| Issue |
A&A
Volume 631, November 2019
|
|
|---|---|---|
| Article Number | A93 | |
| Number of page(s) | 7 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201936324 | |
| Published online | 28 October 2019 | |
A statistical method for the identification of stars enriched in neutron-capture elements from medium-resolution spectra
1
Departament de Física Quàntica i Astrofísica, Universitat de Barcelona, C. Martí i Franquès, 1, 08028 Barcelona, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institut de Ciències del Cosmos (ICCUB), Universitat de Barcelona, C. Martí i Franquès, 1, 08028 Barcelona, Spain
Received:
16
July
2019
Accepted:
24
September
2019
Abstract
We present an automated statistical method that uses medium-resolution spectroscopic observations of a set of stars to select those that show evidence of possessing significant amounts of neutron-capture elements. Our tool was tested against a sample of ∼70 000 F- and G-type stars distributed among 215 plates from the Galactic Understanding and Exploration (SEGUE) survey, including 13 that were directed at stellar Galaxy clusters. Focusing on five spectral lines of europium in the visible window, our procedure ranked the stars by their likelihood of having enhanced content of this atomic species and identifies the objects that exhibit signs of being rich in neutron-capture elements as those scoring in the upper 2.5%. We find that several of the cluster plates contain relatively large numbers of stars with significant absorption around at least three of the five selected lines. The most prominent is the globular cluster M 3, where we measured a fraction of stars that are potentially rich in heavy nuclides, representing at least 15%.
Key words: nuclear reactions / nucleosynthesis / abundances / line: identification / methods: statistical
© ESO 2019
1. Introduction
Metals in stars today are a snapshot of the metals in the interstellar medium (ISM) at the time and place where stars were born. While element synthesis is reasonably well understood from the primordial lightest elements up to the iron peak via fusion reactions that take place in the stellar interiors, explaining the origin of elements that are heavier than iron remains one of the major challenges in modern astrophysics. In order to accomplish this, it is essential to gather detailed and accurate information on the stellar abundances of the elements in question.
Since the binding energy per nucleon only increases until 62Ni (though it is generally believed that 56Fe is more common than nickel isotopes), heavier elements present in ancient halo stars, the ISM, dust grains, meteorites, and on Earth cannot be produced in a fusion process and must form by reactions of neutron (n) capture usually followed by a β− decay (most commonly) or β+ decay, which have the generic form:
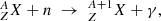 (1)
(1)
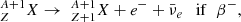 (2)
(2)
or
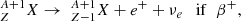 (3)
(3)
where A and Z are the mass number and the atomic number of the nuclide, respectively.
The two predominant n-capture mechanisms are the s-process and the r-process, which are from slow and rapid neutron capture, respectively (Burbidge et al. 1957; Meyer 1994; Sneden & Cowan 2003). In s-process reactions, the characteristic time of β-decay, τβ (Eqs. (2) and (3)), is short compared to the neutron capture time (Eq. (1)), τn, that is τβ ≪ τn, creating elements close to the floor of the valley of stability, which is formed by long-lived heavy nuclides (Busso et al. 1999; Sneden et al. 2008; Heil et al. 2009; Käppeler et al. 2011). Instead, in r-process reactions the time related to β-decay is large compared to the neutron capture time, τβ ≫ τn, allowing the capture of several neutrons before the nuclei have time to undergo radioactive decay (Reifarth 2010; Thielemann et al. 2011; Arnould et al. 2007). As a result, the r-process typically synthesizes the heaviest isotopes of every heavy element.
While τβ only depends on the nuclear species, τn hinges on the neutron flux involved. The s-process takes place within stars, particularly during He-burning. Therefore, it can occur in the He-shell flashes of asymptotic giant branch (AGB) stars or in the He-burning cores of massive stars (M > 12 M⊙) where new heavy elements are synthesized through the capture of free neutrons by preexisting heavy nuclei. This mostly arises in iron isotopes that are left, for instance, by a previous stellar generation (Lugaro et al. 2003; Karakas et al. 2012; Battistini & Bensby 2016; Goriely & Siess 2018; Limongi & Chieffi 2018). Thus, the observation of an overabundance of s-process elements in low-mass halo stars that cannot produce them is nowadays explained by the transfer from a more massive companion, currently a white dwarf, that has gone through some of these He-burning phases (see e.g., the review by Sneden et al. 2008 and references therein). Due to the relatively low neutron densities involved in this process (∼108 cm−3; Busso et al. 1999), typically several decades can pass between consecutive neutron captures.
