| Issue |
A&A
Volume 619, November 2018
|
|
|---|---|---|
| Article Number | A158 | |
| Number of page(s) | 17 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/201833928 | |
| Published online | 20 November 2018 | |
Asteroseismic age estimates of RGB stars in open clusters
A statistical investigation of different estimation methods
1
INAF – Osservatorio Astronomico di Collurania, Via Maggini, 64100 Teramo, Italy
2
INFN, Sezione di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
3
Dipartimento di Fisica “Enrico Fermi”, Università di Pisa, Largo Pontecorvo 3, 56127 Pisa, Italy
e-mail: valle@df.unipi.it
Received:
23
July
2018
Accepted:
13
September
2018
Context. Open clusters (OCs) provide a classical target to calibrate the age scale and other stellar parameters. Despite their wide use, some issues remain to be explored in detail.
Aims. We performed a theoretical investigation focused on the age estimate of red giant branch (RGB) stars in OCs based on mixed classical surface (Teff and [Fe/H]) and asteroseismic (Δν and νmax) parameters. We aimed to evaluate the performances of three widely adopted fitting procedures, that is, a pure geometrical fit, a maximum likelihood approach, and a single stars fit, in recovering stellar parameters.
Methods. A dense grid of stellar models was computed, covering different chemical compositions and different values of the mixing-length parameter. Artificial OCs were generated from these data by means of a Monte Carlo procedure for two different ages (7.5 and 9.0 Gyr) and two different choices of the number of stars in the RGB evolutionary phase (35 and 80). The cluster age and other fundamental parameters were then recovered by means of the three methods previously mentioned. A Monte Carlo Markov chain approach was adopted for estimating the posterior densities of probability of the estimated parameters.
Results. The geometrical approach overestimated the age by about 0.3 and 0.2 Gyr for true ages of 7.5 and 9.0 Gyr, respectively. The value of the initial helium content was recovered unbiased within the large random errors on the estimates. The maximum likelihood approach provided similar biases (0.1 and 0.2 Gyr) but with a variance reduced by a factor of between two and four with respect to geometrical fit. The independent fit of single stars showed a very large variance owing to its neglect of the fact that the stars came from the same cluster. The age of the cluster was recovered with no biases for 7.5 Gyr true age and with a bias of −0.4 Gyr for 9.0 Gyr. The most important difference between geometrical and maximum likelihood approaches was the robustness against observational errors. For the first fitting technique, we found that estimations starting from the same sample but with different Gaussian perturbations on the observables suffer from a variability in the recovered mean of about 0.3 Gyr from one Monte Carlo run to another. This value was as high as 45% of the intrinsic variability due to observational errors. On the other hand, for the maximum likelihood fitting method, this value was about 65%. This larger variability led most simulations – up to 90% – to fail to include the true parameter values in their estimated 1σ credible interval. Finally, we compared the performance of the three fitting methods for single RGB-star age estimation. The variability owing to the choice of the fitting method was minor, being about 15% of the variability caused by observational uncertainties.
Conclusions. Each method has its own merits and drawbacks. The single star fit showed the lowest performances. The higher precision of the maximum likelihood estimates is partially negated by the lower protection that this technique shows against random fluctuations compared to the pure geometrical fit. Ultimately, the choice of the fitting method has to be evaluated in light of the specific sample and evolutionary phases under investigation.
Key words: stars: fundamental parameters / methods: statistical / stars: evolution
© ESO 2018
1. Introduction
Unlike other key stellar parameters, such as mass and radius, stellar ages – with the exception of the Sun – cannot be obtained by any direct measurement. This has profound consequences on a wide range of astrophysical questions, from the study of the evolution of planetary systems to the understanding of the dynamical and chemical evolution of galaxies. Therefore, several techniques have been developed to obtain age estimates that are as accurate as possible for single, binary, and cluster stars (see Soderblom 2010, for a review). These methods rely on different approaches – from local interpolation to maximum likelihood (ML) and Bayesian fitting – generally attempting to match the observational quantities against a set of precomputed stellar models to identify the best fit and possibly an associated statistical error.
In this framework, open clusters (OCs) provide a classical target to calibrate the age scale, and potentially other stellar parameters, which are notoriously difficult to evaluate for single stars, for example, the initial helium abundance or the convective core overshooting efficiency. Classically, the age of an OC is determined by fitting the HR diagram or its observational counterpart – the colour-magnitude (CM) diagram – with a set of stellar isochrones. A review of the age-estimation methods for OCs can be found in Mermilliod et al. (2000), for example. This approach, coupled with robust statistical treatment of the fitting procedure – mainly by ML or Bayesian techniques – leads to a major advancement in the age determination of OCs. However the method suffers from some systematic errors that are sometimes difficult to properly address. A review of the approaches existing in the literature for tackling these problems can be found in Gallart et al. (2005), who also address the question of composite resolved stellar populations.
A different approach to OC age determination became available in the last decade. The space-based missions CoRoT (see e.g. Appourchaux et al. 2008; Michel et al. 2008; Baglin et al. 2009) and Kepler (see e.g. Borucki et al. 2010; Gilliland et al. 2010) made precise asteroseismic measurements available for a large sample of stars. Among the selected targets in the original Kepler field of view there were four open clusters, that is, NGC 6791, NGC 6811, NGC 6819 and NGC 6866. Although individual oscillations were available for only a subset of stars with the best signal-to-noise ratios, two global asteroseismic quantities – the average large frequency spacing Δν and the frequency of maximum oscillation power νmax – are generally well determined. These quantities, combined with traditional non-seismic observables, such as effective temperature Teff, and metallicity [Fe/H], allow a different way to establish stellar masses, radii, and ages.
In particular, the detection of solar-like oscillations in G and K giants (see e.g. Hekker et al. 2009; Mosser et al. 2010; Kallinger et al. 2010) makes these stars ideal targets to exploit the huge amount of asteroseismic observational data (Miglio et al. 2012; Miglio 2012; Stello et al. 2015). This interest lead to the development of fast and automated methods to obtain insight into the stellar fundamental parameters exploiting classical and asteroseismic constraints (see, among many, Stello et al. 2009; Quirion et al. 2010; Basu et al. 2012; Silva Aguirre et al. 2012; Valle et al. 2014, 2015c; Lebreton et al. 2014; Casagrande et al. 2014, 2016; Metcalfe et al. 2014). Several works in the literature exploited the detected oscillations for red giant branch (RGB) stars in clusters to provide an estimate of their age (see e.g. Hekker et al. 2011; Miglio et al. 2012, 2015; Miglio 2012; Corsaro et al. 2012; Wu et al. 2014; Lagarde et al. 2015; Casagrande et al. 2016). These estimates have the advantage of being independent of distance and reddening and provide an invaluable alternative way to check the age obtained by classical photometric fits of the cluster colour-magnitude diagram (CMD). The power of an integrated approach, that is, one that exploits data from various sources such as photometry, asteroseismology, and even binary systems, has been already demonstrated in the literature (e.g. Sandquist et al. 2016).
The availability of a large amount of high-quality data motivated the adoption of powerful statistical methods to derive stellar characteristics. Most of the studies presenting asteroseismic age estimates of OCs adopt a maximum likelihood or Bayesian technique using a mixture of classical surface parameters (usually effective temperature and metallicity) and asteroseismic constraints. Despite the growing popularity of these approaches, the question of the theoretical foundations of the OC fit when such constraints are available is largely unexplored in the literature. Indeed, a comprehensive study of the biases and the random variability to be expected in the OC asteroseismic age estimate from fitting RGB stars is still lacking.
This deficiency is clearly caused by the tremendous computational effort needed to shed light on this topic, an effort that was out of reach until recent years. A similar investigation is needed to carefully consider the different sources of theoretical variability that influence the stellar evolution but are not directly constrained by the observations. Failure to address some relevant sources of variability can lead to meaningless age calibration (see e.g. Valle et al. 2017, 2018). The problem is of particular relevance because the stellar evolution theory is still affected by non-negligible uncertainty (see e.g. Valle et al. 2013; Stancliffe et al. 2015; Dotter et al. 2017; Salaris & Cassisi 2017; Tognelli et al. 2018). Some relevant error sources are related to the treatment of convection and hamper a firm prediction on the extension of convective cores beyond the classical Schwarzschild border – often modelled by assuming a parametric overshooting – and of the efficiency of the superadiabatic convection, generally treated following the mixing-length scheme. To evaluate the effect of these uncertainties on the results grid of models with a wide range of masses, chemical compositions, overshooting, and external convection efficiencies are required. However, such a grid is not freely available in the literature and should be computed ad-hoc when a similar investigation is attempted.
In this investigation we explore some aspects of the performances attainable for cluster stars in the RGB phase. We focus on the fitting of stars whenever either classical surface or global asteroseismic observables are available. In the former group we consider the effective temperature and the metallicity [Fe/H], while in the latter we look at the average large frequency spacing Δν and the frequency of maximum oscillation power νmax. Our aims are twofold. Firstly, we are interested in evaluating the minimal statistical biases and errors on the recovered age (and on other stellar parameters varied in the fit) in various scenarios, with different reference age and size of the studied samples. These quantities are required to plan a sensible investigation on real observed objects. Secondly, we are interested in a thorough statistical comparison of some archetypal techniques adopted in the literature for cluster fitting. To this purpose we assess the relative merits and drawbacks of three approaches widely adopted in the literature, and quantify the bias in the reconstructed age for each of them.
