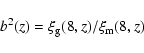A&A 475, 83-99 (2007)
DOI: 10.1051/0004-6361:20077506
R. Gilli1 - E. Daddi2 - R. Chary3 - M. Dickinson4 - D. Elbaz2 - M. Giavalisco5 - M. Kitzbichler6 - D. Stern7 - E. Vanzella8
1 - Istituto Nazionale di Astrofisica (INAF) - Osservatorio
Astronomico di Bologna, via Ranzani 1, 40127 Bologna, Italy
2 -
Laboratoire AIM, CEA/DSM - CNRS - Université Paris Diderot,
DAPNIA/SAp, Orme des Merisiers, 91191 Gif-sur-Yvette, France
3 -
Spitzer Science Center, California
Institute of Technology, Mail Stop 220-6, Pasadena, CA 91125, USA
4 -
National Optical Astronomy Observatory, PO Box 26732, Tucson, AZ
85726, USA
5 -
University of Massachusetts, Astronomy Dept, Amherst, MA 01003, USA
6 -
Max-Planck Institut für Astrophysik,
Karl-Schwarzschild-Strasse 1, 85748 Garching b. München, Germany
7 -
Jet Propulsion Laboratory, California
Institute of Technology, Pasadena, CA 91109, USA
8 -
Istituto Nazionale di Astrofisica (INAF) - Osservatorio Astronomico di Trieste,
via G. Tiepolo 11, 34131 Trieste, Italy
Received 19 March 2007 / Accepted 27 July 2007
Abstract
We present the first spatial clustering measurements of
![]() ,
24
,
24 ![]() m-selected, star forming galaxies in the Great
Observatories Origins Deep Survey (GOODS). The sample under
investigation includes 495 objects in GOODS-South and 811 objects in
GOODS-North selected down to flux densities of
m-selected, star forming galaxies in the Great
Observatories Origins Deep Survey (GOODS). The sample under
investigation includes 495 objects in GOODS-South and 811 objects in
GOODS-North selected down to flux densities of
![]() Jy and
Jy and
![]() mag, for which spectroscopic redshifts are available.
The median redshift, IR luminosity and star formation rate (SFR) of
the sample are
mag, for which spectroscopic redshifts are available.
The median redshift, IR luminosity and star formation rate (SFR) of
the sample are ![]() ,
,
![]()
![]() ,
and
,
and
![]() yr-1, respectively. We measure the
projected correlation function
yr-1, respectively. We measure the
projected correlation function
![]() on scales of
on scales of
![]() Mpc, from which we derive a best fit comoving
correlation length of
Mpc, from which we derive a best fit comoving
correlation length of
![]() Mpc and slope of
Mpc and slope of
![]() for the whole
for the whole
![]() Jy sample after
combining the two fields. We find indications of a larger correlation
length for objects of higher luminosity, with Luminous Infrared
Galaxies (LIRGs,
Jy sample after
combining the two fields. We find indications of a larger correlation
length for objects of higher luminosity, with Luminous Infrared
Galaxies (LIRGs,
![]() )
reaching
)
reaching
![]() Mpc. This would imply that galaxies with larger SFRs are
hosted in progressively more massive halos, reaching minimum halo
masses of
Mpc. This would imply that galaxies with larger SFRs are
hosted in progressively more massive halos, reaching minimum halo
masses of ![]()
![]() for LIRGs. We compare our
measurements with the predictions from semi-analytic models based on
the Millennium simulation. The variance in the models is used to
estimate the errors in our GOODS clustering measurements, which are
dominated by cosmic variance. The measurements from the two GOODS
fields are found to be consistent within the errors. On scales of the
GOODS fields, the real sources appear more strongly clustered than
objects in the Millennium-simulation based catalogs, if the selection
function is applied consistently. This suggests that star formation at
for LIRGs. We compare our
measurements with the predictions from semi-analytic models based on
the Millennium simulation. The variance in the models is used to
estimate the errors in our GOODS clustering measurements, which are
dominated by cosmic variance. The measurements from the two GOODS
fields are found to be consistent within the errors. On scales of the
GOODS fields, the real sources appear more strongly clustered than
objects in the Millennium-simulation based catalogs, if the selection
function is applied consistently. This suggests that star formation at
![]() is being hosted in more massive halos and denser
environments than currently predicted by galaxy formation
models. Mid-IR selected sources appear also to be more strongly
clustered than optically selected ones at similar redshifts in deep
surveys like the DEEP2 Galaxy Redshift Survey and the VIMOS-VLT Deep
Survey (VVDS), although the significance of this result is
is being hosted in more massive halos and denser
environments than currently predicted by galaxy formation
models. Mid-IR selected sources appear also to be more strongly
clustered than optically selected ones at similar redshifts in deep
surveys like the DEEP2 Galaxy Redshift Survey and the VIMOS-VLT Deep
Survey (VVDS), although the significance of this result is ![]()
![]() when accounting for cosmic variance. We find that LIRGs at
when accounting for cosmic variance. We find that LIRGs at
![]() are consistent with being the direct descendants of Lyman
Break Galaxies and UV-selected galaxies at
are consistent with being the direct descendants of Lyman
Break Galaxies and UV-selected galaxies at
![]() ,
both in term
of number densities and clustering properties, which would suggest
long lasting star-formation activity in galaxies over cosmological
timescales. The local descendants of
,
both in term
of number densities and clustering properties, which would suggest
long lasting star-formation activity in galaxies over cosmological
timescales. The local descendants of
![]() star forming
galaxies are not luminous IR galaxies but are more likely to be
normal, L<L* ellipticals and bright spirals.
star forming
galaxies are not luminous IR galaxies but are more likely to be
normal, L<L* ellipticals and bright spirals.
Key words: galaxies: evolution - cosmology: large-scale structure of Universe - cosmology: observations
In the general paradigm of large scale structure formation, the small primordial fluctuations in the matter density field progressively grow through gravitational collapse, leading to the present-day complex network of clumps and filaments which is often referred to as the "Cosmic Web''. Baryons are believed to cool within dark matter halos (DMHs) and form galaxies and cluster of galaxies, whose distribution on the sky should then trace that of the underlying dark matter. While the formation and the evolution of dark matter structures can be followed in a relatively straightforward way through N-body simulations (e.g., Jenkins et al. 1998; Springel et al. 2005), which can be also approximated analytically with high accuracy (Peacock & Dodds 1996), the physics of baryon cooling and galaxy formation within DMHs is far more complex. As a result of these complex physical processes, the distribution of galaxies in the sky may be biased with respect to that of the underlying matter distribution. The amplitude of this bias is expected to evolve with cosmic time and be dependent on galaxy type, luminosity and local environment (Norberg et al. 2002). The comparison between the clustering properties of galaxies and those of DMHs predicted by cold dark matter (CDM) models can be used to evaluate the typical mass of the DMHs in which galaxies form and reside as a function of cosmic time. Following the evolution of the typical DMH hosting a given galaxy type at any given time also allows one to predict the environment in which that galaxy should be found nowadays and the environment in which it was residing in the past. In other words, under reasonable assumptions, it is possible to guess the progenitors and descendants of galaxy populations observed at any cosmological epoch.
Galaxy clustering has been traditionally studied by means of the
two-point correlation function ![]() ,
defined as the excess
probability over random of finding a pair of galaxies at a separation
r from one another, which is often approximated with a power law of
the form
,
defined as the excess
probability over random of finding a pair of galaxies at a separation
r from one another, which is often approximated with a power law of
the form
![]() .
In the local Universe different
clustering properties have been observed as a function of galaxy
type. In the Sloan Digital Sky Survey (SDSS, York et al. 2000), at a
median redshift of
.
In the local Universe different
clustering properties have been observed as a function of galaxy
type. In the Sloan Digital Sky Survey (SDSS, York et al. 2000), at a
median redshift of ![]() ,
red, early-type galaxies show a larger
correlation length and a steeper slope (
,
red, early-type galaxies show a larger
correlation length and a steeper slope (
![]() )
than blue, late type galaxies (
)
than blue, late type galaxies (
![]() ;
Zehavi et al. 2002). Similar results arise from
the 2dF Galaxy Redshift Survey (2dFGRS; Colless et al. 2001), in
which, at a similar median redshift, passive galaxies show a
correlation length and slope of
;
Zehavi et al. 2002). Similar results arise from
the 2dF Galaxy Redshift Survey (2dFGRS; Colless et al. 2001), in
which, at a similar median redshift, passive galaxies show a
correlation length and slope of
![]() as opposed to
as opposed to
![]() measured for star forming galaxies (Madgwick et al. 2003).
measured for star forming galaxies (Madgwick et al. 2003).
At cosmologically significant distances, deep surveys on sky patches
of less than 1 deg2, complemented by large spectroscopic campaigns,
are measuring the clustering of high redshift objects with reasonable
accuracy. The separation between the clustering properties of star
forming and passively evolving galaxies seems to be well established
even at redshifts around 1. In the DEEP2 Galaxy Redshift Survey, Coil
et al. (2004) found that ![]() galaxies with absorption line
spectra have a correlation length significantly larger than
emission-line galaxies at the same redshift. A similar result has been
found in the VIMOS-VLT Deep Survey (VVDS) by Meneux et al. (2006),
who measured a correlation length that was larger for red galaxies
than for blue galaxies at
galaxies with absorption line
spectra have a correlation length significantly larger than
emission-line galaxies at the same redshift. A similar result has been
found in the VIMOS-VLT Deep Survey (VVDS) by Meneux et al. (2006),
who measured a correlation length that was larger for red galaxies
than for blue galaxies at ![]() .
.
Porciani & Giavalisco (2002) and Adelberger et al. (2005) measured
the clustering properties of star forming galaxies selected by the
Lyman-break technique between redshifts of 1.7 and 3 (see also Hamana
et al. 2004; Ouchi et al. 2005; and Lee et al. 2006, for Lyman break
galaxies selected at
![]() ). The measured comoving correlation
length of 4.0-4.5 h-1 Mpc for these high redshift objects is
expected to increase with time and suggests that they will evolve into
moderate-luminosity, elliptical galaxies by z=0 (Adelberger et al. 2005).
). The measured comoving correlation
length of 4.0-4.5 h-1 Mpc for these high redshift objects is
expected to increase with time and suggests that they will evolve into
moderate-luminosity, elliptical galaxies by z=0 (Adelberger et al. 2005).
While all of the above described samples are based on optical
selection, star formation in galaxies can be efficiently traced by
mid-infrared observations. The star formation rate (SFR), particularly
the dust obscured component, is indeed directly correlated to the
mid-IR luminosity, which is in turn a robust proxy for the total
(8-1000 ![]() m) IR luminosity (e.g., Spinoglio et al. 1995; Chary &
Elbaz 2001; Forster-Schreiber et al. 2004). This has been
demonstrated in the present-day Universe, but seems to hold at least
up to
m) IR luminosity (e.g., Spinoglio et al. 1995; Chary &
Elbaz 2001; Forster-Schreiber et al. 2004). This has been
demonstrated in the present-day Universe, but seems to hold at least
up to ![]() ,
where the bulk of star-formation occurs in
dust-obscured regions. Indeed, the deepest existing radio data have
shown that
,
where the bulk of star-formation occurs in
dust-obscured regions. Indeed, the deepest existing radio data have
shown that
![]() values determined from the mid-IR luminosity of
galaxies at
values determined from the mid-IR luminosity of
galaxies at ![]() are consistent with those derived using the radio
to IR luminosity correlation (Elbaz et al. 2002; Appleton et al. 2004).
are consistent with those derived using the radio
to IR luminosity correlation (Elbaz et al. 2002; Appleton et al. 2004).
Early work by the Infrared Astronomical Satellite (IRAS) showed that
the correlation length of nearby (median ![]() )
mid-IR bright
galaxies (
)
mid-IR bright
galaxies (
![]() Jy) is about 4 h-1 Mpc (Fisher et al. 1994), in agreement with the values measured for local star
forming objects by the SDSS and 2dFGRS. More recently, an attempt to
measure the clustering properties of mid-IR selected sources at
fainter flux densities has been made (D'Elia et al. 2005). Based on a
small sample of galaxies detected by the Infrared Space Observatory
(ISO) with
Jy) is about 4 h-1 Mpc (Fisher et al. 1994), in agreement with the values measured for local star
forming objects by the SDSS and 2dFGRS. More recently, an attempt to
measure the clustering properties of mid-IR selected sources at
fainter flux densities has been made (D'Elia et al. 2005). Based on a
small sample of galaxies detected by the Infrared Space Observatory
(ISO) with
![]() mJy, D'Elia et al. found that the
clustering level measured for these
mJy, D'Elia et al. found that the
clustering level measured for these ![]() galaxies is similar to
that measured by IRAS for more local sources.
galaxies is similar to
that measured by IRAS for more local sources.
The Spitzer Space Telescope (Werner et al. 2004), with its
unprecedented sensitivity at mid-IR and far-IR wavelengths, is
enabling further progress to be made. Deep surveys at 24 ![]() m are
being carried out in different regions of the sky (see, e.g., Papovich
et al. 2004), with the deepest ones being performed in the two GOODS
fields down to
m are
being carried out in different regions of the sky (see, e.g., Papovich
et al. 2004), with the deepest ones being performed in the two GOODS
fields down to
![]() Jy (Chary et al., in
preparation). For the first time, this allows us to select field
galaxies based on their ongoing level of star formation activity at a
wavelength where dust corrections are negligible. This is a more
physically motivated selection than those based on qualitative galaxy
properties like color bi-modality. It thus provides greater insight
into the nature of galaxy and star formation in the distant Universe
and a more straightforward comparison to galaxy formation models. Our
goal is to investigate the spatial distribution of
Jy (Chary et al., in
preparation). For the first time, this allows us to select field
galaxies based on their ongoing level of star formation activity at a
wavelength where dust corrections are negligible. This is a more
physically motivated selection than those based on qualitative galaxy
properties like color bi-modality. It thus provides greater insight
into the nature of galaxy and star formation in the distant Universe
and a more straightforward comparison to galaxy formation models. Our
goal is to investigate the spatial distribution of ![]() star
forming galaxies, and assess the relation between environment and
star-formation rate. By constraining the nature of the descendants of
star forming galaxies at
star
forming galaxies, and assess the relation between environment and
star-formation rate. By constraining the nature of the descendants of
star forming galaxies at ![]() ,
we provide insight into the
nature of downsizing of galaxy formation, a well established pattern
for galaxy evolution which implies that star formation is taking place
preferentially in more massive galaxies at higher redshifts (e.g.,
Cowie et al. 1996). A tight correlation between galaxy mass and
star-formation rate has been discovered, with slope close to unity.
