a source parameter, and therefore it is included in ψs. However, it is convenient to split ψs as follows:
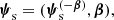
where 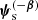 includes all of the remaining source parameters.
includes all of the remaining source parameters.
Let us assume that the angular position in the sky does not correlate with any other source property. Given a strong lens with parameters 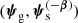 , the probability of the source position being β is proportional to
, the probability of the source position being β is proportional to
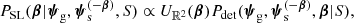
where 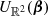 is a uniform distribution over the sky. The inverse of the normalisation constant of this distribution is
is a uniform distribution over the sky. The inverse of the normalisation constant of this distribution is
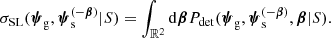
I refer to this quantity as the strong lensing cross-section.
I point out that σSL does not necessarily correspond to a well-defined region in the source plane, within which a source is always lensed. This is because the detection probability Pdet can take any value between 0 and 1, meaning that certain lens–source pairs only give rise to detected lenses with some probability.
2.1.3. Selection criteria
In this work, I focus on a particular class of lens-selection criteria based on a cut in observational space. Let d be an array that summarises the observational data that are relevant for the detection and modelling of a strong lens. This array will include, for instance, the observed lens and source redshift (formally, these are different from the true redshifts that are included in ψg and ψs), the surface brightness distribution of the lens galaxy, the number of images of the strongly lensed source, and their position and surface brightness distribution. I then consider, as selection criterion, one that only selects lenses within a volume Ω of the multi-dimensional space spanned by the data array:
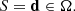
An example of such a criterion is the following: only lens galaxies brighter than a minimum luminosity, within a given redshift range, with at least two strongly lensed images brighter than a given threshold are included in the sample.
Finally, I assume that it is possible to define a volume Ω in observational space and design a lens survey that retrieves all of the existing lenses in Ω. I refer to that as a complete lens sample over the volume Ω.
2.2. Inference with strong lenses alone
Let us assume that the galaxy distribution can be described with an analytical model summarised by a set of population-level parameters η:
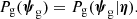
The goal of this method is to infer the posterior probability distribution of η given the data from the ensemble of strong lenses, {d}. From Bayes’ theorem, this is given by the product between the prior probability of η and the likelihood of observing the data given η:
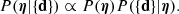
Measurements obtained on different lenses are independent from each other. Therefore, the likelihood term can be written as
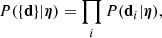
where di is the data array relative to the ith lens. The observed data depend only indirectly on the lens population parameters η: only after specifying the parameters describing the lens and the source properties, ψg and ψs, is it possible to evaluate the likelihood. As these are not univocally set by η, it is necessary to marginalise over all possible values taken by them. In other words, each factor in the product of Eq. (8) becomes
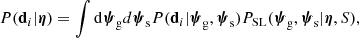
where PSL(ψg, ψs|η, S) is the normalised probability distribution of the strong lenses given the galaxy population parameters η and the lens selection criterion S. With these definitions, it is possible, in principle, to explore the parameter space of η and compute its posterior probability distribution.
Equation (9) is very similar in form to Eq. (30) of Paper I. The main difference is that the formalism adopted in that case was aimed purely at inferring the properties of the lens galaxies. Here, instead, the goal is to recover the distribution of the general galaxy population, Pg(ψg|η), which enters the integrand function of Eq. (9) through the product of Eq. (1).
Evaluating integrals of the kind of Eq. (9) in an accurate way requires good knowledge of the source population and the lens detection probability. Having a complete lens set is not a strict requirement for this purpose, but, as I discuss later, simplifies the problem and guarantees robustness.
2.3. Inference with lenses and non-detections
Section 2.2 explains how to infer the properties of the galaxy population, summarised by the parameters η, when using only data from detected strong lenses. When also considering non-detections, we need to adopt a slightly different formalism.
First of all, the data array d is modified to include an additional observable: the number of strongly lensed sources, Ns. This is Ns = 0 for the non-detections and Ns = 1 (or larger, in the rare cases in which more than one source is strongly lensed by the same galaxy) for the lenses. Second, the product of Eq. (8) is now calculated over the entire galaxy sample. Third, only a fraction of the galaxies in the sample have a background source associated with them. Given these considerations, it is useful to first expand the integrands of Eq. (8) in terms of the galaxy parameters only:
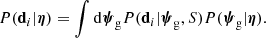
In this case, the galaxy probability distribution is simply described by P(ψg|η), which is the distribution of the general galaxy population. This is because galaxies are included in the sample independently of whether they produce a detectable strong lens or not.
Let us consider the case in which a given galaxy is not a strong lens. The only data available in this situation are the number of strongly lensed sources (Ns = 0) and observables related to the lens galaxy, which I indicate with dg. The likelihood term P(di|ψg, S) can then be written as
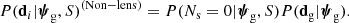
The first factor on the right-hand side of the above equation is the likelihood of observing no strongly lensed sources given the galaxy parameters and the selection criteria of the survey. The probability of detecting Ns lensed sources is given by Poisson statistics:
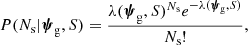
where λ(ψg, S) is the average number of strongly lensed sources that are expected for a galaxy with parameters ψg and a survey with selection criteria S. In the limit λ ≪ 1, which is usually satisfied in the galaxy-scale strong lensing regime, we have
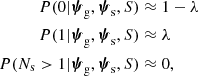
to first order in λ. Assuming that the background sources are uniformly distributed in space with average projected number density nbkg, then λ(ψg, S) is given by
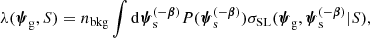
which is the product between nbkg and the strong lensing cross-section, averaged over the distribution of source parameters other than position, 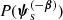 .
