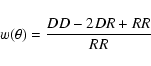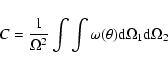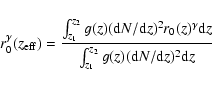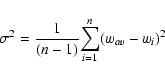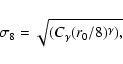A&A 479, 321-334 (2008)
DOI: 10.1051/0004-6361:20078636
H. J. McCracken1 - O. Ilbert2 - Y. Mellier1 - E. Bertin1 - L. Guzzo3 - S. Arnouts4,5 - O. Le Fèvre4 - G. Zamorani6
1 - Institut d'Astrophysique de Paris, UMR 7095
CNRS, Université Pierre et Marie Curie, 98bis boulevard Arago,
75014 Paris, France
2 - Institute for Astronomy, 2680 Woodlawn
Dr., University of Hawaii, Honolulu, 96822, Hawaii
3 -
INAF - Osservatorio Astronomico di Brera, via Bianchi 46, 23807
Merate (LC), Italy
4 - Laboratoire d'Astrophysique de Marseille, BP
8, Traverse du Siphon, 13376 Marseille Cedex 12, France
5 - Canada-France-Hawaii telescope, 65-1238 Mamalahoa Highway, Kamuela,
HI 96743, USA
6 - Osservatorio Astronomico di Bologna, via Ranzani 1,
40127 Bologna, Italy
Received 7 September 2007 / Accepted 20 November 2007
Abstract
We present an investigation of the clustering of the faint
(
i'AB<24.5) field galaxy population in the redshift range
0.2<z<1.2. Using 100 000 precise photometric redshifts extracted
from galaxies in the four ultra-deep fields of the Canada-France
Legacy Survey, we construct a set of volume-limited galaxy
samples. We use these catalogues to study in detail the dependence
of the amplitude Aw and slope ![]() of the galaxy correlation
function w on absolute MB rest-frame luminosity, redshift, and
best-fitting spectral type (or, equivalently, rest-frame
colour). Our derived comoving correlation lengths for
magnitude-limited samples are in excellent agreement with
measurements made in spectroscopic surveys. Our main conclusions are
as follows: 1. the comoving correlation length for all galaxies with
of the galaxy correlation
function w on absolute MB rest-frame luminosity, redshift, and
best-fitting spectral type (or, equivalently, rest-frame
colour). Our derived comoving correlation lengths for
magnitude-limited samples are in excellent agreement with
measurements made in spectroscopic surveys. Our main conclusions are
as follows: 1. the comoving correlation length for all galaxies with
![]() declines steadily from
declines steadily from ![]() to
to ![]() ;
2. at all redshifts and luminosity ranges, galaxies with redder
rest-frame colours have clustering amplitudes from two and three
times higher than bluer ones; 3. for both the red and blue galaxy
populations, the clustering amplitude is invariant with redshift for
bright galaxies (
;
2. at all redshifts and luminosity ranges, galaxies with redder
rest-frame colours have clustering amplitudes from two and three
times higher than bluer ones; 3. for both the red and blue galaxy
populations, the clustering amplitude is invariant with redshift for
bright galaxies (
![]() ); 4. at
); 4. at ![]() for less
luminous galaxies with
for less
luminous galaxies with
![]() we find higher
clustering amplitudes of
we find higher
clustering amplitudes of ![]() 6 h-1 Mpc; 5. the relative bias
between redder and bluer rest-frame populations increases gradually
towards fainter magnitudes. Among the most important implications of
these results is that although the full galaxy population traces the
underlying dark matter distribution quite well (and is therefore
quite weakly biased), redder, older galaxies have clustering lengths
that are almost invariant with redshift are quite
strongly biased by
6 h-1 Mpc; 5. the relative bias
between redder and bluer rest-frame populations increases gradually
towards fainter magnitudes. Among the most important implications of
these results is that although the full galaxy population traces the
underlying dark matter distribution quite well (and is therefore
quite weakly biased), redder, older galaxies have clustering lengths
that are almost invariant with redshift are quite
strongly biased by ![]() .
.
Key words: cosmology: large-scale structure of Universe - galaxies: photometry - cosmology: observations
In the cold dark matter model, structures grow hierarchically under
the influence of gravity. Galaxies form inside ``haloes'' of dark
matter (White & Rees 1978). Because these haloes can only form
at the densest regions of the dark matter distribution, the
distribution of galaxies and dark matter is not the same; the more
strongly clustered galaxies are said to be ``biased''
(Kaiser 1984; Bardeen et al. 1986) with respect to the
dark matter distribution. This relationship between dark and luminous
matter provides important information concerning the galaxy formation
process, and tracing the evolution of bias as a function of scale and
mass of the hosting dark matter halo is one of the key objectives of
observational cosmology. On large scales, (>10 h-1 Mpc) structure
growth is largely driven by gravitation (where we measure the
correlations between separate haloes of dark matter); however on
smaller scales (<1 h-1) non-linear effects generally associated
with galaxy formation dominate the structure formation process. In
this paper we must bear in mind that, although we measure a clustering
signal to around ![]() at
at ![]() ,
this corresponds to around
,
this corresponds to around
![]() 3 h-1 Mpc and
3 h-1 Mpc and ![]() 2 h-1 Mpc at
2 h-1 Mpc at ![]() ,
which means
that our observations are mostly in non-linear to strongly non-linear
regimes where environmental effects play an important role in the
evolution of structure.
,
which means
that our observations are mostly in non-linear to strongly non-linear
regimes where environmental effects play an important role in the
evolution of structure.
On linear scales, as theory and simulations have shown (for example
Jenkins et al. 1998; or Weinberg et al. 2004), the
clustering amplitude of dark matter decreases steadily with
redshift. If galaxies perfectly traced the dark matter component, then
their clustering amplitudes would decrease at each redshift slice, in
step with the underlying dark matter. However, as the galaxy
distribution is biased, stellar evolution intervenes to complicate
this picture; in effect, the actual measured clustering amplitudes are
a complicated interplay between the underlying dark matter component
and how well the luminous matter traces this galaxy distribution, or
how efficiently galaxies form. Understanding fully the evolution of
galaxy clustering requires, therefore, some insights into the galaxy
formation process. Thanks to large spectroscopic redshift surveys we
now have a much more complete picture of the evolution of the galaxy
luminosity function with redshift (Ilbert et al. 2005) and how
the fraction of galaxy types evolves with redshift
(Zucca et al. 2006). For example, Ilbert et al. (2005),
using first-epoch data from the VVDS redshift survey have shown that
the luminosity function brightens considerably between z=0.3 and
z=1, with M* increasing by one or two magnitudes at ![]() .
We
must take this into account when comparing clustering amplitudes
measured at the same absolute luminosities in different redshift
ranges.
.
We
must take this into account when comparing clustering amplitudes
measured at the same absolute luminosities in different redshift
ranges.
In the local Universe, million-galaxy redshift surveys have greatly expanded our knowledge of galaxy clustering at low redshift. We now have a broad idea how the distribution of galaxies depends on their intrinsic luminosity and spectral type (Norberg et al. 2001; Zehavi et al. 2005; Norberg et al. 2002). In general, these works have shown to a high precision that at the current epoch more luminous galaxies are more clustered than faint ones, and that similarly redder objects have higher clustering amplitudes than bluer ones. Other works have shown that slope of the galaxy correlation depends on spectral type (Madgwick et al. 2003). These studies have indicated that, in general, more luminous, redder, objects are more strongly clustered than bluer, fainter galaxies. Some studies have also related physical galaxy properties, such a total mass in stars, with the clustering properties (Li et al. 2006). But how do these relationships change with look-back time?
At intermediate redshifts (![]() ), however, our knowledge is still
incomplete. Multi-object spectrographs mounted on ten-metre class
telescopes have made it possible to construct samples of a few
thousand galaxies. The first studies investigating galaxy clustering
as a function of the object's rest frame luminosity and colour for
large galaxy samples at
), however, our knowledge is still
incomplete. Multi-object spectrographs mounted on ten-metre class
telescopes have made it possible to construct samples of a few
thousand galaxies. The first studies investigating galaxy clustering
as a function of the object's rest frame luminosity and colour for
large galaxy samples at ![]() have now appeared
(Pollo et al. 2006; Coil et al. 2006; Meneux et al. 2006).
Unfortunately, these surveys typically contain
have now appeared
(Pollo et al. 2006; Coil et al. 2006; Meneux et al. 2006).
Unfortunately, these surveys typically contain ![]() 103 galaxies,
which are enough to select objects either by type and absolute
luminosity, but not, for instance, to apply both cuts simultaneously.
103 galaxies,
which are enough to select objects either by type and absolute
luminosity, but not, for instance, to apply both cuts simultaneously.