This correlation has been shown to exist both in the local Universe as
well as at
,
we provide insight into the
nature of downsizing of galaxy formation, a well established pattern
for galaxy evolution which implies that star formation is taking place
preferentially in more massive galaxies at higher redshifts (e.g.,
Cowie et al. 1996). A tight correlation between galaxy mass and
star-formation rate has been discovered, with slope close to unity.
This correlation has been shown to exist both in the local Universe as
well as at ![]() (Noeske et al. 2007; Elbaz et al. 2007) with
tentative evidence that it may be valid even at
(Noeske et al. 2007; Elbaz et al. 2007) with
tentative evidence that it may be valid even at ![]() (Daddi et al. 2007a). As more massive galaxies are on average hosted in more
massive halos, we expect to find a direct correlation between
clustering strength and star formation rate in the distant Universe.
(Daddi et al. 2007a). As more massive galaxies are on average hosted in more
massive halos, we expect to find a direct correlation between
clustering strength and star formation rate in the distant Universe.
Given the large (5-6 arcsec FWHM) resolution of the MIPS instrument
(Multiband Imaging Photometer for Spitzer; Rieke et al. 2004)
confusion problems due to blending are severe at the faintest flux
densities. This makes a proper measure of the angular correlation
function of faint MIPS sources difficult, leaving the 3D correlation
function as the most viable method for estimating their clustering
properties. In this paper, we measure the spatial clustering of 24 ![]() m selected sources in the two GOODS fields by means of the
projected correlation function
m selected sources in the two GOODS fields by means of the
projected correlation function
![]() .
Blending problems at short
scales are completely overcome in this case, as angular clustering
terms are negligible as discussed later in the paper.
.
Blending problems at short
scales are completely overcome in this case, as angular clustering
terms are negligible as discussed later in the paper.
The paper is organized as follows: in Sect. 2 we describe the data sets and the selection criteria adopted to define the samples used in the clustering analysis. In Sect. 3 we present the methods utilized to estimate the correlation function. In Sect. 4 several safety checks are performed to validate the adopted techniques. Simulations are also run to estimate errors on our measurements due to cosmic variance. The results of our analysis are presented in Sect. 5. In Sect. 6 the clustering measurements are discussed, interpreted and compared to estimates from optical surveys. The conclusions are presented in Sect. 7.
Throughout this paper, a flat cosmology with
![]() and
and
![]() is assumed. Unless otherwise stated, we refer
to comoving distances in units of h-1 Mpc, where
is assumed. Unless otherwise stated, we refer
to comoving distances in units of h-1 Mpc, where
![]() km s-1 Mpc-1. Luminosities are calculated using h=0.7.
km s-1 Mpc-1. Luminosities are calculated using h=0.7.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{7506f01.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img56.gif) |
Figure 1:
Spectroscopic completeness down to
|
| Open with DEXTER | |
The GOODS-South and GOODS-North fields, each covering about
![]() arcmin, have been observed by Spitzer as part of
the Great Observatories Origins Deep Survey Legacy Program (Dickinson
et al. 2007, in preparation). Deep 24
arcmin, have been observed by Spitzer as part of
the Great Observatories Origins Deep Survey Legacy Program (Dickinson
et al. 2007, in preparation). Deep 24 ![]() m observations with MIPS
were carried out down to sensitivities of
m observations with MIPS
were carried out down to sensitivities of ![]()
![]() Jy (
Jy (![]()
![]() )
in both fields (Chary et al., in preparation). Source
catalogs at shorter wavelengths (Dickinson et al., in preparation)
based on the Infrared Array Camera (IRAC; Fazio et al. 2004), were
used as prior positions in order to improve source deblending and
identify unique counterparts. Spectroscopic redshifts have been
collected for about 60% of the MIPS sources with
)
in both fields (Chary et al., in preparation). Source
catalogs at shorter wavelengths (Dickinson et al., in preparation)
based on the Infrared Array Camera (IRAC; Fazio et al. 2004), were
used as prior positions in order to improve source deblending and
identify unique counterparts. Spectroscopic redshifts have been
collected for about 60% of the MIPS sources with
![]() mag
from a compilation of all the different follow-up spectroscopy
programs carried out in the GOODS fields. In particular, for the
GOODS-S field, we use the spectroscopic redshifts made available by Le
Fevre et al. (2004), Mignoli et al. (2005), Vanzella et al. (2005,
2006). Redshifts in GOODS-N have been published in many papers over
the years. At the redshifts of interest in this paper, the largest
portion of the published redshifts can be found in Cohen et al. (2000), Wirth et al. (2004), and Cowie et al. (2004). We supplement
these with additional redshifts for 24
mag
from a compilation of all the different follow-up spectroscopy
programs carried out in the GOODS fields. In particular, for the
GOODS-S field, we use the spectroscopic redshifts made available by Le
Fevre et al. (2004), Mignoli et al. (2005), Vanzella et al. (2005,
2006). Redshifts in GOODS-N have been published in many papers over
the years. At the redshifts of interest in this paper, the largest
portion of the published redshifts can be found in Cohen et al. (2000), Wirth et al. (2004), and Cowie et al. (2004). We supplement
these with additional redshifts for 24 ![]() m selected sources from
Stern et al. (in preparation). The spectroscopic completeness down to
m selected sources from
Stern et al. (in preparation). The spectroscopic completeness down to
![]() mag is shown in Fig. 1. In both fields the
completeness level decreases towards fainter magnitudes, but in
GOODS-N it is systematically higher than than in GOODS-S. For sources
with
mag is shown in Fig. 1. In both fields the
completeness level decreases towards fainter magnitudes, but in
GOODS-N it is systematically higher than than in GOODS-S. For sources
with
![]() mag the completeness level in GOODS-N is 65%,
compared to 50% in GOODS-S. Only sources at 0.1<z<1.4 were
considered in this work. The z<1.4 limit is imposed in order to
remain in a redshift range where the spectroscopic sampling is
highest, and where the observed 24
mag the completeness level in GOODS-N is 65%,
compared to 50% in GOODS-S. Only sources at 0.1<z<1.4 were
considered in this work. The z<1.4 limit is imposed in order to
remain in a redshift range where the spectroscopic sampling is
highest, and where the observed 24 ![]() m flux density can be used as
an accurate tracer of the total IR luminosity of galaxies. Although
m flux density can be used as
an accurate tracer of the total IR luminosity of galaxies. Although
![]() m observations can be used to obtain reasonable measurements of
star formation activity averaged over the galaxy population at even
higher redshifts (e.g., Daddi et al. 2005), individual sources with
anomalous properties may show significant errors in their derived
m observations can be used to obtain reasonable measurements of
star formation activity averaged over the galaxy population at even
higher redshifts (e.g., Daddi et al. 2005), individual sources with
anomalous properties may show significant errors in their derived
![]() (Daddi et al. 2007a; Papovich et al. 2007). Redshift quality
flag information is available for most of the spectroscopic surveys
done in GOODS-S, but is missing for some of the surveys in GOODS-N. In
GOODS-S we considered only objects with high quality flags. In GOODS-N
we have excluded some galaxies (<1% of the total sample) which
appear to have incorrect spectroscopic redshifts, based on the shape
of their spectral energy distribution and photometric
redshifts. Furthermore, we have limited our analysis to sources with
(Daddi et al. 2007a; Papovich et al. 2007). Redshift quality
flag information is available for most of the spectroscopic surveys
done in GOODS-S, but is missing for some of the surveys in GOODS-N. In
GOODS-S we considered only objects with high quality flags. In GOODS-N
we have excluded some galaxies (<1% of the total sample) which
appear to have incorrect spectroscopic redshifts, based on the shape
of their spectral energy distribution and photometric
redshifts. Furthermore, we have limited our analysis to sources with
![]() Jy, for which the flux density estimate is reliable and
source confusion is well understood (Chary 2006). About 20% of the
sources fall below this limit and are therefore excluded from our
clustering analysis. In total, 558 objects in GOODS-S and 875 objects
in GOODS-N are found to satisfy these selection criteria (including
AGN, see later). After accounting for spectroscopic incompleteness,
the number of
Jy, for which the flux density estimate is reliable and
source confusion is well understood (Chary 2006). About 20% of the
sources fall below this limit and are therefore excluded from our
clustering analysis. In total, 558 objects in GOODS-S and 875 objects
in GOODS-N are found to satisfy these selection criteria (including
AGN, see later). After accounting for spectroscopic incompleteness,
the number of
![]() Jy sources in GOODS-S and GOODS-N differ
by
Jy sources in GOODS-S and GOODS-N differ
by ![]()
![]() .
As shown in Sect. 5.3, this is consistent
with being due to cosmic variance.
.
As shown in Sect. 5.3, this is consistent
with being due to cosmic variance.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f02.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img62.gif) |
Figure 2:
24 |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f03.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img63.gif) |
Figure 3:
24 |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{7506f04.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img64.gif) |
Figure 4:
|
| Open with DEXTER | |
In Figs. 2 and 3 the 24 ![]() m flux densities of
sources in the two GOODS fields are plotted against their spectroscopic
redshifts and
m flux densities of
sources in the two GOODS fields are plotted against their spectroscopic
redshifts and
![]() magnitudes, respectively. Fainter 24
magnitudes, respectively. Fainter 24 ![]() m
sources have on average fainter optical counterparts and tend to be
at higher redshifts, although the redshift dependence of the
average 24
m
sources have on average fainter optical counterparts and tend to be
at higher redshifts, although the redshift dependence of the
average 24 ![]() m flux density appears rather weak. Several redshift
structures can be immediately identified, which are also traced by
sources selected at other wavelengths (e.g., Cohen et al. 1996;
Gilli et al. 2003; Barger et al. 2003). The 24
m flux density appears rather weak. Several redshift
structures can be immediately identified, which are also traced by
sources selected at other wavelengths (e.g., Cohen et al. 1996;
Gilli et al. 2003; Barger et al. 2003). The 24 ![]() m flux density and
redshift distribution in the two fields are similar (see also
Fig. 5). The median 24
m flux density and
redshift distribution in the two fields are similar (see also
Fig. 5). The median 24 ![]() m flux density, optical magnitude
and redshift for the considered samples are
m flux density, optical magnitude
and redshift for the considered samples are
![]() Jy,
Jy,
![]() mag and
mag and ![]() ,
respectively. We
compute the total (8-1000
,
respectively. We
compute the total (8-1000 ![]() m) IR luminosity
m) IR luminosity
![]() from the observed 24
from the observed 24 ![]() m flux density, assuming the
luminosity-dependent model templates of Chary & Elbaz (2001).
The total IR luminosity
provides a measure of the star formation rate in the galaxy
using the relation
m flux density, assuming the
luminosity-dependent model templates of Chary & Elbaz (2001).
The total IR luminosity
provides a measure of the star formation rate in the galaxy
using the relation
![]() yr-1(Kennicutt et al. 1998). We note that if more recent estimates of the
stellar initial mass function (IMF) are adopted (Kroupa 2001; Chabrier
2003), the same
yr-1(Kennicutt et al. 1998). We note that if more recent estimates of the
stellar initial mass function (IMF) are adopted (Kroupa 2001; Chabrier
2003), the same
![]() systematically converts into a
systematically converts into a ![]() 30%
lower SFR.
The exact conversion rate does not have an important effect on our
results. The
30%
lower SFR.
The exact conversion rate does not have an important effect on our
results. The
![]() (SFR) versus redshift plot for the galaxy
sample considered here
is shown in Fig. 4, along with the
(SFR) versus redshift plot for the galaxy
sample considered here
is shown in Fig. 4, along with the
![]() cut introduced at each redshift by the
cut introduced at each redshift by the
![]() Jy
selection. The luminosity distribution is similar in the two
fields. The median luminosity and star formation rate are
Jy
selection. The luminosity distribution is similar in the two
fields. The median luminosity and star formation rate are
![]() and 7.6
and 7.6 ![]() yr-1, respectively.
About 90% of the objects in the two fields have
yr-1, respectively.
About 90% of the objects in the two fields have
![]() while about 30% have
while about 30% have
![]() .
The latter are classified as Luminous Infrared
Galaxies (LIRGs), and are forming stars at an average
rate of
.
The latter are classified as Luminous Infrared
Galaxies (LIRGs), and are forming stars at an average
rate of ![]() 35
35 ![]() yr-1.
yr-1.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f05a.ps}\hspace*{4mm}
\includegraphics[width=8cm,clip]{7506f05b.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img73.gif) |
Figure 5:
Redshift distribution for MIPS sources with
|
| Open with DEXTER | |
We note that the SFR estimated from the
![]() values may
be a lower limit to the true galaxy SFR since
it excludes the unobscured star-formation traced by the observed
UV emission. We therefore considered B-band
data from the Advanced Camera for Surveys (ACS) onboard the Hubble
Space Telescope (HST), which traces the rest frame UV flux for galaxies
at z>0.5, i.e., for the majority of the sources in our sample. We
found that the SFR increases by only 4% on average when including
the ACS data. We also note that the fraction of galaxies for which the
SFR may have been underestimated significantly (e.g., by a factor of 1.5-2), is less that 4%.
Due to the fact that the UV flux may have a contribution from
old, evolved stars, these correction factors are upper limits.
Our estimates appear to be
in good agreement with those of Bell et al. (2005), who derive an
average UV contribution of 5-10% to the global (mid-IR + UV) SFR of
values may
be a lower limit to the true galaxy SFR since
it excludes the unobscured star-formation traced by the observed
UV emission. We therefore considered B-band
data from the Advanced Camera for Surveys (ACS) onboard the Hubble
Space Telescope (HST), which traces the rest frame UV flux for galaxies
at z>0.5, i.e., for the majority of the sources in our sample. We
found that the SFR increases by only 4% on average when including
the ACS data. We also note that the fraction of galaxies for which the
SFR may have been underestimated significantly (e.g., by a factor of 1.5-2), is less that 4%.
Due to the fact that the UV flux may have a contribution from
old, evolved stars, these correction factors are upper limits.