.
If a galaxy is a strong lens, then the data vector includes also observables related to the lensed source(s), ds. In order to compute the likelihood term P(di|η), then one must expand Eq. (10) by also including the source parameters. In the case of a single source, this becomes
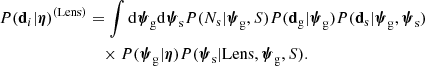
In the integrand function, the probability of observing the data given the lens and source parameters and the selection criteria is written as the product of three factors. The first factor is the probability of observing Ns lensed sources given the lens parameters and selection criteria, which is computed in the same way as in the non-detection case: first by calculating λ via Eq. (14), then by taking the Poisson probability of Eq. (12). The second factor in the integrand is the probability of observing galaxy-related data dg given the parameters ψg, while the third factor is the probability of observing the lensed image configuration ds given the lens and source parameters.
Finally, the last factor in the integrand of Eq. (15) is the probability distribution of the source parameters. This factor must take into account the fact that the source is strongly lensed. Therefore, its unnormalised probability distribution is given by
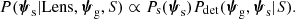
There is a subtle difference between the source parameters ψs of Eq. (15) and those entering the estimation of λ in Eq. (14). The former describe a well-defined background source that corresponds to the observed strongly lensed images. The latter refer generically to the source population and not to a specific source. For this reason, the probability of observing Ns sources depends only on the lens parameters and not on those of its associated source.
On a related note, there need not be a strict correspondence between the number of detected sources and the number of sources that are taken into account in a lens model. For example, if more than a single source is detected, one may decide to only explicitly model one of them, using Eq. (15), all of them, by expanding Eq. (15) over new dimensions ψs, 2, …, ψs, Ns, or even none of them. In this last case, the likelihood can be evaluated simply with Eq. (10).
3. Simulations
In this section, I describe the simulations created to test the method introduced in Sect. 2. The main purpose of these simulations is to show concrete examples of how to carry out an inference with a complete set of lenses. In order to make these examples easy to follow, I created the simulations by making the following series of simplifying assumptions:
-
All of the foreground galaxies have an axisymmetric mass distribution.
-
All of the background sources are point-like.
-
All of the foreground galaxies are at the same redshift, zg.
-
All of the background sources are at the same redshift, zs.
In sect. 3.1, I describe the properties of the foreground galaxy population. In Sect. 3.2, I describe the background source population. In Sect. 3.3, I describe the selection criterion of the resulting strong lens sample.
3.1. Foreground galaxy population
Each foreground galaxy is described by an axisymmetric power-law mass distribution. Let θ be the angular coordinate in the image plane along an axis with its origin on the lens centre. The lensing deflection angle of such a galaxy as a function of θ is
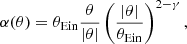
where θEin is the Einstein radius and γ is the density slope (the spherical deprojection of a power-law lens has a density profile ρ(r)∝r−γ).
As Sect. 2.1 of Paper I shows, the types of lensed image configurations that such a lens can produce depend on the value of γ. When γ < 2, the lens has a non-degenerate radial caustic: sources located inside the caustic are strongly lensed into three images. Assuming, without loss of generality, that the source position β is positive, the three images (θ1, θ2, θ3) are located at θ1 > θEin, −θEin < θ2 < −θrad and −θrad < θ3 < 0, where θrad is the radius of the radial critical curve.
Lenses with γ > 2 always produce two multiple images, at θ1 > θEin and −θEin < θ2 < 0. However, the magnification of image 2 goes to zero when the source position is large. Finally, when γ = 2 (not shown in Paper I), sources located within β < θEin are strongly lensed into two images. For more details of the lensing properties of axisymmetric power-law lenses, I refer to Sect. 2.1 of Paper I.
I generated 105 such galaxies, drawing log θEin and γ from the following distributions:
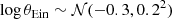
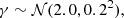
where 𝒩(μ, σ2) indicates a Gaussian with mean μ and variance σ2. The Einstein radius is in units of arcsec, and contains implicitly information on the lens and source redshift and on the cosmology.
3.2. Background source population
I obtained the distribution in apparent magnitude ms of the background sources as follows. First, I considered the rest-frame 1500 Å luminosity function of galaxies at 1.5 < z < 2.5 measured by Parsa et al. (2016). I then converted this to the g-band apparent magnitude assuming a fixed redshift of z = 1.5, which is a typical value for a galaxy-scale strong lens, and a fixed spectral energy distribution, the ‘starb1’ template from the Kinney-Calzetti Spectral Atlas of Galaxies (Calzetti et al. 1994; Kinney et al. 1996). The resulting apparent magnitude distribution is the following:
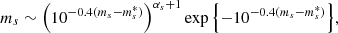
with 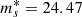 (also referred to as the knee of the magnitude distribution) and αs = −1.32 (the faint-end slope). For the sake of computational efficiency, I truncated the distribution outside of the range ms ∈ [23.0, 28.0]. This cut does not affect the results: the number of galaxies brighter than 23 in the distribution of Eq. (20) is highly suppressed, and, because of the lens-selection criterion that is introduced in Sect. 3.3, the fraction of galaxies fainter than 28 that results in detected strong lenses is also very small.