The study is organised as follows. In Sect. 2 we present the framework for the investigation, the adopted Monte Carlo approach, the grid of stellar models, and the fitting methods discussed in the text. In Sect. 3 we present the results of the investigation and discuss the biases in the recovered parameters. The impact of the observational errors is further analysed in Sect. 4. A comparison between two of the adopted fitting methods is performed in Sect. 5 for the purpose of assessing the variability in RGB single star age estimates due to the adoption of different recovery techniques. Some conclusions are presented in Sect. 6.
2. Methods
Our theoretical analysis has been performed on a mock data set of artificial stars computed at a selected chemical composition and external convection efficiencies to simulate open cluster data. The age of the synthetic cluster, along with other stellar parameters, are recovered through several fitting methods, relying on a grid of stellar models with different chemical input (i.e. metallicity Z and initial helium abundance Y) and mixing-length parameter αml, to evaluate the relative performances of the procedures.
However, we did not take into account other known sources of variability. In particular, all the models were computed keeping the input physics fixed at the reference values and for a given heavy-element solar mixture. This choice stems for the consideration that it is not possible to model these sources of uncertainty using only one scaling parameter. As an example, the variability expected on the mean Rosseland opacity tables can be evaluated by comparing the computations by different groups. For a MS star, especially near the solar mass, mean differences of about 5% have been pointed out in the literature (Rose 2001; Badnell et al. 2005). However, for different ranges of temperature and density, such as those considered in this work, these differences show larger variations. Therefore a single scaling cannot precisely account for the opacity uncertainties.
The reference case chosen in this work approximatively mimics the old open cluster NGC 6791; in the following we assume the reference chemical composition Z = 0.02674, Y = 0.302, corresponding to a helium-to-metal enrichment ratio ΔY/ΔZ = 2.0. This choice implies [Fe/H] = 0.3, assuming the solar heavy-element mixture by Asplund et al. (2009). We fix two different ages at which the recovery is performed, that is, 7.5 Gyr and 9.0 Gyr.
In the subsequent step we sampled n stars from the reference isochrones in a way to systematically cover the whole RGB1. Gaussian perturbations were applied to classical and asteroseismic observables of these synthetic stars, mimicking the observational errors. The assumed uncertainties for this process were: 75 K in Teff, 0.1 dex in [Fe/H], 1% in Δν, and 2.5% in νmax. The errors on the surface parameters were set from the errors quoted in the APOKASC catalogue (Pinsonneault et al. 2014) and in Tayar et al. (2017), while the uncertainties on the asteroseismic quantities were chosen taking into account the values quoted in SAGA of 0.7% and 1.7% on Δν and νmax , respectively (Casagrande et al. 2014), and those in the APOKASC catalogue of 2.2% and 2.7%, respectively. To assess the importance of the sample size on the final results, two different values of n were considered: n = 35 for a scarcely populated RGB, and n = 80 for a well-populated RGB. These choices are representative of real numbers of RGB stars adopted in studies to constrain open cluster parameters by adopting asteroseismic quantities (e.g. Basu et al. 2011; Hekker et al. 2011).
In summary, four scenarios have been considered: a sample of 35 stars at age 7.5 Gyr (S35 in the following), a sample of 80 stars at 7.5 Gyr (S80), a sample of 35 stars at 9.0 Gyr (S35-9) and finally a sample of 80 stars at 9.0 Gyr (S80-9). Moreover, starting from the same artificial sample, the perturbation step was repeated N = 80 times to assess the differences in the age estimate solely due to random errors in the measurement process.
For the recovery step we needed to compute a dense grid of stellar models around the reference scenario. To obtain a sensible age error estimate, the stellar grid should span an appropriate range not only in mass (or age for isochrones) but also in other quantities that impact the stellar evolution, such as the initial chemical composition (Z and Y), and in parameters that affect the position of the RGB, such as the value of the mixing-length parameter αml. The grid of stellar models is presented in Sect. 2.1. The actual recovery was performed by means of three different methods, fully described in Sect. 2.2.
2.1. Stellar model grid
The model grids were computed for masses in the range [0.4, 1.3] M⊙, with a step of 0.05 M⊙. The initial metallicity [Fe/H] was varied from 0.15 to 0.45 dex, with a step of 0.05 dex. The solar heavy-element mixture by Asplund et al. (2009) was adopted. Nine initial helium abundances were considered at fixed metallicity by adopting the commonly used linear relation 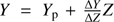 with the primordial abundance Yp = 0.2485 from WMAP (Peimbert et al. 2007a,b) and with a helium-to-metal enrichment ratio ΔY/ΔZ from 1 to 3 with a step of 0.25 (Gennaro et al. 2010).
with the primordial abundance Yp = 0.2485 from WMAP (Peimbert et al. 2007a,b) and with a helium-to-metal enrichment ratio ΔY/ΔZ from 1 to 3 with a step of 0.25 (Gennaro et al. 2010).
The FRANEC code (Degl’nnocenti et al. 2008; Tognelli et al. 2011) was used to compute the stellar models, in the same configuration as was adopted to compute the Pisa Stellar Evolution Data Base2 for low-mass stars (Dell’Omodarme et al. 2012). The models were computed for five different values of mixing-length parameter αml in the range [1.54, 1.94] with a step of 0.1, with 1.74 being the solar-scaled value3. Microscopic diffusion is considered according to Thoul et al. (1994). Convective core overshooting was not included because for the range of mass relevant for the analysis (the reference scenario mass in RGB is about 1.15 M⊙) it does not contribute to the stellar evolution. Further details on the stellar models are fully described in Valle et al. (2009, 2015a,c) and references therein.
Isochrones, in the age range [5, 10] Gyr with a time step of 100 Myr, were computed according to the procedure described in Dell’Omodarme et al. (2012) and Dell’Omodarme & Valle (2013).
The average large frequency spacing Δν and the frequency of maximum oscillation power νmax are obtained using the scaling relations from the solar values (Ulrich 1986; Kjeldsen & Bedding 1995):
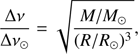
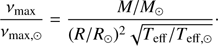
The validity of these scaling relations in the RGB phase has been questioned in recent years (Epstein & Pinsonneault 2014; Gaulme et al. 2016; Viani et al. 2017), posing a serious problem whenever adopted for a comparison with observational data. Fortunately, this question is of minor importance for our aims, because both artificial data and the recovery grid are computed using the same scheme.
2.2. Fitting procedures
For the age recovery phase we employed three different techniques: a pure geometrical isochrone fitting, a Bayesian ML approach, and an independent fit of single stars. All these methods are commonly adopted in the literature (see among many Frayn & Gilmore 2002; Pont & Eyer 2004; Jørgensen & Lindegren 2005; von Hippel et al. 2006; Gai et al. 2011; Casagrande et al. 2016; Creevey et al. 2017), and several aspects of their relative performances are well understood. A comprehensive review of their use for age fitting – but for different observable constraints – can be found in Valls-Gabaud (2014) and references therein. The comparisons of the techniques presented in the literature are frequently made using main sequence stars – for which the reliability of the theoretical stellar model is the highest – and often do not assess the relevance for the results of the different sources of uncertainties in the theoretical stellar models. Indeed, a general theoretical analysis of the age recovery for RGB stars with accurate asteroseismic observational data is still lacking in the literature.
To this aim, the present analysis assesses the biases and the uncertainty – due solely to the observational errors – on the final age estimates for RGB stars, focussing on several key quantities governing the stellar evolution. In other words, we work in an ideal framework in which the synthetic stars are sampled from the same grid adopted in the recovery stage. In this way we evaluate the theoretical minimum uncertainty, and, most importantly, the unavoidable biases that characterise the different adopted methods.
2.2.1. Geometrical fit
The first recovery technique is based on pure geometrical fitting of isochrones to the observed quantities. Let θ = (αml, ΔY/ΔZ, Z, age) be the vector of isochrone parameters and qi ≡ {Teff, [Fe/H], Δν, νmax}i be the vector of observed quantities for each star i in the sample (i = 1, …, N). Although for numerical reasons the fit is performed on the ΔY/ΔZ quantity, this quantity is linked to the initial helium abundance by the linear relation given in Sect. 2.1. The discussion of the results is therefore frequently focussed on the latter quantity.
We set σi to be the vector of observational uncertainties for the ith star. For each point j on a given isochrone we define qj(θ) as the vector of theoretical values. Finally, we compute the geometrical distance dij(θ) between the observed star i and the jth point on the isochrone, defined as
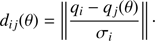
The statistic
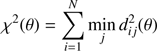
can then be adopted to compute the probability P(θ) that the sample comes from the given isochrone. In fact, if stars are uniformly distributed along the isochrone (this is indeed not the case, but see the following discussion), and assuming an independent Gaussian error model, it follows that
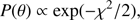
where we neglect the normalization constant, which only depends on the observational errors σ and not on θ, and has no practical importance in the posterior probability estimation. In fact, as detailed below, the relative merits of two sets of parameters θ1 and θ2 are evaluated on the basis of the ratio P(θ1)/P(θ2), meaning that the contribution of the normalization constant cancels out. In other words, the method minimises the sum of the minimum distances from each point to the isochrone and computes the probability that the sample comes from the isochrone parametrized by θ as the product of probability that each star comes from the isochrone.
A key point to address in the computation is that the isochrone is represented by a sequence of points, whose position is dictated by the stellar evolution time step. Therefore some evolutionary phases are more densely populated than others, posing a possible problem in the evaluation of the minimum distance. To overcome this difficulty we determined the minimum distance of an observational point qi from an isochrone in two steps. First we found the minimum distance d1 using Eq. (3),
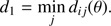
We set j̃ to be the index on the isochrone corresponding to d1. Subsequently, the distances d2 and d3 from the straight line passing from the points j̃ − 1 and j̃ + 1, respectively, are evaluated. The distances d2 and d3 were considered valid if the projection of qi was found to lie on the segments connecting qj̃ − 1 to qj̃ and qj̃ to qj̃ + 1, respectively. Then the minimum of the valid distances among d1, d2, and d3 was adopted as the distance from the point i to the isochrone.