Our estimates appear to be
in good agreement with those of Bell et al. (2005), who derive an
average UV contribution of 5-10% to the global (mid-IR + UV) SFR of
![]() star forming galaxies observed by Spitzer. Furthermore,
since the UV correction decreases with increasing SFR, it becomes
completely negligible for LIRGs. To summarize, UV corrections to the
SFR do not have a significant impact on our results and are
therefore neglected in the following analysis.
star forming galaxies observed by Spitzer. Furthermore,
since the UV correction decreases with increasing SFR, it becomes
completely negligible for LIRGs. To summarize, UV corrections to the
SFR do not have a significant impact on our results and are
therefore neglected in the following analysis.
While most of these mid-IR selected sources are expected to be star
forming galaxies (elliptical galaxies should be virtually absent from
mid-IR selected samples), a significant fraction of sources may be
active galactic nuclei (AGN), in which the radiation absorbed by
circumnuclear material is re-emitted in the IR regime. Based on the
X-ray properties of sources, we therefore tried to eliminate AGN
interlopers. Both fields have been observed by Chandra with
extremely deep (1-2 Msec) exposures (Giacconi et al. 2002; Alexander
et al. 2003). Using an AGN classification similar to that adopted in
Gilli et al. (2005), we flagged as AGN those sources with either
observed 0.5-10 keV luminosities above 1042 erg s-1 or with
a column density above
![]() cm-2. The column density was
estimated by assuming an intrinsic AGN template with spectral index of 0.7 and absorbing it at the source redshift to reproduce the observed
hard-to-soft X-ray flux ratio. About 8% of the sources were removed
from the samples using this AGN classification. We nonetheless
verified that, due to the small fraction of AGN candidates, our
results are insensitive to the methodology adopted to remove
AGN. Moreover, our conclusions do not vary significant even if AGN are
not excluded from the sample.
cm-2. The column density was
estimated by assuming an intrinsic AGN template with spectral index of 0.7 and absorbing it at the source redshift to reproduce the observed
hard-to-soft X-ray flux ratio. About 8% of the sources were removed
from the samples using this AGN classification. We nonetheless
verified that, due to the small fraction of AGN candidates, our
results are insensitive to the methodology adopted to remove
AGN. Moreover, our conclusions do not vary significant even if AGN are
not excluded from the sample.
After the AGN are removed, we are left with samples of 495 and 811 galaxies, in GOODS-South and North, respectively. One may wonder if
our samples are significantly contaminated by AGN which went
undetected in the X-rays. Indeed, Alonso-Herrero et al. (2006) in
GOODS-S and Donley et al. (2007) in GOODS-N, respectively, have
identified a large population of IR luminous galaxies showing
power-law emission in the IRAC
![]() m bands. The power-law
emission is thought to be due to hot dust in the vicinity of the
AGN. Yet, half of these sources do not have an X-ray counterpart. We
verified that none of these power-law AGN are present in our
samples. We note that the Donley et al. (2007) and Alonso-Herrero et al. (2006) samples are based on shallow
m bands. The power-law
emission is thought to be due to hot dust in the vicinity of the
AGN. Yet, half of these sources do not have an X-ray counterpart. We
verified that none of these power-law AGN are present in our
samples. We note that the Donley et al. (2007) and Alonso-Herrero et al. (2006) samples are based on shallow ![]() m data, span a broader
redshift range and primarily include objects with photometric
redshifts. In contrast, our galaxies sample much fainter 24
m data, span a broader
redshift range and primarily include objects with photometric
redshifts. In contrast, our galaxies sample much fainter 24 ![]() m
flux densities and have spectroscopic redshifts of z<1.4. We are in
the process of defining IR-based AGN samples in our deep MIPS
catalogs. Preliminary analysis suggests that
m
flux densities and have spectroscopic redshifts of z<1.4. We are in
the process of defining IR-based AGN samples in our deep MIPS
catalogs. Preliminary analysis suggests that ![]()
![]() of
sources might be flagged as additional AGN candidates and in principle
should be removed from our samples. Their impact on the clustering
measurements presented in this work is unlikely to be significant and
will be discussed elsewhere when the AGN catalogs are finalized. Very
recently, Daddi et al. (2007b) have shown that a population of highly
obscured AGN, which are both undetected in the X-rays and do not show
a power-law continuum in the IRAC bands, hide in about 20-30% of IR luminous (
of
sources might be flagged as additional AGN candidates and in principle
should be removed from our samples. Their impact on the clustering
measurements presented in this work is unlikely to be significant and
will be discussed elsewhere when the AGN catalogs are finalized. Very
recently, Daddi et al. (2007b) have shown that a population of highly
obscured AGN, which are both undetected in the X-rays and do not show
a power-law continuum in the IRAC bands, hide in about 20-30% of IR luminous (
![]() )
galaxies at
)
galaxies at ![]() ,
providing a significant contribution to their 24
,
providing a significant contribution to their 24 ![]() m emission (see
also Fiore et al. 2007).
Given the relatively low IR luminosities (
m emission (see
also Fiore et al. 2007).
Given the relatively low IR luminosities (
![]() )
and the longer mid-IR rest-frame
wavelengths probed here at
)
and the longer mid-IR rest-frame
wavelengths probed here at ![]() ,
we expect that the effect of
contamination from
an obscured AGN population will be less important for our
study.
,
we expect that the effect of
contamination from
an obscured AGN population will be less important for our
study.
It should also be noted that we are measuring the clustering
properties of mid-IR selected galaxies over a broad redshift range
from z=0.1 to z=1.4. Star forming galaxies are undergoing
rapid cosmological evolution in luminosity/density over this
redshift range (e.g., Le Floc'h et al. 2005), and the clustering strength is also likely to
evolve. Although most of the clustering signal measured in
this work is due to galaxy pairs at ![]() ,
our measurements
could be
returning a value for the clustering strength that is
an average between 0<z<1.4. Thus, our analysis is not
identical to that obtained by considering an ideally
large galaxy sample in a narrow redshift interval around
,
our measurements
could be
returning a value for the clustering strength that is
an average between 0<z<1.4. Thus, our analysis is not
identical to that obtained by considering an ideally
large galaxy sample in a narrow redshift interval around ![]() .
This caveat should be borne in mind when comparing our results
with those obtained from other surveys.
.
This caveat should be borne in mind when comparing our results
with those obtained from other surveys.
To eliminate the distortions introduced by peculiar velocities and
redshift errors, which affect the computation of the
source clustering in redshift space, we resort to the projected
correlation function, defined as in Davis & Peebles (1983):
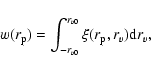 |
(1) |
If the real space correlation function can be approximated by a
power law of the form
![]() and
and
![]() then
the following relation holds (Peebles 1980):
then
the following relation holds (Peebles 1980):
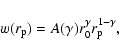 |
(2) |
To estimate the correlation function
![]() we used the Landy
& Szalay (1993) estimator, which has been shown to have a nearly
Poissonian variance and which appears to
outperform other popular estimators (e.g.,
see Kerscher et al. 2000):
we used the Landy
& Szalay (1993) estimator, which has been shown to have a nearly
Poissonian variance and which appears to
outperform other popular estimators (e.g.,
see Kerscher et al. 2000):
![\begin{displaymath}\xi(r_{\rm p}, r_v)=\frac{[DD]-2[DR]+[RR]}{[RR]}\cdot
\end{displaymath}](/articles/aa/full/2007/43/aa7506-07/img90.gif) |
(3) |
![\begin{displaymath}[DD]\equiv DD(r_{\rm p}, r_v)\frac{n_{\rm r}(n_{\rm r}-1)}{n_{\rm d}(n_{\rm d}-1)}
\end{displaymath}](/articles/aa/full/2007/43/aa7506-07/img91.gif) |
(4) |
![\begin{displaymath}[DR]\equiv DR(r_{\rm p}, r_v)\frac{(n_{\rm r}-1)}{2 n_{\rm d}}
\end{displaymath}](/articles/aa/full/2007/43/aa7506-07/img92.gif) |
(5) |
![\begin{displaymath}[RR]\equiv RR(r_{\rm p}, r_v),
\end{displaymath}](/articles/aa/full/2007/43/aa7506-07/img93.gif) |
(6) |
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f06a.ps}\hspace*{4mm}
\includegraphics[width=8cm,clip]{7506f06b.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img98.gif) |
Figure 6:
Distribution of 24 |
| Open with DEXTER | |
We note that in Eqs. (4) and (5), ![]() is the number of sources
observed in each GOODS field separately. Ideally, instead of using
the observed number of sources, which may produce an overestimate
(underestimate) of the clustering amplitude in under-dense
(over-dense) regions,
one should use
the true mean source number, which is unknown.
In principle, averaging the densities of the
GOODS-N and GOODS-S fields would give a better approximation to the
mean source density. However, because of the different spectroscopic
completeness in the two GOODS fields, the estimate of the average
density in a given redshift range may be non-trivial. One possibility
is to assume that the total number of sources in the redshift range
considered in this work (
z=0.1-1.4) is 20% larger in GOODS-N than
in GOODS-S. This would be comparable to
the difference observed in the total surface
density of MIPS sources (after accounting for the 65% and 50% total
spectroscopic completeness of GOODS-N and GOODS-S,
respectively). However, since the spectroscopic completeness is
a function of redshift and optical magnitude, and the completeness
curves are different between the two fields (see Fig. 1), this may not
be the case. At any rate, we have verified that, assuming that the
z=0.1-1.4 source density is 20% larger in GOODS-N than in GOODS-S,
the use of an averaged density value (i.e., increasing
is the number of sources
observed in each GOODS field separately. Ideally, instead of using
the observed number of sources, which may produce an overestimate
(underestimate) of the clustering amplitude in under-dense
(over-dense) regions,
one should use
the true mean source number, which is unknown.
In principle, averaging the densities of the
GOODS-N and GOODS-S fields would give a better approximation to the
mean source density. However, because of the different spectroscopic
completeness in the two GOODS fields, the estimate of the average
density in a given redshift range may be non-trivial. One possibility
is to assume that the total number of sources in the redshift range
considered in this work (
z=0.1-1.4) is 20% larger in GOODS-N than
in GOODS-S. This would be comparable to
the difference observed in the total surface
density of MIPS sources (after accounting for the 65% and 50% total
spectroscopic completeness of GOODS-N and GOODS-S,
respectively). However, since the spectroscopic completeness is
a function of redshift and optical magnitude, and the completeness
curves are different between the two fields (see Fig. 1), this may not
be the case. At any rate, we have verified that, assuming that the
z=0.1-1.4 source density is 20% larger in GOODS-N than in GOODS-S,
the use of an averaged density value (i.e., increasing ![]() by 10% in
GOODS-S and decreasing it by the same amount in GOODS-N) gives a
by 10% in
GOODS-S and decreasing it by the same amount in GOODS-N) gives a ![]()
![]() shorter (longer) correlation length in GOODS-S (GOODS-N) than
that estimated by using the density of each field separately. These
fluctuations are of the same order as produced by redshift structures
in our fields (see Sect. 5.1) and well within the cosmic variance
errors (Sect. 4). Therefore, they do not change the main
conclusions of the paper.
shorter (longer) correlation length in GOODS-S (GOODS-N) than
that estimated by using the density of each field separately. These
fluctuations are of the same order as produced by redshift structures
in our fields (see Sect. 5.1) and well within the cosmic variance
errors (Sect. 4). Therefore, they do not change the main
conclusions of the paper.
Since both the redshift and the coordinate
![]() distributions of the selected MIPS sources are potentially affected by
observational biases, special care has to be taken in creating the
sample of random sources. We adopted a procedure that has been shown
to work well for X-ray AGN selected in the same fields (see Gilli et al. 2005). The redshifts of the random sources were extracted from a
smoothed distribution of the real one, which should then include the
same observational biases. We assumed a Gaussian smoothing length
distributions of the selected MIPS sources are potentially affected by
observational biases, special care has to be taken in creating the
sample of random sources. We adopted a procedure that has been shown
to work well for X-ray AGN selected in the same fields (see Gilli et al. 2005). The redshifts of the random sources were extracted from a
smoothed distribution of the real one, which should then include the
same observational biases. We assumed a Gaussian smoothing length
![]() as a good compromise between smoothing
scales that are too small (which suffer from significant fluctuations due to the observed
redshift spikes) and scales that are too large (where on the contrary the
source density of the smoothed distribution at a given redshift might
not be a good estimate of the average observed value). For each of the
source subsamples considered in this work (see Table 1), we
smoothed the corresponding observed redshift distribution.
The observed and smoothed redshift distributions for the
as a good compromise between smoothing
scales that are too small (which suffer from significant fluctuations due to the observed
redshift spikes) and scales that are too large (where on the contrary the
source density of the smoothed distribution at a given redshift might
not be a good estimate of the average observed value). For each of the
source subsamples considered in this work (see Table 1), we
smoothed the corresponding observed redshift distribution.
The observed and smoothed redshift distributions for the
![]() Jy samples are shown in Fig. 5. Due to the
numerous redshift spikes observed, we did not try to measure the
correlation function in different redshift bins since this would be
extremely sensitive to the choice of bin boundaries. The
coordinates (
Jy samples are shown in Fig. 5. Due to the
numerous redshift spikes observed, we did not try to measure the
correlation function in different redshift bins since this would be
extremely sensitive to the choice of bin boundaries. The
coordinates (
![]() )
of the random sources were extracted
from the coordinate ensemble of the real sample in order to reproduce
the same uneven distribution on the plane of the sky. This procedure
will in principle, reduce the correlation signal, since it removes the
effects of angular clustering. However, as will be verified later,
in deep, pencil-beam surveys like GOODS, where the radial coordinate spans
a much broader distance than the transverse coordinate, most of the
signal is due to redshift clustering, while angular clustering
contributes at most a few percent. The distribution on the sky of
the real sample is shown in Fig. 6. Each random sample
is built to contain more than 10 000 sources.
)
of the random sources were extracted
from the coordinate ensemble of the real sample in order to reproduce
the same uneven distribution on the plane of the sky. This procedure
will in principle, reduce the correlation signal, since it removes the
effects of angular clustering. However, as will be verified later,
in deep, pencil-beam surveys like GOODS, where the radial coordinate spans
a much broader distance than the transverse coordinate, most of the
signal is due to redshift clustering, while angular clustering
contributes at most a few percent. The distribution on the sky of
the real sample is shown in Fig. 6. Each random sample
is built to contain more than 10 000 sources.