(also referred to as the knee of the magnitude distribution) and αs = −1.32 (the faint-end slope). For the sake of computational efficiency, I truncated the distribution outside of the range ms ∈ [23.0, 28.0]. This cut does not affect the results: the number of galaxies brighter than 23 in the distribution of Eq. (20) is highly suppressed, and, because of the lens-selection criterion that is introduced in Sect. 3.3, the fraction of galaxies fainter than 28 that results in detected strong lenses is also very small.
I generated, behind each lens, a random realisation of background source positions drawn from a uniform distribution with average number density nbkg = 100 arcmin−2. Most of these sources are very faint by the standard of current wide-field photometric surveys. When considering only sources brighter than 26, nbkg is a factor of four smaller and closely matches the number density of sources in the Hyper Suprime-Cam Subaru Strategic Program (HSC survey Aihara et al. 2018) weak-lensing shear catalogue (approximately 25 arcmin−2, Mandelbaum et al. 2018).
3.3. Selection criteria
For each lens, I defined a search region in the source plane to identify background sources that are multiply imaged. For lenses with γ < 2, this search region was simply the area within the radial caustic. For lenses with γ > 2, I set the limit to a very large value of β. For each multiply imaged source, I solved the lens equation,
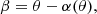
to find the image positions. I assumed that only images 1 and 2 are observable, and discarded image 3, which, when present, is typically highly de-magnified. I calculated the magnification μ of each image and used it to compute its magnitude:
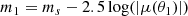
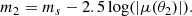
With m1 and m2 I indicate the true magnitudes of the two images. I then added a random observational error of ϵm = 0.1 mag to m1 and m2 to generate observed magnitudes:
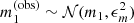
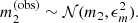
Given these data, I defined as a strong lens any lens-source pair for which the observed magnitude of image 2 is brighter than a limiting magnitude mmax = 26.6. The choice of this value is based on the lens search of Sonnenfeld et al. (2018) among data from the HSC survey: it corresponds to the 5σ detection limit for a point source in the g-band, which is the band used by Sonnenfeld et al. (2018) for the detection of lensed images. The selection criterion is then
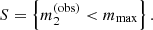
The rationale for this choice is the following. The process of finding lenses always involves a visual inspection step. During this step, lensing experts estimate to what degree a lens candidate can be considered a real strong lens. Only lenses that are identified with high confidence are used for a scientific analysis. One very important element that experts look for in their classification is the presence of multiple images (see e.g. Sonnenfeld et al. 2020). In all practical cases, image 1 is always brighter than image 2. Therefore, the condition of Eq. (26) ensures that both images are detected.
Finally, I assumed that the strong lens survey is complete above the limit imposed with Eq. (26): all of the lenses with an observed magnitude brighter than image 2 are included in the sample; all of the remaining lenses are discarded and treated as non-detections. Under these assumptions, the detection probability of a lens-source pair that produces two images is
![$$ \begin{aligned} {P}_\mathrm{det} (\theta _{\mathrm{Ein} },\gamma ,m_s,\beta |S) = \frac{1}{2}\left[1 - {\mathrm{erf} }{\left(\frac{m_2 - m_{\mathrm{max} }}{\sqrt{2}\epsilon _m}\right)}\right]. \end{aligned} $$](/articles/aa/full_html/2022/03/aa42301-21/aa42301-21-eq38.gif)
The generated sample consists of 867 lenses, out of the initial 105 galaxies. This is a typical value for the ratio between the number of lenses and the number of inspected galaxies in the HSC lens search (Sonnenfeld et al. 2018).
Figure 1 shows the distribution in Einstein radius and density slope of the lens sample compared to that of the parent population of galaxies. The lenses have on average a larger Einstein radius. This can be easily understood: at fixed density slope, a galaxy with a larger Einstein radius has a larger lensing cross-section (to be precise, 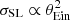 ), and therefore is more likely to be a lens. Additionally, the average value of γ of the lens sample is also larger than that of all galaxies (this can be clearly seen in the histogram at the bottom right of Fig. 1). This suggests that the lensing cross-section is also an increasing function of γ.
), and therefore is more likely to be a lens. Additionally, the average value of γ of the lens sample is also larger than that of all galaxies (this can be clearly seen in the histogram at the bottom right of Fig. 1). This suggests that the lensing cross-section is also an increasing function of γ.
 |
Fig. 1. Distribution in Einstein radius and density slope of the strong lens sample (filled contours and histograms) and of the parent population of galaxies (solid lines). Contour levels enclose 68% and 95% of the sample. The histograms are normalised by the number of objects. |
To better illustrate this feature, Fig. 2 shows σSL as a function of γ for lenses at fixed θEin = 1″ and sources of different magnitudes.
 |
Fig. 2. Strong lensing cross-section, defined according to Eq. (4), as a function of density slope for a power-law lens with Einstein radius θEin = 1″. Coloured lines correspond to different source magnitudes according to the legend. The dotted line indicates the area in the source plane that is lensed into multiple images (infinite for γ > 2). |
The dotted line shows the area of the source-plane region within which a source is lensed into multiple images. This can be considered as the lensing cross-section of an infinitely bright source, which is an upper limit on σSL.
For low values of γ, σSL is equal to this upper limit, independently of the source magnitude: this means that, for any source position within the radial caustic, the magnification of image 2 is sufficiently large to guarantee its detection. As γ increases, we observe a different behaviour, depending on ms. At faint magnitudes, σSL decreases: this means that, with increasing γ, a larger area of the source plane is mapped into sets of images with a low magnification of image 2. However, at bright magnitudes, image 2 can be detected even when it is de-magnified, and therefore σSL increases with γ.
