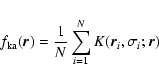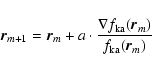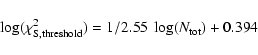A&A 470, 39-51 (2007)
DOI: 10.1051/0004-6361:20077245
M. Ramella1 - A. Biviano1 - A. Pisani2 - J. Varela3,8 - D. Bettoni3 - W. J. Couch4 - M. D'Onofrio5 - A. Dressler6 - G. Fasano3 - P. Kjærgaard7 - M. Moles8 - E. Pignatelli3 - B. M. Poggianti3
1 - INAF/Osservatorio Astronomico di Trieste, via G. B. Tiepolo 11, 34143 Trieste, Italy
2 -
Istituto di Istruzione Statale Classico Dante Alighieri,
Scientifico Duca degli Abruzzi, Magistrale S. Slataper,
viale XX settembre 11, 34170 Gorizia, Italy
3 -
INAF/Osservatorio Astronomico di Padova, vicolo Osservatorio 5, 35122 Padova, Italy
4 - School of Physics, University of New South Wales, Sydney 2052, Australia
5 - Dipartimento di Astronomia, Università di Padova, vicolo Osservatorio 2, 35122 Padova, Italy
6 - Observatories of the Carnegie Institution of Washington, Pasadena, CA 91101, USA
7 - Copenhagen University Observatory. The Niels Bohr Institute for Astronomy Physics and Geophysics, Juliane Maries Vej 30, 2100 Copenhagen, Denmark
8 - Instituto de Astrofísica de Andalucía (C.S.I.C.) Apartado 3004, 18080 Granada, Spain
Received 6 February 2007 / Accepted 3 April 2007
Abstract
Aims. We search for and characterize substructures in the projected distribution of galaxies observed in the wide field CCD images of the 77 nearby clusters of the WIde-field Nearby Galaxy-cluster Survey (WINGS). This sample is complete in X-ray flux in the redshift range
0.04<z<0.07.
Methods. We search for substructures in WINGS clusters with DEDICA, an adaptive-kernel procedure. We test the procedure on Monte-Carlo simulations of the observed frames and determine the reliability for the detected structures.
Results. DEDICA identifies at least one reliable structure in the field of 55 clusters. 40 of these clusters have a total of 69 substructures at the same redshift of the cluster (redshift estimates of substructures are from color-magnitude diagrams). The fraction of clusters with subclusters (73%) is higher than in most studies. The presence of subclusters affects the relative luminosities of the brightest cluster galaxies (BCGs). Down to
![]() ,
our observed differential distribution of subcluster luminosities is consistent with the theoretical prediction of the differential mass function of substructures in cosmological simulations.
,
our observed differential distribution of subcluster luminosities is consistent with the theoretical prediction of the differential mass function of substructures in cosmological simulations.
Key words: galaxies: clusters: general - galaxies: elliptical and lenticular, cD
According to the current cosmological paradigm, large structures in the Universe form hierarchically. Clusters of galaxies are the largest structures that have grown through mergers of smaller units and have achieved near dynamical equilibrium. In the hierarchical scenario, clusters are a rather young population, and we should be able to observe their formation process even at rather low redshifts. A signature of such process is the presence of cluster substructures. A cluster is said to contain substructures (or subclusters) when its surface density is characterized by multiple, statistically significant peaks on scales larger than the typical galaxy size, with "surface density'' being referred to the cluster galaxies, the intra-cluster (IC) gas or the dark matter (DM hereafter; Buote 2002).
Studying cluster substructure therefore allows us to investigate the process by which clusters form, constrain the cosmological model of structure formation, and ultimately test the hierarchical paradigm itself (e.g. Thomas et al. 1998; Richstone et al. 1992; Mohr et al. 1995). In addition, it also allows us to better understand the mechanisms affecting galaxy evolution in clusters, which can be accelerated by the perturbative effects of a cluster-subcluster collision and of the tidal field experienced by a group accreting onto a cluster (Dubinski 1999; Bekki 1999; Gnedin 1999). If clusters are to be used as cosmological tools, it is important to calibrate the effects substructures have on the estimate of their internal properties (e.g. Roettiger et al. 1998; Lopes et al. 2006; Schindler & Müller 1993; Biviano et al. 2006; Pinkney et al. 1996). Finally, detailed analyses of cluster substructures can be used to constrain the nature of DM (Markevitch et al. 2004; Clowe et al. 2006).
The analysis of cluster substructures can be performed using the projected phase-space distribution of cluster galaxies (e.g. Geller & Beers 1982), the surface-brightness distribution and temperature of the X-ray emitting IC gas (e.g. Briel et al. 1992), or the shear pattern in the background galaxy distribution induced by gravitational lensing, that directly samples substructure in the DM component (e.g. Abdelsalam et al. 1998). None of these tracers of cluster substructure (cluster galaxies, IC gas, background galaxies) can be considered optimal. The identification of substructures is in fact subject to different biases depending on the tracer used. In X-rays projection effects are less important than in the optical, but the identification of substructures is more subject to a z-dependent bias, arising from the point spread function of the X-ray telescope and detector (e.g. Böhringer & Schuecker 2002). Moreover, the different cluster components respond in a different way to a cluster-subcluster collision. The subcluster IC gas can be ram-pressure braked and stripped from the colliding subcluster and lags behind the subcluster galaxies and DM along the direction of collision (e.g. Clowe et al. 2006; Barrena et al. 2002; Roettiger et al. 1997). Hence, it is equally useful to address cluster substructure analysis in the X-ray and in the optical.
Traditionally, the first detections of cluster substructures were obtained from the projected spatial distributions of galaxies (e.g. Shane & Wirtanen 1954; Abell et al. 1964), in combination, when possible, with the distribution of galaxy velocities (e.g. van den Bergh 1960; de Vaucouleurs 1961; van den Bergh 1961). Increasingly sophisticated techniques for the detection and characterization of cluster substructures have been developed over the years (see Girardi & Biviano 2002; Perea et al. 1986b; Moles et al. 1986; Perea et al. 1986a; Buote 2002, and references therein). In many of these techniques substructures are identified as deviations from symmetry in the spatial and/or velocity distribution of galaxies and in the X-ray surface-brightness (e.g. Mohr et al. 1993; Fitchett & Merritt 1988; Schuecker et al. 2001; West et al. 1988). In other techniques substructures are identified as significant peaks in the surface density distribution of galaxies or in the X-ray surface brightness, either as residuals left after the subtraction of a smooth, regular model representation of the cluster (e.g. Ettori et al. 1998; Neumann & Böhringer 1997), or in a non-parametric way, e.g. by the technique of wavelets (e.g. Biviano et al. 1996; Slezak et al. 1994; Escalera et al. 1994) and by adaptive-kernel techniques (e.g. Bardelli et al. 2001,1998a; Kriessler & Beers 1997).