The source pairs were binned in intervals of
![]() ,
and
,
and
![]() was measured in each bin. The resulting data
points were then fit with a power law and the best fit parameters
was measured in each bin. The resulting data
points were then fit with a power law and the best fit parameters ![]() and r0 were determined via
and r0 were determined via ![]() minimization. Given
the small number of pairs which fall into certain bins (especially at the
smallest scales), we used the formulae of Gehrels (1986) to estimate
the
68% confidence interval (i.e.,
minimization. Given
the small number of pairs which fall into certain bins (especially at the
smallest scales), we used the formulae of Gehrels (1986) to estimate
the
68% confidence interval (i.e., ![]() errorbars in Gaussian statistics).
errorbars in Gaussian statistics).
It is well known that Poisson error bars underestimate the
uncertainties in the correlation function when source pairs are not
independent, which is the case for our sample. More importantly,
these uncertainties do not account for cosmic variance. In the next section we assess the
errors to be assigned to our best fit parameters by measuring
![]() on a series of simulated galaxy catalogs.
on a series of simulated galaxy catalogs.
A practical integration limit rv0 has to be chosen in Eq. (1) in
order to maximize the correlation signal. Indeed, one should avoid rv0 values which are too large since they
would mainly add noise to the
estimate of
![]() .
On the other hand, scales which are too small,
comparable to the redshift uncertainties and to the pairwise
velocity dispersion, should also be avoided since they would not
allow recovery of the entire signal. To search for the best
integration limit rv0, we measured
.
On the other hand, scales which are too small,
comparable to the redshift uncertainties and to the pairwise
velocity dispersion, should also be avoided since they would not
allow recovery of the entire signal. To search for the best
integration limit rv0, we measured
![]() and the corresponding
best fit r0 and
and the corresponding
best fit r0 and ![]() values for different rv0 values
ranging from 3 to
values for different rv0 values
ranging from 3 to
![]() Mpc. Since deviations from a simple
power law are sometimes observed (in particular for
Mpc. Since deviations from a simple
power law are sometimes observed (in particular for
![]() Mpc in GOODS-N), using the best fit correlation
length or clustering amplitude
Mpc in GOODS-N), using the best fit correlation
length or clustering amplitude
![]() as a measure of the
clustering level is incorrect. To overcome this problem, we chose to
quote the
as a measure of the
clustering level is incorrect. To overcome this problem, we chose to
quote the
![]() values on a representative scale, as a function of rv0.
We adopt
values on a representative scale, as a function of rv0.
We adopt
![]() h-1 Mpc as our representative scale,
since it is well within the considered
h-1 Mpc as our representative scale,
since it is well within the considered ![]() range, and is a separation
at which the projected correlation function,
range, and is a separation
at which the projected correlation function,
![]() Mpc),
is determined with good accuracy.
Mpc),
is determined with good accuracy.
In Fig. 7 we plot w(1 h-1 Mpc) as a function of the radial
integration limit rv0. We note that the signal amplitude keeps
increasing up to
![]() Mpc. For rv0 values
greater than
Mpc. For rv0 values
greater than
![]() Mpc, w(1 h-1 Mpc) does not vary
significantly. In the following, we therefore fix rv0 to 10 h-1 Mpc. Such a value for the integration limit is consistent
with what has been widely used in the literature (e.g., Carlberg et al. 2000).
Mpc, w(1 h-1 Mpc) does not vary
significantly. In the following, we therefore fix rv0 to 10 h-1 Mpc. Such a value for the integration limit is consistent
with what has been widely used in the literature (e.g., Carlberg et al. 2000).
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f07.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img116.gif) |
Figure 7:
Projected correlation function
|
| Open with DEXTER | |
We have checked to see if our method for generating the random sample can bias in some way the best fit correlation parameters that we measure. In particular, placing the random sources at the coordinates of the real sources completely removes the contribution of angular clustering to the total clustering signal, which could bias the measured correlation length to lower values. We quantify this effect by considering 428 sources within a radius of 4.8 arcmin from the center of GOODS-N, where the spectroscopic coverage is most complete. We measured the correlation function in two ways: first, by placing the random sources at the coordinates of the real sources, and second, by placing the random sources truly at random within this area. When using this second method, r0 increases by only 4%. Therefore, most of the clustering signal is provided by clustering along the radial direction, validating the adopted technique.
Another confirmation that this technique is not producing biased
measures comes from tests performed on the mock galaxy catalogs
based on the Millennium Simulation (Springel et al. 2005). These
catalogs have been obtained by modeling galaxy formation through
semi-analytic recipes applied to the pure dark matter N-body
simulations of the Millennium run. Physical processes like gas
cooling, star formation, supernovae and AGN feedback are taken into
account, which are described in detail in Croton et al. (2006) and De Lucia & Blaizot (2007). Here we considered the most recent work by
Kitzbichler & White (2007), who built a number of simulated light
cones for deep galaxy surveys over 2 deg2 sky fields. Each cone
contains about
![]() objects, for which a number of observable
and physical properties like redshift, optical and near-IR magnitude,
and star formation rate are listed. We considered one of these mock
catalogs and applied to the simulated galaxies the same selection
criteria adopted to define our data samples (see details in
Sect. 2). Here some assumptions have to be made, since
neither the
objects, for which a number of observable
and physical properties like redshift, optical and near-IR magnitude,
and star formation rate are listed. We considered one of these mock
catalogs and applied to the simulated galaxies the same selection
criteria adopted to define our data samples (see details in
Sect. 2). Here some assumptions have to be made, since
neither the
![]() magnitude, nor the 24
magnitude, nor the 24 ![]() m flux density are
directly available for the simulated sources. We used
m flux density are
directly available for the simulated sources. We used
![]() as
a proxy for
as
a proxy for
![]() ,
assuming the I-z color expected for star forming
galaxies at
,
assuming the I-z color expected for star forming
galaxies at ![]() (
(
![]() ,
Bruzual & Charlot
2003). Also, we converted the model star formation rate into IR
luminosity using the relation
,
Bruzual & Charlot
2003). Also, we converted the model star formation rate into IR
luminosity using the relation
![]() yr-1 and then, at each redshift,
considered only objects above the
yr-1 and then, at each redshift,
considered only objects above the
![]() threshold plotted in
Fig. 4, which corresponds to the
threshold plotted in
Fig. 4, which corresponds to the
![]() Jy threshold
used to define our data samples. The final mock sample contains about
50 000 objects, for which we computed the projected correlation
function over the same
Jy threshold
used to define our data samples. The final mock sample contains about
50 000 objects, for which we computed the projected correlation
function over the same ![]() range used for the GOODS data, first
placing the random control sources at the positions of the Millennium
sources and then placing the random control sources really at random
within the 2 deg2 field. No significant variations are observed
between the projected correlation function computed in the two cases,
suggesting again that the contribution of angular clustering is
negligible.
range used for the GOODS data, first
placing the random control sources at the positions of the Millennium
sources and then placing the random control sources really at random
within the 2 deg2 field. No significant variations are observed
between the projected correlation function computed in the two cases,
suggesting again that the contribution of angular clustering is
negligible.
As shown in Table 1, when the same selection criteria are applied
to the Millennium galaxies, these have on average different redshifts
and luminosities than real mid-IR selected galaxies. We note however
that our main goal is not to select mock galaxies with average
properties identical to the real ones, but investigate any difference
(e.g., in the average
![]() or SFR) between the data and the galaxy
formation models once real and mock galaxies have been selected in the
same way. This issue will be addressed in Sects. 5 and 6.
or SFR) between the data and the galaxy
formation models once real and mock galaxies have been selected in the
same way. This issue will be addressed in Sects. 5 and 6.
Table 1: Summary of the best fit clustering parameters. Poissonian uncertainties (only) are quoted here to allow comparison between different galaxy samples within the same GOODS field (see text). When comparing the results between the two fields, or when comparing the average properties of GOODS sources with those of other fields, cosmic variance uncertainties must also be included (see Table 2).
The mock catalogs from the Millennium simulation have also been used
to estimate the global errors on the best fit parameters r0 and
![]() ,
and to evaluate cosmic variance on the scale of the GOODS fields.
This has been achieved by extracting from one of the Millennium mock
catalogs samples of galaxies with progressively redder R-I colors
and in the same redshift range as the GOODS galaxies. The clustering
strength of the mock samples increases with redder R-I color threshold.
We then split the
,
and to evaluate cosmic variance on the scale of the GOODS fields.
This has been achieved by extracting from one of the Millennium mock
catalogs samples of galaxies with progressively redder R-I colors
and in the same redshift range as the GOODS galaxies. The clustering
strength of the mock samples increases with redder R-I color threshold.
We then split the
![]() deg field over which each sample is distributed
into 40 independent rectangles with the dimensions of a GOODS field
(i.e.,
deg field over which each sample is distributed
into 40 independent rectangles with the dimensions of a GOODS field
(i.e.,
![]() arcmin). For each color sample, we measured the
projected correlation function in each rectangle and computed the
rms of the r0 and
arcmin). For each color sample, we measured the
projected correlation function in each rectangle and computed the
rms of the r0 and ![]() distributions. After subtracting in
quadrature the (small) term due to Poissonian noise, we are left with
the intrinsic cosmic variance. This procedure allows us to compute the
appropriate variance for sources that are clustered similarly to the
GOODS galaxies considered. We found that, on GOODS-sized fields, the
fractional rms of the correlation length increases from 14% for
sources with
distributions. After subtracting in
quadrature the (small) term due to Poissonian noise, we are left with
the intrinsic cosmic variance. This procedure allows us to compute the
appropriate variance for sources that are clustered similarly to the
GOODS galaxies considered. We found that, on GOODS-sized fields, the
fractional rms of the correlation length increases from 14% for
sources with
![]() Mpc to 20% for sources with
Mpc to 20% for sources with
![]() Mpc, i.e., for populations as clustered as our total
and LIRGs samples, respectively (see the next sections). Using the
fractional rms values found with this method, the global errors
related to our samples can be easily estimated once the Poissonian
term is added back in quadrature. When averaging the properties of the
two GOODS fields and presenting the results for the combined GOODS-S
plus GOODS-N sample (see, e.g., Table 2), the variance estimated from
the simulations is divided by a factor of
Mpc, i.e., for populations as clustered as our total
and LIRGs samples, respectively (see the next sections). Using the
fractional rms values found with this method, the global errors
related to our samples can be easily estimated once the Poissonian
term is added back in quadrature. When averaging the properties of the
two GOODS fields and presenting the results for the combined GOODS-S
plus GOODS-N sample (see, e.g., Table 2), the variance estimated from
the simulations is divided by a factor of ![]() .
.
Table 2: Combined GOODS-S plus GOODS-N sample. The uncertainties take into account cosmic variance and have been computed as described in Sect. 4.
We note here that the error term due to cosmic variance should only be considered when comparing the clustering of the same population of sources across different fields, while it should be ignored when investigating clustering trends among different source sub-populations in the same field. Indeed, cosmic variance should increase or decrease the overall clustering amplitude over a given sky region, without modifying significantly the relative clustering between different galaxy subsamples (e.g., sources with different
The Millennium mock catalogs, in which large source samples can be
selected to minimize statistical noise, were also used to check if
limiting the integration radius rv0 to
![]() Mpc may
introduce a systematic bias on our clustering measurements. We
selected a population of mock galaxies with R-I>0.65, which shows a
clustering level similar to that of our MIPS sources (
Mpc may
introduce a systematic bias on our clustering measurements. We
selected a population of mock galaxies with R-I>0.65, which shows a
clustering level similar to that of our MIPS sources (
![]() Mpc), and measured
Mpc), and measured
![]() as a function of the
integration radius rv0. We found that for
as a function of the
integration radius rv0. We found that for
![]() Mpc
the clustering signal already saturates, and we verified that for
Mpc
the clustering signal already saturates, and we verified that for
![]() Mpc the r0 value is biased low by 5% with
respect to the full, saturated value. In the Millennium catalogs,
"purely cosmological'' redshifts are also available which are free
from peculiar velocities. We used these to compute the correlation
function in redshift space
Mpc the r0 value is biased low by 5% with
respect to the full, saturated value. In the Millennium catalogs,
"purely cosmological'' redshifts are also available which are free
from peculiar velocities. We used these to compute the correlation
function in redshift space ![]() for the same mock sample, which
should provide an unbiased measurement of r0. The resulting r0is in very good agreement with that measured from
for the same mock sample, which
should provide an unbiased measurement of r0. The resulting r0is in very good agreement with that measured from
![]() for
for
![]() Mpc and therefore confirms that when using
Mpc and therefore confirms that when using
![]() Mpc, r0 is biased low by 5%. We therefore
conclude that the r0 measurements presented in this work could
underestimate the real values by
Mpc, r0 is biased low by 5%. We therefore
conclude that the r0 measurements presented in this work could
underestimate the real values by ![]()
![]() .
At any rate, we do not
try to correct for this small systematic bias since it is found to be
well within the uncertainties due to cosmic variance.
.
At any rate, we do not
try to correct for this small systematic bias since it is found to be
well within the uncertainties due to cosmic variance.
Finally, one may wonder if the fitting procedure to
![]() adopted
in the previous section, in which a simple Poisson weighting of the
datapoints is used without considering the effects of cosmic variance,
may bias the best fit parameters r0 and
adopted
in the previous section, in which a simple Poisson weighting of the
datapoints is used without considering the effects of cosmic variance,
may bias the best fit parameters r0 and ![]() .
We verified that,
when attributing to each
.
We verified that,
when attributing to each
![]() datapoint the cosmic variance error
as a function of
datapoint the cosmic variance error
as a function of ![]() resulting from our simulations, the best fit
parameters r0 and
resulting from our simulations, the best fit
parameters r0 and ![]() are essentially unchanged. In the
GOODS-N field r0 and
are essentially unchanged. In the
GOODS-N field r0 and ![]() change only by
change only by ![]()
![]() .
In the
GOODS-S field the change is smaller than 1%. This is due to the fact
that the datapoints guiding the fits in both procedures are those with
.
In the
GOODS-S field the change is smaller than 1%. This is due to the fact
that the datapoints guiding the fits in both procedures are those with
![]() in the range
in the range
![]() Mpc, which have both smaller
Poisson errors and cosmic variance. In the following we will therefore
keep using the fitting procedure described in Sect. 3.
