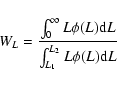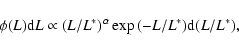A&A 462, 811-825 (2007)
DOI: 10.1051/0004-6361:20065296
J. Einasto1 - M. Einasto1 - E. Tago1 - E. Saar1 - G. Hütsi1 - M. Jõeveer1 - L. J. Liivamägi1 - I. Suhhonenko1 - J. Jaaniste2 - P. Heinämäki3 - V. Müller4 - A. Knebe4 - D. Tucker5
1 - Tartu Observatory, 61602 Tõravere, Estonia
2 -
Estonian University of Life Sciences
3 -
Tuorla Observatory, Väisäläntie 20, Piikkiö, Finland
4 -
Astrophysical Institute Potsdam, An der Sternwarte 16,
14482 Potsdam, Germany
5 -
Fermi National Accelerator Laboratory, MS 127, PO Box 500, Batavia,
IL 60510, USA
Received 28 March 2006 / Accepted 25 October 2006
Abstract
Aims. We use the 2dF Galaxy Redshift Survey data to compile catalogues of superclusters for the Northern and Southern regions of the 2dFGRS, altogether 543 superclusters at redshifts
![]() .
.
Methods. We analyse methods of compiling supercluster catalogues and use results of the Millennium Simulation to investigate possible selection effects and errors. We find that the most effective method is the density field method using smoothing with an Epanechnikov kernel of radius 8 h-1 Mpc.
Results. We derive positions of the highest luminosity density peaks and find the most luminous cluster in the vicinity of the peak, this cluster is considered as the main cluster and its brightest galaxy the main galaxy of the supercluster. In catalogues we give equatorial coordinates and distances of superclusters as determined by positions of their main clusters. We also calculate the expected total luminosities of the superclusters.
Key words: cosmology: large-scale structure of the Universe - galaxies: clusters: general
It is presently well established that galaxies form various systems from groups and clusters to superclusters. Galaxy systems are not located in space randomly: groups and clusters are mostly aligned to chains (filaments), and the space between groups is populated with galaxies along the chain. The largest non-percolating galaxy systems are superclusters of galaxies which contain clusters and groups of galaxies with their surrounding galaxy filaments.
Superclusters of galaxies have been used for a wide range of studies. Superclusters are produced by large-scale density perturbations which evolve very slowly. Thus the distribution of superclusters contains information on the large-scale initial density field, and their properties can be used as a cosmological probe to discriminate between different cosmological models. The internal structure of superclusters conserves information on the galaxy formation and evolution on medium scales. Properties of galaxies and groups in various supercluster environments can be used to study the evolution of galaxies on small scales. Superclusters are massive density enhancements and thus great gravitational attractors which distort the background radiation, yielding information on the gravitation field through the CMB distortion via the Sunyaev-Zeldovich effect, which can be detected using new satellites, such as PLANCK.
Early studies of superclusters of galaxies were reviewed by Oort (1983) and Bahcall (1988). These studies were based on observational data about galaxies, as well as on data about nearby groups and clusters of galaxies. Classical, relatively deep all-sky supercluster catalogues were constructed using the Abell (1958) and Abell et al. (1989) cluster catalogues by Zucca et al. (1993), Einasto et al. (1994, 1997, 2001, hereafter E94, E97, E01) and Kalinkov & Kuneva (1995).
The modern era of the study of various systems of galaxies began when new galaxy redshift surveys began to be published. The first of such surveys was the Las Campanas Galaxy Redshift Survey, followed by the 2 degree Field Galaxy Redshift Survey (2dFGRS) and the Sloan Digital Sky Survey (SDSS). These surveys cover large regions of the sky and are rather deep allowing to investigation of the distribution of galaxies and systems of galaxies out to fairly large distances from us. Group catalogues based on the 2dFGRS survey were published by Eke et al. (2004) and Tago et al. (2006, hereafter T06), and for the SDSS survey by Berlind et al. (2006). Einasto et al. (2003a,b, hereafter E03a and E03b) used equatorial slices of the SDSS and 6 slices of the Las Campanas Galaxy Redshift Survey to find superclusters using 2-dimensional density field. Based on 3-dimensional data catalogues of superclusters were compiled on the basis of these new surveys by Basilakos (2003), Erdogdu et al. (2004) and Porter & Raychaudhury (2005). These observational studies have been complemented by the analysis of the evolution of superclusters and the supercluster-void network (Shandarin et al. 2004; Einasto et al. 2005b; Wray et al. 2006).