The performances of several different methods have been evaluated both using numerical simulations (e.g. Crone et al. 1996; Cen 1997; Valdarnini et al. 1999; Knebe & Müller 2000; Biviano et al. 2006; Buote & Xu 1997; Mohr et al. 1995; Pinkney et al. 1996) and also by applying different methods to the same cluster data-sets and examine the result differences (e.g. Mohr et al. 1996; Fadda et al. 1998; Escalera et al. 1992; Lopes et al. 2006; Kriessler & Beers 1997; Escalera et al. 1994; Kolokotronis et al. 2001; Mohr et al. 1995; Schuecker et al. 2001). Generally speaking, the sensitivity of substructure detection increases with both increasing statistics (e.g. more galaxies or more X-ray photons) and increasing dimensionality of the test (e.g. using galaxy velocities in addition to their positions, or using X-ray temperature in addition to X-ray surface brightness).
Previous investigations have found very different fractions of clusters with
substructure in nearby clusters, depending on the method and tracer
used for substructure detection, on the cluster sample, and
on the size of sampled cluster
regions (e.g. Flin & Krywult 2006; Lopes et al. 2006; Girardi et al. 1997; Solanes et al. 1999; Kriessler & Beers 1997; Jones & Forman 1999; Dressler & Shectman 1988; Geller & Beers 1982; Kolokotronis et al. 2001; Mohr et al. 1995; Schuecker et al. 2001). Although the distribution of subcluster masses has not been determined
observationally, it is known that subclusters of ![]() 10% the
cluster mass are typical, while more massive subclusters are less
frequent (Jones & Forman 1999; Girardi et al. 1997; Escalera et al. 1994). The situation is
probably different for distant clusters which tend to show massive
substructures more often than nearby clusters clearly suggesting
hierarchical growth of clusters was more intense in the past
(e.g. Gioia et al. 1999; Demarco et al. 2005; Rosati et al. 2004; Maughan et al. 2003; van Dokkum et al. 2000; Haines et al. 2001; Huo et al. 2004; Jeltema et al. 2005).
10% the
cluster mass are typical, while more massive subclusters are less
frequent (Jones & Forman 1999; Girardi et al. 1997; Escalera et al. 1994). The situation is
probably different for distant clusters which tend to show massive
substructures more often than nearby clusters clearly suggesting
hierarchical growth of clusters was more intense in the past
(e.g. Gioia et al. 1999; Demarco et al. 2005; Rosati et al. 2004; Maughan et al. 2003; van Dokkum et al. 2000; Haines et al. 2001; Huo et al. 2004; Jeltema et al. 2005).
Additional evidence for the hierarchical formation of clusters is provided by the analysis of brightest cluster galaxies (BCGs hereafter) in substructured clusters. BCGs usually sit at the bottom of the potential well of their host cluster (e.g. Adami et al. 1998b). When a BCG is found to be significantly displaced from its cluster dynamical center, the cluster displays evidence of substructure (e.g. Beers et al. 1991; Ferrari et al. 2006). From the correlation between cluster and BCG luminosities, Lin & Mohr (2004) conclude that BCGs grow by merging as their host clusters grow hierarchically. The related evolution of BCGs and their host clusters is also suggested by the alignment of the main cluster and BCG axes (e.g. Binggeli 1982; Durret et al. 1998). Both the BCG and the cluster axes are aligned with the surrounding large scale structure distribution, where infalling groups come from. These infalling groups are finally identified as substructures once they enter the cluster environment (West & Blakeslee 2000; Adami et al. 2005; Ferrari et al. 2003; Durret et al. 1998; Plionis et al. 2003; Arnaud et al. 2000). Hence, substructure studies really provide direct evidence for the hierarchical formation of clusters.
Concerning the impact of subclustering on global cluster properties, it has been found that subclustering leads to over-estimating cluster velocity dispersions and virial masses (e.g. Bird 1995; Maurogordato et al. 2000; Perea et al. 1990), but not in the general case of small substructures (Xu et al. 2000; Girardi et al. 1997; Escalera et al. 1994). During the collision of a subcluster with the main cluster, both the X-ray emitting gas distribution and its temperature have been found to be significantly affected (e.g. Markevitch & Vikhlinin 2001; Clowe et al. 2006). As a consequence, it has been argued that substructure can explain at least part of the scatter in the scaling relations of optical-to-X-ray cluster properties (e.g. Girardi et al. 1996; Lopes et al. 2006; Barrena et al. 2002; Fitchett 1988).
As far as the internal properties of cluster galaxies are concerned, there is observational evidence that a higher fraction of cluster galaxies with spectral features characteristic of recent or ongoing starburst episodes is located in substructures or in the regions of cluster-subcluster interactions (Bardelli et al. 1998b; Miller 2005; Caldwell et al. 1993; Poggianti et al. 2004; Moss & Whittle 2000; Miller et al. 2004; Abraham et al. 1996; Biviano et al. 1997; Giacintucci et al. 2006; Caldwell & Rose 1997).
In this paper we search for and characterize substructures in the sample of 77 nearby clusters of the WIde-field Nearby Galaxy-cluster Survey (WINGS hereafter, Fasano et al. 2006). This sample is an almost complete sample in X-ray flux in the redshift range 0.04<z<0.07. We detect substructures from the spatial, projected distribution of galaxies in the cluster fields, using the adaptive-kernel based DEDICA algorithm (Pisani 1996,1993). In Sect. 2 we describe our data-set; in Sect. 3 we describe the procedure of substructure identification; in Sect. 4 we use Monte Carlo simulations in order to tweak our procedure; in Sect. 5 we describe the identification of substructures in our data-set; in Sect. 6 the catalog of identified substructures is provided. In Sect. 7 we investigate the properties of the identified substructures, and in Sect. 8 we consider the relation between the BCGs and the substructures. We provide a summary of our work in Sect. 9.
WINGS is an all-sky, photometric (multi-band) and spectroscopic survey, whose global goal is the systematic study of the local cosmic variance of the cluster population and of the properties of cluster galaxies as a function of cluster properties and local environment.
The WINGS sample consists of 77 clusters selected from three X-ray
flux limited samples compiled from ROSAT All-Sky Survey data, with
constraints just on the redshift (0.04 < z < 0.07) and distance from
the galactic plane (
![]()
![]() 20 deg).
The core of the project consists of wide-field optical imaging of
the selected clusters in the B and V bands. The imaging data were
collected using the WFC@INT (La Palma) and the WFI@MPG/ESO2.2 (La Silla)
in the northern and southern hemispheres, respectively.
20 deg).
The core of the project consists of wide-field optical imaging of
the selected clusters in the B and V bands. The imaging data were
collected using the WFC@INT (La Palma) and the WFI@MPG/ESO2.2 (La Silla)
in the northern and southern hemispheres, respectively.
The observation strategy of the survey favors the uniformity of photometric depth inside the different CCDs, rather than complete coverage of the fields that would require dithering. Thus, the gaps in the WINGS optical imaging correspond to the physical gaps between the different CCDs of the mosaics.
During the data reduction process, we give particular care to sky subtraction (also in presence of crowded fields including big halo galaxies and/or very bright stars), image cleaning (spikes and bad pixels) and star/galaxy classification (obtained with both automatic and interactive tools).