To better understand this behaviour, Fig. 3 shows the magnification of image 2 as a function of source position for a few values of γ. For γ < 2, the area of the source plane that produces multiple images (limited by the dashed line) decreases with decreasing γ, but the magnification of image 2 increases at fixed β. For γ > 2, the μ − β curves of different lenses cross each other. This crossing is responsible for the different trends of σSL with γ of sources with different magnitudes.
 |
Fig. 3. Negative magnification of image 2 as a function of source position for power-law lenses with θEin = 1″. Coloured lines correspond to different values of the density slope γ according to the legend. The dashed lines indicate the radial caustic position for the lenses of the corresponding colour. |
The net effect, when averaging over the source population, is that galaxies with a higher γ have a larger cross-section, and therefore the mean γ of the lens population is larger than that of the parent galaxy population. However, this is a result of the particular choice of the source magnitude distribution, and is not a general property of power-law lenses. For example, with a fainter knee of the source magnitude distribution (a higher value of parameter 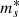 in Eq. (20)), the difference in the average density slope between the general population of galaxies and the strong lenses becomes smaller.
in Eq. (20)), the difference in the average density slope between the general population of galaxies and the strong lenses becomes smaller.
4. Model
The simulation produced 867 strong lenses, each with measurements of the two image positions, 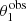 and
and 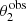 , and related magnitudes,
, and related magnitudes, 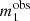 and
and 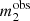 , and 99133 non-detections. I fitted these data with a population of galaxies with power-law density profile, and a population of background sources described by the same magnitude distribution as that used to generate the sample, Eq. (20). I described each galaxy with the pair of parameters (log θEin, γ), and assumed that their population distribution is the following product of Gaussians:
, and 99133 non-detections. I fitted these data with a population of galaxies with power-law density profile, and a population of background sources described by the same magnitude distribution as that used to generate the sample, Eq. (20). I described each galaxy with the pair of parameters (log θEin, γ), and assumed that their population distribution is the following product of Gaussians:
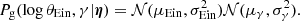
The population parameters of the model are the mean and standard deviations of these two Gaussians:
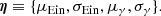
The distribution is expressed in terms of the logarithm of the Einstein radius rather than θEin, as this was the form used in Sect. 3.1 to generate the galaxy population. In general, a log-normal distribution in θEin is preferred over a simple Gaussian in θEin when the Einstein radius distribution of the sample is not limited to a well-defined order of magnitude. This is the case, for example, when both galaxy-scale and group- or cluster-scale lenses are included in the population.
This model reproduces exactly the true distribution that was assumed when creating the mock, for η = { − 0.3, 0.2, 2.0, 0.2}. In other words, the model is accurate by construction. This makes it possible to test for the accuracy of the inference method of Sect. 2.
Each lens has four degrees of freedom, θEin, γ, β, and ms, and four observational constraints: the two image positions and magnitudes. Therefore, unlike in Paper I, the model is fully constrained on an individual lens basis. However, the two magnitudes are only measured with a precision of 0.1 mag. When fitting a power-law model to an individual lens, this translates into an uncertainty on the density slope γ in the range 0.05−0.3, depending on the image configuration. This is illustrated in Fig. 4, which shows the 68% credible region on the Einstein radius and density slope of a subset of lenses obtained by assuming flat priors on all of the parameters. The circles in Fig. 4 show the true values of θEin and γ of the lenses and are colour-coded according to the image asymmetry parameter, which is defined as
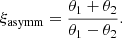
 |
Fig. 4. Inference on the Einstein radius and density slope of a subset of lenses obtained assuming flat priors on all of the lens model parameters. The black bars indicate the 68% credible region. Circles are true values of θEin and γ of the lenses and are colour-coded according to the image asymmetry parameter ξasymm, defined in Eq. (30). The grey dotted lines connect the true values to the corresponding measurement. |
Lenses with more asymmetric configurations (darker points) allow for a more precise inference on γ, though with a stronger degeneracy with θEin. These individual posteriors are shown for illustrative purposes and are not used in the analysis.
I fitted the model first to the sample of strong lenses, and then to the whole sample, including the non-detections. I assumed a flat prior on each parameter, over the range reported in Table 2. I sampled the posterior probability distribution P(η|{d}) with a Markov chain Monte Carlo (MCMC) method.
Inference on the model parameters.
The main technical challenge in this experiment is the computation of the likelihood. Each system in the sample contributes to the likelihood with a multi-dimensional integral: Eq. (9) (when using only lenses) or Eq. (15) (when using the whole sample). In the following two sections, I explain the procedure that I adopted to compute these integrals.
4.1. Likelihood computation: lenses-only case
When fitting the observed data with the power-law model introduced in this section, Eq. (9) becomes the following four-dimensional integral,
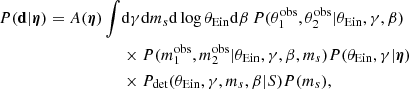
where A(η) is a normalisation constant defined as
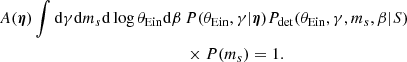
At fixed θEin, γ, and ms, the integral over β in Eq. (32) gives the strong-lensing cross-section defined in Eq. (4). The full integral of Eq. (32) is therefore the population-averaged σSL. This integral separates into a part that depends only on θEin, and a part that depends on (γ, ms). I computed the former with a general purpose 1D integration method, and the latter via Monte Carlo integration.
