| Issue |
A&A
Volume 499, Number 3, June I 2009
|
|
|---|---|---|
| Page(s) | 955 - 965 | |
| Section | Astronomical instrumentation | |
| DOI | https://doi.org/10.1051/0004-6361/200810953 | |
| Published online | 16 April 2009 | |
Dome C site testing: surface layer, free atmosphere seeing, and isoplanatic angle statistics
E. Aristidi - E. Fossat - A. Agabi - D. Mékarnia - F. Jeanneaux - E. Bondoux - Z. Challita - A. Ziad - J. Vernin - H. Trinquet
Laboratoire Hippolyte Fizeau, Université de Nice Sophia Antipolis, Parc Valrose, 06108 Nice Cedex 2, France
Received 11 September 2008 / Accepted 17 March 2009
Abstract
This paper analyses 3
![]() years of site testing data obtained at Dome C, Antarctica, based on measurements obtained with three DIMMs located at three different elevations. Basic statistics of the seeing and the isoplanatic angle are given, as well as the characteristic time of temporal fluctuations of these two parameters, which we found to around 30 min at 8 m. The 3 DIMMs are exploited as a profiler of the surface layer, and provide a robust estimation of its statistical properties. It appears to have a very sharp upper limit (less than 1 m). The fraction of time spent by each telescope above the top of the surface layer permits us to deduce a median height of between 23 m and 27 m. The comparison of the different data sets led us to infer the statistical properties of the free atmosphere seeing, with a median value of 0.36 arcsec. The Cn2 profile inside the surface layer is also deduced from the seeing data obtained during the fraction of time spent by the 3 telescopes inside this turbulence. Statistically, the surface layer, except during the 3-month summer season, contributes to 95 percent of the total turbulence from the surface level, thus confirming the exceptional quality of the site above it.
years of site testing data obtained at Dome C, Antarctica, based on measurements obtained with three DIMMs located at three different elevations. Basic statistics of the seeing and the isoplanatic angle are given, as well as the characteristic time of temporal fluctuations of these two parameters, which we found to around 30 min at 8 m. The 3 DIMMs are exploited as a profiler of the surface layer, and provide a robust estimation of its statistical properties. It appears to have a very sharp upper limit (less than 1 m). The fraction of time spent by each telescope above the top of the surface layer permits us to deduce a median height of between 23 m and 27 m. The comparison of the different data sets led us to infer the statistical properties of the free atmosphere seeing, with a median value of 0.36 arcsec. The Cn2 profile inside the surface layer is also deduced from the seeing data obtained during the fraction of time spent by the 3 telescopes inside this turbulence. Statistically, the surface layer, except during the 3-month summer season, contributes to 95 percent of the total turbulence from the surface level, thus confirming the exceptional quality of the site above it.
Key words: site testing - atmospheric effects
1 Introduction
The Italo-French Concordia station located on the Dome C site of the Antarctic plateau has been attracting more and more interest from the astronomical community since its official opening in 2005. The dry, cold and clean air as well as the absence of aerosols and light pollution are obvious advantages for infrared astronomy. The long nights and days are well suited for long term monitoring programs. The vertical repartition of the turbulence is regarded as extremely interesting for high angular resolution imaging.
It is now well known that the surface seeing on the Antarctic plateau is quite poor. It has been measured at about 1.7 arcsec in the visible at the South Pole (Marks et al. 1999; Travouillon et al. 2003). However, microthermal radio soundings by balloon-borne sensors estimated a seeing that would be around 0.3 arcsec above a turbulent surface layer (SL), measured to be of 200 m thickness at the South Pole. Because of the geographical situation, this SL is expected to be much thinner at Concordia (see for instance Swain at Gallee 2006). Indeed, the same radio soundings made at Concordia during the first winter-over season in 2005 revealed a median thickness of 32 m and a seeing likely to be of the order of 0.4 arcsec or better above it, while it is not significantly better than at the South Pole at surface level (Trinquet et al. 2008a).
The important parameters to be explored in more detail are the statistical behaviour of the SL thickness, the seeing above it (noted hereafter as above surface layer (ASL) to avoid confusion with the so-called free atmosphere that starts a few hundred meters higher), their possible seasonal dependence, and the isoplanatic angle, again with its seasonal dependence. The summer seeing parameters have been extensively studied (Aristidi et al. 2004). A first estimation of the free atmosphere seeing was provided by a SODAR+MASS analysis by Lawrence et al. (2004). The exceptionally small values of the turbulence outer scale have been measured by the GSM (Ziad et al. 2008), and also deduced from winter radio soundings (Trinquet et al. 2008b), while the isopistonic angle has been estimated by Elhalkouj et al. (2008) who demonstrated that a 3 m telescope at Dome C would have the same isopistonic angle as the Keck in Hawaii.
This paper shows that 3 DIMMs operated at 3 different altitudes can be exploited like a turbulence profiler of the SL, and can give access to both its geometrical statistics and its typical Cn2 content and profile. Given the fraction of time spent by these DIMMs above the upper limit of the SL, the free atmosphere seeing is also accessible with a robust statistical significance. The time dependence of the seeing parameters, on short scales as well as the possible seasonal variations, is also adressed. A surprising result is the very large fraction (nearly 95%) of the total turbulence found to be inside this thin SL, making the site conditions very useful just above it.
2 Results
2.1 Seeing statistics
The seeing measurements exploited here consist of 3 different time series. The main one was obtained by the DIMM located on the wooden Concordiastro platform (about 8 m height) during the first summer campaign (2003-2004) and then nearly continuously since December 2004, thus covering more than 3 and a half years of data in 320 000 measurements (a seeing point is computed from a set of 2 min of data). The overal duty cycle since December 2004 is of 36%. A fraction of the missing measurements of around 10% (Mosser & Aristidi 2007) is due to adverse weather, the rest to technical difficulties. However, the longest permanent gap during these nearly continuous 3 and a half years is less than 18 days. Each of the 14 consecutive seasons covered by this data set has enough measurements to undertake significant statistical studies. A second time series comes from the ground-based DIMMs operated as a GSM instrument (Ziad et al. 2008). It contains 227 000 measurements covering the period from December 2004 to April 2008. The duty cycle during this period was only of 25%, including a gap longer than 6 months during the winter 2006 (fatal technical failure). During the period July-October 2005, one of the telescopes of the GSM experiment was moved to the roof of the so-called calm building of Concordia and provided 24 000 measurements at an elevation of 20 m above the ground. GSM is composed of 2 identical DIMMs operated at about 3 m above the plateau. For 3 months in the winter and spring periods, it was then possible to obtain simultaneous values of the seeing from 3 different heights: 3 m, 8 m and 20 m. The 20 m monitor was however located at a horizontal distance of 300 m from the two others, and is suspected to be contamined by local turbulence generated by the building, even though it was exposed in the prevaling wind direction.
