| Issue |
A&A
Volume 638, June 2020
|
|
|---|---|---|
| Article Number | A95 | |
| Number of page(s) | 10 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/201936906 | |
| Published online | 19 June 2020 | |
Efficient modeling of correlated noise
II. A flexible noise model with fast and scalable methods★
Département d’astronomie, Université de Genève,
51 chemin des Maillettes,
1290
Versoix,
Geneva,
Switzerland
e-mail: jean-baptiste.delisle@unige.ch
Received:
11
October
2019
Accepted:
10
April
2020
Correlated noise affects most astronomical datasets and to neglect accounting for it can lead to spurious signal detections, especially in low signal-to-noise conditions, which is often the context in which new discoveries are pursued. For instance, in the realm of exoplanet detection with radial velocity time series, stellar variability can induce false detections. However, a white noise approximation is often used because accounting for correlated noise when analyzing data implies a more complex analysis. Moreover, the computational cost can be prohibitive as it typically scales as the cube of the dataset size. For some restricted classes of correlated noise models, there are specific algorithms that can be used to help bring down the computational cost. This improvement in speed is particularly useful in the context of Gaussian process regression, however, it comes at the expense of the generality of the noise model. In this article, we present the S + LEAF noise model, which allows us to account for a large class of correlated noises with a linear scaling of the computational cost with respect to the size of the dataset. The S + LEAF model includes, in particular, mixtures of quasiperiodic kernels and calibration noise. This efficient modeling is made possible by a sparse representation of the covariance matrix of the noise and the use of dedicated algorithms for matrix inversion, solving, determinant computation, etc. We applied the S + LEAF model to reanalyze the HARPS radial velocity time series of the recently published planetary system HD 136352. We illustrate the flexibility of the S + LEAF model in handling various sources of noise. We demonstrate the importance of taking correlated noise into account, and especially calibration noise, to correctly assess the significance of detected signals.
Key words: methods: data analysis / methods: statistical / methods: analytical / planets and satellites: general
We provide an open-source reference implementation of the S + LEAF model, the spleaf package (C library with python wrappers), available at https://gitlab.unige.ch/jean-baptiste.delisle/spleaf
© ESO 2020
1 Introduction
Astronomical datasets, like most datasets, are contaminated by various sources of noise, such as photon noise, the intrinsic variability of the object of interest, contamination by the Earth’s atmosphere, instrumental noise, etc. While the photon noise is purely white (i.e., uncorrelated), most of the other sources of noise have temporal or spatial correlations. When neglected, these correlations can lead to spurious signal detections.
In the context of exoplanet detection with radial velocity time series, stellar variability could induce signals that mimic planetary signatures (e.g., Queloz et al. 2001). The mitigation of stellar variability has become a major subject in planet search studies and is now routinely achieved by modeling it as correlated Gaussian noise. Adopting such models significantly improves the robustness of planet detection (e.g., Haywood et al. 2014; Rajpaul et al. 2015; Faria et al. 2016). Correlated noise also affects the determination of a planet’s parameters and can induce, in particular, spurious eccentricities when it is not properly accounted for (e.g., Hara et al. 2019).
In many cases, the physical processes inducing correlated noise cannot be modeled precisely but qualitative properties, typical timescales, and amplitudes can be estimated. Thus, a common approach is to use simple parametric noise models. For a time series of size n with observations taken at times ti (i < n), the covariance matrix of the noise is typically modeled as:
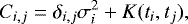 (1)
(1)
where σi are individual errorbars (e.g., photon noise) and K is the kernel of the correlated noise. The noise is often assumed to be stationary, such that K(ti, tj) only depends on |ti − tj|,
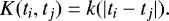 (2)
(2)
A simple, widespread model assumes the correlation to decrease exponentially with time, with a timescale of τ,
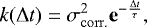 (3)
(3)
but it is sometimes chosen to decrease as a squared exponential (Schwarzenberg-Czerny 1991),
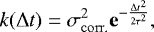 (4)
(4)
or other similar functions. Slightly more complex models have also been proposed, for instance, quasiperiodic kernels, such as that of Haywood et al. (2014)
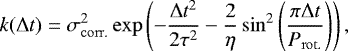 (5)
(5)
which allow for a more flexible modeling of the underlying physical processes.
In the case of a poorly understood noise source, the choice of a kernel is somewhat arbitrary but nonetheless, it should be governed by the qualitative properties that the noise is expected to present (typical timescales, periodicities, etc.). For instance, quasiperiodic kernels are well-suited to model the radial velocity signal induced by stellar spots coming in and out of view due to the rotation of the star (see Haywood et al. 2014). Even if the connection to the exact physics of the process is loose, the qualitative properties of quasiperiodic kernels are sufficient to bring a significant improvement in detection reliability.
While correlated noise models improve detection robustness, they might be prohibitive in terms of computational cost and memory footprint. Indeed, for a dataset of size n, the covariance matrix of the noise is of size n × n. In the general case, the memory footprint of storing C is thus 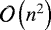 . Then some operations must be performed with this matrix to compute useful quantities (such as the χ2 or the likelihood of a model). The computational cost of these operations (e.g., inversion, dot product, determinant) typically scales as
. Then some operations must be performed with this matrix to compute useful quantities (such as the χ2 or the likelihood of a model). The computational cost of these operations (e.g., inversion, dot product, determinant) typically scales as 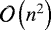 to
to 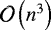 in the general case. These scalings make a correct modeling of the noise intractable for large datasets. To address this issue, Ambikasaran (2015) and Foreman-Mackey et al. (2017) proposed a flexible parametric noise model, which allow a linear scaling of the memory footprint and computational cost of the correlated noise. This so-called celerite model is capable of handling a mixture of quasiperiodic covariance kernels of the form:
in the general case. These scalings make a correct modeling of the noise intractable for large datasets. To address this issue, Ambikasaran (2015) and Foreman-Mackey et al. (2017) proposed a flexible parametric noise model, which allow a linear scaling of the memory footprint and computational cost of the correlated noise. This so-called celerite model is capable of handling a mixture of quasiperiodic covariance kernels of the form:
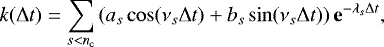 (6)
(6)
where nc is an arbitrarily high number of components in the model. This model has the property to be semiseparable, which allows a scaling of the computational cost as 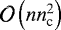 (Ambikasaran 2015). It is similar to the quasiperiodic kernel of Haywood et al. (2014) which is detailed in Eq. (5). The celerite model is well-suited to represent stellar signals modulated by the rotation period of the star (e.g., Foreman-Mackey et al. 2017). It has been used, in particular, for the analysis of radial velocity and photometric time series.