Mpc, which have both smaller
Poisson errors and cosmic variance. In the following we will therefore
keep using the fitting procedure described in Sect. 3.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{7506f08.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img181.gif) |
Figure 8:
Projected correlation function measured for the total
|
| Open with DEXTER | |
Having defined the analysis methods to estimate the galaxy projected correlation function and the global errors related to it, we are now in the position to measure the clustering properties of star forming galaxies in GOODS-S and GOODS-N and to compare them with those expected for mock galaxies from the Millennium simulation. Also, the clustering properties of different source subsamples, defined e.g., on the basis of their IR luminosity, can be readily investigated.
We first measured the projected correlation function for the total
GOODS-N and GOODS-S samples over the projected scale range
![]() Mpc. The results are shown in Fig. 8. In
both fields a clear clustering signal is measured, with very high
significance (>
Mpc. The results are shown in Fig. 8. In
both fields a clear clustering signal is measured, with very high
significance (>![]() ). The best fit parameters (r0,
). The best fit parameters (r0, ![]() )
are 4.25 h-1 Mpc, 1.51 in GOODS-S and 3.81 h-1 Mpc, 1.52 in
GOODS-N (see Table 1). The clustering amplitude therefore appears
about 10% larger in GOODS-S than in GOODS-N, confirming that the
GOODS-S field has more structure than the GOODS-N field, as already
noted from X-ray selected sources (Gilli et al. 2005). As shown in
Fig. 8, most of the excess signal in GOODS-S is produced at
projected scales in the range
)
are 4.25 h-1 Mpc, 1.51 in GOODS-S and 3.81 h-1 Mpc, 1.52 in
GOODS-N (see Table 1). The clustering amplitude therefore appears
about 10% larger in GOODS-S than in GOODS-N, confirming that the
GOODS-S field has more structure than the GOODS-N field, as already
noted from X-ray selected sources (Gilli et al. 2005). As shown in
Fig. 8, most of the excess signal in GOODS-S is produced at
projected scales in the range
![]() Mpc, while at
smaller and larger scales the signals measured in the two fields are
almost identical. A simple check was performed by computing the
projected correlation function in the GOODS-S field after removing
those sources within the two redshift spikes at z=0.67 and z=0.73,
which showed that most of the excess signal at
Mpc, while at
smaller and larger scales the signals measured in the two fields are
almost identical. A simple check was performed by computing the
projected correlation function in the GOODS-S field after removing
those sources within the two redshift spikes at z=0.67 and z=0.73,
which showed that most of the excess signal at
![]() Mpc
is indeed produced by these two structures. At any rate, as it will be
shown later, the difference among the two r0 values is fully
accounted for by cosmic variance.
Mpc
is indeed produced by these two structures. At any rate, as it will be
shown later, the difference among the two r0 values is fully
accounted for by cosmic variance.
It should be noted that in the
![]() Mpc scale range
considered here, the datapoints at the smallest and largest scales are
the least reliable. At small scales, e.g.,
Mpc scale range
considered here, the datapoints at the smallest and largest scales are
the least reliable. At small scales, e.g.,
![]() Mpc, source
pairs at high redshifts (z>1.2) have separations on the plane of the
sky comparable to the MIPS angular resolution at
Mpc, source
pairs at high redshifts (z>1.2) have separations on the plane of the
sky comparable to the MIPS angular resolution at ![]() m. Therefore
source blending may be an issue. Furthermore, other biases might be
introduced by the different angular selection functions of the many
spectroscopic campaigns from which our catalogs are built. Also, the
transverse size of the GOODS fields (19 arcmin diagonal) becomes
smaller than
m. Therefore
source blending may be an issue. Furthermore, other biases might be
introduced by the different angular selection functions of the many
spectroscopic campaigns from which our catalogs are built. Also, the
transverse size of the GOODS fields (19 arcmin diagonal) becomes
smaller than
![]() Mpc for pairs at z<0.5. The
corresponding
Mpc for pairs at z<0.5. The
corresponding
![]() measurements may thus be distorted with respect
to those at smaller scales because of the different redshift range
sampled. At any rate, the datapoints at the smallest and largest scales
have the largest errorbars and thus do not significantly affect the
overall estimate of the best fit parameters r0 and
measurements may thus be distorted with respect
to those at smaller scales because of the different redshift range
sampled. At any rate, the datapoints at the smallest and largest scales
have the largest errorbars and thus do not significantly affect the
overall estimate of the best fit parameters r0 and ![]() .
Indeed, when repeating the fits limiting the
.
Indeed, when repeating the fits limiting the ![]() range to
range to
![]() Mpc (or even
Mpc (or even
![]() Mpc), we obtained results
in agreement with the previous ones within the errors. In the
following computations we simply considered datapoints from
Mpc), we obtained results
in agreement with the previous ones within the errors. In the
following computations we simply considered datapoints from
![]() Mpc all the way down to the smallest scale from which
we get signal.
Mpc all the way down to the smallest scale from which
we get signal.
At scales
![]() Mpc, the correlation function data
points appear to lay above the best fit power law, which may indicate
that the intra-halo clustering term, i.e., the clustering term due to
galaxy pairs within the same dark matter halo, is emerging, as
has recently been seen in very large galaxy samples (e.g., SDSS,
Zehavi et al. 2004). However, because of the possible biases in
the
Mpc, the correlation function data
points appear to lay above the best fit power law, which may indicate
that the intra-halo clustering term, i.e., the clustering term due to
galaxy pairs within the same dark matter halo, is emerging, as
has recently been seen in very large galaxy samples (e.g., SDSS,
Zehavi et al. 2004). However, because of the possible biases in
the
![]() datapoints at smaller
datapoints at smaller ![]() scales mentioned above, the
observed small-scale excess should be considered with caution. We will
return to this in the Discussion.
scales mentioned above, the
observed small-scale excess should be considered with caution. We will
return to this in the Discussion.
The clustering behavior measured for the GOODS samples appears
markedly different from the expectations from the Millennium
simulation. As explained in the previous section, we computed the
projected correlation function for a sample of about 50 000 objects in
a mock galaxy catalog based on the Millennium run after applying the
same selection criteria used for the real data. The projected
correlation function for the mock catalog is also shown in
Fig. 8 and the best fit clustering parameters are quoted in
Table 1. Simulated mid-IR selected sources appear much less clustered
than real sources. The overall
![]() shape is also very different,
with a flattening below 0.8 h-1 Mpc, as opposed to the
steepening observed in GOODS, and a steepening above
shape is also very different,
with a flattening below 0.8 h-1 Mpc, as opposed to the
steepening observed in GOODS, and a steepening above
![]() h-1 Mpc, whereas the GOODS
h-1 Mpc, whereas the GOODS
![]() appears to have a constant
slope
appears to have a constant
slope![]() .
.
A similar discrepancy between the predictions based on the Millennium mock catalogs and the real data has also been reported by McCracken et al. (2007), who measured the angular correlation function (ACF) of I-band selected galaxies in the COSMOS field. While at bright magnitudes the COSMOS and the Millennium ACF are in good agreement, at fainter magnitudes, I>22 mag, Millennium sources are less clustered than the real COSMOS sources, with an overall correlation function shape very similar to the one we measured for Millennium. In the same work, McCracken et al. (2007) point out that the observed discrepancy cannot be accounted for by cosmic variance.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{7506f09.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img194.gif) |
Figure 9:
Best fit correlation length ( upper panel) and slope ( lower
panel) measured over 40 mock fields obtained by splitting the 2 deg2Millennium field into independent rectangles with the dimensions of a
GOODS field. The average r0 and |
| Open with DEXTER | |
The correlation lengths measured in the GOODS-S and GOODS-N fields then appear to be about 6 and 5 standard deviations, respectively, larger than the value measured from the Millennium catalog. It therefore seems unlikely that the stronger clustering measured in the GOODS fields be produced by cosmic variance. Several possible explanations for this discrepancy are investigated in the Discussion, as well as a series of caveats that have to be kept in mind when comparing models with observations.
It is interesting to note how the average correlation length and slope
measured on these
![]() arcmin mock subsamples are smaller than
those measured for the full 2 deg2 mock catalog and reported in
Table 1. One reason is that at large projected separations, where the
Millennium
arcmin mock subsamples are smaller than
those measured for the full 2 deg2 mock catalog and reported in
Table 1. One reason is that at large projected separations, where the
Millennium
![]() is steeper, the relative weight of the
is steeper, the relative weight of the
![]() datapoints is much higher in the full 2 deg2 field than in any
GOODS-sized field, since distant galaxy pairs are much better
sampled. As an example, over the whole
datapoints is much higher in the full 2 deg2 field than in any
GOODS-sized field, since distant galaxy pairs are much better
sampled. As an example, over the whole
![]() Mpc range
considered in this work, the number of pairs in a typical GOODS-sized
field is maximum in the range
Mpc range
considered in this work, the number of pairs in a typical GOODS-sized
field is maximum in the range
![]() Mpc, while in the full 2 deg2 field it steadily increases towards larger projected
separations. Another reason may be related to the effects of the
integral constraint (Groth & Peebles 1977), which bias the
measurements of the correlation function on finite size fields. We
estimate that the bias introduced by the integral constraint may
affect the
Mpc, while in the full 2 deg2 field it steadily increases towards larger projected
separations. Another reason may be related to the effects of the
integral constraint (Groth & Peebles 1977), which bias the
measurements of the correlation function on finite size fields. We
estimate that the bias introduced by the integral constraint may
affect the
![]() estimates by at most a few percent at the largest
scales probed here (above 5 h-1 Mpc).
estimates by at most a few percent at the largest
scales probed here (above 5 h-1 Mpc).
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f10a.ps}\hspace*{4mm}
\includegraphics[width=8cm,clip]{7506f10b.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img202.gif) |
Figure 10:
Left: projected correlation function for sources with
|
| Open with DEXTER | |
Recent observations have shown that, among star-forming galaxies at
any redshift, the star formation rate appears to be correlated with the
galaxy mass (Noeske et al. 2007; Elbaz et al. 2007; Daddi et al. 2007a). This is in agreement with the predictions from
semi-analytic models of structure formation (Finlator et al. 2006;
Kitzbichler & White 2007), though models also predict that this
correlation breaks down for the most massive galaxies. It is therefore
interesting to investigate if and how the clustering of galaxies
depends on the IR luminosity, which is a good proxy for the star
formation rate. We measured the projected correlation function for
sources with
![]() and for LIRGs
(
and for LIRGs
(
![]() ), as shown in Fig. 10. In both
fields we measure an increase of the clustering level with IR luminosity,
with r0 going from
), as shown in Fig. 10. In both
fields we measure an increase of the clustering level with IR luminosity,
with r0 going from ![]()
![]() Mpc for the whole
samples to
Mpc for the whole
samples to ![]()
![]() Mpc for the LIRGs (see also Tables 1 and 2). A
comparison between the correlation length of the different samples is
shown in Fig. 13 for the combined GOODS-S plus GOODS-N
fields. Because of the unavoidable degeneracy between luminosity and
redshift which characterizes any flux limited sample, LIRGs are on
average at higher redshifts than the full IR galaxy
population. However, as reported in Table 1, while the median
luminosity of LIRGs is about a factor of 5 larger than that of the
total sample, their median redshift of
Mpc for the LIRGs (see also Tables 1 and 2). A
comparison between the correlation length of the different samples is
shown in Fig. 13 for the combined GOODS-S plus GOODS-N
fields. Because of the unavoidable degeneracy between luminosity and
redshift which characterizes any flux limited sample, LIRGs are on
average at higher redshifts than the full IR galaxy
population. However, as reported in Table 1, while the median
luminosity of LIRGs is about a factor of 5 larger than that of the
total sample, their median redshift of ![]() is not dramatically
higher than that of the total sample, z=0.75. The modest difference in
the median redshift for the two samples suggests that luminosity, not
cosmic time, is the main factor contributing to the clustering dependence
that we observe. Because the dark matter clustering is smaller at higher
redshift, the difference would be even larger for the implied galaxy bias.
Since r0 for a given galaxy population is expected to increase with
time, i.e., towards lower redshifts (see Sect. 6.4), properly
accounting for the redshift differences between subsamples would actually
strengthen the detection of IR luminosity segregation of clustering.
is not dramatically
higher than that of the total sample, z=0.75. The modest difference in
the median redshift for the two samples suggests that luminosity, not
cosmic time, is the main factor contributing to the clustering dependence
that we observe. Because the dark matter clustering is smaller at higher
redshift, the difference would be even larger for the implied galaxy bias.
Since r0 for a given galaxy population is expected to increase with
time, i.e., towards lower redshifts (see Sect. 6.4), properly
accounting for the redshift differences between subsamples would actually
strengthen the detection of IR luminosity segregation of clustering.
In order to properly establish the statistical significance of the
trend of clustering versus luminosity, we also considered sources with
![]() (non-LIRGs), which therefore
constitute a source sample disjoint from the LIRGs (see Table 1). The
difference between the clustering correlation length of LIRGs and
non-LIRGs is about
(non-LIRGs), which therefore
constitute a source sample disjoint from the LIRGs (see Table 1). The
difference between the clustering correlation length of LIRGs and
non-LIRGs is about ![]() and
and ![]() significant in GOODS-S and
GOODS-N, respectively. As explained in Sect. 4, only the Poissonian
errorbars quoted in Table 1 have been considered for this estimate.
However, since the redshift distributions of the LIRGs and
non-LIRGs samples are rather different (e.g., the median redshift for
LIRGs is
significant in GOODS-S and
GOODS-N, respectively. As explained in Sect. 4, only the Poissonian
errorbars quoted in Table 1 have been considered for this estimate.