On the other hand, although the astrophysical sources of the r-process are still not definitively identified, it is well known that this is a primary process that only occurs in environments with extremely large neutron densities (∼1020–1028 cm−3 depending on the source consulted, e.g., Kratz et al. 2007; Frebel & Beers 2018; Liccardo et al. 2018), meaning that it cannot occur in stellar interiors. The huge densities involved also imply, contrary to the s-process, that the r-process can itself create free nucleons as well as the heavy seeds (iron-peak nuclei) that are required to build heavier elements.
Traditionally, the most probable site for the r-process has been assumed to be the large regions swept by the ejecta (i.e., neutrino winds) of core-collapse supernovae (SNII; Burbidge et al. 1957; Woosley et al. 1994; Cowan & Thielemann 2004; Thielemann et al. 2018). However, theoretical models that rely on this mechanism have difficulties in explaining the observed, very low abundance of r-process nuclides in the interstellar medium, as well as the required high density of free neutrons in the ejected material.
Another possible, presumably less uniformly distributed, source of neutron-rich matter are binary neutron star (NS–NS) mergers (Freiburghaus et al. 1999; Komiya & Shigeyama 2016; Kasen et al. 2017; Naiman et al. 2018). The feasibility of this scenario was recently confirmed in 2017 when the gravitational waves coming from the LIGO/Virgo Event GW170817 were used to identify the location of a kilonova1 whose rapidly expanding ejecta revealed spectral features consistent with the presence of high-opacity lanthanides (Pian et al. 2017; Arcavi et al. 2017; Smartt et al. 2017). Assuming the solar r-process abundance pattern for the ejecta, current Galactic chemical evolution models suggest that this NS–NS merger event may have generated between 1–5 Earth masses of europium (Eu) and 3–13 Earth masses of gold (Argast et al. 2004; Côté et al. 2018). This is a much higher yield of heavy materials than in typical SNII, which compensates for their alleged greater rarity. More importantly, the range of the cosmic NS–NS merger rate estimated by LIGO/Virgo, although still poorly constrained, is consistent with the range required by these models to explain the nucleosynthesis of heavy elements in the Milky Way.
Very recently, collapsars – the supernova-triggering collapse of rapidly spinning, massive stars into black holes – have also been suggested to explain the presence of heavy elements in the stars that formed early in the history of the universe. This rare type of supernovae can occur shortly after the first stars begin to form and they are expected to be even more prolific producers of r-process elements than NS–NS mergers (Siegel et al. 2019). All of these findings are shifting the focus from SNII to both binary NS mergers and collapsars as the primary r-process sites in the universe.
The aim of this work is to provide a tool to locate regions of our Galaxy that show signs of being rich in n-capture elements, such as those arising from the r-process mentioned above. For this purpose, we use the complete spectral sample from the Sloan Extension for Galactic Understanding and Exploration (SEGUE) survey collected under the program names segue2 and segcluster during the first and second extensions of the Sloan Digital Sky Survey that was made available for its eighth Data Release (SDSS-III DR8; Yanny et al. 2009; Eisenstein et al. 2011). The segue2 program plates contain spectra for approximately 119 000 stars, and the program focuses on the in situ stellar halo of the Galaxy at distances between 10 and 60 kpc. Among the different target types included in this survey, there are blue horizontal branch stars, F and G main-sequence stars, and K- and M-giants. On the other hand, the segcluster program consists of 13 plates specifically targeted on known globular or open clusters. We aim to search for the presence of neutral or singly ionized Eu in the spectra of these stars since this element is one of the best indicators of enrichment by rapid n-capture reactions (Argast et al. 2004). In particular, Eu is an element synthesized practically on its totality through the r-process (97% at solar metallicity according to Burris et al. 2000) that has several strong absorption lines in the part of the electromagnetic spectrum falling within the wavelength coverage of SEGUE. Fig. 1 illustrates the major differences that can result in a small range of visible wavelengths between an n-capture-rich star and one that is not when they are observed with a very high-resolution spectrometer.
 |
Fig. 1. High-resolution spectra of two stars: HD 122563 (blue) and HE 1523−0901 (red). While the former star has low abundances of r-process elements, the latter is the richest object in these elements ever found in the Galaxy’s halo. It is important to note that the spectrum of HE 1523−0901 shows a large number of strong absorption lines from lanthanides such as lanthanum (La), cerium (Ce), samarium (Sm) and europium (Eu), which produces the most intense absorption line at 4129.70 Å. (Reproduced from Frebel & Beers 2018, with the permission of the American Institute of Physics). |
This article is organized as follows. In Sect. 2 we describe our data sample and the analysis performed. In Sect. 3 we briefly discuss the results obtained. Finally, in Sect. 4 we present the main conclusions of this work.
