A&A 474, 315-338 (2007)
DOI: 10.1051/0004-6361:20077880
The multiscale morphology filter:
identifying and extracting spatial patterns in the galaxy distribution
M. A. Aragón-Calvo - B. J. T. Jones - R. van de Weygaert - J. M. van der Hulst
Kapteyn Astronomical Institute, University of Groningen,
PO Box 800, 9700 AV Groningen, The Netherlands
Received 14 May 2007 / Accepted 9 August 2007
Abstract
Aims. We present here a new method, MMF, for automatically segmenting cosmic structure into its basic components: clusters, filaments, and walls. Importantly, the segmentation is scale independent, so all structures are identified without prejudice as to their size or shape. The method is ideally suited for extracting catalogues of clusters, walls, and filaments from samples of galaxies in redshift surveys or from particles in cosmological N-body simulations: it makes no prior assumptions about the scale or shape of the structures.
Methods. Our Multiscale Morphology Filter (MMF) method has been developed on the basis of visualization and feature extraction techniques in computer vision and medical research. The density or intensity field of the sample is smoothed over a range of scales. The smoothed signals are processed through a morphology response filter whose form is dictated by the particular morphological feature it seeks to extract, and depends on the local shape and spatial coherence of the intensity field. The morphology signal at each location is then defined to be the one with the maximum response across the full range of smoothing scales.
The success of our method in identifying anisotropic features such as filaments and walls depends critically on the use of an optimally defined intensity field. This is accomplished by applying the DTFE reconstruction methodology to the sample particle or galaxy distribution.
Results. We have tested our MMF Filter against a set of heuristic models of weblike patterns such as are seen in the Megaparsec cosmic matter distribution. To test its effectiveness in the context of more realistic configurations we also present preliminary results from the MMF analysis of an N-body model. Comparison with alternative prescriptions for feature extraction shows that MMF is a remarkably strong structure finder
Key words: cosmology: theory - large-scale structure of Universe -
methods: statistical - surveys
On scales from a few Megaparsecs up to more than a hundred Megaparsecs, the spatial cosmic matter distribution displays a salient and pervasive weblike pattern which is perceived in the first instance as a cellular structure. The distribution of galaxies in large scale redshift surveys such as the 2-deg Field Galaxy Redshift Survey (2dF: Colless et al. 2003) and the Sloan Digital Sky Survey (SDSS: York et al. 2000) clearly delineate this Cosmic Web
(Bond et al. 1996; see van de Weygaert 2002, for a review).
Large computer simulations of the evolution of cosmic structure (Springel et al. 2005) show prominent cellular patterns arising from gravitational instability. Galaxies accumulate in flattened walls, elongated filaments and dense compact clusters. These structures surround large near-empty void regions (Zeldovich et al. 1982). Their spatial distribution displays a distinctive frothy texture, interconnected in a cosmic weblike pattern.
While it is rather straightforward to find qualitative descriptions of the spatial structure and components of the cosmic web, a useful, and physically meaningful, quantitative analysis has proven to be far from trivial. This would be important, for example, when we wish to study the effect of environment on the formation of galaxies and their halos.
We present here a new method for automatically segmenting cosmic structure into its basic components: clusters, filaments, and walls. Importantly, the segmentation is scale independent, so all structures are identified without prejudice as to their size or shape.
There are two parts to this: firstly, the reconstruction of a continuous density field from a point sample and secondly, the identification of structures within that density field. For the first part we use the Delaunay Tessellation Field Estimator (DTFE) technique of Schaap & van de Weygaert (2000). The second part, which is the main thrust of this paper, consists of a series of morphology filters that identify, in a scale independent manner, particular kinds of structure in data. The method is referred to as the Multiscale Morphology Filter (MMF) and is based on the kind of Scale Space analysis that has in recent years proved so successful in imaging science.
It is worth emphasising at this juncture that we have chosen a specific implementation of this kind of multi-scale analysis. Our choice is made on the following grounds: (a) it is simple to understand and program, (b) it works under quite general conditions and (c) the approach is generic and easy to modify. There are many alternative multi-scale strategies: we leave those for another day or for other people to follow up. Thus we shall try to keep this presentation as general as possible so that the points at which we make implementation specific choices are clear.
Structure in the Universe emerged as a result of the gravitational growth of small amplitude primordial density and velocity perturbations. Following the initial linear growth of the Gaussian primordial perturbations, the gravitational clustering process leads to the emergence of complex patterns and structures in the density field. At least three characteristics of the midly nonlinear cosmic matter stand out.
The most prominent property is its hierarchical nature. The gravitational clustering process proceeds such that small structures are the first to materialize and subsequently merge into ever larger entities. As a result each emerging cosmic structure consists of various levels of substructure. Hence, upon seeking to identify structure at one characteristic spatial scale we need to take into account a range of scales.
The second prominent aspect is that of the weblike geometry marked by highly elongated filamentary and flattened planar structures. The existence of the cosmic web can be understood through the tendency of matter concentrations to contract and collapse gravitationally in an anisotropic manner.
A final conspicuous aspect is that of the dominant presence of large roundish underdense regions, the voids. They form in and around density troughs in the primordial density field.
The challenge for any viable analysis tool is to trace, highlight and measure these features of the cosmic web.
We start in Sect. 3 by reviewing the DTFE method that is used to sample discrete point sets onto a regular mesh. Then in Sect. 5 we introduce the basic ideas from scale space theory that we will use. In Sect. 5 we introduce the morphology filters and give them a geometrical interpretation. The filters are tested using a Voronoi model in Sect. 9. We present
brief results from an N-body simulation in Sect. 10, leaving a detailed study to a subsequent paper in this series.
Many attempts to describe, let alone identify, the features and components of the Cosmic Web have been of a mainly heuristic nature.
There is a variety of statistical measures characterizing specific aspects of the large scale matter distribution (for an
extensive review see Martínez & Saar 2002). For completeness and comparison, we list briefly a selection of methods for structure characterisation
and finding. It is perhaps interesting to note two things about this list:
- a)
- each of the methods tends to be specific to one particular structural entity;
- b)
- there are no explicit wall-finders.
This emphasises an important aspect of our Scale Space approach: it provides a uniform approach to finding Blobs, Filaments and Walls
as individual objects that can be catalogued and studied.
The clustering of galaxies and matter is most commonly described in terms of a hierarchy of correlation functions. The two-point correlation function (and its Fourier transform, the power spectrum) remains the mainstay of cosmological clustering analysis and has a solid physical basis. However, the nontrivial and nonlinear patterns of the cosmic web are mostly a result of the phase correlations in the cosmic matter distribution (Coles & Chiang 2000; Ryden & Gramann 1991; Chiang & Coles 2000). While this information is contained in the moments of cell counts (de Lapparent et al. 1991; Peebles 1980; Gaztañaga 1992) and, more formally so, in the full hierarchy of M-point correlation functions
 ,
their measurement has proven to be impractical for all but the lowest orders (Peebles 1980; Szapudi 1998; Jones et al. 2005).
,
their measurement has proven to be impractical for all but the lowest orders (Peebles 1980; Szapudi 1998; Jones et al. 2005).
The Void probability Function (White 1979; Lachieze-Rey et al. 1992) provided a characterisation of the "voidness'' of the Universe in terms of a function that combined information from many higher moments of the point distribution. But, again, this has not provided any identification of individual voids.
The shape of the local matter distribution may be traced on the basis of an analysis of the statistical properties of its inertial moments
(Basilakos et al. 2001; Babul & Starkman 1992; Luo & Vishniac 1995). These concepts are closely related to the full characterization of the topology of the matter distribution in terms of four Minkowski functionals (Schmalzing et al. 1999; Mecke et al. 1994). They are solidly based on the theory of spatial statistics and also have the great advantage of being known analytically in the case of Gaussian random fields. In particular, the genus of the density field has received substantial attention as a strongly discriminating factor between intrinsically different spatial patterns (Hoyle & Vogeley 2002; Gott et al. 1986).
The Minkowski functionals provide global characterisations of structure. An attempt to extend its scope towards providing locally defined topological measures of the density field has been developed in the SURFGEN project defined by Sahni and Shandarin and their coworkers (Shandarin et al. 2004; Sahni et al. 1998). The main problem remains the user-defined, and thus potentially biased, nature of the continuous density field inferred from the sample of discrete objects. The usual filtering techniques suppress substructure on a scale smaller than the filter radius, introduce artificial topological features in sparsely sampled regions and diminish the flattened or elongated morphology of the spatial patterns. Quite possibly the introduction of more advanced geometry based methods to trace the density field may prove a major advance towards solving this problem.
Importantly, Martínez et al. (2005) and Saar et al. (2007) have generalized the use of Minkowski Functionals by calculating their values in a hierarchy of scales generated from wavelet-smoothed volume limited subsamples of the 2dF catalogue. This approach is particularly effective in dealing with non-Gaussian point distributions since the smoothing is not predicated on the use of Gaussian smoothing kernels.
In the context of analysing distributions of galaxies we can think of cluster finding algorithms. There we might define a cluster as an aggregate of neighbouring galaxies sharing some localised part of velocity space. Algorithms like HOP attempt to do this. However, there are always issues arising such as how to deal with substructure: that perhaps comes down to the defintion of what a cluster is. Here we focus on defining coherent structures based on particle positions alone. The velocity space data is not used since there is no prior prejudice as to what the velocity space should look like.
The connectedness of elongated supercluster structures in the cosmic matter distribution was first probed by means of percolation analysis, introduced and emphasized by Zel'dovich and coworkers (Zeldovich et al. 1982), while a related graph-theoretical construct, the minimum spanning tree of the galaxy distribution, was extensively probed and analysed by Bhavsar and collaborators (Colberg 2007; Graham 1995; Barrow et al. 1985) in an attempt to develop an objective measure of filamentarity.
Finding filaments joining neighbouring clusters has been tackled, using quite different techniques, by Colberg et al. (2005) and by Pimbblet (2005). More general filament finders have been put forward by a number of authors. Stoica et al. (2005) use a generalization of the classical Candy model to locate and catalogue filaments in galaxy surveys. This approach has the advantage that it works directly with the original point process and does not require the creation of a continuous density field. However, it is very computationally intensive.
The mathematically most rigorous program for filament description and analysis is that of the skeleton analysis of density fields
by Novikov et al. (2006) (2D) and Sousbie et al. (2007) (3D). Based on Morse theory (see Colombi et al. 2000) the skeleton formalism analyzes
continuous density fields and detects morphological features - maxima and saddle points in the density field - by relating density field gradients to the
Hessian of the density field (also see Doré et al. 2007). It results in an elegant and effective tool with a
particular focus towards tracing the filamentary structures in the cosmic web. However, it is computationally intensive and may be sensitive
to the specific method of reconstruction of the continuous density field. The Hessian of the density field also forms the basis of the MMF presented
in this study, although MMF embeds this within a formalism that explicitly adresses the multiscale character of the cosmic density field and
includes the shape conserving abilities of the tessellation based density field reconstruction Schaap & van de Weygaert (2000).
Voids are distinctive and striking features of the cosmic web, yet finding them systematically in surveys and simulations has proved rather difficult. There have been extensive searches for voids in galaxy catalogues (Hoyle & Vogeley 2002; Plionis & Basilakos 2002) and in numerical simulations
(Arbabi-Bidgoli & Müller 2002; Aikio & Mähönen 1998).
Several factors contribute to making systematic void-finding difficult. The fact that voids are almost empty of galaxies means that the sampling density plays a key role in determining what is or is not a void (Schmidt et al. 2001). Moreover, void finders are often predicated on building void structures out of cubic cells (Kauffmann & Fairall 1991) or out of spheres (e.g. Patiri et al. 2006). Such methods attempt to synthesize voids from the intersection of cubic or spherical elements and do so with varying degrees of success. The Aspen-Amsterdam Void Finder Comparison Project of Colberg et al. (2007) will clarify many of these issues.
The Watershed-based algorithm of Platen et al. (2007) aims to avoid issues of both sampling density and shape.
Combining the local Hessian matrix eigenvalues on various scales, this is the new technique that we are presenting here for the first time in the cosmological context.
