A&A 462, 397-410 (2007)
DOI: 10.1051/0004-6361:20065501
Superclusters of galaxies from the 2dF redshift survey
II. Comparison with simulations
J. Einasto1 - M. Einasto1 -
E. Saar1 - E. Tago1 - L. J. Liivamägi1 -
M. Jõeveer1 - I. Suhhonenko1 -
G. Hütsi1 - J. Jaaniste2 - P. Heinämäki3 - V. Müller4 - A. Knebe4 - D. Tucker5
1 - Tartu Observatory, 61602 Tõravere, Estonia
2 -
Estonian University of Life Sciences
3 -
Tuorla Observatory, Väisäläntie 20, Piikkiö, Finland
4 -
Astrophysical Institute Potsdam, An der Sternwarte 16,
14482 Potsdam, Germany
5 -
Fermi National Accelerator Laboratory, MS 127, PO Box 500, Batavia,
IL 60510, USA
Received 26 April 2006 / Accepted 28 July 2006
Abstract
Aims. We investigate properties of superclusters of galaxies found in of the 2dF Galaxy Redshift Survey, and compare them with properties of superclusters from the Millennium Simulation.
Methods. We study the dependence of various characteristics of superclusters on their distance from the observer, on their total luminosity, and on their multiplicity. The multiplicity is defined by the number of Density Field (DF) clusters in superclusters. Using the multiplicity we divide superclusters into four richness classes: poor, medium, rich and extremely rich.
Results. We show that superclusters are asymmetrical and have a multi-branching filamentary structure, with the degree of asymmetry and filamentarity being higher for the more luminous and richer superclusters. The comparison of real superclusters with Millennium superclusters shows that most properties of simulated superclusters agree very well with real data, the main differences being in the luminosity and multiplicity distributions.
Key words: cosmology: large-scale structure of Universe - galaxies: clusters: general
The largest non-percolating galaxy systems are superclusters of galaxies that
contain clusters and groups of galaxies along with their surrounding galaxy
filaments. Superclusters evolve slowly and contain information about the very
early universe; thus their properties can be used as cosmological probes to
discriminate between different cosmological models. Early studies of
superclusters were based on galaxies and groups (see the reviews by Oort
1983; and Bahcall 1988). All-sky catalogues of
superclusters were complied by Zucca et al. (1993), Kalinkov & Kuneva
(1995), Einasto et al. (1994, 1997, 2001,
hereafter E94, E97 and E01, respectively) using galaxy cluster catalogues by
Abell (1958) and Abell et al. (1989).
In fact, superclusters consist of galaxy systems of different richness classes
- from single galaxies, galaxy groups and filaments to rich clusters of
galaxies. This was realised long ago (Jõeveer et al.
1978; Gregory & Thompson 1978) and has been confirmed by
recent studies of superclusters using deep new galaxy surveys, such as the Las
Campanas Galaxy Redshift Survey, the 2 degree Field Galaxy Redshift Survey
(2dFGRS, Colless et al. 2001, 2003), and the Sloan Digital Sky
Survey (SDSS) (Doroshkevich et al. 2001; Einasto et al. 2003a,b;
Erdogdu et al. 2004; Porter & Raychaudhury 2005;
and Einasto et al. 2007, hereafter Paper I). These new surveys have
shown that morphological properties of galaxies depend on the large-scale
cosmological environment: Einasto et al. (2003c,a, 2005, hereafter E05b); Balogh et al. (2004); Croton et al.
(2005); Lahav (2004, 2005); Ragone et al.
(2004). The densest global environment is provided in
superclusters of galaxies.
The goal of this paper is to investigate properties of real superclusters and
to compare them with simulated superclusters found in numerical simulations of
the evolution of the structure of the Universe. We shall use the supercluster
catalogue of Paper I and catalogues of simulated superclusters based on the
Millennium Simulation of Springel et al. (2005), and the
Millennium Run mock galaxy catalogue by Croton et al. (2006) (see
also Gao et al. 2005). Traditionally in supercluster studies the
multiplicity and the shape is discussed and used as a cosmological probe
(Basilakos et al. 2001; Kolokotronis et al. 2002; Basilakos
2003; Wray et al. 2006). Additional parameters of galaxy
systems in high- and low-density environments (supercluster and field
populations) were investigated by Doroshkevich et al. (2001) using
the minimal spanning tree and inertia tensor methods. In this paper we
also discuss a number of supercluster properties, such as the luminosity
function; the maximal, minimal and effective diameters and their ratios; the
geometric and dynamical centres and their differences; and the main clusters
and galaxies. We define the multiplicity of superclusters by the number of
Density Field (DF) clusters, and divide superclusters according to their
multiplicity into four richness classes: poor, medium, rich, and extremely
rich. Properties of galaxies in superclusters, including properties of main
galaxies and main clusters, will be investigated in a separate paper by
Einasto et al. (2006b, Paper III).
Section 2 describes the data used for
the analysis. In Sect. 3 we discuss multiplicities of
superclusters and define supercluster richness classes. In Sect. 4
we study properties of superclusters and compare these
properties with those of simulated superclusters. We consider
the dependence of supercluster properties on the distance from the
observer, on the total luminosity, and on the richness. In Sect. 5 we
discuss our results and compare our lists of superclusters with
superclusters found in earlier studies. In the last section we give
our conclusions. The catalogue of superclusters is available
electronically at the web-site
http://www.aai.ee/~maret/2dfscl.html
![\begin{figure}
\par\mbox{\resizebox{8.5cm}{!}{\includegraphics[clip]{5501_fig1a....
...2mm}
\resizebox{8.5cm}{!}{\includegraphics[clip]{5501_fig1b.eps}} }
\end{figure}](/articles/aa/full/2007/05/aa5501-06/Timg2.gif) |
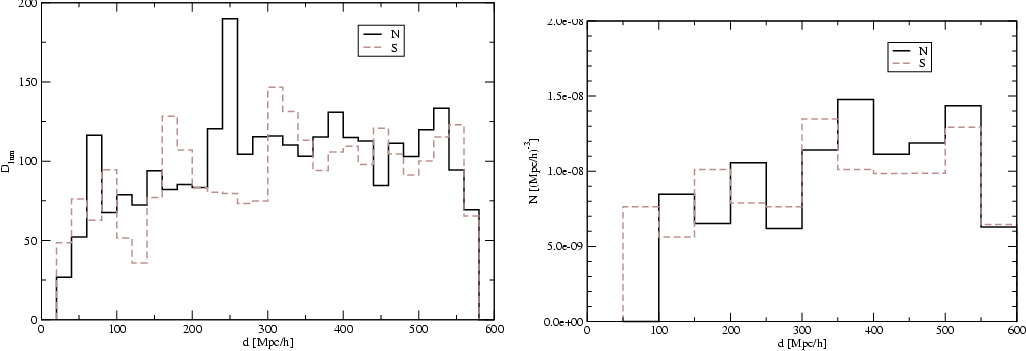
Figure 1:
The multiplicity of superclusters at various distances from
the observer. Here we have used groups of galaxies in the left panel
and DF-clusters in the right panel as supercluster multiplicity
indicators. Solid lines show median values of multiplicities at various
distance. In the case of DF-clusters almost half the superclusters
have a multiplicity 1, and a few have multiplicity 0 (i.e. the peak density
of the central cluster lies below the threshold used to define DF-clusters),
thus the median value is very close to 1. |
| Open with DEXTER |
 |
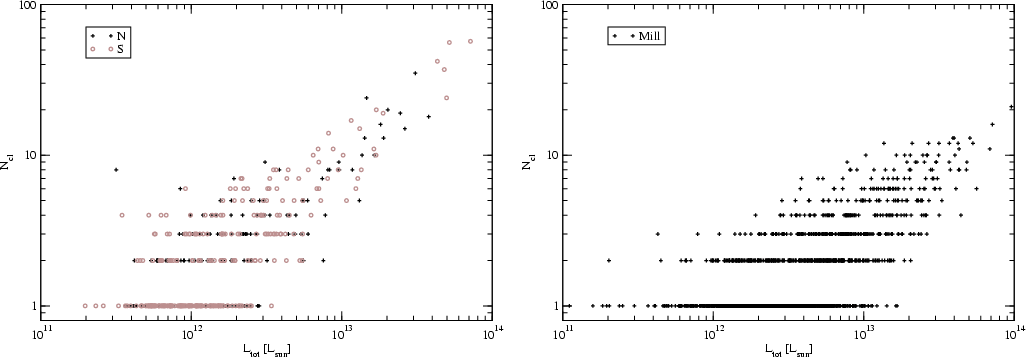
Figure 2:
The number of DF-clusters as functions of the total
luminosity of the supercluster. Left: 2dF superclusters,
right: Millennium Run superclusters. |
| Open with DEXTER |
We have used the supercluster catalogues published by Einasto et al. (Paper I). The main data used in this paper can be found in the
electronic supplement of this paper; some unpublished data on real and model
supercluster samples are also used. To compile supercluster catalogues we
used the 2dFGRS final release (Colless et al. 2001, 2003), and
the group catalogue based on this survey by Tago et al. (2006,
hereafter T06). We calculated weights, which are inversely proportional to the
width of the observational window in absolute magnitudes at the distance of
the galaxy, and estimated total luminosities of galaxies and galaxy systems.
Using an Epanechnikov kernel of radius 8 h-1Mpc we calculated the smoothed
luminosity density field. Superclusters were defined as contiguous regions of
the density field above a certain threshold density, 4.6 in units of the mean
luminosity density.
The data used in the present analysis are the following.
The geometric data are: the supercluster distance d, and the minimal,
maximal, and effective diameters of the supercluster,  ,
,
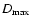 ,
,
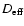 .
The minimal diameter is the shortest size of the
supercluster along rectangular coordinates x, y, z, calculated in
rectangular equatorial coordinates (for details see Paper I), the maximal
diameter is the diagonal of the box containing the supercluster along
rectangular coordinates, and the effective diameter is the diameter of
the sphere whose volume equals that of the supercluster. We further use the
ratio of the mean to effective diameter
.
