Fig. 2
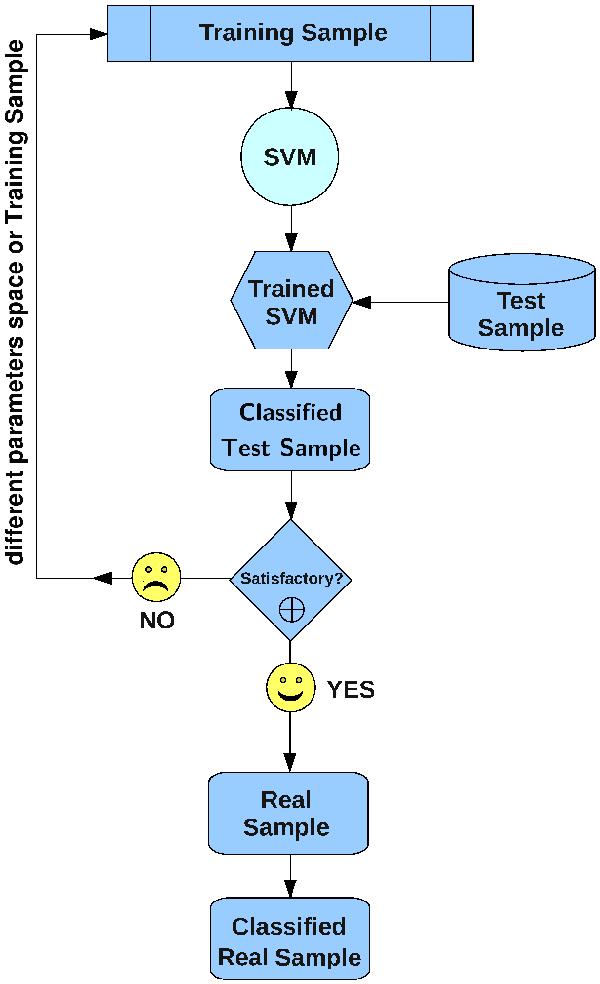
Schematic representation of the SVM algorithm classification process. We take as input the preselected training sample consisting of (in the case of this work) three distinct classes of objects. The SVM is taught how to distinguish one class from the others based on the discriminating properties chosen as feature vectors. Then, the classifier is trained by tuning the free parameters (C and γ). If the result reaches a high enough accuracy rate (the number of objects from the training sample that are correctly recognised by the classifier) without overfitting (the resulting hyperplane does not confine the sources of a specific type too tightly), it will be used to classify the unknown objects (test sample). If the accuracy is not satisfactory, a different parameter space (or training sample, if possible) is chosen to tune C and γ. After a number of iterations, which allow the classifier to reach high enough efficiency level, a real sample can be classified using the discriminant hyperplanes.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.