Scale space analysis looks for structures of a mathematically specified type in a hierarchical, scale independent, manner. It is presumed that the specific structural characteristic is quantified by some appropriate parameter (e.g.: density, eccentricity, direction, curvature components). The data is filtered to produce a hierarchy of maps having different resolutions, and at each point, the dominant parameter value is selected from the hierarchy to construct the scale independent map. We refer to this scale-filtering processes as a Multiscale morphology filter.
For simplicity, the paper describes one specific implementation, or embodiment, of the process in relation to the problem of cataloguing the structural elements of the cosmic web. Other embodiments are possible, but the present one turns out to be highly effective in structure segregation and feature identification.
While this sounds relatively straightforward, in practise a number of things are required to execute the process. Firstly there must be an unambiguous definition of the structure-defining characteristic. In the present case we shall use the principal components of the local curvature of the density field at each point as a morphology type indicator. This requires that the density be defined at all points of a grid, and so there must be a method for going from a discrete point set to a grid sampled continuous density field. We choose to do this using the DTFE methodology since that does minimal damage to the structural morphology of the density field.
Since we are looking for three distinct structural morphologies, blobs, walls and filaments, we have to apply the segmentation process three times. However, since we shall be using curvature components as structural indicators, we shall have to eliminate the blobs before looking for filaments, and we shall then have to eliminate the filaments before looking for walls.
![\begin{figure}
\par\mbox{ \includegraphics[width=7.3cm,clip]{7880fig1a.eps} \includegraphics[width=7.3cm,clip]{7880fig1b.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg20.gif) |
Figure 1:
DTFE image of a slice through the N-body simulation used in this work.
Left: DTFE density field in a central slice. Right: the corresponding particle distribution in a slice of width
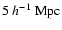 . . |
| Open with DEXTER |
3 Resampling and rescaling point sets
The cosmological problem presents its own difficulties, not the least of which is the fact that the data set is presented not as a density field, but as a set of discrete points which are presumed to sample some underlying density field. However, the filtering procedures we use here for defining objects act on continuous fields (or images) and require continuous first and second derivatives of field values. It is therefore necessary to resample the point set data on a grid. In doing this we need to assure ourselves that the objects, structures, features and patterns in these fields are resampled in an optimal way: both substructure and morphological characteristics must be preserved. To achieve this we use the DTFE reconstruction of the density field.
The Delaunay Triangulation Field Estimator ("DTFE'') (Schaap & van de Weygaert 2000; Schaap 2007) is a powerful new method, based upon concepts from computational geometry (Okabe et al. 2000) that offers a "safe'' reconstruction in that it accurately preserves the local features. DTFE produces a morphologically unbiased and optimized continuous density field retaining all features visible in a discrete galaxy or particle distribution.
The input samples for our analysis are mostly samples of galaxy positions obtained by galaxy redshift surveys or the positions of a large number of particles produced by N-body simulations of cosmic structure formation. In order to define a proper continuous field from discrete distribution of points - computer particles or galaxies - we translate the spatial point sample into a continuous density field by means of the Delaunay Tessellation Field Estimator (Schaap & van de Weygaert 2000; Schaap 2007).
The DTFE technique recovers fully volume-covering and volume-weighted continuous fields from a discrete set of sample field values. The method has been developed by
Schaap & van de Weygaert (2000, also see Schaap 2007) and forms an elaboration of the velocity interpolation scheme introduced by Bernardeau & van de Weygaert (1996). It is based on the use of the Voronoi and Delaunay tessellations of a given spatial point distribution. It provides a basis for a natural, fully self-adaptive filter in which the Delaunay tessellations are used as multidimensional interpolation intervals.
The primary ingredient of the DTFE method is the Delaunay tessellation of the particle distribution. The Delaunay tessellation of a point set is the uniquely defined and volume-covering tessellation of mutually disjunct Delaunay tetrahedra. A Delaunay tetrahedron is defined by the set of four points whose circumscribing sphere does not contain any of the other points in the generating set (Delaunay 1934) (triangles in 2D). The Delaunay tessellation is intimately related to the Voronoi tessellation of the point set, they are each others dual. The Voronoi tessellation of a point set is the division of space into mutually disjunct polyhedra, each polyhedron consisting of the part of space closer to the defining point than any of the other points (Okabe et al. 2000; Voronoi 1908).
DTFE exploits three particular properties of Voronoi and Delaunay tessellations. The tessellations are very sensitive to the local point density. The DTFE method uses this fact to define a local estimate of the density on the basis of the inverse of the volume of the tessellation cells. Equally important is their sensitivity to the local geometry of the point distribution, which allows them to trace anisotropic features such as encountered in the cosmic web. Finally it uses the adaptive and minimum triangulation properties of Delaunay tessellations to use them as adaptive spatial interpolation intervals for irregular point distributions. In this it is the first order version of the Natural Neighbour method (NN method: Watson 1992; Braun & Sambridge 1995; Sukumar 1998; Okabe et al. 2000; Sibson 1981,1980).
One of the important - and crucial - properties of a processed DTFE density field is that it is capable of delineating three fundamental characteristics of the spatial structure of the Megaparsec cosmic matter distribution. It outlines the full hierarchy of substructures present in the sampling point distribution, relating to the standard view of structure in the Universe having arisen through the gradual hierarchical buildup of matter concentrations. DTFE also reproduces any anisotropic patterns in the density distribution without diluting their intrinsic geometrical properties. This is a great advantage when seeking to analyze the cosmic matter distribution, characterized by prominent filamentary and wall-like components
linking up into a cosmic web. A third important aspect of DTFE is that it outlines the presence and shape of voidlike regions. DTFE renders the low-density regions as regions of slowly varying, moderately low density values through the interpolation definition of the DTFE field reconstruction.
An outline of the DTFE reconstruction procedure can be found in Appendix A.
In building the scale space we need to construct a hierarchy of rescaled replicas of the original grid-sampled data. In this paper this is done simply by applying a hierarchy of isotropic Derivative of Gaussian smoothing filters to the data.
Of course, substructure and morphological characteristics will be altered during this hierarchical smoothing process. The smearing of features through smoothing is inevitable if we smooth using isotropic filters and there has been some discussion as to whether one might do better by rescaling in such a way as to minimise feature smearing (for example Martínez et al. 2005; Saar et al. 2007). It is possible to use refined (nonlinear) smoothing procedures that minimize the side effects of smoothing but that issue is not addressed here. Here, we simply rescale using isotropic Gaussian filters: this seems to work very well and avoids complications arising from using other filters.
In this contribution we introduce a method for recognizing and identifying features in data based on the use of a "Scale Space'' representation of the data (Florack et al. 1992; Lindeberg 1998). The Scale Space representation of a data set consists simply of a sequence of copies of the data having different resolutions. A feature searching algorithm is applied to all of these copies, and the features are extracted in a scale independent manner by suitably combining the information from all copies.
We use a particular feature recognition process based on eigenvalues of the Hessian matrix of the density field. It should be understood that the technique we describe here could well be used with other feature recognition systems, such as, for example, the ShapeFinder process (Sahni et al. 1998). Scale Space is a powerful tool for scale independent data analysis.
The use of this technique can be traced back to the work of David Marr at M.I.T in the 1970's (Marr & Hildreth 1998), reviewed in his seminal book on the physiology of image understanding: Vision (Marr 1980). There (loc. cit. Chapter 2, especially
Figs. 2-10 and 2-23) he describes what is called the "Primal Sketch'' and the use of what today are called "Marr Wavelets'' in extracting scale independent information. We apply precisely this transformation to a scale space representation of a cosmological density field, and in doing so ostensibly extract features in much the same way, according to Marr, that the human visual cortex does.
More recently, Frangi et al. (1998) and Sato et al. (1998) used Scale Space analysis for detecting the web of blood vessels in a medical image. The vascular system is a notoriously complex pattern of elongated tenuous features whose branching make it closely resemble a fractal network. We translate, extend and optimize this technology towards the recognition of the major characteristic structural elements in the Megaparsec matter distribution. The resulting methodology yields a unique framework for the combined identification of dense, compact bloblike clusters, of the salient and moderately dense elongated filaments and of tenuous planar walls.
4.2 Multiscale structure identification
Segmentation of a density field into distinct, meaningful, components has been one of the major goals of
image processing over the past decades. There are two stages involved: firstly providing a criterion describing
the basis for the segmentation, be it colour, texture, motion or some other attribute and secondly providing
an algorithm whereby those distinguishing attributes can be automatically and unambiguously identified.
Ambiguities in structure finding frequently occur when the sought-for structure exists on a variety of
scales that may be nested hierarchically.
Maps used in morphological analysis.
The technique presented here, the Multiscale Morphology Filter (MMF), looks to synthesize global structures by identifying local structures on a variety of scales and assembling them into a single scale independent structural map. The assembly is done by looking at each point and asking which of the structures found on the various search scales dominates the local environment. This is the essence of the so-called Scale Space approach. We first provide an outline of the various stages involved with the MMF method. In the subsequent sections we treat various aspects in more detail.
We are looking for three distinct morphologies within the same distribution. This requires three passes through the data, each time eliminating the features found in the previous pass. In the first pass, the blobs in the dataset are identified along with their enclosed datapoints. The points that are in blobs are eliminated and then the filaments are identified with their constituent points. After eliminating the filament points the walls and their constituent points can be identified.
Each pass involves the following components and procedures:
- Point Dataset. For each pass this is the set of galaxies or particles in an N-body model from which we are going to extract a specified feature. In the first pass this is the full data sample within which we are going to identify blobs. On the second pass it is the original point set from which the points in the blobs have been removed. Likewise for the third pass.
-
- DTFE Density Field.
The discrete spatial distribution of galaxies, or particles in a N-body computer model, is resampled to give a continuous volume-filling density field map
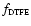 on a high resolution grid. In order to guarantee an optimal representation of morphological features this is accomplished on the basis of the DTFE method (Schaap & van de Weygaert 2000; Schaap 2007).
on a high resolution grid. In order to guarantee an optimal representation of morphological features this is accomplished on the basis of the DTFE method (Schaap & van de Weygaert 2000; Schaap 2007).
-
- Scale filtering.
The raw DTFE density field
is filtered over a range of spatial scales Rn in order to produce a family
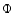 of smoothed density maps
of smoothed density maps
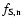 ,
each defining a level of the Scale-Space representation. The range of scales is set by the particular interest of the analysis.
,
each defining a level of the Scale-Space representation. The range of scales is set by the particular interest of the analysis.
-
- Hessian & Eigenvalues.
The Hessian matrix
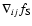 of the density field is computed at each point of each of the smoothed density fields in the filtered Scale-Space density maps
of the density field is computed at each point of each of the smoothed density fields in the filtered Scale-Space density maps 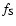 .
At each point the eigenvalues
.
At each point the eigenvalues
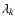 (k=1,2,3) of the Hessian matrix are determined.
(k=1,2,3) of the Hessian matrix are determined.
-
- Morphology Mask.
The Morphology Mask
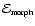 identifies the locations obeying the required morphology/shape constraints. At every location in every map,
identifies the locations obeying the required morphology/shape constraints. At every location in every map,
 if the shape constraint is valid,
if the shape constraint is valid,
 if it does not. This is a "hard'' filter.
if it does not. This is a "hard'' filter.
-
- Shape Significance Map.
A Feature shape Significance (or fidelity) index
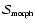 is determined for the specified morphology. This is done on the basis of the signs and ratios of the three eigenvalues
(k=1,2,3), and thus dependent only on the local variations of the field on the various scales present in the scale space maps.
is determined for the specified morphology. This is done on the basis of the signs and ratios of the three eigenvalues
(k=1,2,3), and thus dependent only on the local variations of the field on the various scales present in the scale space maps.
-
- Morphology Response Map.
The Morphology Response Filter,
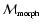 ,
is the soft thresholded version of the shape significance map
.
It selects out the most locally shape conformant features and is computed for each scale space level by processing
,
weighted by a specified threshold parameter
,
is the soft thresholded version of the shape significance map
.
It selects out the most locally shape conformant features and is computed for each scale space level by processing
,
weighted by a specified threshold parameter 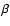 .
.
-
- Morphology Intensity Map.
In order to avoid enhancing noisy low intensity structures we include a Morphology Intensity function
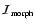 that modulates the morphology response map according to some measure of the feature strength. We characterise feature strength by the values of the specifc eigenvalues:
that modulates the morphology response map according to some measure of the feature strength. We characterise feature strength by the values of the specifc eigenvalues: 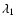 for the walls,
for the walls, 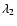 for the filaments and
for the filaments and 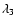 for the blobs.
for the blobs.
