| Issue |
A&A
Volume 494, Number 3, February II 2009
|
|
|---|---|---|
| Page(s) | 845 - 855 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361:200810384 | |
| Published online | 11 December 2008 | |
Galaxy clusters in the CFHTLS![[*]](/icons/foot_motif.gif)
II. Matched-filter results in different passbands
L. F. Grove1,![]() -
C. Benoist2 - F. Martel2
-
C. Benoist2 - F. Martel2
1 -
Dark Cosmology Centre, Niels Bohr Institute, University of
Copenhagen, Juliane Maries Vej 30, 2100 Copenhagen, Denmark
2 -
Observatoire de la Côte d'Azur, Laboratoire Cassiopée, BP 4229,
06304 Nice Cedex 4, France
Received 13 June 2008 / Accepted 7 November 2008
Abstract
Aims. We investigate the gain of added leverage and completeness of the constructed cluster catalogue, of applying the matched-filter detection algorithm to multiple passbands. In particular, we investigate the gain from having both i'- and z'-band data available when searching for galaxy clusters at ![]() .
.
Methods. We applied a matched filter detection method to the CFHTLS r'- and z'-band data of the four Deep fields and compared the cluster catalogues with the one extracted from the i'-band data presented in a previous paper. We also applied the matched filter to the Deep fields but with the limiting magnitudes appropriate for the much larger Wide survey in order to understand the best combination of i'- and z'-band depth for the most efficient cluster searches based on this algorithm.
Results. The density of clusters identified in the Deep r'- and z'-band catalogues are 36 and 80 per square degree, respectively. The estimated densities of false detections are 12 and 20 per square degree in the two bands. We find that the recovered properties are in good agreement between the different bands and also that the efficiency of each band is consistent with the expectations based on the shift of the 4000 Å break through the filters. When comparing r'- and i'-band, we do not find any significant additions to the i'-band catalogue. On the contrary, we find a large number of high redshift detections in the z'-band not in i'. These detections add ![]() 60% to the number of high-redshift detections in the i'-band.
60% to the number of high-redshift detections in the i'-band.
Conclusions. We conclude that, for cluster searches to redshifts ![]() 1, it is important to include sufficiently deep data redward of the i'-band, which in this work is provided by the z'-band coverage. The combination of catalogues extracted from two different passbands does not provide a cluster sample with greater purity.
1, it is important to include sufficiently deep data redward of the i'-band, which in this work is provided by the z'-band coverage. The combination of catalogues extracted from two different passbands does not provide a cluster sample with greater purity.
Key words: methods: data analysis - surveys - galaxies: clusters: general - cosmology: large-scale structure of Universe
1 Introduction
Clusters of galaxies are important tools in observational cosmology
(e.g. Rosati et al. 2002; Borgani et al. 2001). They are the largest relaxed
structures in the Universe with both their properties and evolution
tightly connected to the cosmological parameters and to the physics of
structure formation. However, to fully understand structure
evolution and constrain cosmological parameters, large,
well-understood samples are required. Therefore, in recent years a
number of automatic and objective cluster searches have been or are
being carried out. Currently, the main searches are being carried out
in X-rays or at optical wavelengths, but soon searches based on the
Sunyaev-Zel'dovich effect are expected to start contributing. The
X-ray searches have the great advantage that the contamination rate is
low, however, covering the large areas to the necessary depth needed
for building up statistical samples over a wider redshift range is
very time consuming. Some of the most widely used X-ray surveys
originate in the ROSAT data. Only one survey, the ROSAT Deep Cluster
Survey, reaches cosmologically relevant redshifts. This survey
identified clusters in the redshift range ![]() with a
density of
with a
density of ![]() 3.3 per square degree over 48 square degrees
(Rosati et al. 1998). In the optical, the ongoing searches are based on
large areas and deep data, appropriate to search large volumes at a
range of redshifts (e.g. RCS2
3.3 per square degree over 48 square degrees
(Rosati et al. 1998). In the optical, the ongoing searches are based on
large areas and deep data, appropriate to search large volumes at a
range of redshifts (e.g. RCS2![]() and
CFHTLS
and
CFHTLS![]() ).
Among the largest and deepest searches are the Red-sequence Cluster
Survey (RCS), which led to the identification of clusters with
).
Among the largest and deepest searches are the Red-sequence Cluster
Survey (RCS), which led to the identification of clusters with
![]() at a density of 13.3 per square degree
over
at a density of 13.3 per square degree
over ![]() 72 square degrees (Gladders & Yee 2005). Other surveys have
reached slightly higher densities
72 square degrees (Gladders & Yee 2005). Other surveys have
reached slightly higher densities ![]() 15-20 per square degree
covering slightly larger redshift intervals of about
15-20 per square degree
covering slightly larger redshift intervals of about
![]() (e.g. Postman et al. 1996; Scodeggio et al. 1999).
(e.g. Postman et al. 1996; Scodeggio et al. 1999).
A number of automatic cluster identification methods have been developed for detecting clusters in optical data. The first objective methods developed were based on detections in a single passband and on applying a maximum likelihood algorithm indexed by the redshift (e.g. Postman et al. 1996; Olsen et al. 1999a; Kepner et al. 1999). These methods modelled the clusters based on typical luminosity functions and radial profiles. More recently, methods based on two (e.g. Koester et al. 2007; Gladders & Yee 2000) or more passbands (e.g. Miller et al. 2005; Goto et al. 2002) have been used to identify clusters. Such methods improve the ability to disentangle chance alignments, but they also rely on their own assumptions, such as the presence of the colour-magnitude relation of early type galaxies (e.g. Bower et al. 1992; de Propris et al. 1999; Stanford et al. 1998). Each of the detection methods have their own biases and selection effects depending on their specific assumptions. A good understanding of these effects is essential for constraining the structure-growth function based on cluster experiments. In principle, such an understanding is best addressed statistically from the analysis of realistic mock catalogues. However, the difficulty in reproducing the galaxy properties within forming clusters in simulations covering a cosmological volume, leads to the necessity of also investigating biases of cluster finders by direct comparisons on real data.
The Sloan Digital Sky Survey (SDSS) data with their large area and
multi-colour coverage, as well as complementing spectroscopic
information, have recently provided an important test-bed for a number
of optical cluster detection methods at low redshifts
(e.g., Kim et al. 2002; Goto et al. 2002; Kepner et al. 1999). Thorough comparisons between
the different methods have been carried out by Kim et al. (2002); Goto et al. (2002) and
Bahcall et al. (2003). These comparisons show that, not surprisingly, there
are always differences between the various catalogues, some of which
are caused by the different ways the parameters, such as for example
richness, are estimated. The SDSS data are sufficient for detecting
clusters to at most intermediate redshifts (![]() ). At higher
redshifts only smaller data samples have been available, such as the
KPNO/Deeprange survey by Postman et al. (2002) and the ESO Imaging Survey
(Olsen et al. 1999a,b; Scodeggio et al. 1999). Recently, the Red sequence
Cluster Survey by Gladders & Yee (2005, RCS) covering 100 square
degrees has been achieved thus starting to probe large volumes to high
redshift. However, a detailed comparison of the efficiency of
different methods at high-z has yet to be carried out.
). At higher
redshifts only smaller data samples have been available, such as the
KPNO/Deeprange survey by Postman et al. (2002) and the ESO Imaging Survey
(Olsen et al. 1999a,b; Scodeggio et al. 1999). Recently, the Red sequence
Cluster Survey by Gladders & Yee (2005, RCS) covering 100 square
degrees has been achieved thus starting to probe large volumes to high
redshift. However, a detailed comparison of the efficiency of
different methods at high-z has yet to be carried out.
For detailed comparisons between different methods, wide, deep, and
preferentially multi-passband homogeneous surveys are required in
order to provide the necessary data for a number of different
detection methods. The design of the Wide survey of the
Canada-France-Hawaii Telescope Legacy Survey (CFHTLS) provides a data
set that is particularly well-suited to carrying out such studies.
This survey is currently underway and is planned to cover
![]() square degrees in 5 passbands spread in 4 patches with
limiting magnitudes up to 25
square degrees in 5 passbands spread in 4 patches with
limiting magnitudes up to 25![]() .
It will provide the necessary ground
for building a large, well-controlled cluster candidate sample at
redshifts
.