The method easily allows one to specify a prior on the θ parameter, adding them as multiplicative factors in Eq. (5). In the following we adopt flat priors for all the parameters.
The results obtained in this way can be compared to a direct numerical integration of the likelihood function P(θ) over the whole grid. This procedure does not rely on isochrone interpolations but evaluates the likelihood for all the grid θ values and approximates the integral with a discrete sum. The marginalized distributions of each parameter are obtained by summing the likelihood function over all the other parameters. Then, the mean values and the standard deviations of the distributions are adopted as best estimates and their 1σ errors. This approach works well when the grid is dense enough in the parameter space because it cannot explore combinations of parameters outside those adopted in the grid computation. An in-depth discussion of the relative performance of this approach with respect to others, such as Monte Carlo Markov chain (MCMC) simulations in the framework of a binary system, fit can be found in Bazot et al. (2012).
2.2.2. Maximum-likelihood fit
It is well known (see Valls-Gabaud 2014, and references therein) that pure geometrical fitting suffers from intrinsic degeneracy, and different sets of parameters can provide similar likelihoods. In particular, the age-metallicity degeneracy poses a significant problem, chiefly in the main sequence phase. Indeed the geometrical fit does not exploit all the information provided by the stellar evolution computation, neglecting the timescale of the evolution in the fit. Therefore the second adopted recovery technique was a variation of the previous one, and accounts for the variation of the stellar evolution timescale climbing on the RGB. As widely discussed in the literature, the inclusion of this information in the fitting procedure can lead to better estimates than those obtained with a pure geometrical fit (see Valls-Gabaud 2014, and references therein). We define the likelihood that a star i comes from a given isochrone as
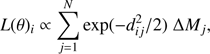
where ΔMj is the mass interval between the point j and j + 1 in the isochrone and accounts for the different evolutionary timescale along the isochrone. As in the previous case, the normalization constant can be safely neglected for our aims.
In other words the likelihood that a point comes from an isochrone can be viewed as the sum over all the isochrone points of the products of the probability that it comes from position j in the isochrone (ΔMj) multiplied by the probability of a distance dij of the observational point to the jth isochrone position (assuming a Gaussian error model). The distance dij from observation to isochrone position was assessed with the same technique discussed above for the geometrical fit. The probability that the whole observed sample comes from the given isochrone is therefore simply the product of all the individual likelihoods:
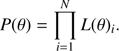
This method reduces to the previous one if all the contributions to L(θ)i are neglected except the one from the point with minimum dij. We note that in the formulation of the likelihood in Eq. (7), a factor giving the contribution of the initial mass function (IMF) is often included; however its inclusion in the RGB phase is of negligible importance given the small differences in mass among the isochrone points (the mass range spanned by the theoretical points is 0.008 M⊙). Therefore we prefer to not include a specific formulation of IMF, implicitly assuming a flat IMF in this mass region. This assumption is in agreement with the discussion in Valls-Gabaud (2014) about the relevance of the IMF weight in different evolutionary phases. However, as a safety measure, we verified that assuming a Salpeter IMF alters the results in a negligible way. As in the case of the geometrical fit, flat priors were assumed on the parameters θ.
As in the previous case, computational implementation is particularly important for the obtention of a reliable estimate from Eq. (7), which approximates the integral over the isochrone. In particular, the likelihood in the equation depends on the mass step between points. The distance in mass between consecutive points in the raw isochrone is not constant and typically too large to grant a fine approximation of the integral. Therefore the isochrones entering in the likelihood evaluation were linearly interpolated in mass so that 600 points were located, equally spaced in mass, in the relevant RGB range (values of Δν/Δν⊙ < 0.15). Each distance was then evaluated and adopted for the computation of Eq. (7). The adopted choices are more than enough for granting stable results, as verified by a direct trial-and-error procedure.
2.2.3. SCEPtER fitting of individual stars
As a last method we relied on fitting individual stars, that is, each star was independently fitted relaxing the constraint that they should share the same chemical composition and superadiabatic convection efficiency. The fit was performed by means of the SCEPtER method (Valle et al. 2015a,b,c), an ML technique adopted in the past for single and binary stars. For the i star, the technique computes a likelihood for each j point of every given isochrone as
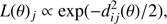
with dij(θ) as in Eq. (3). The likelihood function is evaluated for each grid point within 3σ of all the variables from qi; we define Lmax as the maximum value obtained in this step. The estimated stellar quantities are obtained by averaging the corresponding θ quantity of all the models with a likelihood greater than 0.95 × Lmax. The performances of this method are expected to be clearly inferior to the previous ones since it does not use the information that the stars come from a cluster. Indeed, it serves as a useful reference to compare the performance of the first two techniques and – thanks to the large numbers law – the uncertainty on the recovered mean age is expected to scale as the inverse of the square root of the sample size.
2.3. Simulations scheme
To establish the accuracy and precision of the three techniques we relied on several Monte Carlo simulations. For all of four scenarios defined in Sect. 2 (S35, S35-9, S80, and S80-9), we performed N = 80 Monte Carlo different perturbations of the synthetic observational values. The number of simulations was assessed by means of a trial-and-error procedure, and is enough to reach the stability of the results. Each synthetic sample was subjected to parameter estimation through the three techniques described in Sect. 2.2. A suffix is added to the scenario names to identify the algorithm adopted in the fit. Therefore, as an example, scenario S35 refers to the geometrical fit of 35 artificial stars sampled at 7.5 Gyr, S35w refers to the same configuration fitted by the ML approach, and S35S to the fit of individual stars by means of SCEPtER.
The SCEPtER estimation, which can be viewed as a local interpolation, promptly returns a set of parameters, θ, for each star. Therefore we obtained a dataset of 80 × 35 estimates for scenarios S35S and S35-9S and 80 × 80 estimates for scenarios S80S and S80-9S.
The estimation for the first two methods is more complex than when fitting single stars and was performed adopting a MCMC process, using the likelihoods in Eqs. (5) and (8). This method is widely adopted in the literature, originating from the formulation of Metropolis et al. (1953) and Hastings (1970). The method identifies a good starting point and then explores the parameter space by means of random displacements, following a user-specified “jump function”. Rules for accepting the sampled parameters are based on the comparison of the likelihood of the new set of parameters with that of the previous one. The initial part of the chain is considered non-stationary and is discarded (burning-in phase) from the analysis. The chain is then evolved for a length long enough to fully explore the posterior density space. Details on the procedure, the length of the burning-in and sampling chains, and on the convergence-enhancing algorithmic approach are provided in Appendix A.
For the geometrical fitting, the evolution of eight parallel chains of 7000 repetitions for samples of 35 stars and 21 000 repetitions for samples of 80 stars were adequate for convergence. For the ML approach, the burn-in chain length had to be increased to 9000. The difference is due to the faster convergence of the pure geometrical fitting, whose likelihood function is smoother than that of the ML approach, which is sparse in the parameter space, causing the chain to have greater difficulty in accurately mapping the posterior probability density.
2.4. Differences between geometrical and ML approaches
The apparent similarity of the methods described in Sects. 2.2.1 and 2.2.2 hides a significant difference in the underlying approaches and in the targeted best solution. The geometrical method is insensitive to any part of a fitting isochrone but the nearest point, so two isochrones that have an equal minimum distance but a different shape are indistinguishable. This shows that this method clearly does not exploit all the information coded in the isochrone.
On the other hand, the ML fit can leverage not only the minimum distance, but also a portion of the isochrone in the neighbourhood of this point, as it considers all the points on the curve; see Eq. (7). The ML also accounts for the timescale of the evolution; this term acts as a prior in the fitting stage, always favouring slowly evolving phases over rapid ones.
It is therefore understandable that the best solution for the geometrical fit can be, and will generally be, different from the ML one. Indeed, it is possible to show this behaviour even in a simple toy model (Appendix B). The Appendix considers a simple “isochrone”, modelled by an arc of parabola, and one observational point in a two-dimensional (2D) space that can be shifted in one direction only (see Fig. B.1). The position of the point is then varied continuously and the likelihood from Eqs. (5) and (7) are computed.
It is obvious that the adoption of a pure geometrical approach leads to the best fitting isochrone being the one that exactly passes through the observational point. However, this is not the case for the ML approach, which favours a slightly biased value but allows for a greater portion of the curve to remain close to the observational point. Moreover, Appendix B also shows that the variance of the ML solution is lower than that of the geometrical fit. This is logical because, as mentioned above, the ML approach has much more information to use for discriminating among isochrones and discarding solutions that are still acceptable for the geometrical fitting. Therefore, as the sample size increases, it is expected that the ML error shrinks faster than the geometrical one.
Although for real data the situation is much more complex, these general considerations still hold and are at the basis of the differences between the results obtained with the two methods discussed in the following sections.
