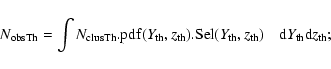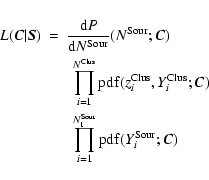A&A 465, 57-65 (2007)
DOI: 10.1051/0004-6361:20054680
J. B. Juin1,2 - D. Yvon1 - A. Réfrégier1 - C. Yèche1
1 - CEA/DSM/DAPNIA, CE Saclay, Bât 141, 91191 Gif-sur-Yvette Cedex, France
2 -
Universidad de Concepción, Astronomy group, Casilla 160-c, Concepción, Chile
Received 12 December 2005 / Accepted 15 January 2007
Abstract
The cosmological potential of large-scale structure observations for cosmology have been extensively discussed in the litterature. In particular, it has recently been shown how Sunyaev-Zel'dovich (SZ) cluster surveys can be used to constrain dark energy parameters.
In this paper, we study whether selection and systematics effects will limit future wide-field SZ surveys from achieving their cosmological potential. For this purpose, we use a sky simulation and an SZ-cluster detection software presented in Pires et al. (2006, A&A, 455, 741), using the future Olimpo survey as a concrete example. We show that the SZ-cluster selection function and contamination of SZ-cluster catalogues are more complex than is usually assumed. In particular, the simulated field-to-field detected cluster counts variance can be a factor 3 larger than the expected Poisson fluctuations. We also study the impact of missing redshift information and of the uncertainty of the scaling relations for
low mass clusters. We quantify, through hypothesis tests, how near-future SZ experiments can be used to discriminate between different structure formation models. Using a maximum likelihood approach, we then study the impact of these systematics on the joint measurement of cosmological models and of cluster scaling relations.
Key words: cosmology: cosmological parameters - large-scale structure of Universe - cosmic microwave background - galaxies: clusters: general
In the next few years, a new generation of dedicated instruments based on large-array bolometer cameras (APEX![]() , ACT
, ACT![]() , SPT
, SPT![]() , BOLOCAM
, BOLOCAM![]() , OLIMPO (Masi et al. 2003), and improved interferometers (AMI
, OLIMPO (Masi et al. 2003), and improved interferometers (AMI![]() , AMiBA
, AMiBA![]() , SZA
, SZA![]() ) will provide large amount of information on cosmic structure formation and evolution, and thus on cosmological models. The Planck satellite (Lamarre et al. 2004), to be launched in 2007, will provide a full-sky catalogue of galaxy clusters detected by their Sunyaev-Zel'dovich (SZ) signal (Sunyaev & Zel'dovich 1972,1970). The potential of SZ observations results from the properties of the SZ effect: the lack of surface dimming and the "clean'' measurement of thermal energy of the cluster gas, should afford a measure of the cluster mass function up to high redshift, with reduced systematics when combined with X-ray observations and weak lensing surveys. The distribution of cluster abundance with redshift is sensitive to the cosmological parameters
) will provide large amount of information on cosmic structure formation and evolution, and thus on cosmological models. The Planck satellite (Lamarre et al. 2004), to be launched in 2007, will provide a full-sky catalogue of galaxy clusters detected by their Sunyaev-Zel'dovich (SZ) signal (Sunyaev & Zel'dovich 1972,1970). The potential of SZ observations results from the properties of the SZ effect: the lack of surface dimming and the "clean'' measurement of thermal energy of the cluster gas, should afford a measure of the cluster mass function up to high redshift, with reduced systematics when combined with X-ray observations and weak lensing surveys. The distribution of cluster abundance with redshift is sensitive to the cosmological parameters ![]() and
and
![]() ,
and also to a lower extend to
,
and also to a lower extend to
![]() and the dark energy equation-of-state (Haiman et al. 2001; Barbosa et al. 1996; Oukbir & Blanchard 1997). Battye & Weller (2003) studied the dependence of these cosmological constraints on large scale structure formation and gas cluster physics models. Melin et al. (2005) presented a first study of the selection function of large SZ-cluster survey.
and the dark energy equation-of-state (Haiman et al. 2001; Barbosa et al. 1996; Oukbir & Blanchard 1997). Battye & Weller (2003) studied the dependence of these cosmological constraints on large scale structure formation and gas cluster physics models. Melin et al. (2005) presented a first study of the selection function of large SZ-cluster survey.
Table 1:
Cosmological and gas physics parameters used in the simulations. Densities relative to critical density are labelled ![]() .