It will provide the necessary ground
for building a large, well-controlled cluster candidate sample at
redshifts ![]() ,
derived from a set of different search
techniques using the spatial and/or photometric properties in one or
more passbands. Such catalogues will allow us to accurately test the
z>0.5 component of the cluster distribution. Using automatic search
techniques will allow us to build selection functions for each of our
independently extracted catalogues. A careful comparison between the
various independently extracted cluster samples will allow us to
understand the additional difficulties in detecting clusters at
successively higher redshifts, as well as improve our knowledge about
clusters at these redshifts. Combining the catalogues from several
searches we will create a robust cluster sample well-suited to both
cosmological and galaxy evolution studies.
,
derived from a set of different search
techniques using the spatial and/or photometric properties in one or
more passbands. Such catalogues will allow us to accurately test the
z>0.5 component of the cluster distribution. Using automatic search
techniques will allow us to build selection functions for each of our
independently extracted catalogues. A careful comparison between the
various independently extracted cluster samples will allow us to
understand the additional difficulties in detecting clusters at
successively higher redshifts, as well as improve our knowledge about
clusters at these redshifts. Combining the catalogues from several
searches we will create a robust cluster sample well-suited to both
cosmological and galaxy evolution studies.
Based on the CFHTLS Deep data, several optical cluster finders have already been applied including the i'-band matched filter (Olsen et al. 2007, hereafter Paper I), photometric redshift slicing (Mazure et al. 2007), and weak lensing (Gavazzi & Soucail 2007). In this paper we compare the results of applying the matched filter detection method to different passbands, thereby discussing the benefits of having independent cluster catalogues for gaining leverage of individual systems, and to complement each other at redshifts where the bluer passbands become less efficient. In Paper I we described our implementation of the matched filter and its application to the CFHTLS i'-band catalogues. Here we extend this work to the r'- and z'-bands with the main aim of investigating the added value of the different bands. We also investigate the outcome expected from the CFHTLS Wide in terms of depth and completeness of the cluster search. The paper is structured as follows. In Sect. 2 we describe the galaxy catalogues used as the basis for our search. In Sect. 3 we give an overview of the detection method and describe the parameter settings based on simulations, as well as the selection function for each passband. In Sect. 4 we present the new cluster candidate lists for the r'- and z'-band and compare them with that of the i'-band presented in Paper I. In Sect. 5 we discuss the added value of the new passbands. In Sect. 6 we discuss the expected outcome of the CFHTLS Wide survey in terms of depth of the extracted cluster catalogues and the optimum combination of depth in the i'- and z'-band for obtaining the most complete cluster sample based on the matched filter algorithm also at high redshift. In Sect. 7 we summarise the paper.
Throughout the paper we use a cosmological model with
![]() ,
,
![]() ,
and H0=75 km s-1 Mpc-1
,
and H0=75 km s-1 Mpc-1 ![]() .
.
2 Galaxy catalogues
Our implementation of the matched filter algorithm treats one passband
at a time, thus the basic input is the single passband galaxy
catalogues. The basic source catalogues in the r'- and z'-bands
are the ones provided by the Terapix team as part of the CFHTLS
release T0003 in February
2006![]() .
For the i'-band we continue to use the ones from the T0002 release
as in Paper I to facilitate the comparison to the previous work. The
characteristics of the released data in the r'- and z'-bands are
summarised in Table 1 given as ranges for the four
deep fields considered here.
.
For the i'-band we continue to use the ones from the T0002 release
as in Paper I to facilitate the comparison to the previous work. The
characteristics of the released data in the r'- and z'-bands are
summarised in Table 1 given as ranges for the four
deep fields considered here.
Table 1: Characteristics of the released data in the r'- and z'-bands of the T0003 Terapix release.
Starting from the release catalogues, we apply a star-galaxy separation
based on the locus of the objects in a half-light radius versus
i'-magnitude diagram, where the stars are clearly separated from the
galaxies at magnitudes
![]() .
As in Paper I we applied a
correction for Galactic extinction based on the Schlegel et al. (1998) maps
and used the masks created for the i'-band images to exclude false
detections. For these post-processed catalogues, we show the
differential number counts in Fig. 1 for each of the
four Deep fields considered in this paper. It can be seen that the
number counts for the four fields are consistent. The vertical dotted
lines mark the limiting magnitudes applied for this work which for the
r'-band is
.
As in Paper I we applied a
correction for Galactic extinction based on the Schlegel et al. (1998) maps
and used the masks created for the i'-band images to exclude false
detections. For these post-processed catalogues, we show the
differential number counts in Fig. 1 for each of the
four Deep fields considered in this paper. It can be seen that the
number counts for the four fields are consistent. The vertical dotted
lines mark the limiting magnitudes applied for this work which for the
r'-band is
![]() and for z'-band
and for z'-band
![]() .
.
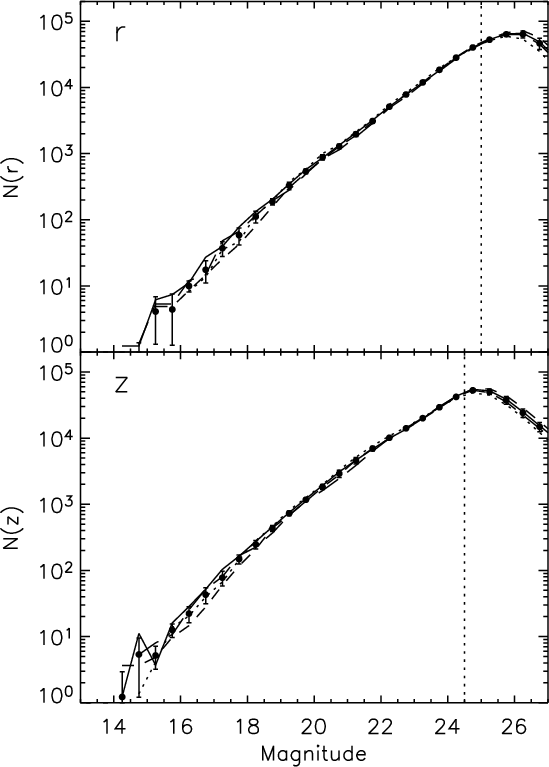 |
Figure 1: Average galaxy number counts (filled dots with error bars) for the four Deep fields in the r'- and z'-band as indicated in each panel. The number counts for the individual fields are shown as follows: D1 - solid line; D2 - dotted line; D3 - short-dashed line; and D4 - long-dashed line. The vertical dotted lines denote our adopted magnitude limit for the present analysis. |
| Open with DEXTER | |
3 Cluster detection
3.1 The matched-filter procedure
Our cluster detection procedure was described in detail in Paper I. It was based on the matched-filter technique (e.g., Postman et al. 1996) as it was implemented for the ESO Imaging Survey (Olsen et al. 1999a) with some additional improvements. Here we only summarise the main steps and our choice of input parameters for the present work.
The matched-filter technique is a maximum likelihood analysis with the following steps:
- 1.
- creation of a filter based on an assumed cluster galaxy luminosity function and radial profile;
- 2.
- creation of likelihood maps for a series of redshifts;
- 3.
- detection of significant peaks;
- 4.
- cross-matching of peaks for different redshifts;
- 5.
- creation of likelihood curves and identification of the redshift of maximum likelihood used for defining the cluster properties such as redshift and richness.
Table 2: Detection and filtering parameters for building the cluster catalogues.
3.2 Simulated galaxy catalogues
To balance the number of false detections with the recovery rate, we created a set of simulated background catalogues reproducing the first and second order statistics of the clustering properties of the galaxy distribution. In Paper I we described the procedure used for a single passband for obtaining catalogues resembling the data. There we created 20 simulated background catalogues with an area of 1 square degree each matching the i'-band properties. Those catalogues were used here as the basis for creating the r'- and z'-band, keeping the positions but assigning random r'- and z'-magnitudes according to the magnitude dependent colour distributions. The clustering of the constructed catalogues has been confirmed to resemble that of the data.
To estimate the recovery rate, we added clusters resembling the model cluster. For this purpose we again used the 3360 clusters created in the i'-band in Paper I and applied a redshift dependent colour correction to get the equivalent clusters in r'- or z'-band. We used the colour correction for a non-evolving elliptical galaxy to match the choice in Paper I of using the same k-correction for all galaxies in the cluster, thus for the moment disregarding the effects of variations in galaxy types. The effects of these variations will be discussed in a forthcoming paper where we discuss the selection funcion based on N-body simulations.