Daily and monthly averages of the seeing are plotted as a function of time in Fig. 1. We see a strong dependence of the seeing with the season. The best conditions are observed in the summer with a median of 0.54
![]() at an elevation of 8 m, then the seeing degrades to values around 2
at an elevation of 8 m, then the seeing degrades to values around 2
![]() in August. This behaviour was noticed since the first winterover (Agabi et al. 2008; Trinquet et al. 2008a), and seems to occur every year. It was explained by the occurrence, in winter, of a strongly turbulent SL whose thickness is about 30 m (Trinquet et al. 2008a). Seeing values at the three available elevations are summarized in Table 1.
in August. This behaviour was noticed since the first winterover (Agabi et al. 2008; Trinquet et al. 2008a), and seems to occur every year. It was explained by the occurrence, in winter, of a strongly turbulent SL whose thickness is about 30 m (Trinquet et al. 2008a). Seeing values at the three available elevations are summarized in Table 1.
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg1a.eps}\vspace*{3mm}
\includegraphics[width=9cm,clip]{0953fg1b.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img6.png) |
Figure 1: Top: daily average seeing at an elevation of 8 m as a function of time. Bottom: monthly seeing for the three elevations 3 m, 8 m and 20 m respectively. Seeing scale is logarithmic. |
| Open with DEXTER | |
Table 1: Global seeing statistics for the three available DIMM data.
The large volume of the available data set encourages us to use the basic tools of statistics, the simplest one being histograms. A first histogram looked at is the longest time series, including all seasons and obtained at 8 m height (Fig. 2). It shows a bi-modal distribution, each one of the two peaks having a log-normal shape. However, this all-season histogram mix the very different conditions that prevail in summer and winter. It is then highly preferable to analyse the histograms season by season, this being permitted by the large size of the data sets. The seasons are called Summer (when the Sun never set, Nov. 1st-Feb. 4th), Winter (when it never rises, May 4th-August 11th), the other two being Autumn (Feb. 4th-May 4th) and Spring (August 11th-Nov. 1st). Figure 3 is an example of a winter histogram (2006). The bi-modal appearance is more striking, with a sharp peak of excellent seeing centered at 0.3 arcsec, and a broader peak of poor seeing located around 1.7 arcsec. As this is a one-season histogram, the bi-modal appearance cannot be interpreted as possible evidence for two different regimes of summer and winter. It seems to indicate that the telescope stands either inside or outside the SL. This indicates that the upper limit of the SL must be rather sharp.
We attempted to model the histograms by a sum of two log-normal functions, but it failed in the dip between the two curves. A sum of three log-normal functions was required to obtain the good fit that is visible here. Figure 4, for comparison, is an autumn histogram, from 2007. It shows a very similar general behaviour: a poor seeing distribution, now peaked around 1.3 arcsec, a good seeing distribution still peaked at 0.3 arcsec, and a similar third component. The fitted functions are defined by
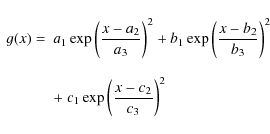
where x is the natural logarithm of the seeing. The addition of these histograms assumes that the SL and the ASL atmosphere are statistically independent. The interpretation of these curves is that most of the time, the telescope is embedded inside the SL (curve c), while for a smaller fraction of the time, it is totally outside the SL (curve a). There remains an intermediate situation (curve b) that can correspond to two cases: (i) the SL is not unique, but contains a second (and weaker) layer above the telescope (such situations were shown by the radio soundings, see Fig. 9 for examples); (ii) the SL upper limit is just in front of the entrance window of the telescope and moves slightly up and down during the two-minute integration time of one seeing measurement.
![\begin{figure}
\includegraphics[width=9cm,clip]{0953fg2.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img9.png) |
Figure 2: The histogram of 3 and a half years of DIMM seeing data recorded at an elevation of 8 m on the Concordiastro platform reveals two different regimes corresponding to good and bad seeing. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg3.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img10.png) |
Figure 3: The fit of 3 log-normal curves of the winter 2006 histogram of the 8 m DIMM. It clearly distinguishes 3 different situations: a) an excellent seeing distribution, corresponding to situations where the telescope is above the SL; c) a poor seeing distribution (the telescope is totally embedded inside the SL); b) the distribution of less frequent intermediate events. |
| Open with DEXTER | |
![\begin{figure}
\includegraphics[width=9cm,clip]{0953fg4.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img11.png) |
Figure 4: An autumn histogram showing a situation very similar to the winter one displayed in Fig. 3, the only difference being the weaker turbulent energy inside the SL (the maximum of the curve (c) is centered on a smaller value). |
| Open with DEXTER | |
2.2 A statistical model of the surface layer
As the three telescopes have been operated at 3 different altitudes the histograms and their modeling by the sum of log-normal functions give access to a 3-level vertical profile of the turbulence strength Cn2 inside the SL, season by season. Indeed, curve (a) shows almost no displacement all year round and can then be regarded as representing the seeing above the SL: it provides a robust estimation of the ASL seeing probability density function (PDF); this will be discussed in Sect. 2.5. Its surface gives the probability of the SL of being thinner than the telescope height (respectively 18% and 24% in the examples shown in Figs. 3 and 4). Similarly, the curve (c) gives the probability of the main part of the SL being thicker than the telescope height (respectively 70% and 65% in the same examples).
The histogram of the data set of the 20 m high DIMM gives a probability of about 45% of it being outside the SL. It is interesting to compare it with the histograms of the data obtained simultaneously at 8 m (Fig. 5). Though the telescopes were not absolutely synchronized and each data set exhibits different gaps, these measurements were made during the same 3 and a half months.