According to Fasano et al. (2006) and Varela et al. (2007), the
overall quality of the data reported in the WINGS photometric catalogs
can be summarized as follows: (i) the astrometric errors for extended
objects have
![]() 0.2 arcsec; (ii) the average limiting magnitude is
0.2 arcsec; (ii) the average limiting magnitude is
![]() 24.0, ranging from 23.0 to 25.0; (iii) the completeness of the
catalogs is achieved (on average) up to
24.0, ranging from 23.0 to 25.0; (iii) the completeness of the
catalogs is achieved (on average) up to ![]() 22.0; (iv) the total
(systematic plus random) photometric rms errors, derived from
both internal and external comparisons, vary from
22.0; (iv) the total
(systematic plus random) photometric rms errors, derived from
both internal and external comparisons, vary from ![]() 0.02 mag, for
bright objects, up to
0.02 mag, for
bright objects, up to ![]() 0.2 mag, for objects close to the
detection limit.
0.2 mag, for objects close to the
detection limit.
We base our search for substructures in WINGS clusters on the DEDICA procedure (Pisani 1996,1993). This procedure has the following advantages:
We proceed as follows. First we need to estimate the
probability density function
![]() (with
(with
![]() )
associated with the set of N galaxies with coordinates
)
associated with the set of N galaxies with coordinates
![]() .
Second,
we need to find the local maxima in our estimate of
.
Second,
we need to find the local maxima in our estimate of
![]() in
order to identify clusters and also to evaluate their significance relatively
to the noise. Third and finally, we need to estimate the probability that a galaxy is a member of the identified clusters.
in
order to identify clusters and also to evaluate their significance relatively
to the noise. Third and finally, we need to estimate the probability that a galaxy is a member of the identified clusters.
DEDICA is a non-parametric method in the sense that it does not require any
assumption on the probability density function that it is aimed to estimate.
The only assumptions are that
![]() must be continuous and at
least twice differentiable.
must be continuous and at
least twice differentiable.
The function
![]() is an estimate of
is an estimate of
![]() and it is
built by using an adaptive kernel method given by:
and it is
built by using an adaptive kernel method given by:
The most valuable feature of DEDICA is the procedure to select the values of
kernel widths
![]() .
It is possible to show that the optimal choice for
.
It is possible to show that the optimal choice for
![]() ,
i.e. with asymptotically minimum variance and
null bias, is obtained by minimizing the distance between our estimate
,
i.e. with asymptotically minimum variance and
null bias, is obtained by minimizing the distance between our estimate
![]() and
and
![]() .
This distance can be evaluated by a particular function called the integrated square error
.
This distance can be evaluated by a particular function called the integrated square error
![]() given by:
given by:
![\begin{displaymath}%
{\it ISE}(f)=\int_{\Re} [\Psi({\vec r}) - f({\vec r})]^2 {\rm d}{\vec r}.
\end{displaymath}](/articles/aa/full/2007/28/aa7245-07/img22.gif) |
(2) |
The second step of DEDICA consists in the identification of the local
maxima in
![]() .
The positions of the peaks in the density
function
.
The positions of the peaks in the density
function
![]() are found as the solutions of the iterative
equation:
are found as the solutions of the iterative
equation:
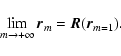 |
(4) |
In order to maintain a coherent notation, we identify with the label ![]() the n0 isolated galaxies considered a system of background galaxies. We
have:
the n0 isolated galaxies considered a system of background galaxies. We
have:
![]() .
.
The statistical significance ![]() (
(
![]() )
of each cluster is
based on the assumption that the presence of the
)
of each cluster is
based on the assumption that the presence of the ![]() th cluster causes an increase in the local probability density as well as in the sample likelihood
th cluster causes an increase in the local probability density as well as in the sample likelihood
![]() relatively to the value
relatively to the value ![]() that one
would have if the members of the
that one
would have if the members of the ![]() th cluster were all isolated, i.e.
belonging to the background.
th cluster were all isolated, i.e.
belonging to the background.
A large value in the ratio
![]() characterizes the most
important clusters. According to Materne (1979) it is possible to
estimate the significance of each cluster by using the likelihood
ratio test. In other words
characterizes the most
important clusters. According to Materne (1979) it is possible to
estimate the significance of each cluster by using the likelihood
ratio test. In other words
![]() is distributed as a
is distributed as a
![]() variable with
variable with ![]() degrees of freedom. Therefore, once we
compute the value of
degrees of freedom. Therefore, once we
compute the value of ![]() for each cluster (
for each cluster (
![]() ), we can also
compute the significance
), we can also
compute the significance ![]() of the cluster.
of the cluster.
Here we assume that the contribution to the global density field
![]() of the
of the ![]() th cluster is
th cluster is
![]() .
The
ratio between the value of
.
The
ratio between the value of
![]() and the total local density
and the total local density
![]() can be used to estimate the membership probability of each
galaxy relatively to the identified clusters. This criterion also allows us to
estimate the probability that a galaxy is isolated.
can be used to estimate the membership probability of each
galaxy relatively to the identified clusters. This criterion also allows us to
estimate the probability that a galaxy is isolated.
At the end of the DEDICA procedure we are left with a) a catalog of
galaxies each with information on position, membership, local density
and size of the Gaussian kernel, b) a catalog of structures with
information on position, richness, the
![]() parameter, and peak
density. For each cluster we also compute from the coordinate
variance matrix, the cluster major axis, ellipticity and position
angle.
parameter, and peak
density. For each cluster we also compute from the coordinate
variance matrix, the cluster major axis, ellipticity and position
angle.
In this section we describe our analysis of the performance of DEDICA and the guidelines we obtain for the interpretation of the clustering analysis of our observations.
We build simulated fields containing a cluster with and without subclusters. The simulated fields have the same geometry of the WFC field and are populated with the typical number of objects we will analyze. For simplicity we consider only WFC fields. Because DEDICA is scale-free, a different sampling of the same field of view has no consequence on our analysis.
In the next section we limit our analysis to
![]() .
At the median redshift of the WINGS cluster,
.
At the median redshift of the WINGS cluster,
![]() ,
this
absolute magnitude limit corresponds to an apparent magnitude
,
this
absolute magnitude limit corresponds to an apparent magnitude
![]() .
Within this magnitude limit the representative number of galaxies in
our frames is
.
Within this magnitude limit the representative number of galaxies in
our frames is
![]() = 900.
= 900.
We then consider
![]() =
=
![]() +
+
![]() ,
with
,
with
![]() the number of
cluster members and
the number of
cluster members and
![]() the number of field - or background -
galaxies. We set
the number of field - or background -
galaxies. We set
![]() = 670, close to the average number of
background galaxies we expect in our frame based on typical observed
fields counts, e.g. Berta et al. (2006) or Arnouts et al. (1997). With this
choice, we have
= 670, close to the average number of
background galaxies we expect in our frame based on typical observed
fields counts, e.g. Berta et al. (2006) or Arnouts et al. (1997). With this
choice, we have
![]() = 230.
= 230.
We distribute uniformly at random
![]() objects. We distribute at
random the remaining
objects. We distribute at
random the remaining
![]() = 230 objects in one or more overdensities
depending on the test we perform. We populate overdensities according
to a King profile (King 1962) with a core radius
= 230 objects in one or more overdensities
depending on the test we perform. We populate overdensities according
to a King profile (King 1962) with a core radius
![]() kpc,
representative of our clusters. We then scale
kpc,
representative of our clusters. We then scale
![]() with the
number of members of the substructure,
with the
number of members of the substructure, ![]() .
We use
.
We use
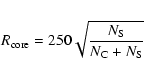
As far as the relative richnesses of the cluster and subcluster are
concerned, we consider the following richness ratios
![]() .