3.3 Detection parameters
Our matched filter detection procedure is applied to one band at a
time. The data from different passbands are treated independently
following the same procedures as in Paper I. The most important
parameters for setting up the peak detection are the minimum accepted
area and the detection threshold. The two parameters are not
independent, since a larger threshold leads to smaller areas and
vice versa. In Paper I we estalished that a minimum area of ![]()
![]() is necessary for achieving a good completeness at high
redshifts. It was also found that a number of high redshift X-ray
detected systems were only included if the detection threshold was set
to
is necessary for achieving a good completeness at high
redshifts. It was also found that a number of high redshift X-ray
detected systems were only included if the detection threshold was set
to ![]() .
With these settings we found that the fraction of
false detections is
.
With these settings we found that the fraction of
false detections is ![]()
![]() .
Here we aim at a similar noise
fraction. Below, the cross-matching between the different
catalogues will be used to assess their relative completeness.
.
Here we aim at a similar noise
fraction. Below, the cross-matching between the different
catalogues will be used to assess their relative completeness.
Table 3 gives the estimated frequency of false
detections for the r'- and z'-band catalogues and compares these
to the one in i'-band for the chosen minimum area and different
detection thresholds. From the table it is, as expected, clear that
the highest thresholds give the smallest fraction of
false positives. However, this also leads to the lowest completeness
of the cluster catalogues and is therefore undesirable. It can be seen
that the fraction of false positives do not differ a lot between the
different passbands for a given threshold, and thus in all cases we
decide to use ![]() for the detection threshold. Curiously, the
fraction of false detections in the z'-band is at high detection
thresholds always lower than in the other bands. The reason for this
is not clear, but may be related to a better detection efficiency at
high redshift and thus more real detections in the catalogue.
for the detection threshold. Curiously, the
fraction of false detections in the z'-band is at high detection
thresholds always lower than in the other bands. The reason for this
is not clear, but may be related to a better detection efficiency at
high redshift and thus more real detections in the catalogue.
In Fig. 2 we show the redshift distribution of the detections in the r'- and z'-catalogues including the estimated number of false detections. There it can be seen that in both cases the false detections are found in roughly equal number at all redshifts, except that there is a slight indication of a peak at the lowest redshift for the r'-band. The figure also shows the richness distributions. Not surprisingly, the fraction of false positives increases for lower richness.
Table 3:
The estimated fraction of false-positives for each of the
three passbands using a minimum area of ![]()
![]() and
different detection thresholds.
and
different detection thresholds.
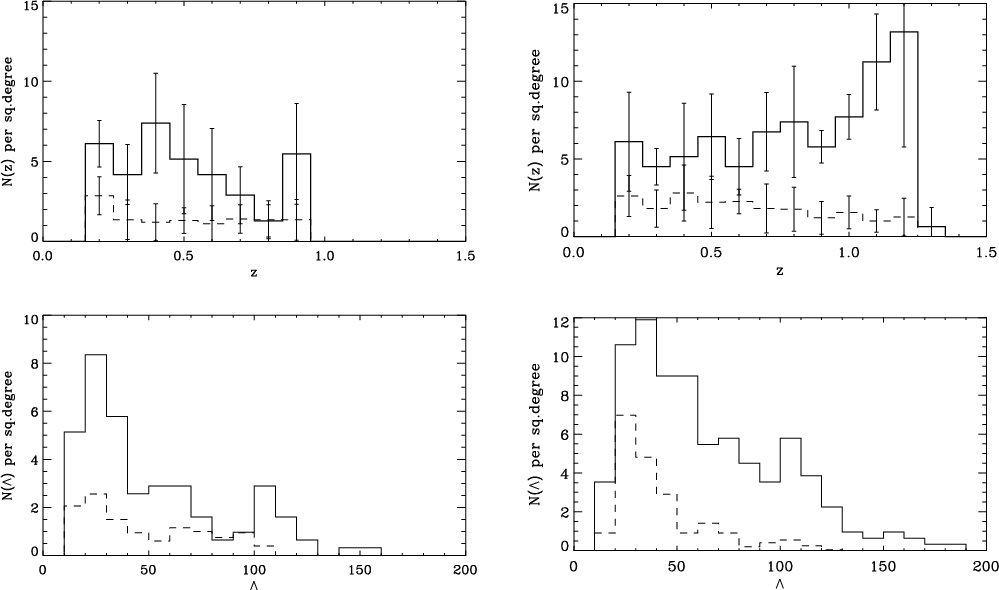 |
Figure 2: Redshift ( top) and richness ( bottom) distributions (solid line) for all the candidate clusters in the r'- ( left) and z'-band ( right) catalogues. The distributions for the false detections (dashed lines) are estimated using the simulated backgrounds described in the text. For the redshift distributions the error bars denote the scatter between the fields. |
| Open with DEXTER | |
3.4 Recovery rate
Having decided on the detection threshold and minimum area we
investigated the recovery rate as function of redshift and
richness. We covered redshifts from z=0.2 to 1.3 and richnesses in
the range
![]() .
These richnesses correspond to
systems of richness class R<0 up to
.
These richnesses correspond to
systems of richness class R<0 up to ![]() .
We used the simulated
catalogues described above starting from the i'-band catalogues
correcting the magnitudes to r'- or z'-band, respectively, and
identify systems in these catalogues. This method is equivalent to
building clusters for each passband following the Schechter luminosity
function also used for constructing the filter as was the procedure
for the i'-band; hence the determined recovery rate can be compared
directly between the different catalogues.
.
We used the simulated
catalogues described above starting from the i'-band catalogues
correcting the magnitudes to r'- or z'-band, respectively, and
identify systems in these catalogues. This method is equivalent to
building clusters for each passband following the Schechter luminosity
function also used for constructing the filter as was the procedure
for the i'-band; hence the determined recovery rate can be compared
directly between the different catalogues.
Figure 3 shows the recovery rate as determined for both
bands and compares them with the one found for the i'-band in
Paper I. For each band we show the recovery rate for four richness
classes starting at poor groups up to very rich clusters as detailed
in the figure caption. The cutoff in each passband is related to the
shifting of the 4000 Å break out of the filter, which strongly
depletes the catalogue for detectable cluster members. For the
r'-band, this effect already sets in for the poor clusters at
![]() ,
while the richer systems are detected with good
completeness up to
,
while the richer systems are detected with good
completeness up to ![]() .
For the z'-band the poor systems
start to be significantly affected at
.
For the z'-band the poor systems
start to be significantly affected at ![]() and the rich systems
only drop significantly at
and the rich systems
only drop significantly at ![]() .
For comparison we also show the
i'-band results that can be seen to be intermediate but only
slightly shallower in terms of recovery rate than the z'-band
catalogue for these idealized cases.
.
For comparison we also show the
i'-band results that can be seen to be intermediate but only
slightly shallower in terms of recovery rate than the z'-band
catalogue for these idealized cases.
Being able to detect a cluster is obviously the most basic recovery
property, however it is also important to know how
reliably the
parameters are recovered. To investigate this, we studied the offsets
in redshift and richness between the input values and matched-filter
estimates as was done for the i'-band in Paper I. We find a similar
trend towards overestimating the redshift for the most nearby systems,
while at high-z we find an underestimate. The offsets in richness are
consistent with this picture showing also an overestimate at low-z and
an underestimate at high-z. The reason for this is that the
![]() -richness gives the equivalent number of L* galaxies
and thus an overestimated redshift gives a fainter estimated apparent
Schechter magnitude, which leads to overestimating the richness. The
effect is opposite for the underestimated redshifts.
-richness gives the equivalent number of L* galaxies
and thus an overestimated redshift gives a fainter estimated apparent
Schechter magnitude, which leads to overestimating the richness. The
effect is opposite for the underestimated redshifts.
4 Matched-filter catalogues
We applied the matched filter algorithm with the parameters determined
above to the r'- and z'-band galaxy catalogues of the four deep
CFHTLS fields. This resulted in lists of 114 candidates in the
r'-band and 247 in z'-band as presented in Tables 4 and 5. Here we present the first five lines of each catalogue
with the entire lists being available at the CDS. The tables list: in
Col. 1 the cluster name, in Cols. 2 and 3 the right ascension and
declination in J2000, in Col. 4 the estimated redshift, in Col. 5 the
![]() richness, in Col. 6 the S/N of the peak value of the
detection, in Col. 7 the number of bins where the candidate was
detected, in Col. 8 the fraction of lost area within a distance of
richness, in Col. 6 the S/N of the peak value of the
detection, in Col. 7 the number of bins where the candidate was
detected, in Col. 8 the fraction of lost area within a distance of
![]() from the cluster position, in Col. 9 the
grade as defined below, and in Col. 10 the corresponding i'-band
detection when there is a match. Table 6 gives the
12 matches between r'- and z'-band but not detected in i'.
from the cluster position, in Col. 9 the
grade as defined below, and in Col. 10 the corresponding i'-band
detection when there is a match. Table 6 gives the
12 matches between r'- and z'-band but not detected in i'.
