| Issue |
A&A
Volume 551, March 2013
|
|
|---|---|---|
| Article Number | A88 | |
| Number of page(s) | 5 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201220538 | |
| Published online | 28 February 2013 | |
Research Note
On the assumption of Gaussianity for cosmological two-point statistics and parameter dependent covariance matrices
1 Institute for Astronomy, ETH Zurich, 8093 Zurich, Switzerland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Institute for Astronomy, University of Hawaii, 2680 Woodlawn Dr., Honolulu, HI 96815, USA
Received: 11 October 2012
Accepted: 14 January 2013
Abstract
In this brief paper we revisit the Fisher information content of cosmological power spectra or two-point functions of Gaussian fields in order to comment on the assumption of Gaussian estimators and the use of parameter-dependent covariance matrices for parameter inference in the context of precision cosmology. Even though the assumption of a Gaussian likelihood is motivated by the central limit theorem, we discuss that it leads to Fisher information content that violates the Cramér-Rao bound if used consistently, owing to independent but artificial information from the parameter-dependent covariance matrix. At any fixed multipole, this artificial term is shown to become dominant in the case of a large number of correlated fields. While the distribution of the estimators does indeed tend to a Gaussian with a large number of modes, it is shown, however, that its Fisher information content does not, in the sense that their covariance matrix never carries independent information content, precisely because of the non-Gaussian shape of the distribution. In this light, we discuss the use of parameter-dependent covariance matrices with Gaussian likelihoods for parameter inference from two-point statistics. As a rule of thumb, Gaussian likelihoods should always be used with a covariance matrix fixed in parameter space, since only this guarantees that conservative information content is assigned to the observables, and at the same time, prevents biases appearing.
Key words: cosmology: observations / cosmology: theory / cosmological parameters / methods: statistical
© ESO, 2013
1. Introduction
Starting from the second half of the nineties (Jungman et al. 1996a,b; Tegmark 1997; Tegmark et al. 1997), calculating Fisher information matrices in order to understand the constraining power of an experiment quantitatively has become ubiquitous in cosmology, with its fundamental aspects now covered in cosmological textbooks (e.g. Dodelson 2003; Durrer 2008, Sects. 11 and 6 respectively), or (Heavens 2009). This is especially true for experiments aimed at measuring the power spectra of fields that are close to Gaussian fields, since in this case very handy analytical expressions can be obtained that can be applied in a variety of major cosmological subfields, such as the CMB, galaxy clustering, weak lensing, or their combination.
Nevertheless, even when applied to Gaussian variables, Fisher information matrices are not totally exempt from subtleties. We revisit the two different possible perspectives on the Fisher information content of such spectra. One starting point is often the assumption of Gaussian errors. We point out that this assumption of a multivariate Gaussian likelihood for power spectra estimators is not fully consistent with the purpose of understanding their information content, owing to a term violating the Cramér-Rao inequality, which we show is not necessarily small. Too much information is therefore assigned to the spectra under this assumption. We show that we can understand why this term is artificial precisely from the non Gaussian properties of the estimators, and discuss the reasons the usual formula, i.e. without this term, or with setting the covariance matrix to be parameter independent, still gives the correct amount of information. Our considerations apply indifferently to the spectra or the real space two-point correlation function. Namely, since the correlation function and the power spectrum are linearly related, the assumption of Gaussian power spectra is equivalent to assuming Gaussian two-point functions. We then comment on the role of the model parameter dependence of the covariance matrix within the Gaussian approximation, as studied in Eifler et al. (2009) and Labatie et al. (2012).
In Sect. 2 the two common approaches to the information content of spectra are discussed in detail in the case of a single field. We clarify to what extent and why one is actually flawed, which is the source our comments on the use of Gaussian likelihoods and parameter-dependent covariances. In Sect. 3 we then turn to a correlated family of fields, where the violation of the Cramér-Rao inequality is shown to become substantial. We summarize and conclude in Sect. 4.
We recall first the specific form of the Fisher information matrix, defined for a probability density function p as Fαβ = ⟨∂αlnp∂βlnp ⟩ ,α,β model parameters of interest, in the particular case of a multivariate Gaussian distribution with mean vector μ and covariance matrix Σ (Vogeley & Szalay 1996; Tegmark et al. 1997) 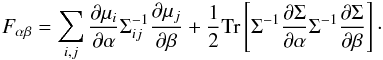 (1)Remember that the Fisher information matrix has all the properties that a meaningful measure of information on parameters must have, most importantly for us here that any transformation of the data can only decrease its Fisher information matrix, regardless of the data distribution and parameter posterior. Thus, the Fisher information of the distribution of any estimator can only be lower than or equal to that of the data it is applied to.