(Ambikasaran 2015). It is similar to the quasiperiodic kernel of Haywood et al. (2014) which is detailed in Eq. (5). The celerite model is well-suited to represent stellar signals modulated by the rotation period of the star (e.g., Foreman-Mackey et al. 2017). It has been used, in particular, for the analysis of radial velocity and photometric time series.
The star is not the only source of noise in the data. Instruments also introduce a correlated signature. For instance, for precise radial velocity time series (and in other fields), the instrument must be calibrated periodically, typically once per night. Several scientific measurements might use the same calibration and, therefore, share the same calibration noise. The covariance matrix of the calibration noise is then block-diagonal with the blocks corresponding to each calibration (each night). This calibration noise is not stationary and, thus, it is not well represented by the celerite model (see Eq. (6)). More generally, when considering various sources of noise together, the complete covariance matrix might present quasiperiodic components and sparse (block diagonal, banded, etc.) components. While efficient dedicated algorithms exist for both quasiperiodic (semiseparable) and sparse covariance matrices, they cannot be applied in a straightforward way for a mixture of both.
In this article, we extend the method described by Foreman-Mackey et al. (2017) to correlated noise with a semiseparable component plus a sparse component. We introduce the notion of LEAF matrices, a general class of sparse, “close to diagonal” symmetric matrices encompassing banded, block-diagonal, staircase matrices, etc. Our complete model, which we call the S + LEAF model, is the sum of a semiseparable component and a LEAF component.
In Sect. 2, we present the S + LEAF correlated noise model and dedicated algorithms. In Sect. 3, we illustrate our methods using the HARPS radial velocities of HD 136352. We discuss our results in Sect. 4. We provide an open-source reference implementation of S + LEAF matrices and related algorithms as a C library with python wrappers1.
2 The S + LEAF noise model
The likelihood (i.e., the probability of the data assuming a given model is correct) is a common tool for assessing the agreement of a given model to a dataset. In a Bayesian approach, the quantity of interest is the posterior probability (probability of a model given the data), but the computation of the likelihood is still required as an intermediate step. In this section, we describe the S + LEAF noise model and dedicated algorithms which allow, in particular, for the efficient computation of the likelihood and its derivatives.
In Sect. 2.1, we introduce notations and describe the computation of the likelihood in the general case. We define S + LEAF matrices in Sect. 2.2, and we present dedicated algorithms for S + LEAF matrices in Sect. 2.3.
2.1 Likelihood computation, general case
Let us assume that a given dataset yi (0 ≤ i < n) can be modeled with a deterministic component (the model) m with parameters θ, and a correlated Gaussian noise component ɛ with parameters α:
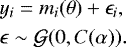 (7)
(7)
The log-likelihood of a given set of parameters (θ, α) is read as:
![\begin{align*}\ln\mathcal{L}(\theta, \alpha) & = \ln p(y|\theta, \alpha)\nonumber \\[2pt] & = -\frac{1}{2} \Big(y-m(\theta)\Big)^{\textrm{T}} C^{-1}(\alpha) \Big(y-m(\theta)\Big)\nonumber \\[2pt] & \quad -\frac{1}{2} \ln\det \Big(2\pi C(\alpha)\Big), \end{align*}](/articles/aa/full_html/2020/06/aa36906-19/aa36906-19-eq12.png) (8)
(8)
where C(α) is the n × n covariance matrix of the correlated noise ɛ.
The computational cost of evaluating the log-likelihood obviously depends on the cost of evaluating the model m(θ). However, once the model is obtained, we still have to compute the χ2 = rTC−1r (where r represents the residuals, r = y − m) and the determinant of C.
An efficient and robust way to compute the log-likelihood in the general case is to compute the Cholesky decomposition of C as an intermediate step. By definition, the covariance matrix C is symmetric, positive, and definite. It could, in principle, be singular (only semi-definite) but this would mean that some almost-certain affine relation exists in the noise component. This almost-certain relation could thus be included in the deterministic part of the model. Assuming C to be invertible (non-singular), its Cholesky decomposition can be read as:
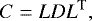 (9)
(9)
where D is diagonal and L is lower triangular with ones on the diagonal. The classical Cholesky decomposition is actually C = ΛΛT, where 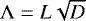 is also lower triangular. However, we use the alternative form of Eq. (9) throughout the article since this notation is more convenient in our case. The computational cost of the Cholesky decomposition is
is also lower triangular. However, we use the alternative form of Eq. (9) throughout the article since this notation is more convenient in our case. The computational cost of the Cholesky decomposition is 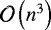 in the general case. Once the Cholesky decomposition is obtained, the determinant of C is easily computed (in
in the general case. Once the Cholesky decomposition is obtained, the determinant of C is easily computed (in 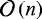 ) since ln detC = lndetD = ∑i lnDi. The computation of the χ2 is performed in
) since ln detC = lndetD = ∑i lnDi. The computation of the χ2 is performed in 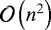 in the general case by first solving u = L−1r and then computing uTDu.
in the general case by first solving u = L−1r and then computing uTDu.
2.2 Symmetric S + LEAF covariance matrix
A common method for improving the computational cost and memory footprint of correlated noise models is to obtain a sparse representation of the covariance matrix and to then use dedicated algorithms for solving, computing the determinant, and other functions that make use of this sparsity. For instance, dedicated representations and algorithms for banded matrices, block-diagonal matrices, etc., exist, allowing for the linear scaling in n of the computational cost and footprint of the model (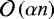 , where α depends on the bandwidth, block size, etc.). In Delisle et al. (2018), the covariance matrix was truncated and approximated by a banded matrix. This representation improved the computational speed of the Markov chain Monte Carlo (MCMC) algorithm used to compute the posterior densities of the orbital elements and noise parameters.
, where α depends on the bandwidth, block size, etc.). In Delisle et al. (2018), the covariance matrix was truncated and approximated by a banded matrix. This representation improved the computational speed of the Markov chain Monte Carlo (MCMC) algorithm used to compute the posterior densities of the orbital elements and noise parameters.
2.2.1 LEAF matrix
Here we introduce a general class of sparse, “close to diagonal” matrices, called LEAF matrices, that encompasses banded, block-diagonal, staircase matrices, etc. A symmetric LEAF matrix F must verify:
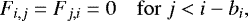 (10)
(10)
where bi is the number of non-zero entries left to the diagonal at line i. A sketch of a symmetric LEAF matrix is shown in Fig. 1.