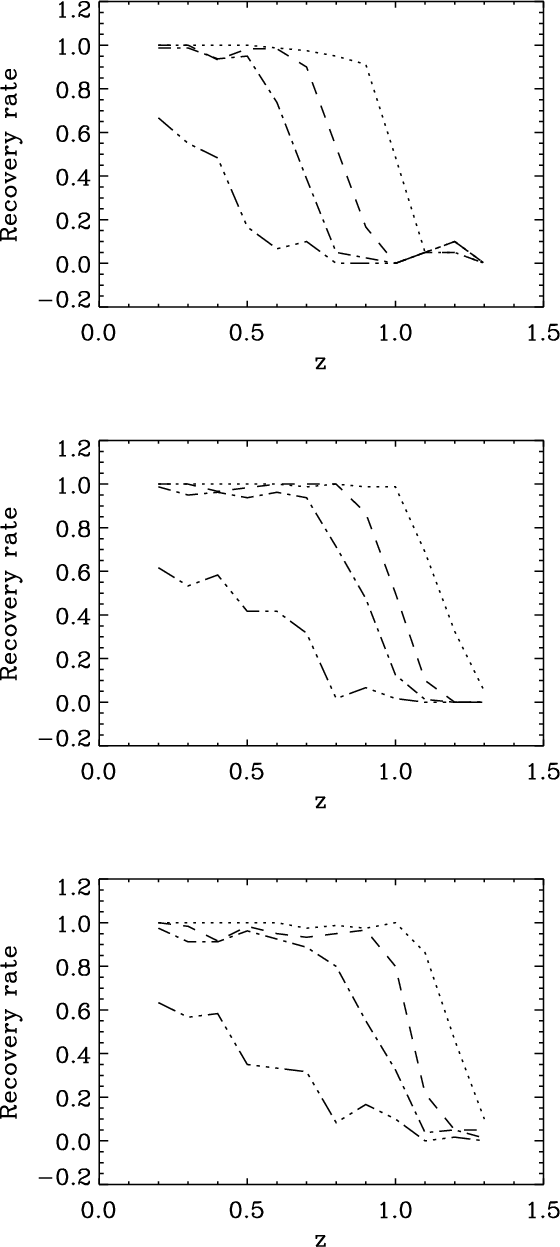 |
Figure 3:
The recovery rate as derived for each band
( from top to bottom: r', i' and z') used in the present work. The lines cover
different richness classes:
|
| Open with DEXTER | |
The effective area covered by the search is 3.112 square degrees and
leads to average densities for the four deep fields in r'-band of
![]() per square degree with an estimated noise frequency of
per square degree with an estimated noise frequency of
![]() per square degree and in z' of
per square degree and in z' of
![]() per square
degree with a noise contribution of
per square
degree with a noise contribution of
![]() per square degree.
Figure 2 displays the redshift and richness
distributions of the detections in the two catalogues. The median
redshift is 0.5 for the r'-band detections and 0.8 for the z'-band
ones.
per square degree.
Figure 2 displays the redshift and richness
distributions of the detections in the two catalogues. The median
redshift is 0.5 for the r'-band detections and 0.8 for the z'-band
ones.
With the available multi-passband coverage we created colour images
for each of the detected candidates. These images were used for visual
inspection in order to obtain a measure of their reliability in terms
of their colour and concentration appearance. During the visual
inspection grades were assigned from A to D with grade A systems
showing a clear concentration of galaxies with similar colours;
grade B systems are characterised by an overdensity of galaxies, less
concentrated than grade A systems or without any obvious colour
concentration; grade C systems do not reveal any clear galaxy
overdensity; and finally grade D systems are systems that were
detected because of lack of masking of the galaxy catalogue or because
of an artefact due to the presence of an edge. The inspection done for
this paper was carried out by CB. However, originally when the system
was setup, both LFG and CB inspected about half of the cluster
candidates. For that sample we estimate that we agreed in ![]() 90%
of the cases. In general, the quality of the detected systems is high
with about two thirds of the systems in the first two categories. The
distribution in r' was found to be grade A 31%, grade B 40%, grade
C 29%, and no grade D systems. In z' we found grade A 30%, grade B
36%, grade C 34%, and no grade D systems. In both cases the fraction
of systems graded A or B is marginally less than for the i'-band
catalogue (Paper I). This may indicate a better success rate of
detecting physical systems using the i'-band data, even though this
should not be the case judged from the estimated fraction of false
detections. This classification is expected to be quantified in a
future paper discussing the colour-magnitude diagrams and in
particular the red sequence of the detected systems.
90%
of the cases. In general, the quality of the detected systems is high
with about two thirds of the systems in the first two categories. The
distribution in r' was found to be grade A 31%, grade B 40%, grade
C 29%, and no grade D systems. In z' we found grade A 30%, grade B
36%, grade C 34%, and no grade D systems. In both cases the fraction
of systems graded A or B is marginally less than for the i'-band
catalogue (Paper I). This may indicate a better success rate of
detecting physical systems using the i'-band data, even though this
should not be the case judged from the estimated fraction of false
detections. This classification is expected to be quantified in a
future paper discussing the colour-magnitude diagrams and in
particular the red sequence of the detected systems.
5 Value of multiple passbands
In this section we compare the detections identified in r'-, i'-, and z'-band to shed light on how this combination of bands is best used to select the least contaminated samples and how they can be combined for constructing a more complete catalogue. The first question considers candidates detected in multiple passbands (Sect. 5.1), the second those detected in only one band (Sect. 5.2).
Throughout this section, we have to identify those systems we consider the most likely clusters among the candidates. To do so, we follow the procedure introduced in Paper I based on systematic visual inspection. A more robust classification based on photometric redshifts will be presented in a forthcoming paper. The candidates graded A or B both show a concentration of galaxies and thus we consider these the most promising candidates and in this section will be counted as the most likely real systems. It is important to emphasise that when a more thorough investigation becomes available some of the grade C systems may also turn out to be physical systems, just as some of the grade A and B systems may turn out to be false.
The cross-matching between different passbands is made by positional coincidence such that two detections are matched if the centres are within 0.5 Mpc of each other. In practice, this is done by matching the cluster candidates in order of increasing redshift and then identifying other detections within 0.5 Mpc. If more than one detection in the same passband is found to match a given detection, then the one with the closest match in redshift is preferred. If this does not give a unique match, we assign the detection closest in redshift and space as the corresponding candidate. In this way we define a unique matching without a particular reference catalogue.
When interpreting the results of the matching, it is important to keep
in mind that not all bands are equally efficient at all redshifts. The
bluest band (here r') will become inefficient before the redder
ones due to the shift of the 4000 Å break through the filters with
increasing redshift. From Sect. 3.4 we see that the
r'-band is sensitive to systems of richness class ![]() up to
z=0.5, while the i'- and z'-bands are sensitive to such systems
up to redshifts
up to
z=0.5, while the i'- and z'-bands are sensitive to such systems
up to redshifts ![]() .
Therefore, in the following these
redshifts are used as guides for the discussion of the value of the
different bands.
.
Therefore, in the following these
redshifts are used as guides for the discussion of the value of the
different bands.
The observing strategy of the CFHTLS is to first complete the i'-band survey. Therefore we chose to use this as a reference in the discussion, even though the matching of the candidates is not related to any particular band. In the following we discuss the matching between the new catalogues and the one based on the i'-band from Paper I. Table 7 summarises the main numbers.
5.1 Selecting the least contaminated sample
In this section we use the candidates matched either between r'and i' or i' and z' to investigate whether these combinations can be used to select samples that are less contaminated than the individual catalogues.
In Sect. 3.4 we found that the r'-band catalogue
becomes significantly incomplete at ![]() .
Therefore, we
concentrate on lower redshifts when discussing the matching between
the r'- and i'-band catalogues. In the i'-band catalogue we
find 76 candidates with
.
Therefore, we
concentrate on lower redshifts when discussing the matching between
the r'- and i'-band catalogues. In the i'-band catalogue we
find 76 candidates with
![]() .