So far the attention of astronomers has been focused either on small compact systems, such as groups and clusters, or on very large systems - rich superclusters of galaxies. Modern redshift surveys make it possible to investigate not only these classical systems of galaxies, but also galaxy systems of intermediate sizes and richness classes of various sizes, from poor galaxy filaments in large cosmic voids to rich superclusters. In the present series of papers we shall discuss the richest of these systems - superclusters of galaxies. We shall use the term "supercluster'' for galaxy systems larger than groups and clusters which have a certain minimal mean overdensity of the smoothed luminosity density field but are still non-percolating. They form intermediate-scale galaxy systems between groups and poor filaments and the whole cosmic web.
The main goal of this paper is to compile a new catalogue of superclusters using the 2dFGRS. To get a representative statistical sample we include in our catalogue superclusters of all richness classes, starting from poor superclusters of the Local Supercluster class, and ending with very rich superclusters of the Shapley Supercluster class (see Proust et al. 2006a,b, and references therein). In the compilation of a statistically homogeneous and complete sample of superclusters we make use of the possibility to recover the true expected total luminosity of galaxy systems, using weights to compensate the absence of galaxies from the sample which are too faint to fall within the observational window of the survey. The use of weights has some uncertainties, so we have to investigate errors and possible biases of our procedure to recover the total luminosity of superclusters. To investigate selection effects and biases we shall investigate properties of simulated superclusters based on the catalogue of galaxies by Croton et al. (2006) of the Millennium Simulation of the evolution of the structure of the Universe by Springel et al. (2005). In an accompanying paper we shall investigate properties of superclusters and compare properties of real superclusters with those of simulated superclusters (Einasto et al. 2007, hereafter Paper II). An analysis of the luminosity function of superclusters using both 2dFGRS and SDSS superclusters is presented by Einasto et al. (2006a).
The paper is composed as follows. In the next section we shall describe the observational and model data used. In Sect. 3 we shall discuss superclusters in the cosmic web and describe our preliminary study of 2dFGRS superclusters. In Sect. 4 we shall discuss selection effects and their influence on supercluster catalogues. This section is based on simulated superclusters using the Millennium Simulation. Section 5 describes the catalogue itself. In the last section we give our conclusions. The catalogues of superclusters are available electronically at the web-site http://www.aai.ee/~maret/2dfscl.html and at the CDS.
In this paper we have used the 2dFGRS final release (Colless et al. 2001, 2003) that contains 245591 galaxies. This survey
has allowed the 2dFGRS Team and many others to estimate fundamental
cosmological parameters and to study intrinsic properties of galaxies
in various cosmological environments (see Lahav 2004, 2005, for recent reviews). The survey consists of two main
areas in the Northern and Southern galactic hemispheres within the
coordinate limits given in Table 1. The 2dF sample becomes
very diluted at large distances, thus we restrict our sample to a redshift limit z=0.2; we apply a lower limit
![]() to avoid
the confusion with unclassified objects and stars. In the calculating
distances we use a flat cosmological model with the parameters: matter
density
to avoid
the confusion with unclassified objects and stars. In the calculating
distances we use a flat cosmological model with the parameters: matter
density
![]() ,
dark energy density
,
dark energy density
![]() (both in units of the critical cosmological density), and the
mass variance on 8 h-1 Mpc scale in linear theory
(both in units of the critical cosmological density), and the
mass variance on 8 h-1 Mpc scale in linear theory
![]() .
Here and elsewhere h is the present-day dimensionless Hubble
constant in units of 100 km s-1 Mpc-1. In Table 1
.