.
![]() is the density of universe, all components included,
is the density of universe, all components included,
![]() is the baryon density,
is the baryon density,
![]() the vacuum energy density,
the vacuum energy density,
![]() the dark matter density. h is the reduced Hubble constant,
the dark matter density. h is the reduced Hubble constant, ![]() the spectral index of primordial density power spectrum,
the spectral index of primordial density power spectrum, ![]() the rms density fluctuations in spheres of
the rms density fluctuations in spheres of ![]() diameter,
diameter,
![]() the mass function used in cluster abundance computations,
the mass function used in cluster abundance computations, ![]() the cluster mass-temperature normalisation factor, and
the cluster mass-temperature normalisation factor, and ![]() the cluster gas mass fraction. The double vertical line destinguishes the primordial cosmological parameters, from the ingredients of the structure formation semi-analytic model.
the cluster gas mass fraction. The double vertical line destinguishes the primordial cosmological parameters, from the ingredients of the structure formation semi-analytic model.
In this paper, we use simulations of the sky and of an SZ experiment, along with a recent cluster detection pipeline presented in Pires et al. (2006), to simulate future large-array bolometer observations and cluster detections. We first discuss photometric issues, and then present a detected cluster catalogue, with its selection function, and purity curves. Those are found to be complex. In particular, the contamination of the cluster catalogue is quantified as a function of cluster brightness. We also compute the count variance in the observed catalogues.
We then assume that the observations and cluster detection can be statistically described by an observation model. This observation model allows us to transform a semi-analytic cosmology-motivated cluster count functions,
![]() ,
into a set of probability density functions (pdf) of the detected cluster observed parameters
,
into a set of probability density functions (pdf) of the detected cluster observed parameters
![]() and of the contaminants
and of the contaminants
![]() and
and
![]() ,
where Y is the Compton parameter integrated over the cluster angular size, and z the redshift. This observation model is found to be accurate enough given the statistics of the upcoming SZ cluster surveys and to be computationally very effective.
Based on this model, we then discuss our ability to constraint cosmology assumptions and parameters. We show, using an hypothesis test method, how future SZ surveys will make it possible to distinguish between several mass functions. We quantify the constraint that such an experiment would place on the effective "heating'' parameter T*, using the cosmological parameters values measured by WMAP to break degeneracies.
We conclude by showing how any conclusions on cosmological parameters are sensitive to inaccuracies in the observation model.
,
where Y is the Compton parameter integrated over the cluster angular size, and z the redshift. This observation model is found to be accurate enough given the statistics of the upcoming SZ cluster surveys and to be computationally very effective.
Based on this model, we then discuss our ability to constraint cosmology assumptions and parameters. We show, using an hypothesis test method, how future SZ surveys will make it possible to distinguish between several mass functions. We quantify the constraint that such an experiment would place on the effective "heating'' parameter T*, using the cosmological parameters values measured by WMAP to break degeneracies.
We conclude by showing how any conclusions on cosmological parameters are sensitive to inaccuracies in the observation model.
Future large-array bolometer surveys share some common features. They observe the sky in several frequency bands to facilitate astronomical source separation. They use large bolometer matrices to maximise redundancy of observation on the sky and speed up field coverage. They are ambitious in terms of mission length, given the technology. In this paper, we mostly use the Olimpo project as a concrete example of an upcoming bolometer-based large SZ survey. The same methods should be easely adapted for the other large-array bolometers surveys.
In the following, we use the sky simulation software, the instrument model and the cluster detection pipeline described in (Pires et al. 2006). We briefly summarise it here for convenience and pointout the minor differences when necessary. We simulated four astrophysical contributions to the sky map: primordial CMB anisotropies (excluding the dipole), bright infrared galaxies as observed by SCUBA (Borys et al. 2003), the infrared emission of the Galaxy and SZ-clusters. All simulations uses a cosmological model with parameters shown in Table 1.
Figure 1 shows the distribution of the generated cluster as a function of redshift and integrated Compton flux.