These works confirm some of the broad trends seen at lower redshift and with magnitude-limited samples (Le Fèvre et al. 2005a) but are still not quite large enough to investigate in detail how galaxy clustering depends simultaneously on more than one galaxy property. For example, one may investigate the dependence of clustering amplitude within a volume-limited sample (Meneux et al. 2006), but one may not, as yet, investigate simultaneously samples selected by type and absolute luminosity. Unfortunately, even with efficient wide-field multi-object spectrographs, gathering redshift samples of thousands of galaxies at redshift of one or so requires a significant investment of telescope time.
Photometric redshifts offer an exit from this impasse, and represent a
middle ground between simple studies using imaging data with magnitude
or colour-selected samples and spectroscopic surveys. Several attempts
have been made in the past to carry out galaxy clustering studies with
photometric redshifts, mostly using the Hubble deep field data sets
(Magliocchetti & Maddox 1999; Teplitz et al. 2001; Arnouts et al. 2002).
However, such works either suffered from sampling and cosmic variance
issues or poorly-controlled systematic errors. The advent of
wide-field mosaic cameras like MegaCam (Boulade et al. 2000) has
made it feasible for the first time to construct samples of tens to
hundreds of thousands of galaxies from ![]() all the way to
all the way to
![]() and beyond. Two key advances have made this possible;
firstly, rigorous quality control of photometric data, and secondly,
the availability of much larger, reliable training samples reaching to
faint (
and beyond. Two key advances have made this possible;
firstly, rigorous quality control of photometric data, and secondly,
the availability of much larger, reliable training samples reaching to
faint (![]() ) mag.
) mag.
In this paper we will describe measurements of galaxy clustering
derived from a large sample of galaxies with accurate photometric
redshifts in Canada-France legacy survey (CFHTLS) deep fields. These
fields have been observed repeatedly since the start of survey
operations in June 2003 as part of the on-going SNLS project
(Astier et al. 2006) and consequently each filter has very long
integration times (for r and i bands the total integration time in
certain fields is over 100 h). A full description of our
photometric redshift catalogue can be found in
Ilbert et al. (2006). Containing almost 100 000 galaxies to
i'<24.5 we are able to divide our sample by redshift, absolute
luminosity and spectral type. These photometric redshifts have been
calibrated using 8000 spectra from the VIRMOS-VLT deep survey (VVDS;
Le Fèvre et al. 2005b). In addition, our sample has sufficient
volume to provide reliable measurements of galaxy clustering
amplitudes at redshifts as low as ![]() ;
and we are thus able to
follow the evolution of galaxy correlation lengths over a wide
redshift interval. In the lower redshift bins, the extremely deep
CFHTLS photometry means it is possible to measure clustering
properties of a complete sample of objects as faint as
;
and we are thus able to
follow the evolution of galaxy correlation lengths over a wide
redshift interval. In the lower redshift bins, the extremely deep
CFHTLS photometry means it is possible to measure clustering
properties of a complete sample of objects as faint as
![]() (at
(at ![]() we have large numbers of very faint
objects with
we have large numbers of very faint
objects with
![]() although we do not consider them
here). In addition, by using all four independent deep fields of the
Canada-France legacy survey, we are able to robustly estimate the
amplitude of cosmic variance for each of our samples.
although we do not consider them
here). In addition, by using all four independent deep fields of the
Canada-France legacy survey, we are able to robustly estimate the
amplitude of cosmic variance for each of our samples.
Our objective in this paper is to determine, first of all, how the observed properties of galaxies determines their clustering. We are able to carry out such an investigation of galaxy clustering strength for samples of galaxies selected independently in absolute luminosity, rest-frame colour and redshift.
Our paper is organised as follows: in Sect. 2 we describe how our catalogues were prepared and how we computed our photometric redshifts; in Sect. 3 we describe how we measure galaxy clustering in our data; our results are presented in Sect. 4. Finally, our discussions and conclusions are presented in Sect. 5. In this work we divide the CFHTLS galaxy samples in three ways: first of all, we consider simple magnitude limited samples, divided by bins of redshift (described in Sect. 4.1); next, at two fixed redshift ranges, we consider galaxy samples selected by absolute luminosity and type (Sect. 4.2); and lastly, at a range of redshift bins and for the same slice in absolute luminosity, we consider galaxies selected by type (presented in Sect. 4.4).
Throughout the paper, we use a flat lambda cosmology (
![]() = 0.3,
= 0.3,
![]() = 0.7) and we define
h =
= 0.7) and we define
h =
![]() km s-1 Mpc-1. Magnitudes are given in the
AB system unless otherwise noted.
km s-1 Mpc-1. Magnitudes are given in the
AB system unless otherwise noted.
We now describe the preparation of the photometric catalogues used to derive our photometric redshifts. Although our input catalogue has already been released to the community as part of the CFHTLS-T0003 release (hereafter ``T03''), no extensive description of the catalogue processing has yet appeared in the literature; for completeness we provide a brief outline of the main processing steps in this section.
These photometric catalogues were released by the TERAPIX data centre
to the Canadian and French communities as part of the T03 release and
have been made public world-wide one year later. They comprise
observations taken with the MegaCam wide-field mosaic camera
(Boulade et al. 2000) at the Canada-France-Hawaii telescope
between June 1st, 2003 and September 12th, 2005. Full details of these
observations, data reductions, catalogue preparation and quality
assessment steps can be found on the TERAPIX web
pages![]() ,
however, we now outline our data reduction and catalogue preparation
procedure.
,
however, we now outline our data reduction and catalogue preparation
procedure.
MegaCam is a wide-field CCD mosaic camera consisting of 36 thinned EEV
detectors mounted at the prime focus of the 3.6 m Canada France Hawaii
Telescope on Mauna Kea, Hawaii. The detectors are arranged in two
banks. The nominal pixel scale at the centre of the detector is
0.186
![]() /pixel; the size of each detector pixel is
/pixel; the size of each detector pixel is ![]() .
All
observations for the CFHTLS are taken in queue-scheduling mode. Each
of the four fields presented in this paper have been observed in all
five MegaCam broad-band filters primarily for the supernovae legacy
survey. After pre-processing (bias-subtraction and flat-fielding) at
the CFHT, images are transferred to the Canadian astronomy data centre
(CADC) for archiving, and thence to TERAPIX at the IAP in Paris for
processing. At TERAPIX, the data quality assessment tool ``QualityFITS''
is run on each image, which provides a ``report card'' in the form of a
HTML page containing information on galaxy counts, stellar counts, and
the point-spread function for each individual image. Catalogues and
weight-maps are also generated. At this point each image is also
visually inspected and classified.
.
All
observations for the CFHTLS are taken in queue-scheduling mode. Each
of the four fields presented in this paper have been observed in all
five MegaCam broad-band filters primarily for the supernovae legacy
survey. After pre-processing (bias-subtraction and flat-fielding) at
the CFHT, images are transferred to the Canadian astronomy data centre
(CADC) for archiving, and thence to TERAPIX at the IAP in Paris for
processing. At TERAPIX, the data quality assessment tool ``QualityFITS''
is run on each image, which provides a ``report card'' in the form of a
HTML page containing information on galaxy counts, stellar counts, and
the point-spread function for each individual image. Catalogues and
weight-maps are also generated. At this point each image is also
visually inspected and classified.
In the classification process galaxies are divided into four grades according to seeing and associated image features (for instance, if the telescope lost tracking or other artifacts were present). Only the two highest-quality grades are kept for subsequent analysis.
After all images have been inspected, and bad images rejected, an
astrometric and photometric solution is computed using the TERAPIX
tool scamp which computes a solution simultaneously for all
filters (Bertin 2006). Finally, this astrometric
solution is used to re-project and co-add all images (and weights) to
produce final stacked image. All of these steps are managed from an
web-based pipeline environment. The internal rms astrometric
accuracy over the entire MegaCam field of view is always less than one
MegaCAM pixel (
![]() )
)
Galaxy number counts, stellar colour-colour plots and incompleteness
measurements have been calculated for all four deep stacks in all five
bands. By examining the position of the stellar locus in each field in
the u-g vs. g-r and g-r vs. r-i colour-colour planes we see that
the photometric zero-point accuracy field to-field is ![]() 0.03 or
better. Detailed comparisons between CFHTLS-wide survey fields and
overlapping Sloan Digital Sky Survey fields show systematic errors of
a comparable amplitude. This degree of photometric precision is
essential if we are to compute accurate photometric redshifts. A full
list of the characteristics of release T03 can be found at http://terapix.iap.fr/cplt/tab_t03ym.html.
0.03 or
better. Detailed comparisons between CFHTLS-wide survey fields and
overlapping Sloan Digital Sky Survey fields show systematic errors of
a comparable amplitude. This degree of photometric precision is
essential if we are to compute accurate photometric redshifts. A full
list of the characteristics of release T03 can be found at http://terapix.iap.fr/cplt/tab_t03ym.html.