Here and elsewhere h is the present-day dimensionless Hubble
constant in units of 100 km s-1 Mpc-1. In Table 1
![]() is the number of galaxies,
is the number of galaxies,
![]() is the number of
superclusters found, and V is the volume covered by the sample (in
units
is the number of
superclusters found, and V is the volume covered by the sample (in
units
![]() ). These numbers are based upon version B of
the catalogue of groups by Tago et al. (T06). This version of the
group catalogue was found using the Friend-of-Friend (FoF) method with
a linking length, which increased slightly with distance, as suggested
by the study of the behaviour of groups with distance (for details see
T06).
). These numbers are based upon version B of
the catalogue of groups by Tago et al. (T06). This version of the
group catalogue was found using the Friend-of-Friend (FoF) method with
a linking length, which increased slightly with distance, as suggested
by the study of the behaviour of groups with distance (for details see
T06).
Table 1: Data on 2dF samples.
Table 2: Data on comparison samples.
Galaxies were included in the 2dFGRS, if their corrected apparent
magnitude ![]() lay in the interval from
m1 = 13.5 to
m2 =
19.45. Actually the faint limit m2 varies from field to field. In
calculation of the weights these deviations have been taken into
account, as well as the fraction of observed galaxies among all
galaxies up to the fixed magnitude limit. This fraction is typically
about 0.9, while in rare cases it might become very small. In such
cases, to avoid too high values of respective corrections, we have
applied the completeness correction only when the completeness is
higher than 0.5, otherwise we assumed a value 1, i.e. no completeness
correction was applied. The number of galaxies with completeness
parameter less than 0.5 is very small and their inclusion or exclusion
has little effect to final results. In the preliminary version of the
2dF supercluster catalogue no completeness correction was applied at
all; nevertheless, supercluster properties of the final and
preliminary catalogues are very close.
lay in the interval from
m1 = 13.5 to
m2 =
19.45. Actually the faint limit m2 varies from field to field. In
calculation of the weights these deviations have been taken into
account, as well as the fraction of observed galaxies among all
galaxies up to the fixed magnitude limit. This fraction is typically
about 0.9, while in rare cases it might become very small. In such
cases, to avoid too high values of respective corrections, we have
applied the completeness correction only when the completeness is
higher than 0.5, otherwise we assumed a value 1, i.e. no completeness
correction was applied. The number of galaxies with completeness
parameter less than 0.5 is very small and their inclusion or exclusion
has little effect to final results. In the preliminary version of the
2dF supercluster catalogue no completeness correction was applied at
all; nevertheless, supercluster properties of the final and
preliminary catalogues are very close.
For comparison we used simulated galaxy samples of the Millennium Simulation by Springel et al. (2005). This simulation was made using modern values of cosmological parameters in a box of side-length 500 h-1 Mpc, using a very fine grid (about 20003), and the largest so far number of Dark Matter particles. Using semi-analytic methods catalogues of simulated galaxies were calculated by Croton et al. (2006). The simulated galaxy catalogue contains almost 9 million objects, for which positions and velocities are given, as well as absolute magnitudes in the Sloan Photometric system (u,g,r,i,z). The limiting absolute magnitude of the catalogue is -17.4 in the r band. Data on comparison samples are shown in Table 2 (for details see Sect. 4). Model catalogues were found for various selection parameters and smoothing lengths. The smoothing lengths 4, 6, 8 h-1 Mpc were used to study the influence of this parameter to supercluster properties. To find local environmental densities of galaxies we calculated the high-resolution density field using a smoothing length 0.5 h-1 Mpc. This field was also used to compile a catalogue of groups and clusters. The largest systems in this catalogue correspond to superclusters.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{5296_fig1a_c.eps}\includeg...
...296_fig1c_c.eps}\includegraphics[width=8.5cm,clip]{5296_fig1d_c.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img14.gif) |
Figure 1: The high-resolution 2-dimensional density field of the Northern and Southern parts of the 2dF redshift survey. Upper panels show the Northern region, and lower panels the Southern region. In left panels only galaxies and galaxy systems in high-density regions are shown, in right panels only galaxies and galaxy systems in low-density regions. The threshold density between high- and low-density objects is 4.5 in units of the mean density, smoothed on scale 8 h-1 Mpc. The samples are conical, i.e. their thickness increases with distance, thus on large distance from the observer we see many more systems of galaxies. |
| Open with DEXTER | |
So far statistical samples of superclusters have been compiled mainly on the basis of catalogues of clusters of galaxies. Now deep galaxy catalogues are available for large areas of the sky. To make the best use of these new data a number of problems is to be solved. The main problems are: 1) how to define superclusters using new data; 2) which method is best suited to find superclusters; 3) which selection parameters are to be used in supercluster search; 4) which parameters can be derived to characterise supercluster properties; in particular, which parameters can be used to characterise the richness of superclusters and how to estimate the supercluster total luminosity; 5) what is the accuracy of estimated supercluster parameters.