However, since the redshift distributions of the LIRGs and
non-LIRGs samples are rather different (e.g., the median redshift for
LIRGs is
![]() ,
while for non-LIRGs it is
,
while for non-LIRGs it is
![]() ;
see
Table 1), this evidence must be investigated further since the two
populations might not be tracing the same large scale structures. We
have therefore restricted our analysis to the redshift range
z=0.5-1.0, which allows us to compare LIRGs and non-LIRGs at similar
median redshifts (see Table 1). Figures 11 and 12 show the redshift distributions and the projected
correlation functions
;
see
Table 1), this evidence must be investigated further since the two
populations might not be tracing the same large scale structures. We
have therefore restricted our analysis to the redshift range
z=0.5-1.0, which allows us to compare LIRGs and non-LIRGs at similar
median redshifts (see Table 1). Figures 11 and 12 show the redshift distributions and the projected
correlation functions
![]() measured for the
z=0.5-1.0 LIRGs and
non-LIRGs in the GOODS-S and GOODS-N field, respectively. Because of
the limited source statistics, we used larger
measured for the
z=0.5-1.0 LIRGs and
non-LIRGs in the GOODS-S and GOODS-N field, respectively. Because of
the limited source statistics, we used larger ![]() bins
(
bins
(
![]() )
than those previously adopted, and limit
our analysis to the
)
than those previously adopted, and limit
our analysis to the
![]() Mpc range, where the
Mpc range, where the
![]() measure is more robust. We found that the significance of stronger
clustering of LIRGs decreases slightly, to
measure is more robust. We found that the significance of stronger
clustering of LIRGs decreases slightly, to ![]()
![]() ,
when performing
this more appropriate comparison at similar median redshifts. Although the
measured correlation lengths are quite sensitive to the choice of the
redshift bin boundaries because of the spiky nature of the observed
redshift distributions, we note that we systematically measure larger correlation
lengths for LIRGs than for non-LIRGs, even adopting other redshift intervals.
We conclude that our data suggest an increase
of the correlation length with average
,
when performing
this more appropriate comparison at similar median redshifts. Although the
measured correlation lengths are quite sensitive to the choice of the
redshift bin boundaries because of the spiky nature of the observed
redshift distributions, we note that we systematically measure larger correlation
lengths for LIRGs than for non-LIRGs, even adopting other redshift intervals.
We conclude that our data suggest an increase
of the correlation length with average
![]() or SFR, although this
result needs to be confirmed using larger samples with better statistics.
or SFR, although this
result needs to be confirmed using larger samples with better statistics.
As in the case of the total sample, we compared the results from the
GOODS fields with those from the Millennium simulation. In
Fig. 13 the r0 values of the samples with
![]() and
and
![]() in the
redshift range
z=0.1-1.4 for the combined GOODS-S plus GOODS-N sample
(see Table 2) are plotted as a function of the sample median
luminosity and compared with the expectations from mock samples
extracted from Millennium using the same
in the
redshift range
z=0.1-1.4 for the combined GOODS-S plus GOODS-N sample
(see Table 2) are plotted as a function of the sample median
luminosity and compared with the expectations from mock samples
extracted from Millennium using the same
![]() thresholds. Since in
each Millennium sample the median
thresholds. Since in
each Millennium sample the median
![]() is lower than in the
corresponding GOODS sample (see Table 1) - and this is especially true
for LIRGs - we also measured
is lower than in the
corresponding GOODS sample (see Table 1) - and this is especially true
for LIRGs - we also measured
![]() for mock sources above
for mock sources above
![]() ,
which have the same median luminosity of
GOODS LIRGs. Again, we used the 40 GOODS-sized subregions of the
2 deg2 full mock field to obtain the average correlation length and
dispersion for model galaxies selected at different luminosities. This
is shown by the shaded region in Fig. 13. Even at
high luminosities, the overall clustering of the data appears stronger
than that predicted by the simulations, although with reduced
significance.
,
which have the same median luminosity of
GOODS LIRGs. Again, we used the 40 GOODS-sized subregions of the
2 deg2 full mock field to obtain the average correlation length and
dispersion for model galaxies selected at different luminosities. This
is shown by the shaded region in Fig. 13. Even at
high luminosities, the overall clustering of the data appears stronger
than that predicted by the simulations, although with reduced
significance.
![\begin{figure}
\par\includegraphics[width=5.5cm,clip]{7506f11a.ps}\par\vspace*{2mm}
\includegraphics[width=5.5cm,clip]{7506f11b.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img213.gif) |
Figure 11:
Upper panel: redshift distributions and
selection functions for LIRGs and non-LIRGs in GOODS-S. Sources in the
z=0.5-1.0 redshift interval used to compute the projected
correlation function
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=5.5cm,clip]{7506f12a.ps}\par\vspace*{2mm}
\includegraphics[width=5.5cm,clip]{7506f12b.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img214.gif) |
Figure 12: Same as in Fig. 11 but for the GOODS-N field. |
| Open with DEXTER | |
As noted above, among galaxies with
![]() Jy, the fraction of
IR luminous objects is lower in the mock catalog than in GOODS. As
an example, the fraction of LIRGs is 13% in Millenium, as opposed to
the 30% in GOODS (see Table 1). This is related to the fact that, as
emphasized by Elbaz et al. (2007), Millennium galaxies are forming
stars at rates
Jy, the fraction of
IR luminous objects is lower in the mock catalog than in GOODS. As
an example, the fraction of LIRGs is 13% in Millenium, as opposed to
the 30% in GOODS (see Table 1). This is related to the fact that, as
emphasized by Elbaz et al. (2007), Millennium galaxies are forming
stars at rates ![]() 3 times lower than those which are observed at
3 times lower than those which are observed at
![]() .
We have verified that artificially increasing the SFR of
all model galaxies (i.e., independent of their positions within
the simulation) by this amount does not change our conclusions, as it
would imply even smaller correlation lengths all luminosities (as can
already be argued from Fig. 13).
.
We have verified that artificially increasing the SFR of
all model galaxies (i.e., independent of their positions within
the simulation) by this amount does not change our conclusions, as it
would imply even smaller correlation lengths all luminosities (as can
already be argued from Fig. 13).
The AGN removal performed on our sample does not
significantly affect the best fit correlation lengths or slopes.
However, two points are worth noting. First, the fraction of
AGN candidates is higher among LIRGs (17%) than in the total samples (8%), consistent with what observed for IRAS galaxies in the local Universe,
where a higher fraction of AGN is found in more luminous IR objects
(e.g., Sanders & Mirabel 1996). Second, a small (![]()
![]() )
systematic decrease of the correlation lengths is observed when AGN
are removed from the samples, which is consistent with the fact that
AGN in GOODS (which have
r0=5-10 h-1 Mpc, Gilli et al. 2005)
are more strongly clustered than is the full IR galaxy population.
)
systematic decrease of the correlation lengths is observed when AGN
are removed from the samples, which is consistent with the fact that
AGN in GOODS (which have
r0=5-10 h-1 Mpc, Gilli et al. 2005)
are more strongly clustered than is the full IR galaxy population.
![\begin{figure}
\par\includegraphics[width=8.3cm,clip]{7506f13.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img217.gif) |
Figure 13:
From top to bottom panel: best fit correlation length,
slope and amplitude, for the total,
|
| Open with DEXTER | |
The measured clustering level of star forming galaxies implies that
important field-to-field variations should be observed in the number counts
of these sources. As discussed in Sect. 2, we have in fact found that the
surface densities in GOODS-N versus GOODS-S field differ at the 20%
level, once spectroscopic incompleteness is taken into account. Given our
direct clustering measurements, we can verify a posteriori if
this difference may be understood in terms of cosmic variance in the
counts. The expected total variance in the counts can be expressed as:
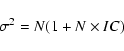 |
(7) |
Deep redshift surveys such as VVDS and DEEP2 are providing an accurate
census of the galaxy population at ![]() ,
measuring in particular
the dependence of galaxy clustering on several parameters such as the
galaxy spectroscopic type, color and luminosity. In both surveys,
galaxies which can be identified as star forming appear to have a
correlation length smaller than that measured for our GOODS 24
,
measuring in particular
the dependence of galaxy clustering on several parameters such as the
galaxy spectroscopic type, color and luminosity. In both surveys,
galaxies which can be identified as star forming appear to have a
correlation length smaller than that measured for our GOODS 24 ![]() m
selected sample, although the significance of this difference is still
limited. In detail, Coil et al. (2004) find
m
selected sample, although the significance of this difference is still
limited. In detail, Coil et al. (2004) find
![]() Mpc for emission line galaxies in DEEP2 (
Mpc for emission line galaxies in DEEP2 (![]()
![]() lower than
that for the total GOODS
lower than
that for the total GOODS ![]() m sample), while Meneux et al. (2006)
find
m sample), while Meneux et al. (2006)
find
![]() Mpc for star forming, blue galaxies in
the VVDS (
Mpc for star forming, blue galaxies in
the VVDS (![]()
![]() lower than the total GOODS
lower than the total GOODS ![]() m
sample). The main difference between the GOODS sample considered here
and those from DEEP2 and VVDS resides in the selection at mid-IR
versus optical wavelengths. The required detection of sources at 24
m
sample). The main difference between the GOODS sample considered here
and those from DEEP2 and VVDS resides in the selection at mid-IR
versus optical wavelengths. The required detection of sources at 24 ![]() m for GOODS (in particular the requirement of
m for GOODS (in particular the requirement of
![]() Jy) imposes a lower limit to SFR of about 2.5
Jy) imposes a lower limit to SFR of about 2.5 ![]() yr-1 at
yr-1 at ![]() (see Fig. 4), while
optical selection (
(see Fig. 4), while
optical selection (
![]() mag and
mag and
![]() mag for VVDS and
DEEP2 galaxies, respectively) does not translate as directly into a
SFR. Indeed, because of older stars and dust extinction, even galaxies
with very similar optical properties could span a very wide range of
star formation rates. We verified that if we impose a cut in SFR or
24
mag for VVDS and
DEEP2 galaxies, respectively) does not translate as directly into a
SFR. Indeed, because of older stars and dust extinction, even galaxies
with very similar optical properties could span a very wide range of
star formation rates. We verified that if we impose a cut in SFR or
24 ![]() m flux density on the Millennium mock catalogs, many low-SFR
objects excluded from the sample would be included if a simple
optical magnitude cut had been used instead (e.g.,
m flux density on the Millennium mock catalogs, many low-SFR
objects excluded from the sample would be included if a simple
optical magnitude cut had been used instead (e.g.,
![]() mag, the
limit for optical spectroscopy of GOODS sources considered here). In
fact, the median SFR of Millennium mock sources increases by a factor
of
mag, the
limit for optical spectroscopy of GOODS sources considered here). In
fact, the median SFR of Millennium mock sources increases by a factor
of ![]() 6 when the additional mid-IR cut is included. Therefore, in
optically selected samples, star forming galaxies are expected to have
a lower star formation rate on average than that of our MIPS
sources. The trend discussed in the previous section, in which r0is larger for samples selected at increasing
6 when the additional mid-IR cut is included. Therefore, in
optically selected samples, star forming galaxies are expected to have
a lower star formation rate on average than that of our MIPS
sources. The trend discussed in the previous section, in which r0is larger for samples selected at increasing
![]() (or SFR), is in
line with this interpretation. In connection with the above
considerations, it is interesting to note that the strong clustering
level measured for GOODS LIRGs appears then to be more similar to that
measured for passive galaxies than for moderately star forming
galaxies at
(or SFR), is in
line with this interpretation. In connection with the above
considerations, it is interesting to note that the strong clustering
level measured for GOODS LIRGs appears then to be more similar to that
measured for passive galaxies than for moderately star forming
galaxies at ![]() (Coil et al. 2004, see also
Fig. 14). Since the amplitude of galaxy clustering is directly
related to the galaxy mass (on average, more massive galaxies reside
in denser, i.e., more clustered, environments), this result is in
agreement with the observed dichotomy for massive galaxies at
(Coil et al. 2004, see also
Fig. 14). Since the amplitude of galaxy clustering is directly
related to the galaxy mass (on average, more massive galaxies reside
in denser, i.e., more clustered, environments), this result is in
agreement with the observed dichotomy for massive galaxies at
![]() ,
most of which either have already ceased forming
stars, or are doing so at very high rates (Noeske et al. 2007; Elbaz
et al. 2007).
,
most of which either have already ceased forming
stars, or are doing so at very high rates (Noeske et al. 2007; Elbaz
et al. 2007).
In Sect. 5 we showed that MIPS detected sources in the GOODS fields
appear to be significantly more clustered than expected from galaxy
formation models based on the Millennium simulation (Kitzbichler &
White 2007). One may wonder if this discrepancy can be ascribed to
uncertainties in the SFR to
![]() conversion, since
conversion, since
![]() is the
available (although indirect)
measurement for real data, while SFR is the primary output
for mock galaxies. Under different assumptions on the stellar IMF the
overall uncertainties in the SFR to
is the
available (although indirect)
measurement for real data, while SFR is the primary output
for mock galaxies. Under different assumptions on the stellar IMF the
overall uncertainties in the SFR to
![]() relation can be
quantified to about 30%. We verified that a 30% variation of the
24
relation can be
quantified to about 30%. We verified that a 30% variation of the
24 ![]() m flux density threshold in the mock catalog does not alter
significantly the Millennium correlation function.
m flux density threshold in the mock catalog does not alter
significantly the Millennium correlation function.
As emphasized by Elbaz et al. (2007), at ![]() Millennium galaxies
are forming stars at rates about a factor of 3 lower than observed
galaxies. As far as object selection is concerned, artificially
increasing the SFR of model galaxies is equivalent to selecting
galaxies in the mock sample at lower 24
Millennium galaxies
are forming stars at rates about a factor of 3 lower than observed
galaxies. As far as object selection is concerned, artificially
increasing the SFR of model galaxies is equivalent to selecting
galaxies in the mock sample at lower 24 ![]() m flux densities. This
selects many more sources, which are in general less clustered
since the lower tail of the SFR distribution is now being
sampled. We checked that reducing the limiting f24
flux density by a factor of 3 produces a lower correlation
function for Millennium sources, thus reinforcing the discrepancy with
the real data. To be fair, it should be noted that simulated galaxies
are free from some of the observational selection effects which affect
real data in our samples and complicate a direct comparison. For
example, at the faintest flux limits of
m flux densities. This
selects many more sources, which are in general less clustered
since the lower tail of the SFR distribution is now being
sampled. We checked that reducing the limiting f24
flux density by a factor of 3 produces a lower correlation
function for Millennium sources, thus reinforcing the discrepancy with
the real data. To be fair, it should be noted that simulated galaxies
are free from some of the observational selection effects which affect
real data in our samples and complicate a direct comparison. For
example, at the faintest flux limits of
![]() Jy, where
Jy, where
![]() for MIPS detections, we might be failing to detect sources
in crowded regions or close to brighter mid-IR targets. We expect this
should be a small effect, but not entirely negligible and in any case
difficult to properly simulate. Also, the 50-65% spectroscopic
completeness may introduce a bias if sources with measured redshifts
have different clustering properties from sources without redshifts
(i.e., if sources with redshifts are not a random sampling of the full
population). For example, some tendency is detected in both fields for
larger spectroscopic completeness at brighter z-band magnitudes (see
Fig. 1). Therefore the observed discrepancy between the GOODS data and
the mock catalogs from Millennium should be considered by keeping in
mind those caveats.
for MIPS detections, we might be failing to detect sources
in crowded regions or close to brighter mid-IR targets. We expect this
should be a small effect, but not entirely negligible and in any case
difficult to properly simulate. Also, the 50-65% spectroscopic
completeness may introduce a bias if sources with measured redshifts
have different clustering properties from sources without redshifts
(i.e., if sources with redshifts are not a random sampling of the full
population). For example, some tendency is detected in both fields for
larger spectroscopic completeness at brighter z-band magnitudes (see
Fig. 1). Therefore the observed discrepancy between the GOODS data and
the mock catalogs from Millennium should be considered by keeping in
mind those caveats.