![\begin{figure}
\par\includegraphics[width=5.65cm,clip]{Figures/4680fg1a.eps}\par\includegraphics[width=5.65cm,clip]{Figures/4680fg1b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img30.gif) |
Figure 1: Generated cluster distribution as a function of redshift and integrated Compton flux. |
| Open with DEXTER | |
The frequency dependence of the bright infrared sources and of galactic dust are described by a grey-body spectrum. The spectral index of bright infrared sources is generated randomly for each sources between 1.5 and 2. Table 2 provide the noise level and the FWHM of antenna lobe at each frequencies, which is assumed be Gaussian. Bandwidth filters are assumed have a top hat response.
| |
Figure 2: Simulations of sky maps, as observed by a large-array bolometer experiment. For these simulations, we used the Olimpo experiment model. From left to right, 143, 217, 385, and 600 GHz bands are shown. In the two lower frequencies band, CMB primordial anisotropies are the dominant features. At higher frequencies bands, bright Infrared galaxies and Galactic dust become dominant. The SZ cluster signal is sub-dominant at all frequencies. |
| Open with DEXTER | |
Figure 2 shows the "observed'' maps, simulated using the Olimpo parameters. We then apply an Independent Component Analysis method named JADE (Cardoso 1999) on our map, after a wavelet transform. JADE separates the SZ signal from the other astrophysical sources effectively, as long as the noise level is kept low enough, and provides a noisy SZ map. Unlike in Pires et al. (2006), we convolve the noisy SZ map with a Gaussian of user chosen width: this turned out to minimise photometry biases at low brightness. Then we use the SExtractor software (Bertin & Arnouts 1996) to detect bright sources. Detected sources can be reliably associated with simulated clusters and are labelled as "true'' clusters. This allows us to compute the selection function and the photometric accuracy of our simulated observations. Detections that are not associated with simulated clusters are identified as contaminants. We can then calculate the purity of our recovered sample and the brightness distribution of the contaminants.
Table 2: Foreseen experimental features of the Olimpo balloon bolometer project.
Selecting the sources associated with simulated clusters, following Melin et al. (2005), we plot in Fig. 3 the observed cluster flux
![]() versus the true simulated flux
versus the true simulated flux
![]() ,
and derive our photometry model, i.e. the probability density function pdf(
,
and derive our photometry model, i.e. the probability density function pdf(
![]() ). The observed flux is overestimated at low brightness due to the Malmquist-Eddington bias (Malmquist 1920). Our first attempt for a statistical model reproduces very well the simulated photometric behaviour, except for the (small) non-Gaussian tails.
). The observed flux is overestimated at low brightness due to the Malmquist-Eddington bias (Malmquist 1920). Our first attempt for a statistical model reproduces very well the simulated photometric behaviour, except for the (small) non-Gaussian tails.
![\begin{figure}
\par\mbox{
\includegraphics[width=5.85cm,clip]{Figures/4680fg3a.eps}\includegraphics[width=6.15cm,clip]{Figures/4680fg3b.eps} }
\end{figure}](/articles/aa/full/2007/13/aa4680-05/img40.gif) |
Figure 3: Left: cluster reconstructed flux versus the true simulated flux, and our photometry model contours. Dashed lines are the one sigma error and dash-dotted are the 2 sigmas errors; the continuous line is the mean. 20 cumulative Monte-Carlo simulations where used for this plot. Right: SZ cluster reconstructed virial size versus true simulated virial size. Although the normalization is not correct, a small correlation is visible for large clusters. |
| Open with DEXTER | |
One way to infer the redshift of a cluster would be to measure its virial radius. Figure 3 plots the reconstructed clusters virial radius versus their true (simulated) virial radius. One can hardly see a significant correlation between the simulated virial radius and the observed virial radius. This is the reason why we decided to neglect this information in the following work.
| |
Figure 4: Completness as a function of redshift for flux (left) and mass (middle), as simulated from a semi-analytic large scale structure and cosmology model. We used design parameters of the Olimpo project to model observation performance. Right: modelled selection function after extended simulations. |
| Open with DEXTER | |
From the true cluster catalogue, we computed the cluster detection probability as a function of cluster integrated fluxes, redshifts and masses. Figure 4 left and middle, show the results. We see that a selection function can not be taken as a simple cut in total flux, nor in mass. We also notice that clusters at large redshift are detected, even though very few are predicted by the cosmological model. To quantify the selection function at high redshift, we therefore introduced "by hand'' in our simulated map, 10% additional high-z clusters, randomly generated in the guessed Y-threshold area (3.5 ![]() 10-5 < Y < 10-3 and
1.2 < z < 5). We averaged 100 Monte-Carlos and we obtained the completness map plotted at Fig. 4 right. The selection function reduces to a simple Y sensitivity curve at large redshift, when cluster sizes become smaller than angular resolution. But at redshift below 1, where we expect to detect most of the clusters, the completness curve is strongly distorted toward high Compton flux.