To answer these questions we performed a preliminary analysis of the 2dFGRS data. The results of this analysis are presented below. In particular, we compared different methods to compile superclusters, and studied possibilities to find the best values of the selection parameters. To answer the last question, to investigate the influence of various smoothing lengths on supercluster lists, and to compare various possibilities to define the center of superclusters we analysed simulated supercluster catalogues; this analysis is given in Sect. 4.
Superclusters have been defined so far either as "clusters of clusters'' using catalogues of clusters of galaxies, following Abell (1958, 1961), or as high-density regions in the galaxy distribution, following the pioneering study by de Vaucouleurs (1953) of the Local Supergalaxy. Nearby superclusters have been found mostly on the basis of combined galaxy and cluster data (Jõeveer et al. 1978; Gregory & Thompson 1978; Fleenor et al. 2005; Proust et al. 2006a,b; Ragone et al. 2006). Until recently, more distant superclusters have been found almost exclusively on the basis of catalogues of rich clusters of galaxies by Abell (1958) and Abell et al. (1989). Only in recent years distant superclusters have been found using new deep redshift surveys of galaxies, such as the Las Campanas Redshift Survey, the 2dF Galaxy Redshift Survey, and the Sloan Digital Sky Survey (E03a; E03b; Basilakos 2003; Erdogdu et al. 2004; and Porter & Raychaudhury 2005).
As in previous supercluster searches we are confronted with the problem of how to define superclusters. To visualize the problem we show in Fig. 1 2-dimensional projections of the 2dF Redshift Survey Northern and Southern regions. In these plots luminosity density was found using Gaussian smoothing with rms scale 0.8 h-1 Mpc, survey volumes were projected onto a great circle through respective regions of the sky, and the regions were rotated in order to have symmetrical areas around the vertical axis. Galaxies and galaxy systems located in different global environments are plotted separately: the left panels show only systems located in high-density environment, and the right panels show only systems in low-density environment. High- and low-density regions are defined by the low-resolution density field smoothed with Epanechnikov kernel of radius 8 h-1 Mpc; a threshold density 4.5 was applied in the mean density units.
The comparison of left and right panels shows the presence of a striking contrast between galaxy systems in high- and low-density regions. Luminous systems in high-density regions are fairly compact; they have been conventionally classified as superclusters of galaxies. These systems are well isolated from each other. The majority of these high-density systems are fairly small in size. As we shall see below, these small systems contain only 1-2 clusters of galaxies and resemble in structure systems like the Local and the Coma Superclusters. We see also some very rich superclusters: in the Northern region the supercluster SCL126 (E97) or the Sloan Great Wall (Nichol et al. 2006, and references therein); and in the Southern region the Sculptor Supercluster SCL9 (E97).
In contrast, galaxy systems in the low-density region form an almost continuous network of small galaxy filaments. Faint galaxy systems are seen even within large low-density regions (cosmic voids). Most importantly, the distribution of galaxies in space is almost continuous: faint galaxy bridges join groups and clusters, and thus it is a matter of convention, where to put the border between superclusters and poorer galaxy systems.
Traditionally galaxy systems of various scale have been selected from the cosmic web using quantitative methods, such as the Friends-of-Friends (FoF) method or the Density Field (DF) method. In the first case neighbours of galaxies or clusters are searched using a fixed or variable search radius. This method is very common in searching systems of particles in numerical simulations, where all particles have identical masses. The variant with variable search radius has been successfully employed in the compilation of catalogues of groups of galaxies. For the 2dFGRS such catalogues have been published by Eke et al. (2004) and Tago et al. (T06). The FoF method was also used by Berlind et al. (2006) to find groups in the SDSS survey, by Einasto et al. (E94; E97; E01) in the compilation of the Abell supercluster catalogues, and by Wray et al. (2006) to find superclusters in numerical simulations. This method is simple and straightforward and especially suitable for volume limited samples, such as the sample of Abell clusters and similar samples of simulated dark matter haloes.