Of these, 49 are also
detected in the r'-band. The redshift estimates for the candidates
in common agree well. The largest offset is
.
Of these, 49 are also
detected in the r'-band. The redshift estimates for the candidates
in common agree well. The largest offset is
![]() and the
mean redshift offset
and the
mean redshift offset
![]() .
Also the
richness estimates agree well with a mean of
.
Also the
richness estimates agree well with a mean of
![]() .
We find that of the 76
i'-band candidates
.
We find that of the 76
i'-band candidates ![]()
![]() are graded A or B, while it is
are graded A or B, while it is
![]()
![]() for the matched sample.
for the matched sample.
For combining i'- and z'-band we limit the discussion to
![]() corresponding to the redshift where the catalogues
become incomplete as seen in Fig. 3. We find
114 candidates with
corresponding to the redshift where the catalogues
become incomplete as seen in Fig. 3. We find
114 candidates with
![]() .
Of these, 87 are also detected
in the z'-band data. The redshift and richness estimates agree well
for the matched candidates. We find
.
Of these, 87 are also detected
in the z'-band data. The redshift and richness estimates agree well
for the matched candidates. We find
![]() and
and
![]() .
The grade distribution for the i'-band candidates show that
.
The grade distribution for the i'-band candidates show that
![]()
![]() have grades A or B. Among the detections matched with a
z'-band candidate the fraction of systems graded A or B is
have grades A or B. Among the detections matched with a
z'-band candidate the fraction of systems graded A or B is
![]()
![]() .
Therefore, we conclude that, in the sense of corroborating
the candidates in this redshift range, the z'-band data does not add
any significant information.
.
Therefore, we conclude that, in the sense of corroborating
the candidates in this redshift range, the z'-band data does not add
any significant information.
Table 4: The first five entries of the cluster candidate catalogue for the r'-band. The full table is available at the CDS.
Table 5: The first five entries of the cluster candidate catalogue for the z'-band. The full table is available at the CDS.
In Fig. 4 we show the redshift and grade distribution of candidates for the entire i'-band catalogue and matched between the r'- and i'-band and i'- and z'-band. For each set of candidates the distribution is normalized by the total number of candidates in the set, in order to facilitate the comparison of the frequency of the different grades. In general it can be seen that there is a large fraction of systems with grades A or B in all samples and at all redshifts. Furthermore, the grade distributions as a function of redshift are similar for the different samples (i' only, r'+i' and z'+i') except maybe for a slight improvement in the matched sample at high redshift.
From this discussion it appears that the candidate samples matched between two of the bands are indeed marginally less contaminated in particular at high redshift. In deciding whether such a combined sample is preferred over a one-passband sample, it has to be taken into account that the selection function of the combined sample is more complicated than in the single passband case. Therefore, even if the matched samples are less contaminated, it may be preferable to keep the larger more well-understood samples as the basis for many applications.
5.2 Complementing the i'-band catalogue
With data available in several passbands, one can study how the individually extracted catalogues complement each other. In this section, we discuss whether the candidates detected in one passband only (r' or z') represents a significant contribution, relative to the i'-band detections, for constructing a complete cluster sample. We use the quality of the detections in the r'- or z'-band (but not matched with i') to quantify whether these candidates are likely to be an important contribution to a complete cluster sample.
In Fig. 5 we show the redshift and grade distribution for the entire i'-band catalogue together with the same distribution for the candidates detected in r' or z' but without a match in i'-band. It can be seen immediately that the number of r'-band detections without a match in i' is relatively small while in particular at higher redshifts the z'-band contribution may be a significant addition to the i'-band catalogue.
To understand this in more detail, we first concentrate on the
r'-band. The total r'-band sample consists of 114 candidates of
which a total of 84 match an i'-band candidate. The remaining
30 candidates can be split into 17 with
![]() and 13 with
and 13 with
![]() .
In the low-redshift bin the fraction of good
candidates is
.
In the low-redshift bin the fraction of good
candidates is ![]()
![]() ,
but dominated by grade B cases. In the
high-redshift data set, the fraction of good candidates decreases to
,
but dominated by grade B cases. In the
high-redshift data set, the fraction of good candidates decreases to
![]()
![]() .
Including these grade A and B systems in a follow-up
programme would increase the sample by
.
Including these grade A and B systems in a follow-up
programme would increase the sample by ![]()
![]() at the expense of
complicating the selection function.
at the expense of
complicating the selection function.
For the z'-band catalogue we first consider detections at
redshifts
![]() .
In total there are 21 systems that were
not detected in the i'-band. Of these
.
In total there are 21 systems that were
not detected in the i'-band. Of these ![]()
![]() or 13 systems are
graded A or B, with about two thirds in the latter category. At these
redshifts the addition of the good z'-band candidates to the good
i'-band candidates would increase the sample with
or 13 systems are
graded A or B, with about two thirds in the latter category. At these
redshifts the addition of the good z'-band candidates to the good
i'-band candidates would increase the sample with ![]()
![]() .
At
higher redshifts the z'-band catalogue has a lot more candidates
than the i'-band, but only
.
At
higher redshifts the z'-band catalogue has a lot more candidates
than the i'-band, but only ![]()
![]() of these are in the categories
of grade A or B. This is a total of 26 candidates, which is comparable
to the number of good candidates (30 in total) in the i'-band
catalogue at these redshifts. Thus, even though 22 of the additional
z'-band candidates are graded B, they are an interesting source for
completing a cluster catalogue at these higher redshifts. Using the
whole sample will add a lot of grade C systems as well. For follow-up
programmes it is thus necessary to either add a large number of less
promising systems or rely on visual inspection of all candidates as
preparation.
of these are in the categories
of grade A or B. This is a total of 26 candidates, which is comparable
to the number of good candidates (30 in total) in the i'-band
catalogue at these redshifts. Thus, even though 22 of the additional
z'-band candidates are graded B, they are an interesting source for
completing a cluster catalogue at these higher redshifts. Using the
whole sample will add a lot of grade C systems as well. For follow-up
programmes it is thus necessary to either add a large number of less
promising systems or rely on visual inspection of all candidates as
preparation.
In summary, for using these matched filter cluster samples for cosmological studies relying on statistics and thus good knowledge of the selection function, it would be preferable to stick to the individual catalogues, possibly using both the i'- and z'-band catalogues to have a double check of the results. If one wants to assemble a large sample of clusters for investigating the variety of systems identified by the matched filter, the combined sample would be preferred.
Table 6: The matches between r'- and z'-band with no i'-band detection.
6 Design of high-redshift cluster surveys
The design of large imaging surveys aimed at detecting clusters of
galaxies is always a balance of depth and area and possibly of the
number of passbands used. The adopted strategy will depend on the
desired redshift range to be covered and the requirements for
including confirmation like detection in multiple passbands or even
the ability to compute photometric redshifts for a more solid
confirmation of the detected cluster candidates. In this section we
use the available data from the CFHTLS Deep to extract catalogues
based on the expected depth of the CFHTLS Wide data to investigate the
properties of those wider but shallower catalogues. We will also use
the comparison of the deep and shallow catalogues to discuss the best
strategy for constructing a matched-filter cluster catalogue at
![]() .
.
6.1 Expectations for CFHTLS Wide
The ongoing CFHTLS Wide Survey is planned to cover a total of
170 square degrees of the sky split in 4 different
patches![]() . The
area will be covered in the 5 Sloan bands (u*, g', r', i',
z') planned to reach limiting magnitudes up to
. The
area will be covered in the 5 Sloan bands (u*, g', r', i',
z') planned to reach limiting magnitudes up to
![]() .
We are
mainly interested in the high-redshift (
.
We are
mainly interested in the high-redshift (![]() )
cluster
population. In the previous section, we saw that the i'- and
z'-bands are the relevant ones for such a catalogue, we
limit this discussion to these two bands. The currently
planned depth for the Wide data is
)
cluster
population. In the previous section, we saw that the i'- and
z'-bands are the relevant ones for such a catalogue, we
limit this discussion to these two bands. The currently
planned depth for the Wide data is
![]() and
and
![]() .
.
As for the Deep data we used simulations to assess the number of false detections and to determine the selection functions. We use the same detection parameters as before, which is the result of the same procedure for assessing the minimum area and detection thresholds as used for the Deep data. To get a realistic prediction for the densities and other general properties of the Wide catalogues we use the Deep data as a basis but execute the cluster search with the shallower limiting magnitudes expected for the Wide galaxy catalogues.