For convenience, we provide in Annex 6 the tabulated values of Olimpo selection function versus cluster mass and redshift.
10-5 < Y < 10-3 and
1.2 < z < 5). We averaged 100 Monte-Carlos and we obtained the completness map plotted at Fig. 4 right. The selection function reduces to a simple Y sensitivity curve at large redshift, when cluster sizes become smaller than angular resolution. But at redshift below 1, where we expect to detect most of the clusters, the completness curve is strongly distorted toward high Compton flux.
For convenience, we provide in Annex 6 the tabulated values of Olimpo selection function versus cluster mass and redshift.
![\begin{figure}
\par\includegraphics[width=5.6cm,clip]{Figures/4680fg5a.eps}\par\includegraphics[width=5.6cm,clip]{Figures/4680fg5b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img43.gif) |
Figure 5: We ran 100 montecarlo on 400 deg2. Left: the black curve is the histogram of generated cluster flux, compared to the blue (dashed line) histogram of true cluster detection. Right: the blue (dashed line) histogram is the true cluster observed flux. The flux distribution of the contamination is plotted in (light line) orange. The (thin line) red curve is our modelled flux distribution of contamination. |
| Open with DEXTER | |
Future SZ-cluster experiments won't be able to easily sort the contamination from the true clusters. Our evaluation of the observed flux distribution of contaminants is done by selecting sources that are not associated with simulated clusters, and is shown at Fig. 5. The contamination histogram provides the red curve which we use as our modelled flux distribution of contamination. An integration over histograms shown in Fig. 5 lead to a sample purity value of 95%, tuned by choosing the detection threshold.
Cluster counts provides powerful information for large scale structure physics and cosmology. If the counts are dominated by field-to-field variations, one would expect them to follow a Poisson distribution. We found that this might not be true.
Figure 6 shows the histograms of cluster, contamination and source counts for 100 simulated fields. Overprinted is the fit to simulation data. By computing the peak FWHM, we note a factor of 3 excess widths, relative to Poisson's distribution expectation. The issue is related to the flux calibration of the observations. Astronomical observations are usually calibrated on reference objects on the sky. This is what we have done with these simulations: we selected the 100 brightess true clusters in the recovered map, and fitted a single scaling coefficiant so that their recovered flux best match the simulated flux.
It turns out that doing so, we introduce a random error (5![]() )
on our qualibration and thus on the Y threshold applied when selecting clusters, that lead to the observed enlarged count variance.
Assuming now the (thermal) SZ frequency spectrum known, (a rigourous approximation for non relativitic cluster gas) and perfect knowledge of the instrumentation, we can on simulated data, compute the true calibration factor including the cluster extraction software chain. The count variance recovered using this calibration now closely match the Poisson distribution. Abnormal number of detections for some data set (i.e., the tails of the distribution) are also significantly reduced. Thus one of the challenge of future experiments will be to optimize their Y calibration, since as we will show at paragraph 4.4.1, enlarged count variance dramatically deteriorates constraints on cosmological parameters.
In the following we will use both the nominal Poisson distribution and fits to the degraded simulated cluster and contamination counts (red curves in Fig. 6) to construct our observation models and support discussion.
)
on our qualibration and thus on the Y threshold applied when selecting clusters, that lead to the observed enlarged count variance.
Assuming now the (thermal) SZ frequency spectrum known, (a rigourous approximation for non relativitic cluster gas) and perfect knowledge of the instrumentation, we can on simulated data, compute the true calibration factor including the cluster extraction software chain. The count variance recovered using this calibration now closely match the Poisson distribution. Abnormal number of detections for some data set (i.e., the tails of the distribution) are also significantly reduced. Thus one of the challenge of future experiments will be to optimize their Y calibration, since as we will show at paragraph 4.4.1, enlarged count variance dramatically deteriorates constraints on cosmological parameters.
In the following we will use both the nominal Poisson distribution and fits to the degraded simulated cluster and contamination counts (red curves in Fig. 6) to construct our observation models and support discussion.
![\begin{figure}
\par\mbox{
\includegraphics[width=4cm,clip]{Figures/4680fg6a.eps}...