-
- Morphology Filter.
Morphology weighted filter
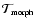 for the Morphology Mask
.
Provides each location which obeys the morphology constraint with a measure of the strength of morphology signal.
for the Morphology Mask
.
Provides each location which obeys the morphology constraint with a measure of the strength of morphology signal.
-
- Feature Map.
For each level of Scale-Space the feature map
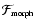 is constructed from the Feature Intensity Map
and the Morphology Response Map. This represents local structures as seen on the different scales of the Scale-Space.
is constructed from the Feature Intensity Map
and the Morphology Response Map. This represents local structures as seen on the different scales of the Scale-Space.
-
- Scale-Space Map Stack.
By combining the individual Feature Maps
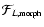 of each level of Scale-Space, the ultimate scale independent map of features is produced, the Scale-Space Map Stack
of each level of Scale-Space, the ultimate scale independent map of features is produced, the Scale-Space Map Stack  .
Each pixel in this map is the maximum value of the corresponding pixels in the Feature maps that make up the Scale-Space stack.
.
Each pixel in this map is the maximum value of the corresponding pixels in the Feature maps that make up the Scale-Space stack.
-
- Object Maps.
Astrophysical and Cosmological criteria determine the final Object Maps
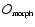 .
These maps are produced by thresholding the Scale-Space Map Stack
according to a criterion translating a feature map of physically recognizable objects.
.
These maps are produced by thresholding the Scale-Space Map Stack
according to a criterion translating a feature map of physically recognizable objects. -
- Datapoint identification.
Datapoints within the feature contours of the object map
are identified. They are removed from the original dataset at each pass through the feature finding process.
![\begin{figure}
\par\includegraphics[width=18cm,clip]{7880fig2.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg47.gif) |
Figure 2:
Scale-space: a particle distribution ( left) is translated by DTFE into a density field ( centre),
followed by the determination of the field, by means of filtering, at a range of scales ( righthand). |
| Open with DEXTER |
5 Scale space technology
The so-called Scale-Space approach to morphology consists simply of calculating and comparing morphology indicators on a variety of scales. Fundamental in this is the ability to view a given dataset on different scales. This task is accomplished simply by convolving the original
data
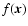 with smoothing filters W to produce a smoothed field
with smoothing filters W to produce a smoothed field
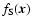 :
:
The smoothing filter could be any of a number of suitable filters: it is usual, though neither necessary nor optimal, to choose filters based on Gaussian functions. There are alternatives to this scaling strategy: any form or pyramidal or wavelet transform will have a similar effect.
In this paper we generate scaled representations of the data by repeatedly smoothing the DTFE reconstructed density field
with a hierarchy of spherically symmetric Gaussian filters 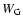 having different widths R:
having different widths R:
where
denotes a Gaussian filter of width R:
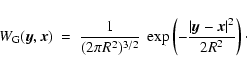 |
(1) |
A pass of the smoothing filter attenuates structure on scales smaller than the filter width.
The scale-space MMF analysis described in this study involves a discrete number of N+1 levels,
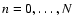 .
Following Sato et al. (1998) we use a nested hierarchy of filters having widths differing by a factor of
.
Following Sato et al. (1998) we use a nested hierarchy of filters having widths differing by a factor of 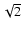 :
:
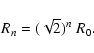 |
(2) |
The base-scale R0 is taken to be equal to the pixel scale of the raw DTFE density map. Sato et al. (1998) showed that using a ratio of
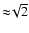 between discrete levels involves a deviation of a mere
between discrete levels involves a deviation of a mere 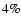 with respect to the ideal case of a continuum of scale-space
levels
with respect to the ideal case of a continuum of scale-space
levels![[*]](/icons/foot_motif.gif) . As a retrospective on this research we would argue that, in the context of cosmic structure, the factor of
is somewhat too coarse.
. As a retrospective on this research we would argue that, in the context of cosmic structure, the factor of
is somewhat too coarse.
The largest structure that survives this process is determined by the effective width of the filter used in the final smoothing stage. For our purposes it is sufficient to use n=5.
We shall denote the 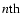 level smoothed version of the DTFE reconstructed field
by the symbol fn.
level smoothed version of the DTFE reconstructed field
by the symbol fn.
The Scale Space itself is constructed by stacking these variously smoothed data sets, yielding the family
of smoothed density maps fn:
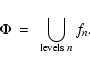 |
(3) |
A data point can be viewed at any of the scales where scaled data has been generated. The crux of the concept is that the neighbourhood of a given point will look different at each scale. There are potentially many ways of making a comparison of the scale dependence of local environment. We chose here to use the Hessian Matrix of the local density distribution in each of the smoothed replicas of the original data.
![\begin{figure}
\par\includegraphics[width=18cm,clip]{7880fig3.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg61.gif) |
Figure 3:
Maps of the eigenvalues of the Hessian matrix at 3 different scales (levels).
From top to bottom: the 3 eigenvalues
,
and
(
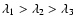 ).
From left to right: 3 different scales R1R3 and R5, (
R1>R2>R5). Positive values are represented as gray shades in logarithmic scale while negative values are indicated by contour lines also in logarithmic scale. ).
From left to right: 3 different scales R1R3 and R5, (
R1>R2>R5). Positive values are represented as gray shades in logarithmic scale while negative values are indicated by contour lines also in logarithmic scale. |
| Open with DEXTER |
At each point of each dataset in the Scale Space view of the data we can quantify the local "shape" of the density field in the neighbourhood of that point by calculating, at each point the eigenvalues of the Hessian Matrix of the data values.
We can express the local variations around a point 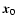 of the density field
as a Taylor expansion:
of the density field
as a Taylor expansion:
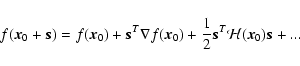 |
(4) |
where
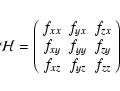 |
(5) |
is the Hessian matrix. Subscripts here denote partial derivatives of f with respect to the named variable. There are many possible algorithms for evaluating these derivatives.
In our case we compute the scale-space Hessian matrices for each level n directly from the DTFE density field, via the convolution
where
x1,x2,x3=x,y,z and
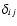 is the Kronecker delta. In other words, the scale space representation of the Hessian matrix for each level n is evaluated by means of a convolution with the second derivatives of the Gaussian filter, also known as the Marr (or, less appropriately, "Mexican Hat'') Wavelet.
is the Kronecker delta. In other words, the scale space representation of the Hessian matrix for each level n is evaluated by means of a convolution with the second derivatives of the Gaussian filter, also known as the Marr (or, less appropriately, "Mexican Hat'') Wavelet.
In order to properly compare the values of the Hessian arising from the differently scaled variants of the data that make up the Scale Space we must use a renormalised Hessian:
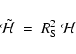 |
(7) |
where 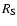 is the filter width that has been used (
is the filter width that has been used (
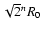 for level n in our case). Instead of using this "natural'' renormalization, it would be possible to use a scaling factor
for level n in our case). Instead of using this "natural'' renormalization, it would be possible to use a scaling factor
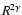 .
Using values
.
Using values
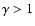 will give a bias towards finding larger structures, while values
will give a bias towards finding larger structures, while values
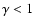 will give a bias towards finding smaller structures.
will give a bias towards finding smaller structures.
The eigenvalues of the Hessian matrix evaluated at a point quantify the rate of change of the field gradient in various directions about each point
(Fig. 3). The eigenvalues are coordinate independent measures by the components of the second derivatives of the field at each point .
A small eigenvalue indicates a low rate of change of the field values in the corresponding eigen-direction, and vice versa.
We denote these eigenvalues by
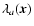 and arrange them so that
and arrange them so that
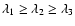 :
:
The
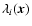 are coordinate independent descriptors of the behaviour of the density field in the locality of the point
are coordinate independent descriptors of the behaviour of the density field in the locality of the point 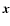 and can be combined to create a variety of morphological indicators. The criteria we used for identifying a local bloblike, filamentary or sheetlike
morphology are listed in Table 1. A similar philosophy was also followed by Colombi et al. (2000) and Doré et al. (2007). The corresponding eigenvectors
show the local orientation of the morphology characteristics. Note, however, that in this study we do not make use of the eigenvectors.
and can be combined to create a variety of morphological indicators. The criteria we used for identifying a local bloblike, filamentary or sheetlike
morphology are listed in Table 1. A similar philosophy was also followed by Colombi et al. (2000) and Doré et al. (2007). The corresponding eigenvectors
show the local orientation of the morphology characteristics. Note, however, that in this study we do not make use of the eigenvectors.
![\begin{figure}
\par\mbox{\includegraphics[width=17cm]{7880fig4.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg83.gif) |
Figure 4:
Morphology Mask
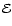 :
on the basis of the 3 eigenvalues ,
and
at each location we
determine whether the morphological criterion - here whether it corresponds to a filament (Table 1) - is valid. If so
,
otherwise it is
.
Top row: maps of the three eigenvalues;
bottom row: the Morphology Mask
. :
on the basis of the 3 eigenvalues ,
and
at each location we
determine whether the morphological criterion - here whether it corresponds to a filament (Table 1) - is valid. If so
,
otherwise it is
.
Top row: maps of the three eigenvalues;
bottom row: the Morphology Mask
. |
| Open with DEXTER |
Table 1:
Eigenvalue relationships defining the characteristic morphologies. The
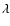 -conditions describe objects with intensity higher than their
local background as clusters, filaments or walls. For voids we would have to reverse the
sign of the eigenvalues.
-conditions describe objects with intensity higher than their
local background as clusters, filaments or walls. For voids we would have to reverse the
sign of the eigenvalues.
The eigenvalues of the Hessian therefore encode the local morphology of the density field in terms of the curvature components of the local density field in the direction of the corresponding eigenvectors. Evaluating the eigenvalues and eigenvectors for the renormalised Hessian
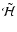 of each dataset in a Scale Space shows how the local morphology changes with scale (Fig. 3).
of each dataset in a Scale Space shows how the local morphology changes with scale (Fig. 3).
With the local curvature and shape encapsulated in the three eigenvalues ,
and
of the Hessian, the MMF seeks to identify the regions in space which correspond to a certain morphology and at the scale at which the corresponding morphology signal attains its optimal value. First we set out to select these regions by means of a Morphology Mask. Subsequently we develop a filter-based procedure for assigning at each scale a local weight which is used to select the scale at which the morphology reaches its strongest signal.
Locally "spherical'' topology is indicated by all three eigenvalues being similar in size, and locally "filamentary'' topology is indicated by having two similar eigenvalues and a negligible third; the direction of the filamentary structure is then in the direction of the eingenvector corresponding to the smallest (insignificant) eigenvalue. A locally "sheet-like' structure is characterised by one dominant eigenvalue, its corresponding eigenvector indicating the normal to the sheet. The formal morphology conditions are listed in Table 1.
There are many ways of using the eigenvalues of the Hessians in the Scale Space representation of the data to identify and demarcate specific types of structure. Here we start by defining a morphology mask. The Morphology Mask
is a hard filter which identifies all pixels obeying the morphology and shape condition:
See Fig. 4 to see how this works.
![\begin{figure*}
\par\includegraphics[width=17cm,clip]{7880fig5.eps}
\end{figure*}](/articles/aa/full/2007/40/aa7880-07/Timg93.gif) |
Figure 5:
Morphology Filter
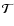 .
The Morphology Response function .
The Morphology Response function
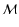 ( top centre) is the soft thresholded version of the Shape Significance map
( top centre) is the soft thresholded version of the Shape Significance map
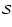 ( left frame), determined from the values of the eigenvalues ,
and .
The Morphology Intensity function
( left frame), determined from the values of the eigenvalues ,
and .
The Morphology Intensity function
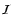 ( bottom centre) is also computed from the 's using Eq. (11). Finally, the Morphology Filter
( right frame) is obtained by combining
with
.
( bottom centre) is also computed from the 's using Eq. (11). Finally, the Morphology Filter
( right frame) is obtained by combining
with
. |
| Open with DEXTER |
The degree of ``blobbiness'', ``filamentariness'' or "wallness'' is reflected in the degree to which the inequalities of Table 1 defining those structures are satisfied. We would be impressed by a blob in which all three eigenvalues were equal - it would look like a spherical lump. We would be less impressed if there was a factor 3 between the eigenvalues since the blob would then look more like a flattened sausage while not manifestly being a filament or a wall.