With these richness ratios,
the number of objects in the
cluster are
.
With these richness ratios,
the number of objects in the
cluster are
![]() ,
and those in
subclusters are
,
and those in
subclusters are
![]() respectively.
respectively.
In a first set of simulated fields we place the substructure at 2731 pixels (15 arcmin) from the main cluster so that they do not overlap. In a second set of
simulations, we place main cluster and substructure at shorter distances, 683
and 1366 pixels, in order to investigate the ability of DEDICA to resolve
structures. At each of these shorter distances we build simulations
with both
![]() = 1 and 2.
= 1 and 2.
For each richness ratio and/or distance between cluster and subcluster we produce 16 simulations with different realizations of the random positions of the data points representing galaxies.
In order to minimize the effect of the borders on the detection of structures we add to the simulation a "frame'' of 1000 pixel. We fill this frame with a grid of data points at the same density as the average density of the field.
The first result we obtain from the runs of DEDICA on the simulations with
varying richness ratio is the positive rate at which we detect real structures.
We find that we always recover both cluster and substructure even when the
substructure only contains ![]() = 1/8
= 1/8 ![]() objects, i.e. 26 objects (on top
of the uniform background). In other words, if there is a real structure DEDICA
finds it.
objects, i.e. 26 objects (on top
of the uniform background). In other words, if there is a real structure DEDICA
finds it.
We also check how many original members the procedure assigns to structures it
recovers. The results are summarized in Fig. 1. In the
diagram, the fraction of recovered members of each substructure is represented
by the values of its
![]() .
The solid line connects substructures with
.
The solid line connects substructures with
![]() and 4.
and 4.
![\begin{figure}
\par\includegraphics[width=7cm,clip]{7245f01.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img61.gif) |
Figure 1:
Fraction of recovered members of each substructure for different
|
| Open with DEXTER | |
From Fig. 1 it is clear that our procedure recovers a large fraction of members, almost irrespective of the richness of the original structure. It is also interesting to note that the fluctuations identified as substructures are located very close to the center of the corresponding simulated substructures. In almost all cases the distance between original and detected substructure is significantly shorter than the mean inter-particle distance.
The second important result we obtain from the simulations is the false positive rate, i.e. the fraction of noise fluctuations that are as significant as the fluctuations corresponding to real structures.
First of all we need to define an operative measure of the
reliability of the detected structures. In fact DEDICA provides a default value ![]() (
(
![]() )
of the significance (see
Sect. 3.3). However,
)
of the significance (see
Sect. 3.3). However, ![]() has a relatively small dynamical range, in particular for highly significant clusters.
has a relatively small dynamical range, in particular for highly significant clusters.
Density or richness both allow a reasonable "ranking'' of structures. However, both large low-density noise fluctuations (often built up from more than one noise fluctuation) and very high density fluctuations produced by few very close data points could be mistakenly ranked as highly significant structures according to, respectively, richness and density criteria.
We therefore prefer to use the parameter
![]() which stands at the base of
the estimate of
which stands at the base of
the estimate of ![]() and which is naturally provided by DEDICA. The main
characteristic of
and which is naturally provided by DEDICA. The main
characteristic of
![]() is that it depends both on the density of a cluster relative to the background and on its richness. Using
is that it depends both on the density of a cluster relative to the background and on its richness. Using
![]() we
classify correctly significantly more structures than with either density or
richness alone.
we
classify correctly significantly more structures than with either density or
richness alone.
![\begin{figure}
\par\includegraphics[width=7.2cm,clip]{7245f02.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img62.gif) |
Figure 2:
|
| Open with DEXTER | |
In Fig. 2 we plot the distribution of
![]() of noise
fluctuations (solid line). In the same plot we also mark the
of noise
fluctuations (solid line). In the same plot we also mark the
![]() of real
structures as detected by our procedure. We use labels indicating
of real
structures as detected by our procedure. We use labels indicating
![]() and
place them at the abscissa corresponding to their
and
place them at the abscissa corresponding to their
![]() and at arbitrary ordinates.
and at arbitrary ordinates.
Figure 2 shows that the structures detected with
![]() = 1, 2 are always distinguishable from noise fluctuations. Substructures with
= 1, 2 are always distinguishable from noise fluctuations. Substructures with
![]() = 4 or higher, although correctly detected, have
= 4 or higher, although correctly detected, have
![]() values that are close to or lower than the level of noise.
values that are close to or lower than the level of noise.
With the second set of simulations, we test the minimum distance at
which cluster and subcluster can still be identified as separate
entities. We place cluster and substructure (
![]() = 1, 2) at
distances
= 1, 2) at
distances
![]() 683 and 1366 pixel. These distances are 1/4 and 1/2 respectively of the distance between cluster and substructure in the first set of simulations. Again we produce 16 simulations for each of the 4 cases.
683 and 1366 pixel. These distances are 1/4 and 1/2 respectively of the distance between cluster and substructure in the first set of simulations. Again we produce 16 simulations for each of the 4 cases.
We find that at
![]() 1366 pixel cluster and substructure are always
correctly identified. At the shorter distance
1366 pixel cluster and substructure are always
correctly identified. At the shorter distance
![]() 683 pixel, DEDICA merges cluster and substructure in 1 out of 16 cases for
683 pixel, DEDICA merges cluster and substructure in 1 out of 16 cases for
![]() = 1 and in 8 out
of 16 cases for
= 1 and in 8 out
of 16 cases for
![]() = 2. With our density profile,
= 2. With our density profile,
![]() 683 pixel
corresponds to
683 pixel
corresponds to
![]() with
with ![]() ,
,
![]() the radii
of the main cluster and of the subcluster respectively.
the radii
of the main cluster and of the subcluster respectively.
In order to verify the results we obtain for 900 data points we produce more
simulations with
![]() = 450, 600 and 1200. In all these simulations
= 450, 600 and 1200. In all these simulations ![]() and
and ![]() are the same as in the set with
are the same as in the set with
![]() = 900. We vary
= 900. We vary
![]() and
and
![]() so
that
so
that
![]() /
/
![]() is the same as in the case
is the same as in the case
![]() = 900.
= 900.
These simulations confirm the results we obtain in the case
![]() = 900, and allow us to set a detection
threshold,
= 900, and allow us to set a detection
threshold,
![]() (
(
![]() ), for significant fluctuations
in the analysis of real clusters.
), for significant fluctuations
in the analysis of real clusters.
We summarize the behavior of the noise fluctuations in our simulations
in Fig. 3. In this figure, the small symbols
correspond to
![]() as a function of the number of members of noise
fluctuations. In particular, crosses, circles, dots and triangles are
as a function of the number of members of noise
fluctuations. In particular, crosses, circles, dots and triangles are
![]() for the noise fluctuations of the simulations with
for the noise fluctuations of the simulations with
![]() =
450, 600, 900, and 1200 respectively.
=
450, 600, 900, and 1200 respectively.
The larger symbols are the
![]() of the fluctuations corresponding to
simulated clusters and subclusters of equal richness (
of the fluctuations corresponding to
simulated clusters and subclusters of equal richness (
![]() = 1).
= 1).