2. Methodology
2.1. The data
The spectra range of SEGUE is from 385 nm to 920 nm, with an average spectral resolution of R ≡ λ/Δλ ∼ 2000 (4 km s−1). Although it does not allow one to resolve the usually very thin lines corresponding to atomic electronic transitions, it is, however, good enough to make the application of the statistical procedure that we describe in this article feasible. The SEGUE sample consists primarily of two surveys, SEGUE-1 and SEGUE-2, which in turn encompass several programs that vary in their observational focus. Each program consists of a number of different plates or tiles, each covering an area of 7 deg2 and containing 640 fibers. The segue2 program mainly focuses on the distant northern Galactic halo region. It consists of 202 tiles that encompass a total sky area of 1317 deg2 and spectroscopically observe a total of 118 151 unique stars up to a magnitude of g = 19. The segue2 “blind” plates contain stars that are likely heterogeneous in terms of their chemical abundances because of the mixing that results from the high proper motions, which are characteristic of this structural component. In contrast, the segcluster program focuses on regions dominated by open and globular clusters, that is, on collections of stars that are expected to be more chemically homogeneous because they contain numerous objects that have been gravitationally bound since the day they were born.
In this work, we analyze the subset of high-quality, high signal-to-noise ratio (S/N) spectra (see next section) of ∼70 000 stars of F and G spectral types. In fact, the adopted dataset is heavily biased against G-type stars. Therefore, we were forced to limit the application of our statistical procedure to the warmest objects (subclasses G0–G2) of G-type stars. This constraint was far from an inconvenience and was actually beneficial for this analysis since we excluded the coolest G-type objects, which are also the most likely to be affected by absorption lines from diatomic molecules (CH, CN) in the spectral region studied. Depending on the intensity of these lines, they could potentially lead to false detections, something that might happen if our method is applied to the colder K- and M-type stars.
2.2. Spectral analysis
Our methodology essentially consists of first averaging the spectra for all of the stars with the same spectral type and then comparing each individual spectrum with the inferred mean to identify the most discordant ones (i.e., the most flux deficient) in several narrow spectral bands that encompass certain strong absorption lines of n-capture elements. The averaging process is based on the algorithm described in detail by Mas-Ribas et al. (2017; see references therein), which we modified in order to adapt it to our needs. We began by shifting each spectrum to the laboratory rest-frame. Because the binning in wavelength has a constant logarithmic dispersion, the correction is given by log λr = log λo − log(1+z), where λr is the rest-frame wavelength and λo is the observed one. After this correction, we rebinned the flux and its error by interpolating into pixels with a constant logarithmic spacing of 0.0001, so the resolution of the original spectra was preserved along the full visible range2. Next, we removed the pixels whose errors are set to infinity from the spectra as well as those that have the mask bit BRIGHTSKY activated3. Any spectrum containing more than 50% of problematic pixels was discarded from the sample. Furthermore, we also discarded from the analysis those spectra in which the most immediate neighborhood of the lines selected to probe the presence of n-rich species (see below) was not free of anomalies. This neighborhood is formed by the twenty pixels located to the left and right of the central pixel of these lines (i.e., the interval λi − 20 ≤ λi ≤ λi + 20, with λi the pixel containing the wavelength of any line of interest).