The following shape indices reflect the strength
of the classification in terms of the local geometry as characterised by the 's.
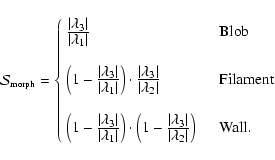 |
(9) |
It is important to emphasise when using this equation that the values of
are only meaningful if the relevant inequalities in Table 1 are already satisfied.
![\begin{figure}
\par\includegraphics[width=16.7cm,clip]{7880fig6.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg95.gif) |
Figure 6:
The Feature Map
 ( righthand frame) is computed for each scale and is equal to the Morphology Filter
at the locations where the Morphology Mask
is unity (and nonzero).
( righthand frame) is computed for each scale and is equal to the Morphology Filter
at the locations where the Morphology Mask
is unity (and nonzero). |
| Open with DEXTER |
As a cautionary warning it must be stressed that we cannot identify a point as being part of a locally filamentary structure and assess the significance by using an evaluation of
that applies to blobs or walls. Likewise the value of
cannot be used to assess the relative significance of different types of structure. This means that the identification of structural elements using this eigenvalue classification scheme must be done cyclically: first find blobs (three roughly equal eigenvalues), then lines (two roughly equal and dominant eigenvalues) and finally walls (one dominant eigenvalue). There are other schemes that are one-pass classifiers.
We shall use the symbols
 ,
,
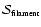 ,
,
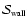 to denote the values of
computed for each kind of feature.
to denote the values of
computed for each kind of feature.
We shall need a filter that preferentially selects out points where the value of the feature shape parameter
lies above some threshold. With this we can tune the aggressiveness of feature-selection. This can be done by defining a morphology measure
by
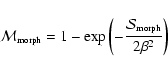 |
(10) |
where morph = (blob, filament, or wall). The adjustable parameter
tunes the discrimination level of the morphology response filter. A typical value is
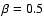 .
Lower values will increase the feature selectivity. Higher values will decrease the selectivity giving feature images with smooth features but contamination from other morphologies.
.
Lower values will increase the feature selectivity. Higher values will decrease the selectivity giving feature images with smooth features but contamination from other morphologies.
We shall use the symbols
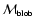 ,
,
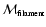 ,
,
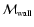 to denote the values of
computed for each kind of feature.
to denote the values of
computed for each kind of feature.
Methods of thresholding image data such as Eq. (10) are generally referred to as "soft thresholding'', as opposed to "hard thresholding'' in which all values below a critical value are zeroed. Soft thresholding results in visually more appealing density distributions. See Fig. 5.
Morphology Intensity is a property of structures that represents how strong the feature is: a filament that is nice and narrow is in some sense more filament-like than one which is rather wide and diffuse.
The discriminating factor in this case is the magnitude of the eigenvalue .
Note that it would be inappropriate to normalise or non-dimensionalize this relative to some local values such as the sum of the local 's:
it is the fact of comparing the
values at different spatial locations that discriminates features.
If, in our example, the value of
were roughly constant over the data set, we would not be impressed by any filamentariness.
Qian et al. (2003) noted that the smallest eigenvalue ()
will be large only for blobs, while
will be large for blobs and filaments, and
for blobs, filaments, and walls. Combining these relations with the
constraints in table 1 (3rd column) we
can use the following intensity function:
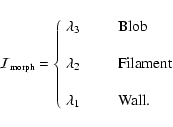 |
(11) |
The use of this morphology intensity function solves the problem of detecting low-intensity/noisy structures but it introduces another problem: the range of values of
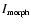 is not well defined within a given interval since it depends on the nature of the density field itself. We therefore normalise its values in the interval [0,1] in order to apply it in a consistent way.
is not well defined within a given interval since it depends on the nature of the density field itself. We therefore normalise its values in the interval [0,1] in order to apply it in a consistent way.
There are other posible measures of feature intensity.
Frangi et al. (1998) introduced the Frobenius matrix
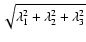 as a measure of second-order structure. However, this measure is biased towards blob-like structures and can produce erroneous signals in the detection of filaments and walls.
as a measure of second-order structure. However, this measure is biased towards blob-like structures and can produce erroneous signals in the detection of filaments and walls.
For each level of the scale space, we can generate a Morphology Filter,
,
from the Morphology Intensity Map
and Morphology Response Filter
.
Formally we can write this as
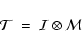 |
(12) |
where the combination operator 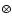 simply means that every pixel of the Morphology Intensity Map,
,
is multiplied by the value of the corresponding pixel in the Morphology Response Filter
.
As described above, these hold information on different aspects of the structural morphology, and by combining them we can hope to improve on the results that would be obtained by using either of them alone. Thus the Morphology Filter has its most significant values at those places where the morphology is close to what we are looking for.
simply means that every pixel of the Morphology Intensity Map,
,
is multiplied by the value of the corresponding pixel in the Morphology Response Filter
.
As described above, these hold information on different aspects of the structural morphology, and by combining them we can hope to improve on the results that would be obtained by using either of them alone. Thus the Morphology Filter has its most significant values at those places where the morphology is close to what we are looking for.
![\begin{figure}
\par\includegraphics[width=16.5cm,clip]{7880fig7.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg109.gif) |
Figure 7:
The Scale Space Map Stack :
the formalism selects at any location the scale with the optimal signal
of the feature map. Depicted are the Feature maps
for three different scales
( top row), and the
resulting Map Stack
( bottom row), determined over the full range of scales. |
| Open with DEXTER |
This is where, for each level of scale space, we combine information contained in the morphology mask
and filter
:
we select out those regions of
where the morphology constraint is valid.
For each level of the scale space, we can generate a Feature Map,
.
The feature map comprises the information
contained in the Morphology Filter
and allocates it to the locations contained in the Morphology Mask
.
Formally we can write this as
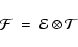 |
(13) |
where the combination operator
simply means that every pixel of the Morphology Filter,
,
is modulated by the mask value
,
1 or 0 dependent on whether the morphology constraint is valid at the corresponding location. See Fig. 6.
Each level of the scale space has its Feature Map constructed according to
Eq. (13). They must now be combined in order to produce the definitive scale independent map of features, .
We can refer to
as the "feature stack'' and formally write it as
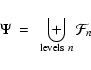 |
(14) |
where the combination operator 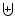 represents a new Feature Map built by combining the individual Feature Maps,
represents a new Feature Map built by combining the individual Feature Maps,
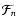 ,
of the scale space. Each pixel of
takes on the maximum value of the corresponding pixel values in the stack of Feature Maps
in the Scale Space. We can write this (for a 3D map) as
,
of the scale space. Each pixel of
takes on the maximum value of the corresponding pixel values in the stack of Feature Maps
in the Scale Space. We can write this (for a 3D map) as
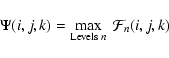 |
(15) |
where i,j,k represent the location of the pixels in the map. In this way we assign each point of the dataset a value quantifying the degree to which it can be said to be a part of some feature (blob, filament, or wall) on any of the scales investigated by the scale space. See Fig. 7.
The Scale Space Map Stack
has to be thresholded in order to identify the most significant features. This will be discussed in detail in Sect. 7. It is at this point that we see astronomical input by requiring that the sought-after structure correspond to some structure that we would recognise.
Given the Scale Space Map Stack
for a given feature (blobs, filaments or walls), we can assign each particle of the original dataset to the specific feature identified in the Scale Space Map Stack.
7 Cosmological feature detection: threshold definition
The final stage of each cycle of the analysis is the thresholding of the scale space map stack in order to identify individual objects that are being sought in that cycle. Without the thresholding the maps are noisy and over-structured: we can refer to this as as "texture noise''. This texture noise is simplest removed by applying a simple threshold to the processed maps. There is a potential problem in applying a simple threshold: it is necessary to determine a threshold that removes texture noise (however that is determined) while leaving the sought-after features intact.
We set the thresholds for each feature to the value such that raising the threshold higher would start eroding objects and decrease their number. In other words, the threshold value is set so that the object count is maximised while at the same time texture noise is eliminated.
We use
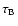 to denote the value of
above which a pixel is considered as part of a blob. Figure 8a plots the number of objects detected above each value of the threshold,
.
to denote the value of
above which a pixel is considered as part of a blob. Figure 8a plots the number of objects detected above each value of the threshold,
.
For blob finding the thresholding is quite straightforward. At very low threshold, there will be many round objects (the eigenvalue criterion fixes their shape) of which only a small fraction will be the blobs we are seeking. As the threshold is raised from zero, the noise and the the less significant blobs are eliminated. There comes a point when the threshold stops annihilating these small, less significant, blobs and simply starts eroding the large blobs. This is the point where we define out optimal threshold. The dotted vertical line indicates the best value of
.
If we plot a graph of the fraction of the sample volume occupied by below-threshold blobs against the threshold we obviously find a monotonic curve that rises from zero to one. This is shown in Fig. 8a where we see a two power-law behaviour with a break marking where the transition from texture noise annihilation to simple blob erosion takes place.
![\begin{figure}
\par\subfigure[Threshold determination for blobs.]
{ \mbox{\hski...
...0truecm\includegraphics[width=0.71\linewidth]{7880fig8c.eps} }
}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg116.gif) |
Figure 8:
Thresholds for feature isolation based on the feature erosion criterion. The selected value is shown as a dotted vertical line. The object count to the right of the line declines due to erosion. |
| Open with DEXTER |
For filament and wall finding we again choose to threshold the distributions, but this time we decide on the optimal value of the threshold on the basis of the population curve of features defined at each threshold value.
We use
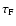 to denote the value of
above which a pixel is considered as part of a filament. Figure 8b plots the normalised number of objects detected for each value of the threshold,
.
to denote the value of
above which a pixel is considered as part of a filament. Figure 8b plots the normalised number of objects detected for each value of the threshold,
.
The explanation for the shape of this curve is as follows. The low threshold (small-
)
objects are largely due to texture noise: the number of these declines as the threshold increases. When real filamentary features appear the number of detections increases with
to reach a maximum. This is because at lower thresholds the features tend to percolate, so that raising the threshold breaks the structure up into a greater number of filamentary objects. As the threshold rises further the filaments are eroded and get rarer. The point at which filament erosion starts to act is taken as the optimal value of
.
This is indicated by the dotted line in the figure.
We use
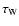 to denote the value of
above which a pixel is considered as part of a wall. Figure 8c plots the normalised number of objects detected for each value of the threshold,
.
to denote the value of
above which a pixel is considered as part of a wall. Figure 8c plots the normalised number of objects detected for each value of the threshold,
.
The threshold for defining walls is determined in the same way as for filaments. Note, however, that the particles classified as lying in blobs and filaments have been removed in previous cycles of the analysis so there is no longer a significant texture noise component. As the threshold is varied there is a peak in the number of walls that are found. At thresholds below this critical value the walls join up and percolate, eventually leaving one vast percolating structure. At higher threshold values walls are eroded and eventually destroyed. The dotted vertical line indicates the best value of
.
We have described the process of constructing a Feature Map and identifying features in that map. However there is a complication that arises in practise because both the Intensity Map and the Morphology Filter are built on a hierarchy of
values. In the case of the Morphology Filter, the different 's come in through
Eqs. (9) and (10). In the case of the Intensity Map, different 's define the strength of different features as described in Eq. (11).
The analysis cycle can be expressed in pseudo-code (see accompanying code in next column). In this form of pseudo-code, keywords
(which correspond to class methods in object oriented programming) are in boldface.
The nature of the hierarchy is such that we have first to identify blobs, remove them from the sample, then identify filaments, and after removing them from the sample finally identify the walls. This arises because data points in blobs are defined by having three significant eigenvalues, data points in filaments are defined by having two significant eigenvalues, and data points in walls have only one significant eigenvalue. Identifying a filament before eliminating blobs would not work since the blobs would be more strongly detected.
8 Areas of further development
The methodology we have presented is very simple, yet, as we shall see, it is highly effective in differentiating the three main structural features that make up the cosmic web. The following section will test the methodology against a sample with controlled clustering: the Voronoi model, and present results for an N-Body simulation. Before going on to that analysis it is worth making a few remarks about some details of our procedure that might be enhanced.