The FoF method has the disadvantage that objects of different luminosity (or mass) are treated identically. Galaxy systems contain galaxies of very different luminosity from dwarf galaxies to luminous giant galaxies. Thus, using the FoF method, it is difficult to make a clear distinction between poor and rich galaxy systems, if their number density of galaxies is similar. The second problem of the FoF method is the complication in using neighbours: the method is simple if a constant linking length (neighbour search radius) is used, but the price for this simplicity is the elimination of faint galaxies from the analysis, in order to get a volume limited galaxy sample.
To overcome these difficulties, the DF method can be used. Here luminosities of galaxies are taken into account, both in the search of galaxy systems, as well as in the determination of their properties. The second advantage of the DF method is the possibility to make allowance for completeness and in this way to restore unbiased values of group (and supercluster) total luminosities.
There exists several variants of the density field method to investigate properties of the distribution of galaxies. Basilakos et al. (2001) compiled a catalogue of superclusters using the PSCz flux limited galaxy catalogue, using cell sizes equal to the smoothing radius, 5 h-1 Mpc and 10 h-1 Mpc, for galaxy samples of maximal distance 150 and 240 h-1 Mpc, respectively. The use of a fairly large cell size introduces a bias to the density field, which has been corrected. Another variant of the density smoothing is the use of the Wiener Filtering technique, recently applied to the 2dFGRS to identify superclusters and voids by Erdogdu et al. (2004). The data are covered by a grid whose cells grow in size with increasing distance from the observer. Their "target cell width'' is set to 10 h-1 Mpc at the mean redshift giving a smaller smoothing window for all objects closer and a much larger for galaxies farther away from us.
Our goal is to find superclusters of galaxies, poor and rich, at all distances from the observer until a certain limiting distance. To achieve this goal the selection procedure must be the same for all distances from the observer. For this reason we shall use constant cell size and constant smoothing radius over the whole sample. Of course, random errors of some quantities increase with distance, but we want to suppress systematic bias as much as possible. This allows the identification of smaller systems at all distances from the observer.
The key element in our scheme is the restoration of the expected total luminosity of superclusters as accurately as possible. This goal can be achieved using the weight for galaxies in the calculation of the density field. We have used this approach in estimating total luminosities of superclusters of the Las Campanas Survey and Sloan Early Data Release (E03a, E03b). We shall describe the estimation of expected total luminosities in the next section.
To apply the DF method the luminosity density field is calculated using an appropriate kernel, cell size and smoothing length. An additional parameter which influences the sample, is the threshold density to separate superclusters from poorer galaxy systems. It has the same meaning as the linking length in the FoF method. This is the key parameter which makes a clear distinction between rich and poor galaxy systems, and its influence is illustrated in Fig. 1. Additionally a certain minimal radius (or volume) of objects must be fixed to avoid the inclusion of noise (too small systems) in our sample. Further, a lower limit must be used for the number of galaxies or clusters inside the supercluster to avoid inclusion to our sample very uncertain data. And, finally, certain distance limits must be used for the whole sample to restrict the study to a region covered by observations with a sufficient spatial density of objects. The collection of all these selection parameters defines the final sample of superclusters. We shall discuss the choice of selection parameters below.
In the preliminary phase of the present study we applied both the FoF and DF methods. The FoF method is simple when absolute magnitude (volume) limited galaxy samples are used. In this case one can use a constant linking length over the whole sample to find superclusters. We tried two limiting absolute magnitudes, -19.0 and -19.5, with distance limits 400 and 520 h-1 Mpc, respectively. A lower limit of the number of galaxies in superclusters of 100 was chosen. Superclusters were selected in the Northern and Southern regions; selection limits in coordinates are given in Table 1.
