| Issue |
A&A
Volume 623, March 2019
|
|
|---|---|---|
| Article Number | A97 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201834450 | |
| Published online | 11 March 2019 | |
Evolution of superclusters in the cosmic web
1
Tartu Observatory, 61602 Tõravere, Estonia
e-mail: jaan.einasto@to.ee, einasto@aai.ee
2
ICRANet, Piazza della Repubblica 10, 65122 Pescara, Italy
3
Estonian Academy of Sciences, 10130 Tallinn, Estonia
Received:
17
October
2018
Accepted:
26
January
2019
Aims. We investigate how properties of the ensemble of superclusters in the cosmic web evolve with time.
Methods. We performed numerical simulations of the evolution of the cosmic web using the Λ cold dark matter model in box sizes L0 = 1024, 512, 256 h−1 Mpc. We found supercluster ensembles of models for four evolutionary stages, corresponding to the present epoch z = 0, and to redshifts z = 1, z = 3, and z = 10. We calculated fitness diameters of superclusters defined from volumes of superclusters divided by filling factors of over-density regions. Geometrical and fitness diameters of largest superclusters, and the number of superclusters as functions of the threshold density were used as percolation functions to describe geometrical properties of the ensemble of superclusters in the cosmic web. We calculated the distributions of geometrical and fitness diameters and luminosities of superclusters, and followed the time evolution of percolation functions and supercluster distributions. We compared percolation functions and supercluster distributions of models and samples of galaxies of the Sloan Digital Sky Survey (SDSS).
Results. Our analysis shows that fitness diameters of superclusters have a minimum at a certain threshold density. Fitness diameters around minima almost do not change with time in co-moving coordinates. Numbers of superclusters have maxima which are approximately constant for all evolutionary epochs. The geometrical diameters of superclusters decrease during the evolution of the cosmic web, and the luminosities of superclusters increase during this evolution.
Conclusions. Our study suggests that evolutionary changes occur inside supercluster cells of dynamical influence. The stability of fitness diameters and numbers of superclusters during the evolution is an important property of the cosmic web.
Key words: large-scale structure of Universe / dark matter / cosmology: theory / methods: numerical
© ESO 2019
1. Introduction
The large-scale distribution of galaxies in the Universe is very complex. Density enhancements of various sizes and shapes exist, such as clusters of galaxies, filaments, walls, and low-density regions (voids) between high-density regions. The largest building blocks of the Universe are superclusters of galaxies. The supercluster concept was introduced by de Vaucouleurs (1953, 1958) for the Local or Virgo supercluster. Superclusters as clusters of rich clusters of galaxies were defined by Abell (1958) and Abell et al. (1989). Actually superclusters are much richer; they contain, in addition to rich Abell type clusters, poor (Zwicky et al. 1968) clusters, and galaxies. But most importantly, cluster and galaxy filaments link superclusters to a connected network, called the cellular structure (Jõeveer & Einasto 1978), supercluster-void network (Einasto et al. 1980), or cosmic web (Bond et al. 1996).
Cosmic web elements can be selected using various methods. Cautun et al. (2014) give a good overview about various structure-finding algorithms. Among these methods are the multi-scale morphology filter by Aragón-Calvo et al. (2010a), the Bayesian sampling of the density field by Jasche et al. (2010). The largest elements of the cosmic web are superclusters of galaxies. The definition of superclusters is not very precise since they have no well-fixed boundaries. Catalogues of rich clusters of galaxies by Abell (1958) and Abell et al. (1989) were used by Einasto et al. (1994, 1997, 2001), to compile all-sky catalogues of superclusters. The luminosity density field method was used by Einasto et al. (2007) based on the Two degree Field (2dF) redshift survey. Costa-Duarte et al. (2011), Luparello et al. (2011) and Liivamägi et al. (2012) used the Sloan Digital Sky Survey (SDSS) for supercluster search. Chon et al. (2015) analysed the definition of superclusters and suggested using the term “superstes-clusters” for overdense regions which would eventually collapse in the future.
To identify structures in the density field, it is necessary to define a density threshold to separate high-density regions (superclusters) from low-density regions (voids). There is no natural value of the threshold density. Costa-Duarte et al. (2011) applied two criteria for the selection of superclusters: one threshold density which maximises the number of superclusters, and the other which selects the largest supercluster length (diameter) ≈120 h−1 Mpc, as adopted by Einasto et al. (2007). Liivamägi et al. (2012) used two methods for a supercluster search: one with a fixed density threshold; and the other with an adaptive density threshold, depending on the distribution of galaxies in the particular region.
Large-scale systems of galaxies remember their history well since the crossing time in these systems is much greater than in small systems (Jõeveer & Einasto 1977). The evolution of the cosmic web can be investigated by numerical simulations, and results of simulations can be compared with observations. These studies have a long history (Aarseth et al. 1979; Doroshkevich et al. 1982; Zeldovich et al. 1982; White et al. 1983). Recent advances in the study of the cosmic web and its evolution are summarised in the Zeldovich symposium report (van de Weygaert et al. 2016). In most studies the evolution of the whole web is considered. Special studies are devoted to investigating the evolution of components of the web, such as clusters and voids. Luparello et al. (2011) and Gramann et al. (2015) investigated the future evolution of superclusters as virialised structures.
The goal of the present study is to investigate the evolution of the ensemble of superclusters in the cosmic web. Superclusters are the largest known coherent structures of the Universe. Large-scale density perturbations play an important role in the formation of superclusters. To include large-scale density perturbations we performed numerical simulations of the evolution in a box of size L0 = 1024 h−1 Mpc. As shown by Klypin & Prada (2018), larger simulation boxes are not needed to understand main properties of the cosmic web. For comparison we also used simulations in smaller boxes of sizes L0 = 512, 256 h−1 Mpc.
To describe geometrical properties of the ensemble of superclusters in the cosmic web we use the extended percolation analysis by Einasto et al. (2018). A critical parameter in the search of superclusters is the density threshold to divide the density field into high- and low-density regions. In percolation analysis high-density regions are called clusters, and low-density regions are referred to as voids (Stauffer 1979). We use density fields smoothed with 8 h−1 Mpc kernel. In this case high-density regions can be called superclusters. We find ensembles of superclusters of models for four epochs, corresponding to the present epoch z = 0, and to redshifts z = 1, z = 3, and z = 10. We vary the density threshold in broad limits, divide the density field at each threshold density into high- and low-density systems, and select the largest superclusters. The lengths and volumes of largest superclusters, and the numbers of superclusters at respective threshold density levels, are used as percolation functions.
In addition to geometrical diameters of superclusters, we introduce fitness volumes and diameters of superclusters into our analysis. Fitness volumes are proportional to their geometrical volumes, weighted by a factor to get the whole volume of the sample for the sum of fitness volumes. We use fitness volumes to calculate fitness diameters and use the distribution of fitness diameters of largest superclusters as an additional percolation function. Percolation functions are used to describe properties of the whole ensemble of superclusters. We also derive distributions of sizes and masses of superclusters. The comparison of percolation functions and size and mass distributions for different epochs allows us to study the evolution of the ensemble of superclusters. For comparison we use the main sample of the SDSS DR8 survey to calculate the luminosity density field of galaxies, and to find percolation functions of the SDSS sample. Thorough this paper we use the Hubble parameter H0 = 100 h km s−1 Mpc−1.
The paper is organised as follows. In the next Section we describe the calculation of the density field of observed and simulated samples, the method to find superclusters and their parameters, and supercluster fitness diameters. In Sect. 3 we perform percolation analysis of simulated superclusters, and investigate changes of percolation functions and supercluster parameters with time. We also compare percolation properties of model and SDSS samples and the dependence of percolation properties on parameters of the cosmic model. The last Section brings the general discussion and summary remarks.