(1)Remember that the Fisher information matrix has all the properties that a meaningful measure of information on parameters must have, most importantly for us here that any transformation of the data can only decrease its Fisher information matrix, regardless of the data distribution and parameter posterior. Thus, the Fisher information of the distribution of any estimator can only be lower than or equal to that of the data it is applied to.
2. One field, gamma distribution
Consider a zero mean isotropic homogeneous Gaussian random field, in euclidean space or on the sphere. It is well known that the Gaussianity of the field is equivalent to the fact that the Fourier or spherical harmonic coefficients are independent complex Gaussian variables, which are only constrained by the reality condition. Another equivalent description is that the real and imaginary parts of those coefficients form independent, real Gaussian variables. Such fields are described entirely by their spectrum, and so the extraction of the spectrum from the data with the help of an estimator is a fairly natural way to proceed for inference on parameters of interest. We place ourselves on the sphere, adopting the spherical harmonic notation for convenience. With the set of alm the harmonic coefficients, the parameter-dependent spectrum Cl is defined as 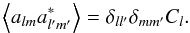 (2)Standard, unbiased quadratic estimators can be written as a sum over the number of Gaussian modes available, as
(2)Standard, unbiased quadratic estimators can be written as a sum over the number of Gaussian modes available, as 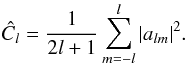 (3)We do not consider any source of observational noise, incomplete coverage, or any other such issue, because they are irrelevant for the points of our discussion.
(3)We do not consider any source of observational noise, incomplete coverage, or any other such issue, because they are irrelevant for the points of our discussion.
At this point, there are two ways to approach the problem of evaluating the amount of information contained within the spectrum in the cosmological literature. The first – we call this approach the “field perspective” – calculates the information content of the field itself (equal to that of the set of alm’s), and then interprets this information as being the information within the spectrum. In this case, the information in the field is given by formula (1), with zero mean vector and diagonal covariance matrix Cl: 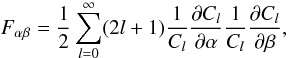 (4)where the factor 2l + 1 accounts for the number of independent Gaussian variables at a given multipole l. The sum is in practice restricted to the multipole range that will actually be measured to obtain the information in the spectrum to be extracted. A very small sample of works using this approach are Tegmark et al. (1997), Hu & Jain (2004), and Bernstein (2009). This approach is conceptually appealing, because it deals with the information content of the field itself and does not require either defining estimators or calculating their covariance. However, for the same reasons, it is only indirectly connected to data analysis since it is not yet specified precisely how this information content is to be extracted.
(4)where the factor 2l + 1 accounts for the number of independent Gaussian variables at a given multipole l. The sum is in practice restricted to the multipole range that will actually be measured to obtain the information in the spectrum to be extracted. A very small sample of works using this approach are Tegmark et al. (1997), Hu & Jain (2004), and Bernstein (2009). This approach is conceptually appealing, because it deals with the information content of the field itself and does not require either defining estimators or calculating their covariance. However, for the same reasons, it is only indirectly connected to data analysis since it is not yet specified precisely how this information content is to be extracted.
