Fig. 2
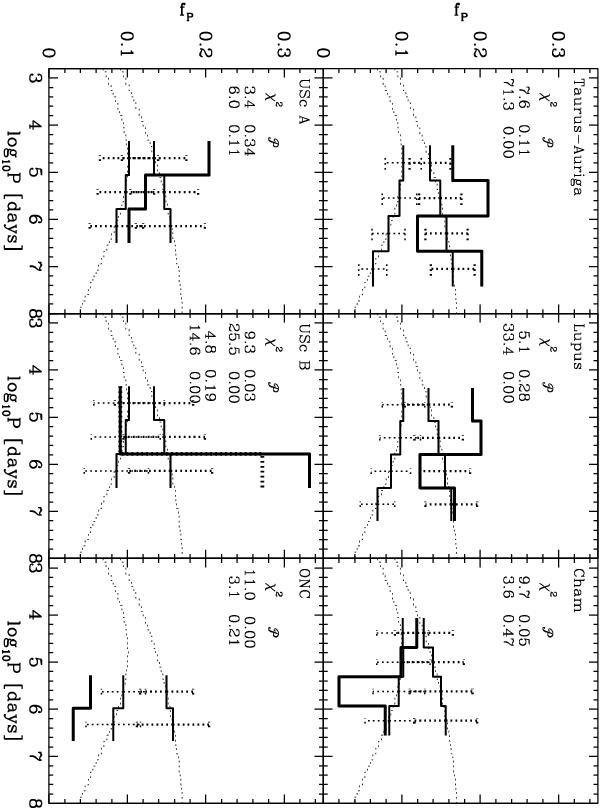
Similar to Fig. 1 but for all pre-main sequence samples. In all panels, the dotted continuous curves are the model distributions (K1 IPF upper curves, DM PDPF lower curves), whereas the model histograms are shown as solid lines with expected binomial uncertainties as dotted error-bars. Thick histograms are the data (Sect. 2). The χ2 value and probability, 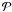 , of observing such a large or larger χ2 is written in each panel (upper numbers for testing the data against the K1 IPF, lower numbers for testing against the DM IPF). For UScB, the lower set of numbers refers to the dotted histogram, which corresponds to the results after removing the three widest binaries from the sample.
, of observing such a large or larger χ2 is written in each panel (upper numbers for testing the data against the K1 IPF, lower numbers for testing against the DM IPF). For UScB, the lower set of numbers refers to the dotted histogram, which corresponds to the results after removing the three widest binaries from the sample.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.