The CG sample we present here is specifically designed to allow
comparison between compact Triplets and higher order CGs.
Therefore, we have chosen to set
![]() kpc and
kpc and
![]() km s
km s![]() .
The prescription for
.
The prescription for ![]() r accounts for possible huge dark
haloes tied to bright galaxies (Zaritsky et al. 1997; Bahcall et al. 1995).
The value for
r accounts for possible huge dark
haloes tied to bright galaxies (Zaritsky et al. 1997; Bahcall et al. 1995).
The value for
![]() is large enough to allow a
fair sampling of the CG velocity dispersion, which can be related to other
observational parameters such as morphological content and
surrounding galaxy density (Somerville et al. 1996; Marzke et al. 1995).
Actually, more than 95% of the CGs display
is large enough to allow a
fair sampling of the CG velocity dispersion, which can be related to other
observational parameters such as morphological content and
surrounding galaxy density (Somerville et al. 1996; Marzke et al. 1995).
Actually, more than 95% of the CGs display
![]() values
below 500 km s
values
below 500 km s![]() .
.
Concerning the large scale, we have set
![]() Mpc and
Mpc and
![]() km s-1 in order
to map the environment on scales typical of loose groups/poor clusters.
Moreover, adopting the same value for
km s-1 in order
to map the environment on scales typical of loose groups/poor clusters.
Moreover, adopting the same value for
![]() and
and
![]() ensures that each CG is sampled
to the same depth of its large scale environment.
Only CGs in a redshift range 1000 km s
ensures that each CG is sampled
to the same depth of its large scale environment.
Only CGs in a redshift range 1000 km s![]() to 10 000 km s
to 10 000 km s![]() enter the sample.
The low redshift threshold allows us to reduce uncertainties due to
peculiar motions, the upper one to reduce the incidence of CGs with
only extremely bright galaxies.
enter the sample.
The low redshift threshold allows us to reduce uncertainties due to
peculiar motions, the upper one to reduce the incidence of CGs with
only extremely bright galaxies.
The search algorithm, applied to the UZC sample with the prescriptions just
defined, yields a sample of 291 CGs:
222 Triplets (Ts) and 69 Multiplets (Ms) with more than 3 member galaxies.
The algorithm additionally detected (and rejected)
56 ACO subclumps and 144 non-symmetric CGs, among which Ms are at
least 50%.
The CG sample is shown in Table 1 which lists RA and Dec of the center
(Cols. 2 and 3), number of members n (multiplicity)
(Col. 4), average projected dimension
![]() (Col. 5),
mean radial velocity cz (Col. 6),
unbiased radial velocity dispersion
(Col. 5),
mean radial velocity cz (Col. 6),
unbiased radial velocity dispersion
![]() (Col. 7)
and, for CGs with
(Col. 7)
and, for CGs with
![]() km s-1 (see Sect. 7),
the number of large scale neighbours
km s-1 (see Sect. 7),
the number of large scale neighbours
![]() within
within
![]() Mpc (Col. 8).
Cross identification with HCGs and RSCGs is reported in Col. 9.
Table 2 lists member galaxies for each CG, their position, magnitude,
radial velocity and spectral classification as reported in UZC.
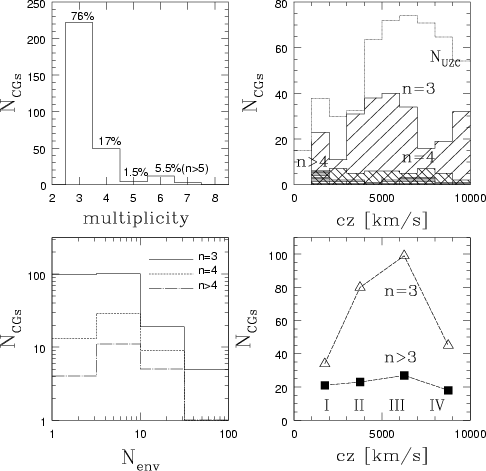
The CG sample characteristics are shown in Fig. 1.
Mpc (Col. 8).
Cross identification with HCGs and RSCGs is reported in Col. 9.
Table 2 lists member galaxies for each CG, their position, magnitude,
radial velocity and spectral classification as reported in UZC.
The CG sample characteristics are shown in Fig. 1.