...80fg6e.eps}\includegraphics[width=4cm,clip]{Figures/4680fg6f.eps} }
\end{figure}](/articles/aa/full/2007/13/aa4680-05/img45.gif) |
Figure 6: From left to right, first line: true clusters, contamination and sources counts histograms for 100 simulations. Red curve fits are used in the following observations' model. Second line show same results when assuming a perfect calibration of SZ cluster observations. |
| Open with DEXTER | |
Our first goal in building an observation model is to identify and understand systematic effects in large-array bolometer surveys, relevant to cluster detection and cosmology. The second is to avoid to run a full Monte-Carlo chain to generate source catalogues observed by SZ-survey, a time consuming step in an analysis software that limits the number of possible iterations in partice. This is a strong assumption, that we checked up to the precision of the statistical uncertainties of upcoming surveys.
Semi-analytic LSS model provides the expected number
![]() of cluster of flux above a chosen threshold
of cluster of flux above a chosen threshold
![]() and the cluster probability density function pdf(
and the cluster probability density function pdf(
![]() ,
,
![]() ). The observation model includes:
). The observation model includes:
| |
Figure 7:
Left: the cluster distribution generated by simulations,
|
| Open with DEXTER | |
The above components of the observation model have been derived from the simulations, given instruments parameters and for the concordance cosmological model. They have been shown to be very sensitive to experiment properties such as noise level, number of observation bands, etc. When constraining cosmological parameters, these experimental effects are expected to be under control. On the other hand, we assume that the observation model is not sensitive to the cosmological parameters, when these are reasonably close to our reference model. This assumption is strong and not obvious, since in large-array bolometers survey, the contribution of source confusion to the photometric noise may not be negligible. We checked the validity of this assumption, all other parameters being kept constant, by changing the cluster map density by a factor 1.5 and 0.75. Both recovered observation models were compatible with the above model, except for a small increase in the width of the photometry curve (paragraph 2.1) in the large density option. We assumed this to be acceptable since, would such a dramatic discrepancy of cluster density be observed, we would recalibrate our observation model on representative simulations.
![\begin{figure}
\par\includegraphics[width=6.15cm,clip]{Figures/4680fig8.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img60.gif) |
Figure 8:
Probability density of the recovered cosmological parameters |
| Open with DEXTER | |
Thus given a cosmological model and observations' model, we derive a set probability density function describing our observations: pdf(
![]() ), pdf(
), pdf(
![]() ,
,
![]() ), pdf(
), pdf(
![]() ), pdf(
), pdf(
![]() ). Figure 7 shows the distributions of flux and redshifts of detected clusters, generated by full Monte-Carlo and from our observation model. Those are remarkably similar, thus confirming the validity of our observation model.
). Figure 7 shows the distributions of flux and redshifts of detected clusters, generated by full Monte-Carlo and from our observation model. Those are remarkably similar, thus confirming the validity of our observation model.
We also tested whether the use of the observation model would bias the cosmological parameter estimation. For this purpose, we computed 100 full Monte-Carlo source catalogues. For each catalogue, we computed the cosmological parameters using our observations' model. Figure 8 show the surface density of two of the cosmological parameters ![]() and
and
![]() mostly relevant for this study, fitted by the Extended Likelyhood method (EL), presented at paragraph 4.1. We observe that the input cosmological parameters are well within the 68% CL contour of the distribution. Thus, the bias induced by the observation model is small compared to the statistical error of the observations.
mostly relevant for this study, fitted by the Extended Likelyhood method (EL), presented at paragraph 4.1. We observe that the input cosmological parameters are well within the 68% CL contour of the distribution. Thus, the bias induced by the observation model is small compared to the statistical error of the observations.
We conclude that the use of an observation model is legitimate given the accuracy of upcoming experiments. This observation model will be improved: taking into account non Gaussian tails in our photometry model is the main improvement foreseen. In the following, all source catalogues have been generated using the observation model.
The mains physics goals of large SZ-cluster surveys are to learn more about cluster gas physics, large scale structure, and cosmology. These physical models are parametrised, and involve assumptions that can be tested by future SZ cluster surveys. In the following, we first present statistical tools and results testing the compatibility of our data, with a parametrised model family in paragraph hypothesis tests. Then we show how SZ cluster data can constraint the mass temperature normalisation factor T*, using a classical parameter estimation method.
Assuming then T* known, we explore the potential of SZ cluster survey, for constraining cosmological parameters
![]() and
and ![]() ,
assuming all other parameters known.
We conclude by showing the effect on cosmological parameters of oversimplifying features of the observations' model.
In the following we assumed we have available a catalogue of observed sources corresponding to a nominal Olimpo scientific flight: 490 sources observed over 300 square degrees.