Let us now consider the image position likelihood term in Eq. (31). Assuming, as in Paper I, that the image positions are measured exactly, we have
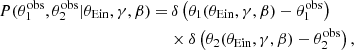
where θ1 and θ2 are the values of the image positions predicted by the model. At fixed γ and ms, the above product of Dirac delta functions can be easily eliminated after the following variable change,
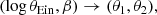
and subsequent integration over θ1 and θ2. The result of this operation is
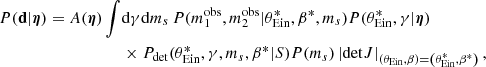
where 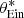 and β* are the values of the Einstein radius and source position needed to reproduce the observed image positions, and detJ is the Jacobian determinant of the variable change of Eq. (34).
and β* are the values of the Einstein radius and source position needed to reproduce the observed image positions, and detJ is the Jacobian determinant of the variable change of Eq. (34).
At fixed γ, the integral over ms is independent of the population parameters η. I computed this integral for each lens on a grid of values of γ with a spline approximation and integration prior to running the MCMC. Finally, I computed the integral over γ via spline integration for each lens at each draw of parameters η.
4.2. Likelihood computation: full sample case
The calculation of the likelihood terms of Eq. (8) takes different avenues, depending on whether the object is a lens or not. In the case of a non-detection, the likelihood of observing the data given the population parameters is obtained by combining Eqs. (10)–(12). The result is
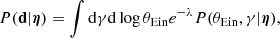
where λ is the expected number of lensed sources given the galaxy parameters. For a power-law lens, this quantity can be written as
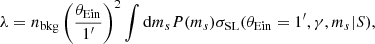
where the lensing cross-section in the integrand is evaluated at a unit Einstein radius. In other words, the dependence of λ on the Einstein radius is analytical. To obtain λ as a function of both θEin and γ, I computed the integral of Eq. (36) on a grid of values of γ and then interpolated the result with a spline polynomial. This calculation was done once before running the MCMC on the population parameters. I then computed the integral of Eq. (36) via Monte Carlo integration. As the non-lenses of the simulation are indistinguishable from one another, this integral is the same for all non-detections. Therefore, it only needs to be computed once (but with high precision) for each draw of η.
In the case of a strong lens, the likelihood is given by Eq. (15), which for a power-law lens model becomes
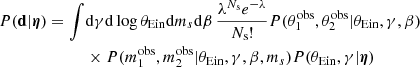
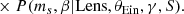
Using the same method as in Sect. 4.1, I reduced this to a 2D integral over γ and ms, which I then computed via spline integration.
Out of the 867 strong lenses, 13 have Ns = 2. For the purpose of evaluating the Poisson likelihood term of Eq. (12), I considered these as double-source lenses. However, I only used image positions and magnitudes for one randomly chosen source. In a real case scenario, all of the available lensed sources would be used for the analysis, as multiple sources allow for more precise constraints on the lens model parameters. However, that would result in a few lenses having extremely precise inferences of γ, which would then dominate the inference on the population parameters. I chose to only use a single source in order to give equal weight to each lens on the inference, which makes for easier interpretation of the results.
5. Results
Figure 5 shows the posterior probability distribution of the population model parameters η obtained by fitting the strong lenses only (green filled contours) and the entire sample of galaxies (red solid lines). The median and 68% credible region of the marginal posterior probability of each parameter is reported in Table 2. In both cases, the model is able to recover the true distribution of θEin and γ of the galaxy sample (dashed black lines).
 |
Fig. 5. Posterior probability distribution of the galaxy population model parameters, η, obtained by fitting only the strong lenses (green filled contours) and the full sample (red solid contour lines). All of the available lensing data (image positions and magnitudes) were used for the fit. Black dashed lines mark the true values of the parameters. Red dotted lines indicate the values of the parameters obtained by fitting the model of Eq. (28) to the subsample of strong lenses (the mean log θEin parameter value is μEin = −0.12, which is outside of the plot range). |
Figure 5 also shows the values of the model parameters of the population of lenses (dotted red lines), which I obtained by fitting the model of Eq. (28) directly to the true values of θEin and γ of the 867 lenses. The average value of γ of the lens population is 2.03. This is the value of μγ that one would infer by fitting the lens sample without taking into account selection effects (that is, following the method of Paper I). Thanks to the formalism introduced in this paper, this solution is ruled out at the 3σ level, and the true value μγ = 2.0 is recovered.
The posterior probability obtained when using the full galaxy sample (red solid lines in Fig. 5) is almost identical to the one based purely on the sample of lenses. The full sample brings in additional information: the number of non-detections and the number density of background sources, nbkg. However, this result shows that this information contributes little to the posterior, which is dominated by the strong lenses, with the exception of the parameter μEin.
The statement above is conditional on the type and quality of the data that the model is fitted to. For the analysis presented so far, I assumed that image positions and magnitudes are available for each lens. The magnitudes of the two images provide a constraint on the ratio of the magnifications at positions θ1 and θ2, which in turn can be used to constrain the density slope (see O’Riordan et al. 2019; O’Riordan et al. 2020). However, statistical strong lensing analyses often do not make use of magnification information (see e.g. Auger et al. 2010; Bolton et al. 2012; Sonnenfeld et al. 2015, 2019), the extraction of which usually requires high-quality imaging data.
