| Issue |
A&A
Volume 505, Number 1, October I 2009
|
|
|---|---|---|
| Page(s) | 385 - 404 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/200912041 | |
| Published online | 16 July 2009 | |
The large quasar reference frame (LQRF)
An optical representation of the ICRS
A. H. Andrei1,2,3 - J. Souchay3 - N. Zacharias4 - R. L. Smart5 - R. Vieira Martins1,2 - D. N. da Silva Neto2,6 - J. I. B. Camargo2 - M. Assafin2 - C. Barache3 - S. Bouquillon3 - J. L. Penna1 - F. Taris3
1 - Observatório Nacional/MCT, R. Gal. José Cristino 77, CEP20921-400, RJ, Brasil
2 -
Observatório do Valongo/UFRJ, Ladeira Pedro Antônio 43, CEP20080-090, RJ, Brasil
3 -
Observatoire de Paris/SYRTE, 61 Avenue de l'Observatoire, 75014 Paris, France
4 -
US Naval Observatory, 3450 Massachusetts Av. NW, Washington, DC 20392, USA
5 -
INAF/Osservatório Astronomico di Torino, Strada Osservatório 20, 10025 Pino Torinese, Italy
6 -
Centro Universitário Estadual da Zona Oeste, Av. Manuel Caldeira de Alvarenga 1203, CEP23070-200, RJ, Brasil
Received 12 March 2009 / Accepted 20 May 2009
Abstract
Context. The large number and all-sky distribution of quasars from different surveys, along with their presence in large, deep astrometric catalogs, enables us to build of an optical materialization of the International Celestial Reference System (ICRS) following its defining principles. Namely: that it is kinematically non-rotating with respect to the ensemble of distant extragalactic objects; aligned with the mean equator and dynamical equinox of J2000; and realized by a list of adopted coordinates of extragalatic sources.
Aims. The Large Quasar Reference Frame (LQRF) was built with the care of avoiding incorrect matches of its constituents quasars, homogenizing the astrometry from the different catalogs and lists in which the constituent quasars are gathered, and attaining a milli-arcsec global alignment with the International Celestial Reference Frame (ICRF), as well as typical individual source position accuracies higher than 100 milli-arcsec![]() .
.
Methods. Starting from the updated and presumably complete Large Quasar Astrometric Catalog (LQAC) list of QSOs, the initial optical positions of those quasars are found in the USNO B1.0 and GSC2.3 catalogs, and from the SDSS Data Release 5. The initial positions are next placed onto UCAC2-based reference frames, This is followed by an alignment with the ICRF, to which were added the most precise sources from the VLBA calibrator list and the VLA calibrator list - when reliable optical counterparts exist. Finally, the LQRF axes are inspected through spherical harmonics, to define right ascension, declination and magnitude terms.
Results. The LQRF contains 100,165 quasars, well represented accross the sky, from -83.5 to +88.5![]() in declination, being 10 arcmin the average distance between adjacent elements. The global alignment with the ICRF is 1.5 mas, and the individual position accuracies are represented by a Poisson distribution that peaks at 139 mas in right ascension and 130 mas in declination. As a by-product, significant equatorial corrections are found for all the catalogs used (apart from the SDSS DR5), an empirical magnitude correction can be discussed for the GSC2.3 intermediate and faint regimes, both the 2MASS and the preliminary northernmost UCAC2 positions are shown of astrometry consistent with the UCAC2 main catalog, and the harmonic terms are found to be always small.
in declination, being 10 arcmin the average distance between adjacent elements. The global alignment with the ICRF is 1.5 mas, and the individual position accuracies are represented by a Poisson distribution that peaks at 139 mas in right ascension and 130 mas in declination. As a by-product, significant equatorial corrections are found for all the catalogs used (apart from the SDSS DR5), an empirical magnitude correction can be discussed for the GSC2.3 intermediate and faint regimes, both the 2MASS and the preliminary northernmost UCAC2 positions are shown of astrometry consistent with the UCAC2 main catalog, and the harmonic terms are found to be always small.
Conclusions. The LQRF contains J2000 referred equatorial coordinates, and is complemented by redshift and photometry information from the LQAC. It is designed to be an astrometric frame, but it is also the basis for the GAIA mission initial quasars' list, and can be used as a test bench for quasars' space distribution and luminosity function studies. The LQRF is meant to be updated when new quasar identifications and newer versions of the astrometric frames used are realized. In the later case, it can itself be used to examine the relations between those frames.
Key words: catalogs - reference systems - quasars: general - methods: data analysis - astrometry
1 Introduction
The establishment of the ICRS as the celestial reference system (Arias et al. 1995; Feissel & Mignard 1998) answers not only the desiderata in terms of the choice of the physical model and coherence, but also of practicality when confronted with the earlier dynamical model. This is especially true since the system is materialized by the direction of quasi-inertial grid points, which are given by distant, extragalactic sources, instead of nearby, moving stars. However, for a long time after the establishment of the ICRS, the faintness of the extragalactic sources prevented a precise determination of optical positions for a large number of them. The VLBI radio technique answered this need, by providing precise positions. However, such precise positions could only be derived for a limited number of strong and stable sources, and the ones with richer observational history have come to define the ICRF (Ma et al. 1998). Yet even this small number of sources enabled the VLBI to make important contributions in defining both geophysics and radio astronomy standards.
In contrast, for extragalactic sources on the optical domain, poor astrometry and a small number of known sources made with which the standard representation of the ICRF were assigned to the stellar catalog Hipparcos (Perryman et al. 1997). Currently several extensions of the Hipparcos Catalog Reference Frame (HCRF), densify this representation, reaching fainter magnitudes.
The quantity of optically recognized bright quasars has increased significantly in recent years, along with an improvement of the evenness of their sky distribution (Véron-Cetty & Véron 2006; Souchay et al. 2008a,b). At the same time, the science's demands for accurate astrometry of these objects have also increased. Examples include micro and macro lensing, binaries, and space density counts, as well as the requirements of space astronomy missions (Andrei et al. 2008) and the very improvement of the stellar catalogs, that requires for a dense mesh of fiducial points (Fienga & Andrei 2002, 2004).
Therefore, we combine the large number of quasars optically recognized, with the large, precise optical catalogs to produce an optical materialization of the ICRS in terms of its first principles, namely kinematically non-rotating with respect to the ensemble of distant extragalactic objects, aligned with the mean equator and dynamical equinox of J2000, and realized by a list of adopted coordinates of extragalatic sources. This article presents one such realization, hereafter termed Large Quasar Reference Frame (LQRF).
In the next section, the input data is presented and reviewed, whereas in its final subsection a schematic of the data stream is presented. The data stream is detailed in Sects. 3-5, where the analytical expressions used to derive the catalog's intermediary steps are shown. In Sect. 3, a local astrometric solution is employed to place all quasar input catalogs onto the UCAC reference frame. In Sect. 4, the positions derived in this way are aligned with the ICRF frame. In Sect. 5, local inhomogeneities are tackled by spherical harmonics fitting and local average redressing. The LQRF catalog is presented in Sect. 6, and a summary and follow-up perspectives are presented in the last section.
2 Input data and data flow
The LQRF is built from gathering, comparison, and adjustment of positions of quasars and their stellar neighborhood, extracted from several catalogs and lists. A brief summary of their content is presented in the following subsections. The role of each one is also mentioned, for the sake of introducing the general flow of the data treatment. The final subsection outlines the data flow, leaving the details for the subsequent main sections.
2.1 LQAC
The Large Quasar Astrometric catalog (Souchay et al. 2008a,b), hereafter LQAC, compiles the detections of 113 653 quasars from the original entries of the eight largest lists, with a surplus extracted from the latest edition of the Véron & Véron catalog (Véron-Cetty & Véron 2006) after an analysis on the reliability of the input contributors. The LQAC contains extensive information on the physical properties of each object. It contains, in particular, whenever available, the redshift, the magnitudes of the objects in 9 different optical bands (u, b, v, g, r, i, z, J, and K), and the radio fluxes at 5 different frequencies (1.4 Ghz, 2.3 Ghz, 5.0 Ghz, 8.4 Ghz, and 24 Ghz). The position of each object is given by the most precise equatorial coordinate directly available from the input lists. Therefore, the precision is quite variable, ranging from sub-milli-arcsec for VLBI determinations to a tenth of arcsec for optical determinations, and nearly one arcsec for single dish determinations, On the other hand, there are no double entries, either from misrecognition or from double radio spots. Although the position unevenness prevents them from characterizing an astrometric reference frame, the LQAC positions and magnitudes are adopted as the starting point for finding the objects in the dense optical catalogs presented next. Figure 1 presents the LQAC sky distribution and sky density.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig01.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img6.png) |
Figure 1:
Sky distribution (equatorial coordinates, N up, E right) of the quasars
found in the LQAC catalog. The highest density regions indicate the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 sq |
| Open with DEXTER | |
2.2 USNO B1.0
The US Naval Observatory B1.0 catalog (Monet et al. 2003), hereafter B1.0, is the latest one of the series of all-sky ultra dense catalogs issued by the USNO. It brings positions and three colors magnitudes (Johnston B, R and I) at two epochs for 1 042 618 261 objects, up to about V=20. It results from scans of 7435 Schmidt plates taken for six sky surveys and calibrated using Tycho-2 stars (Hog et al. 2000). The nominal astrometric accuracy is 200 mas, but the individual objects position precision has a median value of 120 mas along each direction of measurement. Noticing that the quasars forming the LQRF seat at the B1.0 fainter end, where astrometric precision and accuracy is lower, the LQAC objects were searched for in the B1.0, and a neighborhood of stars, i.e., their position, proper motion, and magnitude, was also collected around the detected objects. Figure 2 presents the sky distribution and sky density of the 83 980 quasars recognized in the USNO B1.0.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig02.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img7.png) |
Figure 2:
Sky distribution (equatorial coordinates, N up, E right) of the quasars found in the USNO B1.0 catalogs. Again, the highest density regions indicate the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 sq |
| Open with DEXTER | |
2.3 GSC2.3
The Second Generation Guide Star catalog latest version (Lasker et al. 2008), hereafter GSC2.3, is an all-sky catalog derived from the Digitized Sky Survey (Taff et al. 1990a,b) that the Space Telescope Science Institute and the Osservatório di Torino created from the Palomar and UK Schimdt survey plates. It contains position, proper motion, and magnitude (Johnston B, R, and I) for 945 592 853 objects, and is expected to be complete to R=20. The astrometric total error is quoted as smaller than 300 mas, while the relative astrometric error is lower than 200 mas. In fact, the astrometric residuals compared to external reference catalogs only become higher than 150 mas above R=18 at the fainter end. The astrometric calibration was done using Tycho-2 stars. As can be seen, there are overwhelming similarities between the GSC2.3 and the B1.0 raw data, which were measured and treated however by distinct methods, enabling a most natural combination of the independent results from each of them. As before, we searched for the LQAC objects in the GSC2.3, and a neighborhood of stars (position, proper motion, and magnitude) was collected around the found objects. Figure 3 presents the sky distribution and sky density of the 93 943 quasars recognized in the GSC2.3.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig03.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img8.png) |
Figure 3: Sky distribution (equatorial coordinates, N up, E right) of the quasars found in the GSC2.3 catalog. As before, the highest density regions mark the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 deg2 shown on the plots. Notice that the scale is slightly different from that of Fig. 2 relative to the B1.0 catalog. |
| Open with DEXTER | |
2.4 SDSS DR5
The Sloan Digitized Sky Survey (SDSS) data release 5 (Adelman-McCarthy et al. 2007), hereafter DR5, represents the completion of the SDSS-I project. It covers 8000 sq![]() ,
around the north Galactic cap (b < 30
,
around the north Galactic cap (b < 30![]() )
and three stripes towards the south Galactic cap, for magnitudes as faint as i=20.2, and a total of 215 million unique objects. The astrometry is preferably referred to the UCAC catalog, or else to the Tycho-2 catalog. The rms residuals per coordinate are 45 mas and 75 mas for reductions against the UCAC (Zacharias et al. 2000) and the Tycho-2 (Hoeg et al. 1997), respectively, with additional 30 mas systematic errors in both cases (Pier et al. 2003). The internal astrometric precision is mainly limited by seeing effects, and it is quoted as around 35 mas in each coordinate. We note that quasars are signaled in the DR5, for a total of 74 869 entries with quasi-stellar object spectral class. As seen from Fig. 1, the large number of DR5 quasars represents an important feature of the LQAC input.