Once images have been resampled and median-combined for each field we
use swarp to produce a ``chi-squared'' detection image
(Szalay et al. 1999) based on the g', r' and i' stacks (the
pixel scale on each image in all fields and colours is fixed to
![]() /pixel. Next, sextractor
(Bertin & Arnouts 1996) is executed in ``dual-image'' mode on all
stacks using the chi-squared image as the detection image. This method
``automatically'' produces matched catalogues between each stack as in
all cases the detection image remains the same. We note that, given
the strict criterion on the image seeing used to select input images
in the CFHTLS stacks, all deep stacks are approximately
seeing-matched, with the median seeing on each final stack in each
band of
/pixel. Next, sextractor
(Bertin & Arnouts 1996) is executed in ``dual-image'' mode on all
stacks using the chi-squared image as the detection image. This method
``automatically'' produces matched catalogues between each stack as in
all cases the detection image remains the same. We note that, given
the strict criterion on the image seeing used to select input images
in the CFHTLS stacks, all deep stacks are approximately
seeing-matched, with the median seeing on each final stack in each
band of ![]()
![]() .
This means one can safely use dual-mode detection.
We use Sextractor's mag_auto Kron-like ``total'' galaxy
magnitudes (Kron 1980). At faint magnitudes, where the
error on the Kron radius can be large, our total magnitudes revert to
simple
.
This means one can safely use dual-mode detection.
We use Sextractor's mag_auto Kron-like ``total'' galaxy
magnitudes (Kron 1980). At faint magnitudes, where the
error on the Kron radius can be large, our total magnitudes revert to
simple
![]() diameter aperture magnitudes. After the extraction
of catalogues redundant information is removed from each band and a
``flag'' column is added to the catalogues containing information
about the object compactness using the ``local'' measurement of the
object's half-light radius (McCracken et al. 2003).
A mask file, generated automatically and fine-tuned by hand, is
used to indicate areas near bright stars or with lower cosmetic
quality, and this information is incorporated in the object
flag. Objects used in the subsequent scientific analysis are those
which do not lie in these masked regions, are not saturated, and are
not stars.
diameter aperture magnitudes. After the extraction
of catalogues redundant information is removed from each band and a
``flag'' column is added to the catalogues containing information
about the object compactness using the ``local'' measurement of the
object's half-light radius (McCracken et al. 2003).
A mask file, generated automatically and fine-tuned by hand, is
used to indicate areas near bright stars or with lower cosmetic
quality, and this information is incorporated in the object
flag. Objects used in the subsequent scientific analysis are those
which do not lie in these masked regions, are not saturated, and are
not stars.
A full description of our method used to compute photometric redshifts
is given in Ilbert et al. (2006). Briefly we use a two-step
optimisation process based on firstly the bright sample (to set the
zero-points) and the full sample (which optimises the templates). This
new template set is then used to compute photometric redshifts in all
four fields. In this paper we consider photometric redshifts computed
using only the five CFHTLS filters (u*griz). This is true even in
fields where additional photometric information is available (for
example, CFHTLS-D1 field where there is supplementary
![]() photometry). This approach was taken to ensure that field-to-field
variation in photometric redshift accuracy as a function of redshift
was kept to a minimum. Our photometric redshifts are essentially
identical to those presented in Ilbert et al. with
the exception that in the D2 field we use additional ultra-deep u*imaging kindly supplied by the COSMOS consortium; this serves to
equalise the u* integration time between the fields. We separate
stellar sources from galaxies by using a combination of sextractor
flux_radius parameter and the best fitting spectral template.
photometry). This approach was taken to ensure that field-to-field
variation in photometric redshift accuracy as a function of redshift
was kept to a minimum. Our photometric redshifts are essentially
identical to those presented in Ilbert et al. with
the exception that in the D2 field we use additional ultra-deep u*imaging kindly supplied by the COSMOS consortium; this serves to
equalise the u* integration time between the fields. We separate
stellar sources from galaxies by using a combination of sextractor
flux_radius parameter and the best fitting spectral template.
We emphasise that a key aspect of our photometric redshifts is that
extensive comparisons have been made with large database of
spectroscopic redshifts (Le Fèvre et al. 2005a). In particular, we
draw attention to Figs. 9 and 10 of Ilbert et al.
which show photometric redshift accuracy and the fraction of
catastrophic errors as a function of redshift. For galaxies with
i'<24 in the redshift range 0.2<z<1.2 the photometric redshift
accuracy in the D1 field, expressed as
![]() ,
is
always less than 0.06; in the redshift range 0.2<z<0.6 it is less
than 0.04. Catastrophic errors are defined as the number of galaxies
with
,
is
always less than 0.06; in the redshift range 0.2<z<0.6 it is less
than 0.04. Catastrophic errors are defined as the number of galaxies
with
![]() where
where ![]() is the spectroscopic
redshift and
is the spectroscopic
redshift and ![]() the photometric redshifts. From Fig. 10 in
Ilbert et al. we can see that the fraction
the photometric redshifts. From Fig. 10 in
Ilbert et al. we can see that the fraction ![]() of objects with catastrophic redshift errors is better than
of objects with catastrophic redshift errors is better than ![]() in
the redshift range 0.2<z<1.2 for objects with
22.5<iAB<24.0.
in
the redshift range 0.2<z<1.2 for objects with
22.5<iAB<24.0.
Although there are smaller numbers of spectroscopic redshifts in the
other fields, some useful comparisons can be made; using 364 publicly-available spectra from the DEEP1 project, Fig. 14 in Ilbert et al. shows that the dispersion
![]() is 0.03 in the redshift interval 0.2<z<1.2. In the
D2 field we have carried out an additional comparison with
spectroscopic redshifts obtained by J. P. Kneib and collaborators in
the context of the COSMOS project. This test, making use of 335 i'<24spectroscopic redshifts, shows that, once again, in the interval
0.2<z<1.2, our photometric redshift errors
is 0.03 in the redshift interval 0.2<z<1.2. In the
D2 field we have carried out an additional comparison with
spectroscopic redshifts obtained by J. P. Kneib and collaborators in
the context of the COSMOS project. This test, making use of 335 i'<24spectroscopic redshifts, shows that, once again, in the interval
0.2<z<1.2, our photometric redshift errors
![]() are
are
![]() 0.035.
0.035.
During the preparation of this article, an independent comparison has been carried out by members of the DEEP2 team between their large spectroscopic sample and the CFHTLS-T03 photometric redshifts presented here. They find an excellent agreement between, comparable to the values presented here for the other fields, for more than 20 000 galaxies in the D3 survey field.
We would like to use photometric redshifts for objects fainter than
the
IAB<24.0 VVDS spectroscopic limit. We can define another
figure of merit, the percentage of objects with
![]() ,
where
,
where
![]() is the
is the
![]() photometric redshift error bar. This is plotted in Fig. 15
in Ilbert et al. and gives an indication of how
good the photometric redshifts are beyond the spectroscopic limit. In
the interval
photometric redshift error bar. This is plotted in Fig. 15
in Ilbert et al. and gives an indication of how
good the photometric redshifts are beyond the spectroscopic limit. In
the interval
![]() ,
this is always better than
,
this is always better than ![]() for all
four CFHTLS deep fields even as faint as i'<24.5.
for all
four CFHTLS deep fields even as faint as i'<24.5.
We measure the absolute magnitude of each galaxy in ![]() standard
bands (U Bessel, B and V Johnson, R and I Cousins). Using the
photometric redshift, the associated best-fit template and the observed
apparent magnitude in one given band, we can directly measure the
k-correction and the absolute magnitude in any rest-frame band. Since
at high redshifts the k-correction depends strongly on the galaxy
spectral energy distribution it is the main source of systematic error
in determining absolute magnitudes. To minimise k-correction
uncertainties, we derive the rest-frame luminosity at
standard
bands (U Bessel, B and V Johnson, R and I Cousins). Using the
photometric redshift, the associated best-fit template and the observed
apparent magnitude in one given band, we can directly measure the
k-correction and the absolute magnitude in any rest-frame band. Since
at high redshifts the k-correction depends strongly on the galaxy
spectral energy distribution it is the main source of systematic error
in determining absolute magnitudes. To minimise k-correction
uncertainties, we derive the rest-frame luminosity at ![]() using
the object's apparent magnitude closer to
using
the object's apparent magnitude closer to
![]() .
We
use either the r', i' or z' observed apparent magnitudes
according to the redshift of the galaxy. The procedure is described in
the Appendix A of Ilbert et al. (2005) where it shown that this
method greatly reduces the dependency of the k-corrections on galaxy
templates.
.
We
use either the r', i' or z' observed apparent magnitudes
according to the redshift of the galaxy. The procedure is described in
the Appendix A of Ilbert et al. (2005) where it shown that this
method greatly reduces the dependency of the k-corrections on galaxy
templates.