The left peak of the two histograms of Fig. 5 is expected to represent the same function, i.e. the ASL seeing PDF, as will be discussed in Sect. 2.5. There should only be a difference in the weight of these functions regarding the total seeing distribution (18% at 8 m, 45% at 20 m). Figure 6 shows the ratio (20 m/8 m) of the two normalized histograms. In its left part (i.e. for seeing values below 0.5 arcsec) it should tend towards the ratio of the two ASL PDFs, i.e. the ratio of two identical functions, which is a constant. This constant is the ratio of 45% to 18%, i.e. 2.5. However this expected saturation of the graph for small values (represented with the dashed line in Fig. 6) is not observed. Instead, we have a depletion for seeings between 0.1 and 0.3 arcsec, and too many points in the range 0.3-0.45 arcsec. The extreme values, around 0.1 arcsec, are missing at 20 m while they sometimes do appear at 8 m. Very likely, the seeing measurements made by this DIMM situated on the roof of the building suffer from the large amplitude mechanical vibrations created by this situation.
Extreme seeing values of 0.1
![]() to 0.25
to 0.25
![]() are biased, and measured in the range 0.3
are biased, and measured in the range 0.3
![]() -0.45
-0.45
![]() .
However, the mean value of this ratio between 0.1 and 0.45 arcsec remains equal to 2.5. This supports the robustness of the DIMM measurements, that appears to be insensitive to the building vibrations if the seeing is not better than 0.3 or 0.4 arcsec.
.
However, the mean value of this ratio between 0.1 and 0.45 arcsec remains equal to 2.5. This supports the robustness of the DIMM measurements, that appears to be insensitive to the building vibrations if the seeing is not better than 0.3 or 0.4 arcsec.
The third data set, excluding summers, from the ground-based DIMM is shown in Fig. 7. The mean seeing is poor, almost 2 arcsec on average, but two bumps of extremely good (curve a) and very good (curve b) seeing, around 0.3 and around 0.65 arcsec are seen. They correspond respectively to probabilities of 2% and 5%. Curve a shows a small fraction of ASL seeing, when the SL is totally confined below 3 m or vanishes, while the other one shows the intermediate situation. This is further confirmation of the sharpness of the upper edge of the SL, when its total thickness is not higher than 2 or 3 m.
Table 2 gives the fits for all individual seasons and for the 3 telescopes. In most cases, they are the result of the 3-curve fit described above. In a few situations, a 2-curve fit was sufficient.
2.3 The surface layer thickness
| |
Figure 5: Histograms of the seeing obtained during the same 4 months in 2005 at 8 m and 20 m showing how much the seeing improves in this 12 m vertical interval. Quantitatively, they provide the probabilities of beeing above the SL at these two altitudes. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{0953fg6.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img13.png) |
Figure 6: Ratio of the two histograms of Fig. 5. The dashed line at count ratio = 2.5 corresponds to the expected horizontal asymptote of the curve when the seeing tends to zero (see text). |
| Open with DEXTER | |
Table 2 shows that the SL significantly changes with the season, being stronger in winter, weaker in autumn, and intermediate in Spring. We already know that it is definitely much weaker in summer, even disappearing totally every day at 5 p.m. However it seems that only its turbulent energy changes, and not its geometry. The small variations of the mean probabilities (integral of curve c) between Autumn, Winter and Spring are not statistically significant. All these probabilities can then be plotted as a function of altitude (Fig. 8). Assuming that sometimes the SL contains a second component above the first main one, this plot shows two probabilities for each value
![]() of the height: the highest means all the content of the SL is less than
of the height: the highest means all the content of the SL is less than
![]() ,
while the lowest means only the main, most energetic part of this SL is less than
,
while the lowest means only the main, most energetic part of this SL is less than
![]() .
The 3-curve fits on the DIMM data sets provide these numbers at 3, 8 and 20 m. At higher altitudes, a hint can be obtained from the 2005 winter radio soundings (Trinquet et al. 2008a). Figure 9 shows the 32 available SL profiles with a vertical resolution of the order of 5 to 10 m (depending on the vertical speed of the balloons). It shows a turbulent profile drastically changing from sample to sample, and ending very sharply, at a mean height of about 30 m, and sometimes including a second bump. We estimate the two probabilities from the profiles up to an elevation of 50 m. The error bars of the DIMM measurements come from both the scatter of individual seasonal histograms at 8 m, and from the statistical error. The error bars for the balloon points assume that all the radio soundings are independent, with a Poisson probability (the mean equals the variance). From this figure, the mean and the median SL thickness are both of the order of 25 m.
.
The 3-curve fits on the DIMM data sets provide these numbers at 3, 8 and 20 m. At higher altitudes, a hint can be obtained from the 2005 winter radio soundings (Trinquet et al. 2008a). Figure 9 shows the 32 available SL profiles with a vertical resolution of the order of 5 to 10 m (depending on the vertical speed of the balloons). It shows a turbulent profile drastically changing from sample to sample, and ending very sharply, at a mean height of about 30 m, and sometimes including a second bump. We estimate the two probabilities from the profiles up to an elevation of 50 m. The error bars of the DIMM measurements come from both the scatter of individual seasonal histograms at 8 m, and from the statistical error. The error bars for the balloon points assume that all the radio soundings are independent, with a Poisson probability (the mean equals the variance). From this figure, the mean and the median SL thickness are both of the order of 25 m.
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg7.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img14.png) |
Figure 7: Histogram of the seeing data taken by the 3-m DIMM, as usual excluding summers. As for Fig. 3, curves (a), (b), (c) represent the three log-normal fits. The mean seeing is quite poor (close to 2 arcsec), but the excellent and intermediate seeing situations are still visible, even with a telescope mount placed on the snow surface, with probabilities of about 2% and 5%. |
| Open with DEXTER | |
Table 2: Table of fitted parameters relevant to Eq. (1) for the 3 DIMMs at 3, 8 and 20 m and for each season and/or each year.