The minimal diameter is the shortest size of the
supercluster along rectangular coordinates x, y, z, calculated in
rectangular equatorial coordinates (for details see Paper I), the maximal
diameter is the diagonal of the box containing the supercluster along
rectangular coordinates, and the effective diameter is the diameter of
the sphere whose volume equals that of the supercluster. We further use the
ratio of the mean to effective diameter
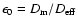 ,
where
,
where
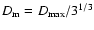 is the mean diameter. This parameter
characterizes the compactness of the system. A further geometrical
parameter is the center offset, which is the difference
between the geometric center (as defined by the x, y, z-coordinates
of the density field above the threshold density), and the dynamic
centre - the center of the main (most luminous) cluster
of the supercluster. This parameter characterises the asymmetry of the
supercluster.
is the mean diameter. This parameter
characterizes the compactness of the system. A further geometrical
parameter is the center offset, which is the difference
between the geometric center (as defined by the x, y, z-coordinates
of the density field above the threshold density), and the dynamic
centre - the center of the main (most luminous) cluster
of the supercluster. This parameter characterises the asymmetry of the
supercluster.
The physical data are: the peak and mean density of the supercluster (in units
of the mean luminosity density); the number of galaxies and groups (from the
catalogue T06); the multiplicity of the supercluster, defined as the number of
DF-clusters in it (for definition of DF-clusters see below Sect. 3); and the
total luminosity of the supercluster,
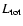 ,
expressed in Solar units in
the
,
expressed in Solar units in
the
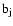 filter passband. The total luminosity of a supercluster is
calculated by summing the estimated total luminosities of all its member
galaxies and groups.
filter passband. The total luminosity of a supercluster is
calculated by summing the estimated total luminosities of all its member
galaxies and groups.
We use corresponding characteristics for simulated superclusters using the
Millennium Run mock galaxy catalogue by Croton et al. (2006).
Table 1:
Data on 2dFGRS and Millennium Run superclusters of
various richness.
Peaks of the luminosity density have been calculated using luminosities of
groups corrected for the luminosity outside of the
apperent magnitude limits.
These data are used to
find DF-clusters - peaks of the density field smoothed with an Epanechnikov
kernel of radius 8 h-1Mpc. The use of the Epanechnikov kernel is preferable
since it has no low-density wings as the Gaussian kernel does. The number
density of DF-clusters is 57 and 58 per million (h-1Mpc)3, respectively, in
the 2dFGRS Northern and Southern regions, using a threshold density of 5.0 in
units of the mean density. For the Millennium Run density field,
DF-clusters have been found for a density threshold of 5.5; for this limit the
number density of DF-clusters is 25 per million (h-1Mpc)3. For comparison we
note that the number density of Abell clusters is 26 per million (h-1Mpc)3(E97). If a higher threshold density is used, then
the number density of DF-clusters in 2dFGRS samples becomes very close to the
Millennium Run and Abell cluster density estimates. Thus,
DF-clusters can be considered as an equivalent to Abell clusters. We searched
the neighbourhood of DF-clusters for galaxies and groups of galaxies. This
search shows that all DF-clusters lie in a high-density environment: in a box
of radius 3 h-1Mpc around a DF-cluster there are, depending on the distance
from the observer, up to 60 2dFGRS groups and field galaxies outside groups.
The multiplicity of Abell superclusters was derived by Einasto et al. (E97).
The distribution of multiplicities is close to the distribution found in the
present paper. The multiplicity of simulated superclusters was studied by
Wray et al. (2006) using rich DM-halos. The multiplicity function was derived
for a number of linking lengths. The linking length L = 5 h-1Mpc corresponds
approximately to our accepted threshold density. The integrated multiplicity
function is presented in their Fig. 3. The case L=5 h-1Mpc is similar to the
multiplicity function of our DF-clusters. We shall discuss the multiplicity
function and its cosmological consequences in separate papers by Saar et al.
(2006) and Einasto et al. (2006a).
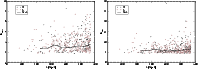 |
Figure 3:
The mean ( left panel) and the maximal density ( right
panel) of superclusters at various distances from the observer. Solid lines
show median values of densities at various distances.
|
| Open with DEXTER |
A natural division of superclusters into poor, medium and rich systems would
be according to the total luminosity. However, it is not always easy to
determine the total luminosity of superclusters. Another possibility to
characterize the richness of superclusters as the number of galaxies or
groups/clusters. As we have seen above, the numbers of galaxies and groups in
superclusters are influenced by selection effects, thus they are less suited
for this purpose. For this reason we have used the number of high-density
peaks, in our case DF-clusters. The multiplicity of superclusters is easily
determined from observation, also for superclusters found using Abell clusters
or DM-halos in simulations. Figure 2 shows that the number of
DF-clusters is proportional to the supercluster total luminosity: the
relationship is linear in the log-log diagram. The spread of luminosities of
superclusters of given multiplicity is rather large, especially for poor
superclusters. This spread is due to variations in the number of galaxies and
groups of galaxies in superclusters of a given number of DF-clusters.
We shall use the supercluster multiplicity to divide superclusters
into four richness classes. We call superclusters that have less
than 3 DF-clusters poor, superclusters with 3 to 9 DF-clusters
medium rich, superclusters with 10 to 19 DF-clusters rich, and with
20 or more DF-clusters extremely rich superclusters. As shown
above, DF-clusters are of the Abell class. As a prototype of a poor
supercluster we can use the Virgo and Coma superclusters, containing
one and two Abell class clusters, respectively. A characteristic
supercluster of medium richness class is the Perseus-Pisces
Supercluster; its visible part contains 3 Abell clusters, but part of
the supercluster is hidden in the zone of avoidance. Examples of
nearby rich superclusters are
the Leo-Sextans and
Horologium-Reticulum Superclusters, and also the supercluster SCL126
(see Fig. 14 below). The class of extremely rich
superclusters includes the Shapley Supercluster.
We have used these richness classes and determined for all richness classes
the median values of various parameters, determined in Paper I for 2dFGRS
superclusters. To get an idea of the spread in these parameters we also
calculated
the 1st and 4th quantiles of the distribution. Data are given in
Table 1, both for the 2dFGRS and Millennium Run (sample
Mill.F8) superclusters. Here N is the number of superclusters of the
respective richness class, denoted by P, M, R and E for poor, medium, rich,
and extremely rich superclusters, respectively (the numbers are given only
once, they are identical for all quantities given in the table). The
quantities are: the luminosity
(in Solar units); the absolute
magnitude of the main galaxy 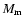 (in the
(in the 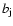 filter passband for
2dFGRS, and in the g filter passband for the Millennium Run); the mean
and maximal densities,
filter passband for
2dFGRS, and in the g filter passband for the Millennium Run); the mean
and maximal densities,
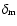 and
and
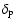 ,
respectively (in units of
the mean density); the maximal diameter
(diagonal of the rectangular
box around the supercluster) and the effective diameter
(the
diameter of the sphere equal in volume to that of the supercluster, both in
h-1Mpc); the center offset parameter
,
respectively (in units of
the mean density); the maximal diameter
(diagonal of the rectangular
box around the supercluster) and the effective diameter
(the
diameter of the sphere equal in volume to that of the supercluster, both in
h-1Mpc); the center offset parameter 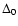 (the distance between the
geometric and dynamic center, also in h-1Mpc); and the ratio of the mean to the
effective diameter
(the distance between the
geometric and dynamic center, also in h-1Mpc); and the ratio of the mean to the
effective diameter
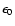 .
.
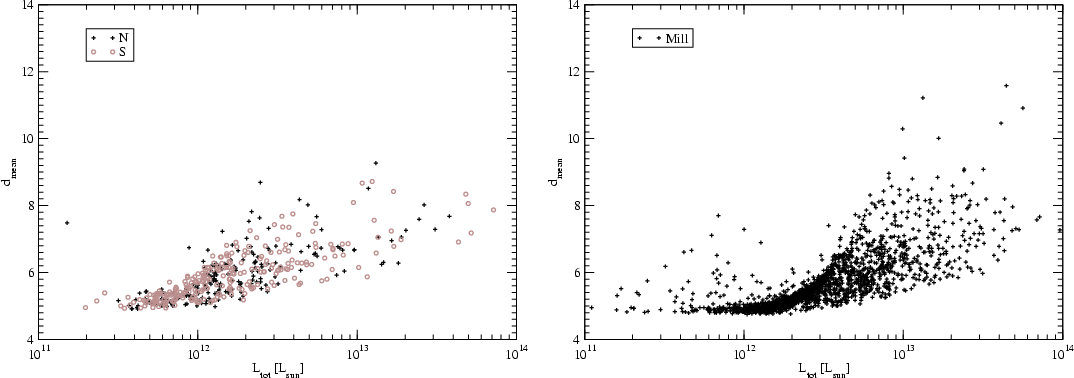
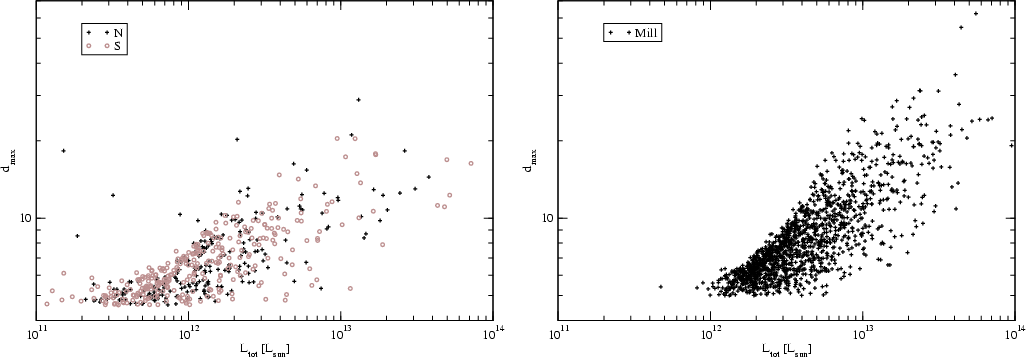
The number of DF-clusters in superclusters is on average the same in nearby
and distant superclusters (see Fig. 1). There is a strong
dependence of the number of DF-clusters on the total luminosity of
superclusters. Table 1 shows that about 2/3 of the
superclusters are poor, both in the real and simulated samples - i.e. they
belong to the same supercluster richness class as the Local and Coma
Superclusters. With increasing total luminosity the number of DF-clusters -
or the multiplicity of superclusters - increases.