In the second approach – which we call the “estimator perspective” – an estimator Ĉl is defined first for each Cl to be extracted, within some lmin and lmax (maybe with some bandwidth that we will not consider here), and its covariance matrix Σll′ = ⟨ĈlĈl′⟩ − ⟨Ĉl ⟩ ⟨Ĉl′⟩ is calculated. Then it is argued that owing to the central limit theorem, the distribution of the estimator will be approximately Gaussian. In the case of the spectra of Gaussian fields, this is very well founded, at least for large l, since (3)is a large sum of well-behaved, identically distributed, independent variables. Then, under this assumption of Gaussianity, their information content is given by Eq. (1)with the mean vector this time the set of Cl itself and (parameter-dependent) covariance matrix Σll′, 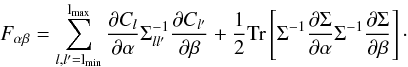 (5)It is well known that we have
(5)It is well known that we have 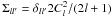 for the estimator (3). The Fisher information matrix, in the estimator perspective, thus reduces to
for the estimator (3). The Fisher information matrix, in the estimator perspective, thus reduces to 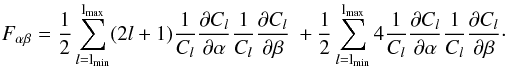 (6)Clearly, the first term in the estimator perspective corresponds to that of the field perspective. However, the second term, which comes from the derivative of the covariance matrix, is new. That term is not enhanced by a (2l + 1) factor, and is therefore very subdominant at high l. It is either usually neglected, or the covariance matrix of the estimators is inconsistently taken to be parameter-independent, and in these cases the two approaches give the same results. Some expositions that explicitly use this perspective include Tegmark (1997) and Seo & Eisenstein (2003, 2007), where the additional term is neglected, or the approach in (Dodelson 2003, Sect. 11.4.3) where the covariance matrix is treated as parameter-independent. Works where this term plays the main role are Eifler et al. (2009) and Labatie et al. (2012), where the authors specifically study the impact of parameter dependent covariance matrices for parameter estimation using these Gaussian likelihoods.
(6)Clearly, the first term in the estimator perspective corresponds to that of the field perspective. However, the second term, which comes from the derivative of the covariance matrix, is new. That term is not enhanced by a (2l + 1) factor, and is therefore very subdominant at high l. It is either usually neglected, or the covariance matrix of the estimators is inconsistently taken to be parameter-independent, and in these cases the two approaches give the same results. Some expositions that explicitly use this perspective include Tegmark (1997) and Seo & Eisenstein (2003, 2007), where the additional term is neglected, or the approach in (Dodelson 2003, Sect. 11.4.3) where the covariance matrix is treated as parameter-independent. Works where this term plays the main role are Eifler et al. (2009) and Labatie et al. (2012), where the authors specifically study the impact of parameter dependent covariance matrices for parameter estimation using these Gaussian likelihoods.
Beyond the question of the quantitative relevance of this additional term, its very appearance is, however, very disturbing. Under this arguably reasonable Gaussian assumption, our estimator (3)is found to carry more information than the full field, even on the smallest scales. This obviously violates the most fundamental property of Fisher information, i.e. that information can only be conserved at best when transforming the data (in this case reducing the field to its spectrum), a fact essentially equivalent to the celebrated Cramér-Rao inequality (Tegmark et al. 1997). Something must clearly have gone wrong in the assumption of a Gaussian likelihood for our spectra.
To understand what has happened, it is worth tracking the exact distribution and information content of the estimator (3). Since they are independent at different l, we can work at a fixed l, and the total information content of these estimators will simply be the sum over l of the information of the estimator at fixed l. Under our assumptions, the estimator is a sum of squares of 2l + 1 independent Gaussian variables, and its probability density function can be obtained with no difficulty. The exact distribution is the gamma probability density function with shape parameter k and location parameter θ: 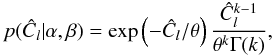 (7)with
(7)with 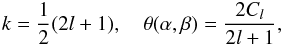 (8)and where Γ is the gamma function. It is well known that the gamma distribution does indeed tend towards the Gaussian distribution for large k, with mean μ = kθ = Cl and variance
(8)and where Γ is the gamma function. It is well known that the gamma distribution does indeed tend towards the Gaussian distribution for large k, with mean μ = kθ = Cl and variance 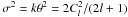 , as expected. However, its Fisher information content does not tend to that of the Gaussian. In our case, since only θ is parameter dependent, we find that the Fisher information in the estimator density function (7)is
, as expected. However, its Fisher information content does not tend to that of the Gaussian. In our case, since only θ is parameter dependent, we find that the Fisher information in the estimator density function (7)is 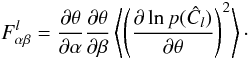 (9)Since ∂θlnp = (Ĉl − kθ)/θ2, and ∂αθ = 2θ∂αCl/Cl, we obtain with straightforward algebra
(9)Since ∂θlnp = (Ĉl − kθ)/θ2, and ∂αθ = 2θ∂αCl/Cl, we obtain with straightforward algebra 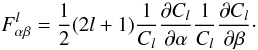 (10)Summing over l, we recover the first term of (6), but not the second. We have recovered the field perspective result (4)at any l without the Gaussian assumption but with the exact distribution. It turns out that even though the variance of the gamma distribution is parameter-dependent, it does not in fact contribute to the information. This can be seen as the following. Consider the information in the mean only of the estimator. From the Cramér-Rao inequality this must be less than the total information,
(10)Summing over l, we recover the first term of (6), but not the second. We have recovered the field perspective result (4)at any l without the Gaussian assumption but with the exact distribution. It turns out that even though the variance of the gamma distribution is parameter-dependent, it does not in fact contribute to the information. This can be seen as the following. Consider the information in the mean only of the estimator. From the Cramér-Rao inequality this must be less than the total information, 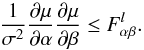 (11)Plugging in the values for the mean and variance actually leads to the result that the inequality is an equality, so that the mean of the estimator captures all of its information.