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg8.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img23.png) |
Figure 8: Probabilities of being inside the SL as a function of altitude above the snow surface. See text (Sect. 2.3) for details. |
| Open with DEXTER | |
![\begin{figure}
{%
\includegraphics[width=142mm]{0953fg9a.eps}\\ \includegraphics[width=142mm]{0953fg9b.eps} %
}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img24.png) |
Figure 9: 32 samples of the SL Cn2 vertical distribution in the first 80 m above the ground, measured during winter 2005 by balloon radio soundings. The horizontal axis is Cn2 in units of 10-13 m-2/3 and the vertical axis is the altitude over the ground in meters. Note that the Cn2 is displayed in linear scale (it is often shown in log scale). |
| Open with DEXTER | |
2.4 The Cn2 vertical distribution inside the surface layer
The Cn2 vertical distribution inside the surface layer can be inferred from curves c. The subsets of data that provide these ``poor seeing'' parts of the histograms correspond to all situations when the SL exceeds the altitude of each telescope. The seeing produced both by the upper part of the SL, above the telescope located at the altitude ![]() ,
and the rest of the free atmosphere, is defined by:
,
and the rest of the free atmosphere, is defined by:
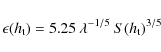
where
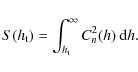
The three seeing data sets corresponding to the period Jul.-Oct. 2005 were binned into 15 mn intervals (to increase the probability of finding simultaneous events, and also to account for the possible difference in the internal clock of the computers). This value of 15 mn was chosen because it is shorter than the characteristic time of seeing fluctuations (discussed in Sect. 2.7). That led to 901 triplets S(h1), S(h2) and S(h3) at altitudes h1=3 m, h2=8 m and h3=20 m. Two different analyses were made from these data, giving similar results.
2.4.1 First analysis
The first calculation was made from the mean values ![]() of S(hi). The 3 mean values for the 3 altitudes are
of S(hi). The 3 mean values for the 3 altitudes are
![]() ,
,
![]() and
and
![]() .
.
As we are interested in the content of the SL only, we first subtracted the contribution of the ASL turbulence, estimated from the mean seeing of 0.36 arcsec deduced from the integral of curves a, i.a.
![]() .
This gives 3 values, denoted as Si which are:
S1 = 24.87,
S2 = 13.87 and
S3 = 6.27 in units of
.
This gives 3 values, denoted as Si which are:
S1 = 24.87,
S2 = 13.87 and
S3 = 6.27 in units of
![]() .
These values average all measurements, they include situations when the telescopes are inside the SL and are above the SL. The latter does not provide information on the SL content. To estimate the mean value of Cn2 inside the SL, we need the mean value of S restricted to the situations when the telescope is located inside the SL. This is obtained by dividing the 3 values of Si by the corresponding probabilities P(hi) of being inside the SL. Then we obtain 3 triplets
.
These values average all measurements, they include situations when the telescopes are inside the SL and are above the SL. The latter does not provide information on the SL content. To estimate the mean value of Cn2 inside the SL, we need the mean value of S restricted to the situations when the telescope is located inside the SL. This is obtained by dividing the 3 values of Si by the corresponding probabilities P(hi) of being inside the SL. Then we obtain 3 triplets
![]() .
.
A simplified 3-level quantitative model of Cn2(h) inside the SL can then be estimated from 3 to 20 m and can be compared to the average of the 32 samples provided by the radio soundings, after correction for the probability P(h) for the same reason as above (the averaged profile at a given altitude contains a fraction of events outside the SL).
As an integral is an additive process, the differences
![]() and
and
![]() provide the mean values of Cn2 respectively between 3 and 8 m and between 8 and 20 m. The results are
provide the mean values of Cn2 respectively between 3 and 8 m and between 8 and 20 m. The results are
![]() between 3 m and 8 m and
between 3 m and 8 m and
![]() .
.
![]() itself is the integral of Cn2 from 20 m to the top of the SL. The mean altitude of the SL when it is higher than 20 m can be estimated from the radio soundings. This conditional mean is of the order of 40 m, that indicates a mean value of Cn2 in the altitude range
itself is the integral of Cn2 from 20 m to the top of the SL. The mean altitude of the SL when it is higher than 20 m can be estimated from the radio soundings. This conditional mean is of the order of 40 m, that indicates a mean value of Cn2 in the altitude range
![]() of
of
![]() .
Figure 10 shows the comparison of this rough, 3-layer profile with the one obtained from the balloon radio soundings. No information is available near the snow surface, below the lowest telescope. It would not make sense to extend the curves above 40 m, where the statistical information is poor (the SL does not reach this altitude more than 10% of the time). The two integrals up to 40 m agree within 10%, which is good, given the two very different technical approaches and the non simultaneity of the measurements. It is clear that the radio soundings do not provide reliable values below 20 m. Il seems also clear from the DIMM data that the lowest layers are by far the most turbulent. Around 50% of the turbulent energy of the SL is in the first 10 to 15 m, and 95% of the turbulent energy of the total atmosphere is inside the SL, which is more than previously thought.
.
Figure 10 shows the comparison of this rough, 3-layer profile with the one obtained from the balloon radio soundings. No information is available near the snow surface, below the lowest telescope. It would not make sense to extend the curves above 40 m, where the statistical information is poor (the SL does not reach this altitude more than 10% of the time). The two integrals up to 40 m agree within 10%, which is good, given the two very different technical approaches and the non simultaneity of the measurements. It is clear that the radio soundings do not provide reliable values below 20 m. Il seems also clear from the DIMM data that the lowest layers are by far the most turbulent. Around 50% of the turbulent energy of the SL is in the first 10 to 15 m, and 95% of the turbulent energy of the total atmosphere is inside the SL, which is more than previously thought.
From these results, we can propose a description of the ``typical'' SL: starting at an altitude
![]() m, ending very sharply at a variable altitude
m, ending very sharply at a variable altitude
![]() with an exponential probability, and with a content that can be deduced from both the poor seeing measurements and the winter balloon radio soundings. Figure 11 shows this typical SL. This figure is a ``typical'' example, valid at one given moment, and is not an average. Several radio soundings look very much like this model (flights number 544, 559, 565 or 568).
with an exponential probability, and with a content that can be deduced from both the poor seeing measurements and the winter balloon radio soundings. Figure 11 shows this typical SL. This figure is a ``typical'' example, valid at one given moment, and is not an average. Several radio soundings look very much like this model (flights number 544, 559, 565 or 568).