However, there exists a remarkable difference between the distribution of
supercluster richness classes for the real and simulated samples. For the
2dFGRS supercluster sample, 5% of the superclusters are of richness class R
and E, and the richest superclusters have up to about 60 DF-clusters. In
contrast, only 1% of the Millennium Run supercluster sample has this
richness class, and the richest simulated superclusters have only 20
DF-clusters. This difference in the richness of real and simulated
superclusters is one of the major results of our study. A further discussion
of this problem is given by Saar et al. (2006) and Einasto et
al. (2006a).
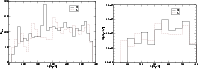 |
Figure 4:
Left panel: the mean luminosity density in the Northern and Southern
regions of the 2dF as a function of distance (in arbitrary units). Right
panel: the mean number density of 2dF superclusters as functions of
distance. |
| Open with DEXTER |
The major problem in using flux-limited galaxy samples is the magnitude
selection effect. Faint galaxies and groups are not seen at large distances,
thus it is expected that the number of visible galaxies and groups in
superclusters decreases with distance. This is what is actually observed:
there exists a lower limit of the number of galaxies and groups in
superclusters, and this limit decreases with distance due to the use of
flux-limited galaxy samples (Fig. 1, see also T06). This selection
effect distorts the number of galaxies and groups as supercluster richness
indicators. For this reason we have used as a richness indicator the number of
local high-density peaks - DF-clusters (see right panel of Fig. 1).
DF-clusters have been found using luminosities of galaxies and groups
corrected for the effect of luminosity bias. (See Paper I for details of the
reconstruction of estimated true total luminosities of DF-clusters and
superclusters.) The right panel of Fig. 1 shows that the number of
DF-clusters in superclusters - the supercluster multiplicity - is on
average the same in nearby and distant superclusters. Due to the volume-effect
there are no very rich superclusters at small distance D < 300 h-1Mpc.
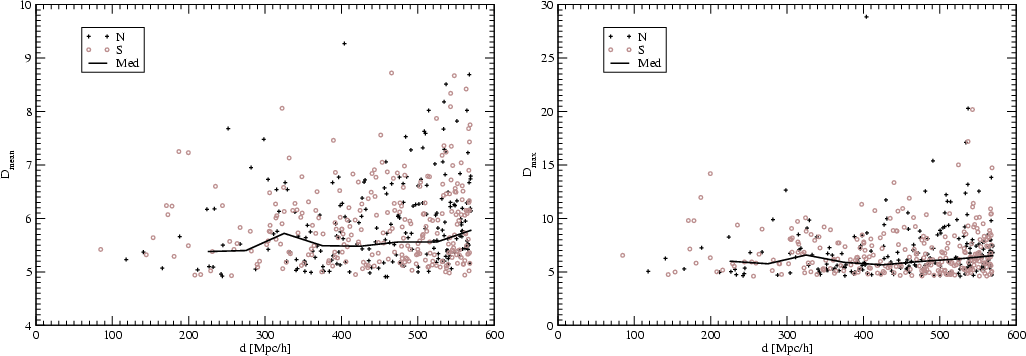
In Fig. 3 we show the mean and maximal luminosity density of
superclusters at various distances from the observer, for the Northern
and Southern regions. We see that the distributions are rather uniform
- both densities are distributed similarly irrespective of distance.
The comparison of the mean luminosity density of the whole 2dFGRS
sample (Fig. 4) shows that
there are several peaks due to very rich superclusters, but in general
the luminosity density is approximately constant. The mean number
density of superclusters is is also approximately the same at various
distances from the observer, see Fig. 4 right panel.
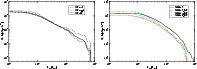 |
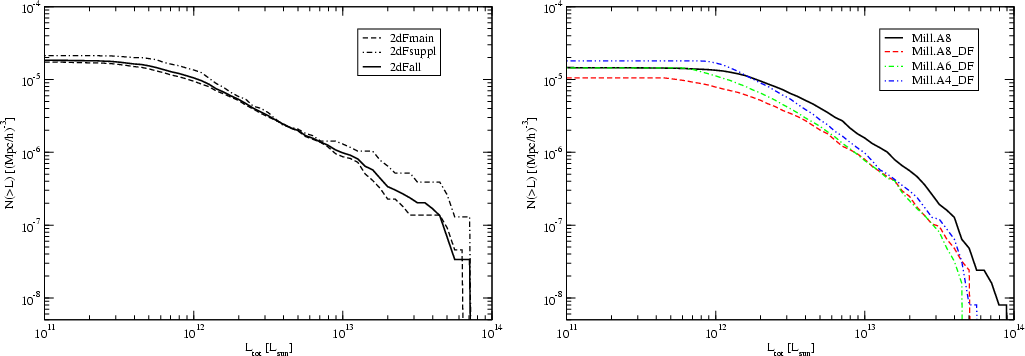
Figure 5:
The luminosity functions of superclusters. Left: 2dF
superclusters, right: Millennium Run superclusters. The supercluster
luminosity function for the 2dFGRS was calculated for the main,
supplementary, and the total supercluster samples (North and South added),
plotted with dashed, dot-dashed and solid curve, respectively. For
simulated superclusters the solid bold curve is the luminosity function
calculated by adding luminosities of supercluster member galaxies; dashed,
dot-dashed and dot-dot-dashed curves correspond to Millennium samples
Mill.A8, Mill.A6 and Mill.A4, in these cases the luminosity of superclusters
was found from the density field. |
| Open with DEXTER |
One of the major goals of the present study was the compilation of a
representative sample of superclusters over a broad range of
luminosities. This gives us the possibility to derive the luminosity
function of superclusters. The results of our calculations are shown in
Fig. 5. Our dataset is large enough to measure the
luminosity function spanning almost 3 orders in luminosity and spatial
density.
We have calculated the supercluster luminosity function separately for
the main supercluster sample, which contains superclusters with
distances up to 520 h-1Mpc, and for the supplementary sample, containing
more distant superclusters. In both cases Northern and Southern
subsamples were stacked. The main samples have 379 superclusters, the
supplementary ones 164. Our analysis has shown that the largest and
most luminous superclusters have extensions beyond the boundaries of
2dFGRS. Thus the total luminosities of most luminous superclusters
(SCL9 and SCL126 from the list by Einasto et al., E97) are
probably underestimated.
Figure 5 shows that there are no large differences between
luminosity functions found for the main and supplementary samples, only the
luminosity function of the supplementary sample is slightly higher. This is
due to two factors: the expected total luminosities of groups have random
errors due to large weight factors used in the restoration of the expected
total luminosities, and there are errors in the density field due to
inaccuracies in the expected total luminosities. Due to the second error some
superclusters fall below the threshold density and are missed, and some poor
superclusters are added to our list which are actually fainter than our
threshold density limit. On average these errors cancel each other out and
increase only slightly the supercluster luminosities, because the supplementary
list contains, in comparison to the main list, richer superclusters.
In Paper I we have compared luminosities of simulated superclusters
calculated from the true density field and from the density field
of simulated flux-limited galaxy samples. This comparison has shown
that luminosities of superclusters found from a flux limited sample are
systematically fainter than "true'' luminosities found from all data.
A detailed analysis is needed to investigate this and other biasing
factors (including a detailed study of the structure of individual
rich superclusters) to have a more accurate estimate of the
supercluster luminosity function.
For comparison we show in the right panel of Fig. 5 the
luminosity function of simulated superclusters extracted from the Millennium
Run. The luminosity function was constructed in two ways. The solid
line corresponds to the sample Mill.A8 where luminosities of superclusters
were found by adding luminosities of galaxies in superclusters. The
supercluster sample includes systems with a minimal volume limit of 100 Mpc3h-3. Dashed, dot-dashed and dot-dot-dashed curves were calculated
for models Mill.A8, Mill.A6 and Mill.A4, respectively, by integrating the
luminosity density field inside the contour of the supercluster, multiplied by
the mean luminosity per cell. Supercluster samples Mill.A8, Mill.A6, and
Mill.A4 were found using an Epanechnikov kernel with radius 8, 6, and 4 h-1Mpc,
respectively, see Paper I for details. In these models the limiting volume
was taken to be 200 Mpc3h-3. We see that there exists a shift in
luminosities between the two sets of data. This shift can be explained by the
fact that, in the luminosity density field, part of the luminosity of galaxies
is smoothed away beyond the threshold contour (see Fig. 14). For
this reason total luminosities obtained from the density field are
underestimates. To avoid this systematic bias we have used in the calculation
of total luminosities of superclusters estimates based on luminosities of
supercluster member galaxies and galaxy groups/clusters.
The comparison of luminosity functions of the samples Mill.A8, Mill.A6, and
Mill.A4 shows the effect of using different smoothing lengths in
the calculation of the density field. The smaller the smoothing
length, the more often outlying parts of superclusters have a tendency to
form independent poor superclusters. This increases the number of poor
superclusters and changes the resulting luminosity function. The
figure shows that these changes are rather modest; in the range of
high luminosities the frequency of superclusters of various
luminosities is almost constant. If we use identical smoothing lengths and
selection parameters (threshold density and lower volume limit) for models
and real data, we get comparable supercluster samples.