(11)Plugging in the values for the mean and variance actually leads to the result that the inequality is an equality, so that the mean of the estimator captures all of its information.
In summary, the Gaussian approximation assumes the mean and the variance of the estimator are uncorrelated, such that both contribute to the information, while for the exact gamma, they are degenerate in such a way that the variance does not carry independent information. Another way to see this, which we will use below when the exact form of the distribution is less convenient, comes from the fact that ∂θlnp(Ĉl) is a first-order polynomial in Ĉl. It can be shown that the first n moments capture all the information precisely when ∂αlnp is a polynomial of order n (Carron 2011).
That this function ∂θlnp(Ĉl) is correctly reproduced by the Gaussian assumption with variance treated as fixed in parameter space has another interesting consequence that is relevant to cosmological parameter inference. Namely, performing parameter inference under that assumption does not shift maximum likelihood points ∂θlnp(Ĉl) = 0, since this function is identical to that of the true likelihood (7). Therefore, no bias is introduced. This is no longer true if the variance is treated as parameter-dependent, where it is not difficult to see that the peak of the likelihood gets shifted by some amount decaying with l.
3. Several fields
It is instructive to see how these considerations generalize to a situation of a family of n jointly zero mean Gaussian correlated fields, where the analysis proceeds through the extraction of the spectra and cross spectra. In this case, the Cl of the above discussion becomes an n × n (possibly complex) Hermitian matrix 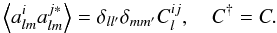 (12)From the hermiticity property, there are only n(n + 1)/2 nonredundant spectra. Adequate estimators are defined by a straightforward generalization of Eq. (3),
(12)From the hermiticity property, there are only n(n + 1)/2 nonredundant spectra. Adequate estimators are defined by a straightforward generalization of Eq. (3), 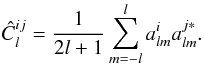 (13)While the estimators are still independent for different l’s, the different components at a given l are not. The information content of the set of
(13)While the estimators are still independent for different l’s, the different components at a given l are not. The information content of the set of 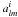 in the field perspective is still given by formula (1)for zero mean Gaussian variables. Explicitly, at a given l,
in the field perspective is still given by formula (1)for zero mean Gaussian variables. Explicitly, at a given l, 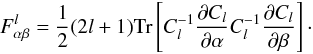 (14)In the estimator perspective, assuming the estimators
(14)In the estimator perspective, assuming the estimators 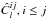 are jointly Gaussian, we instead have
are jointly Gaussian, we instead have 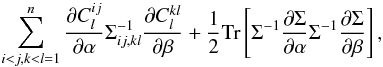 (15)where the covariance matrix is
(15)where the covariance matrix is 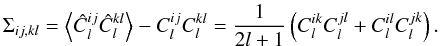 (16)While it may not be immediately obvious this time, it has been noted (e.g. Hu & Jain 2004) that the first term in (15)is rigorously equivalent to the expression from the field perspective (14). The estimator perspective under the assumption of a multivariate Gaussian distribution for Ĉl thus still violates the Cramér-Rao inequality due the presence of the second term. Since this term is not enhanced by a factor of 2l + 1 we expect it to be subdominant again. However, it is less true this time than in the one-dimensional setting: using the explicit form of the inverse covariance matrix,
(16)While it may not be immediately obvious this time, it has been noted (e.g. Hu & Jain 2004) that the first term in (15)is rigorously equivalent to the expression from the field perspective (14). The estimator perspective under the assumption of a multivariate Gaussian distribution for Ĉl thus still violates the Cramér-Rao inequality due the presence of the second term. Since this term is not enhanced by a factor of 2l + 1 we expect it to be subdominant again. However, it is less true this time than in the one-dimensional setting: using the explicit form of the inverse covariance matrix, 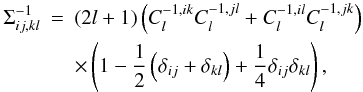 (17)one can derive, with some lengthy but straightforward algebra, the following expression for the violating term,