2.4.2 Second analysis
![\begin{figure}
\par\includegraphics[width=9.7cm,clip]{0953fg10.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img45.png) |
Figure 10: The mean value of Cn2 inside the turbulent SL, seen by the radio soundings (continuous curve) and modelled from the 3 DIMMs time series (triangles). The first few meters above the surface are poorly estimated. Given the different technologies and the different epochs of these measurements, the general agreement above 8 m is satisfactory. Values of Cn2 at each altitude take in account the situations where the SL reaches at least this altitude (it is not an average including the nearly zero values when the SL is entirely below this altitude), as described in the text. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg11.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img46.png) |
Figure 11: A ``typical'' example of the Cn2 SL. The upper limit is always extremely sharp. |
| Open with DEXTER | |
We made a second analysis on the integral triplets S(h1), S(h2) and S(h3). The idea is to compute instantaneous values of the SL thickness
![]() for every occurrence of simultaneous measurements by the 3 DIMMs.
We modelled the function Cn2(h) by a piecewise function equal to a negative exponential law in the interval
for every occurrence of simultaneous measurements by the 3 DIMMs.
We modelled the function Cn2(h) by a piecewise function equal to a negative exponential law in the interval
![]() (
(![]() is the lower limit
of the surface layer) and 0 outside the interval (see Fig. 11).
The function
is the lower limit
of the surface layer) and 0 outside the interval (see Fig. 11).
The function
![]() is then
is then
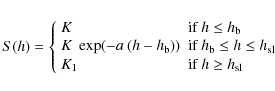 |
(4) |
with
The roof-based DIMM could be either outside or inside the SL (as illustrated by Fig. 12). The latter corresponds to a function ln(S(h)) showing 3 aligned points with a slope -a which was computed by least-square fitting on the 3 points. Otherwise, the slope was computed using only the points 1 and 2. The value of
![]() was computed so that
was computed so that
![]() (i.e. the turbulent energy above the SL represents 5% of the turbulent energy above
(i.e. the turbulent energy above the SL represents 5% of the turbulent energy above ![]() ).
).
This was applied to all the seeing triplets and led to a mean value
![]() m and a median of 27 m, which is a little more pessimistic that our previous analysis. The time series of
m and a median of 27 m, which is a little more pessimistic that our previous analysis. The time series of
![]() and its statistics are shown in Fig. 13.
and its statistics are shown in Fig. 13.
2.5 The ASL seeing
The values of the left peaks of all seeing histograms (excluding summers) can be summed to provide a PDF of the ASL seeing that proves to be, within our statistics, independent of the season and of the altitude in the first 20 m, provided that the SL is completely below this altitude. Figure 14 shows the sum of 10 seasons (3 winters, 3 springs and 4 autums). It can be regarded as a very robust estimation of the ASL PDF of the seeing, especially since it does not appear to depend on the season. We know that the high altitude winds increases in winter and reduce, for instance, the isoplanatic angle, but they do not significantly influence the seeing. Even the very peculiar case of summer (see Sect. 2.6) shows a mean seeing of the order of 0.3 arcsec at 5 p.m. local time, when the SL essentially disappears, so that the ASL seeing becomes accessible every day for a moment at surface level. This PDF, with a log-normal distribution, is characterized by two key numbers: seeing
![]() arcsec, and median = 0.36 arcsec. Further statistics are displayed in Fig. 14.
arcsec, and median = 0.36 arcsec. Further statistics are displayed in Fig. 14.
![\begin{figure}
\par\includegraphics[width=8.2cm,clip]{0953fg12.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img57.png) |
Figure 12:
Piecewise model for S(h). Points 1, 2 and 3 correspond to the DIMMs at elevations h1, h2 and h3. Two situations are shown. (1) theSL upper limit
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg13.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img58.png) |
Figure 13:
SL thickness
|
| Open with DEXTER | |
2.6 The peculiar case of the summer seeing
In summer, the SL becomes much weaker as both the temperature and the wind speed gradients are significantly weaker than in cold seasons. As already mentioned several times (i.e. Aristidi et al. 2004), they even disappear every day at 5 p.m, while these gradients are similar to the winter conditions at local midnights. This seeing depending strongly on local time does not permit the histograms to discriminate different situations that are not sharply separated. The summer histograms tend to show a unique log normal distribution (Fig. 15), with a mean seeing much better than in other seasons but with the ASL seeing being lost in the mixing of the different situations. Only the daily average at 5 p.m permits us to confirm that this ASL seeing is, again, the same as in all other seasons.
We thus selected the seeing data (at elevation 8 m) measured in summer (we selected only the months of December and January, the closest to the summer solstice) in the local time range 4pm-6pm, i.e. a 2 h interval in which the seeing is usually the best. Results are shown in Fig. 15. The statistics of such events is indeed very close to the FA distribution presented above, the mean and the median value being identical.
The same analysis made on the 3 m DIMM data shows a minimum median value of the seeing of 0.57 arcsec at 5 pm. This is much greater than the FA median seeing of 0.36 arcsec, and would indicate that the SL does not totally disappear and that there is still a little turbulence between 3 and 8 m that may be caused by surface effects.
![\begin{figure}
\par\includegraphics[width=88mm]{0953f14.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img59.png) |
Figure 14: Distribution of the ASL seeing at Concordia, measured during 10 seasons between 2005 and 2008, and excluding summers. The table on the right the corresponding statistics. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg15.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img60.png) |
Figure 15: Histogram and statistics of the seeing values corresponding to the period 4pm-6pm in summer (December and January). The superimposed solid curve is the ASL seeing distribution. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=9cm,clip]{0953fg16.eps}\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img61.png) |
Figure 16: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken in summer and in winter winters with the DIMM at an elevation of 3 m. |
| Open with DEXTER | |
2.7 Temporal fluctuations of the seeing
This is an important point to consider high angular resolution imaging. Temporal fluctuations of the seeing were studied by Racine (1996) and by Ziad et al. (1999) and gave a characteristic time of 17 min for the two temperate sites of Mauna Kea and La Silla. At Dome C, we noticed that the periods of ``good'' seeing (0.3 arcsec or lower) are shorter than the periods of ``bad'' seeing (>1 arcsec) and we propose here a different approach to estimate the characteristic time of seeing fluctuations as a function of the seeing. It is quite a difficult question as we lack very long sequences of uninterrupted data sets. For various technical reasons, our data sequences have interruptions that make this specific statistical study somewhat inaccurate.
