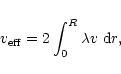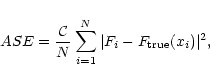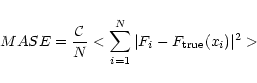We will calculate the values of the relaxation time as a function of three free parameters, namely the number of field particles, the initial velocity of the test particles and the softening. In this section we will discuss what the relevant ranges for these parameters are.
The question for the initial velocity is more convoluted. The simple
analytical approaches leading to Eqs. (6) and (7),
instead of taking a spectrum of velocities for the individual
encounters and then integrating over these velocities, introduce an
effective or average velocity and assume that all interactions are
made at this velocity. In our numerical calculations individual
encounters occur at different velocities, depending on their position
on the trajectory of the test particle and on the initial velocity of
this particle. We can, nevertheless, introduce
![]() ,
an
average or effective velocity, in a similar way as the analytical
approximation. A simple and straightforward, albeit not
unique, such definition can be obtained as follows:
let us assume that the test particle moves on a straight line. At each
point of its trajectory we can define a thin sheet going through this
point and locally perpendicular to the trajectory. It will contain all
field particles which have this point as their closest approach with
the test particle.
Let dr be the thickness of
this sheet and
,
an
average or effective velocity, in a similar way as the analytical
approximation. A simple and straightforward, albeit not
unique, such definition can be obtained as follows:
let us assume that the test particle moves on a straight line. At each
point of its trajectory we can define a thin sheet going through this
point and locally perpendicular to the trajectory. It will contain all
field particles which have this point as their closest approach with
the test particle.
Let dr be the thickness of
this sheet and
![]() the fraction of the total mass of the field
particles that is in it. Then we can define the effective velocity
the fraction of the total mass of the field
particles that is in it. Then we can define the effective velocity
The third free parameter in our calculations is the softening. Merritt
(1996; hereafter M96) and Athanassoula et al. (2000; hereafter
AFLB)
showed that, for a given mass distribution and a given number
of particles N, there is a value of the softening, called optimal
softening
![]() ,
which gives the most accurate
representation of the gravitational forces within the N-body
representation of the mass distribution. For values of the softening
smaller than
,
which gives the most accurate
representation of the gravitational forces within the N-body
representation of the mass distribution. For values of the softening
smaller than
![]() the error in
the force calculation is mainly due to noise, because of the
graininess of the configuration. For values of the softening larger than
the error in
the force calculation is mainly due to noise, because of the
graininess of the configuration. For values of the softening larger than
![]() the error is mainly due to the biasing, since the
force is heavily softened and therefore far from Newtonian.
Since the two-body
relaxation is also a result of graininess it makes sense to consider
softening values for which it is the noise and not the bias that
dominates, i.e. to concentrate our calculations mainly on values
of the softening which are smaller than or of the
order of
the error is mainly due to the biasing, since the
force is heavily softened and therefore far from Newtonian.
Since the two-body
relaxation is also a result of graininess it makes sense to consider
softening values for which it is the noise and not the bias that
dominates, i.e. to concentrate our calculations mainly on values
of the softening which are smaller than or of the
order of
![]() ,
keeping in mind that too small values of
the softening have no practical significance. The value of the optimal
softening
decreases with N and can be well approximated by a power law
,
keeping in mind that too small values of
the softening have no practical significance. The value of the optimal
softening
decreases with N and can be well approximated by a power law
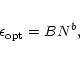
M96 and AFLB have calculated
![]() using the
mean average square error (MASE) of the force, which
measures how well the forces in an N-body representation of a given
mass distribution represent the true forces in this distribution. The average
square error (ASE) is defined as
using the
mean average square error (MASE) of the force, which
measures how well the forces in an N-body representation of a given
mass distribution represent the true forces in this distribution. The average
square error (ASE) is defined as
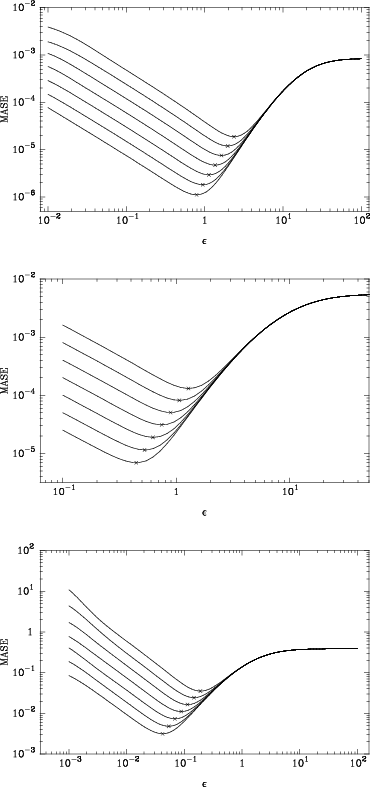
Figure 2 shows values of MASE as a function of ![]() for
the three models considered in Sects. 5.1 to 5.4 and seven values of N, in
the range of values considered here
(cf. Sect. 4.1). The general form of the curves is
as expected. There is in all cases a minimum error between the
region dominated by the noise (small values of the softening) and the
region dominated by the bias (large values of the softening). This
minimum - marked with a
for
the three models considered in Sects. 5.1 to 5.4 and seven values of N, in
the range of values considered here
(cf. Sect. 4.1). The general form of the curves is
as expected. There is in all cases a minimum error between the
region dominated by the noise (small values of the softening) and the
region dominated by the bias (large values of the softening). This
minimum - marked with a ![]() in Fig. 2 - gives the
value of
in Fig. 2 - gives the
value of
![]() .