The comparison of properties of superclusters found with the DF and FoF methods demonstrates that the main properties of rich superclusters (positions, diameters, total luminosities etc.) are rather stable and do not depend too much on the method to select them. In most cases it was possible to make a one-to-one identification of superclusters found with different methods or sets of selection parameters. Of course, in some cases a rich supercluster found with one method was split into two or more subclusters when a different set of parameters or method was used. As the real cosmic web is continuous, such differences are expected. It is encouraging that these differences were rather small. A major disadvantage of the FoF method is that a large fraction of the data is not used, since all galaxies fainter than the magnitude limit are ignored. The other disadvantages are the difficulty to include small systems of the Local Supercluster class in the supercluster list, and difficulties in calculating the volume, effective diameter, and mean and maximal luminosity densities of superclusters. Thus the final analysis was carried out with the DF method only.
Due to the selection of galaxies in a fixed apparent magnitude interval the observational window in absolute magnitudes shifts toward higher luminosities when the distance of the galaxies increases. This is the major selection effect in all flux-limited catalogues of galaxies. Due to this selection effect the number of galaxies seen in the visibility window decreases. When calculating estimated total luminosities of galaxies (and groups) we must take this effect into account.
We regard every galaxy as a visible member of a group or cluster
within the visible range of absolute magnitudes, M1 and M2,
corresponding to the observational window of apparent magnitudes at
the distance of the galaxy. To calculate total luminosities of groups
we have to find the estimated total luminosity per one visible galaxy,
taking into account galaxies outside of the visibility window. This
estimated total luminosity is calculated as follows (E03b)
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig2.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img24.gif) |
Figure 2: Weights of galaxies to correct observed luminosities for calculation of expected total luminosities of superclusters. |
| Open with DEXTER | |
The weights used to calculate estimated total luminosities of
superclusters are shown in the Fig. 2. What is important
here is not only the absence of faint members of groups at large
distance, but also the absence of faint groups. In this paper we are
interested in the total luminosities of large systems (superclusters),
thus in calculation of estimated total luminosities we use the set of
Schechter parameters
![]() ,
,
![]() ,
as found by Norberg et al. (2002) for
the whole 2dF galaxy sample. Our calculations show that this set of
Schechter parameters yields total mean luminosity density which is
approximately independent of the distance from the observer, as
expected for a fair sample of the Universe (see Fig. 4 of Paper II).
,
as found by Norberg et al. (2002) for
the whole 2dF galaxy sample. Our calculations show that this set of
Schechter parameters yields total mean luminosity density which is
approximately independent of the distance from the observer, as
expected for a fair sample of the Universe (see Fig. 4 of Paper II).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig3a.eps}\includegraphics[width=8.4cm,clip]{5296_fig3b.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img27.gif) |
Figure 3: Left panel: the maximal diameter of the largest supercluster as a function of the threshold density. Right panel: the number of superclusters found for various threshold density values. |
| Open with DEXTER | |
For the DF method we used a cell size of 1 h-1 Mpc. This is the characteristic
size of compact galaxy systems - groups and clusters. To characterize the
global environment of galaxies a smoothing with characteristic scale 8-10 h-1 Mpc has been applied, using either a Gaussian or an Epanechnikov kernel, see
De Propis et al. (2003), Croton et al. (2005) and Einasto et al. (2005b, hereafter E05b). In the present analysis we used the
Gaussian smoothing only to calculate the high-resolution density field with
rms scale 0.8 h-1 Mpc. To avoid excessive smoothing with large wings (which
increase the computation time more than tenfold) we calculated the
low-resolution field with an Epanechnikov kernel
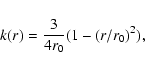 |
(4) |
We have to fix the minimal volume (or radius) of systems to be
considered as superclusters. This choice is important in order to have a difference between compact galaxy systems, such as groups and
clusters, and more extended systems - i.e., superclusters. We take into
account the fact that all compact systems transform to extended
objects after smoothing. In our previous analysis (E03a and E03b) we
used Gaussian smoothing with rms scale 10 h-1 Mpc, and the limiting
radius of the smallest system to be considered as a supercluster is 5.04 h-1 Mpc; this radius corresponds to a system of volume 535 (h-1 Mpc)3.