The CG distribution
as a function of multiplicity (upper left panel) shows that Ts
represent the majority of the sample.
The upper right panel shows how the redshift
distribution of CGs of different multiplicity compares to redshift
distribution of UZC galaxies.
The lower left panel shows the relation between CG multiplicity and
the number of large scale neighbours
![]() .
A correlation between
multiplicity and large scale environment clearly emerges, with Ts representing
the majority of the structures with few neighbours.
The KS test indicates that distributions between Ts and higher multiplicity
CGs are different
with significance level larger than 99.7%.
.
A correlation between
multiplicity and large scale environment clearly emerges, with Ts representing
the majority of the structures with few neighbours.
The KS test indicates that distributions between Ts and higher multiplicity
CGs are different
with significance level larger than 99.7%.
To extract physical information from the complete flux limited sample the role of the luminosity of member galaxies has to be properly disentangled, hence nearby CGs have to be separated from more distant ones. With this aim the sample was split into 4 distance classes whose radial velocities span over a 3000 km s-1 range each, with an overlap among adjacent samples of 500 km s-1. The first subsample is actually slightly smaller because all CGs at redshift below 1000 km s-1 are excluded, and its overlap with the next subsample slightly larger. The 4 subsamples lie within 1000-3000 km s-1, 2000-5000 km s-1, 4500-7500 km s-1, and 7000-10 000 km s-1 respectively (henceforth referred as subsamples I, II, III and IV). Subsamples mimic homogeneous samples, complete in magnitude and volume, and allow to correctly take into account multiplicity and neighbour density. The small overlap in redshift space does not bias the statistical analysis of the sample, as only Ts and Ms within the same subsample are compared, and no comparison between CGs in different subsamples is performed. Table 3 reports for each subsample the median value of the kinematical parameters provided by the algorithm, together with the median value of the large scale neighbours. The distribution of Ts and Ms, in the four defined distance classes, is shown in the lower right panel in Fig. 1. The decline in both distributions in subsample IV reflects the sharply decreasing luminosity function of galaxies at the high luminosity end. The fraction of UZC galaxies in CGs within each of the 4 defined subsamples is 11%, 10%, 7% and 4% respectively. Actually, since the volumes covered are extremely different, our results on the 4 subsamples exhibit different levels of statistical significance. Subsample I should strongly reflect our position within the Local Supercluster. For example, several CGs in subsample I are Virgo cluster subclumps (see Mamon 1989).
The volume number density of all CGs (computed for systems
at
![]() km s-1 and
km s-1 and
![]() )
turns out to be
)
turns out to be
![]() Mpc-3,
almost 4 times the density of Ms alone. CGs number density
slightly exceeds values estimated in RSCGs (Barton et al. 1996), which in turn,
retrieve number densities much higher than in HCGs
because of Hickson's bias against Ts.
Mpc-3,
almost 4 times the density of Ms alone. CGs number density
slightly exceeds values estimated in RSCGs (Barton et al. 1996), which in turn,
retrieve number densities much higher than in HCGs
because of Hickson's bias against Ts.
| subsample | Ts |
|
|
|
|
|
Ms |
|
|
|
|
|
| II | 80 | 128 | 141 | 74 | 99 | 3 | 23 | 245 | 279 | 82 | 135 | 5 |
| III | 99 | 152 | 175 | 65 | 93 | 3 | 27 | 262 | 380 | 82 | 121 | 4 |
| IV | 45 | 174 | 200 | 79 | 109 | 2 | 18 | 314 | 446 | 91 | 122 | 3 |
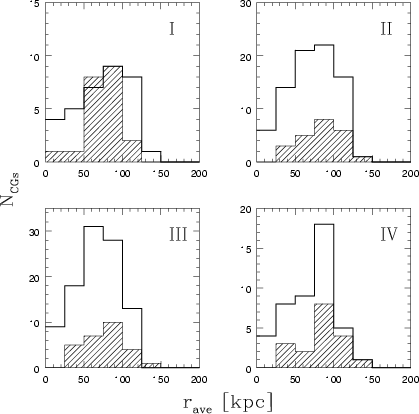 |
Figure 2:
Distribution of Ts and Ms
(hatched) as a function of the parameter
|
Copyright ESO 2002