Fig. 1.
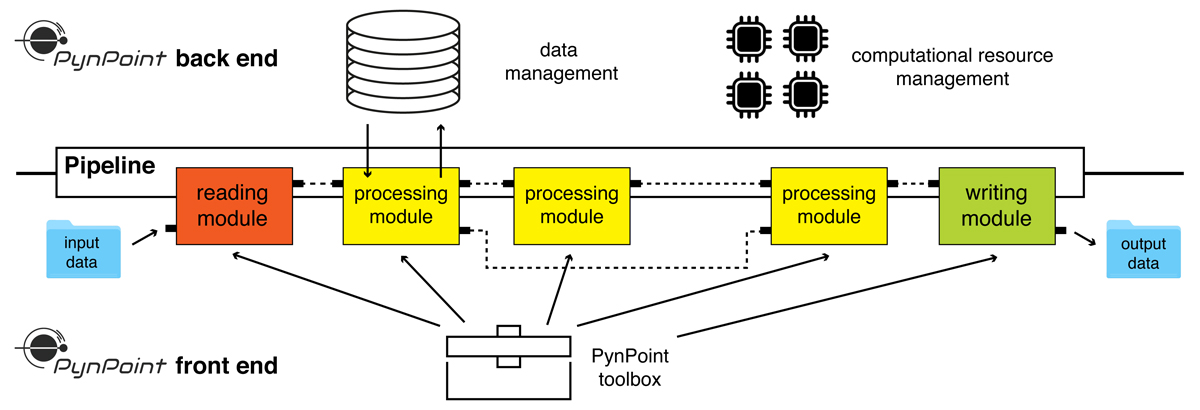
Schematic overview of the software design with the separation of the front-end and back-end functionalities. PynPoint offers a simple front end which can be used to define a sequence of pipeline modules. Management of the data and the computational resources (i.e., multiprocessing and memory usage) is handled by the back-end of PynPoint. Reading, processing, and writing modules are attached to the pipeline and sequentially executed while results are stored in the central database. The architecture allows the user to easily rerun pipeline modules and evaluate the results at various stages of the data reduction.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.