![\begin{figure}
\par\includegraphics[width=7.9cm,clip]{8636fig1.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img47.gif) |
Figure 1: Rest frame MU-MV colour as a function of B-band absolute magnitude for the D1 field. Each panel from top to bottom corresponds to the redshift bins used in this paper. The points show the four different best-fitting spectral types. In the colour version of this figure (available electronically) red, magnenta, green and blue points correspond to Coleman et al. Ell, Sbc, Scd, and Irr templates. The right-hand panels show the colour distribution for each redshift slice. |
| Open with DEXTER | |
Galaxies have been classified using multi-colour information in a similar fashion to other works in the literature (for example Wolf et al. 2003; Lin et al. 1999; Zucca et al. 2006). For each galaxy the rest-frame colours were matched with four templates from Coleman et al. (1980) (hereafter referred to ``Coleman, Wu and Weedman'' or ``CWW'' templates). These four templates have been optimised using the VVDS spectroscopic redshifts, as described in Ilbert et al., and are presented in Fig. 2 of this work. Galaxies have been divided in four types, corresponding to the optimised E/S0 template (type one), early spiral template (type two), late spiral template (type three) and irregular template (type four). Type four includes also starburst galaxies. Note that, in order to avoid introducing dependencies on any particular model of galaxy evolution, we did not apply templates corrections aimed at accounting for colour evolution as a function of redshift.
We show in Fig. 1 the rest-frame colour distribution of the galaxies for each type. Type one galaxies comprise most of the galaxies of the red peak of the bimodal colour distribution. The other types are distributed in the blue peak. Galaxies become smoothly bluer from type one to type four respectively.
There are two approaches which may be used to measure the clustering
of objects with photometric redshifts. One is simply to isolate
galaxies in a certain redshift range using photometric redshifts, and
then to compute the projected correlation function ![]() for
galaxies in this slice, as has long been done for magnitude-limited
samples. However, the additional information provided by photometric
redshifts on the bulk properties of our slice (its redshift
distribution) allows us to use the Limber's equation
(Limber 1953) to invert the projected correlation
function and recover spatial correlations at the effective redshift of
the slice. These computations are easy to perform and are relatively
insensitive to systematic errors in the photometric redshifts as one
just integrates over all galaxies in a given redshift slice; it has
already been used extensively in smaller surveys and is usually the
method of choice when only small numbers of galaxies or poorer-quality
photometric redshifts are available, and has been used extensively
over the past few years (see, for example Daddi et al. 2001;
or Arnouts et al. 1999). It has the disadvantage that it
provides only limited information on the shape of the angular
correlation function as one measures a correlation function integrated
over a given redshift slice.
for
galaxies in this slice, as has long been done for magnitude-limited
samples. However, the additional information provided by photometric
redshifts on the bulk properties of our slice (its redshift
distribution) allows us to use the Limber's equation
(Limber 1953) to invert the projected correlation
function and recover spatial correlations at the effective redshift of
the slice. These computations are easy to perform and are relatively
insensitive to systematic errors in the photometric redshifts as one
just integrates over all galaxies in a given redshift slice; it has
already been used extensively in smaller surveys and is usually the
method of choice when only small numbers of galaxies or poorer-quality
photometric redshifts are available, and has been used extensively
over the past few years (see, for example Daddi et al. 2001;
or Arnouts et al. 1999). It has the disadvantage that it
provides only limited information on the shape of the angular
correlation function as one measures a correlation function integrated
over a given redshift slice.
A second approach is to decompose the redshift of each galaxy into
it's components perpendicular (![]() )
and parallel (
)
and parallel (![]() )
to the
observer's line of sight, and then to compute a full two-dimensional
correlation function
)
to the
observer's line of sight, and then to compute a full two-dimensional
correlation function
![]() based on pair counts of galaxies
in both directions. Finally, one computes the sum of this clustering
amplitude in the direction parallel to the line of sight,
based on pair counts of galaxies
in both directions. Finally, one computes the sum of this clustering
amplitude in the direction parallel to the line of sight, ![]() .
In
spectroscopic surveys, this has the advantage of removing the effect
of redshift-space distortions caused by infall onto bound
structures. This technique has been used successfully for many
spectroscopic redshift surveys
(Le Fèvre et al. 1996; Zehavi et al. 2005; Davis & Peebles 1983)
and some attempts have been made to apply it to samples with
lower-accuracy photometric redshifts (Phleps et al. 2006). It
has the advantage that it can provide direct information on the shape
of the correlation function but this comes at the price of much
greater sensitivity to systematic errors in the photometric redshifts
(for example, integration over a much larger range in redshift space
is necessary). We plan an analysis using this technique in a
forthcoming article, but in this paper we adopt a conservative
approach, as we are primarily interested in the overall clustering
properties of our galaxy samples.
.
In
spectroscopic surveys, this has the advantage of removing the effect
of redshift-space distortions caused by infall onto bound
structures. This technique has been used successfully for many
spectroscopic redshift surveys
(Le Fèvre et al. 1996; Zehavi et al. 2005; Davis & Peebles 1983)
and some attempts have been made to apply it to samples with
lower-accuracy photometric redshifts (Phleps et al. 2006). It
has the advantage that it can provide direct information on the shape
of the correlation function but this comes at the price of much
greater sensitivity to systematic errors in the photometric redshifts
(for example, integration over a much larger range in redshift space
is necessary). We plan an analysis using this technique in a
forthcoming article, but in this paper we adopt a conservative
approach, as we are primarily interested in the overall clustering
properties of our galaxy samples.
We first use our photometric redshift catalogue to produce a galaxy sample generated using a given selection criterion, for example either by absolute or apparent magnitude, redshift or type. This same selection criterion is applied to catalogues for all four fields.
From these masked catalogues of object positions, we measure
![]() ,
the projected angular correlation function, using the
standard Landy & Szalay (1993) estimator:
,
the projected angular correlation function, using the
standard Landy & Szalay (1993) estimator:
An important point to consider is that, of course, the precision of
our photometric redshifts are limited. In a given redshift interval,
z1<z<z2 it is certainly possible that a given galaxy may be in
fact outside this range. To account for this, we employ a weighted
estimator of ![]() ,
as suggested by
Arnouts et al. (2002). In this scheme we weight each galaxy by
the fraction of the galaxy's probability distribution function
enclosed by the interval z1<z<z2.
,
as suggested by
Arnouts et al. (2002). In this scheme we weight each galaxy by
the fraction of the galaxy's probability distribution function
enclosed by the interval z1<z<z2.
In this case for each pair we must now compute
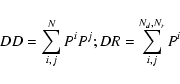 |
(2) |
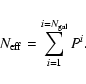 |
(3) |
We compute w in a series of logarithmically spaced bins from
![]() to
to
![]() with
with
![]() ,
where
,
where ![]() is in degrees. In the
following sections we will consider both measurements derived from
each field separately (using that field's redshift distribution) and
also measurements constructed from the sum of pairs over all fields
(in which case we use a combined, weighted redshift distribution
derived from all fields).
is in degrees. In the
following sections we will consider both measurements derived from
each field separately (using that field's redshift distribution) and
also measurements constructed from the sum of pairs over all fields
(in which case we use a combined, weighted redshift distribution
derived from all fields).
We can associate each value of Aw and ![]() with a
corresponding comoving correlation length, r0 by making use of the
relativistic Limber equation (Peebles 1980). For further discussion of
this method see, for example Daddi et al. (2001) or
Arnouts et al. (1999). If we assume that the spatial correlation
function can be expressed as
with a
corresponding comoving correlation length, r0 by making use of the
relativistic Limber equation (Peebles 1980). For further discussion of
this method see, for example Daddi et al. (2001) or
Arnouts et al. (1999). If we assume that the spatial correlation
function can be expressed as
![]() (where
(where
![]() and
and ![]() is the incomplete Gamma function)
is the incomplete Gamma function)
![\begin{displaymath}%
w(\theta)={\sqrt\pi\Gamma((\gamma-1)/2)\over{\Gamma(\gamma/...
...eft[\int({\rm d}N/{\rm d}z){\rm d}z\right]^2}\theta^{1-\gamma}
\end{displaymath}](/articles/aa/full/2008/08/aa8636-07/img66.gif) |
(5) |
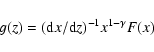 |
(6) |
![\begin{displaymath}%
{\rm d}s^2 = c^2{\rm d}t^2 - a^2[{\rm d}x/F(x)^2 + x^2 (\sin^2\theta {\rm d}\phi^2)].
\end{displaymath}](/articles/aa/full/2008/08/aa8636-07/img69.gif) |
(7) |
![\begin{displaymath}%
A_w=r_0^\gamma(z_{\rm eff})\sqrt\pi{\Gamma((\gamma-1)/2)\ov...
...eft[\int_{z_1}^{z_2}({\rm d}N/{\rm d}z){\rm d}z\right]^2}\cdot
\end{displaymath}](/articles/aa/full/2008/08/aa8636-07/img72.gif) |
(9) |
Given that we have four separate fields, we may derive r0 from
a ``global'' ![]() derived from the sum of pairs over all fields
and computed using the average, weighted
derived from the sum of pairs over all fields
and computed using the average, weighted
![]() .
Alternatively, we
can compute r0 for each field using that field's redshift
distribution and individual correlation function amplitudes; the final
value of r0 is then calculated simply as the average over all four
fields. We find that, in general, these methods agree for most
samples. However, in some cases the error bars are larger with the
field-to-field measurements. This is discussed in more detail in the
following section.