At any rate it is interesting to investigate what could be a likely ingredient that has to be modified within the semi-analytic models in Millennium to explain the observed discrepancy. We suggest here that a possible weakness in the models is the SFR algorithm adopted for the mock galaxies. Indeed, within simulated dense environments like galaxy clusters and groups, a very abrupt cut-off of gas-cooling is applied to galaxies as soon as they become non-central. Therefore, simulated satellite galaxies might be not forming stars at sufficiently high rates, which would indeed reduce the correlation length of the star forming simulated population as well as their number density (see the next section).
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f14.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img230.gif) |
Figure 14:
Correlation length and space density of GOODS "all''
(
|
| Open with DEXTER | |
While at small scales, comparable to the dimensions of dark matter
halos, the clustering of a given galaxy population is difficult to
predict because of merging and interactions that can trigger a number
of physical processes, at larger scales (e.g., >![]() Mpc), where
galaxy interactions are rare, the galaxy correlation function should
follow that of the hosting dark matter halos.
An interesting consequence is that one can estimate the masses of the
typical halos hosting a given galaxy population by simply comparing
their clustering level (see, e.g., Giavalisco & Dickinson
2001). Indeed, according to the standard
Mpc), where
galaxy interactions are rare, the galaxy correlation function should
follow that of the hosting dark matter halos.
An interesting consequence is that one can estimate the masses of the
typical halos hosting a given galaxy population by simply comparing
their clustering level (see, e.g., Giavalisco & Dickinson
2001). Indeed, according to the standard ![]() CDM hierarchical
scenario, dark matter halos of different mass cluster differently,
with the more massive halos being more clustered for any given epoch,
and it is then straightforward to compute the correlation function for
halos above a given mass threshold. It is worth noting that since less
massive halos are more abundant, the correlation function of halos
above a given mass threshold is very similar to the clustering of
halos with mass close to that threshold. Also, it is important to note
that as far as our clustering measurements are concerned (see Sect. 5), the
CDM hierarchical
scenario, dark matter halos of different mass cluster differently,
with the more massive halos being more clustered for any given epoch,
and it is then straightforward to compute the correlation function for
halos above a given mass threshold. It is worth noting that since less
massive halos are more abundant, the correlation function of halos
above a given mass threshold is very similar to the clustering of
halos with mass close to that threshold. Also, it is important to note
that as far as our clustering measurements are concerned (see Sect. 5), the
![]() datapoints at large scales (
datapoints at large scales (
![]() Mpc) have
smaller errorbars and guide the power law fit (see Fig. 8). Therefore
the measured r0 and
Mpc) have
smaller errorbars and guide the power law fit (see Fig. 8). Therefore
the measured r0 and ![]() values are essentially due to the
clustering signal at large scales, where the galaxy correlation
function follows that of the dark matter, allowing a meaningful
comparison with the clustering expected for dark matter halos.
values are essentially due to the
clustering signal at large scales, where the galaxy correlation
function follows that of the dark matter, allowing a meaningful
comparison with the clustering expected for dark matter halos.
We considered the dark matter halo catalogs available for the
milli-Millennium simulation![]() , a reduced version of the Millennium
run which includes 1/512 of the full simulated volume. Halo catalogs
are available at different time steps along the simulation. Here we
considered those at
, a reduced version of the Millennium
run which includes 1/512 of the full simulated volume. Halo catalogs
are available at different time steps along the simulation. Here we
considered those at ![]() (parameter stepnum=41 in the
simulation). In total there are about 32 000 halos with mass above
(parameter stepnum=41 in the
simulation). In total there are about 32 000 halos with mass above
![]() in a cubic volume of 62.5
in a cubic volume of 62.5![]() Mpc on a
side. We computed the correlation function and the space density of
halos above mass thresholds of log(
Mpc on a
side. We computed the correlation function and the space density of
halos above mass thresholds of log(
![]() ,
11.2, 11.6,
12.0, 12.4, 12.8. Here we use as halo mass estimator the simulation
parameter m_Crit200, defined as the mass within the radius
where the integrated halo overdensity is 200 times the critical
density of the simulation. The results are shown in Fig. 14,
where it is readily evident that more massive halos are more clustered
and less numerous. The halo region plotted in Fig. 14 takes
into account the fluctuations in the halo space density due to cosmic
variance on volumes equal to the milli-Millennium volume (see
Sect. 5.3 and Somerville et al. 2004, for a description of
the methods to derive the fluctuations in the source counts from the
clustering parameters).
,
11.2, 11.6,
12.0, 12.4, 12.8. Here we use as halo mass estimator the simulation
parameter m_Crit200, defined as the mass within the radius
where the integrated halo overdensity is 200 times the critical
density of the simulation. The results are shown in Fig. 14,
where it is readily evident that more massive halos are more clustered
and less numerous. The halo region plotted in Fig. 14 takes
into account the fluctuations in the halo space density due to cosmic
variance on volumes equal to the milli-Millennium volume (see
Sect. 5.3 and Somerville et al. 2004, for a description of
the methods to derive the fluctuations in the source counts from the
clustering parameters).
We computed the space density of sources in our GOODS samples and
compared the r0 and density values of our populations with those of
other galaxy populations at ![]() and with those of dark matter
halos at
and with those of dark matter
halos at ![]() as computed above. Comparable values for the space
densities of GOODS sources were found when considering the full
z=0.1-1.4 redshift range or a restricted redshift interval
(
z=0.7-1.2) around the peak of the selection function. The
comparison is shown in Fig. 14. Conservative uncertainties of 50% have been considered in the galaxy space densities, which should
take into account the fluctuations due to cosmic variance as well as
the uncertainties in the volume effectively spanned by the considered
galaxy populations. By comparing the halo and the galaxy r0values, one can immediately see that
as computed above. Comparable values for the space
densities of GOODS sources were found when considering the full
z=0.1-1.4 redshift range or a restricted redshift interval
(
z=0.7-1.2) around the peak of the selection function. The
comparison is shown in Fig. 14. Conservative uncertainties of 50% have been considered in the galaxy space densities, which should
take into account the fluctuations due to cosmic variance as well as
the uncertainties in the volume effectively spanned by the considered
galaxy populations. By comparing the halo and the galaxy r0values, one can immediately see that
![]() Jy star forming
galaxies are hosted by halos with masses
Jy star forming
galaxies are hosted by halos with masses ![]()
![]() ,
while LIRGs, which are more clustered, are on
average likely hosted by more massive halos with
,
while LIRGs, which are more clustered, are on
average likely hosted by more massive halos with
![]() .
The population of absorption-line galaxies by
Coil et al. (2004) also appears to be hosted by massive halos
(
.
The population of absorption-line galaxies by
Coil et al. (2004) also appears to be hosted by massive halos
(
![]() ), while their emission line galaxies
seem to reside in smaller halos with
), while their emission line galaxies
seem to reside in smaller halos with
![]() .
When looking at their space densities,
.
When looking at their space densities,
![]() Jy star forming galaxies (and LIRGs) and absorption
line galaxies at
Jy star forming galaxies (and LIRGs) and absorption
line galaxies at ![]() appear more abundant than halos that can
host them, i.e., there is likely more than one such galaxy per
halo. This is consistent with our measurements of
appear more abundant than halos that can
host them, i.e., there is likely more than one such galaxy per
halo. This is consistent with our measurements of
![]() .
Indeed, as
shown in Fig. 8, the clustering signal is well detected down to very
small scales of
.
Indeed, as
shown in Fig. 8, the clustering signal is well detected down to very
small scales of
![]() kpc, well within the typical size of
dark matter halos. As an example, the average half-mass radius for
Millennium halos with
kpc, well within the typical size of
dark matter halos. As an example, the average half-mass radius for
Millennium halos with
![]() ,
i.e., those which
likely host GOODS IR galaxies, is about 100 h-1 kpc. Therefore,
most of the signal at scales
,
i.e., those which
likely host GOODS IR galaxies, is about 100 h-1 kpc. Therefore,
most of the signal at scales
![]() Mpc is likely
dominated by galaxies within the same halos (i.e., the so-called
intra-halo term) and a steepening of
Mpc is likely
dominated by galaxies within the same halos (i.e., the so-called
intra-halo term) and a steepening of
![]() is indeed consistently
observed at these scales (Fig. 8). A fully consistent analysis of
mid-IR galaxy clustering within the halo occupation number (HOD)
theoretical framework (e.g., Peacock & Smith 2000; Moustakas &
Somerville 2002; Kravtsov et al. 2004) is however beyond the scope of
this paper.
is indeed consistently
observed at these scales (Fig. 8). A fully consistent analysis of
mid-IR galaxy clustering within the halo occupation number (HOD)
theoretical framework (e.g., Peacock & Smith 2000; Moustakas &
Somerville 2002; Kravtsov et al. 2004) is however beyond the scope of
this paper.
To conclude this section we note that Millennium simulated star
forming galaxies and LIRGs at ![]() are less clustered than
observed in GOODS and that, moreover, observed LIRGs appear
significantly more abundant than those in Millennium (Fig. 12).
This further supports the interpretation that, at
are less clustered than
observed in GOODS and that, moreover, observed LIRGs appear
significantly more abundant than those in Millennium (Fig. 12).
This further supports the interpretation that, at ![]() ,
many
galaxies within dense environments such as groups or clusters are
forming stars at high rates, in contrast to the star formation history
assumed in the Millennium simulation. The model's scarcity of star forming
galaxies in dense environments, e.g., within the same dark matter halo,
may be also responsible for the observed flattening of the Millennium
correlation function towards small scales (see Fig. 8).
,
many
galaxies within dense environments such as groups or clusters are
forming stars at high rates, in contrast to the star formation history
assumed in the Millennium simulation. The model's scarcity of star forming
galaxies in dense environments, e.g., within the same dark matter halo,
may be also responsible for the observed flattening of the Millennium
correlation function towards small scales (see Fig. 8).
It is not clear yet what is the main driver of star formation in
galaxies at ![]() .
On the one hand, a correlation between star
formation rate and galaxy mass is observed (Noeske et al. 2007; Elbaz
et al. 2007). On the other hand, as found in this work, higher star
formation rates are hosted by galaxies in denser environments. These
two results are perfectly consistent one another (and with the
conclusions of Elbaz et al. 2007 and Cooper et al. 2007), since more
massive galaxies are indeed located in dense environments, but it is
hard to establish what is the ultimate driver for the star formation
increase: is it the galaxy mass or the environment? In other words, is
the star formation rate in each galaxy simply linked to the gas mass
and triggered at a given time along the galaxy life almost
independently of the environment or, instead, are environmental
effects necessary to produce gas instabilities and trigger star
formation? Solving these issues is beyond the scope of this paper. It
will require much larger samples of star forming galaxies with
spectroscopic redshifts, with which one will be able to study
clustering of galaxies versus their star formation rates in narrow
mass bins.
.
On the one hand, a correlation between star
formation rate and galaxy mass is observed (Noeske et al. 2007; Elbaz
et al. 2007). On the other hand, as found in this work, higher star
formation rates are hosted by galaxies in denser environments. These
two results are perfectly consistent one another (and with the
conclusions of Elbaz et al. 2007 and Cooper et al. 2007), since more
massive galaxies are indeed located in dense environments, but it is
hard to establish what is the ultimate driver for the star formation
increase: is it the galaxy mass or the environment? In other words, is
the star formation rate in each galaxy simply linked to the gas mass
and triggered at a given time along the galaxy life almost
independently of the environment or, instead, are environmental
effects necessary to produce gas instabilities and trigger star
formation? Solving these issues is beyond the scope of this paper. It
will require much larger samples of star forming galaxies with
spectroscopic redshifts, with which one will be able to study
clustering of galaxies versus their star formation rates in narrow
mass bins.
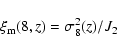 |
(9) |
The above relations allow us to estimate the bias of the galaxy
population at its median redshift. One can further assume that the
spatial distribution of the observed galaxy population simply evolves
with time under the gravitational pull of growing dark matter
structures. This scenario, in which galaxy merging is considered
negligible, is often called the galaxy conserving model and in
this case the bias evolution can be approximated by
| b(z)=1+[b(0)-1]/D(z) | (10) |
Once b(z) is determined, the evolution of
![]() and hence of
r0(z) can be obtained by inverting Eq. (8). The best fit
and hence of
r0(z) can be obtained by inverting Eq. (8). The best fit
![]() values found in this work are assumed in the above
relations. In Fig. 15 we show the evolution of b(z)and r0(z) for the combined GOODS samples reported in Table 2. Star
forming (
values found in this work are assumed in the above
relations. In Fig. 15 we show the evolution of b(z)and r0(z) for the combined GOODS samples reported in Table 2. Star
forming (
![]() Jy) objects at
Jy) objects at ![]() are expected to
have
are expected to
have
![]() Mpc at a redshift of 0.1. Since local early
type galaxies
Mpc at a redshift of 0.1. Since local early
type galaxies![]() with L<L* have been observed to be
clustered that strongly in the SDSS and 2dFGRS (Zehavi et al. 2002;
Madgwick et al. 2003), at least part of them could descend from
with L<L* have been observed to be
clustered that strongly in the SDSS and 2dFGRS (Zehavi et al. 2002;
Madgwick et al. 2003), at least part of them could descend from
![]() star forming objects. Similarly, some of the brighter
(
star forming objects. Similarly, some of the brighter
(![]() )
ellipticals in the local Universe, for which
)
ellipticals in the local Universe, for which
![]() Mpc has been measured (Guzzo et al. 1997; Budavari
et al. 2002) could descend from
Mpc has been measured (Guzzo et al. 1997; Budavari
et al. 2002) could descend from ![]() LIRGs
(
LIRGs
(
![]() ), which are expected to evolve into a
population with
), which are expected to evolve into a
population with
![]() Mpc by z=0. This would be
consistent with the recent findings by Cimatti et al.