2.2.2 Semiseparable matrix
For efficient computations (typically linear in n), the covariance matrix does not need to be sparse itself, but it should be expressed as a function of sparse matrices (sum, product, inverse, etc.). For instance, Rybicki & Press (1995) showed that exponential matrices, defined as:
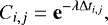 (11)
(11)
with Δti,j = |ti − tj|, possess a tridiagonal inverse T which can be computed directly, without requiring to compute C first (see Rybicki & Press 1995). While the covariance matrix C is not sparse, using the property C = T−1 allows for a very efficient (i.e., in 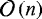 ) representation and computation. These exponential matrices (as defined in Eq. (11)) are also a particular example of semiseparable matrices which makes it possible to obtain another sparse representation. Indeed, assuming t to be ordered increasingly, and defining u = e−λt and v = eλt (vectors of size n), C can be decomposed as:
) representation and computation. These exponential matrices (as defined in Eq. (11)) are also a particular example of semiseparable matrices which makes it possible to obtain another sparse representation. Indeed, assuming t to be ordered increasingly, and defining u = e−λt and v = eλt (vectors of size n), C can be decomposed as:
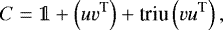 (12)
(12)
where tril (respectively triu) stands for the strictly lower (respectively upper) triangular part. The two sparse representations of the exponential matrix of Eq. (11) (i.e., tridiagonal inverse and semiseparable form) are actually linked one to the other, since the inverse of invertible tridiagonal matrices are rank one semiseparable matrices and vice versa (e.g., Vandebril et al. 2005, and references therein).
More generally, a symmetric semiseparable matrix is defined as:
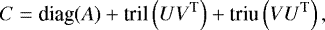 (13)
(13)
where diag(A) is the diagonal matrix built from the vector A (size n), U, and V are (n × r) matrices, and r is the rank of the semiseparable matrix C. Semiseparable matrices can represent a large class of correlated noise models. For instance, the celerite model (see Eq. (6)) proposed by Foreman-Mackey et al. (2017) can be represented as a semiseparable matrix of rank r = 2nc, with:
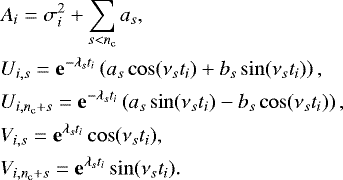 (14)
(14)
The computational cost and memory footprint of a semiseparable noise model are linear in n (footprint in 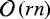 and cost in
and cost in 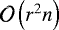 , see Ambikasaran 2015; Foreman-Mackey et al. 2017).
, see Ambikasaran 2015; Foreman-Mackey et al. 2017).
 |
Fig. 1 Sketch of a symmetric LEAF matrix. |
2.2.3 S + LEAF matrix
We define a S + LEAF matrix simply as the sum of a semiseparable and a LEAF matrix. A symmetric S + LEAF matrix takes, thus, the form of:
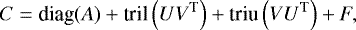 (15)
(15)
where A is a vector of size n representing the diagonalpart of C; U and V are n × r matrices representing the symmetric semiseparable part of C; and F is the symmetric LEAF part of C, as defined in Eq. (10). Since the diagonal part of C is represented by the vector A, we assume the diagonal of F to be filled with zeros. As in Eq. (10), we denote by bi the number of non-zero entries left to the diagonal, at line i of F (see also Fig. 1). The sparse matrix F can thus be stored in a compact way (i.e., storing only non-zero entries, and using its symmetry) with 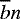 values. The memory footprint of the S + LEAF model scales as
values. The memory footprint of the S + LEAF model scales as 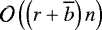 and the computational cost as
and the computational cost as 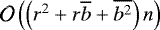 , where r is the number of components in the semiseparable part and for any vector x,
, where r is the number of components in the semiseparable part and for any vector x, 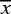 stands for the mean of x.
stands for the mean of x.
2.3 Likelihood computation with S + LEAF matrices
2.3.1 Cholesky decomposition
We then look for a sparse representation and an efficient computation of the matrices D and L involved in the Cholesky decomposition (see Eq. (9)) of C as defined by Eq. (15). In the case F = 0, Foreman-Mackey et al. (2017) showed that L can be written as:
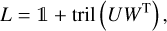 (16)
(16)
where W is a new n × r matrix which need to be determined. In the case F≠0, this decomposition does not hold but we can prove that there exist a n × r matrix W and a strictly lower triangular LEAF matrix G with the same shape as F (i.e., same values of bi), such that:
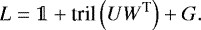 (17)
(17)
Let us first simply assume that G is strictly lower triangular (not necessarily LEAF). In this case, the decomposition is degenerated but always exists. Replacing L by the expression of Eq. (17) in the Cholesky decomposition of C (Eq. (9)) and equating it to Eq. (15), we obtain (for j < i):
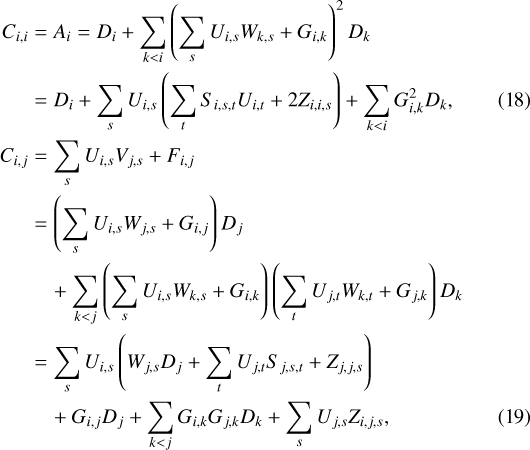
where S is defined following Foreman-Mackey et al. (2017),
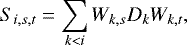 (20)
(20)
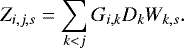
We then break the degeneracy in the expression of L by identifying the terms in front of Ui,s in Eq. (19). Thus we obtain:
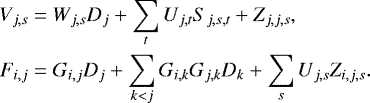 (22)
(22)
We deduce the following expressions for D, W, and G (for j < i):
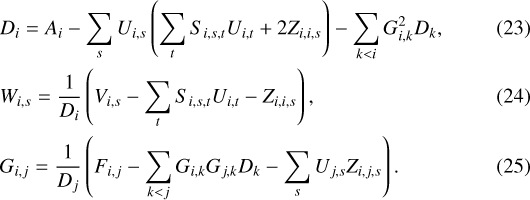
From Eqs. (21) and (25), we can check by induction that Gi,j = Zi,j,s = 0 for j < i − bi. Therefore, G and Z have the same LEAF shape as F, which proves that the decomposition of Eq. (17) always exists.