.
Alternatively, we
can compute r0 for each field using that field's redshift
distribution and individual correlation function amplitudes; the final
value of r0 is then calculated simply as the average over all four
fields. We find that, in general, these methods agree for most
samples. However, in some cases the error bars are larger with the
field-to-field measurements. This is discussed in more detail in the
following section.
We have investigated two different approaches to estimate the errors
on our measurements of r0. As described above, for each of our four
fields, we compute r0 from a fit to a measurement of ![]() and the redshift distribution for that field. We then
compute the variance in r0 and
and the redshift distribution for that field. We then
compute the variance in r0 and ![]() over all fields.
over all fields.
In the second method, for each sample, we compute the sum of the pairs
over all fields at each angular bin. The error bar at each angular bin
is then calculated from the variance in ![]() over all
fields. If wav is the mean correlation function then wi is
the correlation function for each field, then the error over the n fields of the CFHTLS is given as
over all
fields. If wav is the mean correlation function then wi is
the correlation function for each field, then the error over the n fields of the CFHTLS is given as
A ``global'' correlation length is determined using the average redshift distribution over four fields. In this case, the error in r0 is computed from the error in the best fitting Aw. This error is, in turn, computed from the covariance matrix derived using the Levenberg-Marquardt non-linear fitting routine, as presented in Numerical Recipes (Press et al. 1986).
We find that in general the error bars in r0 estimated by these two
different methods are consistent. However at lower redshifts ranges
(0.2<z<0.6), where the numbers of galaxies is smaller,
field-to-field dispersion is higher than the global errors. Further
investigations reveal this is due to the presence of a single field
(d2) which has anomalously higher correlation lengths. Properties of
this field are discussed in detail in McCracken et al. (2007). This
is undoubtedly due to the presence of very large structures at
![]() and
and ![]() in this field We believe that our ``global''
correlation function provides a more robust estimate of the total
error and we adopt this measurement for the remainder of the paper.
in this field We believe that our ``global''
correlation function provides a more robust estimate of the total
error and we adopt this measurement for the remainder of the paper.
Can photometric redshifts be used to make reliable measurements of
galaxy clustering at ![]() ? In this section we will construct a
sample similar to those already in the literature in order to address
this question. We consider galaxies selected by redshift and apparent
magnitude. In each field we divide our catalogues into a series of
bins of width
? In this section we will construct a
sample similar to those already in the literature in order to address
this question. We consider galaxies selected by redshift and apparent
magnitude. In each field we divide our catalogues into a series of
bins of width
![]() over the range 0.2<z<1.2. In each bin,
galaxies with
17.5<iAB<24.0 are selected to match the criterion
used by the VIMOS-VLT deep survey (VVDS) as presented in
Le Fèvre et al. (2005a) (we note that the Megacam instrumental i' magnitudes are very close to the CFH12K instrumental I magnitudes used in Le Fèvre et al.). Following the procedures outlined in Sect. 3, we measure the
weighted pair counts at each angular separation for each field and sum
them together. Equation (1) is used to derive a
``global''
over the range 0.2<z<1.2. In each bin,
galaxies with
17.5<iAB<24.0 are selected to match the criterion
used by the VIMOS-VLT deep survey (VVDS) as presented in
Le Fèvre et al. (2005a) (we note that the Megacam instrumental i' magnitudes are very close to the CFH12K instrumental I magnitudes used in Le Fèvre et al.). Following the procedures outlined in Sect. 3, we measure the
weighted pair counts at each angular separation for each field and sum
them together. Equation (1) is used to derive a
``global'' ![]() .
The error bar at each bin of angular
separation is computed from the variance of the individual
measurements of
.
The error bar at each bin of angular
separation is computed from the variance of the individual
measurements of ![]() over all four fields, as described in
Eq. (10). These results are illustrated in
Fig. 2, which shows the amplitude of w for all four
fields for a range of redshift slices. We note that in all redshift
slices except the lowest-redshift one, at intermediate scales,
over all four fields, as described in
Eq. (10). These results are illustrated in
Fig. 2, which shows the amplitude of w for all four
fields for a range of redshift slices. We note that in all redshift
slices except the lowest-redshift one, at intermediate scales,
![]() is well represented by a power law. In addition our error
bars are reassuringly small. This global
is well represented by a power law. In addition our error
bars are reassuringly small. This global ![]() is then fitted
with the usual power law, correcting for an integral constraint
corresponding to a total area of
is then fitted
with the usual power law, correcting for an integral constraint
corresponding to a total area of ![]() .
.
In calculating the correlation amplitude r0 at the effective
redshift of each slice we use a redshift distribution derived from the
weighted, summed
![]() from each field. Our results are displayed
in Figs. 3 and 4. They are
consistent with the measurements from the VVDS deep survey which was
based on a much smaller sample of
from each field. Our results are displayed
in Figs. 3 and 4. They are
consistent with the measurements from the VVDS deep survey which was
based on a much smaller sample of ![]() 7000 spectroscopic
redshifts. Our data does show some evidence for a decline in the
correlation amplitude strength in the interval 0.5<z<1.1, as well as
a slightly higher slope, in contrast with this earlier work. This will
be discussed in more detail in Sect. 5.
7000 spectroscopic
redshifts. Our data does show some evidence for a decline in the
correlation amplitude strength in the interval 0.5<z<1.1, as well as
a slightly higher slope, in contrast with this earlier work. This will
be discussed in more detail in Sect. 5.
The main difficulty in interpreting Figs. 3 and 4 is that at each redshift slice the sample's median absolute luminosity changes significantly as a consequence of the selection in apparent magnitude. This is evident if one considers Fig. 5 which shows a two-dimensional image of the objects distribution in the absolute magnitude-redshift plane. Slices extracted at lower redshift are dominated by galaxies of intrinsically low absolute luminosity.
![\begin{figure}
\par\includegraphics[width=7.1cm,clip]{8636fig2.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img79.gif) |
Figure 2:
The amplitude of the angular correlation w as a function of
angular separation |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.1cm,clip]{8636fig3.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img80.gif) |
Figure 3:
The comoving correlation length, r0 as a function of
redshift for the four combined CFHTLS fields (filled squares)
compared to literature values (open symbols) computed for a galaxy
sample limited at i'<24.0. For these fits, both |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=6.8cm,clip]{8636fig4.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img81.gif) |
Figure 4:
The best-fitting slope |
| Open with DEXTER | |
To investigate the dependence of galaxy clustering amplitude on absolute luminosity, in this Section we extract samples in two fixed redshift intervals selected from the absolute-magnitude/luminosity plane. We consider galaxies between 0.2<z<0.6 and 0.7<z<1.1. In each redshift range we select a minimum absolute magnitude (shown by the solid lines in Fig. 5) so that the median redshift of galaxies selected in each slice of absolute luminosity is approximately constant. At each redshift interval we separate the galaxy population into ``early'' (types one and two) and ``late'' (types three and four). We also consider samples comprising all galaxy types. These samples are illustrated in Fig. 6, where the median rest-frame Johnson (B-I) colour is plotted as a function of median rest-frame MB magnitude. In both high- and low-redshift slices, changes in the absolute magnitude bin produces the largest changes in rest-frame colours. Moreover, at same bin in absolute magnitude, galaxy populations become progressively bluer at higher redshifts.
Our type-selected correlation functions for galaxies in the redshift
range 0.2<z<0.6 are displayed in Fig. 7, and
for the higher redshift range in
Fig. 8. These plots show the amplitude of
the angular correlation function w as a function of angular
separation, ![]() ,
for different slices of absolute magnitude. In
each panel we show correlation functions measured for the red and blue
(early and late) populations. The size of the error bars at each
angular separation corresponds to the amplitude of the field-to-field
cosmic variance computed over the four fields. The long-dashed and
dashed lines show the fitted amplitudes for the red and blue
populations respectively. For the higher redshift bin, we superimpose
the fitted amplitudes at the same bin in absolute luminosity at the
lower redshift interval. At all redshifts and absolute luminosity
ranges, galaxies with redder rest-frame colours are more clustered
than their bluer counterparts.