2. Data
To find superclusters we have to fix the supercluster definition method and basic parameters of the method. We used the density field method. This method allows us to use flux-limited galaxy samples and to take into account galaxies that are too faint to be included in the flux-limited samples. We define superclusters as large non-percolating, high-density regions of the cosmic web. Based on our previous experience we used the luminosity (matter in simulations) density field for the supercluster search, calculated with the B3 spline of kernel size RB = 8 h−1 Mpc. The determination of the second parameter of the supercluster search, which is the threshold density, is discussed below.
2.1. Simulation of the cosmic web
We performed simulations in the conventional Λ cold dark matter model (ΛCDM) with parameters Ωm = 0.286, ΩΛ = 0.714, and Ωtot = 1.000. The initial density fluctuation spectra were generated using the COSMICS code by Bertschinger (1995). To generate the initial data we used the baryonic matter density Ωb = 0.044 (Tegmark et al. 2004). Calculations were performed with the GADGET-2 code by Springel (2005). Particle positions and velocities were extracted for seven epochs between redshifts z = 30…0. We searched for superclusters at four cosmological epochs, corresponding to redshifts z = 0, z = 1, z = 3, and z = 10. The resolution of all simulations was Npart = Ncells = 5123, the size of the simulation box was L0 = 1024 h−1 Mpc, the volume of simulation box was V0 = 10243 (h−1 Mpc)3, and the size of the simulation cell was 2 h−1 Mpc. This box size is sufficient to see the role of large-scale density perturbations to the evolution of superclusters, which have characteristic lengths up to ∼100 h−1 Mpc (Liivamägi et al. 2012). We designated the simulation with the box size L0 = 1024 h−1 Mpc as L1024.z, where the index z notes the simulation epoch redshift. To see the dependence of results on the size of the simulation box we also used simulations in L0 = 512 h−1 Mpc and L0 = 256 h−1 Mpc boxes; these simulations are designed as L512.z and L256.z. Data on simulated and SDSS superclusters are given in Table 1.
Parameters of model and SDSS superclusters.
2.2. SDSS data
The density field method allows us to use flux-limited galaxy samples and to take statistically into account galaxies too faint to be included to the flux-limited samples, as applied among others by Einasto et al. (2003, 2007), and Liivamägi et al. (2012) to select superclusters of galaxies.
We used the SDSS Data Release 8 (DR8; Aihara et al. 2011) and galaxy group catalogue by Tempel et al. (2012) to calculate the luminosity density field. In the calculation of the luminosity density field we took into account the selection effects present in flux-limited samples (Tempel et al. 2009; Tago et al. 2010). In the calculation of the luminosity density field, galaxies were selected within the apparent r magnitude interval 12.5 ≤ mr ≤ 17.77 (Liivamägi et al. 2012). In the nearby region relatively faint galaxies are included in the sample, in more distant regions only the brightest galaxies are seen. To take this into account, we calculated a distance-dependent weight factor,
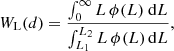
where L1, 2 = L⊙100.4(M⊙ − M1, 2) are the luminosity limits of the observational window at distance d, corresponding to the absolute magnitude limits of the window M1 and M2. The weight factor WL(d) increases to ≈8 at the far end of the sample. Liivamägi et al. (2012) provided a more detailed description of the calculation of the luminosity density field and corrections used. The algorithm to find superclusters is described below. The volume of the SDSS main galaxy sample is (509 h−1 Mpc)3 (Liivamägi et al. 2012).
2.3. Calculation of the density field
We determined the density field using a B3 spline (see Martínez & Saar 2002) as follows:
![$$ \begin{aligned} B_3(x)=\frac{1}{12}\left[|x-2|^3-4|x-1|^3+6|x|^3-4|x+1|^3+|x+2|^3\right]. \end{aligned} $$](/articles/aa/full_html/2019/03/aa34450-18/aa34450-18-eq2.gif)
This function is different from zero only in the interval x ∈ [ − 2, 2]. To calculate the high-resolution density field we used the kernel of the scale, equal to the cell size of the simulation, L0/Ngrid, where L0 is the size of the simulation box, and Ngrid is the number of grid elements in one coordinate. The smoothing with index i has a smoothing radius ri = L0/Ngrid × 2i. The effective scale of smoothing is equal to ri. We applied this smoothing up to index 6. For models of the L1024 series smoothing index 2 corresponds to the kernel of radius 8 h−1 Mpc, for models of L512 and L256 series smoothing indexes 3 and 4 correspond to kernel radius 8 h−1 Mpc. Most calculations were performed with the model in the simulation box of size L0 = 1024 h−1 Mpc, and with smoothing scale RB = 8 h−1 Mpc. To see the dependence of results on the smoothing scale we made calculations for the L0 = 1024 h−1 Mpc model using smoothing kernels of sizes RB = 4 h−1 Mpc and RB = 16 h−1 Mpc. These model series are noted as F1024 for the RB = 4 h−1 Mpc case, and E1024 for the RB = 16 h−1 Mpc case (F for Fine and E for Extended).
2.4. Percolation functions and cluster parameters
The percolation analysis consists of several steps: finding over-density regions (clusters as potential superclusters) in the density field, calculation of parameters of potential superclusters, and finding the supercluster with the largest volume for a given density threshold. As traditional in the percolation analysis, over-density regions are called clusters in the general case (Stauffer 1979).
We scanned the density field in the range of threshold densities from Dt = 0.1 to Dt = 10 in mean density units. We used a linear step of densities, ΔDt = 0.1, to find over- and under-density regions. This range covers all densities of practical interest, since in low-density regions the minimal density is ≈0.1, and the density threshold to find conventional superclusters is Dt ≈ 5 (Liivamägi et al. 2012). We marked all cells with density values equal or above the threshold Dt as filled regions, and all cells below this threshold as empty regions.
Inside the first loop we made another loop over all filled cells to find neighbours among filled cells. Two cells of the same type are considered as neighbours (friends) and members of the cluster if they have a common sidewall. Every cell can have at most six cells as neighbours. Members of clusters are selected using a friend-of-friend (FoF) algorithm: the friend of my friend is my friend. To exclude very small systems, only systems with fitness diameters at least 20 h−1 Mpc are added to the list of over-density regions (see below for the definition of fitness diameters).
The next step is the calculation of parameters of clusters. We calculated the following parameters: centre coordinates, xc, yc, zc; diameters (lengths) of clusters along coordinate axes, Δx, Δy, Δz; geometrical diameters (lengths), 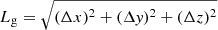 ; fitness diameters (lengths), Lf, discussed in the next subsection; geometrical volumes, Vg, defined as the volume in space where the density is equal or greater than the threshold density Dt; and total masses (or luminosities), ℒ, the mass (luminosity) inside the density contour Dt of the cluster, in units of the mean density of the sample. We also calculated total volume of over-density regions, equal to the sum of volumes of all clusters, VC = ∑Vg, and the respective total filling factor,
; fitness diameters (lengths), Lf, discussed in the next subsection; geometrical volumes, Vg, defined as the volume in space where the density is equal or greater than the threshold density Dt; and total masses (or luminosities), ℒ, the mass (luminosity) inside the density contour Dt of the cluster, in units of the mean density of the sample. We also calculated total volume of over-density regions, equal to the sum of volumes of all clusters, VC = ∑Vg, and the respective total filling factor,
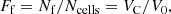
where Nf is the number of filled (over-density) simulation cells, and V0 is the volume of the sample.
