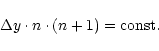In general echelle order curvature and location on the detector can either be assumed a priori or determined empirically from the image being reduced. Assumed order maps can be calculated from an optical model or measured empirically from a reference image. Alignment of the assumed map with actual order locations may require an offset. Although some echelle spectrographs may be stable enough to rely on an assumed order map, we believe a general echelle reduction package should determine order curvature and location empirically, whenever possible.
Empirical order maps may be determined interactively or automatically. Automated procedures are preferable because they are reproducible and allow batch processing of many spectra, though the robustness of human interaction must then be captured in an automated algorithm. Automated procedures must also evaluate whether order mapping has been successful, halting or reverting to a default order map if a specific image cannot be mapped, for example when there is no signal.
The new order location algorithm presented here consists of four steps: selection of pixels that might be in spectral orders, clustering analysis of these selected pixels, merging and rejection of clusters, and fitting of merged clusters. The procedure is sufficiently robust to use on every science image, but UVES is stable enough that order locations need only be determined once, for example using the mean flat. A special order definition image may be needed when an image slicer is used as the entrance slit.
Recall that after forcing a canonical orientation, spectral orders are
aligned approximately along image rows. Selection of pixels that might be
in spectral orders is done by first smoothing each column and then
selecting pixels above the median of the difference between the original
and the smoothed column:
 |
(1) |
The x and y indices of selected pixels are stored and used in the
clustering analysis, which associates connected groups of pixels. One can
think of this procedure as coloring selected pixels so that all
neighboring pixels (with x and y that differ by at most 1) have the
same color. This is a non-trivial problem because some initially detached
clusters may ultimately need to be merged, as illustrated in Fig. 1.
Coloring begins by creating a vector to store the color of each selected pixel in x and y. Neighbors in the same row are easily detected by sorting x and y so that y increases monotonically, while x scans the row corresponding to each value of y. In order to make the procedure as efficient in the vertical direction, we also sort x and y so that x increases monotonically, while y scans columns. We use a lookup array that relates both sets of sorted coordinates to assign a common color to neighboring pixels, thereby forming a cluster. Spurious clusters may persist in areas of very low signal. After the coloring step, clusters with fewer pixels than some tunable threshold are deselected, causing them to be ignored in the final fitting step.
Orders are often truncated by the top or bottom edge of the detector,
potentially hampering attempts to fit order location. To avoid this
problem, columns with cluster pixels in the first or last row of the
detector are ignored, when fitting the remaining pixels in a cluster (see
Fig. 2). This prepares for accurate extraction of
partial orders.
Even after clustering analysis, a single order may be partitioned into
multiple clusters due to detector defects or deep absorption features.
Polynomial fits are useful for deciding whether to merge or discard
clusters. For each cluster, we fit a polynomial of tunable order to pixel
y values, as a function of x, and then extend the fit to cover all
columns. Extended fits for pairs of consecutive clusters are compared to
identify which pair has fits that are most coincident for x values
present in the later cluster. As a metric of coincidence, we use the
number of columns in which both fits disagree by less than a few pixels.
![\begin{figure}
\par\includegraphics[width=10cm,clip]{h3260f5.eps}\end{figure}](/articles/aa/full/2002/15/aah3260/img7.gif) |
Figure 5: A segment of a stellar spectrum (HD 217522) obtained with an image slicer (upper left) and the corresponding decomposition into an oversampled (M=10) spatial profile (upper right) and the spectrum (lower right). The reconstructed model image (Eq. (4)) is shown in the lower left. The upper-right panel also shows data for every column, scaled and offset according to the model. The only significant outlier corresponds to a cosmic ray feature in the observation which left no trace in the extracted spectrum. The regions used to estimate scattered light are marked in the upper-right panel. |
In automatic mode, the most coincident pair of clusters is merged if the
two fits coincide over at least 95% of the x values present in the
later cluster. Otherwise, the smaller of the two clusters is ignored.
After merging or discarding a cluster, coincidence is re-assessed based on
new polynomial fits. Merging halts when no clusters coincide. This
procedure must converge in less than
![]() iterations but in practice the detector properties and layout of the focal
plane may allow more rapid convergence.
iterations but in practice the detector properties and layout of the focal
plane may allow more rapid convergence.
If the automated merging algorithm fails, manual intervention is required. The only situation we found requiring such intervention was the case of a bad row crossing multiple spectral orders (Fig. 2). In this case, fits to partial clusters created by the bad row may result erroneously in more significant coincidence with an adjacent order.
For each order, our clustering analysis yields a polynomial description of
order location, an uncertainty estimate for the fitted polynomial, and the
beginning and ending columns to use during spectrum extraction. In
addition, we attempt to identify the echelle order number of the first and
last order in the image, based on the observed change in order spacing.
For a grating cross-disperser, the grating equation for the echelle
(assuming that each detector column corresponds to a constant reflection
angle) gives:
Copyright ESO 2002
![\begin{figure}
\par\includegraphics[width=9.8cm,clip]{h3260f3.eps}\end{figure}](/articles/aa/full/2002/15/aah3260/img5.gif)
![\begin{figure}
\par\includegraphics[width=5.3cm,clip]{h3260f4.eps}\end{figure}](/articles/aa/full/2002/15/aah3260/img6.gif)
![\begin{figure}
\par\includegraphics[width=7.2cm,clip]{h3260f6.eps}\end{figure}](/articles/aa/full/2002/15/aah3260/img8.gif)