)
and three stripes towards the south Galactic cap, for magnitudes as faint as i=20.2, and a total of 215 million unique objects. The astrometry is preferably referred to the UCAC catalog, or else to the Tycho-2 catalog. The rms residuals per coordinate are 45 mas and 75 mas for reductions against the UCAC (Zacharias et al. 2000) and the Tycho-2 (Hoeg et al. 1997), respectively, with additional 30 mas systematic errors in both cases (Pier et al. 2003). The internal astrometric precision is mainly limited by seeing effects, and it is quoted as around 35 mas in each coordinate. We note that quasars are signaled in the DR5, for a total of 74 869 entries with quasi-stellar object spectral class. As seen from Fig. 1, the large number of DR5 quasars represents an important feature of the LQAC input.
2.5 UCAC2
The second USNO CCD Astrograph catalog (Zacharias et al. 2004), hereafter UCAC2, is the latest release of the ongoing UCAC project, designed to observe the entire sky for R magnitudes between about 7.5 and 16. The observed positional errors are about 20 mas for the stars in the 10
to 14 mag range, and about 70 mas at the limiting magnitude of R=16. The UCAC2 is a high density, highly accurate, astrometric catalog (positions and proper motions) of 48 330 571 stars covering the sky from -90 to +40![]() in declination and as high as +52
in declination and as high as +52![]() in some areas. The northern limit is a function of right ascension. The astrometry provided in the UCAC2 is on the Hipparcos system. Positions are given at the standard epoch of Julian date 2000.0. The UCAC2 supersedes the Tycho-2 catalog, having a stellar density that is over 20 times higher. It is used here as the preferred catalog to place the quasar positions collected from the catalogs described in the above subsections onto the Hipparcos system. Nevertheless, since the UCAC2 coverage does not include the entire sky, two additional stellar frames are complementary used and are presented below.
in some areas. The northern limit is a function of right ascension. The astrometry provided in the UCAC2 is on the Hipparcos system. Positions are given at the standard epoch of Julian date 2000.0. The UCAC2 supersedes the Tycho-2 catalog, having a stellar density that is over 20 times higher. It is used here as the preferred catalog to place the quasar positions collected from the catalogs described in the above subsections onto the Hipparcos system. Nevertheless, since the UCAC2 coverage does not include the entire sky, two additional stellar frames are complementary used and are presented below.
2.6 UCACN
We hereafter term UCACN a cutout of the preliminary UCAC positions around the LQAC quasars in the northern part of the sky that is not reached by the UCAC2 coverage (Zacharias 2007). Although, as discussed further on, the astrometric accuracy of the UCACN positions and its stellar density granted no degradation on the results obtained using it, it will be dropped in future revisions of this work, after the forthcoming release of the all-sky catalog UCAC3. The nominal astrometric accuracy of the UCACN stars is similar to that of the UCAC2 ones, but no proper motion data were released for these stars. Throughout this paper when referring to the combination of the UCAC2 and UCACN, the designation UCAC is used.
2.7 2MASS
The Two Micron All-Sky Survey point source catalog (Cutri et al. 2003), hereafter 2MASS, derives from an uniform scan of the entire sky in three near-infrared bands to detect and characterize point sources brighter than about 1 mJy in each band, with signal-to-noise ratio greater than 10, using a pixel size of 2.0'', each point in the survey having been imaged six times. The detectors worked
to a 3![]() limiting sensitivity of J=17.1, H=16.4, and K=15.3. The 2MASS contains the position of 470 992 970 sources, but no proper motions. The astrometry is referred to the Tycho-2 catalog and it is accurate to 70-80 mas over the magnitude range of 9 < K < 14 mag. Comparative studies have shown that the 2MASS positions agree with those from common UCAC2 stars to within 10 mas (Zacharias et al. 2003), and that the 2MASS is compliant to the ICRF in the range 100-120 mas, Taking advantage of its all-sky coverage, very high stellar density, and consistent astrometry, the 2MASS catalog is used here as an independent means to place the LQAC quasars recognized in the large, deep catalogs on the Hipparcos system.
limiting sensitivity of J=17.1, H=16.4, and K=15.3. The 2MASS contains the position of 470 992 970 sources, but no proper motions. The astrometry is referred to the Tycho-2 catalog and it is accurate to 70-80 mas over the magnitude range of 9 < K < 14 mag. Comparative studies have shown that the 2MASS positions agree with those from common UCAC2 stars to within 10 mas (Zacharias et al. 2003), and that the 2MASS is compliant to the ICRF in the range 100-120 mas, Taking advantage of its all-sky coverage, very high stellar density, and consistent astrometry, the 2MASS catalog is used here as an independent means to place the LQAC quasars recognized in the large, deep catalogs on the Hipparcos system.
2.8 ICRF-Ext2
The International Celestial Reference Frame ![]() extension (Ma et al. 1998; Fey et al. 2004), hereafter ICRF-Ext2, is the present materialization of the International Celestial Reference System
(ICRS) at radio frequencies. It represents the basic frame with respect to which the position of any object in the celestial sphere should be measured. In its primary contents, the ICRF consists of 212 sources, called ``defining'', whose positions are independent of the classical planes (equator, ecliptic) and reference points (equinox), but consistent with the previous realizations of the Celestial System as the FK5. With the help of a considerable amount of VLBI observations, the individual positions of the sources were found to be accurate to within roughly 0.25 mas, while the stability of the reference axes attains a remarkable 20
extension (Ma et al. 1998; Fey et al. 2004), hereafter ICRF-Ext2, is the present materialization of the International Celestial Reference System
(ICRS) at radio frequencies. It represents the basic frame with respect to which the position of any object in the celestial sphere should be measured. In its primary contents, the ICRF consists of 212 sources, called ``defining'', whose positions are independent of the classical planes (equator, ecliptic) and reference points (equinox), but consistent with the previous realizations of the Celestial System as the FK5. With the help of a considerable amount of VLBI observations, the individual positions of the sources were found to be accurate to within roughly 0.25 mas, while the stability of the reference axes attains a remarkable 20 ![]() as (micro-arcsec) accuracy. In the ICRF initial version 608 sources complemented the defining 212 sources. The entrance of the ICRF-Ext1 and of the ICRF-Ext2 provided 109 new sources to the catalog, thus leading to a total number of 717 radio-sources. Notice that in the ICRF-Ext.2 catalog, a very small sample of objects are not quasars: 10 of them are cathegorized as AGN (Active Galactic Nuclei) and 10 are cathegorized as BL LAC (BL Lacertae). Although the LQAC a priori exclusively considers quasars in its compilation, these particular objects were retained because of their astrometric accuracy. The ICRF-Ext2 is used here to match the VLBI positions directly to the derived optical positions. In the derivation of the LQRF, such match serves to two distinct steps: (a) to redress the global frame orientation towards the ICRF; and (b) to redress local departures of the derived quasar catalog from the ICRF.
as (micro-arcsec) accuracy. In the ICRF initial version 608 sources complemented the defining 212 sources. The entrance of the ICRF-Ext1 and of the ICRF-Ext2 provided 109 new sources to the catalog, thus leading to a total number of 717 radio-sources. Notice that in the ICRF-Ext.2 catalog, a very small sample of objects are not quasars: 10 of them are cathegorized as AGN (Active Galactic Nuclei) and 10 are cathegorized as BL LAC (BL Lacertae). Although the LQAC a priori exclusively considers quasars in its compilation, these particular objects were retained because of their astrometric accuracy. The ICRF-Ext2 is used here to match the VLBI positions directly to the derived optical positions. In the derivation of the LQRF, such match serves to two distinct steps: (a) to redress the global frame orientation towards the ICRF; and (b) to redress local departures of the derived quasar catalog from the ICRF.
2.9 VCS6
The Very Long Baseline Array (VLBA) Calibrator Survey (Petrov et al. 2006), hereafter VCS6, consists of a catalog containing milli-arcsec accurate positions of 3910 extragalacic radio sources, mainly quasars. These positions were derived from the astrometric analysis of dual-frequency 2.3 and 8.4 GHz VLBA observations, in the framework of the International Celestial Reference System (ICRS) as realized by the ICRF. Thus, to the level of precision and accuracy of the optical positions determined here, the VCS6 sources represent the ICRF. In order to strictly validate such representation, 524 VCS6 sources with formal inflated errors larger than 10 mas were excluded. The VCS6 sources that did not belong to the ICRF-Ext2 were added to it, to obtain an enlarged radio frame, which was used for the two steps mentioned in the ICRF-Ext2 subsection, that is, the global and local redressing of the optical quasar positions towards the ICRF.