(17)one can derive, with some lengthy but straightforward algebra, the following expression for the violating term, 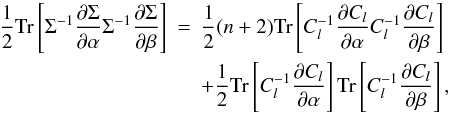 (18)for any number n of fields. If n = 1, we indeed recover (6). While the term is still subdominant at high l, the situation is still a bit less comfortable. The number of fields is not necessarily very small in cosmologically relevant situations, such as tomographic joint shear and galaxy densities analysis in redshift slices, to which one may also add magnification, flexion fields, etc. Writing schematically n = NfNbin, where Nbin is the number of bins and Nf the number of fields per bin, we have, e.g., Nf = 3 for the galaxy density and the two shear fields, Nf = 4 including magnification, Nf = 8 adding hypothetically the four flexion fields, and so on. Comparing (14) and (18), and neglecting the second term in (18), we find that, at
(18)for any number n of fields. If n = 1, we indeed recover (6). While the term is still subdominant at high l, the situation is still a bit less comfortable. The number of fields is not necessarily very small in cosmologically relevant situations, such as tomographic joint shear and galaxy densities analysis in redshift slices, to which one may also add magnification, flexion fields, etc. Writing schematically n = NfNbin, where Nbin is the number of bins and Nf the number of fields per bin, we have, e.g., Nf = 3 for the galaxy density and the two shear fields, Nf = 4 including magnification, Nf = 8 adding hypothetically the four flexion fields, and so on. Comparing (14) and (18), and neglecting the second term in (18), we find that, at 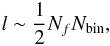 (19)the Cramér-Rao violating term is actually still the dominant one. This is still optimistic. Due to the product of two traces in the second term in (18), one can expect roughly the same scaling with n as the first term. Thus, the correct l in (19)may generically be closer to
(19)the Cramér-Rao violating term is actually still the dominant one. This is still optimistic. Due to the product of two traces in the second term in (18), one can expect roughly the same scaling with n as the first term. Thus, the correct l in (19)may generically be closer to 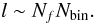 (20)From the discussion in Sect. 2, we can easily guess what went wrong. Consider the information content of the means of the estimators exclusively. This is given for any probability density function by weighting the derivatives of the means with the inverse covariance matrix, and is thus equal to the first term in (15). Since already the means of the estimators do exhaust the information in the field, we can therefore already conclude that the total information content of the estimators must be equal to that of their means. In particular, the covariance matrix does not contribute to the information. As before, the second term in the estimator perspective is an artifact of the Gaussian assumption. It is interesting though to derive as above more explicitly why only the means carry information, from the shape of the joint probability density of the estimators. The remainder of this section sketches how this can be simply performed, leading to Eq. (26).
(20)From the discussion in Sect. 2, we can easily guess what went wrong. Consider the information content of the means of the estimators exclusively. This is given for any probability density function by weighting the derivatives of the means with the inverse covariance matrix, and is thus equal to the first term in (15). Since already the means of the estimators do exhaust the information in the field, we can therefore already conclude that the total information content of the estimators must be equal to that of their means. In particular, the covariance matrix does not contribute to the information. As before, the second term in the estimator perspective is an artifact of the Gaussian assumption. It is interesting though to derive as above more explicitly why only the means carry information, from the shape of the joint probability density of the estimators. The remainder of this section sketches how this can be simply performed, leading to Eq. (26).