The 4 horizontal lines mark the level of
![]() ,
i.e. the
average
,
i.e. the
average
![]() of the 3 most significant noise fluctuations in each
of the 4 groups of simulations with
of the 3 most significant noise fluctuations in each
of the 4 groups of simulations with
![]() = 450, 600, 900, and 1200.
= 450, 600, 900, and 1200.
The expected increase of
![]() with
with
![]() is evident.
is evident.
We note that the only significant difference with these findings we obtain from
the simulations with
![]() = 2 is that
= 2 is that
![]() of simulated clusters and
subclusters is closer to
of simulated clusters and
subclusters is closer to
![]() (but still higher).
(but still higher).
![\begin{figure}
\par\includegraphics[width=7.2cm,clip]{7245f03.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img69.gif) |
Figure 3:
Small symbols correspond to
|
| Open with DEXTER | |
We fit
![]() with
with
![]() and obtain
and obtain
As a final test we verify that infra-chip gaps do not have a dramatic impact on
the detection of structures in the cases
![]() = 1 and 2. We place a 50 pixel wide gap where it has the maximum impact, i.e. where the
kernel size is shortest. Even if the infra-chip gap cuts through the center of
the structures, DEDICA is able to identify these structures correctly.
= 1 and 2. We place a 50 pixel wide gap where it has the maximum impact, i.e. where the
kernel size is shortest. Even if the infra-chip gap cuts through the center of
the structures, DEDICA is able to identify these structures correctly.
We summarize here the main results of our tests on simulated clusters with substructures:
We apply our clustering procedure to the 77 clusters of the WINGS sample. The
photometric catalog of each cluster is deep, reaching a completeness
magnitude
![]() .
The number of galaxies is correspondingly
large, from
.
The number of galaxies is correspondingly
large, from
![]() to
to
![]() .
.
The large number of bright background galaxies (faint apparent
magnitudes) dilutes the clustering signal of local WINGS clusters. We
perform test runs of the procedure on several clusters with magnitude
cuts brighter than
![]() .
Based on these tests, we decide to
cut galaxy catalogs to the absolute magnitude threshold
MV =
-16.0. With this choice a) we maximize the signal-to-noise ratio of
the detected subclusters and b) we still have enough galaxies for a stable identification of the system. At the median redshift of WINGS clusters,
.
Based on these tests, we decide to
cut galaxy catalogs to the absolute magnitude threshold
MV =
-16.0. With this choice a) we maximize the signal-to-noise ratio of
the detected subclusters and b) we still have enough galaxies for a stable identification of the system. At the median redshift of WINGS clusters,
![]() ,
our absolute magnitude cut corresponds to an apparent magnitude
,
our absolute magnitude cut corresponds to an apparent magnitude
![]() .
.
This apparent magnitude also approximately corresponds to the magnitude where the contrast of our typical cluster relative to the field is maximum (this estimate is based on the average cluster luminosity function of Yagi et al. (2002), De Propris et al. (2003) and on the galaxy counts of Berta et al. (2006)).
The number of galaxies that are brighter than the threshold
MV =
-16.0 is in the range
![]() for a large fraction of
clusters observed with either WFC@INT or with WFI@MPG/ESO2.2.
for a large fraction of
clusters observed with either WFC@INT or with WFI@MPG/ESO2.2.
In order to proceed with the identification of significant structures within
WINGS clusters, we need to verify that our simulations are sufficiently
representative of the real cases. In practice we need to compare the observed
distributions of
![]() values of noise fluctuations with the corresponding
simulated distributions. In the observations it is impossible to identify
individual fluctuations as noise. In order to have an idea of the distributions
of
values of noise fluctuations with the corresponding
simulated distributions. In the observations it is impossible to identify
individual fluctuations as noise. In order to have an idea of the distributions
of
![]() of noise fluctuations we consider that our fields are centered
on real clusters. As a consequence, on average, fluctuations in the center of
the frames are more likely to correspond to real systems than those at the borders.
of noise fluctuations we consider that our fields are centered
on real clusters. As a consequence, on average, fluctuations in the center of
the frames are more likely to correspond to real systems than those at the borders.
![\begin{figure}
\par\includegraphics[width=7.25cm,clip]{7245f04.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img78.gif) |
Figure 4:
|
| Open with DEXTER | |
We therefore consider separately the fluctuations within the central
regions of the frames and all other fluctuations (borders). We define
the central regions as the central 10% of WFC and WFI areas. We
plot in Fig. 4 the two distributions. The thick
solid histogram is for the border and the thick dashed histogram for
the center of the frames. The difference between "noise'' and "signal''
is clear. In the same figure we also plot the normalized distribution
of
![]() of the noise fluctuations in our simulations (thin solid
line). The distributions of
of the noise fluctuations in our simulations (thin solid
line). The distributions of
![]() of the observed and simulated
fluctuations are in reasonable agreement considering a) the simple
model used for the simulations and that b) in the observations we can
not exclude real low-
of the observed and simulated
fluctuations are in reasonable agreement considering a) the simple
model used for the simulations and that b) in the observations we can
not exclude real low-
![]() structures among noise fluctuations. We
conclude that for our clusters we can adopt the same reliability
threshold
structures among noise fluctuations. We
conclude that for our clusters we can adopt the same reliability
threshold
![]() we determine from our simulations
(Eq. (5)).
we determine from our simulations
(Eq. (5)).
We detect at least one significant structure in 55 (71%) clusters. We find that 12 clusters (16%) have no structure above the threshold (undetected). In the case of another 10 (13%) clusters we find significant structures only at the border of the field of view. In absence of a detection in the center of the frame, we consider these border structures unrelated to the target cluster. We also verify that in the Color-Magnitude Diagram (CMD) these border structures are redder than expected given the redshift of the target cluster. We consider also these 10 clusters undetected.
Here we list the 22 undetected clusters: A0133, A0548b, A0780, A1644, A1668, A1983, A2271, A2382, A2589, A2626, A2717, A3164, A3395, A3490, A3497, A3528a, A3556, A3560, A3809, A4059, RX1022, Z1261.
We note that undetected clusters are real physical systems according to their x-ray selection. From an operative point of view, the fact that these clusters are not detected by DEDICA is the result of the division into too many structures of the total available clustering signal in the field (or of a too large fraction of the clustering signal going into border structures). Several physical situations could be at the origin of missed detections. One possibility is an excess of physical substructures of comparable richness. Another possibility is that these clusters are embedded in regions of the large scale structure that are highly clustered.
We do not try to recover these structures because they can not be prominent enough. Since our analysis is bidimensional, we can only detect and use confidently the most prominent structures. Redshifts are needed for a more detailed analysis of cluster substructures.
We list the 55 clusters with significant structures
in Table A.1. We give, for each substructure: (1) the name of the parent cluster; (2) the classification of the structure as main (M), subcluster (S), or
background (B) together with their order number; (3) right ascension
(J2000), and (4) declination (J2000) in decimal degrees of the DEDICA
peak; the parameters of the ellipse we obtain from the variance matrix
of the coordinates of galaxies in the substructure, i.e. (5) major
axis in arcminutes, (6) ellipticity, and (7) position angle in
degrees; (8) luminosity (see the next section); (9)
![]() .
.
![\begin{figure}
\par\includegraphics[width=6.9cm,clip]{7245f05CMJN.eps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img79.gif) |
Figure 5:
Isodensity contours (logarithmically spaced) of the Abell 85
field. The title lists the coordinates of the center.