2.10 VLAC
The Very Large Array (VLA) Calibrator list (Claussen 2006), hereafter VLAC, consists of 5523 radio flux, structure code, position, and associated error entries for 1860 extragalactic sources. It is foremostly indicated as a reference tool for observations at the VLA, but the radio positions are accurate and compliant with the ICRF. Then, as in the previous subsection, the VLAC positions were added to those of the ICRF-Ext2 core data set, after removing 297 with errors larger than 10 mas. The combination of the ICRF-Ext2, VCS6, and VLAC will be here termed as the enlarged radio frame (ERF) and represents the ICRF to within an uncertainty of 10 mas. The order of priority for the radio lists contributing to the enlarged radio frame was, ICRF-Ext2 (718 sources), VCS6 (2684 sources), and finally VLAC (59 sources). The 3461 sources now represent the ICRF on a better distributed all-sky basis (Fig. 4), and the sources for which the optical counterpart position is known will provide the most reliable means of relating the LQRF to the ICRF.
![\begin{figure}
\par\includegraphics[width=7.8cm,clip]{12041fig04.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img11.png) |
Figure 4: Sky distribution (equatorial coordinates, N up, E right) of the enlarged radio frame quasars. The filled symbols mark the sources for which an optical counterpart is found in at least one of the deep, dense source catalogs (B1.0, GSC2.3, DR5). The enlarged radio frame is formed, in order of priority of choice, by the ICRF-Ext2 (718 sources), the VCS6 (2684 sources), and the VLAC (59 sources). |
| Open with DEXTER | |
2.11 Data flow
The various origins of the sources compiled in the LQAC imposes first of all to refer their positions to a single frame on the ICRS system. After that, the quasar frame formed in this way is aligned with the ICRF. Finally, the position of each source is calculated by weighted average. This data flow can be sketched as follows:
- 1.
- The LQAC entries are all admitted.
- 2.
- The LQAC quasars are searched for, by a main criterion of position coincidence, in the B1.0, GSC2.3, and SDSS DR5 high density catalogs. Each individual match is kept and treated separately.
- 3.
- Around each of the individual quasars thus matched a stellar neighborhood is extracted
from the appropriate high density catalogs.
- 4.
- The stellar neighborhood contents from the high density catalogs are searched for in the stellar catalogs UCAC2, UCACN, and 2MASS, as before by a main criterion of position coincidence.
- 5.
- Within each neighborhood, the stars common to the high density catalog
and to the stellar catalog have their positions projected onto the tangential plane
centered on the quasar. A local transformation function from the high density
catalog to the stellar catalog is calculated, mimicking the complete plate
solution polynomials.
- 6.
- At this point, for each quasar, typically, a number of positions are
determined (e.g., from more than one high density catalog, and local solutions
from the two stellar catalogs). Each of these families of positions will still be
handled separately.
- 7.
- Within each family, the quasars for which there is a position in the
enlarged radio frame (that is, the combination of the ICRF, VCS6, and VLAC catalogs)
are found, since they are also flagged in the LQAC, what as before follows mainly a criterion
of positional coincidence.
- 8.
- The subsets so defined are used to calculate the global rotation and
zero point corrections to obtain coincidence with the ICRF origin and axes. The
global rotation and zero point corrections are next applied to the positions of
all quasars of each given family.
- 9.
- As in the previous step, the optical and radio positions in subsets are combined using orthogonal functions, in right ascension, declination, and magnitude, to correct systematic local departures from the ICRF axes directions. And likewise the significant orthogonal functions are
applied to the positions of all quasars in each given family.
- 10.
- Again the optical and radio positions in subsets are combined in small regions around each quasar to derive its correction for localized inhomogeneities.
- 11.
- For each position of each source in a given family, a total error is
assigned that combines the formal error from the high density catalog where it appears,
the error from the particular local correction, the error from the particular
global rotation and bias, and the error from both the significant orthogonal function
adjustments and the inhomogeneity corrections.
- 12.
- From the squared inverse of the total error, a weight is assigned to each determined position of a given quasar. The final position of each quasar is given as the weighted average of the determined positions. The error in the position is assigned according to an individualized function of the optical to radio disagreement.
3 The local astrometric solution
We now derive the points 1 to 6 of Sect. 2.11 (data flow).
Starting from the LQAC input list of quasars, the first step in obtaining their astrometric positions, to form a whole consistent reference frame, is to match the positions of the objects with those in the two large, deep all sky catalogs, the USNO B1.0 and the GSC2.3, as well as in the SDSS DR5. The basic matching criteria is position agreement to within 1 arcsec. This is equal to the poorest astrometric accuracy in the surveys contributing to the LQAC. It is also a safe threshold given the typical seeing and astrographic plate resolution limits. Additionally, a magnitude limit was applied preventing the selection of objects brighter than R=7, nevertheless this threshold was not reached by any source. No proper motion limit was enforced because both the USNO B1.0 and the GSC2.3 warn against possible offsets of the proper motion zeropoints. A check was made afterwards by determining local zeropoints of proper motion, given by the average motion. In comparison to the local zeropoints of proper motion, just 0.7% of the GSC2.3 selected objects show significant motion, while for the B1.0 selected objects just 0.1% of them show significant motion. To verify what would be the odds of a chance hit, the input coordinates were varied by random values between 1 and 5 arcmin. In this way the same region of the true objects was swept. Keeping the search radius to 1 arcsec, in only 0.2% of the cases was verified a hit on the false coordinates. Moreover, in only 0.1% of cases was a second object found significantly close to the adopted match. These satisfying rates change very little when the search radius is increased to 2 arcsec. While this provides additional proof of the overwhelming correctness of the matches, it at the same time indicates that there is little advantage in adopting a larger radius, and certainly no gain to the confidence level attached to the cross-identifications.
In all, 83 980 quasars are recognized in the B1.0, and 93 943 quasars are recognized in the GSC2.3. The sky distribution follows closely that shown in Fig. 1. From the figure the significant contribution of the SDSS DR5 is clear. For the DR5, 74 825 quasars are retrieved using the SDSS query server. The positions from the three catalogs were added independently to the input list. The final input data contains 100 165 quasars. Just small fractions of the total appear in only one of the catalogs (1405 only in USNO B1.0, 4425 only in GSC2.3, and 3276 only in SDSS DR5), while 61 532 quasars appear in all three catalogs.
These three catalogs that bring the input positions for the recognized quasars are originally placed on the ICRF J2000 reference frame by different astrometric pipelines based on the Tycho-2 catalog. Their global orientation and equatorial bias relative to the ICRF J2000 frame are shown in Table 1. Local deviations are also apparent in Figs. 5-7.
Table 1: Initial optical to radio relationshipsa.
![\begin{figure}
\par\includegraphics[width=14.7cm,clip]{12041fig05.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img15.png) |
Figure 5: USNO B1.0 right ascension and declination offset distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
![\begin{figure}\includegraphics[width=14.7cm,clip]{12041fig06.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img16.png) |
Figure 6: GSC2.3 right ascension and declination offsets distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=14.8cm,clip]{12041fig07.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img17.png) |
Figure 7: SDSS DR5 right ascension and declination offsets distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
To homogenize all the original different positions, a local astrometric reduction was performed based on the catalogs UCAC and 2MASS. The local correction follows the standard tangent plane astrometric reduction, taking the quasar original position as the central point of the rigorous gnomic projection (Assafin et al. 1997). Through it the catalog coordinates are adjusted to the reference frames represented by the stellar catalogs. Three assumptions are implicit to the method: that the stellar catalogs deliver an improved, and similar, representation of the ICRF, either relatively to the two Schmidt plate surveys, as well as relatively to the photometric one. That in a very restricted neighborhood the deviation between the deep surveys and the stellar catalogs, whichever one it originated from, can be modeled by simple relationships. And that the removal of such deviations can significantly improve the accuracy of the quasar positions found in the large surveys. The results of previous investigations support these assumptions (da Silva Neto et al. 2005).
3.1 The polynomial degree of the solution
On the functional side, the initial question to be tackled is the polynomial degree of the local astrometric correction representation. The UCAC is the less dense of the catalogs involved, and already presents a typical density of 10 stars per 5 ![]() 5 arcmin. Translated to the
Schmidt plates scale this means that a first degree solution with 10 reference stars can be applied over a physical area as small as 25 mm2. According to the adopted a priori assumptions, and given the sky density of the stellar catalogs, the simplest models seem to be well suited. To verify this procedure, a trial local reduction was performed for 29 quasars randomly distributed across the celestial sphere, at every one hour of right ascension, and away from the galaxy plane. Around
each of them, a field of UCAC2 stars was selected in boxes of side 10 arcmin, which contained at least 30 stars. For these 29 fields of quasars, complete polynomial solutions were tested, with orders varying from 0 to 3
5 arcmin. Translated to the
Schmidt plates scale this means that a first degree solution with 10 reference stars can be applied over a physical area as small as 25 mm2. According to the adopted a priori assumptions, and given the sky density of the stellar catalogs, the simplest models seem to be well suited. To verify this procedure, a trial local reduction was performed for 29 quasars randomly distributed across the celestial sphere, at every one hour of right ascension, and away from the galaxy plane. Around
each of them, a field of UCAC2 stars was selected in boxes of side 10 arcmin, which contained at least 30 stars. For these 29 fields of quasars, complete polynomial solutions were tested, with orders varying from 0 to 3![]() ,
and a straight averages solution. The quasar positions were taken from the USNO B1.0 and all positions were transported to the USNO B1.0 plate epoch, using the proper motions of either catalog. Table 2 summarizes the mean results.
,
and a straight averages solution. The quasar positions were taken from the USNO B1.0 and all positions were transported to the USNO B1.0 plate epoch, using the proper motions of either catalog. Table 2 summarizes the mean results.
Table 2: Comparison between the models for the local astrometric solutiona.