For the sake of notation we restrict ourselves now to the case of two fields, n = 2, but the following argumentation holds for any n. The exact joint distribution for the three estimators 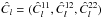 , is given from the rules of probability theory as
, is given from the rules of probability theory as 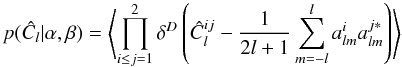 (21)where δD is the Dirac delta function. The average is over the joint probability density for the two sets of harmonic coefficients
(21)where δD is the Dirac delta function. The average is over the joint probability density for the two sets of harmonic coefficients 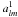 and
and 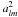 . Define the vector
. Define the vector 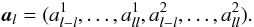 (22)Since the alm are zero mean Gaussian variables with correlations as given in (12), this probability density function is given by
(22)Since the alm are zero mean Gaussian variables with correlations as given in (12), this probability density function is given by 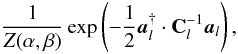 (23)with
(23)with 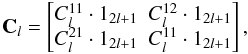 (24)where 12l + 1 is the unit matrix of size 2l + 1, and Z(α,β) is the normalization of the density for a, which does depend on the model parameters through the determinant of the Cl matrix. The inverse matrix
(24)where 12l + 1 is the unit matrix of size 2l + 1, and Z(α,β) is the normalization of the density for a, which does depend on the model parameters through the determinant of the Cl matrix. The inverse matrix 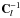 has the same block structure, with entries those of
has the same block structure, with entries those of 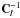 . In the following we are not really interested in keeping track of the exact value of the components of this matrix, but only that they are dependent on the model parameters. With the understanding that
. In the following we are not really interested in keeping track of the exact value of the components of this matrix, but only that they are dependent on the model parameters. With the understanding that 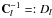 , we have thus, due to the sparse structure of the
, we have thus, due to the sparse structure of the 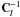 matrix and the Dirac delta functions in (21),
matrix and the Dirac delta functions in (21), 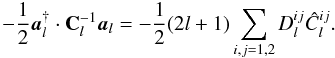 (25)The presence of the Dirac delta functions means we can take the exponential (23)out of the integral in (21). Writing the dependency of the different terms on Ĉl on the model parameters explicitly, we obtain the following form
(25)The presence of the Dirac delta functions means we can take the exponential (23)out of the integral in (21). Writing the dependency of the different terms on Ĉl on the model parameters explicitly, we obtain the following form 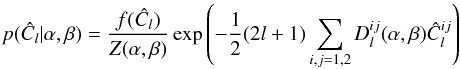 (26)which generalizes the gamma distribution, Eq. (7), in this multidimensional case. The factor f(Ĉl) is what is left from the integral (21)when the density for the set of alm is taken out, i.e., the volume of the space spanned by the alm that satisfies the constraints set by the Dirac delta function. It is thus a factor that depends on Ĉl but – important for us – not on the model parameters1. The point of the representation (26)is that it is immediately apparent that ∂αlnp(Ĉl) is a polynomial first order in the components of Ĉl. Second-order terms, which correspond to information within the covariance matrix, never appear, even though the exact density function becomes very close to Gaussian for large l. It follows that the total Fisher information matrix is always equal to that of the mean, even if we did not derive the exact shape of the distribution.
(26)which generalizes the gamma distribution, Eq. (7), in this multidimensional case. The factor f(Ĉl) is what is left from the integral (21)when the density for the set of alm is taken out, i.e., the volume of the space spanned by the alm that satisfies the constraints set by the Dirac delta function. It is thus a factor that depends on Ĉl but – important for us – not on the model parameters1. The point of the representation (26)is that it is immediately apparent that ∂αlnp(Ĉl) is a polynomial first order in the components of Ĉl. Second-order terms, which correspond to information within the covariance matrix, never appear, even though the exact density function becomes very close to Gaussian for large l. It follows that the total Fisher information matrix is always equal to that of the mean, even if we did not derive the exact shape of the distribution.
4. Summary and conclusions
We discussed two common perspectives (the “field” and “estimator” perspectives) on the Fisher information content of cosmological power spectra and the reason the assumption of a Gaussian likelihood of the spectra estimators violates the Cramér-Rao inequality, by assigning the estimators more information than there is in the full underlying fields. Under the assumption of Gaussianity of the estimators, their means and covariance matrix are artificially rendered uncorrelated, creating an additional piece of information in their covariance, which we showed was inexistent by calculating the exact information content of the estimators’ true probability density function. We showed that this violating term can become dominant in the limit of a large number of fields. Using Gaussian likelihoods consistently, i.e. with parameter-dependent covariance matrices as studied for example in Eifler et al. (2009) and Labatie et al. (2012), therefore assigns far too much information to the spectra in this regime, and should thus be avoided, as this allows tighter but artificial constraints on the parameters and can introduce biases as well. A slight tightening of the constraints on parameters and tiny shifts in the parameters posterior maximum are indeed observed in these works. It is thus important to realize that these two effects do not reflect improvements over the method of treating the covariance matrix fixed, but should be considered spurious.