The orientation is East to the left, North to
the top. Galaxies belonging to the systems detected by DEDICA are shown
as dots of different colors. Black, light green, blue, red, magenta,
dark green are for the main system and the subsequent
substructures ordered as in Table A.1. Large symbols are for
galaxies with
|
| Open with DEXTER | |
We make available contour plots of the number density fields of all
clusters in Fig. 6 of the electronic version of this
journal. In Fig. 5 we show an example of these
plots. Isodensity contours are drawn at ten logarithmic
intervals. Galaxies belonging to the systems detected by DEDICA are
shown as dots of different colors. We use large symbols for brighter
galaxies (
![]() )
that lie where local densities are higher than
the median local density of the structure the galaxy belongs to.
We also mark with open symbols the positions
of the first- and second-ranked cluster galaxies, BCG1 and BCG2
respectively. Color coding is black, light green, blue, red, magenta,
dark green for the main system and the subsequent substructures
ordered as in Table A.1.
)
that lie where local densities are higher than
the median local density of the structure the galaxy belongs to.
We also mark with open symbols the positions
of the first- and second-ranked cluster galaxies, BCG1 and BCG2
respectively. Color coding is black, light green, blue, red, magenta,
dark green for the main system and the subsequent substructures
ordered as in Table A.1.
We describe and analyze in detail our catalog in the next section.
The first problem we face in order to study the statistical and physical properties of substructures is to determine their association with the main structure. In fact, the main structure itself has to be identified among the structures detected by DEDICA in each frame.
In most cases it is easy to identify the main structure of a cluster
since it is located at the center of the frame and it has a high
![]() .
In two cases (A0168 and A1736) the choice of the main
structure is complicated because there are several similar structures
near the center of the frame. In these cases we select the main
structure for its highest
.
In two cases (A0168 and A1736) the choice of the main
structure is complicated because there are several similar structures
near the center of the frame. In these cases we select the main
structure for its highest
![]() .
.
At this point we limit our analysis to members of the structure that
a) have an absolute magnitude
![]() (corrected for Galactic
absorption) and that b) are in the upper half of the distribution of
DEDICA-defined local galaxy densities of the system they belong to.
The galaxy density threshold we apply allows us to separate adjacent
structures whose definition becomes more uncertain at lower galaxy
density levels. The magnitude cut increases the relative weight of the
galaxies we use to evaluate the nature of structures in the CMD.
(corrected for Galactic
absorption) and that b) are in the upper half of the distribution of
DEDICA-defined local galaxy densities of the system they belong to.
The galaxy density threshold we apply allows us to separate adjacent
structures whose definition becomes more uncertain at lower galaxy
density levels. The magnitude cut increases the relative weight of the
galaxies we use to evaluate the nature of structures in the CMD.
After having identified the main structure, we need to determine which structures in the field of view of a given cluster have to be considered background structures. We consider a structure a physical substructure (or subcluster) if its color-magnitude relation (CMR hereafter) is identical, within the errors, to the CMR of the main structure.
As a first step we define the color-magnitude relation (CMR) of the "whole cluster'', i.e. of galaxies in the main structure together with all other galaxies not assigned to any structure by DEDICA. We compute the (B - V) CMR of the Coma cluster from published data (Adami et al. 2006). Then we keep fixed the slope of the linear CMR of Coma and shift it to the mean redshift of the cluster.
In order to determine that the main structure and a substructure are at
the same redshift, we evaluate the fraction of background (red)
galaxies,
![]() ,
that each structure has in the CMD. If these
fractions are identical within the errors (Gehrels 1986), we
consider the two structures to be at the same redshift.
,
that each structure has in the CMD. If these
fractions are identical within the errors (Gehrels 1986), we
consider the two structures to be at the same redshift.
In practice we determine
![]() by assigning to the background those
galaxies of a structure that are redder than a line parallel to the
CMR and vertically shifted (i.e. redwards) by 2.33 times the root-mean
square of the colors of galaxies in the CMR. We note that the
probability that a random variable is greater than 2.33 in a Gaussian
distribution is only 1%.
by assigning to the background those
galaxies of a structure that are redder than a line parallel to the
CMR and vertically shifted (i.e. redwards) by 2.33 times the root-mean
square of the colors of galaxies in the CMR. We note that the
probability that a random variable is greater than 2.33 in a Gaussian
distribution is only 1%.
The result of the selection of main structures and substructures is
the following: 40 clusters have a total of 69 substructures at the
same redshift as the main structure, only 15 clusters are left without
substructures. A total of 35 systems are found in the background.
Considering a) the number density of poor-to-rich clusters
(Mazure et al. 1996; Zabludoff et al. 1993), b) the average luminosity function of
clusters (De Propris et al. 2003; Yagi et al. 2002), c) the total area covered by
the 55 cluster fields, and d) the limiting apparent magnitude
corresponding to our absolute magnitude threshold MV=-16.0, we
expect to find ![]() 0.5
0.5 ![]() 0.2 background systems per cluster
field, 28
0.2 background systems per cluster
field, 28 ![]() 11 in total. This estimate is consistent with the 35 background systems we find.
11 in total. This estimate is consistent with the 35 background systems we find.
The fraction of clusters with subclusters (73%) is higher than
generally found in previous investigations (typically ![]()
![]() ,
see, e.g., Girardi & Biviano 2002; Flin & Krywult 2006; Lopes et al. 2006, and references therein). Even if
we count all undetected clusters as clusters without substructures,
this fraction only decreases to 52% (40/77). It is however
acknowledged that the fraction of substructured clusters depends,
among other factors, on the algorithm used to detect substructures, on
the quality and depth of the galaxy catalog. For example
Kolokotronis et al. (2001) using optical and X-ray data find that the fraction of
clusters with substructures is
,
see, e.g., Girardi & Biviano 2002; Flin & Krywult 2006; Lopes et al. 2006, and references therein). Even if
we count all undetected clusters as clusters without substructures,
this fraction only decreases to 52% (40/77). It is however
acknowledged that the fraction of substructured clusters depends,
among other factors, on the algorithm used to detect substructures, on
the quality and depth of the galaxy catalog. For example
Kolokotronis et al. (2001) using optical and X-ray data find that the fraction of
clusters with substructures is ![]() 45%, Burgett et al. (2004) using a battery of tests detect substructures in 84% of the 25 clusters of their sample.
45%, Burgett et al. (2004) using a battery of tests detect substructures in 84% of the 25 clusters of their sample.
Having established the "global'' fraction of substructured clusters,
we now investigate the degree of subclustering of individual clusters,
i.e. the distribution of the number of substructures
![]() we find in our sample.
we find in our sample.
We find 15 (27%) clusters without substructures; 22 (40%) clusters
with
![]() = 1; 10 (18%) clusters with
= 1; 10 (18%) clusters with
![]() = 2; 6 (11%)
clusters with
= 2; 6 (11%)
clusters with
![]() = 3; and 2 (3%) clusters with
= 3; and 2 (3%) clusters with
![]() = 4.
We plot in the left panel of Fig. 7 the integral
distribution of
= 4.
We plot in the left panel of Fig. 7 the integral
distribution of
![]() .
.