I investigated an alternative scenario in which the only lensing data available are the image positions and the knowledge of the lens detection probability, Pdet, as a function of the model parameters. As the selection criterion of the simulated sample, Eq. (26), relies on the magnitude of the second image, it is difficult to imagine a situation in which Pdet is known but the image magnitudes are not. However, the rationale of this experiment is to simulate a more general scenario in which the selection function is known, but no magnification information is available.
Figure 6 shows the posterior probability distribution obtained by fitting the same model of Sect. 4 to lensing data, while removing the term related to the observed magnitudes, 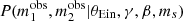 , from the likelihood. The inference on the parameters describing the γ distribution is much less precise as a result of the lack of direct constraints on the magnification ratios. When using only the strong lenses, I obtained μγ = 1.97 ± 0.10, which is an order of magnitude more uncertain than what the full dataset allows. In this case, the addition of the non-detections reduces this uncertainty by a factor of two: μγ = 2.01 ± 0.05.
, from the likelihood. The inference on the parameters describing the γ distribution is much less precise as a result of the lack of direct constraints on the magnification ratios. When using only the strong lenses, I obtained μγ = 1.97 ± 0.10, which is an order of magnitude more uncertain than what the full dataset allows. In this case, the addition of the non-detections reduces this uncertainty by a factor of two: μγ = 2.01 ± 0.05.
 |
Fig. 6. Same as Fig. 5, but obtained by fitting only the image positions (no magnitudes) of the lenses. |
Interestingly, image position data are still able to constrain μγ to some extent, even when non-detections are not considered. This is because certain image configurations can only be produced by lenses with certain values of γ: for example, in lenses with γ > 2, the position of image 2 can be arbitrarily close to the lens centre. However, if γ < 2, there is a lower limit to the value of θ2 set by the position of the radial critical curve. This explains the shape of the μγ − σγ degeneracy observed in the fit to the lens sample (see the panel in the third column and bottom row of Fig. 6): if the average γ is smaller than 2, the scatter in γ must be large in order to allow for the presence of lenses with γ > 2 in the sample, which are needed to reproduce highly asymmetric image configurations.
6. Discussion
6.1. Advantages of a complete lens sample
I introduced a formalism for the analysis of strong lensing data from a survey with known selection function, then applied it to a simulated sample of lenses that is complete above a well-defined observational cut. Sample completeness is not a strict requirement in order to apply the method of Sect. 2: in principle, it is sufficient to know the lens detection probability Pdet of the survey. However, if a fraction of lenses is missed by the survey in a way that correlates with some lens property and that is not taken into account by the model for Pdet, biases will be introduced.
For example, let us suppose that the lens-detection efficiency of a survey such as the one considered in Sect. 3 depends not only on the magnitude of image 2, but also on the surface brightness contrast between the lens and the source light. Let us suppose that lenses with a small value of θ2 are, for this reason, missed by the survey. If this selection is not taken into account, the model might be biased against solutions with large values of γ, which are instead needed to reproduce lenses with highly asymmetric configurations. Having a complete lens sample guarantees against such a possibility. In this example case, this requires ensuring that no lenses are missed, regardless of their image configuration.
6.2. Technical challenges
In order to apply this method to real samples of lenses, several challenges need to be overcome. The most important one is obtaining an accurate description of the lens-detection probability in order to avoid biases like the one in the example above. The experiment that I carried out assumed point-like sources, but virtually all strongly lensed sources have non-zero size. Lensed galaxies are usually well-resolved, which means that their detection depends on their surface brightness distribution. The source parameter set, ψs, will then need to include quantities such as the half-light radius and the Sérsic index in addition to the magnitude.
As new parameters are introduced, the model describing the source population, P(ψs), must be updated accordingly. While, in principle, ψs can be measured on the large population of galaxies that are not strongly lensed, in practice the lens detection probability could depend on features that are below the resolution limit of non-lensed galaxies. For example, the presence of bright clumps can boost the detectability of a lens, but the appearance of a clumpy galaxy changes when it is strongly lensed, which is due to the magnification effect (see e.g. Faure et al. 2021). It is possible, in principle, to generalise the model of Sect. 4 and infer the source property distribution P(ψs) simultaneously with the lens distribution. In practice, this would increase the computational burden of the inference procedure.
In the case of a lens sample selected on the basis of the availability of spectroscopic redshifts, then the selection function needs to also take into account the efficiency of obtaining such measurements. On the one hand, this can complicate the selection function even further, as in the case of the SL2S survey discussed in Sect. 1. On the other hand, if the primary means of the lens search is spectroscopic, meaning that the presence of a lensed source is assessed with the same observational data used to measure its redshift, then the image detection and source redshift measurement aspects of the problem can be merged.
This is the case, for example, of the Sloan ACS Lens Survey (SLACS, Bolton et al. 2006), and the SINFONI Nearby Elliptical Lens Locator Survey (SNELLS, Smith et al. 2015). Arneson et al. (2012) carried out a study of the selection function of SLACS, which, if extended, could be used to carry out an analysis like the one presented in this paper. SNELLS, and the more recent MNELLS (Collier et al. 2020), are particularly well suited for the application of this method in virtue of their clean selection function.