Since in the following, we compare the catalogues with the shallow limiting magnitudes with the deep ones, we list in Table 8 the main properties of the 4 catalogues used in this section. Here, we will first discuss the properties of the shallow catalogues expected to represent the Wide data and below we will return to the comparison with the deeper catalogues.
Table 7: Key numbers for the matching between the new catalogues and the one based on the i'-band from Paper I.
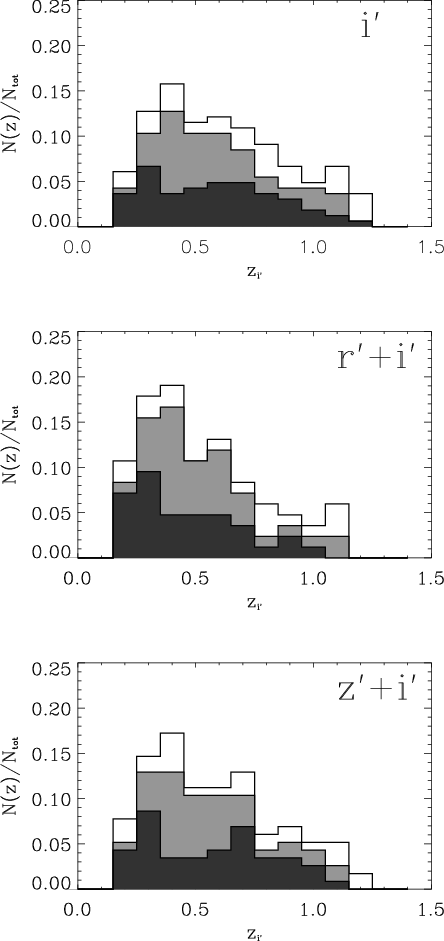 |
Figure 4: The i'-band redshift and grade distribution of candidates in the i'-band ( upper panel) and matched between r'- and i'-band ( middle panel) and i'- and z'-band ( lower panel) of all candidates graded A (dark grey), B (light grey) and C (no shading). |
| Open with DEXTER | |
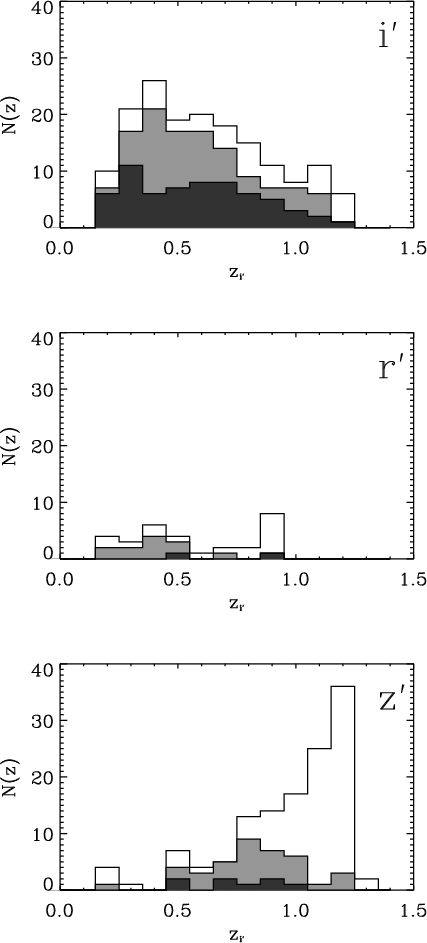 |
Figure 5: The i'-band redshift and grade distribution of candidates in the i'-band ( upper panel). The middle panel shows the redshift and grade distributions for systems detected in r' but not in i'and the lower panel those detected in z' but not in i'. The shading denotes the different grades as follows: grade A (dark grey), B (light grey), and C (no shading). |
| Open with DEXTER | |
The candidate density in the shallow catalogues is
![]() in i' and
in i' and
![]() in z'. The number of false detections is
in z'. The number of false detections is
![]() and
and
![]() ,
respectively. These numbers of false
detections correspond to a frequency of false detections of about one
third. In the upper panels of Fig. 6 we show the
redshift distribution of the detected candidates, together with the
redshift distribution for the false detections. The errorbars are
field-to-field standard deviations. With these results we would expect
to detect a total of about 9000 cluster candidates in the complete Wide
survey, which when subtracting the expected number of false detections
would correspond to a sample of about 6000 real clusters.
,
respectively. These numbers of false
detections correspond to a frequency of false detections of about one
third. In the upper panels of Fig. 6 we show the
redshift distribution of the detected candidates, together with the
redshift distribution for the false detections. The errorbars are
field-to-field standard deviations. With these results we would expect
to detect a total of about 9000 cluster candidates in the complete Wide
survey, which when subtracting the expected number of false detections
would correspond to a sample of about 6000 real clusters.
Table 8: Main properties of the 4 catalogues used for investigating the added value of the different depths.
As for the deep catalogues, we have carried out a visual inspection of
all the candidates included in the shallow catalogues. In
Table 9 we summarise the resulting grade
distributions. The fraction of systems with grade A or B is slightly
smaller in the z'-band catalogue than in the i'-band. We have
matched the candidates between the shallow i'- and z'-band
catalogues. The matching is carried out as in
Sect. 5. We find 109 candidates detected in both
catalogues. As can be seen from the table the grade distribution of
this sample has a marginally higher fraction of grade A or B systems
than both of the individual catalogues, but also the selection
function of the sample is more complicated to estimate. Looking at the
complementary 70 systems included in the z'-band catalogue but
without a counterpart in i'-band, we find that the fraction of A or
B systems is only 47%, thus at first sight this subsample is more
contaminated than any other subsample. The z'-band is, however,
expected to add most to the high-redshift end where the 4000 Å break
shifts out of the i'-filter. Therefore we also include the
statistics for systems with ![]() .
For this redshift range,
the total number of detections in i'-band is 59 (43 with grades A
or B) including matched and non-matched detections. Out of the
59 systems, 38 were found in both catalogues with 31 (82%) systems
having grades A or B, thus a slightly higher fraction than for the
i'-band sample. For the systems found in z'- but not in i'-band,
we find that 26 (50%) are in these grade categories. Thus even though
the fraction of good grade systems is not as impressive, addition of
the z'-band detections will increase the size of the sample of
promising candidates by about 60%. At the same time, it also
increases the number of less promising (grade C) systems from 16 to
42, thus an increase of about 150%. For any application the final
decision on whether to use the samples separately or combined will
depend on the scientific aim. From this we conclude that the
z'-band is a significant contribution towards a more complete high-zsample, even though with the drawback of adding a relatively large
number of less promising systems.
.
For this redshift range,
the total number of detections in i'-band is 59 (43 with grades A
or B) including matched and non-matched detections. Out of the
59 systems, 38 were found in both catalogues with 31 (82%) systems
having grades A or B, thus a slightly higher fraction than for the
i'-band sample. For the systems found in z'- but not in i'-band,
we find that 26 (50%) are in these grade categories. Thus even though
the fraction of good grade systems is not as impressive, addition of
the z'-band detections will increase the size of the sample of
promising candidates by about 60%. At the same time, it also
increases the number of less promising (grade C) systems from 16 to
42, thus an increase of about 150%. For any application the final
decision on whether to use the samples separately or combined will
depend on the scientific aim. From this we conclude that the
z'-band is a significant contribution towards a more complete high-zsample, even though with the drawback of adding a relatively large
number of less promising systems.
6.2 Comparing Deep and Wide catalogues
An important question in designing imaging surveys for cluster
searches is how to balance the observing time between different
bands. Here we use the available Deep catalogues and compare them with
the Wide equivalent catalogues to discuss the value of deeper i'-
and z'-band data for the construction of a matched-filter cluster
catalogue reaching ![]() .
.
Table 8 gives the general properties of the four catalogues in question. It can be seen that for the i'-band the additional depth in the deep catalogue does not add much in terms of additional detections, while in the z'-band the candidate density is increased dramatically. Turning to the number density of false detections, it can be seen that the differences are very small with an insignificant increase of not even one detection per square degree.
In Fig. 6 the redshift distributions of the
candidates in the four different catalogues are compared. For the
i'-band the distributions are not very different, which is
consistent with the number of candidates being increased by only 11
(![]()
![]() )
between the shallow and the deep catalogues. For the
z'-band, the situation is very different. Here the deeper catalogue
has a large increase at the high-redshift end.