Using this property, we are able to compute compact recursion formulas for the expression of S, Z, G, D, and W. We find that for increasing values of i and increasing values of j at i fixed (with i − bi ≤ j < i):
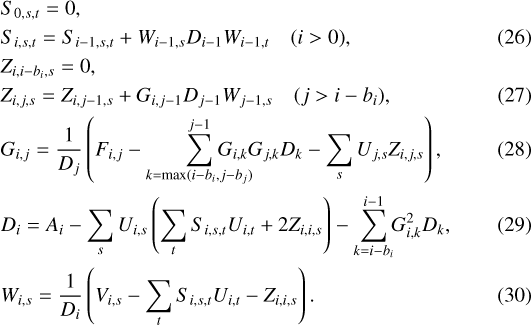
While S is a n × r× r tensor, it is not necessary to keep all its values in memory, and S can be stored as a r × r matrix which is updated in place for increasing values of i. The same reasoning holds for Z, which can be stored as a vector of size r, and updated for increasing values of i and j. However, if the backpropagation of the gradient is required, all the values of S and Z should be stored for reasons of stability and performance (see Sect. 2.3.4). In this case, the memory footprint of the S + LEAF model increases but remains linear in n (i.e., 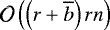 instead of
instead of 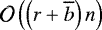 ).
).
2.3.2 Computing the determinant and solving
As explained in Sect. 2.1, once the Cholesky decomposition of the covariance matrix C is known, we need to compute its determinant and solve for x = L−1y to compute the likelihood of a set of parameters. The determinant is trivially obtained in 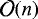 operations,
operations,
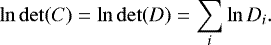 (31)
(31)
We can then describe how to solve for x = L−1y (with L defined as in Eq. (17)). Since y = Lx, we have:
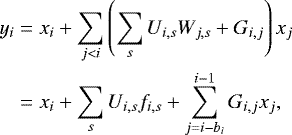 (32)
(32)
with f defined as in Foreman-Mackey et al. (2017),
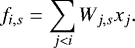 (33)
(33)
We thus obtain the following recursion formulas for increasing values of i:
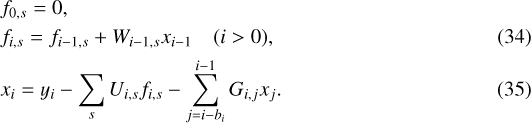
As for the Cholesky factorization, the values of f can be stored in a vector of size r and updated in place for increasing values of i, except in the case where the backpropagation of the gradient is required (see Sect. 2.3.4). The computational cost of this solving is in 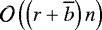 .
.
While it is not needed in the calculation of the likelihood, the computation of the dot product y = Lx is very similar to the solving problem (x = L−1y). For increasing values of i, we compute:
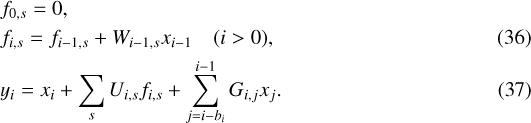
Similar recursion formulas for the dot product y = LTx and the solving of x = L-Ty are easily obtained.
2.3.3 Overflows and preconditioning
As noted byAmbikasaran (2015); Foreman-Mackey et al. (2017), a naive computer implementation of exponential semiseparable matrices can lead to numerical underflows and overflows. Indeed, the separation of the exponential e−λs|ti−tj| in Ui,s= e−λsti and Vj,s= eλstj exhibits very interesting theoretical properties (semiseparable matrix) but in practical applications, λs ti and λs tj can reach values that are much larger than λs|ti − tj|, which causes underflows for U and overflows for V.
To circumvent this numerical issue, we follow Foreman-Mackey et al. (2017) and introduce the (n − 1) × r preconditioning matrix ϕ, and the preconditioned matrices Ũ and Ṽ, such that
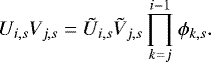 (38)
(38)
For instance, in the case of the celerite model – Eqs. (6) and (14) – Foreman-Mackey et al. (2017) proposed the following preconditioning:
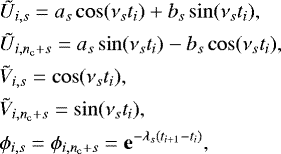 (39)
(39)
which avoids the computation of exponentials with large exponents. All the algorithms presented above (Cholesky decomposition, dot product and solving) can be adapted to take into account this preconditioning. We refer the reader to Appendix A for more details.
2.3.4 Efficient computation of the likelihood derivatives
Once the model is chosen, we typically need to determine a point estimate or the posterior distribution of the parameters. In order to use efficient optimization or exploration algorithms, it might be useful to compute the gradient of the log-likelihood (Eq. (8)) with respect to the model parameters (θ) and the noise parameters (α). Foreman-Mackey (2018) provided gradient backpropagation algorithms for the Cholesky decomposition, dot product, and solving problem in the case of semiseparable matrices (F = 0 in our notations). These algorithms allow to very efficiently compute (in 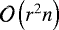 , see Foreman-Mackey 2018) the gradient of the log-likelihood using analytical formulas. The generalization of this method to S + LEAF matrices is straightforward and we provide more details in Appendix B.
, see Foreman-Mackey 2018) the gradient of the log-likelihood using analytical formulas. The generalization of this method to S + LEAF matrices is straightforward and we provide more details in Appendix B.
3 Application to the analysis of radial velocities
In this section, we illustrate the use of the S + LEAF noise model by reanalyzing the HARPS radial velocity time series of HD 136352 (see Udry et al. 2019). The star HD 136352 is a quiet G4V star known to host three super-Earth planets, at periods of 11.5824 d, 27.5821 d, and 107.6 d, and with minimum masses of 4.8, 10.8, and 8.6 M⊕ respectively (see Udry et al. 2019). These results were obtained by binning the data and only searching for planets with periods above 1 d. This is a common practice that allows to damp many instrumental and stellar short-term variations (Dumusque et al. 2011). However, it does not allow us to characterize these short-term variations and to fully correct for them. Moreover, binning the data could significantly damp the amplitude of short period planets. Here we reanalyze the raw radial velocities and do not restrict our study to periods above 1 d.
The radial velocities of HD 136352 taken with HARPS consist of 648 points, taken over almost 11 yr (2004–2015), and spread over 238 distinct nights. The number of points per night varies between one and ten, with an average of 2.7 points per night.
We describe the different noise models we use for our study in Sect. 3.1 and present our reanalysis of the HD 136352 system in Sect. 3.2.
3.1 Noise models
To illustratethe role of each component in our S + LEAF noise model, we analyze the data using five different noise models:
- 1.
diag.: a diagonal matrix, with the observational errorbars σi plus a jitter term (σjit.) added inquadrature (same value for all data points)
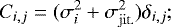 (40)
(40) - 2.
bin.: same as diag. but using nightly binned radial velocity data;
- 3.
celerite: same as diag. plus quasiperiodic terms at 1 d and 1 yr,
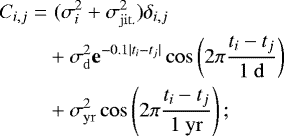 (41)
(41) - 4.