,
assuming all other parameters known.
We conclude by showing the effect on cosmological parameters of oversimplifying features of the observations' model.
In the following we assumed we have available a catalogue of observed sources corresponding to a nominal Olimpo scientific flight: 490 sources observed over 300 square degrees.
The tool for all the following statistical tests is the so called extended likelihood of the cosmological parameters ![]() ,
given the experimental source catalog
,
given the experimental source catalog ![]() :
:
![]() .
.
The likelihood incoporates three kinds of information available in the data. The first factor is the probability of observing
![]() sources given the cosmological parameters
sources given the cosmological parameters ![]() .
The second factor is the probability of observing a cluster with a flux Y and at redshift z (using follow-up observations). We assume that the follow-up observation established whether the source is a cluster of galaxies, or a false detection. In the latter case, this source is excluded from the likelihood, except from the first factor. The third factor is the probability of observing a source of flux Y, when no follow-up observations were available. In this case, we do not know whether this source is a SZ-cluster or a false detection. Our observation model (paragraph 3) provides these three factors in the likelihood, either directly or after integration and normalisation of the distributions.
.
The second factor is the probability of observing a cluster with a flux Y and at redshift z (using follow-up observations). We assume that the follow-up observation established whether the source is a cluster of galaxies, or a false detection. In the latter case, this source is excluded from the likelihood, except from the first factor. The third factor is the probability of observing a source of flux Y, when no follow-up observations were available. In this case, we do not know whether this source is a SZ-cluster or a false detection. Our observation model (paragraph 3) provides these three factors in the likelihood, either directly or after integration and normalisation of the distributions.
![\begin{figure}
\par\includegraphics[width=5.65cm,clip]{Figures/4680fg9a.eps}\par\includegraphics[width=5.65cm,clip]{Figures/4680fg9b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img68.gif) |
Figure 9:
Left: histogram of log-likelihood L (black) for N Monte-Carlo catalogue of a Press-Schechter cosmological model. The peak is fitted by a Gaussian law (red line), with mean
|
| Open with DEXTER | |
The question we wish to answer before constraining parameters models is whether there exist a parametrised model which is compatible with our data. To settle this issue, we use an hypothesis test method. For a cosmological model, we generate by Monte-Carlo a large number of observed source catalogues, compute their likelihood for the given cosmological model and build an histogram of the likelihood (see Fig. 9). The normalisation of the integral of the histogram provides the probability curve of an observed catalogue to be compatible with the cosmological model. The use of the statistical observation model speeds up this work dramatically. Figure 9 left, shows the histogram of the likelihoods computed assuming the concordance cosmological model and a Press and Schechter mass function (Press & Schechter 1974) for the clusters. The black line shows the likelihood value computed for a source catalogue computed with the same cosmology, but with the mass function of Sheth and Tormen (Sheth et al. 2001). The probability of compatibility is lower than 10-5. The Press and Schechter hypothesis is thus rejected by the data. In practise, cosmological parameters are free parameters and we often obtain a compatibility valley for our parameters with our "observed'' data. Other sources of constraints on cosmological parameters (such as CMB anisotropies) will allow us to select the relevant cosmological models and mass function.
Once we have selected a parametrised model compatible with out data, the next question is to
estimate a set of best cosmological parameters, in agreement with data and to compute the associated errors (or confidence levels).
For this purpose, we minimise the function
![]() over
over ![]() ,
vector of the model parameters, to find the best model
,
vector of the model parameters, to find the best model
![]() according to our data and his likelihood
according to our data and his likelihood
![]() .
Then we generate, according to
.
Then we generate, according to
![]() ,
many source catalogues
,
many source catalogues ![]() .
We minimise the likelihood to find the best model
.
We minimise the likelihood to find the best model ![]() matching each
matching each ![]() ,
and build the histogram of
,
and build the histogram of
| (2) |
![\begin{figure}
\par\includegraphics[width=5.65cm,clip]{Figures/4680fg10.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img79.gif) |
Figure 10:
Left: histogram (red) of difference of log-likelihood |
| Open with DEXTER | |
We now use the above tools to constraint the cosmological parameters. In the following, we will assume a ![]() CDM cosmological model with parameter list of Table 1. The most important parameters for large scale structure formation and SZ-clusters are
CDM cosmological model with parameter list of Table 1. The most important parameters for large scale structure formation and SZ-clusters are ![]() and
and
![]() as well as T*, the normalisation of the mass to temperature scale relations (Pierpaoli et al. 2001) in cluster formation models. We plot in Fig. 11 the expected constraints on
as well as T*, the normalisation of the mass to temperature scale relations (Pierpaoli et al. 2001) in cluster formation models. We plot in Fig. 11 the expected constraints on ![]() and
and
![]() from SZ-cluster observations, assuming all other cosmological parameters known, at their simulated values. We assumed that follow-up observations provided redshifts for all the sources. This is the best constraint achievable, according to our observation model.
from SZ-cluster observations, assuming all other cosmological parameters known, at their simulated values. We assumed that follow-up observations provided redshifts for all the sources. This is the best constraint achievable, according to our observation model.