One class of systems for which it is easier to obtain the selection function compared to lensed galaxies is that of strongly lensed quasars. Current lensed quasar searches are already able to produce highly complete lens samples (see e.g. Agnello & Spiniello 2019). It could be possible, in the near future, to identify a complete set of strongly lensed quasars: for instance, by carrying out a systematic search on a well-defined sample of massive galaxies, applying a selection criterion such as that of Eq. (26), and obtaining spectroscopic follow-up observations to obtain redshifts and rule out contaminants (as was done by Agnello et al. 2018).
However, lensed quasars are subject to microlensing, which introduces a source of scatter in the relation between the intrinsic source magnitude and the observed one. Microlensing depends on the fraction of mass in compact objects (that is, stars) and on the size of the light-emitting region of the quasar, which is the accretion disk. A rigorous analysis would require modelling microlensing in order to obtain an accurate selection function of lensed quasars. This would also provide an opportunity to further constrain the stellar mass-to-light ratio of the lens galaxies (Vernardos 2019). However, there is an associated cost in terms of model complexity.
If the lens detection probability is a function of image configuration, whether directly, or, as in the simulation of Sect. 3, indirectly (highly asymmetric configurations are rarely detected because of the de-magnification of image 2), then the lens population model, P(ψg), needs to be extended. This is because, unlike in the experiment carried out in this work, real lenses are not axisymmetric, and the ellipticity of a lens can change the number, the shape, and the magnification of the strongly lensed images. At the very least, it is necessary to add two degrees of freedom to the model: the axis ratio and orientation of the mass component. Moreover, lens models often require that external shear be accounted for in order to correctly reproduce the observed images. Galaxy ellipticity and external shear could be incorporated into the hierarchical model used to describe the lens population, but this would make computations more challenging (especially the evaluation of integrals of the kind of Eq. (9)).
In summary, most practical applications of the method proposed in this paper will likely require an extension of the model considered so far. This will pose important computational challenges analogous to those discussed in Sect. 6.5 of Paper I.
6.3. Other applications
In addition to providing unbiased descriptions of the structural parameter distribution of galaxies, this method can be used for combining information from different samples of lenses. One important case in which this is needed is the analysis of time-delay lenses for the study of cosmology. The current approach of the leading team in this field, the TDCOSMO4 collaboration, is that of using information obtained from samples of strong lenses with no time delays as a prior on a smaller set of time-delay lenses (Birrer et al. 2020). In Paper II (Sonnenfeld 2021), I showed how, with such an approach, it is possible to obtain 1%-level measurements of the Hubble constant.
However, Eq. (1) shows that two different lens samples, PSL, 1 and PSL, 2, with different source populations, Ps, 1 and Ps, 2, and selection functions Pdet, 1 and Pdet, 2, are biased in different ways with respect to the general population of galaxies Pg. Therefore, using information relative to one lens sample as a prior on the other might lead to biases (the amplitude of which needs to be quantified with dedicated simulations).
The formalism introduced in this work offers a solution to this problem: if the parent population of galaxies, among which strong lenses are searched, is selected in the same way in the two surveys, then Pg is by construction the same distribution for the two samples. It is relatively easy to achieve this: usually, galaxy populations are selected by means of cuts applied at the catalogue level (e.g. by imposing that galaxies lie in a given redshift range and are brighter than a luminosity threshold), and so it is sufficient to apply the same cuts consistently to the two samples. In that case, it is possible, with the method of Sect. 2, to infer Pg from one sample and then use it as a prior on the other sample.
Another possible application is the analysis of strong lenses with no spectroscopic measurement of the source redshift. Although for the experiment carried out in this work I assumed that the source redshifts were known, this is not a strict requirement. The main requirement is for the source parameter distribution, P(ψs), to be known, which includes the source redshift. If that is the case, then the source redshift can be treated as a nuisance parameter and marginalised over. This is the subject of Paper IV (Sonnenfeld 2022).
Finally, information from the relative number of lenses and non-detections can in principle be used to break the mass–sheet degeneracy. This is because, in general, a mass–sheet transformation (see Sect. 2.1 of Paper II, for a definition) changes the strong lensing cross-section of a galaxy. I tried to explore this possibility on the sample generated in Sect. 3. However, the change in σSL with the mass–sheet transformation parameter varies with source magnitude, and any signal is washed out after averaging over the source population.
7. Conclusions
This paper introduced the formalism necessary for inferring the structural properties of a sample of galaxies from the observations of a subset of strong lenses drawn from it. Although the strong lenses are a biased sample, when the properties of the background source population and the selection function of the sample are known, it is possible, with this method, to remove this bias.
There are two variations of the method: one that uses only the strong lenses, and one that combines the lens sample with non-detections. I tested both of these methods on a simulated sample of galaxies that included a complete set of lenses. In both cases, the true properties of the general galaxy population were accurately recovered.
The experiment also revealed that, when the lensing data provide constraints on the relative magnification between the images, in addition to the image positions, then the non-detections add little constraining power. Nevertheless, in such cases, the number of non-detections could be used as a consistency check to test the model assumptions. However, when magnification constraints are not available, non-detections reduce model uncertainties significantly.
There are several technical challenges to be overcome in order to apply this method to real samples of lenses. Nevertheless, the formalism developed in this work constitutes the first necessary step towards using strong lenses to make unbiased statements on the galaxy population.