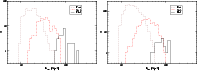 |
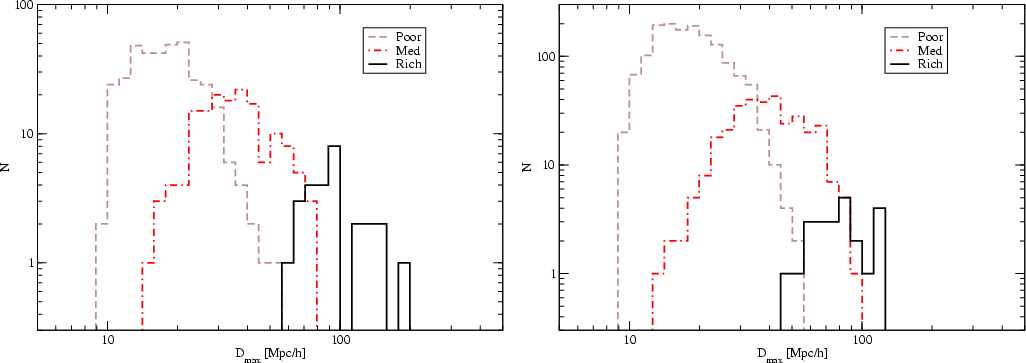
Figure 6:
The distribution of maximal diameters of poor, medium, and
rich superclusters, defined by supercluster multiplicity. The left
panel shows data for 2dFGRS superclusters (Northern and Southern
regions together), the right panel Mill.A8 superclusters. |
| Open with DEXTER |
The mean number-density of superclusters as defined in the present analysis is
well determined: both the Northern and Southern regions of 2dF yield about 17
superclusters per million Mpc3 h-3. A sample with similar selection
parameters for the Millennium Run contains 14 superclusters per million
Mpc3 h-3 - i.e. the number densities of real and simulated
superclusters are very similar. The number density of rich and extremely rich
superclusters is much lower - 0.6 and 0.3 per million Mpc3 h-3,
respectively, in the real sample. If this density is characteristic of the
whole Universe, then we have a chance to observe one extremely rich
supercluster in a volume of 3 million Mpc3h-3. We note that nearby
examples of rich and extremely rich superclusters SCL126 and SCL9 have
a higher total luminosity than found in the 2dFGRS, since both are
cut by the observational limits of the survey in declination, as seen from the
density field. Larger deep galaxy redshift surveys are needed to find more
accurate values of luminosities of these very rich superclusters.
The comparison of luminosity functions of real and simulated
superclusters shows several differences. First, as noted above, the
number density of rich and extremely rich superclusters in the
simulated sample is much lower, only 0.15 per million Mpc
3 h-3.
The other difference between total luminosities of real and simulated
superclusters is in their median luminosity values. Table 1 shows that median luminosities of simulated
superclusters of all richness classes are higher than median values
of luminosities of 2dF superclusters by a factor of 2-3. A similar
shift is seen in the luminosity functions of the 2dF and Millennium
Run superclusters. The reason for this discrepancy is not clear.
The third difference between luminosity functions of real and
simulated superclusters is in the shape of the functions: the luminosity
function of 2dFGRS superclusters has an almost constant slope in the
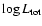 vs.
vs.
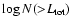 diagram, whereas the luminosity
function of simulated superclusters has a continuous change of the
slope.
diagram, whereas the luminosity
function of simulated superclusters has a continuous change of the
slope.
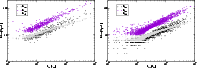 |
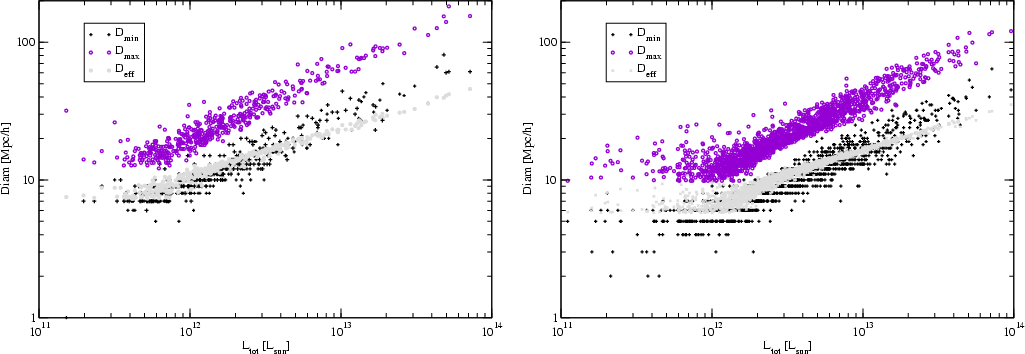
Figure 7:
The minimal, maximal and effective diameter of superclusters
of various total luminosity. The left panel shows data for 2dF
superclusters, the right panel for Millennium Run
superclusters. |
| Open with DEXTER |
The general shape of the integrated luminosity function, found here
for the 2dFGRS and Millennium Run supercluster samples, is
rather close to the theoretical luminosity function calculated by
Oguri et al. (2004) using the Press-Schechter
approximation. Both real and simulated supercluster samples span an
interval of total luminosities exceeding two orders of magnitude,
similar to the range of luminosities discussed by Oguri et al. They
compared the model with the sample of superclusters of SDSS by E03a, which was
compiled on the basis of the 2-dimensional density field. This sample covered
only one decade in total luminosity. The present paper gives improved
possibilities for comparison. Also, the number of DF-clusters
found here is close to the number of clusters in
simulations by Oguri et al.
Next we study the geometric properties of DF superclusters. As an argument we
use the total luminosity of superclusters which was found by summing all
estimated total luminosities of member galaxies and groups/clusters in the
supercluster. As geometric quantities we consider the minimal diameter
(along one of the coordinate axes, whatever is the smallest), the maximal
diameter of the supercluster defined as the length of the diagonal of the
rectangular box surrounding the supercluster along coordinate axes, and the
effective diameter - the diameter of the sphere equal to the volume of the
supercluster (remember that the volume is defined as the number of cells which
have a density equal or greater than the threshold density, where the cell
size is 1 (h-1Mpc)3).
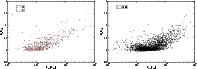 |
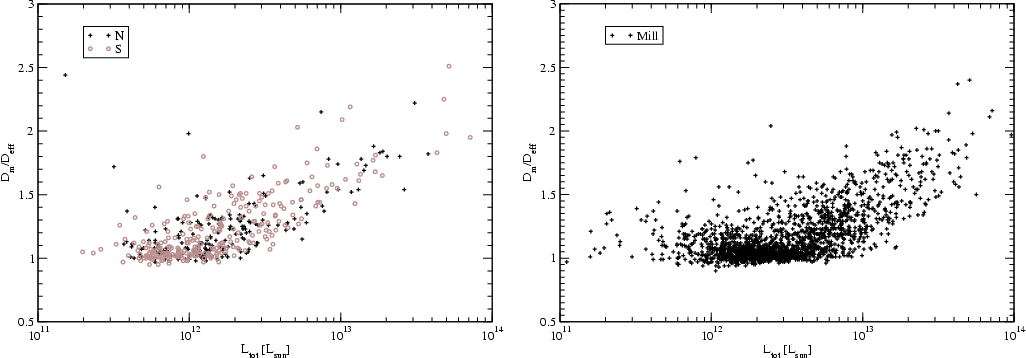
Figure 8:
The ratio of the mean diameter to the effective diameter in
superclusters of various total luminosity. The left panel shows
data for 2dF superclusters, the right panel for Millennium Run
superclusters. |
| Open with DEXTER |
The distribution of the maximal diameters of poor, medium, and rich
superclusters is shown in Fig. 6 for the 2dFGRS and Millennium
Run superclusters, median values and quantiles for superclusters of
different richness class are given in Table 1. As expected,
the maximal diameters depend strongly on the supercluster richness, both in
the real data and in the simulations. Median values of maximal (and minimal)
diameters of superclusters of various richness are in good agreement with
semiaxis lengths for Abell superclusters (Jaaniste et al. 1998) and
LCRS superclusters (Doroshkevich et al. 2001) of similar richness. An
even closer correlation exists between the effective diameter and the total
luminosity, shown in Fig. 7. The scatter in this relationship is
the smallest and the relationship in log-log representation is linear.
Figure 7 demonstrates one important aspect of our supercluster
catalogue: the total luminosities and sizes of superclusters have a rather
sharp lower limit. This limit is determined by two selection parameters: the
density threshold and the volume threshold. The density threshold excludes
systems of galaxies of low density from the sample, and the volume threshold
excludes small systems like single clusters. We have used values as low as
possible in our supercluster selection in an attempt to include all galaxy
systems which could be classified as superclusters. The analysis presented
above has shown that the choice of these selection parameters has been rather
successful: the sample of superclusters is fairly homogeneous. With our
choice of selection parameters we have excluded about 60% of galaxies. As
noted above, these galaxies are located in less dense galaxy systems, and the
main galaxies of these poor systems have a much broader distribution of
luminosities and their mean luminosities are also considerably lower (see Paper
III for more details). All this
confirms that we have selected a practically complete sample of galaxy systems
(within the observed region) which can be called superclusters.
The axis ratios of superclusters have a mean value around unity in all three
directions. More interesting is the dependence of the minimal, maximal and
effective diameters on the expected total luminosity of the supercluster,
shown in Fig. 7. This figure shows that all three diameters are
larger the higher the total luminosity of the supercluster and the richer
the supercluster (see Table 1). The dependence is, however,
different for various diameters: the maximal and minimal diameters grow faster
with luminosity, and the effective diameter grows slower. This
difference is due to a variation of the shape and compactness of superclusters
with differing luminosity.
The right panel of Fig. 7 shows the same set of axis ratios
for superclusters found in the Millennium Run Mill.F8. The
general trend is very close to the trend seen in the real
supercluster sample. This similarity shows that geometric properties
of simulated superclusters fit real data very well.