,
for different slices of absolute magnitude. In
each panel we show correlation functions measured for the red and blue
(early and late) populations. The size of the error bars at each
angular separation corresponds to the amplitude of the field-to-field
cosmic variance computed over the four fields. The long-dashed and
dashed lines show the fitted amplitudes for the red and blue
populations respectively. For the higher redshift bin, we superimpose
the fitted amplitudes at the same bin in absolute luminosity at the
lower redshift interval. At all redshifts and absolute luminosity
ranges, galaxies with redder rest-frame colours are more clustered
than their bluer counterparts.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{8636fig5.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img82.gif) |
Figure 5: Gray-scaled histogram showing the distribution of galaxies as a function of absolute magnitude and redshift for four CFHTLS fields for all galaxy types and for an apparent magnitude limit of i'<24.5. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.2cm,clip]{8636fig6.ps} \end{figure}](/articles/aa/full/2008/08/aa8636-07/img83.gif) |
Figure 6: Median rest-frame (B-I) colour versus median rest frame B-band absolute luminosity for samples at 0.2<z<0.6 (open symbols, solid lines) and 0.7<z<1.1 (filled symbols, dotted lines). For each redshift range we show all galaxy types (circles), types one and two (squares) and types three and four (triangles). |
| Open with DEXTER | |
Because of the strong covariance between ![]() and r0 it is
useful to consider contours of constant
and r0 it is
useful to consider contours of constant ![]() at each slice in
absolute magnitude. This is shown in Fig. 9. The
vertical and horizontal lines mark an arbitrary reference point. Solid
lines indicate galaxies with 0.2<z<0.6 and dotted lines those with
0.7<z<1.1. From these plots we see a gradual increase in comoving
correlation length as a function of absolute rest-frame luminosity. We
also see some evidence for a slight decrease in the comoving
correlation length at given fixed absolute luminosity between higher
and lower redshift slices.
at each slice in
absolute magnitude. This is shown in Fig. 9. The
vertical and horizontal lines mark an arbitrary reference point. Solid
lines indicate galaxies with 0.2<z<0.6 and dotted lines those with
0.7<z<1.1. From these plots we see a gradual increase in comoving
correlation length as a function of absolute rest-frame luminosity. We
also see some evidence for a slight decrease in the comoving
correlation length at given fixed absolute luminosity between higher
and lower redshift slices.
Figures 10 and 11 show the comoving correlation function
![]() contours for red and blue populations in both redshift
ranges; and correspond to the angular correlation functions presented
in Figs. 7 and 8. Figure 9 shows
the comoving correlation length for the full galaxy population in both
redshift ranges.
contours for red and blue populations in both redshift
ranges; and correspond to the angular correlation functions presented
in Figs. 7 and 8. Figure 9 shows
the comoving correlation length for the full galaxy population in both
redshift ranges.
The results presented in this section are summarised in Figs. 12, 13 and in Tables 1 and 2. These figures show the best-fitting correlation amplitude as a function of absolute luminosity for the three different samples (early, late and the full galaxy population) in the two redshift ranges (0.2<z<0.6and 0.7<z<1.1) considered in this section.
![\begin{figure}
\par\includegraphics[width=12cm,clip]{8636fig7.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img85.gif) |
Figure 7:
The amplitude of the angular correlation w as a function of
angular separation |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=12cm,clip]{8636fig8.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img86.gif) |
Figure 8:
Similar to Fig. 7: the amplitude of
the angular correlation w as a function of angular separation |
| Open with DEXTER | |
Considering these plots, several features are apparent. Firstly, at
all absolute magnitude slices and in both redshift ranges, early-type
galaxies are always more strongly clustered (higher values of
r0) than late-type galaxies. Secondly, we note that clustering
amplitude for the late-type population is remarkably constant,
remaining fixed at ![]() 2 h-1 Mpc over a large range of absolute
magnitudes and redshifts. The behaviour of the early-type population
is more complicated. For the 0.2<z<0.6 bin, we some evidence that as
the median luminosity increases, the clustering amplitude of this
population decreases, from around
2 h-1 Mpc over a large range of absolute
magnitudes and redshifts. The behaviour of the early-type population
is more complicated. For the 0.2<z<0.6 bin, we some evidence that as
the median luminosity increases, the clustering amplitude of this
population decreases, from around ![]() 6 h-1 Mpc for the
faintest bins, to
6 h-1 Mpc for the
faintest bins, to ![]() 5 h-1 Mpc. We note that the difference in
clustering amplitude between the early and late populations is smaller
for the higher-redshift bin. We also note that the clustering
amplitudes we derive for our blue and full-field galaxy populations
are considerably lower than those reported by
Norberg et al. (2002) at lower redshifts.
5 h-1 Mpc. We note that the difference in
clustering amplitude between the early and late populations is smaller
for the higher-redshift bin. We also note that the clustering
amplitudes we derive for our blue and full-field galaxy populations
are considerably lower than those reported by
Norberg et al. (2002) at lower redshifts.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{8636fig9.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img87.gif) |
Figure 9:
The comoving correlation length r0 and slope
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{8636fig10.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img90.gif) |
Figure 10:
The comoving correlation length r0 and slope
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{8636fig11.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img91.gif) |
Figure 11:
The comoving correlation length r0 and slope
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=6.7cm,clip]{8636fig12.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img92.gif) |
Figure 12: The comoving correlation length r0 as a function of median absolute luminosity and type for objects in the redshift range 0.2<z<0.6. Filled circles show the full galaxy population. In addition to type selection, the galaxy sample is selected in one-magnitude bins of absolute luminosity. Triangles and squares represent the late and early-type populations respectively. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.1cm,clip]{8636fig13.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img93.gif) |
Figure 13: Similar to Fig. 12; here we show measurements from our 0.6<z<1.1 sample. Points from the literature from the measurements made by the DEEP2 and VVDS surveys. |
| Open with DEXTER | |
We carried out several test to verify the robustness of the higher
correlation amplitudes observed for the fainter red galaxy population
at ![]() .
Selecting galaxies with redder rest-frame colours
(classified as type one) in larger bins of absolute magnitude we also
measure higher clustering amplitudes for objects fainter than
.
Selecting galaxies with redder rest-frame colours
(classified as type one) in larger bins of absolute magnitude we also
measure higher clustering amplitudes for objects fainter than
![]() .
We also note that the origin of the large error bar
for the bin at
.
We also note that the origin of the large error bar
for the bin at
![]() is due to the presence of structures
in one of the four fields; interestingly, for the D1 field, for this
faint red population, the correlation function does not follow a
normal power-law shape. Our resulting error bars reflect this
behaviour, but it is clear that for certain galaxy populations, for
instance the bright elliptical population, simple power-law fits are
not appropriate.
is due to the presence of structures
in one of the four fields; interestingly, for the D1 field, for this
faint red population, the correlation function does not follow a
normal power-law shape. Our resulting error bars reflect this
behaviour, but it is clear that for certain galaxy populations, for
instance the bright elliptical population, simple power-law fits are
not appropriate.
In the redshift range 0.7<z<1.1 we have compared our measurements of pure luminosity dependent clustering (i.e., without type selection) to works in the literature computed using smaller samples of spectroscopic redshifts, namely Pollo et al. (2006) and Coil et al. (2006), shown in Fig. 13 as the open triangles and open stars respectively. Their points should be compared with the full circles derived from our measurements. In general the agreement is acceptable, although for higher luminosity bins, our amplitudes are below the measurements from the DEEP2 survey (although it seems that the amplitude of their error bars is perhaps underestimated).
For all the plots previously shown in this section we fitted
simultaneously for the slope and amplitude of the galaxy correlation
function. In Figs. 14 and 15
we summarise our results from our low and high redshift
samples. Figure 15 shows the slope ![]() as a
function of absolute luminosity for early-type, late type, and
full-field populations at high redshifts. Figure 14
presents the results from the 0.2<z<0.6 sample. Error bars are
computed from the field-to-field variance.
as a
function of absolute luminosity for early-type, late type, and
full-field populations at high redshifts. Figure 14
presents the results from the 0.2<z<0.6 sample. Error bars are
computed from the field-to-field variance.
Table 1: Low redshift sample (0.2<z<0.6). Columns show the median rest-frame B-band absolute luminosity, total number of galaxies over the four fields, median absolute rest-frame B-I colour, effective redshift, best fitting correlation length and slope.
Table 2: High redshift sample (0.7<z<1.1).
Interestingly, we find for the higher redshift bin (0.7<z<1.1) the slope is relatively insensitive to absolute magnitude. However, at lower redshifts, luminous red galaxies have a steeper correlation function slope than fainter galaxies. A similar effect is observed in the SDSS and two-degree field surveys at lower redshifts (Norberg et al. 2002).
![\begin{figure}
\par\includegraphics[width=7.05cm,clip]{8636fig14.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img140.gif) |
Figure 14:
Best-fitting slope |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.05cm,clip]{8636fig15.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img141.gif) |
Figure 15: As in Fig. 12 but for the redshift range 0.7<z<1.1. Slopes are plotted as a function of the median absolute magnitude in each bin of one magnitude in width. |
| Open with DEXTER | |
In Fig. 16 we plot the clustering amplitudes of bright early-type galaxies in our survey. As expected, the clustering amplitudes of the pure type one population (with overall redder rest-frame colours) are higher than the combined type one and two samples. (We have also measured the clustering amplitude of the pure type four population and find that in this case clustering amplitudes are lower than the combined sample of types three and four.) Error bars are computed from the field-to-field variance.