)
between the shallow and the deep catalogues. For the
z'-band, the situation is very different. Here the deeper catalogue
has a large increase at the high-redshift end.
The difference in the number of detections originate in both the
differences in limiting magnitude and in wavelength of the
filters. For the i'-band the 0.5 mag depth difference between the two
catalogues roughly corresponds to the difference in apparent Schechter
magnitude between two adjacent shells corresponding to a redshift
difference of 0.1. The difference is 0.8 mag for the z'-band and more
closely corresponds to the offset in apparent Schechter magnitude for
a redshift difference of 0.2, thus twice as large as for the
i'-band. This in itself would lead to an increase in the number of
detections in the z'-band relative to the i'-band. The other
effect, the different wavelength intervals covered by the filters,
leads to the shifting of the 4000 Å break through the i'-band
wavelengths for lower redshifts than for the z'-band. In fact, the
4000 Å break has shifted completely out of the i'-band filter at
![]() ,
where it starts moving through the z'-band
filter. Therefore, the z'-band catalogue is likely including
intrinsically fainter galaxies than the i'-band allowing for
detection of poorer systems, which in turn may correspond to the grade
C systems seen in the catalogue.
,
where it starts moving through the z'-band
filter. Therefore, the z'-band catalogue is likely including
intrinsically fainter galaxies than the i'-band allowing for
detection of poorer systems, which in turn may correspond to the grade
C systems seen in the catalogue.
Table 9:
Grade distributions of candidates in the shallow catalogues
upper part refers to all candidates and the lower half for the
high-redshift sample with ![]() .
.
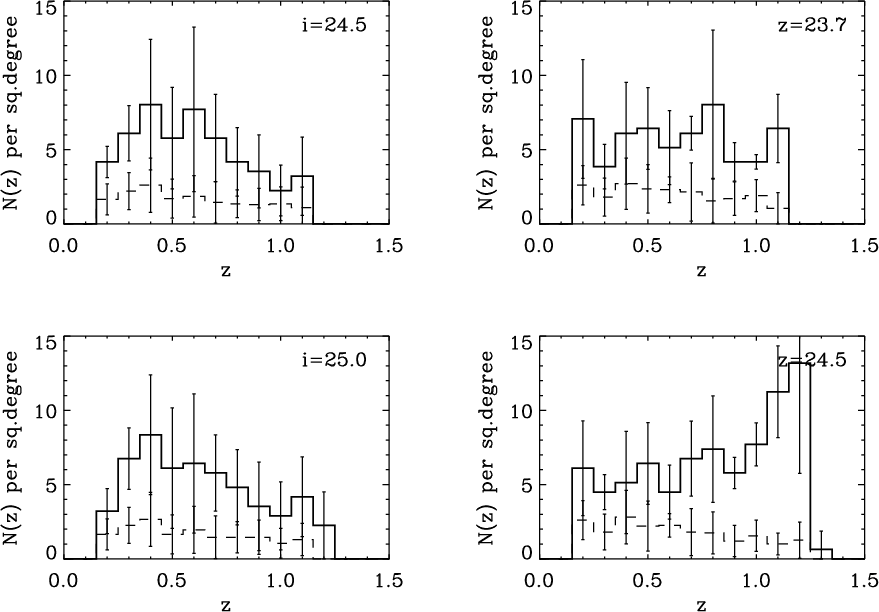 |
Figure 6: The redshift distribution for the candidates (solid line) and false detections (dashed lines) for the two magnitude limits and the two passbands as indicated in each panel. The error bars are field to field standard deviations. |
| Open with DEXTER | |
A better quantification of the value of deeper data to construct
cluster catalogues can be obtained from investigations of the systems
detected either only in the shallow or only in the deep catalogue in
the same band. To identify these detections we carried out a
matching for the catalogues extracted from the same band. Again, the
matching is carried out as in Sect. 5. For the
i'-band the overlap is very large with 146 detections in both
catalogues or alternatively only 12 detections in the shallow
catalogue not in the deep and 23 in the deep not in the shallow. In
the z'-band, there are 155 detections in common and 24 detections in
the shallow catalogue that were not found in the deep and 91 in the
deep not in the shallow. The large number of detections in the deep
catalogues not in the shallow is due, for both bands (though more
pronounced in z' than in i'), to additional high redshift
detections. The quality of the detections is important for assessing
the differences between the catalogues. Therefore,
Table 10 gives the grade distributions for the
detections found in either a shallow or a deep catalogue. For the
i'-band we find that the number of promising candidates is the same
in the two catalogues (in both the shallow and deep catalogue 9
systems are graded A or B), but the actual systems are different. In
addition, the number of less promising systems in the deep catalogue
is larger than in the shallow one. For the z'-band the number of
promising candidates in the deep catalogue is slightly higher (18)
than for the shallow catalogue (12). The number of grade C systems is
much greater in the deep z'-band catalogue than in any of the
others. In all cases most of the unmatched detections are found at
redshifts ![]() ,
which is even more pronounced for the deep than
for the shallow catalogues. From this we conclude that the depth of
the z'-band catalogue is important for building a complete cluster
sample at redshifts
,
which is even more pronounced for the deep than
for the shallow catalogues. From this we conclude that the depth of
the z'-band catalogue is important for building a complete cluster
sample at redshifts ![]() ,
though controlling purity remains an
issue.
,
though controlling purity remains an
issue.
7 Summary
We applied the matched-filter detection technique to the CFHTLS
Deep data in the r'- and z'-bands with limiting magnitudes of
25![]() and 24.5
and 24.5![]() ,
respectively. These catalogues are compared with
that of the i'-band with a limiting magnitude of 25
,
respectively. These catalogues are compared with
that of the i'-band with a limiting magnitude of 25![]() presented in
Paper I. The density of detections in r'-band is 36
presented in
Paper I. The density of detections in r'-band is 36 ![]() 4 and in
z'-band 80
4 and in
z'-band 80 ![]() 9. The estimated fraction of noise is 33% in
r'-band and 25% in the z'-band catalogues. Selection functions
are derived based on simple simulations and show that the r'-band
catalogue starts to become significantly incomplete at redshifts
9. The estimated fraction of noise is 33% in
r'-band and 25% in the z'-band catalogues. Selection functions
are derived based on simple simulations and show that the r'-band
catalogue starts to become significantly incomplete at redshifts
![]() ,
where only clusters in Abell richness classes
,
where only clusters in Abell richness classes ![]() are recovered at more than 80%. For the z'-band catalogue, the
corresponding redshift limit is
are recovered at more than 80%. For the z'-band catalogue, the
corresponding redshift limit is ![]() and the most distant
systems have redshifts beyond 1.
and the most distant
systems have redshifts beyond 1.
The constructed catalogues are compared with the one extracted from the i'-band data and presented in Paper I. The comparison is used to investigate the gain in terms of added leverage of the samples based on a combination of bands and in terms of additional detections missed in one of the bands. Using a grading based on a visual inspection of colour images of all the candidates, we conclude that the visual appearance of candidates detected in more than one band is not more promising than for the one-band samples individually. This result we attribute to the way the matched filter handles the background and cluster model. Since one of the main properties of a group of galaxies to enter into the catalogue is its concentration, the same concentration of galaxies is likely to appear in all bands. In terms of complementing the samples in i'-band, we find that the r'-band contribution is insignificant, while the candidates detected in z'-band are a significant contribution to the i'-band sample.
We also used the data to investigate what to expect for cluster
extraction in the ongoing CFHTLS Wide survey. This is accomplished by
restricting the search for clusters to the planned limiting magnitudes
of
![]() and
and
![]() .
With these numbers we find densities
of 51 and 58 detections per square degree in i' and z',
respectively, with estimated noise fraction of 33% in both cases. From
these numbers we estimated a total number of detections from the
completed wide catalogues of about 9000 with about 6000 of these
corresponding to clusters. Also in this case we compared the visual
appearance of the detections in the two catalogues and find results
similar to the deep case, i.e. the matched samples appear as promising
as the individual ones. Furthermore, the z'-band data are
important for complementing the i'-band catalogue at
.
With these numbers we find densities
of 51 and 58 detections per square degree in i' and z',
respectively, with estimated noise fraction of 33% in both cases. From
these numbers we estimated a total number of detections from the
completed wide catalogues of about 9000 with about 6000 of these
corresponding to clusters. Also in this case we compared the visual
appearance of the detections in the two catalogues and find results
similar to the deep case, i.e. the matched samples appear as promising
as the individual ones. Furthermore, the z'-band data are
important for complementing the i'-band catalogue at ![]() ,
increasing the number of candidates by
,
increasing the number of candidates by ![]()
![]() .