In the first half of Table 2, the average local corrections and the corresponding standard deviation are shown. Although the values only very loosely represent the systematic offsets between the USNO B1.0 and the UCAC2, it is important to note is the similarity between all the rows. In the second half of the table, the average internal errors of each solution and their dispersion are shown. Again all rows behave quite alike. Therefore, to minimize the region in which the local solution is derived, and maximize the ratio of the number of equations to the number of parameters to find, the complete first degree polynomial was adopted. This solution also produces the smallest set of standard deviations. The zero degree solutions fared just as well as the others, so there would be no particular advantage in adopting an even smaller region, while the first degree polynomial allows for some modeling, which is useful face to the large numbers of sources that the local solution is going to be applied to. Two formulations of the first degree polynomial are concurrently used, the complete one (six independent parameters) - hereafter the six-parameter model, and the so-called four constants one (in which the X and Y axes are constrained to have the same scale), hereafter the four-parameter model. Furthermore, we note that with the six-parameter model the error in the central, pseudo-tangential point, which is always the position of the quasar, was also found to be the smallest.
3.2 The stellar catalogs and the size of the local segion
As discussed above, the UCAC2 provides the desiderata for the local astrometric solution: high stellar density, accurate global representation of the HCRF and hence of the ICRF, range of magnitudes up to 16, and small zonal and local frame biases. The stellar density supports using a region as small as 10 arcmin across to be used, which is always within the overlap zone of the Schmidt plate surveys contributing to the B1.0 and the GSC2.3.
However, the UCAC2 has incomplete coverage in the northern celestial hemisphere. Two remedies are used to account for this hindrance, the use of preliminary positions of northern UCAC stars (here called UCACN), and the use of the 2MASS catalog. In the former case, the UCACN positions are by construction on the same system of the UCAC2, and of the same precision.
The 2MASS Point Source catalog positions are compliant with the ICRS by means of the Tycho-2 catalog, and are expected to be accurate to 70-80 mas over the magnitude range of 9 < Ks < 14 mag. At the limit Ks = 16, the accuracy is at the level of 200 mas. As the 2MASS does not provide proper motions, these values are good for the mean epoch of observation, 1999.
The pitfalls created by the magnitude gap between the 2MASS objects and the brighter Tycho-2 reference stars reduce the final astrometric accuracy. The internal precision of the 2MASS individual positions is better, at the level of 40-50 mas, in the 9 < Ks < 14 mag range. A comparison with 5.2 million stars also present in the UCAC2 shows standard deviation of 70-80 mas in both coordinates, for the 9 < Ks < 14 mag range. For the stars in common
around the quasars extracted to define the local solution, the difference average and standard deviation are
![]() = +3 mas,
= +3 mas,
![]() = 99 mas, and
= 99 mas, and
![]() = +11 mas,
= +11 mas,
![]() = 95 mas, all in the sense 2MASS.minus UCAC2. Furthermore, from the limited sample of 700 quasars from the enlarged radio frame found in the 2MASS catalog, the analogous statistics are
= 95 mas, all in the sense 2MASS.minus UCAC2. Furthermore, from the limited sample of 700 quasars from the enlarged radio frame found in the 2MASS catalog, the analogous statistics are
![]() = +0 mas,
= +0 mas,
![]() = 144 mas, and
= 144 mas, and
![]() = -2 mas,
= -2 mas,
![]() = 138 mas.
= 138 mas.
On the positive side, for the same region, the 2MASS catalog contains about 10 times the number of reference stars as the UCAC catalog. In the small regions used for the local solution, it represents a coherent local frame, from which the zonal bias can be removed after later comparisons with the enlarged radio frame sources. It is well aligned with both the UCAC and the ICRF, and represents an all-sky frame. The local solution was computed independently using UCAC and 2MASS reference stars. Each of the results contribute, again independently, to the weighted average used to compute the final LQRF quasar coordinates.
3.3 The analytical expression for the local correction astrometric solution
On establishing the analytical form of the local astrometric solution, a final point to be considered concerns the usefulness of a magnitude dependent term, a feature often present in Schmidt plate based surveys (da Silva Neto et al. 2000). In the present case, the R magnitude represents the obvious choice, mainly because it is common to all the involved catalogs, and closer to the central wavelengths of the 2MASS bands. At the same time, because of the quasars redshift
and to the reddening for the stars, coupled with CCD top sensitivity and wider plate effective passband, the signal-to-noise ratio is usually higher towards the red. An inspection on the magnitude dependency of the catalog minus enlarged radio frame residuals indicates a small linear trend, which has a higher value for the
![]() offsets than for the
offsets than for the
![]() offsets. The same trend is verified for both B1.0 and GSC2,3 increasing with magnitude for declination, and decreasing with magnitude for right ascension. The amplitudes are not higher than 10 mas in the significant cases. For the DR5, the magnitude dependence is of much smaller amplitude and opposite trend. The possibility of a magnitude equation is not excluded in the
presentation of either of the two deep catalogs. However, the causes and ensuing description would be out of the scope of this work. Here, an additional obstacle would be to bridge the magnitude gap between the reference stars and the far dimmer quasars. All accounted, a magnitude dependency is left to be investigated by the orthogonal functions in direct comparison with the enlarged radio frame positions.
offsets. The same trend is verified for both B1.0 and GSC2,3 increasing with magnitude for declination, and decreasing with magnitude for right ascension. The amplitudes are not higher than 10 mas in the significant cases. For the DR5, the magnitude dependence is of much smaller amplitude and opposite trend. The possibility of a magnitude equation is not excluded in the
presentation of either of the two deep catalogs. However, the causes and ensuing description would be out of the scope of this work. Here, an additional obstacle would be to bridge the magnitude gap between the reference stars and the far dimmer quasars. All accounted, a magnitude dependency is left to be investigated by the orthogonal functions in direct comparison with the enlarged radio frame positions.
Therefore, the enforced local solution is
In Eqs. (1) and (2), ``SCat'' is either the UCAC2 (or even its preliminary northernmost part) or the 2MASS, and ``QCat'' designates the B1.0, the GSC2.3 or the DR5. The relations above were determined for the smallest set of ``SCat'' and ``QCat'' stellar objects in commonin a neighborhood larger than 10 arcmin but smaller than a box of size of 30 arcmin, to a minimum of 6 stars. The solutions were calculated independently for right ascension and declination. Whenever that minimum number of stars is touched, either at the start or after elimination of stars, the four-parameter model is used, combining the two equatorial coordinate solutions. In fact, as shown in the next section, the four-parameter model was applied for all quasars and it delivers solutions in excellent agreement with the six-parameter solutions. The analytical form of the four-parameter model is presented below in Eqs. (3) and (4), where ``SCat'' and ``QCAT'' keep their afore-defined meaning.
3.4 Applying the local astrometric solution
As discussed in the previous sections, the initial task of producing the LQRF consists of carrying out a local astrometric reduction using the most precise and accurate stellar catalogs representing the HCRF, through the Tycho-2 reference frame, to locally redress the quasar position input from the high density, deep catalogs.
Table 3: Mean results from the local astrometric correctionsa.
There, however, the question of epochs comes up. The stellar catalogs have a mean epoch very
close to J2000, being J1998.79 (![]() 2.78 y) for the UCAC2, and J2003.34 (
2.78 y) for the UCAC2, and J2003.34 (![]() 0.24 y) for the UCACN, the UCAC2 preliminary northernmost part, and J1998.87 (
0.24 y) for the UCACN, the UCAC2 preliminary northernmost part, and J1998.87 (![]() 0.08 y) for the 2MASS.
Also, the DR5 mean epoch is J2002.96 (
0.08 y) for the 2MASS.
Also, the DR5 mean epoch is J2002.96 (![]() 1.45 y), thus raising no questions. The dilemma on whether the local reduction ought to be performed in the epoch of the quasar input position or directly in J2000 is only meaningful when the B1.0 and the GSC2.3 are locally reduced by the UCAC2. Then, it would not be unreasonable to speculate that a reduction made at the quasar epoch would diminish the scatter in the stellar positions, on the supposition that the stellar images themselves were at the quasar epoch (i.e., the epoch of the plate where the quasar is found) because of the smallness of the used field. The B1.0 mean epoch is J1977.12 (
1.45 y), thus raising no questions. The dilemma on whether the local reduction ought to be performed in the epoch of the quasar input position or directly in J2000 is only meaningful when the B1.0 and the GSC2.3 are locally reduced by the UCAC2. Then, it would not be unreasonable to speculate that a reduction made at the quasar epoch would diminish the scatter in the stellar positions, on the supposition that the stellar images themselves were at the quasar epoch (i.e., the epoch of the plate where the quasar is found) because of the smallness of the used field. The B1.0 mean epoch is J1977.12 (![]() 5.49 y). In the other hand, the B1.0 positions are given by an average of plate reductions, in such a way to jeopardize the hypothesis of common epochs, given the range of magnitudes and to some extent the two different types of objects. For the GSC2.3, in contrast, the positions always refer to one single highest quality plate, whenever possible the red one. But then again, the GSC2.3 mean epoch is J1992.5 (
5.49 y). In the other hand, the B1.0 positions are given by an average of plate reductions, in such a way to jeopardize the hypothesis of common epochs, given the range of magnitudes and to some extent the two different types of objects. For the GSC2.3, in contrast, the positions always refer to one single highest quality plate, whenever possible the red one. But then again, the GSC2.3 mean epoch is J1992.5 (![]() 3.72 y) and therefore there is a balance between reducing modestly the stellar position scatter and the errors that might be introduced by faulty or biased proper motions.
3.72 y) and therefore there is a balance between reducing modestly the stellar position scatter and the errors that might be introduced by faulty or biased proper motions.
To verify which way is preferable, the local corrections for the sources belonging to the enlarged radio frame were evaluated both at J2000 and the quasar position epoch. A second trial was made by considering only the sources from the enlarged radio frame that belonged to the three input catalogs and could be reduced by all the stellar frames. This subsample contains 240 sources but enables a direct comparison between all the possible ways of treatment. The outcomes show no net advantage in working at the quasar epoch. For the B1.0 catalog, the number of sources for which the local reduction converges drops; there is a marginal gain on the number of stars entering in the reduction but the number of actually used stars remains the same; there is no decreasing of the standard deviations from the solution corrections, or from the optical minus radio offsets; and the removal of the equatorial bias is less efficient (by 98 mas). The external check actually indicates a small increase of the average detachment from the representation of the ICRF origin. For the GSC2.3 there is no important loss in working at the quasar epoch, but no gain either. The number of sources for which the local reduction converges remains the same, and so does the number of entry and used stars. The standard deviation in the solution does not change, and for the optical minus radio positions the offset scatter improves only marginally (by 4.5 mas). The equatorial bias is less efficiently removed (by 40 mas). Exactly the same results are obtained when inspecting the subsample of common sources. In view of these results, we decided to work only at J2000 for the local corrections. Thus, all pairs of input quasar catalogs and stellar catalogs are treated identically.