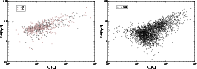 |
Figure 9:
The offset of the geometrical center from the
dynamical one as a function of the total estimated luminosity of
superclusters. The left panel shows 2dF superclusters, right panel
Millennium Run superclusters.
|
| Open with DEXTER |
The ratio of the mean diameter (the average of the extensions along
3-coordinate axes)
to the effective diameter is plotted in Fig. 8, in the left
panel for 2dFGRS superclusters, and in the right panel for Millennium
Run superclusters. This ratio depends on the compactness and
the filling factor of the system. The ratio is the larger the more
empty space (more accurately, regions of space of luminosity density
below the threshold density) is located in the vicinity of the system
defined by galaxy filaments belonging to the system. The figure shows
that in poor superclusters this ratio is close to unity (the minimum
by definition). In other words, poor superclusters are rather
compact systems. Here a good example is the Local Supercluster, which
contains only one rich cluster, the Virgo cluster, close to its center,
and is surrounded by numerous galaxy filaments. These filaments have
low luminosity density and fall outside the threshold density. Thus
systems like the Local supercluster are in our catalogue presented
only by their cores, which are compact and rather spherical, due to the
symmetrical smoothing of the density field. The actual shape of
compact superclusters can be investigated using the distribution
galaxies or groups (see the next subsection).
The scatter of values about unity for poor superclusters is partly
due to errors of the mean diameter. Supercluster sizes have been
found from density field cells with extreme values of coordinates
inside the threshold contour, they can only be determined with an accuracy
of 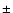 1 h-1Mpc. The mean diameters of smallest systems are of the
order of 10 h-1Mpc, thus a relative error of about 10% is expected for
the ratio of diameters of small systems. In almost all rich
superclusters the mean diameter is much higher than the effective
diameter, i.e. these systems have a lower compactness and filling
factor. This result agrees with that in E97, in which we showed that
rich superclusters have smaller fractal dimensions and are more
filament-like than poor superclusters.
1 h-1Mpc. The mean diameters of smallest systems are of the
order of 10 h-1Mpc, thus a relative error of about 10% is expected for
the ratio of diameters of small systems. In almost all rich
superclusters the mean diameter is much higher than the effective
diameter, i.e. these systems have a lower compactness and filling
factor. This result agrees with that in E97, in which we showed that
rich superclusters have smaller fractal dimensions and are more
filament-like than poor superclusters.
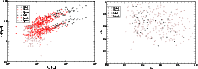 |
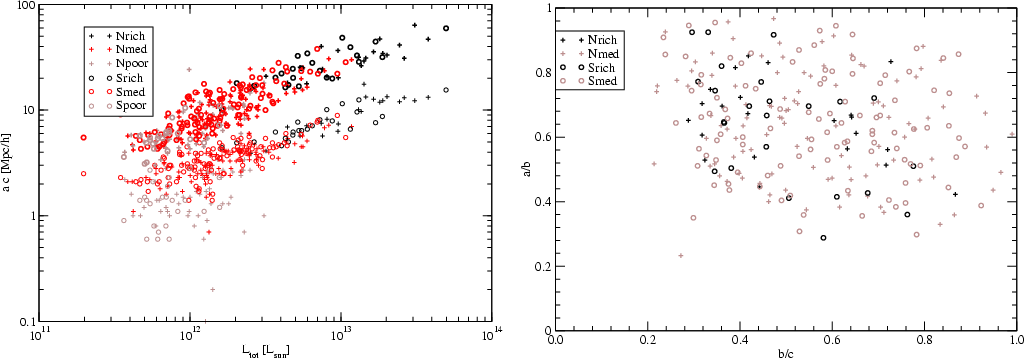
Figure 10:
Left panel: the semi-minor and semi-major axes of the mass
ellipsoid, a and c, are plotted for superclusters of different
total luminosities. Bold symbols are for the semi-major axis, and thin
ones for the semi-minor axis. Superclusters of various richness are
shown with different symbols. Right panel: axial ratios of
superclusters a/b vs. b/c for superclusters with at least 10
member groups. Filamentary superclusters populate the upper left
part of the figure, spherical superclusters the upper right part,
and pancake-like structures the lower right section. Triaxial
superclusters are located in the central region.
|
| Open with DEXTER |
Figure 9 shows the offset of the geometrical center from the
dynamical one, again for the 2dFGRS and Millennium Run
superclusters. The center offset parameter was defined as follows:
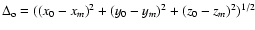 ;
here
x0, y0, z0 are coordinates of the geometric center of the
supercluster, found on the basis of extreme values of coordinates of
the rectangular box containing the system, and
xm, ym, zm are
coordinates of the dynamical center of the supercluster, defined by
the main cluster of the supercluster. In the ideal case it would be
better to determine the dynamical center using the gravitational
potential field. We have used instead the center of the most luminous
cluster near the highest density peak of the system. Poor and medium
superclusters have relatively small offsets of up to 10 h-1Mpc, but the
offset of very rich superclusters can reach values of up to 50 h-1Mpc. In
other words, poor superclusters are fairly symmetrical, but luminous
superclusters are asymmetric: the system of filaments has different
lengths in various directions. Actually filaments form a continuous
web, but in some parts the density of galaxies in filaments is lower
and falls below the threshold used to compile galaxy systems. The
figure also shows that there are no sharp boundaries between
superclusters of low and high luminosity - i.e., the transition is smooth.
;
here
x0, y0, z0 are coordinates of the geometric center of the
supercluster, found on the basis of extreme values of coordinates of
the rectangular box containing the system, and
xm, ym, zm are
coordinates of the dynamical center of the supercluster, defined by
the main cluster of the supercluster. In the ideal case it would be
better to determine the dynamical center using the gravitational
potential field. We have used instead the center of the most luminous
cluster near the highest density peak of the system. Poor and medium
superclusters have relatively small offsets of up to 10 h-1Mpc, but the
offset of very rich superclusters can reach values of up to 50 h-1Mpc. In
other words, poor superclusters are fairly symmetrical, but luminous
superclusters are asymmetric: the system of filaments has different
lengths in various directions. Actually filaments form a continuous
web, but in some parts the density of galaxies in filaments is lower
and falls below the threshold used to compile galaxy systems. The
figure also shows that there are no sharp boundaries between
superclusters of low and high luminosity - i.e., the transition is smooth.
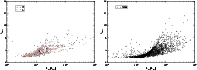 |
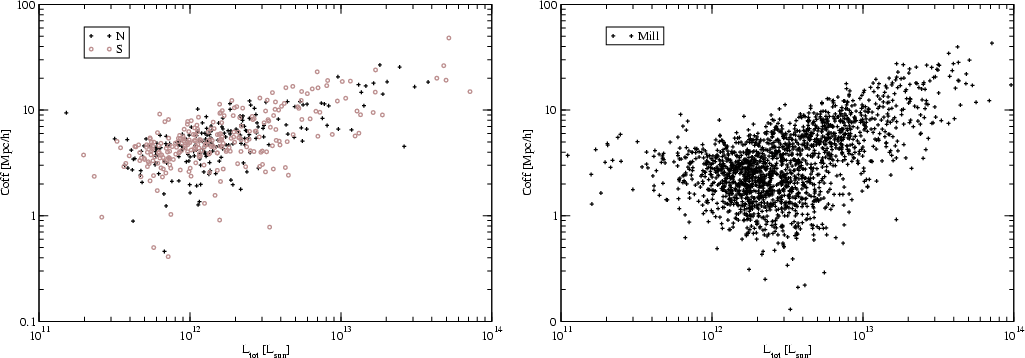
Figure 11:
Mean density of superclusters as functions of the total
luminosity of the supercluster. Left panel shows data for 2dF
samples, right panel for Millennium Run data, calculated with a
minimal volume 100 (h-1Mpc)3. |
| Open with DEXTER |
To study the shape of superclusters we approximate the spatial
distribution of galaxies or groups in superclusters by a 3-dimensional
mass ellipsoid and determine its centre, volume and principal axes.
In most cases our superclusters do
not form a regular body; however, these parameters can be used as a
first approximation to describe the density and alignments of the
elements of large-scale structure.
In the present study we use the classical mass ellipsoid
(see e.g. Korn & Korn 1961):
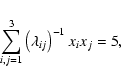 |
(1) |
where
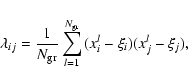 |
(2) |
is the inertia tensor for equally weighted groups,
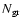 is the
total number of groups, and
is the
total number of groups, and
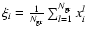 determines the Cartesian coordinates
of the centre of mass of the system.
determines the Cartesian coordinates
of the centre of mass of the system.
The formula determines a 3-dimensional ellipsoidal surface with the
distance from the centre of the ellipsoid equal to the rms deviation
of individual objects in the corresponding direction. This method can
be applied for superclusters with
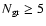 .
The problems related
to the stability of the method and the influence of observational
errors have been discussed in Jaaniste et al. (1998).
.
The problems related
to the stability of the method and the influence of observational
errors have been discussed in Jaaniste et al. (1998).
To investigate the sensitivity of the method to the number of groups
we divided our sample of mass ellipsoids into three richness
classes, Xrich with the number of groups
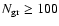 ,
Xmed with
,
Xmed with
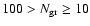 ,
and Xpoor with
,
and Xpoor with
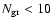 ;
here X denotes N
for the 2dFGRS Northern sample and S the Southern one. Superclusters
with the number of groups exceeding 10 are approximately uniformly
distributed in distance, whereas poor superclusters are all located at
a distance exceeding 300 h-1Mpc (see also Fig. 1). In
Fig. 10 we show in the left panel the semi-minor axis aand the semi-major axis c as a function of the supercluster total
luminosity. We see that poor superclusters have a large scatter of
semi-axis length values. In particular, the length of the semi-minor
axis is for some superclusters less than 1 h-1Mpc. As all these
superclusters are distant objects with only a few groups/clusters in
the visibility window, we assume that this large scatter is due to
small number of objects. Nearby superclusters of similar total
luminosity have considerably larger values of the semi-minor axis a and
a much smaller scatter. To avoid this uncertainty we
exclude samples of poor superclusters with
from further
analysis.