.
Table 10: Grade distributions of candidates in either a shallow or a deep catalogue.
Finally, we investigate the impact in terms of detections and quality
by decreasing the depth from the Deep to the Wide limiting
magnitudes. For the i'-band the difference between the two
catalogues is insignificant, while for the z'-band a large number of
systems is missed in the shallower case. Therefore, when planning
future matched filter cluster searches for clusters at ![]() it
may be preferable to increase the depth in z' and keep the i'-band
relatively more shallow, at least when reaching depths comparable to
the ones discussed here.
it
may be preferable to increase the depth in z' and keep the i'-band
relatively more shallow, at least when reaching depths comparable to
the ones discussed here.
Acknowledgements
We thank the anonymous referee for useful comments that helped improving the paper. The work was based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT), which is operated by the National Research Council (NRC) of Canada, the Institut National des Science de l'Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. This work is based in part on data products produced at TERAPIX and the Canadian Astronomy Data Centre as part of the Canada-France-Hawaii Telescope Legacy Survey, a collaborative project of NRC and CNRS. L.F.G. acknowledges financial support from the Danish Natural Sciences Research Council and the Poincaré fellowship programme atthe Observatoire de la Côte d'Azur. The Dark Cosmology Centre is funded by the Danish National Research Foundation.
References
- Bahcall, N., McKay, T., Annis, J., et al. 2003, ApJS, 148, 243 [NASA ADS] [CrossRef] (In the text)
- Borgani, S., Rosati, P., Tozzi, P., et al. 2001, ApJ, 561, 13 [NASA ADS] [CrossRef]
- Bower, R., Lucey, J., & Ellis, R. 1992, MNRAS, 254, 601 [NASA ADS]
- de Propris, R., Stanford, S. A., Eisenhardt, P. R., Dickinson, M., & Elston, R. 1999, AJ, 118, 719 [CrossRef]
- Gavazzi, R., & Soucail, G. 2007, A&A, 462, 459 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Gladders, M., & Yee, H. 2000, AJ, 120, 2148 [NASA ADS] [CrossRef]
- Gladders, M., & Yee, H. 2005, ApJS, 157, 1 [NASA ADS] [CrossRef] (In the text)
- Goto, S., Nichol, B. L, Kim, A., et al. 2002, AJ, 123, 1807 [NASA ADS] [CrossRef]
- Kepner, J., Fan, X., Bahcall, N., Gunn, J., & Lupton, R. 1999, ApJ, 517, 78 [CrossRef]
- Kim, R., Kepner, J., Postman, M., et al. 2002, AJ, 123, 20 [NASA ADS] [CrossRef]
- Koester, B. P., McKay, T. A., Annis, J., et al. 2007, ApJ, 660, 221 [NASA ADS] [CrossRef]
- Mazure, A., Adami, C., Pierre, M., et al. 2007, A&A, 467, 49 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Miller, C. J., Nichol, R. C., Reichart, D., et al. 2005, AJ, 130, 968 [NASA ADS] [CrossRef]
- Olsen, L. F., Scodeggio, M., da Costa, L., et al. 1999a, A&A, 345, 681
- Olsen, L. F., Scodeggio, M., da Costa, L., et al. 1999b, A&A, 345, 363
- Olsen, L. F., Benoist, C., Cappi, A., et al. 2007, A&A, 461, 81 [NASA ADS] [CrossRef] [EDP Sciences] (Paper I) (In the text)
- Popesso, P., Böhringer, H., Romaniello, M., & Voges, W. 2005, A&A, 433, 415 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Postman, M., Lubin, L., Gunn, J., et al. 1996, AJ, 111, 615 [NASA ADS] [CrossRef]
- Postman, M., Lauer, T., Oegerle, W., & Donahue, M. 2002, ApJ, 579, 93 [NASA ADS] [CrossRef] (In the text)
- Rosati, P., della Ceca, R., Norman, C., & Giacconi, R. 1998, ApJ, 492, L21 [NASA ADS] [CrossRef] (In the text)
- Rosati, P., Borgani, S., & Norman, C. 2002, ARA&A, 40, 539 [NASA ADS] [CrossRef]
- Schechter, P. 1976, ApJ, 203, 297 [NASA ADS] [CrossRef] (In the text)
- Schlegel, D., Finkbeiner, D., & Davis, M. 1998, ApJ, 500, 525 [NASA ADS] [CrossRef] (In the text)
- Scodeggio, M., Olsen, L. F., da Costa, L., et al. 1999, A&AS, 137, 83 [CrossRef] [EDP Sciences]
- Stanford, S., Eisenhardt, P., & Dickinson, M. 1998, ApJ, 492, 461 [NASA ADS] [CrossRef]
Footnotes
- ... CFHTLS
- Tables 4 and 5 are only available in electronic form at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsweb.u-strasbg.fr/cgi-bin/qcat?J/A+A/494/845
- ...
- Previously, L. F. Olsen.
- ... RCS2
- http://www.rcs2.org
- ...
CFHTLS
- http://www.cfht.hawaii.edu/Science/CFHLS
- ...
- We use
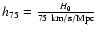 .
.
- ...
2006
- http://terapix.iap.fr/rubrique.php?id_rubrique=208&PHPSESSID=68382a75ec8b2e8b05a4e0dd5371e838
- ...
patches
- http://terapix.iap.fr/cplt/oldSite/Descart/summarycfhtlswide.html
All Tables
Table 1: Characteristics of the released data in the r'- and z'-bands of the T0003 Terapix release.
Table 2: Detection and filtering parameters for building the cluster catalogues.
Table 3:
The estimated fraction of false-positives for each of the
three passbands using a minimum area of ![]()
![]() and
different detection thresholds.
and
different detection thresholds.
Table 4: The first five entries of the cluster candidate catalogue for the r'-band. The full table is available at the CDS.
Table 5: The first five entries of the cluster candidate catalogue for the z'-band. The full table is available at the CDS.
Table 6: The matches between r'- and z'-band with no i'-band detection.
Table 7: Key numbers for the matching between the new catalogues and the one based on the i'-band from Paper I.
Table 8: Main properties of the 4 catalogues used for investigating the added value of the different depths.
Table 9:
Grade distributions of candidates in the shallow catalogues
upper part refers to all candidates and the lower half for the
high-redshift sample with ![]() .
.
Table 10: Grade distributions of candidates in either a shallow or a deep catalogue.
All Figures
| |
Figure 1: Average galaxy number counts (filled dots with error bars) for the four Deep fields in the r'- and z'-band as indicated in each panel. The number counts for the individual fields are shown as follows: D1 - solid line; D2 - dotted line; D3 - short-dashed line; and D4 - long-dashed line. The vertical dotted lines denote our adopted magnitude limit for the present analysis. |
| Open with DEXTER | |
| In the text | |
| |
Figure 2: Redshift ( top) and richness ( bottom) distributions (solid line) for all the candidate clusters in the r'- ( left) and z'-band ( right) catalogues. The distributions for the false detections (dashed lines) are estimated using the simulated backgrounds described in the text. For the redshift distributions the error bars denote the scatter between the fields. |
| Open with DEXTER | |
| In the text | |
| |
Figure 3:
The recovery rate as derived for each band
( from top to bottom: r', i' and z') used in the present work. The lines cover
different richness classes:
|
| Open with DEXTER | |
| In the text | |
| |
Figure 4: The i'-band redshift and grade distribution of candidates in the i'-band ( upper panel) and matched between r'- and i'-band ( middle panel) and i'- and z'-band ( lower panel) of all candidates graded A (dark grey), B (light grey) and C (no shading). |
| Open with DEXTER | |
| In the text | |
| |
Figure 5: The i'-band redshift and grade distribution of candidates in the i'-band ( upper panel). The middle panel shows the redshift and grade distributions for systems detected in r' but not in i'and the lower panel those detected in z' but not in i'. The shading denotes the different grades as follows: grade A (dark grey), B (light grey), and C (no shading). |
| Open with DEXTER | |
| In the text | |
| |
Figure 6: The redshift distribution for the candidates (solid line) and false detections (dashed lines) for the two magnitude limits and the two passbands as indicated in each panel. The error bars are field to field standard deviations. |
| Open with DEXTER | |
| In the text | |
Copyright ESO 2009
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.