LEAF: same as diag. but the estimated calibration error
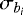 (which is part of the observational error σi) is shared by night blocks (identified by bi), and an additional calibration error term (σcal.) is added in quadrature to these blocks (same value for all blocks),
(which is part of the observational error σi) is shared by night blocks (identified by bi), and an additional calibration error term (σcal.) is added in quadrature to these blocks (same value for all blocks),
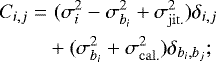 (42)
(42) - 5.
S + LEAF: same as LEAF plus the two quasiperiodic terms at 1 d and 1 yr as in the celerite model,
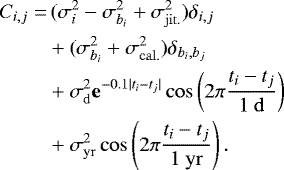 (43)
(43)
The quasiperiodic terms of the celerite and S + LEAF models are modeled according to Eq. (6) and could represent instrumental systematics (CCD stitching, wavelength solution instabilities, incorrect BERV correction, incorrect airmass corrections, etc.; see Dumusque et al. 2015). The HARPS radial velocities of HD 136352 are already corrected from the CCD stitching issue using the method of Dumusque et al. (2015), but remaining systematics could still be present. The amplitudes of the cosines (as in Eq. (6)) are noted σd and σyr. For the sake of simplicity, we fix the amplitudes of the sines to zero (bs = 0), such that the correlation is always maximum for Δt = 0 (see Eq. (6)). The exponential decay timescale is fixed to 10 d for the daily term (λd = 1∕10) and is infinite for the yearly term (λyr = 0).
The noise parameters that remain to be determined are, thus, 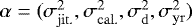 , or a subset of it depending on the chosen noise model. The components of the covariance matrices corresponding to each of these four parameters are illustrated in Fig. 2. For these illustrations, the matrices are expanded as full n × n matrices, but we use their sparse representation (as described in Sect. 2) in the following computations.
, or a subset of it depending on the chosen noise model. The components of the covariance matrices corresponding to each of these four parameters are illustrated in Fig. 2. For these illustrations, the matrices are expanded as full n × n matrices, but we use their sparse representation (as described in Sect. 2) in the following computations.
 |
Fig. 2 Shapes of the four components of the noise models used for the analysis of the HD 136352 system (Sect. 3). |
3.2 Reanalysis of the HD 136352 system
We analyze the HARPS radial velocity time series of HD 136352 using each of the five noise models of Sect. 3.1. The deterministic part of the model is read as:
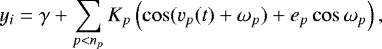 (44)
(44)
where γ is the velocity offset, np is the number of planets, and, for each planet p, Kp is its semi-amplitude, vp its true anomaly, ep its eccentricity, and ωp its argument of periastron. We start our study by considering a model without any planet and add them gradually, one after the other, by computing a periodogram of the residuals. At each step of this process, we adjust all the free parameters (deterministic and noise parameters). The deterministic parameters (vector θ) are the offset γ and the orbital parmeters P, K, M0 (mean anomaly at a reference epoch), e, and ω for each planet included in the model. The noise parameters α are a subset of 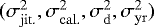 depending on the chosen noise model. We use the L-BFGS-B algorithm (Byrd et al. 1995) to maximize the likelihood (Eq. (8)) and we make use of the backpropagation algorithms described in Sect. 2.3.4 (see also Appendix B) to compute the derivatives of the log-likelihood with respect to the free parameters. We also use classical analytical expressions for the derivatives of the Keplerian model (Eq. (44)) with respect to the orbital parameters of the planets. Then we compute a periodogram of the residuals of this maximum likelihood solution. The offset γ is readjusted for each frequency explored in the periodogram, but the previous planets and noise parameters are fixed (at the values obtained with the last fit).
depending on the chosen noise model. We use the L-BFGS-B algorithm (Byrd et al. 1995) to maximize the likelihood (Eq. (8)) and we make use of the backpropagation algorithms described in Sect. 2.3.4 (see also Appendix B) to compute the derivatives of the log-likelihood with respect to the free parameters. We also use classical analytical expressions for the derivatives of the Keplerian model (Eq. (44)) with respect to the orbital parameters of the planets. Then we compute a periodogram of the residuals of this maximum likelihood solution. The offset γ is readjusted for each frequency explored in the periodogram, but the previous planets and noise parameters are fixed (at the values obtained with the last fit).
We compute the periodograms and associated false alarm probability (FAP) using the analytical method of Delisle et al. (2020), based on the previous work by Baluev (2008). For a frequency ν, we define the normalized power as:
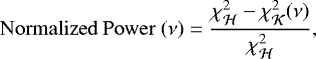 (45)
(45)
which corresponds to the definition of the Generalized Lomb-Scargle periodogram (GLS, see Ferraz-Mello 1981; Zechmeister & Kürster 2009), and to  in the notations of Baluev (2008) and Delisle et al. (2020). In this definition,
in the notations of Baluev (2008) and Delisle et al. (2020). In this definition, 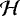 stands for the base model (only the offset γ is adjusted) and
stands for the base model (only the offset γ is adjusted) and 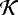 stands for the model with frequency ν (γ plus the amplitudes of the sine and cosine at frequency ν are adjusted). The χ2 of a model m(θ) is defined as:
stands for the model with frequency ν (γ plus the amplitudes of the sine and cosine at frequency ν are adjusted). The χ2 of a model m(θ) is defined as:
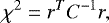 (46)
(46)
where r is the vector of the model residuals (r = y − m(θ)).
The resulting periodograms are shown in Fig. 3. For the sake of readability, we do not show the first two periodograms since the first two planets (at 11.5824 d and 27.5821 d) are unambiguously detected (highest peaks and FAP < 10−10) independently of the noise model. We additionally provide in Table 1 the values of the noise parameters used to compute each of the periodograms of Fig. 3.
We observe in Fig. 3 (left column) that the last planet (HD 136352 d) is well revovered (highest peak and low FAP) by all models except the celerite model. With the celerite model, the peak corresponding to the planet is not the highest peak and the FAP is high (0.4). We see in Table 1, that the amplitude of the daily quasiperiodic term of the celerite model is adjusted to a high value (3.23 m2 s−2). On the contrary, for the S + LEAF model, the amplitude of the noise is shared between the daily quasiperiodic term (1.69 m2 s−2) and the calibration noise (0.56 m2 s−2). It thus seems that the daily quasiperiodic term of the celerite model is overestimated due to the presence of the unmodeled calibration noise. This shows that the way the calibration noise is accounted for in the S + LEAF model is well suited and does correspond to the behavior of the HARPS instrument.