We define here an interval of stability as a continuous period of time in which the seeing is less than a given threshold s0. We denote as ts its length. In this interval, we allow the seeing to be greater than or equal to s0 during 10% of ts. For example if the seeing is less than 0.5 arcsec for one hour with a small interruption of 5 min, this interruption is neglected and ts will be set to one hour. For a given value of s0, the histogram of ts shows a negative exponential behaviour whose mean is taken as the characteristic time of the seeing stability (for an exponential distribution, the mean is the 63% level). The minimum possible value of ts is 2 min, which is the temporal sampling of the DIMMs. Events correspondigs to ts = 2 mn occur quite often when the seeing fluctuations are large or when s0 is close to the actual seeing value. They tend to bias the calculation of the mean of ts and are thus neglected.
We performed this analysis for the DIMMs located at elevations 8 m and 3 m for the summer and the winter periods. The result is displayed in Figs. 16 and 17. One can see that the characteristic time increases with the seeing and saturates. It is of the order of half an hour in winter for seeing values around 0.5 arcsec at elevation 8 m, while it is only 10 min at an elevation of 3 m.
The curves are likely to be polluted by the interruptions of the observations. The ``up-time'' intervals have a mean of 90 min in summer and 82 min in winter for the DIMM at 8 m. It is 199 min in summer and 138 min in winter for the DIMM at 3 m. The saturation of the curves is due both to the fact that the seeing has a maximum value (and the saturation is observed when the threshold becomes of the order of this maximum value), and due to the interruptions.
We did the same analysis for the seeing data taken by the DIMM on the roof of the base. Since the covered period is much shorter (100 days between July and October 2005), we present in Fig. 18 the curves of ts versus s0 for this period of time for the 3 heights (3 m, 8 m and 20 m). This graph shows that the characteristic time is longer at the height of 20 m (the gain is more than 50% for a seeing s0=0.5 arcsec).
2.8 Isoplanatic angle
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg17.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img62.png) |
Figure 17: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken in summer and in winter with the DIMM at an elevation of 8 m. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg18.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img63.png) |
Figure 18: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken at the three elevations between July and October 2005. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg19.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img64.png) |
Figure 19:
Isoplanatic angle |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg20.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img65.png) |
Figure 20: Isoplanatic angle histograms and statistics. Values are in arcsec. |
| Open with DEXTER | |
Direct measurements of the isoplanatic angle ![]() can be obtained by observing the scintillation of a single star through an aperture of diameter 10 cm with a central obstruction of 4 cm (Loos & Hogge 1979). The scintillation index
can be obtained by observing the scintillation of a single star through an aperture of diameter 10 cm with a central obstruction of 4 cm (Loos & Hogge 1979). The scintillation index ![]() (intensity variance normalized by the square of the mean intensity) of the star at a zenithal angle z can be related to the isoplanatic angle by
(intensity variance normalized by the square of the mean intensity) of the star at a zenithal angle z can be related to the isoplanatic angle by
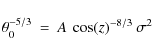 |
(5) |
with A=0.1963. We used for these measurements a telescope of GSM during GSM down time. Details of this so-called ``DIMM-
A total of 46 653 values of ![]() were obtained. They are sparsely distributed over the period 2004-2006; data are available for the months of January 2004, May to July 2005 and January to May 2006. Statistics and the histogram of the distribution are shown in Fig. 20. We found a median value of 3.9
were obtained. They are sparsely distributed over the period 2004-2006; data are available for the months of January 2004, May to July 2005 and January to May 2006. Statistics and the histogram of the distribution are shown in Fig. 20. We found a median value of 3.9
![]() ,
which is slightly lower than the 5.7
,
which is slightly lower than the 5.7
![]() found by Lawrence et al. (2004) with MASS but still very competitive compared to more classical sites (Table 1 of Lawrence et al. 2004). Our value is very close to the South Pole isoplanatic angle of 3.2
found by Lawrence et al. (2004) with MASS but still very competitive compared to more classical sites (Table 1 of Lawrence et al. 2004). Our value is very close to the South Pole isoplanatic angle of 3.2
![]() as estimated by Marks et al. (1999) from in situ radio soundings. This is not surprising; the isoplanatic angle expressed as a weighted integral over the vertical distribution of turbulence is
as estimated by Marks et al. (1999) from in situ radio soundings. This is not surprising; the isoplanatic angle expressed as a weighted integral over the vertical distribution of turbulence is
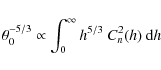 |
(6) |
the weight h5/3 gives more sensitivity to the high altitude turbulence. Both sites of Dome C and South Pole actually exhibit strong winds in winter above 10 km (Marks et al. 1999; Trinquet et al. 2008a).
Figure 19 shows the dependence of ![]() on the period of the year. Data are daily averaged and plotted as a function of the month regardless of the year. We see that
on the period of the year. Data are daily averaged and plotted as a function of the month regardless of the year. We see that ![]() is better in summer (about 7
is better in summer (about 7
![]() ), and decreases to 3
), and decreases to 3
![]() in winter. This is consistent with the value of 2.7
in winter. This is consistent with the value of 2.7
![]() published by Trinquet et al. (2008a) estimated from radio soundings.
published by Trinquet et al. (2008a) estimated from radio soundings.
Temporal fluctuations of ![]() were investigated as well. The method described in Sect. 2.7 was applied to compute the mean time where the isoplanatic angle is greater than a given value
were investigated as well. The method described in Sect. 2.7 was applied to compute the mean time where the isoplanatic angle is greater than a given value ![]() .
The curve displayed in Fig. 21 unsurprisingly shows a negative slope with a saturation of the first points (i.e. values below 1 arcsec) due to the gaps in the data. We can see that the periods where
.