During the cluster search we found the cluster with the largest volume for the given threshold density. We stored the number of clusters found, N(Dt), in a separate file for each threshold density as well as the main data on the largest cluster: the geometrical diameter, Lg(Dt); the fitness diameter, Lf(Dt); the geometrical volume Vg(Dt); the mass (luminosity) of the largest cluster, ℒ(Dt); and the total filling factor, Ff(Dt). Diameters are found in h−1 Mpc, volumes in cubic h−1 Mpc, masses/luminosities in units of the mean density of the sample. These parameters as functions of the density threshold Dt are called percolation functions. They are needed to characterise general geometrical properties of the ensemble of superclusters in the cosmic web and to select the proper threshold density to compile the actual supercluster catalogue. In total we have for every evolutionary stage 100 catalogues of clusters (over-density regions) as potential supercluster catalogues. We note that Einasto et al. (2018) used filling factor of largest clusters, ℱ(Dt)=Vmax/V0 as a percolation function.
We calculated for each model the variance of the density contrast,
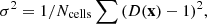
where D(x) is the density at location x, and summing is over all cells of the density field. The dispersion of the density contrast σ depends on the smoothing length RB and the cosmic epoch z of models, as shown below.
In observational studies of superclusters, defined on the basis of luminosity density field, it is natural to use the density threshold in mean density units, Dt, to divide the field into high- and low-density regions. We did all our calculations using density threshold in these units. However, in a theoretical interpretation of results it is more convenient to express densities and threshold densities in units of the dispersion of the density contrast (Yess & Shandarin 1996; Sahni et al. 1997; Colombi et al. 2000). Thus we recalculated all of the percolation functions using as arguments density thresholds reduced to unite value of the dispersion of the density contrast as follows:
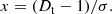
In the discussion below we use, depending on the task, threshold densities in both units.
2.5. Supercluster fitness diameters
We define the fitness volume of the supercluster, Vf, proportional to its geometrical volume, Vg, divided by the total filling factor, as
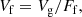
or, using the definition of the total filling factor of all over-density regions at this threshold density, Eq. (3),
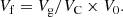
In this way we obtain for the sum of fitness volumes the volume of the sample. In earlier percolation studies the volume (or the filling factor) of the largest cluster and the total filling factor were considered as separate characteristics (Klypin & Shandarin 1993; Sahni et al. 1997; Shandarin & Yess 1998). We combined these parameters into one new parameter. The fitness volume measures the ratio of the supercluster volume to the volume of all superclusters (all filled over-density regions) at the particular threshold density, multiplied by the whole volume of the sample. This is somewhat analogous to the fatness factor defined by Einasto et al. (2018) as the ratio of the volume of the cluster to its maximal possible volume for a given geometrical diameter. Fatness and fitness volumes of superclusters measure the volume of the supercluster in different ways: in one case in relation to its maximal possible value and in the other case in relation to the summed volume all superclusters.
Fitness diameters (lengths) of superclusters are calculated from their fitness volumes as follows:
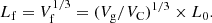
Fitness diameters of the largest superclusters are found for all threshold densities, Dt. We used fitness diameters of largest superclusters, Lf(Dt), as a percolation function, in addition to other percolation functions, i.e. geometrical diameters, Lg(Dt), total filling factors, Ff(Dt), and numbers of clusters, N(Dt).
At very small threshold densities the largest supercluster occupies almost the whole volume of the samples. Thus, by definition, the fitness diameter at very small threshold densities is approximately equal to the size of the sample, Lf = L0. At very high threshold densities the largest supercluster is the only supercluster; its volume is equal to the volume of all filled cells, and by definition also Lf = L0. At medium threshold densities the volume of the largest supercluster is smaller than the volume of all filled cells, Vg < VC; thus fitness diameters are smaller than the size of the sample and follow at threshold densities Dt ≤ 2 approximately geometrical diameters. However, geometrical diameters of the largest superclusters decrease with increasing threshold density almost continuously. In contrast, fitness diameters of the largest superclusters have a minimum at a certain threshold density. This minimum shows that the largest supercluster has the smallest volume fraction Vg/VC. The minimum of the fitness diameter corresponds to the maximum of the fragility of the supercluster as a function of threshold density, and can be used as an additional parameter to characterise the structure of the cosmic web at supercluster scales, and to find the threshold density for supercluster selection.
3. Analysis of models
3.1. Percolation functions of L1024 model samples
We use percolation functions to characterise geometrical properties of the cosmic web and to select superclusters. Superclusters are defined as large non-percolating, high-density regions of the density field, smoothed with 8 h−1 Mpc scale. To select superclusters we have to find the proper value of threshold density to divide the density field to over- and under-density regions. We use percolation functions for this purpose. Figure 1 shows geometrical length functions, Lg, fitness diameter functions, Lf, and numbers of clusters, N. Upper panels show these functions for the L1024 model, in the following panels for models of series L512, L256, F1024, and E0124 all for redshifts z = 0, z = 1, z = 3, and z = 10. In this figure we use the reduced threshold density, x = (Dt − 1)/σ, as arguments of percolation functions.
 |
Fig. 1. Left panels: geometrical length functions. Middle panels: fitness length functions. Right panels: number functions. As arguments of percolation functions we use the reduced threshold density, x = (Dt − 1)/σ. Panels from top down are for models L1024, L512, L256, F1024, and E1024. |
Let us concentrate first on the behaviour of the model L1024 at the present epoch, L1024.0. At small threshold densities, Dt ≤ 2 (x ≤ 0), there exists one percolating cluster, extending over the whole volume of the computational box; we use “clusters” as a general term to designate over-density regions. The percolation threshold density, P = Dt, is defined as follows: for Dt ≤ P there exists one and only one percolating cluster and for Dt > P there are no percolating clusters (Stauffer 1979). Percolation threshold densities, P, and reduced percolation threshold densities, xP = (P − 1)/σ, are given in Table 1. As we see, the reduced percolation threshold density of all models and epochs is almost identical, xP ≈ 1.5. In the reduced threshold density range x ≤ 1.5 geometrical diameters of clusters are equal to the diameter of the box, 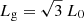 , and their fitness diameters are equal to the side-length of the box, Lf = L0.
, and their fitness diameters are equal to the side-length of the box, Lf = L0.
When we increase the threshold density, then at x ≈ 0 there appear additional clusters, and the number of clusters N starts to increase rapidly. At percolating threshold, x ≈ 1.5, geometrical and fitness diameters of largest clusters, Lg and Lf, start to decrease: the large percolating cluster splits to smaller clusters. At Dt = Dmax ≈ 2.7 (xmax ≈ 2.5), the number of clusters reaches a maximum Nmax ≈ 8300. Dmax, xmax, Nmax and respective geometrical and fitness diameters of the largest clusters at this threshold are given in Table 1. At this threshold density clusters are still complexes of large over-density regions, connected by filaments to form systems of diameters Lg ≈ 300 h−1 Mpc and Lf ≈ 200 h−1 Mpc, i.e. the largest over-density regions are actually complexes of superclusters. The observed sample SDSS has similar behaviour near Dt = Dmax.
When we increase the threshold density more, then the number of clusters starts to decrease, since smallest clusters have maximal densities that are lower than the threshold density and disappear from the cluster sample. At Dt ≈ 4 (x ≈ 4.5), geometrical and fitness diameters of the largest clusters become close, Lg ≈ Dd ≈ 150 h−1 Mpc. With further increase of the density threshold geometrical diameters decrease, but fitness diameters have a minimum and thereafter start to increase. The reason for this behaviour is simple – fitness diameters are calculated from volumes of clusters by dividing geometrical volumes to total filling factors, Vf(Dt)=Vg(Dt)/Ff(Dt). At this threshold density range the total filling factor of over-density regions, Ff(Dt), decreases with increasing Dt more rapidly than the decrease of the geometrical (i.e. the actual) volume of the largest clusters, Vg(Dt).