For all three models a larger number of
particles corresponds to a smaller error and a smaller value of
.
For all three models a larger number of
particles corresponds to a smaller error and a smaller value of
![]() ,
as expected (M96, AFLB).
,
as expected (M96, AFLB).
The more concentrated configurations give smaller values of
![]() ,
as already discussed in AFLB. Thus for
,
as already discussed in AFLB. Thus for
![]() the optimum softening for model H is less than twice that of model P,
while the ratio between the softenings of models P and D is more than 10.
the optimum softening for model H is less than twice that of model P,
while the ratio between the softenings of models P and D is more than 10.
Comparing our results to those of AFLB we can get insight on the
effect of the truncation radius. For this it is best to compare our
results obtained with
![]() with those given by AFLB for
with those given by AFLB for
![]() ,
since these two N values are very close and we do not have
to make corrections for particle number. For our model P
and
,
since these two N values are very close and we do not have
to make corrections for particle number. For our model P
and
![]() we find an optimum softening of 0.52, or,
equivalently, 0.057
we find an optimum softening of 0.52, or,
equivalently, 0.057![]() ,
where
,
where ![]() is the scale
length of the Plummer sphere. This is smaller than the value
of 0.063
is the scale
length of the Plummer sphere. This is smaller than the value
of 0.063![]() found for the AFLB Plummer model and the
difference is due to the
different truncation radii of the two models. AFLB truncated their
Plummer sphere at a radius of 38.71
found for the AFLB Plummer model and the
difference is due to the
different truncation radii of the two models. AFLB truncated their
Plummer sphere at a radius of 38.71![]() ,
which encloses
0.999 of the total mass of the untruncated sphere, while model P is
truncated at 2.2
,
which encloses
0.999 of the total mass of the untruncated sphere, while model P is
truncated at 2.2![]() ,
which contains only 75% of total mass. The difference in the values
of
,
which contains only 75% of total mass. The difference in the values
of
![]() is in good agreement with the discussion in
Sect. 5.2 of AFLB. When the truncation radius is large, the model
includes a relatively high fraction of low density regions, where the
inter-particle distances are large. This is not the case if the
truncation radius is much smaller, as it is here. Thus the mean
inter-particle distance is larger in the former case and, as can
be seen from Fig. 11 of AFLB, the corresponding optimal softening
also. This predicts that the optimal softening should be smaller in
models with smaller truncation radius, and it is indeed what we
find here.
is in good agreement with the discussion in
Sect. 5.2 of AFLB. When the truncation radius is large, the model
includes a relatively high fraction of low density regions, where the
inter-particle distances are large. This is not the case if the
truncation radius is much smaller, as it is here. Thus the mean
inter-particle distance is larger in the former case and, as can
be seen from Fig. 11 of AFLB, the corresponding optimal softening
also. This predicts that the optimal softening should be smaller in
models with smaller truncation radius, and it is indeed what we
find here.
Our model H is the same as that of AFLB, except for the difference in
the cut-off radii. Thus the values of the optimum softening are the
same, after the appropriate rescaling with the cut-off radii has been
applied. Our model D differs in two ways from the corresponding model of
AFLB. We use here
![]() ,
while AFLB used
,
while AFLB used ![]() = 0. We also truncated our model at 6.5
= 0. We also truncated our model at 6.5![]() ,
while
AFLB truncated theirs at 2998
,
while
AFLB truncated theirs at 2998![]() .
It is thus not possible to make any qualitative or quantitative comparisons.
.
It is thus not possible to make any qualitative or quantitative comparisons.
Copyright ESO 2001