The curve displayed in Fig. 21 unsurprisingly shows a negative slope with a saturation of the first points (i.e. values below 1 arcsec) due to the gaps in the data. We can see that the periods where ![]() is greater than 5 arcsec last 40 min on average.
is greater than 5 arcsec last 40 min on average.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0953fg21.eps}
\end{figure}](/articles/aa/full_html/2009/21/aa10953-08/img71.png) |
Figure 21:
Mean duration of intervals in which the isoplanatic angle is greater than a given value |
| Open with DEXTER | |
3 Conclusion
We have presented statistics of the seeing and isoplanatic angle at Dome C using all the DIMM data collected from the beginning of our observations about 4 years ago. Previous results were published in Aristidi et al. (2004) for the summer data and Agabi et al. (2008) for the first half of the first winter. We confirm here the general trend from these first data, i.e. that the seeing is exceptional in summer and can reach values of 0.3 arcsec at a few meters above the ground, and that it degrades to very poor values of around 2 arcsec in winter. The cause is the occurrence of a very strong turbulent layer near the surface that appears in winter. This situation was reproduced 3 times, leading to a sinusoide like curve of the seeing as a function of time. The isoplanatic angle, first found to be excellent in summer (median value of 7 arcsec) also degrades in winter, but not for the same reason. It has been shown that the wind speed increases at high altitude in the free atmosphere in winter (Trinquet et al. 2008a; Geissler & Masciadri 2006) which creates high altitude turbulence and divides the isoplanatic angle by a factor of 2 in winter, although the seeing itself does not display significant variations.
The temporal stability of the seeing and the isoplanatic angle at Dome C have been adressed for the first time, and provide answers to key questions. We found (at 8 m) that the characteristic time for the seeing being lower than a given threshold is around 30 min if this threshold is 0.5 arcsec, i.e. for the periods of ``good'' seeing. The same order of magnitude holds for the isoplanatic angle, since the characteristic time of stability for values higher than 5 arcsec is also around 30 mn.
Using DIMMs at three different elevations, and through the very special geometry of the SL, it is possible to discriminate clearly the ASL from the SL seeing and to study the statistical properties of both. This is a very remarkable result for an instrument as simple as the DIMM. The SL appears to be sharply defined between two heights, starting 2 m above the ground and ending at a median height of 23 to 27 m. Its profile Cn2(h) is exponential-like, and a telescope located 23 m above the ground will be above the SL half of the time. This is the first time that such quantitative results have been obtained, however based on only the 100 days of data (July to October 2005) when the three DIMM were operated together. This emphasizes the need for more statistics, requiring a new DIMM on the roof of the base (or on the top of the 45 m mast, but that is clearly a more difficult technical task) for a longer period of time (at least one full year).
The seeing above the surface layer is, as expected, excellent, while slightly less to the values published by the Australian group operating a MASS+SODAR combination in 2004 (Lawrence et al. 2004). These ASL conditions are accessible in summer at around 5 pm every day for a temporal window of roughly 2 h, when the statistics of the seeing at an elevation of 8 m is almost the same as the winter ASL seeing. This is of course very interesting for solar observations as stated before (Arnaud et al. 2007) but some turbulence does still exist in the first meters above the ground even at 5 pm in the summer and that a solar telescope must be located at least at 8 m to benefit from the excellent seeing of the FA.
Finally, the turbulent profile inside the SL has also been deduced from these DIMM data sets by exploiting only the fraction of time spent by these DIMMs inside the turbulence. It is remarkably consistent with the few samples directly measured in-situ by the radio soundings of the winter balloons, and an important point to be noted is that 95 percent of the total turbulence energy above 3 m is inside the SL.
During the polar summers 2006-2007 and 2007-2008 a set of 6 sonic anemometers was installed on the 45 m mast to perform in situ monitoring of the temperature, wind speed and Cn2 inside the BL (Travouillon et al. 2008). A part of the data corresponding to the winter 2007 are under analysing, but in 2007 the mast was only 33 m high and there were 3 sonic anemometers. The complete data for the 6 sonics have not yet been analysed. They will permit us to obtain better statistics and to address issues such as the relationship between the turbulent layer height and content, and meteorological parameters such as wind speed and temperature gradients.
Acknowledgements
We wish to thank the French and Italian Polar Institutes, IPEV and PNRA and the CNRS for the financial and logistical support of this programme. Thanks also to the different logistics teams on the site who helped us to set up the experiments. We are also grateful to our industrial partners ``Optique et Vision'' and ``Astro-Physics'' for technical improvements of the telescopes and their help in finding solutions to critical technical failures on the site. Thanks to our colleagues Max Azouit and François Martin for constant help and ideas since the beginning of the project. Thanks to F. Vakili, the director of Fizeau laboratory, for his support. We would also like to cite the people who participated in the summer campaigns: Merieme Chadid, Jean-Baptiste Daban, Tatyana Sadibekova, Caroline Santamaria, François-Xavier Schmider, Tony Travouillon and Franck Valbousquet. Finally, we thank Nicolas Epchtein for his critical reading of the manuscript.
References
- Agabi, A., Aristidi, E., Azouit, F., et al. 2006, PASP 118, 344 (In the text)
- Aristidi, E., Agabi, A., Fossat, E., et al. 2005, A&A, 444, 651 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Arnaud, J., Faurobert, M., Grec, G., & Renaud, C., 2007, EAS Pub. Series, 25, 81 [CrossRef]
- Elhalkouj, T., Ziad, A., Petrov, R., et al. 2008, A&A, 477, 337 [NASA ADS] [CrossRef] [EDP Sciences]
- Geissler, K., & Masciadri, E., 2006, PASP, 118, 1048 [NASA ADS] [CrossRef] (In the text)
- Lawrence, J.S., Ashley, M.C.B., Tokovinin, A., & Travouillon, T. 2004 Nature, 431, 278 (In the text)
- Loos, G., & Hogge, C., 1979, Appl. Opt., 18, 2654 [NASA ADS] [CrossRef] (In the text)
- Marks, R., Vernin, J., Azouit, M., Manigault, J. F., & Clevelin, C. 1999, A&AS, 134, 161 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Mosser, B., & Aristidi, E. 2007, PASP 119, 127 (In the text)
- Racine, R. 1996, PASP 108, 372
- Swain, M., & Gallée, H. 2006, PASP, 118, 1190 [NASA ADS] [CrossRef]
- Travouillon, T., Ashley, M., Burton, M., et al. 2003, A&A, 409, 1169 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Travouillon, T., Aristidi, E., Fossat, E., et al. 2008, SPIE, 7012, 147 [NASA ADS] (In the text)
- Trinquet, H., Agabi, A., Vernin, J., et al. 2008a, PASP, 120, 203 [NASA ADS] [CrossRef] (In the text)
- Trinquet, H., et al. 2008b, SPIE v. 7013 (In the text)
- Ziad, A., Martin, F., Conan, R., Borgnino, J., 1999, SPIE, 3866, 156 [NASA ADS] (In the text)
- Ziad, A., Aristidi, E., Agabi, A., et al. 2008, A&A, 491, 917 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
All Tables
Table 1: Global seeing statistics for the three available DIMM data.