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig08.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img37.png) |
Figure 8: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the UCAC stellar reference frame onto the USNO B1.0 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig09.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img38.png) |
Figure 9: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the 2MASS stellar reference frame onto the USNO B1.0 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig10.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img39.png) |
Figure 10: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the UCAC stellar reference frame onto the GSC2.3 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig11.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img40.png) |
Figure 11: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the 2MASS stellar reference frame onto the GSC2.3 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
A second point concerning the issue of epochs has already been touched in the previous discussion. It concerns whether the local reductions made with the UCACN, that is for the northernmost sources, and with the 2MASS would be significantly worse than those made with the UCAC2. As we have seen, both of them have a mean epoch close to J2000, where the local corrections are performed. For the 2MASS catalog, which is not originally presented as an astrometric frame, the number of equations of condition is substantially increased for a same patch of the skies as defined for the UCAC2. To test the performance of the different catalogs, we used the DR5, which was shown in Sect. 3 to have intrinsically smaller scatter relative to the ICRF. As before, the enlarged radio frame and its subset of all common sources are employed, and they provide very similar responses. The UCAC2 based reductions produce the best results as expected. The right ascension and declination standard deviation in the offsets to the radio frame is at 47.5 mas. We remark that this is already a gain relative to the DR5 catalog offsets that are at 59 mas, as produced from Table 1 values. The standard deviation in the solution itself is at 33 mas. The UCACN based reductions perform much alike, being actually slightly better on declination and 30 mas worse on right ascension. The optical minus radio standard deviation is 14 mas worse than that of the UCAC2. The 2MASS based reductions fare somewhat worse than the UCACN ones, the solution standard deviation being larger by 18 mas, and the optical minus radio standard deviations being worse by 6.5 mas. Nonetheless, we note that the average optical to radio position offsets are much similar for the UCAC2 and the 2MASS (differing by just 5 mas). Finally, we remark that, eventhough not bringing a direct improvement in accuracy as the UCAC2 based reductions, the UCACN and the 2MASS local reductions enable us to place the DR5 positions on the same frame with the B1.0 and GSC2.3 reduced positions, without impairing their intrinsic precision.
Table 3 summons up all the applied local corrections.
As can be seen in Table 3, the different quasar input catalogs (codes B, G, or S) require different local corrections, while the three stellar reference catalogs (codes U, N, or T) deliver such corrections with similar accuracy. The local correction outputs (codes C) agree when calculated either by the six-parameter or by the four-parameter models (codes 6 or 4). The local corrections are generally larger than the remaining optical minus radio offsets (codes ![]() ), which supports
their usefulness. The optical minus radio mean offset in all cases is improved relatively to the one obtained using original quasar catalogs positions. As a consequence, the differences between the results from the various local reductions become similarly small.
), which supports
their usefulness. The optical minus radio mean offset in all cases is improved relatively to the one obtained using original quasar catalogs positions. As a consequence, the differences between the results from the various local reductions become similarly small.
At this point, the three quasar input catalogs and the three stellar reference frames deliver concurrent, independent sets of positions. Whenever the 1![]() degree polynomial solution fails to converge, the four-parameter solution results can be adopted equivalently. There are thus up to
twelve possible local solutions calculated for each source. For 61% of the sources more than one solution was obtained, for 844 sources all twelve solutions were completed, and for 12 sources no solution converged. Figures 8 to 11 display the local corrections for the most critical cases, namely the B1.0 and the GSC2.3, as given by the UCAC and 2MASS frames. Comparing with Figs. 5, 6, it is already clear that the local corrections bring the quasar's positions onto the ICRF. The comparison between these figures and the initial plots (Figs. 5-7) show that the local astrometric solution significantly redress the input positions from the large catalogs. We note that the outcomes from the UCAC and 2MASS stellar reference frames have much in common. The
six-parameter and the four-parameter models also provide coincident corrections, and thus, only those from the six-parameter model are shown in the figures. We also note that there is no discontinuity between the zones where either the UCAC2 or the UCACN stellar frames were used.
degree polynomial solution fails to converge, the four-parameter solution results can be adopted equivalently. There are thus up to
twelve possible local solutions calculated for each source. For 61% of the sources more than one solution was obtained, for 844 sources all twelve solutions were completed, and for 12 sources no solution converged. Figures 8 to 11 display the local corrections for the most critical cases, namely the B1.0 and the GSC2.3, as given by the UCAC and 2MASS frames. Comparing with Figs. 5, 6, it is already clear that the local corrections bring the quasar's positions onto the ICRF. The comparison between these figures and the initial plots (Figs. 5-7) show that the local astrometric solution significantly redress the input positions from the large catalogs. We note that the outcomes from the UCAC and 2MASS stellar reference frames have much in common. The
six-parameter and the four-parameter models also provide coincident corrections, and thus, only those from the six-parameter model are shown in the figures. We also note that there is no discontinuity between the zones where either the UCAC2 or the UCACN stellar frames were used.
4 The global orientation towards the ICRS
In this section, points 7 and 8 presented in Sect. 2.11 (data flow) are derived.
Once the local correction is obtained, the next move is to tie the preliminary frame just derived to the ICRF. As discussed in Sect. 1, the ICRF alone is too sparse, and in particular the number of its bright optical counterparts, to suffice for a detailed tying. Since the long base radio interferometric observations always combine data for several sources in different sessions, a radio position net that is considerably larger than the ICRF can be formed by adding the VLBA calibrators and the VLA calibrators. In the case of the VLA, only sources of the highest astrometric precision are included. The accurate, ICRF representing, radio interferometric positions of the enlarged radio sample sources (ERF) are those compared with their optical counterpart from the stellar based preliminary frame derived from the local corrections. From the ICRF, 718 sources are collected, while from the VSC6 and the VLAC, 2684 sources and 59 sources are collected respectively.
The enlarged radio frame produced in this way thus contains 3461 sources. They are adequately represented in all of the three contributing catalogs as described in Table 3 (Col. Nrad). The sky distribution was shown in Fig. 4. From the ERF sources, 2263 have an optical counterpart in at least one of the input catalogs. The average minimum distance between the ERF sources is 187 arcmin, with a mode of 70 arcmin.
The ERF radio positions are then compared with those of their optical counterparts from the stellar based preliminary frame derived by the local corrections. Initially, the comparison entails the derivation of global orientation corrections about the equatorial coordinates standard triad, plus
a correction for a bias relatively to the equator. Following (Arias et al. 1988), the canonical
equations relating the right ascension and declination offsets to the rotations (A1-A3) about the equatorial axes (namely, X on the equator pointing to the conventional origin, Y on the equator
perpendicular to X, and Z pointing to the conventional pole) are given by
Equations (5) and (6) are solved independently to assess the robustness of the corrections. In this case, the direction cosines A1 and A2 agree when calculated either from
For the sake of gathering the largest number of equations of condition, the final values are derived by a combined matrix including the three rotation corrections, plus the representation of the equatorial bias.
4.1 The equatorial bias
Former investigations (Assafin et al. 2001) pointed out marked differences in the equatorial bias concerning the north and south portions of the USNO A2.0 catalog. The point of discontinuity is around -20![]() of declination, which is the boundary of the north and south plate surveys that contributed to that catalog. Although such marked discontinuity should not befall neither the B1.0 nor the GSC23 catalogs, they mostly share the same constituent surveys with the USNO A2.0.
of declination, which is the boundary of the north and south plate surveys that contributed to that catalog. Although such marked discontinuity should not befall neither the B1.0 nor the GSC23 catalogs, they mostly share the same constituent surveys with the USNO A2.0.
To analyze whether a discontinuity remains in the data, Eq. (6) was solved for the catalogs B1.0 and GSC23, as locally corrected by the UCAC2 and the 2MASS frames, by adopting a single A4 unknown, two A4 unknowns dividing the
![]() offsets at -20
offsets at -20![]() of declination, and eighteen A4 unknowns to fit the
of declination, and eighteen A4 unknowns to fit the
![]() offsets within declination strips 10
offsets within declination strips 10![]() wide. The plots in Fig. 13 show features that are more complex than could be described by one A4 standard offset. There is a coarse positive plateau southwards of declination -20
wide. The plots in Fig. 13 show features that are more complex than could be described by one A4 standard offset. There is a coarse positive plateau southwards of declination -20![]() ,
and values averaging near zero northwards. The standard deviation in the residuals from the 18 strips solutions is indeed no smaller than that of the -20
,
and values averaging near zero northwards. The standard deviation in the residuals from the 18 strips solutions is indeed no smaller than that of the -20![]() boundary, 2 A4 terms solution. This is indicative of
an interplay of factors that can be more adequately handled in the next step where harmonic terms are introduced. On the other hand, the solution contemplating a single A4 term fares the worst by a
few mas, and is certain to provide the least appropriate description.
boundary, 2 A4 terms solution. This is indicative of
an interplay of factors that can be more adequately handled in the next step where harmonic terms are introduced. On the other hand, the solution contemplating a single A4 term fares the worst by a
few mas, and is certain to provide the least appropriate description.
The A4 declination dependency that is verified, prompted us to assess whether a similar right ascension dependency is present. In this case, no such dependency exists.
4.2 Rotation angles and equatorial bias
The final values of the A1, A2, and A3 direction cosines for the global orientation towards the ICRF, as well as the equatorial bias, were found by adjusting the optical minus radio residual between the positions evaluated from the local astrometric solution and those given by the enlarged radio frame. The values are presented in Table 4.
For the B1.0 and GSC2.3 northernmost sources, for which the local correction was made using the UCACN, separate values were derived for the rotation angle and the (northern only) equatorial bias. But, for the DR5 northernmost sources, although the number of sources handled with UCACN is small, the precisions are high and so a complete solution including only one equatorial bias term was sufficient. We remark that, for the DR5, the A1 and A2 values, although significant and representing true corrections to be applied to the quasar equatorial coordinates, must be interpreted with caution in terms of what they would represent for the DR5 frame orientation, because of the concentration of the DR5 sources in the direction of the right ascension of 12h.
