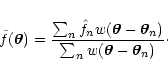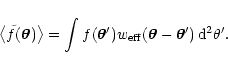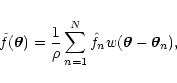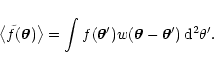A common problem in astronomy is the smoothing of some irregularly sampled data into a continuous map. It is hard to list all possible cases where such a problem is encountered. To give a few examples, we mention the determination of the stellar distribution of our Galaxy, the mapping of column density of dark molecular clouds from the absorption of background stars, the determination of the distribution function in globular clusters from radial and, recently, proper motions of stars, the determination of cosmological large-scale structures from redshift surveys, and the mass reconstruction in galaxy clusters from the observed distortion of background galaxies using weak lensing techniques. Similarly, one-dimensional data, such as time series of some events, often need to be smoothed in order to obtain a real function.
The use of a smooth map is convenient for at least two reasons. First, a smooth map can be better analyzed than irregularly sampled data. Second, if the smoothing is done in a sufficiently coarse way, the smooth map is significantly less noisy than the individual data. The drawback to this last point is a loss in resolution, but often this is a price that we have to pay in order to obtain results with a decent signal-to-noise ratio.
In many cases the transformation of irregularly sampled data into a
smooth map follows a standard approach. A positive weight function,
describing the relative weight of a datum at the position
![]() on the point
on the point
![]() ,
is introduced. This function
is generally of the form
,
is introduced. This function
is generally of the form
![]() ,
i.e. is independent of the
absolute position
,
i.e. is independent of the
absolute position
![]() of the point, and actually often
depends only on the separation
of the point, and actually often
depends only on the separation
![]() .
The weight function
.
The weight function
![]() is also chosen so that its value is large when the datum
is close to the point, i.e. when
is also chosen so that its value is large when the datum
is close to the point, i.e. when
![]() is small, and
vanishes when
is small, and
vanishes when
![]() is large. Then, the data are averaged
using a weighted mean with the weights given by the function w.
More precisely, calling
is large. Then, the data are averaged
using a weighted mean with the weights given by the function w.
More precisely, calling ![]() the nth datum obtained at the
position
the nth datum obtained at the
position
![]() ,
the smooth map is defined as
,
the smooth map is defined as
In this paper we consider in detail the effect of the smoothing on
irregularly sampled data and derive a number of exact
properties for the resulting map. We assume that the measurements
![]() are unbiased estimates of some unknown field
are unbiased estimates of some unknown field
![]() at the positions
at the positions
![]() ,
and we study the
expectation value of the map
,
and we study the
expectation value of the map
![]() using an
ensemble average, i.e. taking the N positions
using an
ensemble average, i.e. taking the N positions
![]() as random variables. We then show that the
expectation value for the smooth map of Eq. (1) is given by
as random variables. We then show that the
expectation value for the smooth map of Eq. (1) is given by
A common alternative to Eq. (1) is a non-normalized weighted
sum, defined as
The paper is organized as follows. In Sect. 2 we
derive some preliminary expressions for the mean value of the map of
Eq. (1). These results are generalized to a variable number
N of objects in Sect. 3. If the weight
function
![]() is allowed to vanish, then some peculiarities
arises. This case is considered in detail in
Sect. 4. Section 5 is
dedicated to general properties for the average of
is allowed to vanish, then some peculiarities
arises. This case is considered in detail in
Sect. 4. Section 5 is
dedicated to general properties for the average of ![]() and
related functions. In Sect. 6 we take an
alternative approach which can be used to obtain an analytic expansion
for
and
related functions. In Sect. 6 we take an
alternative approach which can be used to obtain an analytic expansion
for ![]() .
In Sect. 7, we consider three
specific examples of weight functions often used in practice.
Finally, a summary of the results obtained in this paper is given in
Sect. 8. A variation of the smoothing technique
considered in this paper is briefly discussed in
Appendix A.
.
In Sect. 7, we consider three
specific examples of weight functions often used in practice.
Finally, a summary of the results obtained in this paper is given in
Sect. 8. A variation of the smoothing technique
considered in this paper is briefly discussed in
Appendix A.
Copyright ESO 2001