Table 2: Table of fitted parameters relevant to Eq. (1) for the 3 DIMMs at 3, 8 and 20 m and for each season and/or each year.
All Figures
| |
Figure 1: Top: daily average seeing at an elevation of 8 m as a function of time. Bottom: monthly seeing for the three elevations 3 m, 8 m and 20 m respectively. Seeing scale is logarithmic. |
| Open with DEXTER | |
| In the text | |
| |
Figure 2: The histogram of 3 and a half years of DIMM seeing data recorded at an elevation of 8 m on the Concordiastro platform reveals two different regimes corresponding to good and bad seeing. |
| Open with DEXTER | |
| In the text | |
| |
Figure 3: The fit of 3 log-normal curves of the winter 2006 histogram of the 8 m DIMM. It clearly distinguishes 3 different situations: a) an excellent seeing distribution, corresponding to situations where the telescope is above the SL; c) a poor seeing distribution (the telescope is totally embedded inside the SL); b) the distribution of less frequent intermediate events. |
| Open with DEXTER | |
| In the text | |
| |
Figure 4: An autumn histogram showing a situation very similar to the winter one displayed in Fig. 3, the only difference being the weaker turbulent energy inside the SL (the maximum of the curve (c) is centered on a smaller value). |
| Open with DEXTER | |
| In the text | |
| |
Figure 5: Histograms of the seeing obtained during the same 4 months in 2005 at 8 m and 20 m showing how much the seeing improves in this 12 m vertical interval. Quantitatively, they provide the probabilities of beeing above the SL at these two altitudes. |
| Open with DEXTER | |
| In the text | |
| |
Figure 6: Ratio of the two histograms of Fig. 5. The dashed line at count ratio = 2.5 corresponds to the expected horizontal asymptote of the curve when the seeing tends to zero (see text). |
| Open with DEXTER | |
| In the text | |
| |
Figure 7: Histogram of the seeing data taken by the 3-m DIMM, as usual excluding summers. As for Fig. 3, curves (a), (b), (c) represent the three log-normal fits. The mean seeing is quite poor (close to 2 arcsec), but the excellent and intermediate seeing situations are still visible, even with a telescope mount placed on the snow surface, with probabilities of about 2% and 5%. |
| Open with DEXTER | |
| In the text | |
| |
Figure 8: Probabilities of being inside the SL as a function of altitude above the snow surface. See text (Sect. 2.3) for details. |
| Open with DEXTER | |
| In the text | |
| |
Figure 9: 32 samples of the SL Cn2 vertical distribution in the first 80 m above the ground, measured during winter 2005 by balloon radio soundings. The horizontal axis is Cn2 in units of 10-13 m-2/3 and the vertical axis is the altitude over the ground in meters. Note that the Cn2 is displayed in linear scale (it is often shown in log scale). |
| Open with DEXTER | |
| In the text | |
| |
Figure 10: The mean value of Cn2 inside the turbulent SL, seen by the radio soundings (continuous curve) and modelled from the 3 DIMMs time series (triangles). The first few meters above the surface are poorly estimated. Given the different technologies and the different epochs of these measurements, the general agreement above 8 m is satisfactory. Values of Cn2 at each altitude take in account the situations where the SL reaches at least this altitude (it is not an average including the nearly zero values when the SL is entirely below this altitude), as described in the text. |
| Open with DEXTER | |
| In the text | |
| |
Figure 11: A ``typical'' example of the Cn2 SL. The upper limit is always extremely sharp. |
| Open with DEXTER | |
| In the text | |
| |
Figure 12:
Piecewise model for S(h). Points 1, 2 and 3 correspond to the DIMMs at elevations h1, h2 and h3. Two situations are shown. (1) theSL upper limit
|
| Open with DEXTER | |
| In the text | |
| |
Figure 13:
SL thickness
|
| Open with DEXTER | |
| In the text | |
| |
Figure 14: Distribution of the ASL seeing at Concordia, measured during 10 seasons between 2005 and 2008, and excluding summers. The table on the right the corresponding statistics. |
| Open with DEXTER | |
| In the text | |
| |
Figure 15: Histogram and statistics of the seeing values corresponding to the period 4pm-6pm in summer (December and January). The superimposed solid curve is the ASL seeing distribution. |
| Open with DEXTER | |
| In the text | |
| |
Figure 16: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken in summer and in winter winters with the DIMM at an elevation of 3 m. |
| Open with DEXTER | |
| In the text | |
| |
Figure 17: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken in summer and in winter with the DIMM at an elevation of 8 m. |
| Open with DEXTER | |
| In the text | |
| |
Figure 18: Histogram of the length ts of continuous intervals with seeing <s0, as a function of s0, for seeing data taken at the three elevations between July and October 2005. |
| Open with DEXTER | |
| In the text | |
| |
Figure 19:
Isoplanatic angle |
| Open with DEXTER | |
| In the text | |
| |
Figure 20: Isoplanatic angle histograms and statistics. Values are in arcsec. |
| Open with DEXTER | |
| In the text | |
| |
Figure 21:
Mean duration of intervals in which the isoplanatic angle is greater than a given value |
| Open with DEXTER | |
| In the text | |
Copyright ESO 2009
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.