![\begin{figure}
\par\includegraphics[width=6.5cm,clip]{7245f07.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img84.gif) |
Figure 7:
Cumulative distributions of the two different indicators
ofsubclustering: left panel
|
| Open with DEXTER | |
The distribution of the level of subclustering does not change when we
measure it as the fractional luminosity of subclusters,
![]() ,
relative to the luminosity of the whole cluster (see Fig. 7,
right panel). The luminosities we estimate are background corrected
using the counts of Berta et al. (2006). We use the
ellipses output from DEDICA (see previous section)
as a measure of the area of subclusters.
,
relative to the luminosity of the whole cluster (see Fig. 7,
right panel). The luminosities we estimate are background corrected
using the counts of Berta et al. (2006). We use the
ellipses output from DEDICA (see previous section)
as a measure of the area of subclusters.
We find that
![]() and
and
![]() are clearly correlated according
to the Spearman rank-correlation test.
are clearly correlated according
to the Spearman rank-correlation test.
![\begin{figure}
\par\includegraphics[width=6.9cm,clip]{7245f08.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img85.gif) |
Figure 8: Observed differential distribution of subcluster luminosities (histogram) and theoretical model (arbitrary scaling; De Lucia et al. 2004). |
| Open with DEXTER | |
We now consider the distribution of subcluster luminosities and plot the
corresponding histogram in Fig. 8. In the same figure we also
plot with arbitrary scaling the power-law ![]() L-1. This relation is
the prediction for the differential mass function of substructures in the
cosmological simulations of De Lucia et al. (2004).
L-1. This relation is
the prediction for the differential mass function of substructures in the
cosmological simulations of De Lucia et al. (2004).
Our observations are consistent to within the uncertainties with the
theoretical prediction of De Lucia et al. (2004) down to
![]() .
The disagreement at lower luminosity is expected since: a) below
this limit galaxy-sized halos become important among the simulated
substructures, and b) only above this limit we expect our catalog to be
complete. In fact only subclusters with luminosities brighter than
.
The disagreement at lower luminosity is expected since: a) below
this limit galaxy-sized halos become important among the simulated
substructures, and b) only above this limit we expect our catalog to be
complete. In fact only subclusters with luminosities brighter than
![]() have always richnesses that are
have always richnesses that are ![]() 1/3 of the main
structure. This richness limit approximately corresponds to the completeness
limit of DEDICA detections according to our simulations (see
Sect. 4).
1/3 of the main
structure. This richness limit approximately corresponds to the completeness
limit of DEDICA detections according to our simulations (see
Sect. 4).
Here we investigate the relation between BCGs and cluster structures.
We find that, on average, BCG1s are located close to the density peak
of the main structures. In projection on the sky, the biweight average
(see Beers et al. 1990)
distance of BCG1s from the peak of the main system is 72 ![]() 11 kpc. If we only consider the 44 BCG1s that are on the CMR and are assigned to main systems by DEDICA, the average distance decreases to 56
11 kpc. If we only consider the 44 BCG1s that are on the CMR and are assigned to main systems by DEDICA, the average distance decreases to 56 ![]() 8 kpc. The fact that BCG1s are close to the center of the system is
consistent with current theoretical view on the formation of BCGs
(e.g. Dubinski 1998; Nipoti et al. 2004).
8 kpc. The fact that BCG1s are close to the center of the system is
consistent with current theoretical view on the formation of BCGs
(e.g. Dubinski 1998; Nipoti et al. 2004).
BCG2s are more distant than BCG1s from the peak of the main system:
the biweight average distance is 345 ![]() 47 kpc. If we only consider
the 26 BCG2s that are on the CMR and are assigned to main systems by
DEDICA, the average distance decreases to 161
47 kpc. If we only consider
the 26 BCG2s that are on the CMR and are assigned to main systems by
DEDICA, the average distance decreases to 161 ![]() 34 kpc.
34 kpc.
Projected distances of BCG2s from density peaks remain larger than those of BCG1s even when we consider the density peak of the structure or substructure they belong to. In Fig. 9 we plot the cumulative distributions of the distances of BCG1s (solid line) and BCG2s (dashed line) from the density peak of their systems. The distributions are different at the >99.99% level according to a Kolmogorov-Smirnov test (KS-test).
![\begin{figure}
\par\includegraphics[width=7.25cm,clip]{7245f09.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img88.gif) |
Figure 9: Cumulative distributions of distances of BCG1 (solid line) and BCG2 (dashed line) from the density peak of their system. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=6.9cm,clip]{7245f10.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img89.gif) |
Figure 10: Cumulative distributions of the magnitude difference between BCG1 and BCG2 in clusters with (dashed line) and without subclusters (solid line). |
| Open with DEXTER | |
Now we turn to luminosities and find that the magnitude difference between
BCG1s and BCG2s,
![]() ,
is larger in clusters without
substructures than in clusters with substructures. In
Fig. 10 we plot the cumulative distributions of
,
is larger in clusters without
substructures than in clusters with substructures. In
Fig. 10 we plot the cumulative distributions of
![]() for clusters with (dashed line) and without (solid line)
subclusters. The two distributions are different according to a KS-test at the 99.1% confidence level. We note that Lin & Mohr (2004)
find that
for clusters with (dashed line) and without (solid line)
subclusters. The two distributions are different according to a KS-test at the 99.1% confidence level. We note that Lin & Mohr (2004)
find that
![]() is independent of cluster properties. These
authors however do not consider subclustering.
is independent of cluster properties. These
authors however do not consider subclustering.
In order to determine whether the higher values of
![]() in
clusters without subclusters are due to an increased luminosity of the
BCG1 (L1) or to a decreased luminosity of the BCG2 (L2), we
consider the luminosity of the 10th brightest galaxy (L10)
as a reference. The biweight average luminosity ratios are
in
clusters without subclusters are due to an increased luminosity of the
BCG1 (L1) or to a decreased luminosity of the BCG2 (L2), we
consider the luminosity of the 10th brightest galaxy (L10)
as a reference. The biweight average luminosity ratios are
![]() = 8.6
= 8.6 ![]() 1.0 and
1.0 and
![]() = 3.3
= 3.3 ![]() 0.3 in clusters without substructures, and
0.3 in clusters without substructures, and
![]() = 7.1
= 7.1 ![]() 0.4 and
0.4 and
![]() = 3.4
= 3.4 ![]() 0.2 in clusters with substructures. We then conclude that the
0.2 in clusters with substructures. We then conclude that the
![]() -effect
is caused by a brightening of the BCG1 relative to the BCG2 in
clusters without substructures.
-effect
is caused by a brightening of the BCG1 relative to the BCG2 in
clusters without substructures.