Then, we used the tool iSpec (Blanco-Cuaresma et al. 2014; Blanco-Cuaresma 2019) for each spectrum, j, that fit the criteria just mentioned to determine both its S/N, sj, and normalized flux, fj (for the continuum normalization we used a spline of second degree every 5 nm that ignores any region with strong lines). Finally, the normalized spectra having an S/N ≥ 10 were stacked together as the weighted average
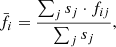 (4)
(4)
where 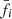 is the mean normalized flux at pixel i. The error assigned to the mean fluxes is simply the sample standard deviation of the composite spectrum at each pixel:
is the mean normalized flux at pixel i. The error assigned to the mean fluxes is simply the sample standard deviation of the composite spectrum at each pixel:
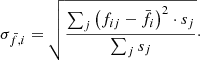 (5)
(5)
To minimize the chances of making erroneous identifications, we chose a total of five lines of two different species of the r-process element Eu that are among the strongest lines of this element in the visible window. There are three intense lines of Eu I, as well as two Eu II resonance lines that are also among the most intense of this species, all of them located near the UV-Blue end of this window (see Kramida et al. 2018 and references therein). In order to detect the lines, we have taken into account that SEGUE’s spectra have been obtained using a medium-resolution instrument with a spectral resolution of about two angstroms in the range of wavelengths of interest. This means that, in practice, the fluxes of the narrow, sub-angstrom-wide lines produced by heavy nuclides (see Fig. 1) end up distributed among several pixels around the peak4. This makes them both wider and weaker and increases the likelihood that they would blend with adjacent lines. The absorption lines that we wish to detect are expected, therefore, to show up in the SDSS data as moderately deep depressions of the continuum that spread over a few angstroms. The different absorption lines adopted and the spectral ranges assigned for their detection are both listed in Table 1.
Strongest lines from Eu in optical window and assigned spectral ranges for detection (see text).
With all of this in mind, we devised a strategy to find candidate stars rich in n-capture elements, which consists in computing the differences between the fluxes of each individual stellar spectrum and the average spectrum of the corresponding spectral class calculated within four-Å-wide spectral ranges around the adopted lines (see Table 1). The differences for each spectral range were then ranked in increasing order and those included in the upper 2.5% were considered to be indicators of the existence of an enhancement in the corresponding species. We also imposed that for a star to be considered a potential candidate rich in n-capture elements, it must have produced positive results in the overabundance of these elements in the majority fraction of the selected spectral regions, that is, in at least three of the five5 Eu lines. The final step consisted of identifying the SEGUE plates that contain the highest number of stars with these characteristics. The idea behind this procedure is that we expect metal enrichment, especially when it is driven by rapid n-capture in spatially localized events, to manifest itself clearly in specific regions of the Galaxy, such as the star clusters targeted by the segcluster program where most objects share a common origin. Likewise, we hope that finding evidence of localized enrichment in heavy nuclides will be more difficult in the segue2 plates, since they include Galactic halo field stars with disparate formation histories.
At this point, it also has to be borne in mind that some of the electronic transitions that we aim to detect produce absorption lines that are known to be ill-suited for equivalent-width analysis. This is because they can blend with nearby lines from lighter metal species and/or by molecular band regions that also lead to difficulties in placing the continuum (e.g., Koch & Edvardsson 2002; Roederer & Lawler 2012; Siqueira Mello et al. 2012; Battistini & Bensby 2016). Certainly, these factors can make the detection of such lines in individual stellar analyses very challenging (even from very high-resolution and S/N observations), which critically limits their usefulness as estimators of the abundance of n-capture elements. We want to emphasize, however, that the effects of crowding are taken into account in our methodology. This is so because it relies on the identification of the most statistically significant deviations in the fluxes from the spectral regions around lines of n-rich elements, which are self-consistently synthesized by averaging the spectra from thousands of similar Galactic halo stars that have been observed with the same instrument. This should also account for possible affectations related to hyperfine splitting due to the presence of different isotopes. In addition, the robustness of this procedure was boosted by introducing the requirement that, for a star to be considered an n-capture-rich candidate, it must present simultaneous indications of flux deficits in the mayority of the lines of interest. In any event, in an effort to be conservative, we subdivided our candidate stars into primary and secondary candidates, according to whether or not they show a significant flux deficit in the spectral ranges that are associated with at least one of the Eu absorption lines at 4129 Å and 4594 Å, which are two of the most frequently used indicators of the abundance of r-process elements in the visible spectral range because of their strength and lack of significant blending (see e.g., Fig. 1).
Figure 2, provides a graphical example of the sort of spectral features with which our method operates. In the top and middle panels of the plot, we include two F5 stars whose stellar spectra show large deficits with respect to the average flux of this spectral class within the spectral ranges that delineate the Eu II line at 4129 Å and the Eu I line at 4661 Å, which are represented by solid green areas. In both cases the flux differences within the corresponding spectral ranges fall into the upper 2.5% and, therefore, are classified as potential detections of these species. This situation clearly contrasts with the bottom panel, where we show the spectrum of another F5 star that, instead of showing a significant decrease in the intensity within the spectral window associated with the Eu I 4661 Å line, presents a slight increase with respect to the mean, which classifies it as a non-detection. Next, we present and comment on the results obtained after applying our methodology to identify stars rich in n-capture elements to the collections of spectra gathered in the segue2 and segcluster samples.