Several authors have presented clustering measurements as a function
of either absolute luminosity, type or redshift. For example,
Meneux et al. (2006) described measurements in the VVDS
spectroscopic redshift survey of the projected correlation function
for early- and late-type galaxies. Their galaxies are classified in
the same way as in this paper, using CWW templates. However, in their
sample galaxies were selected by apparent magnitude; at ![]() ,
their rest frame luminosities are comparable to the brightest galaxies
in our sample. We compare these
,
their rest frame luminosities are comparable to the brightest galaxies
in our sample. We compare these ![]() with our data; they are shown
as the open circles in Fig. 16. Finally, the open
triangles represent measurements from Brown et al. (2003) who
measured clustering of red galaxies selected using three-band
photometric redshifts in the NOAO wide survey. Their results are above
ours by at least one or two standard deviations. In general we note
that our results are lower than literature measurements and speculate
that this could be the consequence of a slight loss of signal due our
use of photometric redshifts. The broad trend seen in our
measurements is that the clustering amplitude of bright early-type
galaxies does not change with redshift.
with our data; they are shown
as the open circles in Fig. 16. Finally, the open
triangles represent measurements from Brown et al. (2003) who
measured clustering of red galaxies selected using three-band
photometric redshifts in the NOAO wide survey. Their results are above
ours by at least one or two standard deviations. In general we note
that our results are lower than literature measurements and speculate
that this could be the consequence of a slight loss of signal due our
use of photometric redshifts. The broad trend seen in our
measurements is that the clustering amplitude of bright early-type
galaxies does not change with redshift.
![\begin{figure}
\par\includegraphics[width=7.1cm,clip]{8636fig16.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img142.gif) |
Figure 16: Clustering amplitude of luminous red galaxies. Open and filled squares show measurements for type one and type one and two combined galaxy samples. Other points show measurements from the literature for early type galaxies selected using a variety of methods. |
| Open with DEXTER | |
How does the comoving correlation length of the various galaxy
populations investigated here depend on redshift? Over the full range
redshift range (0.2<z<1.1), as is apparent from
Fig. 5, this measurement is only possible for
the brightest galaxies; at higher redshifts, intrinsically fainter
galaxies drop out of our survey. For each of the redshift bins used in
Fig. 2 we selected galaxies with
![]() and measured r0 and
and measured r0 and ![]() as above. The derived
amplitudes for this sample are shown as the stars in
Fig. 17. We also selected at each redshift bin
early type galaxies (types 1 and 2) and late type galaxies (types 3
and 4). We find that the median absolute magnitude at each bin is
as above. The derived
amplitudes for this sample are shown as the stars in
Fig. 17. We also selected at each redshift bin
early type galaxies (types 1 and 2) and late type galaxies (types 3
and 4). We find that the median absolute magnitude at each bin is
![]() for the early types and
for the early types and
![]() for the late types. The full galaxy population has an
absolute magnitude of
for the late types. The full galaxy population has an
absolute magnitude of
![]() .
From 0.4<z<1.2, these
values changes by at most 0.1 mag. As in previous plots, the
size of the error bars represent cosmic variance errors over the four fields.
.
From 0.4<z<1.2, these
values changes by at most 0.1 mag. As in previous plots, the
size of the error bars represent cosmic variance errors over the four fields.
![\begin{figure}
\par\includegraphics[width=7.1cm,clip]{8636fig17.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img147.gif) |
Figure 17: Redshift dependence of comoving galaxy correlation length r0 for a series of volume limited samples for early types (squares), late types (triangles) and for the full sample (filled circles). |
| Open with DEXTER | |
We find that in the redshift range 0.4<z<1.2 probed by our survey,
early-type galaxies are always more clustered than late type
galaxies as we have already found in in the previous
sections. Moreover, the difference in clustering amplitudes between
these two populations is approximately constant with redshift. (Note
that the galaxy samples examined here correspond to essentially the
brightest bins plotted in Figs. 12 and 13.) We also find that the clustering of the
![]() luminosity-limited full galaxy sample
(i.e., without including a type selection) decreases steadily from
luminosity-limited full galaxy sample
(i.e., without including a type selection) decreases steadily from
![]() to
to ![]() .
.
We can also compute the relative bias between different galaxy
populations at different redshifts. At each redshift range in
Sect. 4.2 (0.2<z<0.6 and 0.7<z<1.1) we
compute the relative bias b as follows:
| (11) |
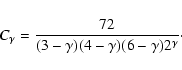 |
(13) |
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{8636fig18.ps}\end{figure}](/articles/aa/full/2008/08/aa8636-07/img156.gif) |
Figure 18:
Top panel: relative bias between early and late-type
populations at |
| Open with DEXTER | |
We compare our relative bias between blue and red galaxy populations
with measurements in the literature. Marinoni et al. (2005)
divided their spectroscopic sample into a red one with rest-frame
(B-I)>0.95 and a bluer one with
(B-I)<0.68. By measuring the
probability distribution function (PDF) of these two populations, they
were able to be measure the relative bias of relatively bright (
![]() )
galaxies in the interval 0.6<z<1.1, indicated by
the starred point in Fig. 18. Recently,
Swanson et al. (2007) investigated the relative bias between red
and blue spectroscopic galaxy samples in the Sloan Digital Sky Survey
as a function of absolute rest-frame red magnitude. Their results are
represented in Fig. 18 as open triangles (with an
approximate offset applied to convert to rest-frame blue magnitudes
used in this paper).
)
galaxies in the interval 0.6<z<1.1, indicated by
the starred point in Fig. 18. Recently,
Swanson et al. (2007) investigated the relative bias between red
and blue spectroscopic galaxy samples in the Sloan Digital Sky Survey
as a function of absolute rest-frame red magnitude. Their results are
represented in Fig. 18 as open triangles (with an
approximate offset applied to convert to rest-frame blue magnitudes
used in this paper).
From Fig. 18 we see that our measurements at ![]() agree with Swanson et al. and
Marinoni et al. Swanson et al.
findings are similar to ours: they observe an increase in the relative
bias between early and late types at fainter magnitudes. However, at
agree with Swanson et al. and
Marinoni et al. Swanson et al.
findings are similar to ours: they observe an increase in the relative
bias between early and late types at fainter magnitudes. However, at
![]() ,
our relative bias measurements are considerably higher
than either measurements
,
our relative bias measurements are considerably higher
than either measurements ![]() or
or ![]() .
.
In this paper we have used a sample of 100 000 photometric redshifts
in the CFHTLS legacy survey deep fields to investigate the dependency
of galaxy clustering on rest-frame colour, luminosity and
redshift. The first sample we considered comprises a series of
magnitude-selected cuts sampling the full galaxy population from
0.2<z<1.2. We find that the clustering amplitude decreases gradually
from 3 h-1 Mpc at ![]() declining to 2 h-1 at
declining to 2 h-1 at
![]() .
The declining correlation amplitude for the full galaxy
population at least to
.
The declining correlation amplitude for the full galaxy
population at least to ![]() indicates that the field galaxy
population must be weakly biased, as this trend follows that of the
underlying correlation amplitudes of the dark matter.
indicates that the field galaxy
population must be weakly biased, as this trend follows that of the
underlying correlation amplitudes of the dark matter.
We next repeated the same experiment (measuring galaxy clustering in
narrow redshift bins) and imposed an additional selection by absolute
luminosity and rest-frame colour. Selecting galaxies by slices of
absolute luminosity the steady decline in comoving correlation length
found for samples selected in apparent magnitude is even more
pronounced (Fig. 17). The luminous field galaxy
population, dominated by blue star-forming galaxies at ![]() ,
is
clearly only weakly biased with respect to the dark matter
distribution.
,
is
clearly only weakly biased with respect to the dark matter
distribution.
Turning to rest-frame colour-selected samples at all redshift ranges we consistently find that galaxies with redder rest-frame colours are more strongly clustered than those with bluer rest-frame colours (Fig. 17). Such an effect has long been observed for galaxies in the local Universe (for example Guzzo et al. 1997; Loveday et al. 1999; Zehavi et al. 2005; Norberg et al. 2002) and at higher redshifts for samples selected by type and luminosity (Coil et al. 2006; Meneux et al. 2006). Numerical simulations find a similar effect: for example, Weinberg et al. (2004) show that older, redder galaxies are more strongly clustered. This is a generic prediction from most semi-analytic models and hydrodynamic simulations of galaxy formation: older, more massive galaxies formed in regions which collapsed early in the history of the Universe. At the present day such regions are biased with respect to the dark matter distribution.
For the brightest ellipticals (
![]() )
in our survey,
we find that their clustering amplitude does not change with redshift
(Fig. 17), indicating that at
)
in our survey,
we find that their clustering amplitude does not change with redshift
(Fig. 17), indicating that at ![]() the
elliptical population must be strongly biased with respect to the
underlying dark matter distribution. Comparing our measurements for
objects with redder rest-frame colours with those of other surveys, we
find similar clustering amplitudes. Reassuringly, as we demonstrated
in Sect. 4.3 sub-samples of galaxies with
redder rest-frame colours produce even higher correlation amplitudes
(Fig. 16).
the
elliptical population must be strongly biased with respect to the
underlying dark matter distribution. Comparing our measurements for
objects with redder rest-frame colours with those of other surveys, we
find similar clustering amplitudes. Reassuringly, as we demonstrated
in Sect. 4.3 sub-samples of galaxies with
redder rest-frame colours produce even higher correlation amplitudes
(Fig. 16).