5 The removal of zonal bias
In this section, points 9 and 10 of Sect. 2.11 (data flow) are derived.
5.1 Harmonic functions
At this point, the optical frame was homogenized by the local corrections, and was globally aligned with the ICRF. The final point is to sweep its axes to check for any remaining zonal modulations. This was done for the right ascension, declination, and R magnitude dimensions. In a sense, this is equivalent to straighten up the axes from waves of corrugation either trapped in the stellar catalogs themselves, or that were present in the initial deep catalogs and could not be completely removed by the local corrections.
The problem, the quantity of assessing points, the sky coverage, the dimensions of dependencies, and the relationship between the less precise, corrugated frame and the more precise, correcting one, are all the same in the case considered by Schwan (1988) when deriving zonal corrections to the FK5 construction. Thus, the same treatment by spherical harmonics (Brosche 1966) is used here. The right ascension and declination corrections are expressed by the linear combination of the terms of a series, in which the cpnml-![]() element is given by
element is given by
where
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{12041fig12.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img54.png) |
Figure 12:
Coincidence of the A1 and A2 direction cosines as obtained either from the
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig13.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img55.png) |
Figure 13:
Declination dependency of the equatorial bias (A4). The plotted averages correspond to bins 10 |
| Open with DEXTER | |
Table 4: Direction cosines relative to the ERF after the application of the local astrometric correctionsa.
The offsets are produced by comparing the equatorial coordinates from the previous step (global rotation) with the VLBI positions from the ERF. That is, 2.263 pairs are available. This is again similar to the number that were available for the Schwan (1988) application. Therefore, terms up to very higher order can be derived. However, the analysis from the earlier steps advises us to be cautious in defining the significant order up which to halt. The distribution in right ascension of the offsets from the original deep catalogs suggests a 2![]() term and smaller ripples (cf. Figs. 5-7), while the analysis of global rotation coefficients exhibits no
term and smaller ripples (cf. Figs. 5-7), while the analysis of global rotation coefficients exhibits no ![]() dependence. In contrast, the analysis of the equatorial bias displays a
dependence. In contrast, the analysis of the equatorial bias displays a ![]() dependence, coherent in bins of 10
dependence, coherent in bins of 10![]() (Fig. 13). Magnitude dependences are believed to be possible within the large quasar catalogs. They could to some extent be introduced by the local solution itself, because of the magnitude difference between stars and quasars. The analysis made in Sect. 3.3 points out to such dependences but of small amplitude. All accounted for, and to have representative quantities of ERF objects with which to compute the coefficients of each term, we
adopted to extend to 9
(Fig. 13). Magnitude dependences are believed to be possible within the large quasar catalogs. They could to some extent be introduced by the local solution itself, because of the magnitude difference between stars and quasars. The analysis made in Sect. 3.3 points out to such dependences but of small amplitude. All accounted for, and to have representative quantities of ERF objects with which to compute the coefficients of each term, we
adopted to extend to 9![]() order the Lagrange (
order the Lagrange (
![]() )
polynomials and the Fourier (
)
polynomials and the Fourier (![]() ) functions. The Hermite (R magnitude) polynomials were extended to 2
) functions. The Hermite (R magnitude) polynomials were extended to 2![]() order, but just to 5
order, but just to 5![]() order of the other two terms. Given the poor sky distribution, declination
terms were not used for catalog combinations including the UCACN frame, nor right ascension terms for catalog combinations including the DR5 quasar list. All the above choices were made to retain only truly significant terms derived from the ERF comparison, such that they could be confidently applied to the full set of quasars.
order of the other two terms. Given the poor sky distribution, declination
terms were not used for catalog combinations including the UCACN frame, nor right ascension terms for catalog combinations including the DR5 quasar list. All the above choices were made to retain only truly significant terms derived from the ERF comparison, such that they could be confidently applied to the full set of quasars.
Since by definition the spherical harmonics are orthogonally independent, their statistical significance can be tested individually. Each term was initially tested separately. Only those statistically significant at 3![]() with coefficients not smaller than 1 mas were retained. Once more, this taxes heavier on the high order polynomials, Next, starting from the lower orders
and up, the corrections brought by each term are removed from the equatorial offsets, and the following term is individually tested. The same criterion of 3
with coefficients not smaller than 1 mas were retained. Once more, this taxes heavier on the high order polynomials, Next, starting from the lower orders
and up, the corrections brought by each term are removed from the equatorial offsets, and the following term is individually tested. The same criterion of 3![]() significance and coefficient not smaller than 1 mas is applied to retain the terms. At this round, the highest order Hermite magnitude polynomials, when convolved with the higher Legendre (declination) and Fourier (right ascension) orders, are retained only if the coefficient is not smaller than 5 mas. The terms surviving these two rounds are added by a linear combination to adjust the right ascension and declination offsets, separately, by least squares. Table 5 reports the number of terms surviving the rounds. We note the important decreasing rate from the first to the second round, which justifies the rounds scheme. On the other hand, there is no dropping from the second round (one by one regimen) to the third round (least squares fit of all validated terms together), what shows that they are truly statistically significant.
significance and coefficient not smaller than 1 mas is applied to retain the terms. At this round, the highest order Hermite magnitude polynomials, when convolved with the higher Legendre (declination) and Fourier (right ascension) orders, are retained only if the coefficient is not smaller than 5 mas. The terms surviving these two rounds are added by a linear combination to adjust the right ascension and declination offsets, separately, by least squares. Table 5 reports the number of terms surviving the rounds. We note the important decreasing rate from the first to the second round, which justifies the rounds scheme. On the other hand, there is no dropping from the second round (one by one regimen) to the third round (least squares fit of all validated terms together), what shows that they are truly statistically significant.
Table 6 reports the coefficients derived during the final adjustment for each family of quasar catalog and stellar frame. As expected, the coefficients do not vary from the second round to the final adjustment, indicating that no secondary harmonic survived. There is only one significant term
including the DR5. It relates to the 2MASS local correction and depends solely on declination (3![]() order). This reflects the high quality of the DR5 positions and indicates that the local correction did not induce any derail on the input quasar catalogs. For the UCACN there is also only one significant term. It relates to the GSC2.3 quasar catalog and is of high right ascension order (8
order). This reflects the high quality of the DR5 positions and indicates that the local correction did not induce any derail on the input quasar catalogs. For the UCACN there is also only one significant term. It relates to the GSC2.3 quasar catalog and is of high right ascension order (8![]() ). The lack of UCACN harmonic terms reflects the confinement of the sky region where it was applied. The positions that originated in the B1.0 required 42 harmonic terms (31 for the right ascension offsets), and those from the GSC23 32 harmonic terms (20 for the right ascension
offsets). Considering the stellar reference frames, the UCAC2 required 32 harmonic terms (25 for the right ascension offsets), while the 2MASS required 42 harmonic terms (28 for the right ascension offsets). In all cases, the right ascension offsets required more harmonic terms. In contrast, the
). The lack of UCACN harmonic terms reflects the confinement of the sky region where it was applied. The positions that originated in the B1.0 required 42 harmonic terms (31 for the right ascension offsets), and those from the GSC23 32 harmonic terms (20 for the right ascension
offsets). Considering the stellar reference frames, the UCAC2 required 32 harmonic terms (25 for the right ascension offsets), while the 2MASS required 42 harmonic terms (28 for the right ascension offsets). In all cases, the right ascension offsets required more harmonic terms. In contrast, the
![]() dominated terms in general correspond to larger coefficients, which worked to correct the deviations detected at the A4 equatorial bias analysis. The magnitude terms appear only at the 1
dominated terms in general correspond to larger coefficients, which worked to correct the deviations detected at the A4 equatorial bias analysis. The magnitude terms appear only at the 1![]() order, in 18 B1.0 related terms and 10 GSC23 related terms. Thus, magnitude terms
are presented as the catalogs authors cautioned, but they are less important than the zonal terms. Figure 14 shows the histograms of the harmonic terms coefficients and associated errors. The errors resemble closely a Poisson distribution. The coefficients peak around -6 mas for the right ascension offsets, and around +6 mas for the declination offsets.
order, in 18 B1.0 related terms and 10 GSC23 related terms. Thus, magnitude terms
are presented as the catalogs authors cautioned, but they are less important than the zonal terms. Figure 14 shows the histograms of the harmonic terms coefficients and associated errors. The errors resemble closely a Poisson distribution. The coefficients peak around -6 mas for the right ascension offsets, and around +6 mas for the declination offsets.
Table 5: Number of significant harmonic terms in the three rounds of testinga.
5.2 Local inhomogeneities
Figures 15 and 16 (open symbols) show that after the correction by harmonic series, the optical minus radio residuals are equal to zero within the statistical significance of 3 ![]() standard error, that is without being attached to the scatter of the optical position determinations. This is shown for the pairs combining the B1.0 (Fig. 15) and GSC (Fig. 16) quasar input lists, and the UCAC2 (squares) and 2MASS (circles) local stellar frames, which are the largest and have the most homogenous sky coverage of the combinations used here.
standard error, that is without being attached to the scatter of the optical position determinations. This is shown for the pairs combining the B1.0 (Fig. 15) and GSC (Fig. 16) quasar input lists, and the UCAC2 (squares) and 2MASS (circles) local stellar frames, which are the largest and have the most homogenous sky coverage of the combinations used here.
Notwithstanding this, some clumping is seen, without a clear pattern over the sky, that can be dealt with further. The ERF sky density is such that the mean distance from any given quasar to the closest ERF VLBI position is 1.7![]() .
And, on average, there are 10 ERF VLBI positions within a radius of 4.4
.
And, on average, there are 10 ERF VLBI positions within a radius of 4.4![]() around any given quasar, the largest distance being on average 6.3
around any given quasar, the largest distance being on average 6.3![]() .
Under such conditions for each of the combinations of quasar list and
stellar reference frame, hence for every quasar a correction for the local inhomogeneities towards the VLBI position can be obtained from the average of 10 ERF quasars. Within the ERF quasars radius, objects are removed one by one if both their right ascension and declination offsets are larger than 2
.