The periodograms of the residuals of HD 136352 after subtracting all known planets (Fig. 3, right) do not show any significant peak for the celerite (FAP = 0.168) and S + LEAF (FAP = 0.213) models. On the contrary, the diag., bin., and LEAF models show significant peaks (with a low FAP) around 0.5 sd and 1 sd, as well as around 1 yr (see Fig. 3, right). These signals could be of planetary origin but are more probably due to instrumental systematics (CCD stitching, wavelength solution instabilities, incorrect BERV correction, incorrect airmass corrections, etc.; see Dumusque et al. 2015). They could also originate from a combination of stellar correlated noise and aliasing. These potential systematics are taken into account in the celerite and S + LEAF models withthe daily and yearly quasiperiodic terms. While the amplitude of the daily quasiperiodic term is adjusted to significant values in the celerite and S + LEAF models, the amplitude of the yearly quasiperiodic term is completely negligible in both cases (see Table 1). We performed a similar analysis on the HARPS radial velocities of HD 136352 without the stitching correction and obtained higher values for the yearly term (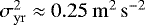 ). This highlights the improvements in the radial velocities obtained with this correction. In the S + LEAF model, the final levels (after substracting all known planets) of the daily quasiperiodic term and the calibration term are of the same order of magnitude (respectively, 0.7 and 0.78 m2 s−2, see Table 1). This provides a good illustration of the importance of taking into account both components in the noise model.
). This highlights the improvements in the radial velocities obtained with this correction. In the S + LEAF model, the final levels (after substracting all known planets) of the daily quasiperiodic term and the calibration term are of the same order of magnitude (respectively, 0.7 and 0.78 m2 s−2, see Table 1). This provides a good illustration of the importance of taking into account both components in the noise model.
The modeling of the systematics using daily and yearly quasiperiodic terms is a rough approximation, and a further investigation is necessary to confirm that these signals are instrumental systematics, to better characterize the systematics for several systems, to understand the mechanisms that might introduce them, and to correct for them, ideally directly in the HARPS data reduction software (DRS). However, this is beyond the scope of this study, and we simply highlight the ability of the S + LEAF model to roughly account for these systematics.
 |
Fig. 3 Periodograms of the radial velocity residuals of HD 136352 after subtracting the two first planets (at 11.5824 d and 27.5821 d, left), and after subtracting the three known planets (11.5824 d, 27.5821 d, and 107.6 d right), for the fivenoise models defined in Sect. 3.1. The noise parameters are set to the values provided in Table 1. The vertical blue line highlights the period of the third planet (107.6 d), and the dashed blue lines highlight its aliases at 1 yr. The dotted vertical red lines highlight 0.5 sd, 1 sd, and 1 yr. For the sake of readability, we do not show here the two first periodograms (raw time series and after subtracting the first planet), since the two first planets (11.5824 d and 27.5821 d) are unambiguously detected (highest peaks and FAP < 10−10) independently of the noise model. Assuming that the 107.6 d signal is due to a planet while the signals at 0.5 sd, 1 sd, and around 1 yr are due to correlated noise, we expect the correct noise model to show a low FAP in the left column and a high FAP in the right column. |
4 Conclusion
In this article, we present the S + LEAF correlated noise model. While in the general case, accounting for correlated noise in a dataset of size n has a cost of 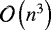 and a footprint of
and a footprint of  , the S + LEAF noise model scales linearly (i.e., in
, the S + LEAF noise model scales linearly (i.e., in 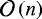 ). This linear scaling is made possible by the sparse properties of the S + LEAF covariance matrices (see Sect. 2). The S + LEAF model incorporates a mixture of quasiperiodic components (see Eq. (6)) as the celerite model (Foreman-Mackey et al. 2017) but it additionally takes into account a LEAF component. We call LEAF matrix a general class of “close to diagonal” matrices which encompasses banded, block-diagonal, and staircase matrices (see Eq. (10) and Fig. 1). For instance, the LEAF component of our model is well suited to account for calibration noise in radial velocity time series.
). This linear scaling is made possible by the sparse properties of the S + LEAF covariance matrices (see Sect. 2). The S + LEAF model incorporates a mixture of quasiperiodic components (see Eq. (6)) as the celerite model (Foreman-Mackey et al. 2017) but it additionally takes into account a LEAF component. We call LEAF matrix a general class of “close to diagonal” matrices which encompasses banded, block-diagonal, and staircase matrices (see Eq. (10) and Fig. 1). For instance, the LEAF component of our model is well suited to account for calibration noise in radial velocity time series.
We illustrate the use of the S + LEAF model in the context of radial velocity time series but the model is more general and could be adapted to other fields. We reanalyze the HARPS radial velocity time series of HD 136352 using different noise models (see Sect. 3.2) and observe that the periodograms and FAP levels strongly depend on the chosen noise model. We find that neglecting the short term correlated noise (short period quasiperiodic noise or calibration noise) can lead to spurious detections of signals (underestimation of the FAP), or to a poor detection power (over estimation of the FAP). We thus show that the calibration noise, which can be included in the S + LEAF model, has a substantial effect on detections.
Acknowledgements
We thank the anonymous referee for their useful comments. We thank X. Dumusque and C. Lovis for fruitful discussions, and V. Bourrier for finding the name LEAF while advocating against the use of S + LEAF. We acknowledge financial support from the Swiss National Science Foundation (SNSF). This work has, in part, been carried out within the framework of the National Centre for Competence in Research PlanetS supported by SNSF.