;
here X denotes N
for the 2dFGRS Northern sample and S the Southern one. Superclusters
with the number of groups exceeding 10 are approximately uniformly
distributed in distance, whereas poor superclusters are all located at
a distance exceeding 300 h-1Mpc (see also Fig. 1). In
Fig. 10 we show in the left panel the semi-minor axis aand the semi-major axis c as a function of the supercluster total
luminosity. We see that poor superclusters have a large scatter of
semi-axis length values. In particular, the length of the semi-minor
axis is for some superclusters less than 1 h-1Mpc. As all these
superclusters are distant objects with only a few groups/clusters in
the visibility window, we assume that this large scatter is due to
small number of objects. Nearby superclusters of similar total
luminosity have considerably larger values of the semi-minor axis a and
a much smaller scatter. To avoid this uncertainty we
exclude samples of poor superclusters with
from further
analysis.
Figure 10 right panel shows the bivariate distribution of
axial ratios a/b vs. b/c. This figure can be compared directly with
Figs. 9-11 of Wray et al. (2006) for samples of
simulated superclusters. Wray et al. defined superclusters as
clusters of rich DM-clusters. They used several linking
lengths to compile supercluster catalogues. The largest linking
length yields percolating superclusters and cannot be compared with our
results, but the linking length L = 5 h-1Mpc corresponds approximately to
our accepted threshold density (Fig. 11 of Wray et al.). The
comparison of our Fig. 10 with the corresponding figure
by Wray et al. shows very good agreement. Both distributions show that
there are no purely filamentary, spherical or pancake-like
superclusters: almost all superclusters are triaxial, with some
tendency toward a filamentary character.
We further note that Fig. 10 is similar to Fig. 7.
While the former shows the length of the semi-minor and semi-major axes aand c for superclusters of various total luminosities, the latter presents
minimal, maximal, and effective diameters of superclusters found from the
density field. Semi-axes of the mass ellipsoid are about one-half to
one-third the size of their respective diameters, as would be expected.
This analysis complements our previous analysis based on the density field.
If the supercluster only barely meets our
threshold density criterion, and only its tip exceeds the threshold density
level, then, by definition, the density field above the threshold is almost
spherical in shape, due to the symmetrical smoothing law applied in the
determination of the density field. Thus the true shape of poor superclusters
cannot be determined from the density field alone. Here the distribution of
objects within the supercluster can help, but only if the number of objects
exceeds 10.
 |
Figure 12:
Maximal density of superclusters as functions of the total
luminosity of the supercluster. Left panel shows data for 2dFGRS
samples, right panel for Millennium Run data, calculated with
minimal volume 200 (h-1Mpc)3. Notice the difference in the number of
poor superclusters. |
| Open with DEXTER |
A similar conclusion on the shape of superclusters has been reached by
Jaaniste et al. (1998). Basilakos et al. (2001) and Basilakos
(2003) applied shape-finders introduced by Sahni et al.
(1998), to find the shape characteristics of PSCz and SDSS
superclusters. PSCz superclusters were defined by the density field method
using rather large cell sizes of 5 and 10 h-1Mpc. SDSS superclusters were found
on the basis of Cut and Enhance clusters by Goto et al. (2002). In
both cases this statistic suggests that filaments dominate over pancakes.
Kolokotronis et al. (2002) compared shapes of Abell superclusters with
simulated superclusters using the same shape-finder statistics. Again a
dominance of filamentary structures both in real and simulated superclusters
was found. Doroshkevich et al. (2001) determined the effective
dimension for galaxy systems in high- and low-density regions, which
correspond to our supercluster and field samples. For the supercluster sample
they found the dimension
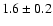 ,
and for the field sample
,
and for the field sample
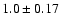 ,
which correspond to sheets and filaments, respectively. Klypin et al.
(1989) investigated the fractal dimensions of nearby superclusters
(Virgo, Coma) and galaxy filaments surrounding them. For superclusters they
found effective dimensions 1.8-2.0, for inter-supercluster regions 1.3.
,
which correspond to sheets and filaments, respectively. Klypin et al.
(1989) investigated the fractal dimensions of nearby superclusters
(Virgo, Coma) and galaxy filaments surrounding them. For superclusters they
found effective dimensions 1.8-2.0, for inter-supercluster regions 1.3.
An inspection of the density fields of 2dFGRS samples shows that
the shape of rich superclusters is more complicated. It
cannot be presented by a simple ellipsoid. The density field shows
that most superclusters are multi-branched, i.e. they consists of
numerous density knots arranged along several cluster chains. This
morphology has been detected in the Perseus-Pisces supercluster by
Jõeveer et al. (1978), Einasto et al. (1980) and
Zeldovich et al. (1982).
The mean luminosity density in superclusters is presented in Fig. 11
for 2dFGRS samples and for the Millennium Run sample. The mean density
rises from 4.5 for poor to 6-10 for rich superclusters. We see also a
gradual increase of the mean density with increasing total luminosity. This
fact demonstrates that rich superclusters are
dense systems, not just percolations of several loose systems.
The maximal luminosity density of superclusters (the smoothed density near the
dynamical center) is shown in Fig. 12. Here the trend with
supercluster total luminosity is even more pronounced: very luminous
superclusters also have high-density peaks at their centers. The maximal
density increases from 5 in poor superclusters to about 20 in rich ones. Note
that the maximal density of poor superclusters in many cases only marginally
exceeds the mean density (about 5), and both are very close to the threshold
density 4.6 used in the compilation of the supercluster catalogues. This
demonstrates that poor superclusters are small density enhancements with a low
scatter of internal density.
Note, however, that the supercluster with the highest luminosity does not have
the highest mean and maximal density, but is slightly lower than the highest
values. This is the case both for the real as well as the simulated
supercluster sample. This indicates that these largest superclusters are not
the very densest, but consist of a number of subunits of slightly lower mean
and maximal density.
There are two types of errors in our supercluster catalogue.
Systematic errors are due to uncertainties in the selection
algorithms and in the input parameters in the selection of
superclusters. Random errors are due to observational errors and errors
due to the small number of observed galaxies in superclusters.
Random errors in the galaxy positions are negligible. More serious
are errors in redshifts and in magnitudes. Large errors in redshift are
very rare and move the galaxy completely outside the supercluster in
question, thus these errors influence the number of galaxies
in the system. Ordinary redshift errors increase the redshift scatter
of galaxies in groups and single galaxies inside superclusters. The
scatter inside groups is taken into account during the group selection
procedure. In this paper we have used the mean redshifts of galaxies in
groups. The influence of random errors on the mean redshift of groups is
small, in most cases less than 1 h-1Mpc (if the redshift error is
transformed to distance error). Redshift errors of single galaxies are
larger, but also do not exceed considerably 1 h-1Mpc, the size of an
elementary cell in the density field. Since densities are smoothed
with an Epanechnikov kernel of radius 8 h-1Mpc, these errors do not
influence our results.
Errors in magnitudes, in particular the corrections due to unobserved
galaxies, are the most serious random errors in our supercluster
catalogue. These errors increase the scatter of expected total
luminosities of superclusters. More important are the errors of the
density field due to the use of corrected expected luminosities of
galaxies. As suggested by Basilakos et al. (2001), the
smoothing of the density field may introduce a systematic error which
increases densities above the mean density and decreases densities
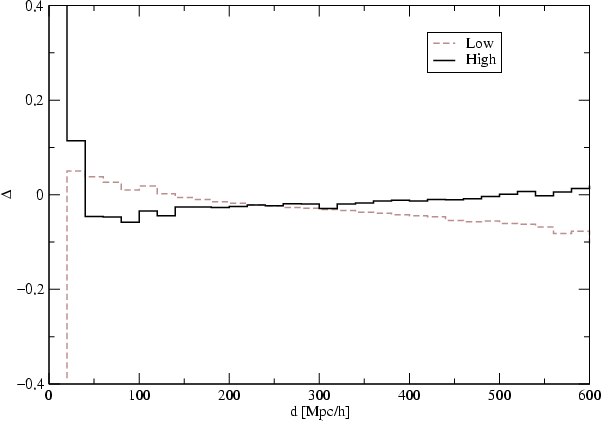
below the mean (see their Fig. 1). To investigate how serious this error is in
our case, we compared two density fields of the Millennium Run,
Mill.A8 and Mill.F8, and calculated the quantity
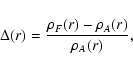 |
(3) |
where 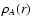 is the mean density found for the original sample
Mill.A8, and
is the mean density found for the original sample
Mill.A8, and 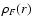 is the mean density found for the simulated
2dF sample. Mean values were found for a series of distance intervals
from the observer. The results of the calculation are shown in
Fig. 13. The trend is the same as found by Basilakos
et al., but the errors are about 10 times smaller. This difference in errors
is probably due to the use of very different cell sizes: in our case
the size was 1 h-1Mpc, whereas Basilakos et al. used cell sizes of 5 and
10 h-1Mpc. Thus, deriving the density field using a small cell size
and calculating from flux-limited galaxy data does not introduce
noticeable systematic errors. Random errors in the density field are
larger, as seen from the comparison of supercluster total luminosities
found for samples Mill.A8 and Mill.F8 (see Paper I).
is the mean density found for the simulated
2dF sample. Mean values were found for a series of distance intervals
from the observer. The results of the calculation are shown in
Fig. 13. The trend is the same as found by Basilakos
et al., but the errors are about 10 times smaller. This difference in errors
is probably due to the use of very different cell sizes: in our case
the size was 1 h-1Mpc, whereas Basilakos et al. used cell sizes of 5 and
10 h-1Mpc. Thus, deriving the density field using a small cell size
and calculating from flux-limited galaxy data does not introduce
noticeable systematic errors. Random errors in the density field are
larger, as seen from the comparison of supercluster total luminosities
found for samples Mill.A8 and Mill.F8 (see Paper I).
 |
Figure 13:
The mean difference of the density between density fields of
Mill.A8 and Mill.F8, at various distances from the "observer''. The
solid line shows differences in overdensity regions, the dashed line
in under-density regions.
|
| Open with DEXTER |
Table 2:
Identification of rich 2dF Northern superclusters
in another supercluster catalogues.