3. Estimated parameters
The three different estimation techniques described in Sect. 2.2 were applied to the four scenarios introduced in Sect. 2. Figures 1–4 display the joint density of the obtained results in the αml versus age, ΔY/ΔZ versus age, and Z versus age planes, while Table 1 contains the median value of the marginalized parameters along with the 16th and 84th percentiles as indicators of the distribution dispersion.
 |
Fig. 1. Top row, left: 2D density of probability in the age vs. αml plane from samples of 35 RGB stars (true age of 7.5 Gyr). Parameters are recovered by means of the pure geometrical method (see text). The cross marks the position of the true values, while the filled circle marks the median of the recovered ones. Middle: same as in the left panel, but in the age vs. ΔY/ΔZ plane. Right: as in the left panel, but in the age vs. Z plane. Middle row: as in the top row, but for maximum likelihood recovery. Bottom row: as in the top row, but for SCEPtER individual recovery. For ease of comparison, the corresponding panels in the three subsequent figures (Figs. 2–4) share the same colour key. |
Estimated median (-est.), 16th (σ−), and 84th (σ+) percentiles of the stellar parameters (αml, ΔY/ΔZ, Z, and age) recovered in the twelve considered scenarios.
It is apparent at first glance that the marginalized distributions have different characteristics depending on the method adopted for the fit. The cluster fit by the SCEPtER pipeline (Sect. 2.2.3) produces diffuse distributions (third rows in Figs. 1–4) due to the possibility of each star to provide independently a best fit solution. The posterior probability density for the stellar parameters are nearly flat for S35S and S80S scenarios, and are only marginally peaked for S35-9S and S80-9S scenarios. The posterior maps from the geometrical fit (Sect. 2.2.1, first rows in the figures) show clearly peaked unimodal distributions, with a somewhat large variance. On the other hand, the marginalized distributions resulting from the ML method (Sect. 2.2.2, second rows in the figures) are heavily peaked and often multimodal. This explains the need in the MCMC construction to rely on a long chain to properly explore the posterior density.
Apart from these differences, there is evidence that some parameters can be recovered well by each of the analysed methods. This is the case of both the mixing-length value and the metallicity Z. This general agreement can be easily understood because these two parameters heavily affect the track position and morphology of RGB stars in the observable hyperspace.
The helium-to-metal enrichment ratio ΔY/ΔZ, and therefore initial helium content through the relation 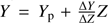 was more difficult to estimate. The results for the geometrical and independent star fits show large uncertainties. This is expected owing to the well-known but weak effect of the initial helium abundance on the position of the RGB. The ML approach performs much better in this case, providing a narrower error range that in all cases includes the unbiased value ΔY/ΔZ = 2.0. This is particularly true for scenarios S80w and S80-9w, where the larger sample size causes a reduction of the error range by a factor larger than three with respect to the pure geometrical approach. Although it is reasonable to obtain information on a cluster initial helium content if different evolutionary phases are taken into account, the uncertainty obtained here (i.e. ±0.03 for the Y value) is particularly small, being only a little larger than the precision of the helium content determination through the full CMD isochrone fitting.
was more difficult to estimate. The results for the geometrical and independent star fits show large uncertainties. This is expected owing to the well-known but weak effect of the initial helium abundance on the position of the RGB. The ML approach performs much better in this case, providing a narrower error range that in all cases includes the unbiased value ΔY/ΔZ = 2.0. This is particularly true for scenarios S80w and S80-9w, where the larger sample size causes a reduction of the error range by a factor larger than three with respect to the pure geometrical approach. Although it is reasonable to obtain information on a cluster initial helium content if different evolutionary phases are taken into account, the uncertainty obtained here (i.e. ±0.03 for the Y value) is particularly small, being only a little larger than the precision of the helium content determination through the full CMD isochrone fitting.
Regarding the age of the cluster, the methods can provide somewhat different estimates. For scenarios with a true age of 7.5 Gyr the differences between pure geometrical and ML fits are about 0.15 Gyr, the geometrical fit providing higher ages. For scenarios with a true age of 9.0 Gyr the difference increases to about 0.3 Gyr, but in this case the age estimate by the ML techniques is higher.
The following subsections are devoted to highlighting and discussing some specific results from the three techniques.
3.1. Results from the pure geometrical fit
The pure geometrical method (Sect. 2.2.1) showed a little bias, overestimating the age by about 0.3 and 0.2 Gyr in the S35 and S80 scenarios (relative errors of 4% and 3%), respectively, and underestimating it by about 0.2 and 0.1 Gyr in the S35-9 and S80-9 scenarios (−2% and −1%), respectively. The facts that the latter biases are smaller than the former and that the signs of the relative differences change are linked to edge effects. In fact, approaching the grid edge, the age estimates are bounded by the upper value of the grid, that is, 10 Gyr. This obviously limits the possibility of age overestimation. The distortion of the age estimate stems from the asymmetry of the stellar model grid in the hyperspace of parameters. As discussed in previous works (see e.g. Valle et al. 2015b, 2016, 2018) stellar track distances from a target point do not change symmetrically for symmetrical perturbations on the parameters adopted in their computation. In this particular case it happens that for scenario S35 and S80, isochrones with ΔY/ΔZ < 2 tend to be a little closer to the synthetic data than those with ΔY/ΔZ > 2. This leads to an underestimation of the initial helium abundance for the OC and consequently an overestimation of its age. For scenarios S35-9 and S80-9 the situation is complicated by the influence of edge effects that limit the possibility of the underestimation of the initial helium content due to the impossibility to obtain an age outside the grid boundary. Luckily, all the detected biases in the estimated ages are small, that is, about one third of the random errors due to observational uncertainties. The differences between the results for the scenarios with 35 and 80 artificial stars are minor, with a slight shrink of the error range and a much lower change in the estimated parameters than the random error component. Although it seems natural to anticipate that the estimated error shrinks with the square root of the sample size, this is only true when not accounting for the variance induced by the different artificial perturbations that occur among the N Monte Carlo experiments. Therefore the total variance is composed of two terms: a term due to the uncertainty in the recovered cluster parameters for a given generation of synthetic cluster stars, which indeed scales as the inverse of the square root of the sample size, and a term that accounts for the dispersion of the N recovered medians of each Monte Carlo simulation. This last component of the variance would not shrink with the sample size, leading to the weak dependence shown in Table 1.
As a consistency check, the results obtained by the geometrical method were compared to a direct integration of the likelihood function P(θ) over the whole grid, as described in Sect. 2.2.1. Table 2 presents the results (identified by a suffix “D”), obtained combining the results from the N = 80 random artificial samples. These agree well with the MCMC results, as should be expected in light of two concurrent effects. First of all, the fitted values returned by the MCMC simulation are very close to points provided by the grid itself, so the grid resolution does not hamper the achievement of good accuracy. Second, the errors shown in Table 1 on the recovered ΔY/ΔZ and age are large with respect to the grid steps. Therefore the coarseness of the grid does not limit the accuracy attainable using a direct approach.
Mean and standard deviation of the stellar parameters (αml, ΔY/ΔZ, Z, and age) recovered by direct likelihood integration.
3.2. Results from the ML fit
The method that adopts an ML fit (Sect. 2.2.2), taking into account the evolutionary timescale on the isochrone (which differentiates this method from the pure geometrical fit), provides similar results to the geometrical method, with some interesting differences. The biases on the recovered age are of about 0.15 and 0.1 Gyr for scenarios S35w and S80w, while for scenarios S35-9w and S80-9w these biases are about 0.10 and 0.3 Gyr. In these cases, the method provides a peak in density for values of the ΔY/ΔZ parameters of about 1.75 and ages of about 9.4 Gyr (central panel in the middle rows of Figs. 2 and 4). This is the origin of the detected age biases. Moreover, no edge effects mitigate the overestimation because the variance of the posterior density is low and the distribution is not heavily truncated at 10 Gyr, that is, the edge of the grid. Figures 3 and 4 show a drastic reduction of the error on the ML recovered parameters for larger sample sizes. In all the scenarios the random errors on the age are about one quarter of the corresponding quantities from the geometrical fitting. This reduction comes from the different approaches to the fit of the two techniques. For the geometrical method, two isochrones that pass at the same minimum distance from a reference point provide identical likelihood. This is not the case for the ML approach, which takes into account the whole evolution of the isochrone and assigns a higher likelihood to a curve that stays closer to the reference point for a larger evolutionary portion. Further details are discussed in Appendix B.
The biases in the initial helium content are almost negligible and the error on the recovered ΔY/ΔZ lower than about 0.3 and 0.15 for scenarios with 35 and 80 stars, respectively. Indeed, these impressive results come from relatively small differences in the shape of the isochrones when the initial helium content varies. While the difference is so subtle that the isochrones are hardly distinguishable by eye, nevertheless it is more than enough for the ML algorithm to discriminate among them. As mentioned above, the ΔY/ΔZ shows a tendency for underestimation in the S80-9w scenario, leading to the value of 1.83, which is marginally consistent with the true value of 2.0 given the very small error of +0.19. The random errors on those estimates are significantly smaller, by about a half, than those from geometrical fitting.
The length of the chain needed to reach the convergence is another major difference between ML and geometrical estimates. Due to the shown unimodality, the geometrical fit reaches convergence much faster: usually the geometrical chains were stationary and well mixed after about one quarter of the lengths stated in Sect. 2.3. For the 80-star scenarios the convergence and mixing tests of Gelman–Rubin and Geweke (Gelman & Rubin 1992; Geweke 1992) reported problems for five chains at 7.5 Gyr and seven at 9.0 Gyr. However, the removal of them from the global statistics leads to negligible differences in the final estimates of the parameters. Indeed the estimates from these problematic chains are indistinguishable from those without convergence issues. The problems reported by the tests arise due to the heavily peaked multimodal posterior distributions (see second row in Figs. 3 and 4); the proposed Gaussian distribution has more difficulty in properly mapping all the local maxima of the posteriors. This is a well-known difficulty in performing MCMC integration, which can be tackled by a change of the proposal distribution to a form that better mimics the posterior (see e.g. Haario et al. 2001; Robert & Casella 2005; Atchadé et al. 2011), which is a difficult task in high-dimensional space. Other possible remedies include adopting a longer chain or relying on more advanced sampling schema such as interacting MCMC (Robert & Casella 2005; Atchadé et al. 2011). However, as stated above, these convergence problems minimally alter the present analysis and do not justify the adoption of these complex integration methods.