An important aspect of this behaviour is the fact that fitness diameters of the largest clusters have a global minimum, Lf(Dt)≈140 at Dt = 4.2 (xt = 5 for the model L1024.0). The geometrical diameter of the largest clusters at this threshold density is Lg ≈ 115 h−1 Mpc, similar to diameters of the largest superclusters known from catalogues by Einasto et al. (2007) and Liivamägi et al. (2012), based on 2dF and SDSS density fields. This means, that the global minimum of fitness diameters can be used as an additional parameter to fix the threshold density to find superclusters among clusters as supercluster candidates. However, caution is needed. In the model L1024.0 the region of low values of the fitness diameters is rather large, and has local minima at x = 2.8, 5.0, 8.0. Each of these minima marks breaks of the largest cluster into smaller systems; see Liivamägi et al. (2012).
We denote the threshold density to find superclusters in our samples as Dt (xt in reduced threshold density units). Threshold densities Dt and xt, respective numbers of superclusters Nscl, geometrical and fitness lengths Lg and Lf, are given in Table 1. The mean reduced threshold density to find superclusters in our model samples has a large scatter with a mean value ≈3.5. At threshold density Dt the total filling factor of high-density regions lies in the interval 0.007 ≤ Ff ≤ 0.02 (see Table 1), and the respective correction factor to calculate the fitness volumes has values 1/Ff ≈ 100. It is remarkable that in spite of this large correction factor geometrical and fitness diameters of largest superclusters are so similar.
3.2. Changes of cluster diameters with time
Supercluster geometrical diameter (length) functions of our model samples are shown in Fig. 1 for redshifts z = 0, z = 1, z = 3, and z = 10. At small threshold densities the over-density region extends over the whole sample (largest clusters are percolated) and the geometrical diameter of the largest cluster is equal to the diameter of the box. With increasing threshold density the largest over-density region splits into smaller units – superclusters and their complexes – until only central regions of superclusters have densities higher than the threshold density. Geometrical diameters decrease with increasing threshold density to a value about 30 h−1 Mpc at Dt = 10 (x = 14 for the model L1024.0). This picture is shifted to lower threshold densities when we consider earlier epochs at higher redshifts (diameters are expressed in co-moving coordinates). At epoch z = 10 clusters exist only at threshold densities Dt ≤ 1.6 (x ≤ 9.5).
The behaviour of fitness diameters is different; they have a minimum at a certain threshold density. Minimal fitness diameters of our models at various evolutionary epochs are given in Table 1 and shown in Fig. 2. Minimal fitness diameters of models are almost identical at all epochs (in co-moving coordinates); for the model L1024 Lf ≈ 140 h−1 Mpc. Geometrical diameters at minima of fitness diameters are Lg ≈ 115 h−1 Mpc for epochs z ≤ 3, and a bit more at z = 10 (both in co-moving coordinates).
 |
Fig. 2. Left panel: evolution of minimal fitness lengths with epoch, Lf(z). Right panel: evolution of the spatial density of maximal numbers of clusters with epoch, N(z), per cubic cell of size L0 = 1 h−1 Gpc. Model designations as in Table 1. |
3.3. Changes of cluster numbers with time
Right panels of Fig. 1 show numbers of clusters as functions of the reduced threshold density. As noted above, at very low threshold densities the whole over-density region contains one percolating cluster since peaks of the density field are connected by filaments to a connected region. With increasing threshold density some filaments became fainter than the threshold density and the connected region splits into smaller units. At reduced threshold density x ≈ −0.5 the number of clusters starts to increase rapidly with increasing threshold density. The number of clusters reaches a maximum, Nmax, at threshold density Dmax. The Table shows that at the earliest epoch the mean value of reduced threshold densities at maximum is xmax ≈ 2.5, increasing to xmax ≈ 3.0 at the present epoch; in the mean xmax = 2.9 ± 0.5.
Figure 2 presents the evolution of maximal numbers of superclusters, N(z); in this figure numbers are actually spatial densities of superclusters, reduced to the volume of the sample of size L0 = 1 h−1 Gpc. Figures 1 and 2, and Table 1 show that maximal numbers of clusters are very similar at all evolutionary stages of the cosmic web, Nmax ≈ 8500 for the model L1024. The almost constant reduced threshold density at maximum and the stability of the maximum itself are remarkable properties of the evolution of the cosmic web. In most models the number of clusters at maxima is higher at earlier epochs, but only a bit. This hints at the evolution: some small clusters have merged with larger clusters during the evolution. However, the effect is surprisingly small.
The decrease of the number of clusters with increasing reduced threshold density x after the maximum is more rapid at earlier epochs. At some threshold density, the highest peaks of the density field are lower than the threshold density; there are no clusters at thresholds higher than this limit.
3.4. Influence of sample size
To find the influence of sample size on the evolution of geometric properties of superclusters in the cosmic web, we used simulations in boxes of sizes L0 = 512 and 256 h−1 Mpc with smoothing lengths RB = 8 h−1 Mpc. The main results for these simulations are given in Table 1 and in Figs. 1 and 2. We see that at all ages geometrical length functions of L512 models are rather similar to respective functions of L1024 models. Number functions are also similar, but maximal numbers of clusters of the L512 model are about eight times lower than in the L1024 model, as expected in a model that has a box size two times smaller. But spatial densities of clusters are almost identical, as shown in Fig. 2.
One difference in the L512 model from the L1024 model lies in the form of the fitness length function: it has no well-defined global minimum. There are four minima of lengths Lf = 140 ± 1 h−1 Mpc at threshold densities Dt = 3.2, 3.6, 5.0, 6.2 (x = 3.4, 4.1, 6.2, 8.1); geometrical lengths at these threshold densities are Lg = 165, 155, 81, 39 h−1 Mpc, respectively. This shows that fitness length minima alone are not sufficient to select superclusters; both geometrical and fitness lengths are needed to have a proper choice.
In the model L256, minima of fitness length functions are lower than in models of larger box sizes, as seen in Table 1 and Figs. 1 and 2. Global minima of fitness lengths are lower than in models of larger box sizes. Maximal numbers of clusters are approximately eight times lower than in the model L512, but spatial densities of clusters are almost identical. As in models of larger box sizes maximal numbers of clusters at different epochs are very close to each other, as shown in Fig. 2. The scatter of all geometrical parameters is larger than in models of larger box sizes, as expected.
The general behaviour of the fitness length functions of the L1024, L512, and L256 models is also rather similar. Minima of fitness length functions at different epochs have a spread Lf = 148 ± 3 h−1 Mpc for the L1024 model, Lf = 129 ± 6 h−1 Mpc for the L512 model, and Lf = 100 ± 5 h−1 Mpc for the L256 model. This means that minima of fitness functions are almost independent of the cosmic epoch, but are smaller for models of smaller box sizes. A likely explanation of this difference is the size of the models; boxes of models L512 and L256 are not large enough to fit very large density waves, which are needed to form the largest superclusters.
3.5. Influence of smoothing length
The search for superclusters has traditionally used density fields smoothed on 8 h−1 Mpc scale. To see how geometrical properties of ensembles of clusters (over-density regions) depend on the smoothing length we calculated percolation functions of the L1024 model using smoothing lengths RB = 4 h−1 Mpc and RB = 16 h−1 Mpc; respective models are designed as F1024 and E1024. Percolation functions of these models are plotted in Fig. 1, and the main parameters of models are given in Table 1.