Code 1: Pseudocode MMF procedure.
get PointSet
set Feature = Blobs
: Map_Feature
resample PointSet to Mesh using DTFE
construct ScaleSpace Hierarchy
for each Level in ScaleSpace
{
build Hessian Eigenvalue Maps
build using Eigenvalue Criteria for Feature
{
Morphology Mask,
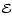 Feature Shape Fidelity,
Feature Shape Fidelity,
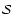 Morphology Response Filter,
Morphology Response Filter,
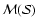 Feature Intensity Map,
Feature Intensity Map,
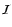 }
}
generate
{
Morphology Filter,
 Feature Map,
Feature Map,
 }
}
}
stack ScaleSpace Feature Maps,
 threshold Feature Maps using Feature Threshold Method
threshold Feature Maps using Feature Threshold Method
in thresholded regions
{
identify Points
publish Points
remove Points from PointSet
}
if Feature = Blobs
set Feature = Filaments
else if Feature = Filaments
set Feature = Walls
else
quit
goto Map_Feature
Our use of isotropic Gaussian filters is perhaps the most important limiting factor in this analysis. The largest filter radius
which is chosen is substantially smaller than the lengths of the typical filaments. Only the shorter filaments will get isotropised and they are "lost'' since they make no contribution in the scalespace stack. Our algorithm is indeed a long thin filament finder. The main side-effect of the Gaussian smoothing is to make the profile (perpendicular to the filament) of the sharper (narrow) filaments Gaussian. A narrow filament having high density contrast will, under linear Gaussian smoothing, spill over into the large scales at a variety of thresholds and it will appear to be fatter than it really is. This latter problem is a consequence of applying simple linear filters: it is generally overcome within the scale space context by using nonlinear filters or by using wavelets (Martínez et al. 2005; Saar et al. 2007)
Another area for improvement is to use the eigenvectors as well as the eigenvalues themselves. Here we have simply relied on the relative magnitudes of the eigenvalues as indicators of curvature morphology. Had the eigenvectors themselves been uncorrelated we might have concluded that there was structure when in fact there was only noise: the eigenvector correlations are good indicators of noise.
A third area for improvement would be to use anisotropic smoothing filters. This leads us into another related approach to this problem: the use of nonlinear diffusion equations to locate structural features. This will be the subject of another article later on.
9 Voronoi clustering models
To test and calibrate the Multiscale Morphology Filter we have
applied the MMF to a set of four Voronoi Element Models.
These models combine the spatial intricacies of the cosmic web with
the virtues of a model that has a priori known properties. They are particularly
suited for studying systematic properties of spatial galaxy distributions confined
to one or more structural elements of nontrivial geometric spatial patterns.
The Voronoi models offer flexible templates for cellular patterns, and they are easy to
tune towards a particular spatial cellular morphology. In the case of the Voronoi models
we have exact quantitative information on the location, geometry and identity of the
spatial components against which we compare the outcome of the MMF analysis.
Voronoi Clustering Models are a class of heuristic models for
cellular distributions of matter van de Weygaert (2002,1991). They use
the Voronoi tessellation as the skeleton of the cosmic matter distribution,
identifying the structural frame around which matter will gradually assemble
during the emergence of cosmic structure (Okabe et al. 2000; Voronoi 1908). The interior of
Voronoi cells corresponds to voids and the Voronoi planes with sheets of
galaxies. The edges delineating the rim of each wall are
identified with the filaments in the galaxy distribution. What is
usually denoted as a flattened "supercluster'' will comprise an
assembly of various connecting walls in the Voronoi foam, as elongated
"superclusters'' of "filaments'' will usually consist of a few
coupled edges. The most outstanding structural elements are the vertices, corresponding to the very dense compact nodes within the
cosmic web, rich clusters of galaxies.
A more detailed description of the model construction may be found in Appendix B.1.
We distinguish two different yet complementary approaches, Voronoi Element Models and
kinematic Voronoi models.
Simple Voronoi models confine their galaxy distributions to one of the
distinct structural components of a Voronoi tessellation:
-
- Field. Particles located in the interior of Voronoi cells
(and thus randomly distributed across the entire model box).
-
- Wall. Particles within and around the Voronoi walls.
-
- Filament. Particles within and around the Voronoi edges.
-
- Blobs. Particles within and around the Voronoi vertices.
Starting from a random initial distribution of N points, these galaxies are projected onto
the relevant wall, edge or vertex of the Voronoi cell in whose interior they are initially located.
![\begin{figure}
\par\includegraphics[width=16.7cm,clip]{7880fig9.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg126.gif) |
Figure 9:
Recovered particles in Blobs, Filaments and Walls from a voronoi particle distribution.
Particles inside blobs are detected ( left), at 90/15 percent real/false detections.
From the new blob-free distribution we detect particles in filaments ( center)
at 90/10 percent real/false detections. Finally the blob-filament-free distribution
is used to find the particles inside walls ( right) at 80/10 percent real/false detections. |
| Open with DEXTER |
For our study we generated four different Voronoi clustering models, labelled as A, B, C and D.
They are all based upon a Voronoi tessellation generated by M=53 nuclei distributed within a box of size
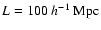 .
The models are composite Voronoi Element Models and consist of the superposition
of galaxies located in field, walls, edges and vertices of a Voronoi tessellation. Our four test models
contain N=323 galaxies. The fraction of galaxies in the various components is a key parameter of the
model, and is specified in Table 2. In and around the walls, edges and
vertices the galaxy distribution follows a radial Gaussian density profile, with scale factors
.
The models are composite Voronoi Element Models and consist of the superposition
of galaxies located in field, walls, edges and vertices of a Voronoi tessellation. Our four test models
contain N=323 galaxies. The fraction of galaxies in the various components is a key parameter of the
model, and is specified in Table 2. In and around the walls, edges and
vertices the galaxy distribution follows a radial Gaussian density profile, with scale factors
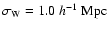 ,
,
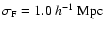 and
and
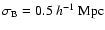 .
.
Table 2:
Voronoi Clustering Models. Percentage of galaxies/points in the various
morphological elements of the model.
A considerable virtue of the Voronoi clustering models is that it is a priori known which galaxies
reside in the various morphological components of the Voronoi test models. This allows an
evaluation of the absolute performance of the MMF and other morphology detection techniques
by determining the fraction of the galaxies which are correctly identified as vertex, filament
and wall galaxy.
For each Voronoi model we computed the DTFE density field from the particle distribution
and applied the MMF. Following our previously described scheme, we first identified the blobs from the
complete particle distribution. After removal of the blob particles, the filaments
are found. Following the equivalent process for the filaments, the last step of
the MMF procedure concerns the identification of the wall particles. The remaining
particles are tagged as field particles.
Figure 9 shows the outcome of the MMF applied to
Voronoi Model C. Visually, the resemblance between real and MMF identified blob,
filament and wall particles is remarkably good. The second row of panels shows the real
detections of MMF: MMF clearly manages to identify all clusters, filaments and
even the more tenuous walls in the weblike galaxy distribution. The false detections do
appear to have a somewhat broader spatial distribution than those of the corresponding
real detections. Most of them reside in the boundary regions of the blobs, filaments and
walls: they are mainly an artefact due to the fact that the effective extent of the MMF
morphology masks is slightly larger than the intrinsic extent of the Voronoi components.
Fine-tuning of the filter scales (Eq. (1)) is a potential solution for
curing this artefact.
![\begin{figure}
\par\includegraphics[width=17.5cm,clip]{7880fig10.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg131.gif) |
Figure 10:
Reals versus false detections for different voronoi models (see Table 2)
(A: solid, B: dotted, C: dashed, D: dotted-dashed) for blobs ( left), filaments ( center) and
walls ( right). We applied the MMF (black) and simple density thresholding (grey) in
order to compare both methods. |
| Open with DEXTER |
The detection rate of blob, filament and walls galaxies is determined and
defined as follows. The galaxies in an MMF blob, filament or wall Map Stack which are genuine Voronoi cluster, filament or wall galaxies are tagged as real
detections. A galaxy detected by one of the three map stacks
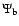 ,
,
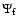 or
or
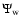 intrinsically belonging to another morphological component is considered
a false detection. For instance, a filament galaxy detected by
is a false blob galaxy.
intrinsically belonging to another morphological component is considered
a false detection. For instance, a filament galaxy detected by
is a false blob galaxy.
The main tunable parameters for optimizing the number of detected galaxies are
blob, filament and wall threshold values,
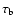 ,
,
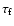 and
and
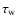 .
By lowering the blob threshold level
,
defined through a
regular density threshold (see Sect. 7), the number of
MMF detected blob galaxies increases. The same holds for adjusting the filament
and wall thresholds, in terms of the lowering of the
and
levels. The galaxies detected by MMF include both real and
false detections. As the threshold levels are adjusted the
number of both will tend to increase.
.
By lowering the blob threshold level
,
defined through a
regular density threshold (see Sect. 7), the number of
MMF detected blob galaxies increases. The same holds for adjusting the filament
and wall thresholds, in terms of the lowering of the
and
levels. The galaxies detected by MMF include both real and
false detections. As the threshold levels are adjusted the
number of both will tend to increase.
The detection rate at a given threshold level is the fraction of genuine
blob, filament or wall galaxies which have been detected by the MMF. Ideally
one would want to trace them all and have a 100% detection rate, in practice
this is set by the the applied threshold. Based upon the 1-1 relation between
,
and
on the one hand and the corresponding blob, filament
and wall detection rate on the other we use the detection rate as threshold
parameter.
The ratio of the corresponding number of false blob galaxies to the
total number of genuine blob galaxies is the blob contamination rate
rate. The filament and wall contamination rate are defined in a similar
way. Because a lowering of the threshold levels will result in a larger
number of detections, both real and false, the contamination
rate will be an increasing function of the detection rate. Note that the
contamination rate may exceed 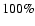 in the case the number of false
detections exceeds that of the total number of genuine (blob, filament or
wall) galaxies.
in the case the number of false
detections exceeds that of the total number of genuine (blob, filament or
wall) galaxies.
We compare the MMF segmentation of the Voronoi models in blobs, filaments and walls
with that achieved by a more direct criterion, that of a straightforward density
threshold on the DTFE density field. We assign the label "DTC" to this naive procedure.
Each of the morphological elements are identified with a particular (disjunct) range of density values. Blobs, ie. clusters, are identified with the highest density values. Filaments are associated with more moderately high density values. Walls follow with density values hovering around unity to a few, while the field/voids may include densities down to a zero value. This approach has frequently been used to discriminate between virialized haloes and the surrounding matter distribution, and has even been used in an attempt to define filamentary or planar features (Dolag et al. 2006). However, it seriously oversimplifies and distorts the perceived structure of the cosmic web. (This is presumably because filaments and walls differ in density and have significant internal density structure. The simplistic density threshold approach does not reflect the reality of the structure: the range of densities in filaments overlaps with densities in walls and even with those of the outskirts of clusters. (Hahn et al. 2007) reach similar conclusions.
Figure 10 compares the contamination rate as a function
of the detection rate for the four different Voronoi models. The A, B, C and
D models are distinguished by means of line style. The black lines relate to the MMF detections,
the grey lines show the results of the equivalent DTC procedure. We find the following:
-
- For all models, and for all morphologies, the MMF procedure is clearly
superior to the DTC detections in suffering significantly lower contamination rates.
-
- The MMF contamination is least for the blob detections. The
filament contamination is lower than the wall contamination for models with many
intrinsic filament galaxies (A and C). For models B and D, containing more
wall galaxies, the situation is the reverse. The same holds true for the DTC
detections, be it much more pronounced and less favorable wrt. the MMF detections.
-
- The MMF and DTC blob contamination rate is more favorable for the
A and B models. Both models contain a relatively high fraction of blob galaxies.
-
- The DTC blob contaminations are surprisingly bad, given that
clusters are compact objects of high density with sharply defined boundaries.
-
- The filament contamination rate is worse for models B and D,
both marked by a relatively low amount of intrinsic filament galaxies. This is true
for both DTC and MMF.
-
- The DTC contamination is extremely bad for models B and D, quickly
exceeding .
This reflects the huge overlap in density range of filaments and
other morphologies resulting in a systematic inclusion of particles belonging
to other morphologies.