In a second set of selections we considered the dependence of
galaxy clustering on luminosity and type in two broad redshift bins:
0.2<z<0.6 and 0.7<z<1.1 (we leave a ``gap'' in the range 0.6<z<0.7to ensure that there is no contamination between high and low redshift
ranges). Once again, for the most luminous objects (
![]() )
the correlation amplitude is approximately constant between
these two redshift bins. However, for fainter red objects, at a fixed
absolute luminosity, we see a decline in correlation amplitude between
)
the correlation amplitude is approximately constant between
these two redshift bins. However, for fainter red objects, at a fixed
absolute luminosity, we see a decline in correlation amplitude between
![]() and
and ![]() ;
the same is true for samples selected purely
by absolute magnitude. We find no evidence for a change in clustering
amplitude at the same luminosity for the blue population with
redshift.
;
the same is true for samples selected purely
by absolute magnitude. We find no evidence for a change in clustering
amplitude at the same luminosity for the blue population with
redshift.
At 0.2<z<0.6, where we are complete to
![]() ,
we find
that red galaxies with
,
we find
that red galaxies with
![]() are more strongly
clustered than bluer galaxies of the same luminosity. Moreover as the
sample rest frame luminosity decreases to
are more strongly
clustered than bluer galaxies of the same luminosity. Moreover as the
sample rest frame luminosity decreases to
![]() the
clustering amplitude rises from
the
clustering amplitude rises from ![]() 4 h-1 Mpc to
4 h-1 Mpc to ![]() 6 h-1 Mpc. A similar effect has been reported in larger, low-redshift samples in the local universe
(Swanson et al. 2007; Norberg et al. 2002), where both the Sloan
and 2dF surveys have found higher clustering amplitudes for redder
objects fainter than L*. Some evidence for this effect has also
been reported in numerical simulations (Croton et al. 2007),
which indicate that this behaviour arises because faint red objects
exist primarily as satellite galaxies in halos of massive, strongly
clustered red galaxies. This means that less luminous, redder objects
reside primarily in higher density environments at
6 h-1 Mpc. A similar effect has been reported in larger, low-redshift samples in the local universe
(Swanson et al. 2007; Norberg et al. 2002), where both the Sloan
and 2dF surveys have found higher clustering amplitudes for redder
objects fainter than L*. Some evidence for this effect has also
been reported in numerical simulations (Croton et al. 2007),
which indicate that this behaviour arises because faint red objects
exist primarily as satellite galaxies in halos of massive, strongly
clustered red galaxies. This means that less luminous, redder objects
reside primarily in higher density environments at ![]() .
This is
in agreement with recent studies of galaxy clusters at intermediate
redshift which indicate a rapid build-up of low luminosity red
galaxies in clusters since
.
This is
in agreement with recent studies of galaxy clusters at intermediate
redshift which indicate a rapid build-up of low luminosity red
galaxies in clusters since ![]() (van der Wel et al. 2007). Our
survey is not deep enough to probe to equivalent luminosities at
(van der Wel et al. 2007). Our
survey is not deep enough to probe to equivalent luminosities at
![]() .
.
Conversely for the redshift bin at 0.7<z<1.1 we see that for the
full galaxy population more luminous objects are more strongly
clustered: ![]() 2 h -1 Mpc for galaxies with
2 h -1 Mpc for galaxies with
![]() and
and ![]() 4 h -1 Mpc for galaxies with
4 h -1 Mpc for galaxies with
![]() .
At all luminosity bins, galaxies with redder rest-frame colours
are always more strongly clustered than bluer galaxies.
.
At all luminosity bins, galaxies with redder rest-frame colours
are always more strongly clustered than bluer galaxies.
In both redshift ranges, we measured the slopes of the correlation
function as a function of redshift, luminosity and rest-frame
colour. At ![]() we observe that redder galaxies have steeper
slopes; at lower redshifts however different galaxy populations have
identical slopes. At these redshifts, we find steeper slopes in our
most luminous bin; at higher redshifts, no such obvious trend is
apparent (in contrast with Pollo et al. 2006, who saw a clear
dependence of slope on absolute luminosity).
we observe that redder galaxies have steeper
slopes; at lower redshifts however different galaxy populations have
identical slopes. At these redshifts, we find steeper slopes in our
most luminous bin; at higher redshifts, no such obvious trend is
apparent (in contrast with Pollo et al. 2006, who saw a clear
dependence of slope on absolute luminosity).
We have also computed the relative bias between red and blue galaxies
at ![]() and
and ![]() .
At
.
At ![]() our results agree with
measurements in the literature. Our measurements at
our results agree with
measurements in the literature. Our measurements at ![]() are
significantly above measurements made at
are
significantly above measurements made at ![]() .
Interestingly, our
results show that the relative bias between early and late types
increases gradually for samples selected with fainter intrinsic
luminosities, which is consistent with the results presented for our
investigation of galaxy clustering.
.
Interestingly, our
results show that the relative bias between early and late types
increases gradually for samples selected with fainter intrinsic
luminosities, which is consistent with the results presented for our
investigation of galaxy clustering.
Concluding, we may summarise our results as follows: firstly, for samples of galaxies with similar absolute luminosities, galaxies with redder rest-frame colours are always more strongly clustered than their bluer counterparts. Secondly, for the bluer galaxy populations, the correlation length depends only weakly on absolute luminosity. At lower redshifts, we find some evidence that redder galaxies with lower absolute luminosities are more strongly clustered. For the entire galaxy population (red and blue types combined) we find that as the median absolute magnitude increases, the overall clustering amplitude increases. For our the most luminous red and blue objects, the clustering amplitude does not change with redshift.
The overall picture we draw from these observations is that the
clustering properties of the blue population is remarkably invariant
with redshift and intrinsic luminosity. In general, galaxies with
bluer rest-frame colours, which comprise the majority of galaxies in
our survey, have lower clustering amplitudes (typically, ![]() 2 h-1 Mpc) than the redder populations. The clustering amplitude of
the blue population depends only weakly on redshift and
luminosity. This is consistent with a picture in which bluer galaxy
types exist primarily in lower density environments.
2 h-1 Mpc) than the redder populations. The clustering amplitude of
the blue population depends only weakly on redshift and
luminosity. This is consistent with a picture in which bluer galaxy
types exist primarily in lower density environments.
In contrast, the clustering amplitude of the low-luminosity red
population is lower at higher redshifts. In
Fig. 17 we see that for the luminous
(
![]() )
red population, the correlation amplitude
does not change with redshift. Moreover, at a fixed absolute
luminosity, the correlation amplitude of the full galaxy population
and the magnitude-selected galaxy population decreases from
)
red population, the correlation amplitude
does not change with redshift. Moreover, at a fixed absolute
luminosity, the correlation amplitude of the full galaxy population
and the magnitude-selected galaxy population decreases from ![]() to
to ![]() ,
in step with the underlying dark matter
distribution.
,
in step with the underlying dark matter
distribution.
We have presented an investigation of the clustering of the faint
(i'<24.5) field galaxy population in the redshift range
0.2<z<1.2. Using 100 000 precise photometric redshifts extracted in
the four ultra-deep fields of the Canada-France Legacy Survey, we
construct a series of volume-limited galaxy samples and use these to
study in detail the dependence of the amplitude Aw and slope ![]() of the galaxy correlation function w on absolute MBrest-frame luminosity, redshift, and best-fitting spectral type (or,
equivalently, rest-frame colour). Our conclusions are as follows:
of the galaxy correlation function w on absolute MBrest-frame luminosity, redshift, and best-fitting spectral type (or,
equivalently, rest-frame colour). Our conclusions are as follows:
It is tempting to interpret our results in terms of studies which show
that the number density of massive, luminous galaxies evolves little
from ![]() to the present day
(Cowie et al. 1996; Cimatti et al. 2006; Zucca et al. 2006). In our survey,
the clustering amplitudes of bright ellipticals are already ``fixed in''
at
to the present day
(Cowie et al. 1996; Cimatti et al. 2006; Zucca et al. 2006). In our survey,
the clustering amplitudes of bright ellipticals are already ``fixed in''
at ![]() .
Most of the changes in the clustering amplitude occur in
the fainter galaxy population. However, a full understanding of the
processes at work here will require mass-selected samples covering a
larger interval in redshift. Such samples will become possible in the
near future with the addition of near-infrared data to the CFHTLS
survey fields.
.
Most of the changes in the clustering amplitude occur in
the fainter galaxy population. However, a full understanding of the
processes at work here will require mass-selected samples covering a
larger interval in redshift. Such samples will become possible in the
near future with the addition of near-infrared data to the CFHTLS
survey fields.
Acknowledgements
This work is based in part on data products produced at TERAPIX located at the Institut d'Astrophysique de Paris. H. J. McCracken wishes to acknowledge the use of TERAPIX computing facilities. This research has made use of the VizieR catalogue access tool provided by the CDS, Strasbourg, France.