 |
Fig. 2. Comparison of certain observed lines in F5 stars (orange curves) with average flux inferred from whole spectral class (blue curves). The lighter bands surrounding the fluxes show their associated uncertainties, while the green colored areas identify the integrated flux differences that we attribute to lines from Eu. Panel a: F5 star (specobjID = 3719984370237415424) that shows a substantial flux deficit compared to the mean in the 4127–4131 Å wavelength range that encompasses an important line of Eu II (see Table 1). Panel b: another F5 star (specobjID = 2786716958031191040) also showing a significant flux deficiency in the 4659–4663 Å range, which is the interval of wavelengths where one expects to find a strong Eu I line. In both cases the stars have been identified as positive detections. In contrast, panel c shows a third F5 star (specobjID = 3002850987342928896) that does not show evidence for the existence of this latter line in absorption, which classifies it as a non-detection. |
3. Results
The application of the statistical procedure described in the previous section led us to detect a total of 67 r-process-rich candidates in the different tiles that make up the segue2 and segcluster programs. Forty-three of these objects (39 primary and 4 secondary) are distributed in the five plates that we include in Table 2 where we list the plate ID (in Col. 2), the galactic coordinates of its center in degrees (Cols. 3 and 4), and the name of the targeted cluster (Col. 5) for those belonging to the segcluster program. These plates correspond to regions of the sky that include at least three positive detections, which is the minimum number required, in the present work, to consider that this part of the Galaxy would merit being explored in the search of n-capture enriched stars. As expected, all but one of these plates are devoted to star clusters. Besides, the only field halo (segue2) plate in this list contains the lowest total number of stars with an enhanced content in heavy elements in at least three lines, N≥3 (Col. 6). Table 2 also reports the number of stars per plate whose spectrum produces evidence that is favorable to the existence of significant amounts of elements arising from n-capture nucleosynthesis in exactly l = 3, 4, and 5 of the narrow spectral ranges investigated and given by N3, N4, and N5 (Cols. 7–9)6, respectively. The last two columns of Table 2 provide information about the fraction of stars within each plate whose spectrum complies our quality requirements (see Sect. 2.2), which is defined by the ratio
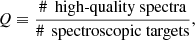 (6)
(6)
SEGUE plates with at least three candidate stars rich in n-capture elements.
and the frequency of candidate stars per plate
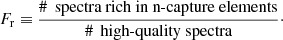 (7)
(7)
The comparison of the values reported for the last relation with its probability distribution function (PDF) inferred from the whole dataset allows one to observe their extreme nature: while the median of the PDF is 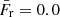 (and the mean is ⟨Fr⟩ = 0.004) all of the frequencies listed are well within its upper decile (Fr > 0.014). Therefore, these figures can be considered as a piece of evidence that lends support to the claim that the selected plates are directed at locations in the Galaxy where there is an overabundance of stars rich in r-process elements. We note that four of these five plates sample areas of the sky containing collections of stars with a contemporary origin and that, therefore, are expected to have a similar chemical composition. On the other hand, the fact that the plates with the highest numbers of candidate stars (IDs 2475 and 2476) show Q values very close to the average of the whole set, ⟨Q⟩≃0.2, excludes the possibility that the number of these stars found in a plate depends on the fraction of spectra analyzed. It should be added that even if we only consider the candidate stars contained in these five plates, the probability of obtaining 43 positive signals from a sample of 70 000 stars by chance is extremely low (in the order of 10−57, or 10−45 if we count the 39 primary detections)7. It is also important to note that eleven of the 43 candidate stars show indications of a heavy nuclide boost in four lines and two of them in all of the five lines (see Table 2). This reinforces the robustness of the detections. All of these very strong objective arguments confirm a posteriori the correct functioning of our method and, therefore, make us particularly confident in our identification, via SEGUE’s spectra, of regions of our Galaxy that are potentially rich in n-capture-enhanced stars. The SDSS spectroscopic identifiers (specobjID), together with the spectral subclasses and metallicities (the latter are taken from Lee et al. 2008) of all candidate stars enriched in Eu detected in the plates discussed above, can be found in Table A.1.