![\begin{figure}
\par\includegraphics[width=5.65cm,clip]{Figures/4680f11.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img81.gif) |
Figure 11:
Expected constraints on |
| Open with DEXTER | |
As shown at paragraph 2.5 the simulated source count variance can be significantly larger than a Poisson's distribution of same expectation that we would assume from field to field variance. In this paragraph we quantify the degradation on confidence level due to such an enlarged count variance. Figure 12 shows the results.
Therefore calibration of Flux measurement must be a priority in the design of Large SZ cluster surveys. Count variance might be due to observations (instruments), but also to cluster detection algorithms (Herranz et al. 2002; Pierpaoli et al. 2005; Pires et al. 2006; Melin 2004). Those should be evaluated, on their efficiency, on the purity of the recovered source catalogue, but definitely on the source count variance at the output of the chain. In the following, we use the poisson-like counting variance obtained with our detection chain assuming a perfect calibration.
![\begin{figure}
\par\includegraphics[width=6cm]{Figures/4680f12a.eps}\includegraphics[width=6cm]{Figures/4680f12b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img82.gif) |
Figure 12:
Degradations of constraint due to the cluster count variance. White marks give the cosmological models used to simulate the data.
Left: black lines are the
|
| Open with DEXTER | |
Galactic physics event heats the extragalactic cluster gas, and thus contribute to the SZ-cluster signal in addition to the gravitational potential and virialisation. Late cluster gas heating mechanisms are not well known yet. Their contribution to gas heating is commonly parametrised in the mass-temperature relation as a normalisation factor, T*. The left panel of Fig. 13 shows the CL contours placed on T* and ![]() marginalised on
marginalised on
![]() .
We observe that with the input of WMAP and CFHT-LS weak-shear forecast, the residual correlation between T* and
.
We observe that with the input of WMAP and CFHT-LS weak-shear forecast, the residual correlation between T* and ![]() is small. In addition on going X-Rays surveys from XMM satellite should provide a lot of information on cluster gas physics and allow precise determination of T*. Thus in the following we set T* to the value 1.9.
is small. In addition on going X-Rays surveys from XMM satellite should provide a lot of information on cluster gas physics and allow precise determination of T*. Thus in the following we set T* to the value 1.9.
![\begin{figure}
\par\includegraphics[width=6cm,clip]{Figures/4680fg13a.eps}\includegraphics[width=6cm,clip]{Figures/4680fg13b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img83.gif) |
Figure 13:
Left: confidence level map, on |
| Open with DEXTER | |
Large clusters involve hundred of galaxies. Their gravitational potential is stronger than in smaller clusters and non-gravitational physics is less important than in low mass systems.
As a result, their mass to temperature scaling law is expected to show a smaller dispersion. Thus one can foresee that heavy clusters will be statistically better modelled, and that constraints based on massive cluster observations will be reliable.
It is thus instructive to study the cosmological constraints which can be derived from a sample restricted to high-mass clusters. The right panel of Fig. 13 shows the confidence level map computed from a catalogue, when we select clusters of flux larger than 7.4 ![]()
![]() .
The CL contour are significantly enlarged compared to the reference contour drawn in black, because of the much smaller statistic. This is a strong motivation for theorists to understand and build a model of low-mass clusters.
.
The CL contour are significantly enlarged compared to the reference contour drawn in black, because of the much smaller statistic. This is a strong motivation for theorists to understand and build a model of low-mass clusters.