In the model F1024 densities have a higher contrast than in the model L1024. The F1024 model selects smaller clusters (over-density regions) than the L1024 model, thus maximal numbers of clusters are about three times higher; see Fig. 2. Global minima of fitness lengths at different epochs are Lf = 111 ± 11 h−1 Mpc, which is smaller than in the L1024 model, Lf = 148 ± 3.
The model E1024 has a lower density contrast than L1024 and F1024 models. Global minima of fitness lengths of largest clusters are larger than in models of the L1024 series, Lf ≈ 218 ± 2 h−1 Mpc. Numbers of superclusters are about four times smaller than in models of the L1024 series; see Fig. 2. The mean geometrical lengths of the largest superclusters of the E1024 series are about two times larger than the mean geometrical lengths of the largest superclusters of the L1024 series (see Table 1). The smoothing length RB = 16 h−1 Mpc was used by Liivamägi et al. (2012) to select superclusters from the luminous red giant (LRG) sample of the SDSS survey. These LRG superclusters, found with the adaptive threshold density, are approximately two times larger than superclusters of the SDSS main galaxy sample.
Our analysis shows that smoothing scale is important in the selection of supercluster type over-density regions. Smaller smoothing selects a larger number but smaller systems, and larger smoothing picks up fewer number but larger systems.
3.6. Comparison of model and SDSS supercluster ensembles
In Fig. 3 we compare percolation functions of observed SDSS samples with percolation functions of L1024.0 and L512.0 models at the present epoch. As we see, geometrical and fitness diameter functions of SDSS samples are shifted relative to L1024.0 and L512.0 samples towards higher threshold densities. The same effect is seen in filling factor and number functions, which are presented in the lower panels of Fig. 3. This is the well-known biasing effect. All densities are expressed in mean density units. In the model samples, the mean density includes dark matter in low-density regions in addition to clustered matter. In these low-density regions, there are no galaxies or galaxies are fainter than the magnitude limit of the observational SDSS survey. Unclustered and low-density dark matter is not included in calculations of the mean density of the observed SDSS sample. This means that densities are divided to a smaller number in the calculation of densities in mean density units, which increases density values of SDSS samples (Einasto et al. 1999).
 |
Fig. 3. Comparison of percolation functions of L1024.0 and L512.0 models with SDSS samples. Model L1024.0 functions are plotted with bold lines and model L512.0 functions with bold dashed lines. Functions for SDSS samples are plotted with coloured dashed lines for biasing parameter values 1.00, 1.15, 1.30. Upper left panel: geometrical length functions, upper right panel: fitness length functions, lower left panel: total filling factor functions, and lower right panel: number functions. |
We do not know how much matter is located in low-density regions with no galaxy formation. Thus we estimate the biasing factor by an trial-and-error procedure. We calculate corrected threshold densities by dividing threshold densities of SDSS samples by the density biasing factor, b,
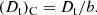
To select biasing factor values we tried a series of b values 1.0 − 1.6. Percolation functions of SDSS samples are shown in Fig. 3 using three values of the density bias: b = 1.00, 1.15, 1.30. The corrected supercluster diameter, filling factor, and number functions are in good agreement with L1024.0 and L512.0 model functions using the biasing factor b = 1.30.
3.7. Distributions of diameters and luminosities
In Fig. 4 we show cumulative distributions of geometrical and fitness diameters and luminosities of superclusters for models of the L1024 series. Data are given for all simulation epochs, using threshold densities given in Col. 10 of Table 1.
 |
Fig. 4. Left panels: cumulative distribution of supercluster geometrical diameters, Lg, fitness diameters, Lf, and total luminosities, ℒ of L1024 models at different evolution epochs, in the upper, central, and lower panels, respectively. Right panels: comparison of cumulative distributions of diameters and luminosities of L1024.0 model and SDSS samples. Upper right panel: cumulative distributions of supercluster geometrical diameters, Lg, the central right panel indicates distributions of fitness diameters, Lf, and the lower right panel shows distributions of total luminosities, ℒ. The SDSS distributions are given for threshold densities Dt = 5.0, 5.4; distributions of total luminosities are calculated for bias parameter b = 1.00 (red) and b = 1.45 (blue). |
As we see from the Fig. 4, geometrical diameters at early epochs are larger than at the present epoch (in co-moving coordinates), approximately by a factor of 2. This means that in co-moving coordinates superclusters shrink during the evolution. Fitness diameters have a different behaviour – the distribution of fitness diameters is almost the same in co-moving coordinates at all epochs. This result means that in co-moving coordinates fitness diameters remain the same during the whole evolution of the cosmic web.
Cumulative distributions of geometrical and fitness diameters of SDSS galaxies are shown in the upper right and middle right panels of Fig. 4 for threshold densities Dt = 5.0, 5.4. We see that the distribution of geometrical diameters is very sensitive to the choice of the threshold density. The higher Dt = 5.4 value is suggested on the basis of the global minimum of fitness diameters. This threshold density is also close to the threshold that yields supercluster samples similar to Liivamägi et al. (2012) supercluster samples found with the adaptive threshold density. For this threshold density the largest SDSS supercluster has geometrical diameter, Lg = 118 h−1 Mpc (see Table 1). The distribution found with Dt = 5.0 shifts the whole geometric diameter distribution towards higher Lg values. Fitness diameter distributions of model and SDSS samples are in good mutual agreement for both density threshold values.
The lower left panel of Fig. 4 shows the cumulative distributions of luminosities (actually masses) of L1024 model superclusters at various epochs. Luminosities are expressed in units of the mean mass of the model per cubic cell of size 1 h−1 Mpc. The comparison shows that masses of superclusters increase during the evolution, approximately by a factor of three. Early superclusters are less massive than at the present epoch. This result is in good agreement with simulations of the growth of the cosmic web. The skeleton of the web with superclusters already forms at early epoch. Superclusters grow by the infall of matter from low-density regions towards early forming knots and filaments, thereby forming early superclusters.
In the lower right panel of Fig. 4 we compare the cumulative distributions of luminosities of L1024 model and SDSS samples. The luminosities of SDSS superclusters were calculated in units of mean luminosity densities in cells of size 1 h−1 Mpc. In this way model and observed distributions are comparable. To take into account the biasing effect in SDSS samples, we divided luminosities of SDSS superclusters to the biasing normalising factor b = 1.00, 1.45. As seen from the lower right panel of Fig. 4, the correction b = 1.45 brings total luminosity distributions of SDSS and L1024.0 samples to a very good agreement. This value of the correction factor is not far from the value found above on the basis of percolation functions.
We note that the number of L1024 model superclusters is approximately eight times larger than the number of SDSS superclusters. This difference is expected because of the larger size of our model sample, 1024 h−1 Mpc, which is about twice the effective size of the SDSS main galaxy sample, 509 h−1 Mpc. In spite of this difference in sample volume, diameter and luminosity distributions of the model and SDSS samples are very similar when proper threshold densities and biasing corrections are applied.