In summary, the main difference between the geometrical and ML fitting methods is an appealing shrink of the random errors granted by the ML approach. As discussed in Sect. 4, when dealing with the reproducibility of the results from the various techniques in the presence of different artificial perturbations on the data, the increase in the precision of the ML estimates can lead the method to a struggle to include the true parameter values in their estimated credible intervals.
3.3. Results from the SCEPtER pipeline
The single and independent star fit (Sect. 2.2.3) shows, as expected, the largest random error because it does not make use of the information of common parameters among the whole sample. While Figs. 1–4 show the joint density from the whole sample of stars, it is possible to adopt a different approach. For each of the Monte Carlo runs one can compute the mean of the stellar parameters over the sample and then adopt these values to construct the joint density. By the law of large numbers it follows that the dispersion of the distribution of the means will shrink as the inverse of the square root of the sample size. Figure 5 shows, in the αml versus age plane, the reconstructed densities of the mean. The results are unbiased for a true age of 7.5 Gyr, while a bias of almost −0.9 Gyr occurs for the 9.0 Gyr true age scenarios. The result for 7.5 Gyr comes from the large, symmetric errors around the central value and is therefore of no practical relevance. The one for 9.0 Gyr shows a large bias, suggesting that this method has an accuracy that is clearly inferior to geometrical and maximum likelihood approaches. The magnitude of the bias stems directly by the fact that the variability of the estimates is of the same order of magnitude or even larger than the half-width of the age interval spanned by the grid. Therefore, the proximity of the upper edge of the grid to the true solution at 9.0 Gyr limits the possibility to explore higher ages, thus inducing a hard boundary in the estimated ages, leading to an edge effect similar to those discussed in Valle et al. (2014). The same does not occur at 7.5 Gyr.
 |
Fig. 5. Top row, left: 2D density of probability in the age vs. αml plane from samples of 35 RGB stars (true age 7.5 Gyr) from the mean of the SCEPtER fit of individual stars (see text). Right: same as in the left panel but for a true age of 9.0 Gyr. Bottom row: as in the top row, but for samples of 80 RGB stars. |
4. Assessing the sample variability
The results presented in the previous section obviously depend in some way on the samples adopted for their computation, and therefore depend on the random Gaussian perturbation added to the artificial stars mimicking the observational uncertainties. Therefore it is worth exploring the relevance of this particular problem; in other words how stable are the fits owing to the random nature of observational errors?
To this purpose we can exploit the results of the simulation to directly evaluate the variability on the recovered ages, splitting the variance into two components: a first one (σg) linked to the variability of the mean age among the Monte Carlo simulations, and a second one (σ) that accounts for the residual variance. Therefore σ is directly linked to the effect of the observational uncertainties on the recovered values, taking the observed values as perfectly unbiased. This is the quantity that would affect a fit for real stellar objects. On the other hand, the σg components, which cannot be assessed for real objects, are due to the fact that a bias (either random or systematic) in the observational values with respect to their true values would modify the median recovered parameters. This value is therefore linked to the dispersion of the medians. A σg that is negligible with respect to σ implies that the mean values are recovered with a low spread with respect to the precision of the estimates. If this is the case, the hidden error source owing to the uncontrollable error on the observations can be safely neglected. On the other hand, when σg is equal to or larger than σ, the spread in the mean recovered values is non-negligible. Therefore random observational errors can lead to different age estimates. Due to the impossibility for the observer to control this source of uncertainty, a large ratio σg/σ would pose serious problems, implying that the fitted age is prone to bias.
To assess the values of the two variance components, we adopted a very powerful statistical method: a random effect model fit (Venables & Ripley 2002; Bates et al. 2015), which is briefly introduced in Appendix C.
The standard error components in the twelve considered scenarios are reported in Table 3 along with the percentage q of the Monte Carlo experiments including the true values of all the parameters in the estimated 1σ interval from the fit, that is, the error on the individual Monte Carlo reconstructions. In this way it is possible to compare the 1σ interval coverage with respect to the prediction under the assumption that the parameters follow a Gaussian distributions with variance σ2 (i.e. 68%). The three methods show notably different performances. The single-star fit has the lower σg variability both in absolute and in relative terms. Therefore the results from this technique can be considered robust against observational errors. Obviously this comes at the cost of a remarkably lower precision in the estimates. The geometrical fitting method has the second smallest variance among realisations, that accounts for about 35% of the random residual error. This contribution is not dominant but is not negligible either, so any sensible analysis of real cluster RGB stars should account for it. As shown in the last column of Table 3, about 30% of the Monte Carlo perturbations lead to estimates of parameters whose 1σ credible interval does not include the true value. Although the contribution of random fluctuations in the observables to the overall variability in the estimates is usually neglected, the present results confirm the finding for detached binary systems discussed in Valle et al. (2018). That work reports a σg error as large as two thirds of the residual error σ. Ultimately, it seems that the role of random variability due to unavoidable measurement errors in the observational constraints is more important than commonly thought.
Age variance components from random models fit in the twelve considered scenarios (see text).
The largest σg/σ ratio comes from the ML fit that accounts for the evolutionary timescale. This result comes mainly from the reduction of the residual error on the age estimates discussed in Sect. 3. Overall the variance among realisations is about 60% of the random residual error, nearly double that resulting from geometrical fit. This leads to the risk of obtaining a best fit set of parameters that is inconsistent with the true ones. Indeed Table 3 shows the dramatic low q value of about 10% for the 80-star scenarios, with clear evidence that the problem gets worse as the sample size increases. It is therefore clear that even when stellar tracks and synthetic data perfectly match – apart from random variations – the adoption of the estimated errors from the ML fit is overoptimistic, greatly increasing the risk of failing to include the true values of the estimated parameters in the obtained 1σ error range.
In light of these results it seems the pure geometrical procedure may offer greater control of the random variability than the ML approach when fitting real objects.
5. Technique comparison for single-star fits
As discussed above, different methods are routinely adopted in the literature for age fitting (see Valls-Gabaud 2014, and references therein). Whereas it is common to present stellar estimates obtained using methods relying upon different grids of stellar models, differences in the estimates obtained in this way, but adopting a different fit method, are rarely explored (see e.g. Bazot et al. 2012 for a fit of α Cen A or Jørgensen & Lindegren 2005, for MS and SGB applications). It is therefore interesting to verify the relative performance of the techniques discussed above, but in the framework of single-star fits in the RGB phase. This section is devoted to the comparison of the age results from the three fitting methods described above.
The comparison is performed selecting 20 parent artificial stars in the RGB phase, equally spaced in Δν/Δν⊙ from 0.08 to 0.009 on the 7.5 Gyr isochrone (Z = 0.02674, Y = 0.2752), that is, centred over the grid described in Sect. 2.1. Each star was subjected to Gaussian perturbations of the observables, as described in Sect. 2. Each synthetic star was then individually fitted using one of the three techniques. The perturbation procedure was repeated 70 times for each star, to account for different observational errors. Alternatively to Sect. 2.2, the SCEPtER method was employed to recover not only the central values but also for estimating their errors, with a Monte Carlo sampling that is fully described in Valle et al. (2015b,c). Briefly, for each star, 500 secondary artificial stars were generated from the same Gaussian distribution adopted in the first perturbation step. All these stars were fitted. The median of the fitted values was usually adopted as the best estimate, and the 16th and 84th percentiles provide information about the errors.
For the MCMC fit, eight parallel chains of 7000 iterations in length were evolved (after a burning-in chain of 3000 iterations) for each star, and then thinned to reduce the sample size to 500 points for computational reasons. The consistency of the estimates from the thinned sample with those of the whole sample was verified.
In summary, the design of the simulation is fully crossed, that is, the experimental units (20 synthetic stars) are fitted by the three techniques, and the Monte Carlo simulation is repeated 70 times. This approach allows one to identify the different sources of variability in the final estimate. It is clear that the individual differences among the various Monte Carlo realisations are not of direct interest by themselves. The main information coded in these data is the variability that can occur only by chance in the results due to errors in measurements carried out on the observed stars. Indeed, although the individual differences between SCEPtER and MCMC estimates are interesting per se if assessed directly, they are much more informative if considered as representative of possible variability in the estimates owing to the choice of the fitting method. Obtaining unbiased and reliable estimates for these quantities from the bulk of the simulations is a relatively challenging task. As in Sect. 4, we exploit the power of a random-effect model fit (see Appendix C). This method was adopted to disentangle the residual variability in the age estimates σ from σa, σb, and σc those due to differences in the fitting methods, the choice of progenitor stars, and the individual Monte Carlo realizations, respectively. A source of variability is relevant whenever it is large with respect to σ.