(2006), who observe a lower number density of
Mpc by z=0. This would be
consistent with the recent findings by Cimatti et al.
(2006), who observe a lower number density of ![]() early
type galaxies at
early
type galaxies at ![]() than at z=0, suggesting that at least
part of local ellipticals have formed since
than at z=0, suggesting that at least
part of local ellipticals have formed since ![]() .
.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{7506f15.ps}\end{figure}](/articles/aa/full/2007/43/aa7506-07/img267.gif) |
Figure 15:
Bias ( upper panel) and correlation length ( lower panel) for
the total,
|
| Open with DEXTER | |
The slope of the correlation function for local ellipticals is
generally found to be steeper than that observed for GOODS IR galaxies. Slopes of
![]() have indeed been measured for
local ellipticals (Guzzo et al. 1997; Zehavi et al. 2002; Madgwick et al. 2003), as opposed to
have indeed been measured for
local ellipticals (Guzzo et al. 1997; Zehavi et al. 2002; Madgwick et al. 2003), as opposed to
![]() for GOODS star forming
galaxies measured in this work. While an average steepening of the
matter correlation function and of the overall galaxy population is
expected towards lower redshifts (see, e.g., Kauffman et al. 1999;
Moustakas & Somerville 2002) since the clustering level progressively
increases at smaller scales, the clustering evolution in the proposed
galaxy conserving scenario above is computed by assuming a fixed
(
for GOODS star forming
galaxies measured in this work. While an average steepening of the
matter correlation function and of the overall galaxy population is
expected towards lower redshifts (see, e.g., Kauffman et al. 1999;
Moustakas & Somerville 2002) since the clustering level progressively
increases at smaller scales, the clustering evolution in the proposed
galaxy conserving scenario above is computed by assuming a fixed
(
![]() )
slope. Also it has to be kept in mind that the galaxy conserving scenario is an ideal, rather extreme,
representation of galaxy evolution, since it, by definition, neglects
galaxy merging. It is therefore somewhat misleading to determine the
descendants of a high redshift galaxy population simply based on the
r0 comparison without considering the slope. A
)
slope. Also it has to be kept in mind that the galaxy conserving scenario is an ideal, rather extreme,
representation of galaxy evolution, since it, by definition, neglects
galaxy merging. It is therefore somewhat misleading to determine the
descendants of a high redshift galaxy population simply based on the
r0 comparison without considering the slope. A ![]() star
forming galaxy does not evolve automatically into a z=0 elliptical
and perhaps subsamples of the local spiral galaxy population may have
the clustering properties expected for the descendants of
star
forming galaxy does not evolve automatically into a z=0 elliptical
and perhaps subsamples of the local spiral galaxy population may have
the clustering properties expected for the descendants of ![]() star forming galaxies. In an SDSS-based paper, Budavari et al. (2002)
have analyzed the clustering properties of
star forming galaxies. In an SDSS-based paper, Budavari et al. (2002)
have analyzed the clustering properties of ![]() galaxies with
different spectral energy distributions (SEDs) corresponding to those
of galaxies with different morphological types. They found that bright
(
-23<MR<-21) galaxies with SEDs corresponding to the morphological
type Scd have a correlation length of
r0=6.75 h-1 Mpc, similar to
those of ellipticals at the same redshift, but with a shallower slope
galaxies with
different spectral energy distributions (SEDs) corresponding to those
of galaxies with different morphological types. They found that bright
(
-23<MR<-21) galaxies with SEDs corresponding to the morphological
type Scd have a correlation length of
r0=6.75 h-1 Mpc, similar to
those of ellipticals at the same redshift, but with a shallower slope
![]() .
We suggest that part of the GOODS LIRGs population
may then evolve into bright, massive spirals. By adding the space
densities of local ellipticals and bright spirals one further sees
that this is similar to what is measured for
.
We suggest that part of the GOODS LIRGs population
may then evolve into bright, massive spirals. By adding the space
densities of local ellipticals and bright spirals one further sees
that this is similar to what is measured for ![]() star forming
galaxies.
star forming
galaxies.
Recently, Adelberger et al. (2005) measured the clustering of star
forming galaxies at
![]() (BM and BX samples) and at z=3(LBGs, see also Giavalisco & Dickinson 2001). By comparing the galaxy
correlation function with that of dark matter halos in the
(BM and BX samples) and at z=3(LBGs, see also Giavalisco & Dickinson 2001). By comparing the galaxy
correlation function with that of dark matter halos in the
![]() CDM-GIF simulation (Kauffmann et al. 1999), Adelberger et al. (2005) found that UV selected galaxies at
CDM-GIF simulation (Kauffmann et al. 1999), Adelberger et al. (2005) found that UV selected galaxies at ![]() are hosted by
halos with masses around
are hosted by
halos with masses around
![]() .
Furthermore, by
following the evolution of these halos in catalogs computed at
subsequent time steps in the simulation, they were then able to infer
the correlation length of the descendants of the
.
Furthermore, by
following the evolution of these halos in catalogs computed at
subsequent time steps in the simulation, they were then able to infer
the correlation length of the descendants of the ![]() galaxy
population. At
galaxy
population. At ![]() they find that the only galaxy population
with clustering strong enough to be consistent with that of the expected
descendants of UV selected galaxies are red absorption line dominated
galaxies from Coil et al. (2004). In Fig. 15 the expected
evolution of
they find that the only galaxy population
with clustering strong enough to be consistent with that of the expected
descendants of UV selected galaxies are red absorption line dominated
galaxies from Coil et al. (2004). In Fig. 15 the expected
evolution of ![]() starburst galaxies as computed by Adelberger et al. (2005) is also shown. The clustering length of LIRGs at
starburst galaxies as computed by Adelberger et al. (2005) is also shown. The clustering length of LIRGs at ![]() is large enough to be consistent with the one predicted for the
descendants of UV selected galaxies. Moreover, the correlation slopes
of the two populations are similar (
is large enough to be consistent with the one predicted for the
descendants of UV selected galaxies. Moreover, the correlation slopes
of the two populations are similar (
![]() ). The
average SFR of UV-selected galaxies is also of the same order of that
of LIRGs (35
). The
average SFR of UV-selected galaxies is also of the same order of that
of LIRGs (35 ![]() yr-1 on average.) It is therefore
possible that LIRGs at
yr-1 on average.) It is therefore
possible that LIRGs at
![]() ,
in addition to passive galaxies,
may be the direct descendants of UV-selected galaxies. This would
imply, in turn, that star formation in these galaxies is sustained,
either continuously or intermittently, over cosmological timescales of
a few Gyrs and suggests they assemble stellar masses up to
,
in addition to passive galaxies,
may be the direct descendants of UV-selected galaxies. This would
imply, in turn, that star formation in these galaxies is sustained,
either continuously or intermittently, over cosmological timescales of
a few Gyrs and suggests they assemble stellar masses up to ![]()
![]() from
from ![]() to
to ![]() .
Our conclusions on the
.
Our conclusions on the
![]() descendants of high redshift star forming galaxies add to
those reached by Adelberger et al. (2005), who, based on the
comparison with the correlation lengths measured in the DEEP2 surveys,
identify passive absorption line galaxies at
descendants of high redshift star forming galaxies add to
those reached by Adelberger et al. (2005), who, based on the
comparison with the correlation lengths measured in the DEEP2 surveys,
identify passive absorption line galaxies at ![]() as the
descendants of their LBG population. DEEP2 star forming objects were
on the contrary ruled out based on their small correlation length. As
explained in the previous section, the low correlation length of
emission line (star forming) galaxies in the DEEP2 survey can be
ascribed to a SFR on average lower than that measured for our
LIRGs. Our results suggest that star formation is intense in a
significant fraction of massive objects at
as the
descendants of their LBG population. DEEP2 star forming objects were
on the contrary ruled out based on their small correlation length. As
explained in the previous section, the low correlation length of
emission line (star forming) galaxies in the DEEP2 survey can be
ascribed to a SFR on average lower than that measured for our
LIRGs. Our results suggest that star formation is intense in a
significant fraction of massive objects at ![]() and that the
descendants of high redshift star-forming galaxies have not
necessarily stopped forming stars at
and that the
descendants of high redshift star-forming galaxies have not
necessarily stopped forming stars at
![]() .
If we consider
that LIRGs and passive galaxies at
.
If we consider
that LIRGs and passive galaxies at ![]() have similar space
densities (
have similar space
densities (![]()
![]() Mpc-3, Fig. 14),
and that their combined density is of the order of the LBG space
density (
Mpc-3, Fig. 14),
and that their combined density is of the order of the LBG space
density (![]()
![]() Mpc-3), then we can conclude that a
significant fraction of
Mpc-3), then we can conclude that a
significant fraction of ![]() star forming galaxies might still be
forming stars at
star forming galaxies might still be
forming stars at ![]() .
.
We present the first measurements of the spatial clustering of star
forming galaxies at ![]() selected at 24
selected at 24 ![]() m by Spitzer/MIPS in the GOODS-S and GOODS-N fields. The correlation
length for the total combined sample has been found to be
m by Spitzer/MIPS in the GOODS-S and GOODS-N fields. The correlation
length for the total combined sample has been found to be
![]() Mpc, the r0 value in GOODS-S being
Mpc, the r0 value in GOODS-S being ![]()
![]() larger than in GOODS-N. We estimate the uncertainties in our
measurements using mock catalogs extracted from the Millennium
simulation, which show that the GOODS-S and GOODS-N measurements are
fully consistent with the expected cosmic variance on these 160
arcmin2 fields. We find indications for an increase of the
correlation length with
larger than in GOODS-N. We estimate the uncertainties in our
measurements using mock catalogs extracted from the Millennium
simulation, which show that the GOODS-S and GOODS-N measurements are
fully consistent with the expected cosmic variance on these 160
arcmin2 fields. We find indications for an increase of the
correlation length with
![]() (or SFR), with LIRGs having
(or SFR), with LIRGs having
![]() Mpc. The measured correlation length in the
GOODS mid-IR selected samples appears larger than that measured in
optical samples of star forming galaxies at
Mpc. The measured correlation length in the
GOODS mid-IR selected samples appears larger than that measured in
optical samples of star forming galaxies at ![]() such as those in
the DEEP2 or the VVDS surveys. Although the significance of this
result is still limited (
such as those in
the DEEP2 or the VVDS surveys. Although the significance of this
result is still limited (
![]() ), it might be interpreted as
evidence that the average star formation rate in optically selected
samples of emission line galaxies is lower than that of our samples,
which, by selection, have larger IR luminosity. This is in agreement
with the observed relation between IR luminosity and clustering
strength, which, in turn, suggests that at
), it might be interpreted as
evidence that the average star formation rate in optically selected
samples of emission line galaxies is lower than that of our samples,
which, by selection, have larger IR luminosity. This is in agreement
with the observed relation between IR luminosity and clustering
strength, which, in turn, suggests that at ![]() more intense star
formation is hosted by more massive (i.e., more clustered) systems.
more intense star
formation is hosted by more massive (i.e., more clustered) systems.
The measured correlation length is significantly larger than that
expected from the Millennium simulations, once the selection criteria
adopted to define the real data samples are applied to the mock
samples. This suggests that star formation is, on average, occurring
in dark matter halos that are more massive than those predicted by
the galaxy formation model implemented in the Millennium simulation
by Croton et al. (2006). By comparing the clustering of GOODS star
forming galaxies with that of Millennium dark matter halos, we find
that more luminous galaxies are hosted by progressively more massive
halos, with LIRGs residing in halos with
![]() .
Since the measured LIRG space density is
higher than that of the hosting halos, each halo appears to contain on
average more than one LIRG. This is also supported by the steepening
of the correlation function observed towards smaller scales, which is
usually interpreted as due to galaxy pairs within the same dark matter
halo (intra halo clustering).
.
Since the measured LIRG space density is
higher than that of the hosting halos, each halo appears to contain on
average more than one LIRG. This is also supported by the steepening
of the correlation function observed towards smaller scales, which is
usually interpreted as due to galaxy pairs within the same dark matter
halo (intra halo clustering).
Based on a galaxy conserving scenario, in which it is assumed that
galaxies observed at a given redshift evolve without merging, simply
pulled by the surrounding density field, we trace the time evolution
of the bias parameter and of the correlation length of ![]() star forming galaxies. By comparing the evolved correlation lengths
with those of local and high-redshift galaxy samples, we infer the
likely descendant and progenitors of our
star forming galaxies. By comparing the evolved correlation lengths
with those of local and high-redshift galaxy samples, we infer the
likely descendant and progenitors of our ![]() sample. We find
that objects in our sample may evolve into L<L* ellipticals or
bright spirals by z=0, with LIRGs evolving into bright
sample. We find
that objects in our sample may evolve into L<L* ellipticals or
bright spirals by z=0, with LIRGs evolving into bright ![]() objects. Similarly, LIRGs, together with passive absorption line
galaxies at
objects. Similarly, LIRGs, together with passive absorption line
galaxies at ![]() ,
may be identified as the descendants of
UV-selected star forming galaxies at
,
may be identified as the descendants of
UV-selected star forming galaxies at ![]() .
.
Acknowledgements
We wish to thank the referee for comments which improved the paper significantly. We acknowledge G. Zamorani, L. Pozzetti, F. Pozzi, C. Gruppioni, L. Moscardini, E. Branchini and M. Magliocchetti for useful discussions. We are also grateful to E. MacDonald and H. Spinrad for their extensive efforts obtaining some of the redshift measurements used in this work. R.G. acknowledges financial support from the Italian Space Agency (under the contract ASI-INAF I/023/05/0) and from the grant PRIN-MUR 2006-02-5203. The work of D.S. was carried out at Jet Propulsion Laboratory, California Institute of Technology, under a contract with NASA.