4. Discussion and summary
4.1. Dependence on the dispersion of the density contrast
The evolution of the cosmic web can be well described by percolation functions, using as an argument the reduced threshold density, x = (Dt − 1)/σ, following Yess & Shandarin (1996), Sahni et al. (1997) and Colombi et al. (2000). The dispersion (rms variance) of the density contrast, σ, was calculated using Eq. (4) for all our models. For completeness we also calculated σ for models L1024 and L512 using smaller smoothing scales, RB = 1, 2 h−1 Mpc, as well as for other epochs, for which we had simulation output of density fields as follows: z = 30, 10, 5, 3, 2, 1, 0.5, 0.0. The dispersion of the density contrast is a function of the cosmic epoch z for constant smoothing scale and of the smoothing scale RB for constant epoch. Respective relations are shown in the left and right panels of Fig. 5. We see that there exists an almost linear relationship between σ and 1 + z, and between σ and RB, when expressed in log-log format. In spite of this similarity, ageing and smoothing affect the structure of the cosmic web in very different ways. As expected, the parameter σ is practically identical in models of various length L0 when identical smoothing scale RB is applied.
 |
Fig. 5. Left panel: change of the dispersion of density fluctuations σ with cosmic epoch z for our models. In this panel we designated models as follows: L1024.i, L512.i, or L256.i, where i = RB is the smoothing kernel radius in h−1 Mpc. Right panel: dependence of σ on density field smoothing length RB; here index i = z in model designation denotes the redshift z. |
Now we consider the relationship between the dispersion of the density contrast σ and the percolation threshold density, P. Data given in Table 1 show that an almost linear relationship exists between σ and percolation threshold P. Most importantly, all our models of different length L0 and smoothing scale RB lie close to an identical curve, which can be written as follows: P = 1 + 1.5 × σ. This relationship is expected since in the very early universe when σ → 0 the percolation threshold density approaches P → 1 (Einasto et al. 2018). Reduced percolation threshold densities xP = (P − 1)/σ are given in Table 1. The mean value for our five models is xP = 1.49 ± 0.13, which agrees well with results by Colombi et al. (2000).
A similar relationship also exists for density thresholds, corresponding to maxima of numbers of superclusters, Dmax = 1 + 2.9 × σ. Reduced density thresholds at maxima of numbers of superclusters, xmax = (Dmax − 1)/σ, are given in Table 1. As noted above at the earliest epoch the mean value is xmax ≈ 2.5, increasing to xmax ≈ 3.0 at the present epoch.
4.2. Fitness diameters as parameters of the cosmic web
Fitness volumes (and respective diameters) are geometrical parameters, proportional to the volume of the largest supercluster, divided by the volume of all over-density regions at the given threshold density. Fitness volumes of largest clusters are approximately inversely proportional to the number of clusters. But fitness volumes and numbers of clusters are calculated from different data, volumes of largest superclusters, and total number of clusters, respectively. Thus these parameters represent different aspects of the structure of the cosmic web.
An essential property of the fitness diameter functions is the presence of global minima at certain threshold densities. The fitness diameter function has a number of local minima, showing the presence of breaks, where largest superclusters split to smaller units. A detailed discussion of this phenomenon is provided in Liivamägi et al. (2012). Breaks of fitness length functions (and breaks of geometrical length functions) are different in models of different sizes, smoothing scales, and epochs, and have a rather large scatter. To select the proper value of the threshold density to find superclusters we used local minima of the fitness length function, which correspond to geometrical lengths of largest superclusters, close to lengths, usually accepted for largest SDSS superclusters (Einasto et al. 2007; Costa-Duarte et al. 2011; Luparello et al. 2011; Liivamägi et al. 2012). For the mean value of the reduced density threshold to select superclusters we get xt = 3.44 ± 0.76.
Fitness diameters of superclusters near minima are approximately identical in samples of different sizes. The largest superclusters in samples of smaller sizes are only slightly smaller than the largest superclusters in samples of larger sizes. Cluster numbers are approximately proportional to the volume of the sample, thus cluster numbers, reduced to identical sample volume are very close; see the right panel of Fig. 2. The dependence of fitness diameters on the sample size up to L0 = 1024 h−1 Mpc suggests that samples smaller than this scale do not represent fair samples of the Universe for the formation of representative samples of rich superclusters. On the other hand, scales larger than ∼1000 h−1 Mpc have little effect on the structure of the cosmic web, as suggested by Klypin & Prada (2018). Thus we can take our models of the L1024 series as estimates of fair samples of the Universe. This scale is larger than expected from previous analyses (Einasto & Gramann 1993).
Fitness diameters of largest superclusters depend on the smoothing scale used to select superclusters. This property is expected since smoothing highlights properties of the cosmic web on different scales. When we use very small smoothing of the order of 1 h−1 Mpc, then characteristic elements of the web are giant galaxies surrounded by dwarf satellites, similar to M 31 and Milky Way, as well as small groups and clusters of galaxies. Smoothing with scale 4 h−1 Mpc highlights systems of intermediate scale between clusters and traditional superclusters. Smoothing with 8 h−1 Mpc scale selects ordinary superclusters. Smoothing with 16 h−1 Mpc scale corresponds to rich superclusters, selected on the basis of bright LRG galaxies, as done by Liivamägi et al. (2012).
4.3. Evolution of the ensemble of superclusters
An important aspect of percolation functions is their shape. Fig. 1 shows that the shape of percolation functions is almost identical for all models and epochs for x ≤ 1.5. The shape of fitness length and number functions is approximately symmetrical around the value x = xmax ≈ 2.5 at early epoch z = 10. This means that at these scales the growth of density perturbations is nearly linear. At later epochs the maximum of number functions is shifted to x = xmax ≈ 3.0. As the web evolves, fitness length and number functions are gradually shifted towards higher x-values and the symmetry is gradually lost. In the model F1024, which has a smaller smoothing scale, the asymmetry growth is the largest.
Supercluster luminosity functions (distributions of luminosities of superclusters) of L1024.0 model and SDSS samples are very similar when a biasing correction is taken into account. Model and SDSS luminosity functions are rather close to luminosity functions found by Einasto et al. (2006) for early SDSS and 2dF superclusters. It is unclear why model superclusters found by Einasto et al. (2006) on the basis of millennium simulations (Croton et al. 2006), had a different luminosity function. In this paper we used identical procedures to select superclusters based on density fields smoothed with 8 h−1 Mpc kernel; thus present results should be more reliable.
Arguments based on geometrical and fitness diameter functions suggest that very large over-density regions, such as the Sloan Great Wall and the BOSS Great Wall, are actually complexes of superclusters, as studied by Liivamägi et al. (2012), and Einasto et al. (2016, 2017). Similarly the Laniakea Supercluster, introduced by Tully et al. (2014), is a complex of several previously known superclusters: the Local Supercluster, the Great Attractor, and some smaller cluster filaments and clouds. The Laniakea Supercluster is surrounded by rich Coma, Perseus-Pisces, Hercules, and Shapley Superclusters.
4.4. Cocoons of the cosmic web
To understand better the evolution of the cosmic web on supercluster scale, we show in Fig. 6 the visual appearance of density fields of models L1024 at different epochs: in the left panel at the early epoch z = 10, in the middle panel at epoch z = 3, and in the right panel at the present epoch z = 0, all smoothed with 8 h−1 Mpc co-moving scale. The evolution of density fields can be followed by comparison of panels. This comparison suggests that supercluster-type structural elements of the cosmic web are present already at very early epochs. Of course, there are differences on small scales, but the main supercluster-type elements of the web are seen at similar locations at all epochs. Basic visible changes are the increase of the density contrast: distributions of densities at epochs z = 10 and z = 3 are very similar, only the amplitude of density perturbations has increased. This means that in this time interval the evolution is near to a linear growth. On later epochs the non-linearity of the evolution is dominant. The flow of small-scale structural elements towards large-scale ones is more visible.
 |
Fig. 6. Density fields of the L1024.10, L1024.3, and L1024.0 models found with smoothing kernel of radius 8 h−1 Mpc. Left panel: epoch z = 10, middle panel: epoch z = 3, and right panel: present epoch z = 0. Cross sections are shown in a 2 h−1 Mpc thick layer, densities are expressed in linear scale. Colour scales from left to right are 0.8 − 1.2, 0.4 − 1.5, 0.2 − 2.5. |
Elements of the cosmic web evolve with time. Physical clusters of galaxies grow by merging of smaller clusters and by infall of non-clustered matter, filaments merge, and voids became emptier. Superclusters also change; their sizes shrink in co-moving coordinates and masses grow by infall and merging. Similar general visual appearance of the density fields at very early and present epochs suggests that supercluster embryos were created very early. This result is not surprising; Kofman & Shandarin (1988) already demonstrated that the whole present-day structure is seen in the initial fluctuation distribution.