Appendix A Cholesky decomposition and solving in the preconditioned case
In this appendix, we show how to adapt the algorithms of the Cholesky decomposition (Sect. 2.3.1) and solving (Sect. 2.3.2) to the preconditioned case. As explained in Sect. 2.3.3 (and following Foreman-Mackey et al. 2017), we introduce the (n − 1) × r preconditioning matrix ϕ, and the preconditioned matrices Ũ and Ṽ, such that:
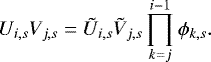 (A.1)
(A.1)
To stay consistent with this preconditioning, we additionally define 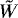 ,
, 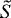 , and
, and 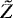 such that:
such that:
![\begin{align*} & U_{i,s} W_{j,s} = \tilde{U}_{i,s} \tilde{W}_{j,s} \prod_{k=j}^{i-1} \phi_{k,s},\nonumber \\[2pt] & U_{i,s} S_{i,s,t} U_{i,t} = \tilde{U}_{i,s} \tilde{S}_{i,s,t} \tilde{U}_{i,t},\nonumber \\[2pt] & U_{j,s} Z_{i,j,s} = \tilde{U}_{j,s} \tilde{Z}_{i,j,s}. \end{align*}](/articles/aa/full_html/2020/06/aa36906-19/aa36906-19-eq73.png) (A.2)
(A.2)
The recursion formulas for the Cholesky decomposition in the preconditioned case (see Eqs. (26)–(30)) are:
![\begin{align}& \tilde{S}_{0,s,t} = 0,\nonumber \\[2pt] & \tilde{S}_{i,s,t} = \phi_{i-1,s}\phi_{i-1,t}\left(\tilde{S}_{i-1,s,t} + \tilde{W}_{i-1,s} D_{i-1} \tilde{W}_{i-1,t}\right)\quad (i>0), \\[3pt]& \tilde{Z}_{i,i-b_i,s} = 0,\nonumber \\[3pt] & \tilde{Z}_{i,j,s} = \phi_{j-1,s}\left(\tilde{Z}_{i,j-1,s} + G_{i,j-1} D_{j-1} \tilde{W}_{j-1,s}\right)\quad (j>i-b_i), \\[3pt]& G_{i,j} = \frac{1}{D_j}\left(F_{i,j} - \sum_{k=\max(i-b_i, j-b_j)}^{j-1}\hspace{-6.5mm} G_{i,k} G_{j,k} D_k - \sum_{s}\tilde{U}_{j,s} \tilde{Z}_{i,j,s}\right), \\[3pt]& D_i = A_i - \sum_{s} \tilde{U}_{i,s} \left(\sum_{t} \tilde{S}_{i,s,t} \tilde{U}_{i,t} + 2 \tilde{Z}_{i,i,s}\right) - \sum_{k=i-b_i}^{i-1}\hspace{-1mm} G_{i,k}^2 D_k, \\[3pt]& \tilde{W}_{i,s} = \frac{1}{D_i}\left(\tilde{V}_{i,s} - \sum_{t} \tilde{S}_{i,s,t} \tilde{U}_{i,t} - \tilde{Z}_{i,i,s}\right). \end{align}](/articles/aa/full_html/2020/06/aa36906-19/aa36906-19-eq74.png)
The recursion formulas for the solving (x = L−1y) in the preconditioned case (see Eqs. (34) and (35)) are:
![\begin{align}&\tilde{f}_{0,s} = 0,\nonumber \\[2pt] &\tilde{f}_{i,s} = \phi_{i-1,s}\left(\tilde{f}_{i-1,s} + \tilde{W}_{i-1,s} x_{i-1}\right)\quad (i>0), \\[2pt]&x_i = y_i - \sum_s \tilde{U}_{i,s} \tilde{f}_{i,s} - \sum_{j=i-b_i}^{i-1} G_{i,j} x_j, \end{align}](/articles/aa/full_html/2020/06/aa36906-19/aa36906-19-eq75.png)
where  is defined such that
is defined such that
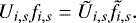 (A.10)
(A.10)
The case of the dot product is very similar to the above (see Eqs. (36) and (37)) as well as the dot product and solving with LT.
Appendix B Backpropagation of the gradient for the S + LEAF model
In this section, we explain how to obtain gradient backpropagation algorithms for the S + LEAF model. Foreman-Mackey (2018) provided backpropagation algorithms for the Cholesky decomposition and solving in the case of semiseparable matrices (F = 0 in our notations). We generalize this method to S + LEAF matrices. We do not detail here the full algorithms but we rather describe the method used to obtain them and refer the reader to the reference implementation2 for further details.
Let us first recall the steps required to evaluate the log-likelihood (see Sect. 2.1):
-
Compute the deterministic part of the model m(θ), and the residuals r = y − m(θ);
-
Compute the S + LEAF representation of the covariance matrix A(α), Ũ(α), Ṽ(α), ϕ(α), F(α);
-
Compute the Cholesky decomposition of the covariance matrix D,
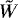 ,
G;
,
G; -
Compute the log-determinant ln det(C) =
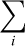 ln Di;
ln Di; -
Solve for u = L−1r;
-
Compute
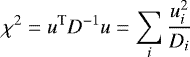 ;
; -
Compute
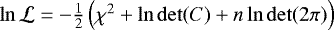 .
.
We then need to compute the derivatives 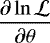 and
and 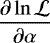 . There are typically two ways to achieve this, the forward and backward propagation of the gradient. In the forward approach, computing the gradient (or the Jacobian matrix) of yn (x) = fn○…○f2○f1(x) is performed by first computing ∇f1(x) and propagating it using the relation,
. There are typically two ways to achieve this, the forward and backward propagation of the gradient. In the forward approach, computing the gradient (or the Jacobian matrix) of yn (x) = fn○…○f2○f1(x) is performed by first computing ∇f1(x) and propagating it using the relation,
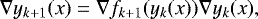 (B.1)
(B.1)
for k = 1…n − 1. In the backward approach, we first compute ∇fn(yn−1(x)), and propagate it using the relation:
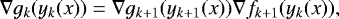 (B.2)
(B.2)
for k = n − 1…1, with gk = fn○…○fk+1. In both methods, we need to compute the gradient of each function appearing in the composition (each fi). The relative efficiency of both methods depends on the number of dimension of the parameter space and of the output space. Let us note p the number of parameters, and mk the number of dimension of yk (x) = fk○…○f2○f1(x). In the forward approach, each step consists in the computation of a mk × p matrix as the dot product of a mk × mk−1 and a mk−1 × p matrices. In the backward approach, each step consists of computing a mn × mk matrix as the dot product of amn × mk+1 and a mk+1 × mk matrices (with m0 = p). Therefore, in the case p < mn, the forward method should be more efficient, while in the case mn < p, the backward method should be faster.
In the case of the log-likelihood, we have mn = 1 (the log-likelihood is a scalar function), and the backward propagation should be preferred. The backpropagation method to compute the gradient of the log-likelihood can be decomposed in the following steps:
-
Compute
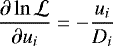 ;
; -
Compute
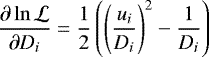 ;
; -
Compute the gradient of
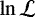 with respect to Ũ,
with respect to Ũ,
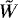 ,
ϕ,
G, and r
by using a backpropagation algorithm for the solving (u = L−1r), and the values of
,
ϕ,
G, and r
by using a backpropagation algorithm for the solving (u = L−1r), and the values of 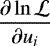 ;
; -
Use a backpropagation algorithm for the Cholesky decomposition to compute the gradient of
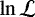 with respect to A,
Ũ,
Ṽ,
ϕ, and F;
with respect to A,
Ũ,
Ṽ,
ϕ, and F; -
Backpropagate the gradient of
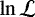 with respect to the residuals to compute
with respect to the residuals to compute 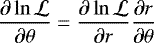 ;
; -
Backpropagate the gradient of
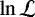 with respect to the S + LEAF decomposition of the covariance to compute
with respect to the S + LEAF decomposition of the covariance to compute 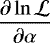 .
.