References
- Agnello, A., & Spiniello, C. 2019, MNRAS, 489, 2525 [Google Scholar]
- Agnello, A., Schechter, P. L., Morgan, N. D., et al. 2018, MNRAS, 475, 2086 [Google Scholar]
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Arneson, R. A., Brownstein, J. R., & Bolton, A. S. 2012, ApJ, 753, 4 [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010, ApJ, 724, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Barnabè, M., Spiniello, C., Koopmans, L. V. E., et al. 2013, MNRAS, 436, 253 [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bolton, A. S., Burles, S., Koopmans, L. V. E., Treu, T., & Moustakas, L. A. 2006, ApJ, 638, 703 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, A. S., Brownstein, J. R., Kochanek, C. S., et al. 2012, ApJ, 757, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Calzetti, D., Kinney, A. L., & Storchi-Bergmann, T. 1994, ApJ, 429, 582 [Google Scholar]
- Collett, T. E. 2015, ApJ, 811, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Collett, T. E., Oldham, L. J., Smith, R. J., et al. 2018, Science, 360, 1342 [CrossRef] [Google Scholar]
- Collier, W. P., Smith, R. J., & Lucey, J. R. 2020, MNRAS, 494, 271 [NASA ADS] [CrossRef] [Google Scholar]
- Faure, B., Bournaud, F., Fensch, J., et al. 2021, MNRAS, 502, 4641 [CrossRef] [Google Scholar]
- Gavazzi, R., Treu, T., Marshall, P. J., Brault, F., & Ruff, A. 2012, ApJ, 761, 170 [Google Scholar]
- Gavazzi, R., Marshall, P. J., Treu, T., & Sonnenfeld, A. 2014, ApJ, 785, 144 [Google Scholar]
- Kinney, A. L., Calzetti, D., Bohlin, R. C., et al. 1996, ApJ, 467, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Mandelbaum, R., Miyatake, H., Hamana, T., et al. 2018, PASJ, 70, S25 [Google Scholar]
- Oguri, M., Rusu, C. E., & Falco, E. E. 2014, MNRAS, 439, 2494 [Google Scholar]
- Oldham, L. J., & Auger, M. W. 2018, MNRAS, 476, 133 [Google Scholar]
- O’Riordan, C. M., Warren, S. J., & Mortlock, D. J. 2019, MNRAS, 487, 5143 [CrossRef] [Google Scholar]
- O’Riordan, C. M., Warren, S. J., & Mortlock, D. J. 2020, MNRAS, 496, 3424 [CrossRef] [Google Scholar]
- Parsa, S., Dunlop, J. S., McLure, R. J., & Mortlock, A. 2016, MNRAS, 456, 3194 [Google Scholar]
- Ruff, A. J., Gavazzi, R., Marshall, P. J., et al. 2011, ApJ, 727, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Schechter, P. L., Pooley, D., Blackburne, J. A., & Wambsganss, J. 2014, ApJ, 793, 96 [Google Scholar]
- Schuldt, S., Chirivì, G., Suyu, S. H., et al. 2019, A&A, 631, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smith, R. J., Lucey, J. R., & Conroy, C. 2015, MNRAS, 449, 3441 [Google Scholar]
- Sonnenfeld, A. 2021, A&A, 656, A153 (Paper II) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A. 2022, A&A, 659, A133 (Paper IV) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., & Cautun, M. 2021, A&A, 651, A18 (Paper I) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2012, ApJ, 752, 163 [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013a, ApJ, 777, 97 [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013b, ApJ, 777, 98 [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018, PASJ, 70, S29 [Google Scholar]
- Sonnenfeld, A., Jaelani, A. T., Chan, J., et al. 2019, A&A, 630, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Verma, A., More, A., et al. 2020, A&A, 642, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vernardos, G. 2019, MNRAS, 483, 5583 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Distribution in Einstein radius and density slope of the strong lens sample (filled contours and histograms) and of the parent population of galaxies (solid lines). Contour levels enclose 68% and 95% of the sample. The histograms are normalised by the number of objects. |
| In the text | |
|
Fig. 2. Strong lensing cross-section, defined according to Eq. (4), as a function of density slope for a power-law lens with Einstein radius θEin = 1″. Coloured lines correspond to different source magnitudes according to the legend. The dotted line indicates the area in the source plane that is lensed into multiple images (infinite for γ > 2). |
| In the text | |
|
Fig. 3. Negative magnification of image 2 as a function of source position for power-law lenses with θEin = 1″. Coloured lines correspond to different values of the density slope γ according to the legend. The dashed lines indicate the radial caustic position for the lenses of the corresponding colour. |
| In the text | |
|
Fig. 4. Inference on the Einstein radius and density slope of a subset of lenses obtained assuming flat priors on all of the lens model parameters. The black bars indicate the 68% credible region. Circles are true values of θEin and γ of the lenses and are colour-coded according to the image asymmetry parameter ξasymm, defined in Eq. (30). The grey dotted lines connect the true values to the corresponding measurement. |
| In the text | |
|
Fig. 5. Posterior probability distribution of the galaxy population model parameters, η, obtained by fitting only the strong lenses (green filled contours) and the full sample (red solid contour lines). All of the available lensing data (image positions and magnitudes) were used for the fit. Black dashed lines mark the true values of the parameters. Red dotted lines indicate the values of the parameters obtained by fitting the model of Eq. (28) to the subsample of strong lenses (the mean log θEin parameter value is μEin = −0.12, which is outside of the plot range). |
| In the text | |
|
Fig. 6. Same as Fig. 5, but obtained by fitting only the image positions (no magnitudes) of the lenses. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.