Tully et al. (2014) defined superclusters as “basins of attraction”: supercluster is the volume containing all galaxies and particles whose flow lines converge at a given attractor, the local minimum of the gravitational potential.
We prefer to define superclusters as high-density regions of the cosmic web. The Tully et al. “basins of attraction” are, in our terminology, supercluster cells of dynamical influence; we refer to these as cocoons. Cells of dynamical influence are regions around superclusters, from which superclusters collect their matter. They are separated from each other by surfaces, where on the one side the smoothed velocity flow is directed to one supercluster, and on the other side to an another supercluster. In this way the whole volume of the universe is divided into supercluster cells of dynamical influence. Cells of dynamical influence are different from cells introduced by Jõeveer & Einasto (1977, 1978; see also Aragón-Calvo et al. 2010b), which are cellular low-density regions surrounded by a network of high-density structures, i.e. clusters, filaments, and walls.
Our analysis gives support to the presence of supercluster cells of dynamical influence. The main arguments are the following: (i) the almost constant number of superclusters and approximately constant fitness diameters in co-moving coordinates at different cosmical epochs; (ii) the growth of the mass of superclusters and decrease of supercluster geometric diameters (in co-moving coordinates) with time; and (iii) the visual appearance of density fields of models at various evolutionary epochs, smoothed with co-moving scale 8 h−1 Mpc.
Supercluster cocoons are seen in all our models using different box sizes and their presence is an important property of the cosmic web. This suggests that the essential evolution of superclusters occurs inside supercluster cocoons. Supercluster cocoons have volumes about hundred times larger than geometrical volumes of superclusters. Fitness diameters of largest superclusters depend slightly on the size of the model and on the smoothing length used in the calculation of the density field. Smoothing highlights properties of the cosmic web at various scales. Thus the size of supercluster cocoons is not a physical scale as the baryonic acoustic oscillation (BAO) scale. The BAO phenomenon is caused by baryonic oscillations of hot gas before the cosmic recombination. Seeds of the cosmic web are scale-free primordial fluctuations. The cosmic web has a fractal nature and superclusters are elements of the cosmic web which can be highlighted by smoothing.
4.5. Summary remarks
We investigated evolutionary changes of geometrical properties of the conventional ΛCDM model applying an extended percolation analysis, which characterises general geometrical properties of the ensemble of superclusters. We calculated density fields of the ΛCDM model using three sample box sizes L0 = 1024, 512, 256 h−1 Mpc, and we analysed four evolutionary epochs of the Universe, z = 0, 1, 3, 10. Our analysis uses density fields smoothed with an RB = 8 h−1 Mpc kernel; for comparison we also smooth with 4 and 16 h−1 Mpc kernels. We scan density fields in a wide interval and find connected over-density regions (clusters). Lengths, total filling factors, and numbers of largest clusters as functions of the threshold density are used as percolation functions. In the analysis we use threshold densities in units of the mean density of the sample, Dt, and reduced threshold densities, x = (Dt − 1)/σ, where σ is the dispersion of the density contrast, D − 1. In addition to geometrical diameters we use fitness diameters, calculated on the basis of cluster volumes, and total filling factors.
Our basic methodical contribution to the percolation analysis is the addition of fitness volumes and diameters of clusters (superclusters) to the list of geometrical properties. We find that the fitness diameter of superclusters is a stable parameter, which is useful to characterise sizes of superclusters and to study geometrical properties of the cosmic web. Fitness diameters of superclusters as functions of the threshold density have a global minimum. Near the minimum of fitness diameters numbers of superclusters have a maximum. At this density threshold the cosmic web can be divided into supercluster cells.
The basic conclusions of our study are as follows:
-
Minimal fitness diameters of largest superclusters almost do not change during the evolution of the cosmic web (in co-moving coordinates).
-
Numbers of superclusters as a function of the threshold density have maxima which are approximately constant for all evolutionary epochs.
-
The maximum of supercluster numbers and minimum of fitness diameters occurs in all models at reduced threshold density, xmax ≈ 2.5 at early evolutionary epoch, increasing to xmax ≈ 3.0 at the present epoch.
-
The shape of percolation functions is very similar in models of various ages and smoothing scales. At early epoch percolation functions around xmax are approximately symmetrical, showing nearly linear growth of density perturbations. At later epochs the positive wing of fitness length and number functions increases, showing the growing non-linearity of density perturbations.
-
Geometrical diameters of superclusters decrease during the evolution (in co-moving coordinates); luminosities of superclusters increase during the evolution.
-
Essential evolutionary changes occur inside supercluster cells of dynamical influence or cocoons. Volumes of supercluster cells are about hundred times larger than their geometrical volumes.
In the present study we use data on spatial coordinates, which allows us to test the concept of supercluster cells as representatives of true dynamical volumes. Our study confirms that the concept of supercluster cells (basins of attraction) has cosmological significance. The determination of true dynamical volumes using velocity data and the gravitation potential field would be an interesting task.
Our study also shows that percolation functions of model samples deviate in a very clear way from respective observed functions derived using SDSS galaxy samples. Differences can be understood in terms of the biased galaxy formation, where in low-density regions galaxies do not form or are too faint to fall into the magnitude range covered by SDSS observations. A more detailed investigation of the biasing phenomenon using density fields of models and galaxies would be an interesting task, but is outside the scope of the present study.
Acknowledgments
Authors thank the anonymous referee for stimulating suggestions. This work was supported by institutional research funding IUT26-2 and IUT40-2 of the Estonian Ministry of Education and Research. We acknowledge the support by the Centre of Excellence“Dark side of the Universe” (TK133) financed by the European Union through the European Regional Development Fund. The study has also been supported by ICRAnet through a professorship for Jaan Einasto, and by the University of Valencia (Vicerrectorado de Investigación) through a visiting professorship for Enn Saar and by the Spanish MEC projects “ALHAMBRA” (AYA2006-14056) and “PAU” (CSD2007-00060), including FEDER contributions. We thank the SDSS Team for the publicly available data releases. Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, the U.S. Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web Site is http://www.sdss.org/. The SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, University of Cambridge, Case Western Reserve University, University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington.