![\begin{figure}
\par\includegraphics[width=6cm,clip]{Figures/4680fg14a.eps}\includegraphics[width=6cm,clip]{Figures/4680fg14b.eps}\end{figure}](/articles/aa/full/2007/13/aa4680-05/img85.gif) |
Figure 14: Left: impact on cosmological constraints, due to an incomplete redshift follow-up of cluster candidates. Black line is the 95% CL contour assuming a 10% coverage follow-up. Dashed line assumes 20% coverage follow-up and dotted line 50% coverage. Colored contours are a copy of Fig. 11. Right: lines show the systematic shift in the CL contour induced by neglecting contaminants in the recovered source catalogue. This plot was generated assuming that 50% of the sources have been observed in follow-up for redshift. Colors stand for contours computed with the same dataset, but taking into account contaminations. White cross is the best model taking into account contaminants, and black cross is the biased best model. The diamond is still the simulated cosmological model. |
| Open with DEXTER | |
Large-array bolometer surveys will provide large cluster catalogues, including flux and positions and shapes for resolved clusters, but have to rely on follow-up experiments for redshift measurements. The left panel of Fig. 14 shows the impact of partial redshift coverage, assuming 10%, 20% or 50% random coverage of clusters candidates. Remaining catalogue contaminations have been properly taken into account. We note that no significant bias on the CL contours is seen, but that the statistics are degraded. This shows that follow-up observations will be very important for the accuracy of the physics output of large SZ-Cluster surveys.
Assuming now that the redshift followup of the observations will be incomplete (as is very likely to be the case in practice), we quantify now the effect of neglecting contamination in the recovered catalogue. We assume in the paragraph that 50% of the sources have a redshift. Technically, this means using in the first factor of the likelihood the pdf count of true detected cluster and in the third factor, the integral over
![]() of
of
![]() .
The right panel of Fig. 14 shows the results. We see that since we assumed that false detections are clusters, the reconstructed parameters are biased toward large
.
The right panel of Fig. 14 shows the results. We see that since we assumed that false detections are clusters, the reconstructed parameters are biased toward large ![]() ,
since contamination produce a spurious enhancement of the cluster distribution at low surface brightnesses. This effect is rather small, since we chose to use a 95% pure SZ Catalog. The reduced size of the CL contour is a secondary effect of the low
,
since contamination produce a spurious enhancement of the cluster distribution at low surface brightnesses. This effect is rather small, since we chose to use a 95% pure SZ Catalog. The reduced size of the CL contour is a secondary effect of the low
![]() fitted value.
fitted value.
In this paper, we have explored, in details, the potential and limitations of upcoming wide-field SZ surveys. We used a full simulation pipeline, going from the cosmological models to recovered cluster catalogues and constraints on cosmological parameters. We showed that the selection function and purity of the recovered catalogues are more complex than is usually assumed. We quantified the foreseen selection function, photometry, contamination and field to field count variance of the upcoming Olimpo project. We presented methods to statistically model the observations, select parametrised models compatible with data, and then constraint models parameters.
We showed that field to field count variance is likely to be enlarged if great care is not taken in the calibration of cluster flux extraction. We showed that any enlargement in cluster count variance must be taken into account in the cosmological parameter estimation, and makes the constraints worse. We showed that, using SZ Cluster data, combined with WMAP and expected CFHTLS weak-shear forecast data, little correlation is seen between the mass-temperature normalisation factor T* and
![]() .
Complementary X-Rays observations will be necessary to put tighter constraints on T*, but on the other hand, we only need moderate precision on T*, to achieve good knowledge on
.
Complementary X-Rays observations will be necessary to put tighter constraints on T*, but on the other hand, we only need moderate precision on T*, to achieve good knowledge on
![]() .
We finally exposed the impact on cosmological parameters of systematics in observations or interpretation of our data.
.
We finally exposed the impact on cosmological parameters of systematics in observations or interpretation of our data.
This paper does not use the 2-point correlations of SZ Cluster to constraint cosmology (Mei & Bartlett 2003), nor cluster angular size. This incorporation of these informations in our simulation pipeline and the computation of their impacts on cosmological parameter constraints is left to future work.
Acknowledgements
We hereby acknowledge many scientific and algorithmic discussions with J. Rich, J.-P. Pansart, C. Magneville, R. Teyssier (CEA Saclay/DAPNIA) and J.-B. Melin and J. G. Bartlett (Univ. Paris 7, APC). Special thanks to P. Lutz and J. Bouchez (CEA Saclay/DAPNIA) for their help with statistic methods. We would like to acknowledge as well, the Dapnia-SAp and the Astronomy group of the University of Concepción, Chile, for computing facilities that helped to achieve this study.
The following Table 3 samples values of the selection function as a function of mass and Compton flux.
Table 3: Selection function versus redshift. Value entered correspond to 90% efficiency.