The fit of the model provided a mean μ = 7.59 Gyr as the global age estimate, very close to the nominal value of 7.5 Gyr. Figure 6 shows a boxplot for the age estimates from the three methods. Pure geometrical and ML estimates gave nearly identical distributions of the ages, while the SCEPtER estimates show a larger variance. This is possibly due to the coarseness of the grid: while the first two methods can rely on isochrone interpolation to explore the posterior density, the SCEPtER method exploits only the existing grid points and therefore requires a much denser grid to offer equivalent accuracy. The global standard deviation was σ = 1.41 Gyr, revealing a large indetermination in the age fit. The other variance components are σa = 0.19 Gyr, σb = 0.11 Gyr, and σc = 0.11 Gyr. These results seems to point to a negligible variability due to either the position on the RGB or random errors on the observables (σb/σ = σc/σ ≈ 8%); more interestingly, the variability among the three estimation techniques is also quite low (σa/σ ≈ 13%). We also verified that the larger variance affecting SCEPtER estimates does not pose a problem of heteroscedasticity (i.e. non-uniform variance) for the the mixed-effect model. To this purpose we repeated the analysis working with the rank of the age4 and obtaining an equivalent result (σa/σ ≈ 10%).
 |
Fig. 6. Box plot of the age estimates for single RGB star fits from the three adopted methods in the text. |
In light of these results, it seems that – for single-star fits in the RGB phase – the choice of method for age recovery has no severe effect on the final age bias. It is clear however that this result cannot be generalised to include other evolutionary phases; further theoretical investigation is needed to address the question of the actual impact of the choice of fitting method on the final stellar age estimate.
6. Conclusions
We performed a theoretical investigation on the biases and random uncertainties affecting the age estimates from RGB stars in clusters. We focussed on the age determination based on a mixture of classical surface (Teff and [Fe/H]) and asteroseismic (Δν and νmax) observables. We built a mock data set of artificial stars with properties that mimic the old galactic open cluster NGC 6791, with metallicity [Fe/H] = 0.3 and an initial helium abundance of Y = 0.302, corresponding to a helium-to-metal enrichment ratio of ΔY/ΔZ = 2.0.
By means of Monte Carlo simulations we studied the performance of OC age reconstruction given a set of stars in the RGB evolutionary phase. We analysed clusters for two different ages, namely 7.5 Gyr and 9.0 Gyr, and for two hypothetical observational sample sizes, namely 35 and 80 stars. For each scenario, stars were sampled from the reference isochrones, and Gaussian perturbations were added to these quantities, to account for the observational errors. We adopted as typical uncertainties 75 K in Teff, 0.1 dex in [Fe/H], 1% in Δν and 2.5% in νmax.
For each of the four aforementioned scenarios we performed the recovery with three different methods: a pure geometrical isochrone fitting, a Bayesian maximum-likelihood fit, and an independent fit for single stars by means of the SCEPtER pipeline (Valle et al. 2015c), the latter being adopted as a reference for the performance of the other techniques. The artificial stars were sampled from the same grid of stellar models used in the recovery. Therefore we worked in an ideal case where stellar models perfectly match observational data. This means that we evaluated the maximum possible performance of the fitting techniques, that is, the minimum biases and random errors. When real stars are used rather than artificial ones, larger errors and biases are to be expected.
Overall, the performances of the methods were found to be similar. The mixing-length value and the metallicity Z are recovered accurately from all the scenarios by all the methods. The geometrical method slightly overestimated the age by about 0.3 Gyr for the scenarios with a true age of 7.5 Gyr, and underestimated it by about 0.2 Gyr for the scenarios of 9.0 Gyr. The value of the initial helium content is underestimated for the scenarios of 7.5 Gyr and overestimated for those of 9.0 Gyr; however these values are still consistent with the true value ΔY/ΔZ = 2.0 since they are affected by large random errors. This is due to the fact that the initial helium content impacts very mildly on the effective temperature of the RGB, therefore different initial helium abundances result in nearly identical isochrones apart from the age.
The ML technique provided similar biases but with a much lower variance. The age is overestimated by about 0.1 Gyr for the scenarios of 7.5 Gyr and 0.2 Gyr for the scenarios of 9.0 Gyr. The initial helium content is accurately estimated, with a small error. These results highlight the benefit of considering the whole isochrone’s path in the fit of an object and not only the distance to the closer point. This method provides random errors on the fitted quantities that are about one quarter of those returned by the pure geometrical fit. However, due to the multimodal nature of the posterior probability densities for the samples of 80 stars the method shows a much slower chain convergence in the MCMC, requiring about four times the number of iterations of the geometrical method.
The reference independent fit of single stars showed, as expected, a large variance. Taking into account only the mean values from each simulation – thus exploiting the variance reduction thanks to the laws of large numbers – we obtained an unbiased estimate for the scenario of 7.5 Gyr (not really informative, due to the symmetry of the grid around this value) and a bias of about −0.4 Gyr for the scenario of 9.0 Gyr.
The most important difference between the first two techniques comes from the robustness of the results against observational errors. We investigated how different perturbations of the synthetic data could lead to different age estimates. For the first fitting technique, we found that estimations starting from the same sample suffer from a 1σ variability of about 0.3 Gyr from one Monte Carlo run to another. This value is not negligible because it is about 45% of the intrinsic variability due to the observational error. The Bayesian fitting method showed a similar variance between runs but owing to the reduction of the global random component, its impact on the final variability is about 65%. This larger variability due to the random perturbation leads most simulations – up to 90% – to fail to include the true parameter values in their estimated 1σ credible interval.
Therefore the results obtained with the purely geometrical method are more resistant to observational errors than those obtained with an ML fit that account for the stellar evolutionary time scale. This is of particular relevance when the methods are adopted in practice to obtain age estimates from real data. As anticipated in Sect. 2, the uncertainty in the input physics neglected in the present work can play a relevant role. Given the very narrow credible intervals from ML estimates, the unexplored error sources can in principle provide a much wider error interval on the recovered parameters. As an example, a rigid percentage variation in the radiative opacity – which is not, as discussed in Sect. 2, a very realistic method to account for this uncertainty for RGB stars – would directly propagate to the estimated age (see e.g. Chaboyer et al. 1996; Valle et al. 2013). This means that a ±5% uncertainty corresponds to about 0.4 Gyr for an isochrone at 7.5 Gyr. While the 1σ error range from geometrical inference is larger than this value, this is not the case for ML estimates, leading to a false sense of accuracy.
While the inclusion of the information of the stellar evolutionary timescale in the fitting was advised for alleviating the problems linked to the age-metallicity degeneracy in the MS (Valls-Gabaud 2014, and references therein), it seems that – in agreement with the discussion in Valle et al. (2015c) – it does not always lead to better results and the gain in the increased precision in the estimates is counterbalanced by the lower protection against random fluctuation than is provided by a purely geometrical fit. Ultimately, the merits and the drawbacks of the methods have to be evaluated in light of the specific sample and evolutionary phases under investigation.
Finally, we compared the performance of the three fitting methods in the framework of single RGB star age estimation. Owing to the fact that we adopt the same grid of stellar models in the procedure, this comparison sheds some light on the differences that could be ascribed to relying on different algorithmic approaches in the age fitting. We obtained that the variability linked to the choice of the fitting method is minor, being about 15% of the variability caused by the observational uncertainties. Therefore it seems that for RGB stars the choice of fitting scheme does not contribute significantly to the final age bias. It is however clear that the validity of this statement is confined to the explored evolutionary phase. Further theoretical investigation is needed to explore the actual impact of the choices in the fitting method on the obtained results.
Acknowledgments
We thank our anonymous referee for the useful comments and suggestions. This work has been supported by PRA Università di Pisa 2018-2019 (Le stelle come laboratori cosmici di Fisica fondamentale, PI: S. Degl’Innocenti) and by INFN (Iniziativa specifica TAsP).