(and the mean is ⟨Fr⟩ = 0.004) all of the frequencies listed are well within its upper decile (Fr > 0.014). Therefore, these figures can be considered as a piece of evidence that lends support to the claim that the selected plates are directed at locations in the Galaxy where there is an overabundance of stars rich in r-process elements. We note that four of these five plates sample areas of the sky containing collections of stars with a contemporary origin and that, therefore, are expected to have a similar chemical composition. On the other hand, the fact that the plates with the highest numbers of candidate stars (IDs 2475 and 2476) show Q values very close to the average of the whole set, ⟨Q⟩≃0.2, excludes the possibility that the number of these stars found in a plate depends on the fraction of spectra analyzed. It should be added that even if we only consider the candidate stars contained in these five plates, the probability of obtaining 43 positive signals from a sample of 70 000 stars by chance is extremely low (in the order of 10−57, or 10−45 if we count the 39 primary detections)7. It is also important to note that eleven of the 43 candidate stars show indications of a heavy nuclide boost in four lines and two of them in all of the five lines (see Table 2). This reinforces the robustness of the detections. All of these very strong objective arguments confirm a posteriori the correct functioning of our method and, therefore, make us particularly confident in our identification, via SEGUE’s spectra, of regions of our Galaxy that are potentially rich in n-capture-enhanced stars. The SDSS spectroscopic identifiers (specobjID), together with the spectral subclasses and metallicities (the latter are taken from Lee et al. 2008) of all candidate stars enriched in Eu detected in the plates discussed above, can be found in Table A.1.
4. Conclusions
We have developed an automated statistical approach to identify stars containing enhanced contents of neutron-rich nuclei that use spectra whose resolution is not optimal to adequately detect from single observations the very thin absorption lines produced by this kind of elements. To illustrate how our methodology actually works, we focused on measuring the integrated flux within windows of a few angstrom wide around three lines of Eu I and two of Eu II that fall within the visible spectrum, subsequently identifying the strongest flux deficiencies found in these narrow spectral ranges with the presence of absorption features linked to these elements. For a star to be considered rich in heavy elements, we require it to test positive in at least three of the five lines investigated.
The performance of the procedure has been tested against a sample of around 70 000 high-quality, medium-resolution optical spectra from F- and G-type stars observed within 215 plates belonging to two programs of the SDSS/SEGUE survey. We find that there is only one plate among the 202 of the segue2 program that reaches the minimum required content of three candidate stars enriched in n-capture elements. In contrast, it is found that up to four of the 13 plates of the segcluster program contain between six and eighteen stars where n-rich nuclei are plentiful. These findings are consistent with the expectation that most targets included in the tiles of the latter program, which are specifically directed at both globular and open star clusters, should be stars created in a common formative environment; while the presumably disparate birth places of the objects observed in the segue2’s tiles should contribute to blur any signature that might exist from past heavy-element nucleosynthesis events in the targeted regions of our Galaxy. For those readers interested in deciphering the site and origin of the n-capture processes, we provide a table listing the spectral SDSS identifiers and other basic information about the 43 candidate stars rich in r-process elements (distinguishing primary and secondary) that have been detected in these five plates.
Highlights of the numerical results obtained include the ten or more objects that are potentially rich in heavy elements found in each one of the NGC 5053 and M 3 globular clusters, which are the two stellar systems observed in the segcluster program with the highest fractions of r-process enriched stars: 7% and 15%, respectively. These results, however, exclusively report on the presence of stars with extreme photospheric abundances of heavy elements within their spectral class. Nevertheless, they do not indicate what could be the particular values of such abundances, neither in absolute terms nor normalized to the stars’ metallicities, which are normally inferred from the Fe abundance. Since the latter, despite being subsolar in all cases, span quite a large range (from [Fe/H] ≃ −0.45 to −2.5; see Table A.1), it seems reasonable to expect that both the selected stars and their host systems can also end up showing substantial variations in the abundance ratios of heavy nuclides. Thus, on one end, only one of the six stars rich in r-process elements located in the region of the open star cluster M 67 is truly metal-poor ([Fe/H] ≲ −1). At the other end, there are the plates M 2, NGC 5053, and M 3, which show fractions of objects with abundances of Fe below 10% of 4/6, 8/10, and 9/10, respectively (for the last fraction we are considering only the stars with known metallic content), which would confirm that globular clusters are one of the best astrophysical sites to find stars with enhanced levels of n-capture elements.