The most serious errors in our catalogue are due to the small number of
galaxies observed in distant superclusters. As seen from Fig. 1,
the number of galaxies observed in superclusters has a lower limit which
decreases with increasing distance according to the same relation as found by
shifting groups of galaxies to larger distance (see T06). At the outer limit
of our galaxy sample at z = 0.2 the lower limit of the number of galaxies
observed in superclusters approaches
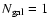 .
It is clear that one
galaxy is not sufficient to define a supercluster, even a poor one. Thus we
have excluded superclusters fewer than 3 groups from our list.
Furthermore, the catalogue was divided into two parts, the main catalogue A
and the supplementary catalogue B. The main catalogue has systems up to
distance 520 h-1Mpc, and the supplementary one even more distant objects. We
have found the luminosity function of superclusters separately for the main
and the supplementary supercluster sample (see Fig. 5). The
luminosity function of the supplementary sample is slightly
higher for rich superclusters.
.
It is clear that one
galaxy is not sufficient to define a supercluster, even a poor one. Thus we
have excluded superclusters fewer than 3 groups from our list.
Furthermore, the catalogue was divided into two parts, the main catalogue A
and the supplementary catalogue B. The main catalogue has systems up to
distance 520 h-1Mpc, and the supplementary one even more distant objects. We
have found the luminosity function of superclusters separately for the main
and the supplementary supercluster sample (see Fig. 5). The
luminosity function of the supplementary sample is slightly
higher for rich superclusters.
Table 3:
Identification of rich 2dF Southern superclusters
in another supercluster catalogues.
In Tables 2 and 3 we give the identification
of superclusters from our lists with the list by Erdogdu et al.
(2004) obtained using the Wiener Filter method, and with Abell
superclusters by Einasto et al. (E01). For superclusters that have no
partners in the Abell supercluster list, we give the number of Abell clusters
within the volume of the supercluster. The reason for the absence of the
supercluster in the Abell supercluster list can be either a too low number of
Abell clusters in the supercluster volume (identified in an Abell supercluster
search as an isolated Abell cluster), or the clusters was too distant to be
included in the Abell supercluster catalogue. The commonly used name given in
the ninth column is according to the Abell supercluster catalogue by E01.
This comparison shows that there is no one-to-one relationship between
superclusters of our lists and the lists by other authors. Differences are
due to the use of different techniques in supercluster definition and to the
use of different observational data.
 |
Figure 14:
The density field through the supercluster SCL126. Left
panel shows the low-resolution field, the right panel the
high-resolution field. In the low-resolution field the contour
limiting green and blue regions corresponds to threshold density 4.6
in units of the mean density, which separates supercluster regions
from low-density ones. The length of the box is 150 h-1Mpc.
|
| Open with DEXTER |
Erdogdu et al. used a much larger and variable cell size when deriving the
smoothed density field, thus their method has lower resolution than ours.
Taking this into account, it is not surprising that several superclusters found
with the Wiener filtering method are split into separate systems in our list.
For instance, the Wiener Northern supercluster 08 combines our superclusters 76, 82, 92 and 97, and the Wiener Southern superclusters 15 and 18 are
combinations of our superclusters 109, 126 and 51, 94, respectively. If we use
a lower threshold density, then at a certain level our method also joins these
superclusters to single systems. We repeat that the actual web of
superclusters and filaments is a continuous one, and it is matter of
convention how to join parts of this web to particular systems.
Abell superclusters were found using only Abell clusters as tracers - no
individual galaxy information was used. Also the linking length used to
combine clusters into superclusters corresponds to a much lower threshold
density in our method. Due to these differences in data and method, one would
expect to see more differences in the results. Actually there exists a rather
good correspondence between our and Abell superclusters. The most notable
differences are that Abell supercluster 265 is divided in our list into three
entries (37, 92 and 97) in the Northern region, and that Abell 232 is a
combination of our 109 and 116 in the Southern region. But there are also
examples in another direction: the most prominent supercluster in the Northern
region, 152 in our list and 06 in the Wiener supercluster list, is partly
divided into Abell superclusters 111 and 126.
The comparison of properties of simulated superclusters with real
superclusters shows that in most cases simulated superclusters have relations
between various parameters and the total luminosity which are almost
identical to similar relations for real superclusters. There are some
differences: the luminosity and the multiplicity functions of the Millennium
Run superclusters do not contain as many very rich superclusters as is
found in the 2dFGRS sample. We shall discuss these differences in more detail
elsewhere (Einasto et al. 2006a; Saar et al. 2006).
The similarity of results for real and simulated superclusters has
several consequences. First, it shows that our procedures to
define superclusters and their parameters are rather robust and yield
stable results. Secondly, it shows that simulations have reached a
stage that produces superclusters of galaxies with properties very
close to the observations.
Superclusters are large-scale density enhancements in the cosmic web,
the supercluster-void network. Rich and very rich superclusters
contain rich clusters of galaxies in a relatively small volume, thus
such objects are easily detected. Their properties depend on the
method of selection of superclusters, but the principal properties are
fairly stable. As an example we show in Fig. 14 the low-
and high-resolution density fields through the richest supercluster in
the 2dFGRS Northern region, SCL126. This supercluster has been
called the Sloan Great Wall (Vogeley et al. 2004; Gott et al. 2005; Nichol et al. 2006). Actually, the
wall-like shape is due to the enhancement of the structure, as at this
distance the observed spatial density of galaxies in the flux limited 2dFGRS
and SDSS samples has a maximum. Praton et al. (1997)
refer to this as the "Bull's Eye'' effect. We see that the density contour 4.6
includes only the main body of the supercluster, the outlying parts and
galaxy filaments (seen in the high-resolution density field) remaining
outside the supercluster volume. Similarly, in poor superclusters, the
supercluster volume contains only the central core of the
supercluster.
Very rich superclusters have been found also in our vicinity outside
the 2dFGRS and SDSS surveys: the Shapley Supercluster and the
Horologium-Reticulum Supercluster (see Proust et al. 2006;
Fleenor et al. 2005; and Ragone et al. 2006, and
references therein).
Most superclusters discussed in this paper are poor. They form small and
medium density enhancements in the cosmic web. The web is a continuous
network of filaments and sheets of galaxies, and there exist density
enhancements of very different scale and luminosity. This continuous network
of filaments was investigated recently by Sousbie et al. (2006).
They found an algorithm which allows one to find the 3-dimensional filamentary
skeleton of the equatorial slice of the SDSS. This slice is overlapped by the
2dFGRS Northern region and is centered around the supercluster SCL126, the
Sloan Great Wall. The density field method with a certain threshold density
allows one to identify as superclusters only their denser parts. As shown by
Sousbie et al. and seen in Fig. 14, the filamentary network
continues outside superclusters.
There exist numerous investigations concerning the shape of structural
elements of the cosmic web: Bond et al. (1996), Doroshkevich et al.
(2001, 2004), Kasun & Evrard 2005, Shen et al.
(2005), Sousbie et al. (2006), to name only a few
studies. Doroshkevich et al. (2001) find that about 40-50% of all
galaxies belong to the "wall'' (i.e. supercluster) population. This is in
very good agreement with our results: we find that for a threshold density of
4.6 the fraction of galaxies in the supercluster population is 42% (in both
2dFGRS regions). The volume filled with superclusters is much lower: 3.2%
in the Northern region, and 3.5% in the Southern one. This volume filling
factor is two times lower than found by E05b for a simulated supercluster
population. The difference can be explained by the use of a lower threshold
density by E05b (2.66 in units of the mean density).
We performed an analysis of properties of superclusters listed in Paper I.
Properties of real superclusters have been compared with properties of
simulated superclusters from the Millennium Run mock galaxy catalogue by
Croton et al. (2006), using identical procedures to collect
galaxies to superclusters.
- We find that our sample of superclusters forms a homogeneous sample of
galaxy systems, where properties of superclusters smoothly change with the
total luminosity and multiplicity of the supercluster. Using the
multiplicity we divide superclusters into four richness classes: poor,
medium, rich and extremely rich.
- We investigated the shape of superclusters using groups of galaxies
located inside superclusters, and the configuration of the density field
above the threshold used to define superclusters. We find that rich
superclusters are more asymmetrical and have a smaller filling factor than
poor ones. The asymmetry is characterized by the offset of the geometrical
mean center from the dynamical one, defined as the center of the main
cluster. Another manifestation of the asymmetry is the ratio of the mean
diameter to the effective diameter (the diameter of a sphere equal to the
volume of the supercluster); this ratio characterizes the filling factor and
the degree of filamentarity of the system.
- We find that the mean and the maximal densities of
superclusters increase when going from poor to rich
superclusters. This fact demonstrates that rich superclusters are
not due to artificial percolation of poorer superclusters: they form
a class of galaxy systems with properties continuously changing with
supercluster richness.
- We calculated the luminosity and the multiplicity functions of
superclusters; both span over two decades in luminosity and spatial density.
The richest superclusters of the 2dFGRS sample contain up to 60
DF-clusters, whereas the richest superclusters in simulations
contain only up to 20. This is the main difference between
simulated supercluster sample and observations.
- The comparison of properties of 2dFGRS superclusters with
those of superclusters found for the Millennium Run
shows that almost all geometric properties of simulated
superclusters are very close to similar properties of real
superclusters of the 2dFGRS sample.