The fact that
![]() is higher in clusters without substructures can
be interpreted, at least qualitatively, in the framework of the hierarchical
scenario of structure evolution. Clusters without substructures are likely to
be evolved after several merger phases. Their BCG1s have already had time to
accrete many galaxies, in particular the more massive ones, which slow down and
sink to the cluster center as the result of dynamical friction. Some of these
galaxies may even have been BCGs of the merging structures. The simulations by
De Lucia & Blaizot (2006) show that the BCG1s continue to increase their mass
via cannibalism even at recent times, and that there is a large variance in the
mass accretion history of BCG1s from cluster to cluster. The result of such a cannibalism process is an increase of the BCG1 luminosity with respect to other
cluster galaxies, and in extreme cases may lead to the formation of fossil
groups (Khosroshahi et al. 2006).
is higher in clusters without substructures can
be interpreted, at least qualitatively, in the framework of the hierarchical
scenario of structure evolution. Clusters without substructures are likely to
be evolved after several merger phases. Their BCG1s have already had time to
accrete many galaxies, in particular the more massive ones, which slow down and
sink to the cluster center as the result of dynamical friction. Some of these
galaxies may even have been BCGs of the merging structures. The simulations by
De Lucia & Blaizot (2006) show that the BCG1s continue to increase their mass
via cannibalism even at recent times, and that there is a large variance in the
mass accretion history of BCG1s from cluster to cluster. The result of such a cannibalism process is an increase of the BCG1 luminosity with respect to other
cluster galaxies, and in extreme cases may lead to the formation of fossil
groups (Khosroshahi et al. 2006).
However, according to these simulations, only 15% of all BCG1s have accreted >30% of their mass over the last 2 Gyr, while another 15% have accreted <3% of their mass over the same period. Our results indicate that about 60% of the BCG1s are more than 1 mag brighter than the corresponding BCG2s. Given the size and generality of the luminosity differences it would seem that cannibalism alone, even if present along the merging history of a given cluster, cannot account for it. Most of the BCG1s should have then been assembled in early times, as pointed out in the downsizing scenario for galaxy formation (Cowie et al. 1996) and entered that merging history already with luminosity not far from the present one.
In this paper we search for and characterize cluster substructures, or subclusters, in the sample of 77 nearby clusters of the WINGS (Fasano et al. 2006). This sample is an almost complete sample in X-ray flux in the redshift range 0.04<z<0.07.
We detect substructures in the spatial projected distribution of galaxies in the cluster fields using DEDICA (Pisani 1996,1993) an adaptive-kernel technique. DEDICA has the following advantages for our study of WINGS clusters:
We find that: a) DEDICA always identifies both cluster and
subcluster even when the substructure richness ratio cluster-to-subcluster
is
![]() = 8, b) DEDICA recovers a large
fraction of members, almost irrespective of the richness of the original
structure (
= 8, b) DEDICA recovers a large
fraction of members, almost irrespective of the richness of the original
structure (![]()
![]() in most cases), c) structures with richness
ratios
in most cases), c) structures with richness
ratios
![]()
![]() 3 are always distinguishable from noise fluctuations of
the poissonian simulated field.
3 are always distinguishable from noise fluctuations of
the poissonian simulated field.
These simulations also allow us to define a threshold that we use to identify significant structures in the observed fields.
We apply our clustering procedure to the 77 clusters of the WINGS sample. We cut galaxy catalogs to the absolute magnitude threshold MV = -16.0 in order to maximize the signal-to-noise ratio of the detected subclusters.
We detect at least one significant structure in 55 (71%) cluster fields. We find that 12 clusters (16%) have no structure above the threshold (undetected). In the remaining 10 (13%) clusters we find significant structures only at the border of the field of view. In absence of a detection in the center of the frame, we consider these border structures unrelated to the target cluster. We also verify that in the CMD these border structures are redder than expected given the redshift of the target cluster. We consider also these clusters undetected.
We provide the coordinates of all substructures in the 55 clusters together with their main properties.
Using the CMR of the early-type cluster galaxies we separate "true'' subclusters from unrelated background structures. We find that 40 clusters out of 55 (73%) have a total of 69 substructures with 15 clusters left without substructures.
The fraction of clusters with subclusters (73%) we identify is higher
than most previously published values (typically ![]() 30%, see,
e.g., Girardi & Biviano 2002, and references therein). It is however acknowledged that
the fraction of substructured clusters depends, among other factors,
on the algorithm used to detect substructures, on the quality and
depth of the galaxy catalog (Burgett et al. 2004; Kolokotronis et al. 2001).
30%, see,
e.g., Girardi & Biviano 2002, and references therein). It is however acknowledged that
the fraction of substructured clusters depends, among other factors,
on the algorithm used to detect substructures, on the quality and
depth of the galaxy catalog (Burgett et al. 2004; Kolokotronis et al. 2001).
Another important result of our analysis is the distribution of
subcluster luminosities. In the luminosity range where our
substructure detection is complete (
![]() ),
we find that the distribution of subcluster luminosities is in
agreement with the power-law
),
we find that the distribution of subcluster luminosities is in
agreement with the power-law ![]() L-1 predicted for the
differential mass function of substructures in the cosmological
simulations of De Lucia et al. (2004).
L-1 predicted for the
differential mass function of substructures in the cosmological
simulations of De Lucia et al. (2004).
Finally, we investigate the relation between BCGs and cluster structures.
We find that, on average, BCG1s are located close to the density peak
of the main structures. In projection on the sky, the biweight average
distance of BCG1s from the peak of the main system is 72 ![]() 11 kpc. BCG2s are significantly more distant than BCG1s from the peak of the
main system (345
11 kpc. BCG2s are significantly more distant than BCG1s from the peak of the
main system (345 ![]() 47 kpc).
47 kpc).
The fact that BCG1s are close to the center of the system is consistent with current theoretical view on the formation of BCGs (Dubinski 1998).
A more surprising result is that the magnitude difference between
BCG1s and BCG2s,
![]() ,
is significantly larger in clusters without
substructures than in clusters with substructures. This fact
may be interpreted in the framework of the hierarchical
scenario of structure evolution (e.g. De Lucia & Blaizot 2006).
,
is significantly larger in clusters without
substructures than in clusters with substructures. This fact
may be interpreted in the framework of the hierarchical
scenario of structure evolution (e.g. De Lucia & Blaizot 2006).
We provide here the catalog of substructures. In
Table A.1 we give, for each substructure: (1) the name of
the parent cluster; (2) the classification of the structure as main (M), subcluster (S), or background (B) together with their order number; (3) right ascension (J2000), and (4) declination (J2000) in decimal degrees of the DEDICA peak; the parameters of the ellipse we
obtain from the variance matrix of the coordinates of galaxies in the
substructure, i.e. (5) major axis in arcminutes, (6) ellipticity, and
(7) position angle in degrees; (8) luminosity; (9)
![]() .
.
![\begin{figure}
\par\includegraphics[width=14.5cm,clip]{7245f601.ps}\end{figure}](/articles/aa/full/2007/28/aa7245-07/img100.gif) |
Figure 6:
Isodensity contours (logarithmically spaced) of the 55 clusters with significant structures. The title lists the coordinates of the center. The orientation is East to the left, North to the top. Galaxies belonging to the systems detected by DEDICA are shown
as dots of different colors. Black, light green, blue, red, magenta,
dark green are for the main system and the subsequent
substructures ordered as in Table A.1. Large symbols are for
galaxies with
|
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f602.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img101.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f603.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img102.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f604.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img103.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f605.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img104.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f606.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img105.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f607.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img106.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f608.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img107.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=14.5cm,clip]{7245f609.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img108.gif) |
Figure 6: continued. |
| Open with DEXTER | |
![\begin{figure}\par\includegraphics[width=6.8cm,clip]{7245f610.ps}
\end{figure}](/articles/aa/full/2007/28/aa7245-07/img109.gif) |
Figure 6: continued. |
| Open with DEXTER | |