In summary, we devised a fast and reliable automated procedure that enables the detection of the fine absorption lines that are produced by heavy elements in stellar spectra by using data from large surveys whose spectral resolution is too coarse to approach this problem in a traditional way. Thus, our method can help, for instance, future high-resolution stellar spectral abundance surveys that search for clues as to the astrophysical origin of the r-process nuclides by facilitating the identification of the sites where it should be possible to find a good number of stars that exhibit enhancement in such elements. This would avoid the time-consuming searches through thousands of candidates that are currently being carried out to find these precious objects in the Galactic halo. Ultimately, this is about contributing to the collection of a more complete inventory of n-capture-enhanced stars that increases our understanding of the synthesis of heavy elements and that sheds more light on the formation history of galaxies from the chemical evolution of their stellar populations.
A rapidly fading optical-infrared transient powered by the radioactive decay of n-rich species synthesized in NS–NS mergers.
See SDSS bitmasks at http://www.sdss.org/dr12/algorithms/bitmasks/#SPPIXMASK.
Pixel size at ∼4000 Å is a bit less that one Å.
This number and the minimum rank for detection were adopted interdependently to avoid selecting too many or too few candidate stars. We verified, however, that the results of the present analysis remain essentially unchanged as long as the values of these two parameters are kept within reasonable bounds.
N≥3 = N3 + N4 + N5.
These estimates are based on a binomial distribution with a probability p of success (i.e., detecting three or more lines on a star by chance) equal to 1.6025 × 10−5, so the expected number of chance detections in a sample of n ≃ 70 000 stars would be ∼1 ± 1.
Acknowledgments
The authors are grateful to an anonymous referee whose comments have prompted us to improve our methodology and its presentation, as well as better emphasize the reliability of the results. We also warmly thank Jaime Perea and María Asunción del Olmo for interesting discussions and useful advice about spectra normalization. J. L. T. and J. M. S. acknowledge financial support from the Spanish AEI and European FEDER funds through the research project AYA2016-76682-C3. Additional funding has been provided by the State Agency for Research of the Spanish MCIU through a “Center of Excellence María de Maeztu” award to the Institut de Ciències del Cosmos of the University of Barcelona.
References
- Arcavi, I., Hosseinzadeh, G., Howell, D. A., et al. 2017, Nature, 551, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Argast, D., Samland, M., Thielemann, F.-K., & Qian, Y.-Z. 2004, A&A, 416, 997 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnould, M., Goriely, S., & Takahashi, K. 2007, Phys. Rep., 450, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Battistini, C., & Bensby, T. 2016, A&A, 586, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanco-Cuaresma, S. 2019, MNRAS, 486, 2075 [NASA ADS] [CrossRef] [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., & Jofré, P. 2014, A&A, 569, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burbidge, E. M., Burbidge, G. R., Fowler, W. A., & Hoyle, F. 1957, Rev. Mod. Phys., 29, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Burris, D. L., Pilachowski, C. A., Armandroff, T. E., et al. 2000, ApJ, 544, 302 [NASA ADS] [CrossRef] [Google Scholar]
- Busso, M., Gallino, R., & Wasserburg, G. J. 1999, ARA&A, 37, 239 [NASA ADS] [CrossRef] [Google Scholar]
- Côté, B., Fryer, C. L., Belczynski, K., et al. 2018, ApJ, 855, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Cowan, J. J., & Thielemann, F.-K. 2004, Phys. Today, 57, 47 [CrossRef] [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Frebel, A., & Beers, T. C. 2018, Phys. Today, 71, 30 [CrossRef] [Google Scholar]
- Freiburghaus, C., Rosswog, S., & Thielemann, F.-K. 1999, ApJ, 525, L121 [Google Scholar]
- Goriely, S., & Siess, L. 2018, A&A, 609, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heil, M., Juseviciute, A., Käppeler, F., et al. 2009, PASA, 26, 243 [NASA ADS] [Google Scholar]
- Käppeler, F., Gallino, R., Bisterzo, S., & Aoki, W. 2011, Rev. Mod. Phys., 83, 157 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karakas, A. I., García-Hernández, D. A., & Lugaro, M. 2012, ApJ, 751, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Kasen, D., Metzger, B., Barnes, J., Quataert, E., & Ramirez-Ruiz, E. 2017, Nature, 551, 80 [Google Scholar]