References
- Appourchaux, T., Michel, E., Auvergne, M., et al. 2008, A&A, 488, 705 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Atchadé, Y., Fort, G., Moulines, E., & Priouret, P. 2011, in Adaptive Markov Chain Monte Carlo: Theory and Methods, eds. D. Barber, A. T. Cemgil, & S. Chiappa (Cambridge: Cambridge University Press), 32 [Google Scholar]
- Badnell, N. R., Bautista, M. A., Butler, K., et al. 2005, MNRAS, 360, 458 [NASA ADS] [CrossRef] [Google Scholar]
- Baglin, A., Auvergne, M., Barge, P. et al. 2009, in IAU Symp., eds. F. Pont, D. Sasselov, & M. J. Holman, 253, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Basu, S., Grundahl, F., Stello, D., et al. 2011, ApJ, 729, L10 [NASA ADS] [CrossRef] [Google Scholar]
- Basu, S., Verner, G. A., Chaplin, W. J., & Elsworth, Y. 2012, ApJ, 746, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Bates, D., Mächler, M., Bolker, B., & Walker, S. 2015, J. Stat. Softw., 67, 1 [Google Scholar]
- Bazot, M., Bourguignon, S., & Christensen-Dalsgaard, J. 2012, MNRAS, 427, 1847 [NASA ADS] [CrossRef] [Google Scholar]
- Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Stello, D., et al. 2014, ApJ, 787, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Schlesinger, K. J., et al. 2016, MNRAS, 455, 987 [NASA ADS] [CrossRef] [Google Scholar]
- Chaboyer, B., Demarque, P., Kernan, P. J., Krauss, L. M., & Sarajedini, A. 1996, MNRAS, 283, 683 [NASA ADS] [Google Scholar]
- Corsaro, E., Stello, D., Huber, D., et al. 2012, ApJ, 757, 190 [NASA ADS] [CrossRef] [Google Scholar]
- Creevey, O. L., Metcalfe, T. S., Schultheis, M., et al. 2017, A&A, 601, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Degl’nnocenti, S., Prada Moroni, P. G., Marconi, M., & Ruoppo, A. 2008, Ap&SS, 316, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Dell’Omodarme, M., & Valle, G. 2013, The R Journal, 5, 108 [Google Scholar]
- Dell’Omodarme, M., Valle, G., Degl’Innocenti, S., & Prada Moroni, P. G. 2012, A&A, 540, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dotter, A., Conroy, C., Cargile, P., & Asplund, M. 2017, ApJ, 840, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Epstein, C. R., & Pinsonneault, M. H. 2014, ApJ, 780, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Feigelson, E. D., & Babu, G. J. 2012, Modern Statistical Methods for Astronomy with R Applications (Cambridge: Cambridge University Press), 476 [CrossRef] [Google Scholar]
- Frayn, C. M., & Gilmore, G. F. 2002, MNRAS, 337, 445 [NASA ADS] [CrossRef] [Google Scholar]
- Gai, N., Basu, S., Chaplin, W. J., & Elsworth, Y. 2011, ApJ, 730, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Gallart, C., Zoccali, M., & Aparicio, A. 2005, ARA&A, 43, 387 [NASA ADS] [CrossRef] [Google Scholar]
- Gaulme, P., McKeever, J., Jackiewicz, J., et al. 2016, ApJ, 832, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Stat. Sci., 7, 457 [Google Scholar]
- Gennaro, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2010, A&A, 518, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geweke, J. 1992, Bayesian Statistics (University Press), 169 [Google Scholar]
- Gilliland, R. L., Brown, T. M., Christensen-Dalsgaard, J., et al. 2010, PASP, 122, 131 [NASA ADS] [CrossRef] [Google Scholar]
- Haario, H., Saksman, E., & Tamminen, J. 2001, Bernoulli, 7, 223 [CrossRef] [MathSciNet] [Google Scholar]
- Härdle, W. K., & Simar, L. 2012, Applied Multivariate Statistical Analysis (Heidelberg: Springer), 580 [CrossRef] [Google Scholar]
- Hastings, W. K. 1970, Biometrika, 57, 97 [Google Scholar]
- Hekker, S., Kallinger, T., Baudin, F., et al. 2009, A&A, 506, 465 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hekker, S., Basu, S., Stello, D., et al. 2011, A&A, 530, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jørgensen, B. R., & Lindegren, L. 2005, A&A, 436, 127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kallinger, T., Mosser, B., Hekker, S., et al. 2010, A&A, 522, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kirkby-Kent, J. A., Maxted, P. F. L., Serenelli, A. M., et al. 2016, A&A, 591, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kjeldsen, H., & Bedding, T. R. 1995, A&A, 293, 87 [NASA ADS] [Google Scholar]
- Lagarde, N., Miglio, A., Eggenberger, P., et al. 2015, IAU Gen. Assem., 22, 2246886 [NASA ADS] [Google Scholar]
- Laird, N. M., & Ware, J. H. 1982, Biometrics, 38, 963 [CrossRef] [Google Scholar]
- Lebreton, Y., Goupil, M. J., & Montalbán, J. 2014, EAS Pub. Ser., 65, 177 [CrossRef] [Google Scholar]
- Mermilliod, J. C. 2000, in Stellar Clusters and Associations: Convection, Rotation, and Dynamos, eds. R. Pallavicini, G. Micela, & S. Sciortino, ASP Conf. Ser., 198, 105 [NASA ADS] [Google Scholar]
- Metcalfe, T. S., Creevey, O. L., Doğan, G., et al. 2014, ApJS, 214, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. 1953, J. Chemi. Phys., 21, 1087 [NASA ADS] [CrossRef] [Google Scholar]
- Michel, E., Baglin, A., Auvergne, M., et al. 2008, Science, 322, 558 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Miglio, A. 2012, in Asteroseismology of Red Giants as a Tool for Studying Stellar Populations: First Steps, eds. A. Miglio, J. Montalbán, & A. Noels, 11 [Google Scholar]
- Miglio, A., Brogaard, K., Stello, D., et al. 2012, MNRAS, 419, 2077 [NASA ADS] [CrossRef] [Google Scholar]
- Miglio, A., Brogaard, K., & Handberg, R. 2015, IAU Gen. Assem., 22, 2251619 [NASA ADS] [Google Scholar]
- Mosser, B., Belkacem, K., Goupil, M.-J., et al. 2010, A&A, 517, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Peimbert, M., Luridiana, V., & Peimbert, A. 2007a, ApJ, 666, 636 [NASA ADS] [CrossRef] [Google Scholar]
- Peimbert, M., Luridiana, V., Peimbert, A., & Carigi, L. 2007b, in From Stars to Galaxies: Building the Pieces to Build Up the Universe, eds. A. Vallenari, R. Tantalo, L. Portinari, & A. Moretti, ASP Conf. Ser., 374, 81 [Google Scholar]
- Pinsonneault, M. H., Elsworth, Y., Epstein, C., et al. 2014, ApJS, 215, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Pont, F., & Eyer, L. 2004, MNRAS, 351, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Quirion, P.-O., Christensen-Dalsgaard, J., & Arentoft, T. 2010, ApJ, 725, 2176 [NASA ADS] [CrossRef] [Google Scholar]
- R Core Team 2017, R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing [Google Scholar]
- Robert, C. P., & Casella, G. 2005, Monte Carlo Statistical Methods (Springer Texts in Statistics) (New York: Springer-Verlag New York, Inc.), 645 [Google Scholar]
- Rose, S. J. 2001, J. Quant. Spectr. Rad. Transf., 71, 635 [NASA ADS] [CrossRef] [Google Scholar]
- Salaris, M., & Cassisi, S. 2017, R. Soc. Open Sci., 4, 170192 [NASA ADS] [CrossRef] [Google Scholar]
- Sandquist, E. L., Jessen-Hansen, J., Shetrone, M. D., et al. 2016, ApJ, 831, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Silva Aguirre, V., Casagrande, L., Basu, S., et al. 2012, ApJ, 757, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Snedecor, G., & Cochran, W. 1989, Statistical Methods (Ames, IA: Iowa State University Press), 276, 530 [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [NASA ADS] [CrossRef] [Google Scholar]
- Stancliffe, R. J., Fossati, L., Passy, J.-C., & Schneider, F. R. N. 2015, A&A, 575, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stello, D., Chaplin, W. J., Bruntt, H., et al. 2009, ApJ, 700, 1589 [NASA ADS] [CrossRef] [Google Scholar]
- Stello, D., Huber, D., Sharma, S., et al. 2015, ApJ, 809, L3 [NASA ADS] [CrossRef] [Google Scholar]
- Tayar, J., Somers, G., Pinsonneault, M. H., et al. 2017, ApJ, 840, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Thoul, A. A., Bahcall, J. N., & Loeb, A. 1994, ApJ, 421, 828 [NASA ADS] [CrossRef] [Google Scholar]
- Tognelli, E., Prada Moroni, P. G., & Degl’Innocenti, S. 2011, A&A, 533, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tognelli, E., Prada Moroni, P. G., & Degl’Innocenti, S. 2018, MNRAS, 476, 27 [Google Scholar]
- Ulrich, R. K. 1986, ApJ, 306, L37 [NASA ADS] [CrossRef] [Google Scholar]
- Valle, G., Marconi, M., Degl’Innocenti, S., & Prada Moroni, P. G. 2009, A&A, 507, 1541 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2013, A&A, 549, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2014, A&A, 561, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2015a, A&A, 579, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2015b, A&A, 577, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2015c, A&A, 575, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2016, A&A, 587, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2017, A&A, 600, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valle, G., Dell’Omodarme, M., Prada Moroni, P. G., & Degl’Innocenti, S. 2018, A&A, 615, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valls-Gabaud, D. 2014, EAS Pub. Ser., 65, 225 [Google Scholar]
- Venables, W., & Ripley, B. 2002, Modern Applied Statistics with S, Statistics and Computing (New York: Springer), 495 [CrossRef] [Google Scholar]
- Viani, L. S., Basu, S., Chaplin, W. J., Davies, G. R., & Elsworth, Y. 2017, ApJ, 843, 11 [NASA ADS] [CrossRef] [Google Scholar]
- von Hippel, T., Jefferys, W. H., Scott, J., et al. 2006, ApJ, 645, 1436 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, T., Li, Y., & Hekker, S. 2014, ApJ, 786, 10 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Details on the adopted Monte Carlo Markov chain
The adopted MCMC method starts by establishing a good starting point in the θ space and evaluates the scale over which the likelihood function varies. Such estimates are obtained by randomly sampling 7000 isochrones on the grid, and evaluating their likelihood. This step sets the initial value and the initial guess of the covariance matrix in the θ space for the jump function. Then a burning-in chain of 3000 points is generated in the following way. We use θk to denote the value of the parameters after the step k and Σ the covariance matrix. A proposal point in the θ space is generated adopting a Gaussian jump function with mean θk and covariance Σ
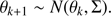
The choice of the jump function is usually critical in preventing the algorithm from being trapped in local minima (see Haario et al. 2001, and Bazot et al. 2012 for an application to α Cen A modelling). In our particular case however the process was facilitated by the artificial objects being sampled from the exact grid adopted in the recovery. Therefore, apart from the random perturbations in the “observables”, we do not have to face systematic discrepancies, that are unavoidable when attempting a fit for real stars. Therefore we found that the simple Gaussian jump function performs well against a mixture of Gaussian distributions with different variances or a mixture of Gaussian and uniform distributions.
