Fig. 2.
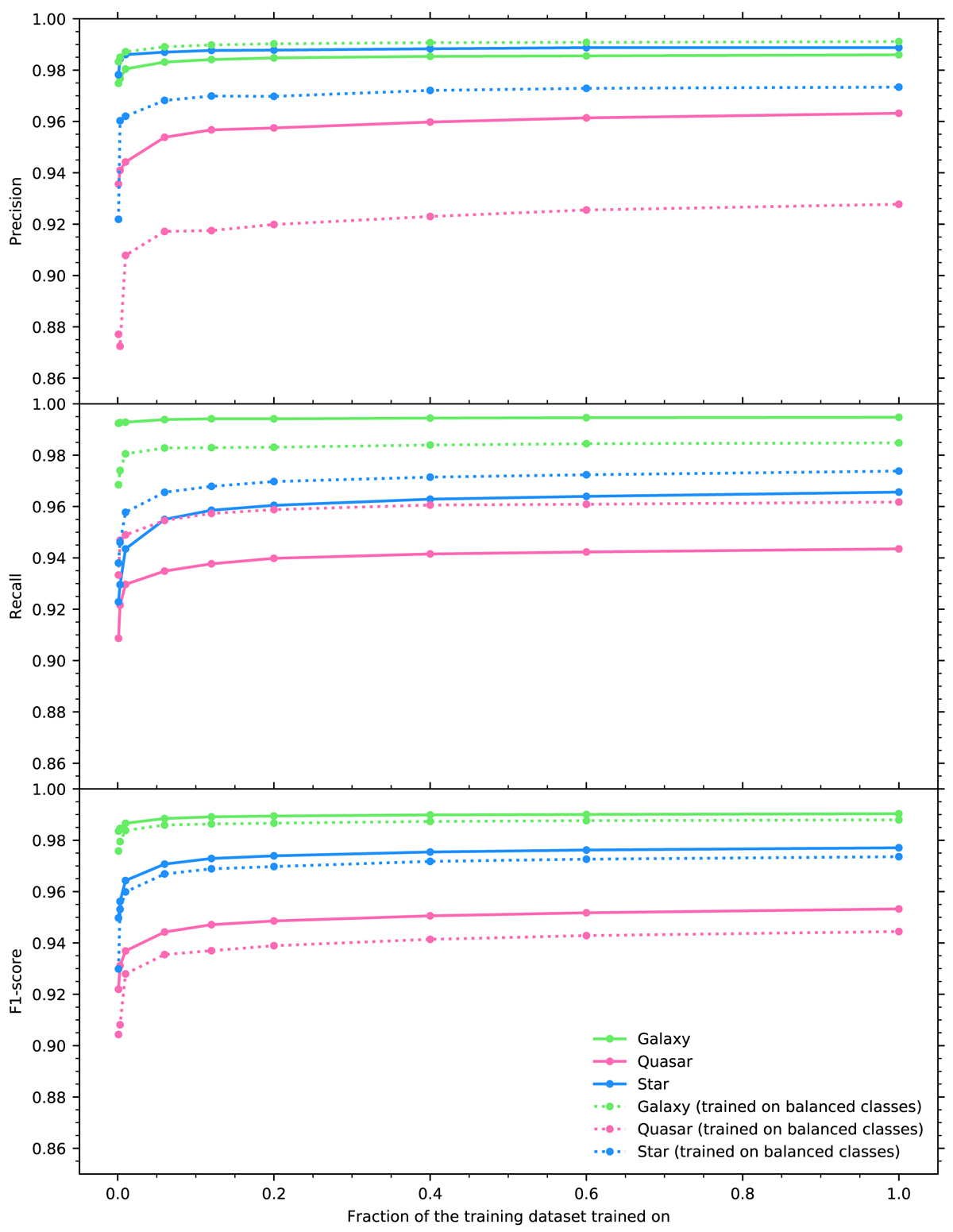
Precision (top), recall (middle), and F1 score (bottom) per class as a function of the fraction of the training dataset (1.55 million sources) used to train the random forest. Balancing the classes was done by taking 20% of the galaxies in the training set. All models were evaluated on the test dataset of 1.55 million spectroscopically confirmed sources, without balancing the classes. Class weights inversely proportional to the class frequency were used in the training in all cases.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.