- Koch, A., & Edvardsson, B. 2002, A&A, 381, 500 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Komiya, Y., & Shigeyama, T. 2016, ApJ, 830, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Kramida, A., Ralchenko, Y., Reader, J., & NIST ASD Team 2018, NIST Atomic Spectra Database (version 5.6.1), https://physics.nist.gov/asd [Google Scholar]
- Kratz, K.-L., Farouqi, K., Pfeiffer, B., et al. 2007, ApJ, 662, 39 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Lee, Y. S., Beers, T. C., Sivarani, T., et al. 2008, AJ, 136, 2022 [NASA ADS] [CrossRef] [Google Scholar]
- Liccardo, V., Malheiro, M., Hussein, M. S., Carlson, B. V., & Frederico, T. 2018, Eur. Phys. J. A, 54, 221 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Limongi, M., & Chieffi, A. 2018, ApJS, 237, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Lugaro, M., Herwig, F., Lattanzio, J. C., Gallino, R., & Straniero, O. 2003, ApJ, 586, 1305 [NASA ADS] [CrossRef] [Google Scholar]
- Mas-Ribas, L., Miralda-Escudé, J., Pérez-Ràfols, I., et al. 2017, ApJ, 846, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Meyer, B. S. 1994, ARA&A, 32, 153 [NASA ADS] [CrossRef] [Google Scholar]
- Naiman, J. P., Pillepich, A., Springel, V., et al. 2018, MNRAS, 477, 1206 [NASA ADS] [CrossRef] [Google Scholar]
- Pian, E., D’Avanzo, P., Benetti, S., et al. 2017, Nature, 551, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Reifarth, R. 2010, J. Phys. Conf. Ser., 202, 012022 [CrossRef] [Google Scholar]
- Roederer, I. U., & Lawler, J. E. 2012, ApJ, 750, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Siegel, D. M., Barnes, J., & Metzger, B. D. 2019, Nature, 569, 241 [NASA ADS] [CrossRef] [Google Scholar]
- Siqueira Mello, C., Barbuy, B., Spite, M., & Spite, F. 2012, A&A, 548, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smartt, S. J., Chen, T. W., Jerkstrand, A., et al. 2017, Nature, 551, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Sneden, C., & Cowan, J. J. 2003, Science, 299, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Sneden, C., Cowan, J. J., & Gallino, R. 2008, ARA&A, 46, 241 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Thielemann, F. K., Arcones, A., Käppeli, R., et al. 2011, Nucl. Phys., 66, 346 [Google Scholar]
- Thielemann, F.-K., Isern, J., Perego, A., & von Ballmoos, P. 2018, Space Sci. Rev., 214, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., Wilson, J. R., Mathews, G. J., Hoffman, R. D., & Meyer, B. S. 1994, ApJ, 433, 229 [NASA ADS] [CrossRef] [Google Scholar]
- Yanny, B., Rockosi, C., Newberg, H. J., et al. 2009, AJ, 137, 4377 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: SDSS/SEGUE stars potentially rich in r-process elements
Spectroscopic identifier, spectral subclass and metallicity of stars with likely enhancement of neutron-rich elements that are located in SEGUE plates listed in Table 2.
All Tables
Strongest lines from Eu in optical window and assigned spectral ranges for detection (see text).
Spectroscopic identifier, spectral subclass and metallicity of stars with likely enhancement of neutron-rich elements that are located in SEGUE plates listed in Table 2.
All Figures
|
Fig. 1. High-resolution spectra of two stars: HD 122563 (blue) and HE 1523−0901 (red). While the former star has low abundances of r-process elements, the latter is the richest object in these elements ever found in the Galaxy’s halo. It is important to note that the spectrum of HE 1523−0901 shows a large number of strong absorption lines from lanthanides such as lanthanum (La), cerium (Ce), samarium (Sm) and europium (Eu), which produces the most intense absorption line at 4129.70 Å. (Reproduced from Frebel & Beers 2018, with the permission of the American Institute of Physics). |
| In the text | |
|
Fig. 2. Comparison of certain observed lines in F5 stars (orange curves) with average flux inferred from whole spectral class (blue curves). The lighter bands surrounding the fluxes show their associated uncertainties, while the green colored areas identify the integrated flux differences that we attribute to lines from Eu. Panel a: F5 star (specobjID = 3719984370237415424) that shows a substantial flux deficit compared to the mean in the 4127–4131 Å wavelength range that encompasses an important line of Eu II (see Table 1). Panel b: another F5 star (specobjID = 2786716958031191040) also showing a significant flux deficiency in the 4659–4663 Å range, which is the interval of wavelengths where one expects to find a strong Eu I line. In both cases the stars have been identified as positive detections. In contrast, panel c shows a third F5 star (specobjID = 3002850987342928896) that does not show evidence for the existence of this latter line in absorption, which classifies it as a non-detection. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.