Acknowledgements
We thank the 2dFGRS Team for the publicly available final
data release. The Millennium Simulation used in this paper was carried out
by the Virgo Supercomputing Consortium at the Computing Centre of the
Max-Planck Society in Garching. The semi-analytic galaxy catalogue is
publicly available at http://www.mpa-garching.mpg.de/galform/agnpaper. We
thank the anonymous referee for constructive suggestions. The present study
was supported by Estonian Science Foundation grants Nos. 4695, 5347 and 6104
and 6106, and Estonian Ministry for Education and Science support by grant
TO 0060058S98. This work has also been supported by the University of
Valencia through a visiting professorship for Enn Saar and by the Spanish
MCyT project AYA2003-08739-C02-01. D.T. was supported by the US Department
of Energy under contract No. DE-AC02-76CH03000. J.E. thanks
Astrophysikalisches Institut Potsdam (using DFG-grant 436 EST 17/2/05) for
hospitality where part of this study was performed. A.K. acknowledges
funding through the Emmy Noether Programme by the DFG (KN 755/1). This
research has made use of SAOImage DS9, developed by Smithsonian
Astrophysical Observatory, and R, a language for data analysis and graphics
(Ihaka & Gentleman 1996).
- Abell, G. 1958, ApJS, 3,
211 [NASA ADS] [CrossRef] (In the text)
- Abell, G., Corwin, H., &
Olowin, R. 1989, ApJS, 70, 1 [NASA ADS] [CrossRef] (In the text)
- Bahcall, N. A.
1988, ARA&A, 26, 631 [NASA ADS] (In the text)
- Balogh, M., Eke,
V., Miller, C., et al. 2004, MNRAS, 348, 1355 [NASA ADS] [CrossRef] (In the text)
- Basilakos, S. 2003,
MNRAS, 344, 602 [NASA ADS] [CrossRef] (In the text)
- Basilakos, S., Plionis,
M., & Rowan-Robinson, M. 2001, MNRAS, 323, 47 [NASA ADS] [CrossRef] (In the text)
- Bond, J. R., Kofman, L.,
& Pogosyan, D. 1996, Nature, 380, 603 [NASA ADS] [CrossRef] (In the text)
- Colless, M. M., Dalton,
G. B., Maddox, S. J., et al. 2001, MNRAS, 328, 1039 [NASA ADS] [CrossRef] (In the text)
- Colless, M. M., Peterson,
B. A., Jackson, C. A., et al. 2003
[arXiv:astro-ph/0306581]
(In the text)
- Croton, D. J.,
Farra, G. R., Norberg, P., et al. 2005, MNRAS, 356, 1155 [NASA ADS] [CrossRef] (In the text)
- Croton, D. J.,
Springel, V., White, S. D. M., et al. 2006, MNRAS, 365, 11 [NASA ADS] [CrossRef] (In the text)
- Doroshkevich, A., Tucker,
D. L., Fong, R., et al. 2001, MNRAS, 322, 369 [NASA ADS] [CrossRef] (In the text)
- Doroshkevich, A., Tucker,
D. L., Allam, S., & Way, M. J. 2004, A&A, 418, 7 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Einasto, J.,
Jõeveer, M., & Saar, E. 1980, MNRAS, 193, 353 [NASA ADS] (In the text)
- Einasto, M., Einasto, J.,
Tago, E., Dalton, G., & Andernach, H. 1994, MNRAS, 269, 301 [NASA ADS]
(E94)
(In the text)
- Einasto, M., Tago, E.,
Jaaniste, J., Einasto, J., & Andernach, H. 1997, A&AS, 123,
119 [NASA ADS] (E97)
(In the text)
- Einasto, M., Einasto, J.,
Tago, E., Müller, V., & Andernach, H. 2001, AJ, 122, 2222 [CrossRef]
(E01)
(In the text)
- Einasto, J., Einasto, M.,
Hütsi, G., et al. 2003a, A&A, 410, 425 [NASA ADS] [CrossRef] [EDP Sciences] (E03a)
(In the text)
- Einasto, J., Hütsi,
G., Einasto, M., et al. 2003b, A&A, 405, 425 [NASA ADS] [CrossRef] [EDP Sciences] (E03b)
- Einasto, M., Einasto,
J., Müller, V., Heinämäki, P., & Tucker, D. L.
2003c, A&A, 401, 851 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Einasto, J., Tago E.,
Einasto, M., et al. 2005, A&A, 439, 45 [NASA ADS] [CrossRef] [EDP Sciences] (E05b)
- Einasto, J., Einasto, M.,
Saar, E., et al. 2006a, A&A, 459, L1 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Einasto, M., Einasto,
J., Tago, E., et al. 2006b, A&A, accepted (E06c)
(In the text)
- Einasto, J., Einasto, M.,
Tago, E., et al. 2007, A&A, 462, 811 [EDP Sciences] (Paper I)
(In the text)
- Erdogdu, P., Lahav, O.,
Zaroubi, S., et al. 2004, MNRAS, 352, 939 [NASA ADS] [CrossRef] (In the text)
- Fleenor, M. C.,
Rose, J. A., Christiansen, W. A., et al. 2005, AJ, 130, 95 [NASA ADS] [CrossRef] (In the text)
- Gao, L., White, S. D. M.,
Jenkins, A., et al. 2005, MNRAS, 363, 379 [NASA ADS] (In the text)
- Goto, T., et al. 2002,
AJ, 123, 1825 [NASA ADS] [CrossRef] (In the text)
- Gott, J. R., Juric, M.,
Schleger, D., et al. 2005, ApJ, 624, 463 [NASA ADS] [CrossRef] (In the text)
- Gregory, S. A., &
Thompson, L. A. 1978, ApJ, 222, 784 [NASA ADS] [CrossRef] (In the text)
- Ihaka, R., & Gentleman,
R. 1996, J. Comput. Graphic. Stat., 5, 299 (In the text)
- Jaaniste, J., Tago, E.,
Einasto, M., et al. 1998, A&A, 336, 35 [NASA ADS] (In the text)
- Jõeveer, M.,
Einasto, J., & Tago, E. 1978, MNRAS, 185, 357 [NASA ADS] (In the text)
- Kalinkov, M., & Kuneva,
I. 1995, A&AS, 113, 451 [NASA ADS] (In the text)
- Kasun, S. F., &
Evrard, A. E. 2005, ApJ, 629, 781 [NASA ADS] [CrossRef] (In the text)
- Klypin, A. A., Einasto,
J., Einasto, M., & Saar, E. 1989, MNRAS, 237, 929 [NASA ADS] (In the text)
- Kolokotronis, V.,
Basilakos, S., & Plionis, M. 2002, MNRAS, 331, 1020 [NASA ADS] [CrossRef] (In the text)
- Korn, G. A., &
Korn, T. M. 1961, Mathematical Handbook for Scientist and Engineers
(McGraw-Hill Book. Co., Inc.)
(In the text)
- Lahav, O. 2004, Pub.
Astr. Soc. Australia, 21, 404 [NASA ADS] (In the text)
- Lahav, O. 2005, in
Nearby Large-Scale Structures and the Zone of Avoidance, ed. A. P.
Fairall, P. Woudt, ASP Conf. Ser., 329, 3
(In the text)
- Nichol, R. C.,
Sheth, R. K., Suto, Y., et al. 2006, MNRAS, 368, 1507 [NASA ADS] [CrossRef] (In the text)
- Oguri, M., Takahashi,
K., Ichiki, K., & Ohno, H. 2004
[arXiv:astro-ph/0410145]
(In the text)
- Oort, J. H. 1983,
ARA&A, 21, 373 [NASA ADS] (In the text)
- Porter, S. C., &
Raychaudhury, S. 2005, MNRAS, 364, 1387 [NASA ADS] [CrossRef] (In the text)
- Praton, E. A.,
Melott, A. L., & McKee, M. Q. 1997, ApJ, 479, L1 [CrossRef] (In the text)
- Proust, D.,
Quintana, H., Carrasco, E. R., et al. 2006, A&A, 447, 133 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Ragone, C. J.,
Merchan, M., Muriel, H., & Zandivarez, A. 2004, MNRAS, 350,
983 [NASA ADS] [CrossRef] (In the text)
- Ragone, C. J.,
Muriel, H., Proust, D., et al. 2006, A&A, 445, 819 [NASA ADS] [CrossRef] [EDP Sciences] (In the text)
- Saar, E., Einasto, J.,
Einasto, M., et al. 2006, in preparation
(In the text)
- Sahni, V.,
Sathyaprakash, B. S., & Shandarin, S. F. 1998, ApJ, 495,
L5 [NASA ADS] [CrossRef] (In the text)
- Shen, J., Abel, T., Mo,
H., & Sheth, R. K. 2005, [arXiv:astro-ph/0511365]
(In the text)
- Sousbie, T.,
Pichon, C., Courtois, H., et al. 2006, ApJ
[arXiv:astro-ph/0602628]
(In the text)
- Springel, V.,
White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [NASA ADS] [CrossRef] (In the text)
- Tago, E., Einasto, J.,
Saar, E., et al. 2006, AN, 327, 365 [NASA ADS] (T06)
(In the text)
- Vogeley, M. S.,
Hoyle, F., Rojas, R. R., et al. 2004, Proc. IAU Coll., 195
[arXiv:astro-ph/0408583]
(In the text)
- Wray, J. J., Bahcall,
N., Bode, P., et al. 2006, [arXiv:astro-ph/060306]
(In the text)
- Zeldovich, Ya. B.,
Einasto, J., & Shandarin, S. F. 1982, Nature, 300, 407 [NASA ADS] [CrossRef] (In the text)
- Zucca, E., Zamorani, G.,
Scaramella, R., et al. 1993, ApJ, 407, 470 [NASA ADS] [CrossRef] (In the text)
Copyright ESO 2007
![\begin{figure}
\par\mbox{\resizebox{8.5cm}{!}{\includegraphics[clip]{5501_fig1a....
...2mm}
\resizebox{8.5cm}{!}{\includegraphics[clip]{5501_fig1b.eps}} }
\end{figure}](/articles/aa/full/2007/05/aa5501-06/img2.gif)