-
- For the MMF procedure there is a clear correlation between the
intrinsic wall galaxy fraction and the contamination rate: model D has the highest
number of wall galaxies and the lowest contamination. This is not true for DTC.
In summary, we find that MMF clearly performs much better in tracing blob, filament and
wall galaxies than a pure threshold criterion would allow. By comparing Voronoi models
A, B, C and D we find that MMF performs better for components which are relatively more
prominent. Because of the mixture in densities between blobs, filaments and walls this is
not necessarily true when using a simple density criterion. The latter involves
often excessive levels of contamination between galaxies in different morphological
entities. If anything, this is perhaps the strongest argument for the use of the shape
and morphology criteria enclosed in the MMF.
![\begin{figure}
\par\includegraphics[width=16.5cm,clip]{7880fig11.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg139.gif) |
Figure 11:
MMF applied to N-body simulation. The top row shows a subsample a) consisting of 10 of the total number of particles together with, in panels b) and c), the structures resulting from simple density thresholding using two different thresholds.
Panels b) and c) both contain both spherical and elongated structures: there is a large amount of cross contamination between morphologies. Simple density thresholding is not an effective morphological discriminator. The second row shows the results of applying the MMF procedure showing clearly segregated a) blobs, b) filaments and c) walls (for clarity we display only the largest structures. The third row shows the particles associated with the MMF defined structures.
of the total number of particles together with, in panels b) and c), the structures resulting from simple density thresholding using two different thresholds.
Panels b) and c) both contain both spherical and elongated structures: there is a large amount of cross contamination between morphologies. Simple density thresholding is not an effective morphological discriminator. The second row shows the results of applying the MMF procedure showing clearly segregated a) blobs, b) filaments and c) walls (for clarity we display only the largest structures. The third row shows the particles associated with the MMF defined structures. |
| Open with DEXTER |
![\begin{figure}
\par\includegraphics[width=15.5cm,clip]{7880fig12.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg140.gif) |
Figure 12:
Comparing blobs found from HOP and from MMF. A): Particles.
B) Isosurfaces of the blob identiffied with MMF. C) Particles inside the blobs (black) and background particles in grey. D) The position of the HOP Haloes (circles) and the particles inside the MMF blobs (dark grey). Light grey particles are just the rest. |
| Open with DEXTER |
10 N-body simulations
The Large Scale Structure of the universe contains an intrincate mixture of morphologies. The boundaries separating each morphological component is rather ill-defined: clusters of galaxies are interconnected by filaments which in turn define the edges of walls.
In order to explore the response of the MMF in this complex scenario we performed a cosmological N-body simulation. We give here only a few preliminary results to illustrate how the methodology works with a "real'' galaxy distribution. A more detailed exploratin follows in a later paper.
The simulation represents a LCDM model with
 ,
,
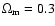 ,
h=0.73 in a periodic box of side 150 Mpc containing 2563 dark matter particles. We also run the same simulation lowering the resolution to 1283 particles according to the prescription given by Klypin et al. (2001) in order to assess the effect of mass resolution in the density field determination. For the scales studied here there is no significant difference between the density fields computed from the two simulations since the mean interparticle separation is small enough to resolve the intermediate-density structures (Schaap 2007).
,
h=0.73 in a periodic box of side 150 Mpc containing 2563 dark matter particles. We also run the same simulation lowering the resolution to 1283 particles according to the prescription given by Klypin et al. (2001) in order to assess the effect of mass resolution in the density field determination. For the scales studied here there is no significant difference between the density fields computed from the two simulations since the mean interparticle separation is small enough to resolve the intermediate-density structures (Schaap 2007).
Figure 11 shows the result of applying the MMF to this simulation. The multiscale nature of the MMF is clearly seen in Fig. 11c which shows blobs of different sizes containing similar sized clusters of points (Fig. 11g).
In the case of filaments and walls (see Figs. 11e and f) the multiscale nature of the MMF is less obvious, however it is nonetheless there.
It is clear from Fig. 11 that even though the LSS presents a great challenge it can succesfully recover each morphological component at its characteristic scale.
![\begin{figure}
\par\mbox{\includegraphics[width=17cm]{7880fig13.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg143.gif) |
Figure 13:
Particles defining filamentary structures in a slice of an N-body model. The grayscale images show the
MMF detection of filamentary features on various filtering scales.
Top lefthand: the filament volume occupancy
(number of sample grid cells with a filament signal) as a function of smoothing scale. |
| Open with DEXTER |
Figure 12A shows a section through the N-body model and Fig. 12B shows the blobs that are found in that section by the MMF process. Figure 12C shows how these blobs relate to the underlying structure displayed in panel A.
In an attempt to see how these blobs compare with clusters that would be identified via a more traditional method, we have use the HOP algorithm to find clusters. The HOP clusters are shown in Fig. 12D superposed on the MMF blobs. Superficially, we see that the agreement is remarkably good: the MMF blobs are indeed what we would subjectively call clusters. As in
Fig. 11 we can appreciate the scale range revealed by MMF.
Making this comparison more precise is rather difficult owing to the vastly different approaches to blob-finding. This will be discussed in detail in a subsequent paper dealing specifically with the application of MMF to N-body simulations.
In Fig. 13 we show the particles that belong to the filaments defined at various scales of the scale space. The top left panel of Fig. 13 shows a histogram of the number of particles contained in the filaments seen at smoothing scales from
1-4 h-1 Mpc. As expected the number of particles rises rapidly with smoothing scale (the filaments are fatter on larger scales and so encompass greater volume). The other three panels show the points contained in filaments, seen in a slice of the N-body simulation at different resolutions.
When these are stacked, application of Eq. (15) determines whether a given pixel is a part of a filament. The process yields the filamentary map of Fig. 11.
Finally we can simply count up the mass fraction of the model in various structural entities and the volume occupied by such structures to see how much of this N-body Universe lies in which structures. The result is shown in the pie diagrams of Fig. 14.
![\begin{figure}
\par\subfigure[Volume occupied by each of the structural features...
...]
{ \includegraphics[width=5.0cm,angle=0.0]{7880fig14b.eps} }
\par
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg144.gif) |
Figure 14:
Occupancy of Cosmic Web features, by volume ( top) and mass ( bottom) for a  CDM N-body simulation
(see text). CDM N-body simulation
(see text). |
| Open with DEXTER |
The result is hardly surprising: the clusters and filaments occupy about the same mass fraction and together contain more than half the haloes in the simulation. The clusters occupy by far the least volume - they are dense systems and they are denser than the filaments. Recall, however, the important remark that we could not use density threshold alone to define these structures (see the top row of panels in Fig. 11).
The large volume occupancy of filamentary structures explains why our impression of the cosmic matter distribution is predominantly filamentary, and the fact that they are all long and thin (as illustrated in Fig. 13)
emphasises the web-like nature of the structure.
Perhaps the only surprise in this analysis is the relatively low volume occupancy of the walls in comparison with the filaments. This may be in part because most of the walls have broken up by the present epoch. It may also be in part due to the fact that the low number of particles in walls makes it relatively difficult to find them: they may get mis-classified as being part of the general field. It is difficult to assess this on the basis of the present experiments alone.
MMF, our simple embodiment of Hessian-based scale space analysis of large scale cosmic structure, is remarkably sucessful in delineating the different structures that make up the cosmic web. Since the morphology filters give us a direct measurement of blobness, filamentariness or wallness they can be used to characterize and quantify, in a systematic way, the large scale matter distribution. The technique has been tested using N-Body and Voronoi models.
It should be emphaised that MMF is not a void finder except insofar as anything that is not in a blob, filament of wall might be deemed to be in a void region. In that case MMF would be a suitable tool for finding so-called "void galaxies'' without being able to identify the host void. Void finding per se is almost certainly best achieved via the Watershed (WVF) method (Platen et al. 2007).
There are many areas where the MMF treatment could be enhanced and some of these will be presented in future papers. We summarize a few issues here in order to place the present work in a more general perspective.
-
- The definition of the intensity component of the morphology filter could be improved by including other local propeties such as gradient, direction of eigenvectors, connectivity, etc.
-
- The Gaussian kernel is not the only possibility for producing the scale-space representation: alternative kernels may improve the performance of the MMF. One side effect of using a simple Gaussian filter is that high peaks in high density filaments are detected always at larger scales even when their density profile is relatively narrow (the "filter smearing'' we referred to earlier).
-
- Our implementation of the Multiscale Morphology Filters is grid-based and that required a resampling of the original point distribution data. It is possible to derive a similar set of filters using particle-based measures for the local distribution of matter (e.g.: inertia tensor analysis), defining window functions and scale normalizations in a multiscale context.
With respect to the above we would also like to refer to Sect. 8.
The ability to accurately identify arbitrarily shaped structures allows the possibility of seeking correlations within the structures that might otherwise be masked by other methods. Already, the method has been used to identify previously unknown systemic properties in the alignment of haloes with the parent structures (Aragón-Calvo et al. 2007).
The technique has been illustrated in terms of spatial point data since that is relatively unambiguous. However, the MMF technique we have described is a quite general technique for scale-free feature finding: it only needs a mathematical prescription of what is being looked for, which in general may not be so easy! Bearing that in mind, the following is a list of possible application areas.
The technique can readily be extended to analysis of velocity data of various kinds such as Fingers Of God in cosmological redshift surveys, analysis of dynamical phase spaces, feature detection in solar images, morphological characterization of structure in spiral arms, feature detection in radio datacubes, etc. Finding clusters and their substructures using MMF would provide an important alternative to HOP. Finding small, low surface brightness, galaxies in noisy neutral hydrogen surveys would be another useful application.
Acknowledgements
We are grateful to Jean-Luc Starck for his interest in this work and to the referee,
Stephane Colombi, for positive and helpful comments. We would like
to thank Pablo Araya for providing the N-body simulations and Erwin Platen for many
useful and clarifying discussions.
Appendix A: The DTFE general reconstruction procedure
For a detailed specification of the DTFE density field procedure we refer to Schaap (2007).
In summary, the DTFE procedure for density field reconstruction from a discrete set of points consists of the
following steps:
-
- Point sample. Given that the point sample is
supposed to represent an unbiased reflection of the underlying density
field, it needs to be a general Poisson process of the (supposed)
underlying density field.
-
- Boundary conditions. The boundary conditions
will determine the Delaunay and Voronoi cells that overlap the
boundary of the sample volume. Dependent on the sample at hand, a
variety of options exists:
- +
- Empty boundary conditions:
outside the sample volume
there are no points.
- +
- Periodic boundary conditions:
the point sample is
supposed to be repeated periodically in boundary boxes, defining a
toroidal topology for the sample volume.
- +
- Buffered boundary conditions:
the sample volume box is
surrounded by a bufferzone filled with a synthetic point sample.
-
- Delaunay tessellation. Construction of the
Delaunay tessellation from the point sample. While we also still use the
Voronoi-Delaunay code of van de Weygaert (1991) and van de Weygaert (1994), at present
there is a number of efficient library routines available. Particularly noteworthy
is the CGAL initiative, a large library of computational geometry
routines.
-
- Field values point sample. The estimate of the
density at each sample point is the normalized inverse of the volume
of its contiguous Voronoi cell
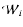 of each point
i. The contiguous Voronoi cell of a point i is the union of
all Delaunay tetrahedra of which point i forms one of the four
vertices. We recognize two applicable situations:
of each point
i. The contiguous Voronoi cell of a point i is the union of
all Delaunay tetrahedra of which point i forms one of the four
vertices. We recognize two applicable situations:
2: !:}- uniform sampling process:
the point sample is an unbiased sample of
the underlying density field. Typical example is that of N-body
simulation particles. For D-dimensional space the density estimate
is,
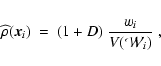 |
(A.1) |
with wi the weight of sample point i, usually we assume
the same "mass'' for each point.
2: !:}- systematic non-uniform sampling process:
sampling density according to specified
selection process. The non-uniform sampling process is quantified by
an a priori known selection function
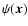 .
This situation
is typical for galaxy surveys,
may encapsulate
differences in sampling density
.