In the estimator perspective when deriving the Fisher information matrix, the piece of information coming from the covariance matrix is usually neglected. This paper clarified why it should not be present in the very first place and how the agreement between the field and estimator perspective can thus arguably be seen as a happy cancellation of two inconsistencies. It is interesting to note that the reason we still find the exact result in the estimator perspective without this wrong piece is that this expression is also the exact Fisher information content of the exact distribution of the estimators, which is strongly non-Gaussian for low l, the central limit theorem actually playing no role.
The other lesson we can take from this work is that when in doubt about the joint distribution of a set of estimators, a safe choice of information content is always that of their means, which only requires knowledge of their covariance. Provided the covariance matrix is correctly chosen, one is indeed certain, from the properties of Fisher information, to make a conservative evaluation for any probability density function that does not rely on any further assumptions on its shape. Thus, leaving aside the question of the accuracy and consistency of the approximation itself, the use of a Gaussian likelihood with a parameter-independent covariance matrix, which has all of its information in the mean vector, remains a safe prescription in the sense that conservative information content is always assigned to the estimators.
Interestingly, the choice of a Gaussian distribution becomes motivated in this case not by the central limit theorem, but by conservative information content being assigned to the observables. From the Cramér-Rao bound, the constraints on the parameters using this assumption cannot be tighter than the ones allowed by the true distribution. It is, however, essential in this respect that the covariance matrix is treated as fixed in parameter space. This holds true for any observables extracted from an arbitrary field distribution.
The prefactors in (26)can be obtained in closed form, leading to the Wishart density function. See, e.g. Hamimeche & Lewis (2008).
Acknowledgments
I wish to thank Cosimo Fedeli, Alexandre Réfrégier, Marc Kamionkowski and Istvan Szapudi, and to acknowledge the Swiss National Science Foundation, as well as NASA grants NNX12AF83G and NNX10AD53G for support.
References
- Bernstein, G. M. 2009, ApJ, 695, 652 [NASA ADS] [CrossRef] [Google Scholar]
- Carron, J. 2011, ApJ, 738, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Dodelson, S. 2003, Modern cosmology (Academic Press) [Google Scholar]
- Durrer, R. 2008, The Cosmic Microwave Background (Cambridge University Press) [Google Scholar]
- Eifler, T., Schneider, P., & Hartlap, J. 2009, A&A, 502, 721 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamimeche, S., & Lewis, A. 2008, Phys. Rev. D, 77, 103013 [NASA ADS] [CrossRef] [Google Scholar]
- Heavens, A. 2009, in Data Analysis in Cosmology, eds. V. J. Martínez, E. Saar, E. Martínez-González, & M.-J. Pons-Bordería (Berlin Springer Verlag), Lect. Not. Phys., 665, 51 [Google Scholar]
- Hu, W., & Jain, B. 2004, Phys. Rev. D, 70, 043009 [NASA ADS] [CrossRef] [Google Scholar]
- Jungman, G., Kamionkowski, M., Kosowsky, A., & Spergel, D. N. 1996a, Phys. Rev. D, 54, 1332 [NASA ADS] [CrossRef] [Google Scholar]
- Jungman, G., Kamionkowski, M., Kosowsky, A., & Spergel, D. N. 1996b, Phys. Rev. Lett., 76, 1007 [NASA ADS] [CrossRef] [Google Scholar]
- Labatie, A., Starck, J. L., & Lachièze-Rey, M. 2012, ApJ, 760, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Seo, H.-J., & Eisenstein, D. J. 2003, ApJ, 598, 720 [NASA ADS] [CrossRef] [Google Scholar]
- Seo, H.-J., & Eisenstein, D. J. 2007, ApJ, 665, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Tegmark, M. 1997, Phys. Rev. Lett., 79, 3806 [NASA ADS] [CrossRef] [Google Scholar]
- Tegmark, M., Taylor, A. N., & Heavens, A. F. 1997, ApJ, 480, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Vogeley, M. S., & Szalay, A. S. 1996, ApJ, 465, 34 [NASA ADS] [CrossRef] [Google Scholar]
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.