References
- Aarseth, S. J., Turner, E. L., & Gott, III, J. R. 1979, ApJ, 228, 664 [NASA ADS] [CrossRef] [Google Scholar]
- Abell, G. O. 1958, ApJS, 3, 211 [NASA ADS] [CrossRef] [Google Scholar]
- Abell, G. O., Corwin, Jr., H. G., & Olowin, R. P. 1989, ApJS, 70, 1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aihara, H., Allende Prieto, C., An, D., et al. 2011, ApJS, 193, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Aragón-Calvo, M. A., van de Weygaert, R., & Jones, B. J. T. 2010a, MNRAS, 408, 2163 [NASA ADS] [CrossRef] [Google Scholar]
- Aragón-Calvo, M. A., van de Weygaert, R., Araya-Melo, P. A., Platen, E., & Szalay, A. S. 2010b, MNRAS, 404, L89 [NASA ADS] [CrossRef] [Google Scholar]
- Bertschinger, E. 1995, ArXiv e-prints [arXiv:astro-ph/9506070] [Google Scholar]
- Bond, J. R., Kofman, L., & Pogosyan, D. 1996, Nature, 380, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Cautun, M., van de Weygaert, R., Jones, B. J. T., & Frenk, C. S. 2014, MNRAS, 441, 2923 [NASA ADS] [CrossRef] [Google Scholar]
- Chon, G., Böhringer, H., & Zaroubi, S. 2015, A&A, 575, L14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Colombi, S., Pogosyan, D., & Souradeep, T. 2000, Phys. Rev. Lett., 85, 5515 [NASA ADS] [CrossRef] [Google Scholar]
- Costa-Duarte, M. V., Sodré, Jr., L., & Durret, F. 2011, MNRAS, 411, 1716 [NASA ADS] [CrossRef] [Google Scholar]
- Croton, D. J., Springel, V., White, S. D. M., et al. 2006, MNRAS, 365, 11 [NASA ADS] [CrossRef] [Google Scholar]
- de Vaucouleurs, G. 1953, AJ, 58, 30 [NASA ADS] [CrossRef] [Google Scholar]
- de Vaucouleurs, G. 1958, Nature, 182, 1478 [NASA ADS] [CrossRef] [Google Scholar]
- Doroshkevich, A. G., Shandarin, S. F., & Zeldovich, I. B. 1982, Comments Astrophys., 9, 265 [NASA ADS] [Google Scholar]
- Einasto, J., & Gramann, M. 1993, ApJ, 407, 443 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, J., Jõeveer, M., & Saar, E. 1980, MNRAS, 193, 353 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Dalton, G. B., & Andernach, H. 1994, MNRAS, 269, 301 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, M., Tago, E., Jaaniste, J., Einasto, J., & Andernach, H. 1997, A&AS, 123, 119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Tago, E., et al. 1999, ApJ, 519, 456 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Müller, V., & Andernach, H. 2001, AJ, 122, 2222 [CrossRef] [Google Scholar]
- Einasto, J., Einasto, M., Hütsi, G., et al. 2003, A&A, 410, 425 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Saar, E., et al. 2006, A&A, 459, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Einasto, M., Tago, E., et al. 2007, A&A, 462, 811 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Lietzen, H., Gramann, M., et al. 2016, A&A, 595, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Lietzen, H., Gramann, M., et al. 2017, A&A, 603, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Suhhonenko, I., Liivamägi, L. J., & Einasto, M. 2018, A&A, 616, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gramann, M., Einasto, M., Heinämäki, P., et al. 2015, A&A, 581, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jasche, J., Kitaura, F. S., Li, C., & Enßlin, T. A. 2010, MNRAS, 409, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Jõeveer, M., & Einasto, J. 1977, Est. Acad. Sci. Prepr., 3 [Google Scholar]
- Jõeveer, M., & Einasto, J. 1978, in Large Scale Structures in the Universe, eds. M. S. Longair, & J. Einasto, IAU Symp., 79, 241 [NASA ADS] [Google Scholar]
- Klypin, A., & Prada, F. 2018, ArXiv e-prints [arXiv:1809.03637] [Google Scholar]
- Klypin, A., & Shandarin, S. F. 1993, ApJ, 413, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Kofman, L. A., & Shandarin, S. F. 1988, Nature, 334, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Liivamägi, L. J., Tempel, E., & Saar, E. 2012, A&A, 539, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luparello, H., Lares, M., Lambas, D. G., & Padilla, N. 2011, MNRAS, 415, 964 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez, V. J., & Saar, E. 2002, in Statistics of the Galaxy Distribution, eds. V. J. Martínez, & E. Saar (Chapman & Hall/CRC) [Google Scholar]
- Sahni, V., Sathyaprakash, B. S., & Shandarin, S. F. 1997, ApJ, 476, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Shandarin, S. F., & Yess, C. 1998, ApJ, 505, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [NASA ADS] [CrossRef] [Google Scholar]
- Stauffer, D. 1979, Phys. Rep., 54, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Tago, E., Saar, E., Tempel, E., et al. 2010, A&A, 514, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tegmark, M., Strauss, M. A., Blanton, M. R., et al. 2004, Phys. Rev. D, 69, 103501 [CrossRef] [Google Scholar]
- Tempel, E., Einasto, J., Einasto, M., Saar, E., & Tago, E. 2009, A&A, 495, 37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Tago, E., & Liivamägi, L. J. 2012, A&A, 540, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tully, R. B., Courtois, H., Hoffman, Y., & Pomarède, D. 2014, Nature, 513, 71 [NASA ADS] [CrossRef] [Google Scholar]
- van de Weygaert, R., Shandarin, S., Saar, E., & Einasto, J. 2016, in The Zeldovich Universe: Genesis and Growth of the Cosmic Web, IAU Symp., 308 [Google Scholar]
- White, S. D. M., Frenk, C. S., & Davis, M. 1983, ApJ, 274, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Yess, C., & Shandarin, S. F. 1996, ApJ, 465, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Zeldovich, Y. B., Einasto, J., & Shandarin, S. F. 1982, Nature, 300, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Zwicky, F., Herzog, E., & Wild, P. 1968, Catalogue of Galaxies and of Clusters of Galaxies (Pasadena: California Institute of Technology (CIT), 1961–1968) [Google Scholar]
All Tables
All Figures
|
Fig. 1. Left panels: geometrical length functions. Middle panels: fitness length functions. Right panels: number functions. As arguments of percolation functions we use the reduced threshold density, x = (Dt − 1)/σ. Panels from top down are for models L1024, L512, L256, F1024, and E1024. |
| In the text | |
|
Fig. 2. Left panel: evolution of minimal fitness lengths with epoch, Lf(z). Right panel: evolution of the spatial density of maximal numbers of clusters with epoch, N(z), per cubic cell of size L0 = 1 h−1 Gpc. Model designations as in Table 1. |
| In the text | |
|
Fig. 3. Comparison of percolation functions of L1024.0 and L512.0 models with SDSS samples. Model L1024.0 functions are plotted with bold lines and model L512.0 functions with bold dashed lines. Functions for SDSS samples are plotted with coloured dashed lines for biasing parameter values 1.00, 1.15, 1.30. Upper left panel: geometrical length functions, upper right panel: fitness length functions, lower left panel: total filling factor functions, and lower right panel: number functions. |
| In the text | |
|
Fig. 4. Left panels: cumulative distribution of supercluster geometrical diameters, Lg, fitness diameters, Lf, and total luminosities, ℒ of L1024 models at different evolution epochs, in the upper, central, and lower panels, respectively. Right panels: comparison of cumulative distributions of diameters and luminosities of L1024.0 model and SDSS samples. Upper right panel: cumulative distributions of supercluster geometrical diameters, Lg, the central right panel indicates distributions of fitness diameters, Lf, and the lower right panel shows distributions of total luminosities, ℒ. The SDSS distributions are given for threshold densities Dt = 5.0, 5.4; distributions of total luminosities are calculated for bias parameter b = 1.00 (red) and b = 1.45 (blue). |
| In the text | |
|
Fig. 5. Left panel: change of the dispersion of density fluctuations σ with cosmic epoch z for our models. In this panel we designated models as follows: L1024.i, L512.i, or L256.i, where i = RB is the smoothing kernel radius in h−1 Mpc. Right panel: dependence of σ on density field smoothing length RB; here index i = z in model designation denotes the redshift z. |
| In the text | |
|
Fig. 6. Density fields of the L1024.10, L1024.3, and L1024.0 models found with smoothing kernel of radius 8 h−1 Mpc. Left panel: epoch z = 10, middle panel: epoch z = 3, and right panel: present epoch z = 0. Cross sections are shown in a 2 h−1 Mpc thick layer, densities are expressed in linear scale. Colour scales from left to right are 0.8 − 1.2, 0.4 − 1.5, 0.2 − 2.5. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.