The kth line of code appearing in the implementation of an algorithm (Cholesky decomposition, dot product y = Lx, solving, etc.) can be seen as a function fk, while the full code is the composition yn(x) = fn○…○f2○f1(x). In the case of the Cholesky decomposition, the vector x represents all the entries of A, Ũ, Ṽ, ϕ, and F, while the output yn(x) represents D, Ũ, 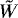 , ϕ, and G. The backpropagation of the gradient for the Cholesky decomposition consists in computing the derivatives
, ϕ, and G. The backpropagation of the gradient for the Cholesky decomposition consists in computing the derivatives 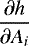 , etc., from the values of
, etc., from the values of 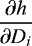 , etc., for some function h. Applying the backpropagation method described above (Eq. (B.2)) is equivalent to reading the code of the algorithm in the reverse order (starting from the last line, and reversing the order of each loop) and backpropagating the gradient for each line.
, etc., for some function h. Applying the backpropagation method described above (Eq. (B.2)) is equivalent to reading the code of the algorithm in the reverse order (starting from the last line, and reversing the order of each loop) and backpropagating the gradient for each line.
Special care should be taken to ensure the stability of the method. For instance, divisions by zero (or small numbers) should be avoided. The only divisions that appear in the computation of the log-likelihood are the divisions by Di (in the Cholesky decomposition and in the computation of the χ2) which are unavoidable but not problematic for a well conditioned matrix. In the backpropagation algorithms, we also avoid any division other than divisions by Di. Let us illustrate why this is preferable with the update formula for the tensor 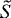 involved in the Cholesky decomposition algorithm (see Eq. (A.3)). As mentioned in Sect. 2.3.1, when computing the Cholesky decomposition of a S + LEAF matrix, the n × r × r tensor
involved in the Cholesky decomposition algorithm (see Eq. (A.3)). As mentioned in Sect. 2.3.1, when computing the Cholesky decomposition of a S + LEAF matrix, the n × r × r tensor 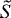 could be stored in memory as a much smaller r × r matrix and updated in place using Eq. (A.3). Then the final value of this r × r matrix
could be stored in memory as a much smaller r × r matrix and updated in place using Eq. (A.3). Then the final value of this r × r matrix 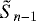 could be used as an initial value in the backpropagation algorithm and updated in place by computing
could be used as an initial value in the backpropagation algorithm and updated in place by computing 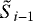 from
from 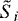 (see Eq. (A.3)),
(see Eq. (A.3)),
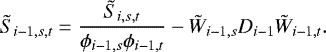 (B.3)
(B.3)
This is done in the celerite code (Foreman-Mackey 2018) as it has a smaller memory footprint. However, looking at the update formula (B.3), we can see that when ϕi−1,sϕi−1,t ≈ 0, this turns out to be unstable numerically. This issue could thus induce a wrong determination of the gradient, which could slow down or prevent the convergence of minimization algorithms. We thus store the full 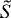 tensor in the Cholesky decomposition algorithm, which increases the memory footprint of the algorithm but improves the efficiency and stability of the backpropagation method.
tensor in the Cholesky decomposition algorithm, which increases the memory footprint of the algorithm but improves the efficiency and stability of the backpropagation method.
References
- Ambikasaran, S. 2015, Numer. Linear Algebra Appl., 22, 1102 [CrossRef] [Google Scholar]
- Baluev, R. V. 2008, MNRAS, 385, 1279 [NASA ADS] [CrossRef] [Google Scholar]
- Byrd, R., Lu, P., Nocedal, J., & Zhu, C. 1995, SIAM J. Sci. Comput., 16, 1190 [Google Scholar]
- Delisle, J.-B., Ségransan, D., Dumusque, X., et al. 2018, A&A, 614, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delisle, J. B., Hara, N., & Ségransan, D. 2020, A&A, 635, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dumusque, X., Udry, S., Lovis, C., Santos, N. C., & Monteiro, M. J. P. F. G. 2011, A&A, 525, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dumusque, X., Pepe, F., Lovis, C., & Latham, D. W. 2015, ApJ, 808, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Faria, J. P., Haywood, R. D., Brewer, B. J., et al. 2016, A&A, 588, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ferraz-Mello, S. 1981, AJ, 86, 619 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2018, Res. Notes Am. Astron. Soc., 2, 31 [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Agol, E., Ambikasaran, S., & Angus, R. 2017, AJ, 154, 220 [NASA ADS] [CrossRef] [Google Scholar]
- Hara, N. C., Boué, G., Laskar, J., Delisle, J. B., & Unger, N. 2019, MNRAS, 489, 738 [NASA ADS] [CrossRef] [Google Scholar]
- Haywood, R. D., Collier Cameron, A., Queloz, D., et al. 2014, MNRAS, 443, 2517 [NASA ADS] [CrossRef] [Google Scholar]
- Queloz, D., Henry, G. W., Sivan, J. P., et al. 2001, A&A, 379, 279 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rajpaul, V., Aigrain, S., Osborne, M. A., Reece, S., & Roberts, S. 2015, MNRAS, 452, 2269 [NASA ADS] [CrossRef] [Google Scholar]
- Rybicki, G. B., & Press, W. H. 1995, Phys. Rev. Lett., 74, 1060 [NASA ADS] [CrossRef] [Google Scholar]
- Schwarzenberg-Czerny, A. 1991, MNRAS, 253, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Udry, S., Dumusque, X., Lovis, C., et al. 2019, A&A, 622, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vandebril, R., Barel, M. V., Golub, G., & Mastronardi, N. 2005, CALCOLO, 42, 249 [CrossRef] [Google Scholar]
- Zechmeister, M., & Kürster, M. 2009, A&A, 496, 577 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Available at https://gitlab.unige.ch/jean-baptiste.delisle/spleaf
All Tables
All Figures
|
Fig. 1 Sketch of a symmetric LEAF matrix. |
| In the text | |
|
Fig. 2 Shapes of the four components of the noise models used for the analysis of the HD 136352 system (Sect. 3). |
| In the text | |
|
Fig. 3 Periodograms of the radial velocity residuals of HD 136352 after subtracting the two first planets (at 11.5824 d and 27.5821 d, left), and after subtracting the three known planets (11.5824 d, 27.5821 d, and 107.6 d right), for the fivenoise models defined in Sect. 3.1. The noise parameters are set to the values provided in Table 1. The vertical blue line highlights the period of the third planet (107.6 d), and the dashed blue lines highlight its aliases at 1 yr. The dotted vertical red lines highlight 0.5 sd, 1 sd, and 1 yr. For the sake of readability, we do not show here the two first periodograms (raw time series and after subtracting the first planet), since the two first planets (11.5824 d and 27.5821 d) are unambiguously detected (highest peaks and FAP < 10−10) independently of the noise model. Assuming that the 107.6 d signal is due to a planet while the signals at 0.5 sd, 1 sd, and around 1 yr are due to correlated noise, we expect the correct noise model to show a low FAP in the left column and a high FAP in the right column. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.