We used the segment Cox point process (see Stoyan et al. 1995)
to model the
correlation properties of our observational samples. This process is
constructed as follows: segments of
length l are randomly generated inside a cube of size L (a Poisson
distribution of starting points and a uniform distribution
of directions in space) and Poisson-distributed points
are generated along these segments.
The second parameter we have to choose after l is the
intensity (mean density) of segments
![]() .
Then the length density
of all segments
.
Then the length density
of all segments ![]() is defined as
is defined as
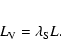
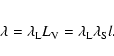
Although this distribution of points might seem
rather artificial, the good news is that the pair correlation
function ![]() for this process is known exactly
(Stoyan et al. 1995):
for this process is known exactly
(Stoyan et al. 1995):
If we want to simulate a cosmological sample, we are usually
given the sample size L, the correlation length
r0 and the number of objects in the sample. How do we
choose the parameters
![]() and
and
![]() that
describe a segment Cox process?
that
describe a segment Cox process?
First, we have to choose the segment length l.
It certainly has to be larger than r0 and can be
chosen by the location of the first zero of the observed
correlation function.
Also, as seen in Fig. B.1, the smaller
the ratio r0/l, the better is the approximation
![]() .
This, however, frequently gives too large
a value for d. A large d means that the intensity of segments will be small
and their total number
.
This, however, frequently gives too large
a value for d. A large d means that the intensity of segments will be small
and their total number
![]() will be small, too;
we get a rather unrealistic distribution of points along a few
long segments.
will be small, too;
we get a rather unrealistic distribution of points along a few
long segments.
On the other hand, if we do not worry too much about
the exact slope of the correlation function, we could
choose l rather close to r0 (the upper curve in Fig. B.1).
We have found that taking
![]() works well in practice.
works well in practice.
Let us say that we have decided to choose
![]() .
Then, formula (B.1) for the correlation
function tells us that
.
Then, formula (B.1) for the correlation
function tells us that
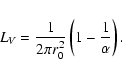
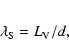
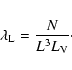
An important point to remember when generating a segment Cox process
is that having a mean number of segments
![]() does not mean that we have to generate
does not mean that we have to generate ![]() segments. The
number of segments is a Poisson-distributed random number
with intensity (mean)
segments. The
number of segments is a Poisson-distributed random number
with intensity (mean) ![]() ,
and it is useful to recall
that its variance is also
,
and it is useful to recall
that its variance is also ![]() .
So every realization
will give us a different number of segments. The same
concerns the number of points on the segments. All this
combines to give us a different total number of points
with every realization.
.
So every realization
will give us a different number of segments. The same
concerns the number of points on the segments. All this
combines to give us a different total number of points
with every realization.
Copyright ESO 2002
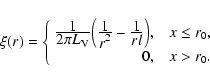
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{h1676f36.eps}\end{figure}](/articles/aa/full/2002/37/aah1676/img179.gif)