We use P(θ)k and P(θ)k + 1 to denote the likelihood of the solutions θk and θk + 1. We define 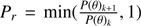 . Then the following chain rule applies:
. Then the following chain rule applies:
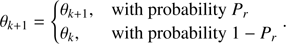
Due to the intrinsic degeneracy among the parameters θ the convergence speed of the chain is known to be sub-optimal (see Haario et al. 2001, and also Kirkby-Kent et al. 2016 for a specific discussion in a detached binary system fit). Therefore after the burning-in phase the covariance matrix of the last 50% of the proposed solutions was adopted to transform the θ variables to θ⊥ orthogonal ones. The step was performed by means of a principal-component analysis (Härdle & Simar 2012; Feigelson & Babu 2012), a statistical technique that computes a set of independent and orthogonal linear combinations θ⊥ of the original θ variables. The chain is then built in the newly computed space, achieving a better convergence speed. At the end the transformation was inverted and the results were remapped in the original θ space.
The burning-in chain is then discarded; the MCMC sampling for the geometrical fitting required the evolution of eight parallel chains of 7000 iterations in length for samples of 35 stars and 21 000 iterations for samples of 80 stars. For the ML approach the burn-in chain length was 9000 points. Indeed the chains from geometrical fitting showed a faster convergence and they are stationary after about one quarter to one half of the adopted length. In fact, the ML posterior density is sparse within the parameter space, implying a greater difficulty of the chain to obtain an accurate map. The lengths of the chains are sufficient to achieve a good convergence and mixing, according to the statistical tests of Gelman–Rubin and Geweke (Gelman & Rubin 1992); Geweke1992.
Appendix B: A toy model for maximum likelihood to geometrical distance comparison
In this section we present a simple toy model to highlight the differences in the geometrical versus ML approaches to the isochrone fitting.
Let us assume that the fictional isochrone can be represented by the arc of parabola, as in Fig. B.1.
 |
Fig. B.1. Toy model adopted for geometrical and ML fit comparison (see text). The dashed line identifies the possible positions of the point Q. |
![$$ \begin{aligned} f(x) = -x^2, \quad \quad x \in [-5,0]. \end{aligned} $$](/articles/aa/full_html/2018/11/aa33928-18/aa33928-18-eq15.gif)
Let Q = ( − 1, yQ) be a point representing an “observation”. Therefore, for yQ = −1, Q lies on the arc of parabola. The squared distance d2 from Q to a point R = (x, f(x)) on the parabola is
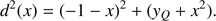
Using 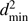 to represent the minimum of d2 over x
to represent the minimum of d2 over x
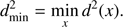
The geometrical fit would compute the likelihood of the arc of parabola given Q as:
Clearly, Lgeo has a maximum for 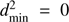 , which occurs for yQ = −1.
, which occurs for yQ = −1.
Differing from the above computation, the ML approach takes into account not only the nearest point but all the other points on the arc of parabola. We use ds(x) to denote the the line element on the arc of parabola around the abscissa x (see Fig. B.1), and assume that the probability of all the points on the parabola are equal. Then the contribution of the point R to the final likelihood is
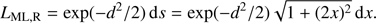
The full likelihood is obtained by integrating Eq. (B.5) over the arc of parabola
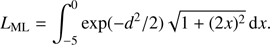
The left panel in Fig. B.2 shows the evolution of Lgeo and LML for different values of yQ. It is apparent that the ML estimates do not reach their maximum value for yQ = −1, when the point Q lies on the arch of parabola, but for a lower value, about yQ = −1.5. In this configuration, thanks to the negative curvature of the arc of parabola, the point at abscissa −1 moves away from Q, but the distance of the neighbourhood region of the arc moves closer to Q thus inducing the discrepancy between the two methods. For real isochrone fitting the problem is obviously complicated by the presence of different classes of isochrones, computed with varying metallicity and initial helium abundance. These parameters modify the shape of the isochrone and contribute in complex ways to the final bias on the estimates.
 |
Fig. B.2. Left panel: likelihood from the pure geometrical method (solid line) and for the ML method (dashed line) when varying the ordinate yQ of the observational data in the toy model (see text). Right panel: ratio of the ML to geometrical variance versus the sample size. |
Another key difference between the fitting methods is that the variance of ML estimates shrinks faster than those of the geometrical method when the sample size increases. This behaviour is caused by the fact that the former technique can exploit a greater amount of information than the latter: the ML approach not only uses the nearest point but also its neighbouring points to differentiate among the isochrones. To simulate how the variances of the two techniques change with sample size we performed a simple exercise. We populate a sample set of observational points simply by considering the same point Q multiple times. The right panel in Fig. B.2 shows the trend of the variance ratio for different sizes of the observational sample. It is apparent that while the two variances are very close for a single observational point, the variance of the ML method shrinks faster and is about three quarters of the variance from the geometrical method for a sample of size about 100.
Appendix C: Random-effect models
Random effect models were adopted in this work for disentangling the variance component owing to observational errors from the residual one (see Sect. 4), and to establish the relevance of different fitting methods, progenitor stars, and Monte Carlo realisations with respect to residual variance (see Sect. 5). We discuss the random effect model approach in the latter case; the adaptation to the former case is straightforward and is given at the end of this section.
As described in Sect. 2 a two-stage approach was adopted in the Monte Carlo simulations. First, N1 artificial systems were generated and subjected to perturbation to account for the observational errors. Second, all these systems were fitted by the algorithms described in Sect. 2.2, which adopts N2 perturbed replicates of each system to evaluate the statistical errors of the estimated parameters.
We use i to denote the method of fit (i = 1, 3), j the progenitor artificial star (j = 1, …, 20), k the Monte Carlo run (k = 1, …, 70), and l the estimates from SCEPtER or MCMC methods (l = 1, …, 500). We use the dependent variable Y to denote the age of the system. A fixed-effect model for the age with respect to the previous variables would be specified as:
where μ is the grand mean, αi are the parameters (to be estimated from the model) for the difference in age among fitting methods, βj the parameters for the difference in age among progenitor stars, γk the parameters for the difference among Monte Carlo replications, and εijkl ∼ N(0, σ2) is the error term. This model corresponds to a classical three-way analysis of variance (ANOVA), and it is appropriate if the individual differences in the age among the exact artificially selected methods, progenitors, and replicates are of interest (see e.g. Snedecor & Cochran 1989; Feigelson & Babu 2012).
However, the studied stars are only a random sample of the possible ones than can be generated by the Monte Carlo procedure. Moreover, the two techniques employed in the analysis are possible choices among several others adopted in the literature. Hence, it is interesting to estimate the variability in the mean age due to the random sampling and fitting methods. This goal is achieved by adopting a random effects model:
where 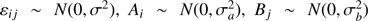 , and
, and  are random variables, the latter three representing the difference between this model and the fixed effect one. The estimates of σ, the residual standard deviation, and σa, σb, and σc, the standard deviation owing to the different source of variability, are the outcome of the model fitting.
are random variables, the latter three representing the difference between this model and the fixed effect one. The estimates of σ, the residual standard deviation, and σa, σb, and σc, the standard deviation owing to the different source of variability, are the outcome of the model fitting.
The fit of the model in Eq. (C.2) was performed using a restricted ML technique adopting the library lme4 in R 3.4.3 (Bates et al. 2015); R. Further details on the method and on its theoretical assumptions can be found in Laird & Ware (1982); Venables & Ripley (2002) and Bates et al. (2015).
For convenience we also report the model adopted for disentangling the variance component owing to observational errors from the residual one.
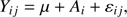
with εij ∼ N(0, σ2) and 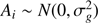 .
.
All Tables
Estimated median (-est.), 16th (σ−), and 84th (σ+) percentiles of the stellar parameters (αml, ΔY/ΔZ, Z, and age) recovered in the twelve considered scenarios.
Mean and standard deviation of the stellar parameters (αml, ΔY/ΔZ, Z, and age) recovered by direct likelihood integration.
Age variance components from random models fit in the twelve considered scenarios (see text).
All Figures
|
Fig. 1. Top row, left: 2D density of probability in the age vs. αml plane from samples of 35 RGB stars (true age of 7.5 Gyr). Parameters are recovered by means of the pure geometrical method (see text). The cross marks the position of the true values, while the filled circle marks the median of the recovered ones. Middle: same as in the left panel, but in the age vs. ΔY/ΔZ plane. Right: as in the left panel, but in the age vs. Z plane. Middle row: as in the top row, but for maximum likelihood recovery. Bottom row: as in the top row, but for SCEPtER individual recovery. For ease of comparison, the corresponding panels in the three subsequent figures (Figs. 2–4) share the same colour key. |
| In the text | |
 |
Fig. 2. As in Fig. 1, but for a true age of 9.0 Gyr. |
| In the text | |
 |
Fig. 3. As in Fig. 1, but for samples of 80 RGB stars. |
| In the text | |
 |
Fig. 4. As in Fig. 3, but for a true age of 9.0 Gyr. |
| In the text | |
|
Fig. 5. Top row, left: 2D density of probability in the age vs. αml plane from samples of 35 RGB stars (true age 7.5 Gyr) from the mean of the SCEPtER fit of individual stars (see text). Right: same as in the left panel but for a true age of 9.0 Gyr. Bottom row: as in the top row, but for samples of 80 RGB stars. |
| In the text | |
|
Fig. 6. Box plot of the age estimates for single RGB star fits from the three adopted methods in the text. |
| In the text | |
|
Fig. B.1. Toy model adopted for geometrical and ML fit comparison (see text). The dashed line identifies the possible positions of the point Q. |
| In the text | |
|
Fig. B.2. Left panel: likelihood from the pure geometrical method (solid line) and for the ML method (dashed line) when varying the ordinate yQ of the observational data in the toy model (see text). Right panel: ratio of the ML to geometrical variance versus the sample size. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.