Under such conditions for each of the combinations of quasar list and
stellar reference frame, hence for every quasar a correction for the local inhomogeneities towards the VLBI position can be obtained from the average of 10 ERF quasars. Within the ERF quasars radius, objects are removed one by one if both their right ascension and declination offsets are larger than 2![]() .
On average, 1.3 ERF quasars are removed, what shows the robustness of the local inhomegeneities corrections. This procedure is similar to that of overlapping circles (Taff et al. 1990a,b), but no overlap is actually required since the autocorrelation between adjacent corrections fades into a characteristic value at a distance of 20
.
On average, 1.3 ERF quasars are removed, what shows the robustness of the local inhomegeneities corrections. This procedure is similar to that of overlapping circles (Taff et al. 1990a,b), but no overlap is actually required since the autocorrelation between adjacent corrections fades into a characteristic value at a distance of 20![]() .
Figure 17 illustrates the weakness of the autocorrelations by taking each quasar in turn as a pole source, and plotting the standard
deviation in the inhomogeinity correction within growing distance rings. For nearby sources, i.e., very small rings, the inhomogeneities are much the same, and the standard deviation is accordingly small. Rapidly, however, before reaching the distance of 20
.
Figure 17 illustrates the weakness of the autocorrelations by taking each quasar in turn as a pole source, and plotting the standard
deviation in the inhomogeinity correction within growing distance rings. For nearby sources, i.e., very small rings, the inhomogeneities are much the same, and the standard deviation is accordingly small. Rapidly, however, before reaching the distance of 20![]() ,
the standard deviation already reaches the limit of scatter characteristic of each family of input catalog and stellar reference frame solutions.
,
the standard deviation already reaches the limit of scatter characteristic of each family of input catalog and stellar reference frame solutions.
Table 6: Values of the coefficients of the adjusted harmonic functionsa.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{12041fig14.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img58.png) |
Figure 14:
Distribution of the coefficients and associated errors of the harmonic functions fitting the
|
| Open with DEXTER | |
By determining in this way the correction for the local inhomogeneities, it is seen in Figs. 15 and 16 (filled symbols) that the clumps are clearly minimized. After applying the corrections by harmonic functions, the optical minus radio offsets are typically null within 1.3![]() ,
what is
reduced further to within 0.7
,
what is
reduced further to within 0.7![]() after applying the complementary local inhomogeneities
corrections.
after applying the complementary local inhomogeneities
corrections.
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig15.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img59.png) |
Figure 15:
Averaged
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=16cm,clip]{12041fig16.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img60.png) |
Figure 16:
Averaged
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig17.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img61.png) |
Figure 17: Fast fading of the autocorrelation of the local inhomogeneities correction. In the figure is plotted the standard deviation of the corrections in samples taken in rings of increasing radius. The upper lines correspond to the USNO B1.0 and GSC2.3 families of solutions, while the lower lines correspond the SDSS DR5 families of solutions. |
| Open with DEXTER | |
![\begin{figure}\includegraphics[width=7.6cm,clip]{12041fig18.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img62.png) |
Figure 18: Distribution of the external errors assigned to the right ascension and declination J2000 positions of the LQRF sources. The distributions can be reckoned to Poisson distributions peaking at 139 mas on right ascension and at 130 mas on declination. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{12041fig19.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img63.png) |
Figure 19:
Sky density of the LQRF. The counts are in bins of 10 |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=6.8cm,clip]{12041fig20.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img64.png) |
Figure 20:
Vectorial distribution of the systematic deviations (north up, east right) of the LQRF to the ICRF within bins of 10 |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig21.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img65.png) |
Figure 21:
Distribution on right ascension of the
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig22.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img66.png) |
Figure 22:
Distribution on right ascension of the
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig23.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img67.png) |
Figure 23:
Distribution on declination of the
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{12041fig24.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img68.png) |
Figure 24:
Distribution on declination of the
|
| Open with DEXTER | |
6 The LQRF catalog
The LQRF catalog right ascension and declination equatorial coordinates are calculated from the values obtained in the final step of the data treatment (removal of zonal bias) by a weighted average. In the average, for each quasar, the solutions from the three input lists (B1.0, GSC23, and DR5) and the three stellar reference frames (UCAC2, UCACN, and 2MASS) are combined. The weights are the inverse of the square root sum of the internal and external errors at each of the correction steps plus the formal errors of each entry quasar input list. To not carry too high or too low a weight for any given combination, however, for each of them separately the errors have been assigned by quartiles. The solutions derived with different weighting schemes or even without any weighting agree to within 10 mas. This indicates that the goal of homogenizing the different inputs was accomplished.
Since the final positions originate in the average of multiple combinations, attaching the final error of them to the squared sum of the contributing errors would favor the sources with fewer solutions obtained. Likewise, if attaching the error to the dispersion in the multiple contributing
solutions. It is more realistic to derive the final error in the equatorial coordinates of each source from the external comparison of the LQRF position with the radio position. Since in the construction of the LQRF the three correction steps focused on the achievement of an homogeneous frame, this is done by taking the average of the LQRF minus radio positions for the 10 closest ERF sources around each quasar. As seen before, this implies a typical radius of 4.4![]() around any LQRF quasar. Figure 18 presents the histograms of the errors in the coordinates. The distributions can be identified as Poisson distributions peaking at 139 mas in right ascension and at 130 mas in declination.
around any LQRF quasar. Figure 18 presents the histograms of the errors in the coordinates. The distributions can be identified as Poisson distributions peaking at 139 mas in right ascension and at 130 mas in declination.
The LQRF contains 100 165 sources. On average, every source has a neighbor within 10 arcmin. Figure 19 shows the sky distribution counts within squares of 10![]() .
Empty boxes are found only in the Galactic plane towards the southern hemisphere. Figure 20 presents a vector map of the offsets versus the VLBI positions, in bins of side 30
.
Empty boxes are found only in the Galactic plane towards the southern hemisphere. Figure 20 presents a vector map of the offsets versus the VLBI positions, in bins of side 30![]() and at least 5 quasars. The mean offset is 32.7 mas and their distribution appears as random, with the largest offsets corresponding to bins of only 5 or 6 quasars.
and at least 5 quasars. The mean offset is 32.7 mas and their distribution appears as random, with the largest offsets corresponding to bins of only 5 or 6 quasars.
Figures 21-24 show the optical minus radio coordinates offsets. A comparison with the equivalent Figs. 5-7 illustrates clearly the evenness of the ICRF representation produced by the LQRF positions.
The LQRF catalog is available by means of CDS access (see URL in the first page footnote). An extract of its first page appears in Fig. 25. Its columns contain
- 1.
- the J2000 right ascension (h, m, s);
- 2.
- the J2000 declination (d, ', '');
- 3.
- the external right ascension error (
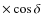 )
(mas);
)
(mas);
- 4.
- the external declination error (mas);
- 5.
- the number of radio interferometry neighbor positions used to evaluate
the external errors;
- 6.
- the R magnitude, taken from the LQAC;
- 7.
- the redshift, taken from the LQAC (blank if not defined);
- 8.
- the right ascension offsets to the radio interferometry position (blank
if there is no radio position) (
)
(mas);
- 9.
- the declination offsets to the radio interferometry position (blank
if there is no radio position) (mas);
- 10.
- the J2000 radio interferometry right ascension (h, m, s) (blank if there is no radio position);
- 11.
- the J2000 radio interferometry declination (h, m, s) (blank if there is no radio position).
7 Summary and perspectives
The LQRF is build to provide an optical representation of the ICRF, retaining the ICRS concept of being defined by extragalactic objects. Starting from the LQAC entries, quasars were indentified in the USNO B1.0, GSC2.3, and SDSS DR5 catalogs. The positions there assigned were ensured to be homogeneous with respect to the HCRF by applying local corrections obtained in small neighborhods around the quasars, relative to the UCAC and 2MASS catalogs. The global orientation was then adjusted to the ICRF and the zonal departures were removed. The ICRF was represented by the ERF, which was formed by accurate long base interferometry radio positions, collected from the ICRF-Ext2, the VCS6, and the VLACalib, and selected to precision better than 10 mas.
![\begin{figure}
\par\includegraphics[width=18cm,clip]{12041fig25.eps}
\end{figure}](/articles/aa/full_html/2009/37/aa12041-09/img70.png) |
Figure 25:
Example extract of the LQRF catalog. Its columns contain the elements as follows. The J2000 right ascension (h, m, s). The J2000 declination (d, ', ''). The external right ascension error (
|
| Open with DEXTER | |
The final LQRF J2000 equatorial cordinates were derived by weighted averages of the input catalog positions, once locally, zonally and globally corrected as indicated. The errors assigned to the LQRF coordinates reflect the departure from the ERF.
The Large Quasar Reference Frame (LQRF) formed in this way contains 100 165 objects, of which 2142 have accurate radio interferometric positions. The comparison between the LQRF positions and the ERF positions indicates that the overall orientation towards the ICRF, as represented by the Euclidean
direction cosines is A1 = +2.1 ![]() 3.8 mas A2 = -0.9
3.8 mas A2 = -0.9 ![]() 3.5 mas A3 = -2.6
3.5 mas A3 = -2.6 ![]() 3.4 mas,
with zero equatorial bias to the level of 2.9 mas. The average offsets to the ICRF are
3.4 mas,
with zero equatorial bias to the level of 2.9 mas. The average offsets to the ICRF are
![]() = +2.7
= +2.7 ![]() 2.9 mas and
2.9 mas and
![]() = +0.3
= +0.3 ![]() 2.9 mas, with standard deviations of
2.9 mas, with standard deviations of
![]() = 134.3 mas and
= 134.3 mas and
![]() = 131.1 mas. The internal
errors are described well by a Poisson representation, peaking at 139 mas in right ascension
and at 130 mas in declination. The LQRF is planned to be maintained and enlarged in the future,
as new versions of the LQAC and other quasar input catalogs appear, as well as to incorporate newer versions of the UCAC stellar reference frame.
= 131.1 mas. The internal
errors are described well by a Poisson representation, peaking at 139 mas in right ascension
and at 130 mas in declination. The LQRF is planned to be maintained and enlarged in the future,
as new versions of the LQAC and other quasar input catalogs appear, as well as to incorporate newer versions of the UCAC stellar reference frame.