This situation
is typical for galaxy surveys,
may encapsulate
differences in sampling density
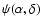 as function of
sky position
as function of
sky position
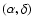 ,
as well as the radial redshift
selection function
,
as well as the radial redshift
selection function 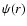 for magnitude- or flux-limited
surveys. For D-dimensional space the density estimate is,
for magnitude- or flux-limited
surveys. For D-dimensional space the density estimate is,
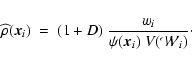 |
(A.2) |
-
- Field gradient
Calculation of the field
gradient estimate
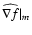 in each D-dimensional
Delaunay simplex m (D=3: tetrahedron; D=2: triangle) by solving
the set of linear equations for the field values fi at the positions
in each D-dimensional
Delaunay simplex m (D=3: tetrahedron; D=2: triangle) by solving
the set of linear equations for the field values fi at the positions
 of the (D+1) tetrahedron vertices,
of the (D+1) tetrahedron vertices,
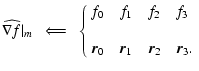 |
|
|
(A.3) |
Evidently, linear interpolation for a field f is only meaningful
when the field does not fluctuate strongly.
-
- Interpolation. The final basic step of the
DTFE procedure is the field interpolation. The processing and
postprocessing steps involve numerous interpolation calculations, for
each of the involved locations .
Given a location ,
the
Delaunay tetrahedron m in which it
is embedded is determined. On the basis of the field gradient
the field value is computed by (linear)
interpolation,
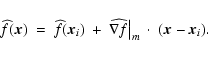 |
(A.4) |
In principle, higher-order interpolation procedures are also
possible. Two relevant procedures are:
- -
- Spline Interpolation
- -
- Natural Neighbour Interpolation.
-
- For NN-interpolation see Watson (1992); Braun & Sambridge (1995); Sukumar (1998) and
Okabe et al. (2000). Implementation of Natural neighbour interpolations is presently
in progress.
-
- Processing. Though basically of the same
character, for practical purposes we make a distinction between
straightforward processing steps concerning the production of images
and simple smoothing filtering operations and more
complex postprocessing. The latter are treated in the next item.
Basic to the processing steps is the determination of
field values following the interpolation procedure(s) outlined
above. Straightforward "first line'' field operations are Image reconstruction and Smoothing/Filtering.
- +
- Image reconstruction.
For a set of image
points, usually grid points, determine the image value.
formally the average field value within the corresponding gridcell.
In practice a few different strategies may be followed
- -
- Formal geometric approach
- -
- Monte Carlo approach
- -
- Singular interpolation approach.
-
- The choice of strategy is mainly dictated by accuracy requirements. For WVF we
use the Monte Carlo approach in which the grid density value is the average
of the DTFE field values at a number of randomly sampled points within the grid
cell.
- +
- Smoothing and Filtering.
A range of filtering operations is conceivable. Two of relevance to WVF are:
- -
- Linear filtering of the field
Convolution of the field
with a filter
function
 ,
usually user-specified,
,
usually user-specified,
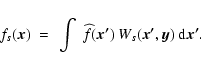 |
(A.5) |
- -
- Natural Neighbour Rank-Ordered filtering
(Platen et al. 2007).
-
-
- Post-processing. The real potential of DTFE
fields may be found in sophisticated applications, tuned towards
uncovering characteristics of the reconstructed fields. An important
aspect of this involves the analysis of structures in the density
field. The WVF formalism developed in this study is an obvious
example.
![\begin{figure}
\par\mbox{\includegraphics[width=18cm]{7880fig15.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg160.gif) |
Figure A.1:
Three different patterns of Voronoi element galaxy distributions,
shown in a 3D cubic setting. The depicted spatial distributions
correspond to a wall-dominated Voronoi Universe ( top), a filamentary
Voronoi Universe ( centre) and a cluster-dominated Voronoi Universe
( bottom). |
Voronoi Clustering Models are a class of heuristic models for cellular distributions of matter
(van de Weygaert 2007,1991). They use the Voronoi tessellation as the skeleton of the cosmic
matter distribution, identifying the structural frame around which matter will gradually assemble during
the emergence of cosmic structure. The interior of Voronoi cells correspond to voids and the Voronoi planes
with sheets of galaxies. The edges delineating the rim of each wall are identified with the filaments in the galaxy distribution.
What is usually denoted as a flattened "supercluster'' will comprise an assembly of various connecting walls in the
Voronoi foam, as elongated "superclusters'' of "filaments'' will usually consist of a few coupled edges. The most
outstanding structural elements are the vertices, corresponding to the very dense compact nodes within the
cosmic web, rich clusters of galaxies.
We distinguish two different yet complementary approaches (see van de Weygaert 2007). One is the fully heuristic approach
of "Voronoi Element models''. They are particularly apt for studying systematic properties of spatial galaxy distributions
confined to one or more structural elements of nontrivial geometric spatial patterns. The second, supplementary, approach is that
of the Voronoi Evolution models or Voronoi Kinematic models, which attempt to "simulate'' weblike galaxy distributions
on the basis of simplified models of the evolution of the Megaparsec scale distribution.
The Voronoi clustering models offer flexible templates for cellular patterns, and they are easy to tune towards a particular
spatial cellular morphology. To investigate the performance of MMF we use composite Voronoi Element Models, tailor-made
heuristic "galaxy'' distributions composed of a superposition of particle distributions in and around the walls, edges and
vertices of the Voronoi skeleton. A complete composite particle distribution includes particles located in four
distinct structural components:
-
- Field
Particles located in the interior of Voronoi cells (and thus randomly distributed across
the entire model box)
-
- Wall
Particles within and around the Voronoi walls.
-
- Filament
Particles within and around the Voronoi edges.
-
- Blobs
Particles within and around the Voronoi vertices.
For each of these four distinct distributions the model galaxies are projected onto the relevant Voronoi wall, Voronoi edge
or Voronoi vertex or retained within the interior of the Voronoi cell in which they are located. Characteristic examples of
simple Voronoi Element galaxy distributions are the ones shown in the boxes in Fig. A.1. The
depicted distributions concern a wall-dominated Voronoi Universe (lefthand), a filamentary Voronoi Universe (centre) and
a cluster-dominated Voronoi Universe (righthand).
In the case of composite models the fraction of field galaxies 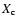 ,
wall galaxies
,
wall galaxies 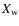 ,
filaments galaxies
,
filaments galaxies 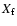 and blob galaxies
and blob galaxies 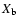 ,
with the constraint
,
with the constraint
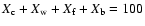 ,
is a key input parameter of the model.
,
is a key input parameter of the model.
B.1 Initial conditions
The initial conditions for the Voronoi galaxy distribution are:
-
- Distribution of M nuclei, expansion centres, within the simulation
volume V. The location
of nucleus m is
 .
.
-
- Generate N model galaxies whose initial locations,
 ,
are randomly
distributed throughout the sample volume V.
,
are randomly
distributed throughout the sample volume V.
-
- Of each model galaxy n determine the Voronoi cell
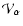 in which it is located, ie.
determine the closest nucleus
in which it is located, ie.
determine the closest nucleus
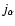 .
.
All different Voronoi models are based upon the displacement
of a sample of N "model galaxies''. The initial spatial
distribution of these N galaxies within the sample volume V is
purely random, their initial locations
(
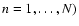 defined by a homogeneous Poisson process. A set of M nuclei within the volume V corresponds to the cell centres, or expansion centres driving the
evolving matter distribution. The nuclei have locations
defined by a homogeneous Poisson process. A set of M nuclei within the volume V corresponds to the cell centres, or expansion centres driving the
evolving matter distribution. The nuclei have locations
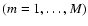 .
.
Following the specification of the initial positions of all galaxies,
the second stage of the procedure consists of the calculation of the
complete Voronoi track for each galaxy
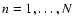 (Sect. B.2)
towards its wall, filament or vertex, or its location within a cell when
it is a field galaxy.
(Sect. B.2)
towards its wall, filament or vertex, or its location within a cell when
it is a field galaxy.
Simple Voronoi Element Models place all model galaxies in either walls, edges or vertices. The
versatility of the model also allows combinations of element models, in which field (cell), wall,
filament and vertex distributions are superimposed. The characteristics of the patterns and
spatial distribution in these Mixed Voronoi Element Models can be varied and tuned according to the
fractions of wall galaxies, filament galaxies, vertex and field galaxies.
![\begin{figure}
\par\vskip 0.5truecm
\mbox{\hskip 0.0truecm\includegraphics[height=7.0cm]{7880fig16.eps} }
\vskip 0.2cm
\end{figure}](/articles/aa/full/2007/40/aa7880-07/Timg174.gif) |
Figure B.1:
Schematic illustration of the galaxy projections in the Voronoi clustering model. See text. |
B.2 Voronoi tracks
The first step of the formalism is the determination for each galaxy n the Voronoi cell
in which it
is initially located, ie. finding the nucleus
which is closest to the galaxies' initial position
.
In the second step the galaxy n is moved from its initial position
,
towards its final
destination in a wall, filament or vertex (see Fig. B.1). The first section of the galaxy displacement is
the radial path along the direction defined by the galaxies' initial location wrt. its expansion centre .
This
direction is defined by the unity vector
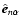 .
.
If the galaxy is a field galaxy it remains at its original location. If it is a wall galaxy it is
projected along direction
onto the Voronoi wall
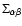 with
which the radial path first intersects. Filament galaxies are moved along the wall to the location where
the path intersects
with
which the radial path first intersects. Filament galaxies are moved along the wall to the location where
the path intersects
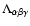 .
Finally, if it is cluster galaxy the galaxies' path
is continued along the edge
until it reaches its final destination,
vertex
.
Finally, if it is cluster galaxy the galaxies' path
is continued along the edge
until it reaches its final destination,
vertex
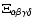 .
The identity of the neighbouring nuclei
,
.
The identity of the neighbouring nuclei
,
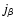 ,
,
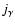 and
and
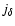 ,
and therefore the identity of the cell
,
the wall
,
the edge
and the vertex
,
depends on the initial location
of the galaxy, the position
,
and therefore the identity of the cell
,
the wall
,
the edge
and the vertex
,
depends on the initial location
of the galaxy, the position
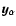 of its closest nucleus and the definition of the galaxies' path
within the Voronoi skeleton.
of its closest nucleus and the definition of the galaxies' path
within the Voronoi skeleton.
In summary, the path 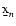 is codified by
is codified by
in which the four different components follow the directions defined by:
-
-
:
unity vector of path within Voronoi cell
;
-
-
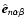 :
:
unity vector of path within Voronoi wall
;
-
-
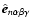 :
:
unity vector of path along Voronoi edge
;
-
- Vertex
.
The cosmic matter distribution is obtained by calculating the individual displacement factors
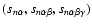 for each model galaxy, corresponding to their location within either wall, filament or vertex. In the
Voronoi Element models all galaxies are directly projected onto wall, edge or vertex following the path depicted in
Fig. B.1. The corresponding displacement factors in Eq. (B.2) for a wall, filament or cluster
galaxy are
for each model galaxy, corresponding to their location within either wall, filament or vertex. In the
Voronoi Element models all galaxies are directly projected onto wall, edge or vertex following the path depicted in
Fig. B.1. The corresponding displacement factors in Eq. (B.2) for a wall, filament or cluster
galaxy are
where the values of the parameters
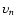 ,
,
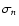 and
and 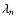 characterize the crossing of the
galaxies' path with the wall, edge or vertex towards which it moves.
characterize the crossing of the
galaxies' path with the wall, edge or vertex towards which it moves.
A finite thickness is assigned to all Voronoi structural elements. The walls, filaments and vertices are assumed to have a
Gaussian radial density distribution specified by the widths 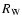 of the walls,
of the walls,  of the filaments
and
of the filaments
and  of the vertices. Voronoi wall galaxies are displaced according to the specified Gaussian density profile in
the direction perpendicular to their wall. A similar procedure is followed for the Voronoi filament galaxies and
the Voronoi vertex galaxies. As a result the vertices stand out as three-dimensional Gaussian peaks.
of the vertices. Voronoi wall galaxies are displaced according to the specified Gaussian density profile in
the direction perpendicular to their wall. A similar procedure is followed for the Voronoi filament galaxies and
the Voronoi vertex galaxies. As a result the vertices stand out as three-dimensional Gaussian peaks.