Acknowledgements
This worrk would have not existed without the effort and fundibg involved in the projects of the USNO B1.0 (US Naval Observatory), the GSC2.3 (Space Telescope Institute and Osservatório di Torino/IBAF), the Sloan Digitized Sky Survey (Astrophysical Research Consortium for the Participating Institutions), the ICRF (International Earth Rotation Service), the VLBA Calibrator Survey programs (Goddard Space Flight Center NASA), VLA (National Radio Astronomy Observatory), the UCAC project (US Naval Observatory), and the 2MASS-The Two Micron All Sky Survey (NASA - NSF). The authors acknowledge their use. A.H.A. thanks CNPq grant PQ-307126/2006-0 and the Royal Society International Joint Projects support for a visit to the University of Hertfordshire (Dr. H. Jones). J.I.B.C. acknowledges grant 151392/2005-6/CNPq and grant E-26/100.229/2008/FAPERJ. M.A. acknowledges grant E-26/170.686/2004/FAPERJ and grants 306028/2005-0 and 478318/2007-3 (CNPq).
References
- Adelman-McCarthy, J. K., Agüeros, M. A., Allam, S. S., et al. 2007, ApJS, 172, 634 [NASA ADS] [CrossRef] (In the text)
- Andrei, A. H., Assafin, M., Barache, C., et al. 2008, Proc. IAU Symp., 248, 260 [NASA ADS] (In the text)
- Arias, E. F., Charlot, P., Feissel, M., & Lestrade, J.-F. 1995, A&A, 303, 604 [NASA ADS] (In the text)
- Arias, E. F., Feissel, M., & Lestrade, J.-F. 1998, A&A, 199, 357 [NASA ADS]
- Assafin, M., Vieira Martins, R., & Andrei, A. H. 1997, A&A, 113, 1451 (In the text)
- Assafin, M., Andrei, A. H., Martins, R., et al. 2001, ApJ, 552, 380 [NASA ADS] [CrossRef] (In the text)
- Brosche, P. 1966, Veroff. Astron. Rechen-Inst. Heidelberg, 17 (In the text)
- Claussen, M. 2006, VLA Calibrator Manual (In the text)
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003, The IRSA 2MASS All-Sky Point Source Catalog, NASA/IPAC Infrared Science Archive (In the text)
- da Silva Neto, D. N., Andrei, A. H., Vieira Martins, R., & Assafin, M. 2000, AJ, 119, 1470 [NASA ADS] [CrossRef] (In the text)
- da Silva Neto, D. N., Andrei, A. H., Assafin, M., & Vieira Martins, R. 2005, A&A, 429, 739 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Fey, A. L., Ma, C., Arias, E. F., et al. 2004, AJ, 127, 3587 [NASA ADS] [CrossRef] (In the text)
- Fienga, A., & Andrei, A. H. 2002, A&A, 393, 331 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Fienga, A., & Andrei, A. H. 2004, A&A, 420, 1163 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Feissel, M., & Mignard, F. 1998, A&A, 331, 33 [NASA ADS] (In the text)
- Hoeg, E., Bässgen, G., Bastian, U., et al. 1997, A&A, 323, 57 [NASA ADS] (In the text)
- Hoeg, E., Fabricius, C., Makarov, V. V., et al. 2000, A&A, 363, 385 [NASA ADS]
- Lasker, B. M., Lattanzi, M. G., McLean, B. J., et al. 2008, AJ, 136, 735 [NASA ADS] [CrossRef] (In the text)
- Ma, C., Arias, E. F., Eubanks, T. M., et al. 1998, AJ, 116, 516 [NASA ADS] [CrossRef] (In the text)
- Monet, D. G., Levine, S. E., Canzian, B., et al. 2003, AJ, 125, 984 [NASA ADS] [CrossRef] (In the text)
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, 49 [NASA ADS] (In the text)
- Petrov, L., Kovalev, Y. Y., Fomalont, E. B., & Gordon, D. 2006, AJ, 131, 1872 [NASA ADS] [CrossRef] (In the text)
- Pier, J. R., Munn, J. A., Hindsley, R. B., et al. 2003, AJ, 125, 1559 [NASA ADS] [CrossRef] (In the text)
- Souchay, J., Lambert, S. B., Andrei, A. H., et al. 2008a, A&A, 485, 299 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Souchay, J., Andrei, A. H., Barache, C., et al. 2008b, A&A, 485, 299 [NASA ADS] [CrossRef] [EDP Sciences]
- Schwan, H. 1988, A&A, 198, 363 [NASA ADS] (In the text)
- Taff, L. G., Lattanzi, M. G., Bucciarelli, B., et al. 1990a, AJ, 353, 45 [CrossRef] (In the text)
- Taff, L. G., Bucciarelli, B., & Lattanzi, M. G. 1990b, ApJ, 361, 667 [NASA ADS] [CrossRef]
- Véron-Cetty, M.-P., & Véron, P. 2006, A&A, 455, 773 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Zacharias, N. 2007, personal communication (In the text)
- Zacharias, N., Urban, S. E., Zacharias, M. I., et al. 2000, AJ, 120, 2131 [NASA ADS] [CrossRef] (In the text)
- Zacharias, N., McCallon, H. L., Kopan, E., & Cutri, R. M. 2003, IAU GA 25, JD16, Extending the Icrf Into the Infrared: 2MASS-UCAC Astrometry (In the text)
- Zacharias, N., Urban, S. E., Zacharias, M. I., et al. 2004, AJ, 127, 3043 [NASA ADS] [CrossRef] (In the text)
Footnotes
- ... 100 milli-arcsec
![[*]](/icons/foot_motif.png)
- The LQRF is only available in electronic form at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsweb.u-strasbg.fr/cgi-bin/qcat?J/A+A/505/385
All Tables
Table 1: Initial optical to radio relationshipsa.
Table 2: Comparison between the models for the local astrometric solutiona.
Table 3: Mean results from the local astrometric correctionsa.
Table 4: Direction cosines relative to the ERF after the application of the local astrometric correctionsa.
Table 5: Number of significant harmonic terms in the three rounds of testinga.
Table 6: Values of the coefficients of the adjusted harmonic functionsa.
All Figures
| |
Figure 1:
Sky distribution (equatorial coordinates, N up, E right) of the quasars
found in the LQAC catalog. The highest density regions indicate the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 sq |
| Open with DEXTER | |
| In the text | |
| |
Figure 2:
Sky distribution (equatorial coordinates, N up, E right) of the quasars found in the USNO B1.0 catalogs. Again, the highest density regions indicate the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 sq |
| Open with DEXTER | |
| In the text | |
| |
Figure 3: Sky distribution (equatorial coordinates, N up, E right) of the quasars found in the GSC2.3 catalog. As before, the highest density regions mark the SDSS DR5 contribution.The scale represents the number of sources in regions of 9 deg2 shown on the plots. Notice that the scale is slightly different from that of Fig. 2 relative to the B1.0 catalog. |
| Open with DEXTER | |
| In the text | |
| |
Figure 4: Sky distribution (equatorial coordinates, N up, E right) of the enlarged radio frame quasars. The filled symbols mark the sources for which an optical counterpart is found in at least one of the deep, dense source catalogs (B1.0, GSC2.3, DR5). The enlarged radio frame is formed, in order of priority of choice, by the ICRF-Ext2 (718 sources), the VCS6 (2684 sources), and the VLAC (59 sources). |
| Open with DEXTER | |
| In the text | |
| |
Figure 5: USNO B1.0 right ascension and declination offset distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
| In the text | |
| |
Figure 6: GSC2.3 right ascension and declination offsets distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
| In the text | |
| |
Figure 7: SDSS DR5 right ascension and declination offsets distributions relative to the equatorial coordinates axes and the R magnitude. The offsets are given in the sense of catalog minus the radio interferometric positions from the ICRF-Ext2, or the VCS6, or the VLAC. |
| Open with DEXTER | |
| In the text | |
| |
Figure 8: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the UCAC stellar reference frame onto the USNO B1.0 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
| In the text | |
| |
Figure 9: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the 2MASS stellar reference frame onto the USNO B1.0 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
| In the text | |
| |
Figure 10: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the UCAC stellar reference frame onto the GSC2.3 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
| In the text | |
| |
Figure 11: Equatorial coordinates distribution of the local astrometric corrections derived by the six-parameter model using the 2MASS stellar reference frame onto the GSC2.3 quasar positions. The clear points correspond to the quasars for which there are ERF radio positions. |
| Open with DEXTER | |
| In the text | |
| |
Figure 12:
Coincidence of the A1 and A2 direction cosines as obtained either from the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 13:
Declination dependency of the equatorial bias (A4). The plotted averages correspond to bins 10 |
| Open with DEXTER | |
| In the text | |
| |
Figure 14:
Distribution of the coefficients and associated errors of the harmonic functions fitting the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 15:
Averaged
|
| Open with DEXTER | |
| In the text | |
| |
Figure 16:
Averaged
|
| Open with DEXTER | |
| In the text | |
| |
Figure 17: Fast fading of the autocorrelation of the local inhomogeneities correction. In the figure is plotted the standard deviation of the corrections in samples taken in rings of increasing radius. The upper lines correspond to the USNO B1.0 and GSC2.3 families of solutions, while the lower lines correspond the SDSS DR5 families of solutions. |
| Open with DEXTER | |
| In the text | |
| |
Figure 18: Distribution of the external errors assigned to the right ascension and declination J2000 positions of the LQRF sources. The distributions can be reckoned to Poisson distributions peaking at 139 mas on right ascension and at 130 mas on declination. |
| Open with DEXTER | |
| In the text | |
| |
Figure 19:
Sky density of the LQRF. The counts are in bins of 10 |
| Open with DEXTER | |
| In the text | |
| |
Figure 20:
Vectorial distribution of the systematic deviations (north up, east right) of the LQRF to the ICRF within bins of 10 |
| Open with DEXTER | |
| In the text | |
| |
Figure 21:
Distribution on right ascension of the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 22:
Distribution on right ascension of the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 23:
Distribution on declination of the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 24:
Distribution on declination of the
|
| Open with DEXTER | |
| In the text | |
| |
Figure 25:
Example extract of the LQRF catalog. Its columns contain the elements as follows. The J2000 right ascension (h, m, s). The J2000 declination (d, ', ''). The external right ascension error (
|
| Open with DEXTER | |
| In the text | |
Copyright ESO 2009
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.