- Aikio J., &
Mähönen, P. 1998, ApJ, 497, 534 [NASA ADS] [CrossRef]
-
Aragón-Calvo, M. A., van de Weygaert, R., Jones, B. J. T.,
& van der Hulst, J. M. 2007, ApJ, 655, L5 [NASA ADS] [CrossRef] (In the text)
- Arbabi-Bidgoli,
S., & Müller, V. 2002, MNRAS, 332, 20 [NASA ADS]
- Babul, A., &
Starkman, G. D. 1992, ApJ, 401, 28 [NASA ADS] [CrossRef]
- Barrow J. D.,
Bhavsar, S. P., & Sonoda, D. H. 1985, MNRAS, 216, 17 [NASA ADS]
-
Basilakos, S., Plionis, M., & Rowan-Robinson, M. 2001, MNRAS,
323, 47 [NASA ADS]
- Bernardeau,
F., & van de Weygaert, R. 1996, MNRAS, 279, 693 [NASA ADS] (In the text)
- Bond, J. R.,
Kofman, L., & Pogosyan, D. 1996, Nature, 380, 603 [NASA ADS] [CrossRef] (In the text)
-
Braun, J., & Sambridge, M. 1995, Nature, 376, 660 [CrossRef]
- Chiang, L.-Y.,
& Coles, P. 2000, MNRAS, 311, 809 [NASA ADS]
- Colberg, J.
M. 2007, MNRAS, 375, 337 [NASA ADS]
- Colberg, J.
M., Krughoff, K. S., & Connolly, A. J. 2005, MNRAS, 359,
272 [NASA ADS] (In the text)
- Colberg, J.
M., Pearce, F., Foster, C., et al. 2007, MNRAS, submitted
(In the text)
- Coles, P.,
& Chiang, L.-Y. 2000, Nature, 406, 376 [NASA ADS] [CrossRef]
- Colless, M.,
et al. 2003 [arXiv:astro-ph/0306581]
(In the text)
- Colombi, S.,
Pogosyan, D., & Souradeep, T. 2000, Phys. Rev. Lett., 85,
5515 [NASA ADS] [CrossRef] (In the text)
- Delaunay,
B. N. 1934, Bull. Acad. Sci. USSR: Clase Sci. Mat., 7,
793 (In the text)
- Dolag, K.,
Meneghetti, M., Moscardini, L., Rasia, E., & Bonaldi, A. 2006,
MNRAS, 370, 656 [NASA ADS] (In the text)
- Doré, O.,
Colombi, S., & Bouchet, F. R. 2003, MNRAS, 344, 905 [NASA ADS] (In the text)
- Florack, L.
M. J., Ter Haar Romeny, B. M., Koenderink, J. J., & Viergever,
M. A. 1992, Image and Vision Computing, 10, 376 [CrossRef]
- Frangi, A. F.,
Niessen, W. J., Vincken, K. L., & Viergever, M. A. 1998, in
Medical Image Computing and Computer-Assisted Interventation -
MICCAI'98, Lecture Notes in Computer Science, 1496
(Springer-Verlag)
(In the text)
-
Gaztañaga, E. 1992, ApJ, 398, L17 [NASA ADS] [CrossRef]
- Gott, J. R. III,
Dickinson, M., & Melott, A. L. 1986, ApJ, 306, 341 [NASA ADS] [CrossRef]
- Graham, M. J.,
& Clowes, R. G. 1995, MNRAS, 275, 790 [NASA ADS]
- Hahn, O., Porciani,
C., Carollo, M., & Dekel, A. 2007, MNRAS, 375, 489 [NASA ADS] (In the text)
- Hoyle, F., &
Vogeley, M. 2002, ApJ, 580, 663 [NASA ADS] [CrossRef]
- Jones, B. J. T.,
Martínez, V. J., Saar, E., & Trimble, V. 2005, Rev. Mod.
Phys., 76, 1211 [NASA ADS] [CrossRef]
- Kauffmann,
G., & Fairall, A. P. 1991, MNRAS, 248, 313 [NASA ADS] (In the text)
- Klypin, A.,
Kravtsov, A. V., Bullock, J. S., & Primack, J. R. 2001, ApJ,
554, 903 [NASA ADS] [CrossRef] (In the text)
-
Lachieze-Rey, M., da Costa, L. N., & Maurogordata, S. 1992,
ApJ, 399, 10 [NASA ADS] [CrossRef]
- de
Lapparent, V., Geller, M. J., & Huchra, J. P. 1991, ApJ, 369,
273 [NASA ADS] [CrossRef]
-
Lindeberg, T. 1998, Int. J. Computer Vision, 30, 48
- Marr, D. 1980,
Vision, W. H. Freeman, 1980
(In the text)
- Marr, D.,
& Hildreth, E. 1980, Proc. R. Soc. Lond. B., 207, 107 (In the text)
-
Martínez, V., & Saar, E. 2002, Statistics of the Galaxy
Distribution (Chapman & Hall/CRC press)
(In the text)
-
Martínez, V., Starck, J.-L., Saar, E., et al. 2005, ApJ,
634, 744 [NASA ADS] [CrossRef] (In the text)
- Mecke, K. R.,
Buchert, T., & Wagner, H. 1994, A&A, 288, 697 [NASA ADS]
- Novikov, D.,
Colombi, S., & Doré, O. 2006, MNRAS, 366, 1201 [NASA ADS] (In the text)
- Okabe, A., Boots,
B., Sugihara, K., & Chiu, S. N. 2000, Spatial
tessellations: concepts and applications of voronoi diagrams, 2nd
edn. (John Wiley & Sons)
(In the text)
- Patiri, S. G.,
Prada, F., Holtzman, J., Klypin, A., & Betancort-Rijo, J. E.
2006, MNRAS, 372, 1710 [NASA ADS] (In the text)
- Peebles
P. J. E. 1980, The large-scale structure of the universe
(Princeton University Press)
- Pimbblet,
K. A. 2005, MNRAS, 358, 256 [NASA ADS] (In the text)
- Platen, E., van
de Weygaert, R., & Jones, B. J. T. 2007, MNRAS, in press
(In the text)
- Plionis, M.,
& Basilakos, S. 2002, MNRAS, 330, 399 [NASA ADS]
- Qian, L., Sone, S.,
& Doi, K. 2003, Med. Phys., 30, 2040 [CrossRef] (In the text)
- Ryden, B.
S., & Gramann, M. 1991, ApJ, 383, 33 [NASA ADS] [CrossRef]
- Saar, E.,
Martiínez, V. J., Starck, J.-L., & Donoho, D. L. 2007,
MNRAS, 374, 1030 [NASA ADS] (In the text)
- Sahni, V.,
Sathyaprakash, B. S., & Shandarin, S. F. 1998, ApJ, 495, 5 [NASA ADS] [CrossRef]
- Sato, Y., Nakajima,
D., Atsumi, H., et al. 1998, IEEE Medical Image Analysis, 2,
143 (In the text)
- Schaap,
W. E., & van de Weygaert, R. 2000, A&A, 363, L29 [NASA ADS] (In the text)
- Schaap,
W. E. 2007, the Delaunay Tessellation Field Estimator, Ph.D.
Thesis, Groningen University
-
Schmalzing, J., Buchert, T., Melott, A. L., et al. 1999, ApJ,
526, 568 [NASA ADS] [CrossRef]
- Schmidt, J.
D., Ryden, B. S., & Melott, A. L. 2001, ApJ, 546, 609 [NASA ADS] [CrossRef] (In the text)
-
Shandarin, S. F., Sheth, J. V., & Sahni, V. 2004, MNRAS, 353,
162 [NASA ADS]
- Sibson, R.
1980, Math. Proc. Cambridge Phil. Soc., 87, 151
- Sibson, R.
1981, in Interpreting Multi-variate Data, ed. V. Barnett
(Chichester: Wiley), 21
- Sousbie, T.,
Pichon, C., Colombi, S., Novikov, D., & Pogosyan, D. 2007,
[arXiv:0707.3123]
(In the text)
-
Springel, V., White, S. D. M., Jenkins, A., et al. 2005,
Nature, 435, 629 [NASA ADS] [CrossRef] (In the text)
- Stoica, R. S.,
Martínez, V. J., Mateu, J., & Saar, E. 2005, A&A, 434,
423 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
-
Sukumar, N. 1998, The Natural Element Method in Solid Mechanics,
Ph.D. Thesis, Northwestern University
- Szapudi, I.
1998, ApJ, 497, 16 [NASA ADS] [CrossRef]
- van
de Weygaert, R. 1991, Voids and the Geometry of Large Scale
Structure, Ph.D. Thesis, Leiden University
- van de
Weygaert, R. 1994, A&A, 283, 361 [NASA ADS] (In the text)
- van de
Weygaert, R. 2002, in Modern Theoretical and Observational
Cosmology, Proc. 2nd Hellenic Cosmology Meeting, ed. M. Plionis,
& S. Cotsakis, ASSL 276 (Dordrecht: Kluwer)
(In the text)
- van de
Weygaert, R. 2007, A&A, submitted
- Luo, R.,
& Vishniac, E. 1995, ApJS, 96, 429 [NASA ADS] [CrossRef]
- Voronoi, G.
1908, J. Reine Angew. Math., 134, 167
- Watson, D. F.
1992, Contouring: A Guide to the Analysis and Display of Spatial
Data (Oxford: Pergamom Press)
- White, S. D. M.
1979, MNRAS, 186, 145 [NASA ADS]
- York, D. G.,
Adelman, J., Anderson, J. E., Jr., et al. 2000, AJ, 120,
1579 [NASA ADS] [CrossRef] (In the text)
-
Zel'dovich, Ya. B., Einasto, J., & Shandarin, S. F. 1982,
Nature, 300, 407 [NASA ADS] [CrossRef] (In the text)
Copyright ESO 2007
![\begin{figure}
\par\mbox{ \includegraphics[width=7.3cm,clip]{7880fig1a.eps} \includegraphics[width=7.3cm,clip]{7880fig1b.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img20.gif)
![\begin{figure}
\par\includegraphics[width=18cm,clip]{7880fig2.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img47.gif)
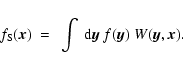
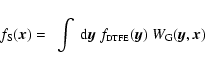
![\begin{figure}
\par\includegraphics[width=18cm,clip]{7880fig3.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img61.gif)
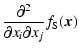
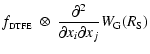
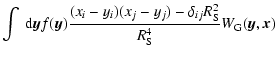
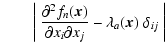
![\begin{figure}
\par\mbox{\includegraphics[width=17cm]{7880fig4.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img83.gif)
![\begin{figure*}
\par\includegraphics[width=17cm,clip]{7880fig5.eps}
\end{figure*}](/articles/aa/full/2007/40/aa7880-07/img93.gif)
![\begin{figure}
\par\includegraphics[width=16.7cm,clip]{7880fig6.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img95.gif)
![\begin{figure}
\par\includegraphics[width=16.5cm,clip]{7880fig7.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img109.gif)
![\begin{figure}
\par\subfigure[Threshold determination for blobs.]
{ \mbox{\hski...
...0truecm\includegraphics[width=0.71\linewidth]{7880fig8c.eps} }
}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img116.gif)
![\begin{figure}
\par\includegraphics[width=16.7cm,clip]{7880fig9.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img126.gif)
![\begin{figure}
\par\includegraphics[width=17.5cm,clip]{7880fig10.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img131.gif)
![\begin{figure}
\par\includegraphics[width=16.5cm,clip]{7880fig11.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img139.gif)
![\begin{figure}
\par\includegraphics[width=15.5cm,clip]{7880fig12.eps}
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img140.gif)
![\begin{figure}
\par\mbox{\includegraphics[width=17cm]{7880fig13.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img143.gif)
![\begin{figure}
\par\subfigure[Volume occupied by each of the structural features...
...]
{ \includegraphics[width=5.0cm,angle=0.0]{7880fig14b.eps} }
\par
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img144.gif)
![\begin{figure}
\par\vskip 0.5truecm
\mbox{\hskip 0.0truecm\includegraphics[height=7.0cm]{7880fig16.eps} }
\vskip 0.2cm
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img174.gif)
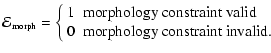
![\begin{figure}
\par\mbox{\includegraphics[width=18cm]{7880fig15.eps} }
\end{figure}](/articles/aa/full/2007/40/aa7880-07/img160.gif)