When using an Epanechnikov kernel with radius ![]() 8 h-1 Mpc we can
use a smaller limiting radius. Taking these considerations into
account we used in our preliminary study two values of the limiting volume, 100 and 200 (h-1 Mpc)3, the corresponding limiting radii are 2.88 and 3.63 h-1 Mpc, respectively.
8 h-1 Mpc we can
use a smaller limiting radius. Taking these considerations into
account we used in our preliminary study two values of the limiting volume, 100 and 200 (h-1 Mpc)3, the corresponding limiting radii are 2.88 and 3.63 h-1 Mpc, respectively.
The final step in the selection of superclusters is the proper
choice of the threshold density D0 to separate high and
low-density galaxy systems. Following E03a we compiled supercluster
catalogues in a wide range of threshold densities from 1 to 7 in
units of the mean luminosity density of the sample. For each
threshold density value we found a list of superclusters, and
calculated the number of superclusters,
![]() ,
and the maximal
diameter (the diagonal of the box containing the supercluster) of
the largest system,
,
and the maximal
diameter (the diagonal of the box containing the supercluster) of
the largest system,
![]() .
The results of these calculations are
presented in Fig. 3.
.
The results of these calculations are
presented in Fig. 3.
We see that with increasing threshold density the maximal diameter of superclusters decreases. At a low threshold density the largest systems span the whole observational volume. It is clear that these large systems consist of many percolating superclusters. Since a large fraction of superclusters is merged in these systems, the number of superclusters in our list is small, and increases with increasing threshold density as more systems are considered as independent superclusters. At a very high threshold density only the most dense parts of the density field are considered as superclusters, thus their diameters and number decrease with increasing threshold. The optimal choice is in the medium range of threshold density, which yields the size of largest superclusters about 100-150 h-1 Mpc, as known from the study of nearby rich superclusters (see E94; E97; and E01).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig4a.eps}\includegraphics[width=8.4cm,clip]{5296_fig4b.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img31.gif) |
Figure 4: Left panel: the number of galaxies in superclusters at various distance from the observer. Right panel: the multiplicity of superclusters (defined as the number of DF-clusters) as a function of distance from the observer. |
| Open with DEXTER | |
For all superclusters found with different selection parameters we calculated geometrical and physical parameters listed below in Sect. 5. Comparison of supercluster properties for various selection parameters gave us additional information to make the final choice of the selection parameters.
The richness of Abell superclusters was characterised by the number of Abell clusters in them (E94; E97; E01). Another possibility to characterise the richness is to use of the number of galaxies or groups of galaxies. These numbers are, however, strongly affected by selection effects. To get an idea of selection effects we show in Fig. 4 the number of galaxies in the superclusters. This number was found by searching for galaxies which lie in the volume above the threshold density level. As we see, the number decreases exponentially with distance. This effect is expected, since galaxies in the 2dFGRS sample are flux-limited, and at larger distances faint galaxies fall outside the observational window. A similar dependence is observed for groups of galaxies of the T06 sample for the same reason: faint distant groups cannot be detected.
This example shows that we cannot use the number of galaxies or groups
as the richness criterion of superclusters. Instead of galaxies or
groups we can use DF-clusters to characterize the richness of
superclusters. To find DF-clusters we used the low-resolution density
field, since it averages over the cluster environment, thus giving
higher weight to clusters which are located in a high-density
environment. In practical terms, all density peaks of the
low-resolution density field were located, having a peak density a bit
higher than the threshold density used in the supercluster search. We
used minimal peak density 5.0 in units of the mean density. The
DF-cluster is characterised by its peak density and its integrated
peak density found by summing luminosity densities of all cells around
the peak together with the central cell (all-together 27 cells).
Additionally we searched for galaxies and groups around the central
peak within relative distance limits ![]() 8 h-1 Mpc from the central
peak. The smoothed density field integrates luminosities of galaxies
inside the whole sphere of radius equal to the smoothing radius, the
volume of the sphere is
8 h-1 Mpc from the central
peak. The smoothed density field integrates luminosities of galaxies
inside the whole sphere of radius equal to the smoothing radius, the
volume of the sphere is
![]() (h-1 Mpc)3. This sphere
contains in nearby regions 200
(h-1 Mpc)3. This sphere
contains in nearby regions 200![]() 1000 galaxies and in most distant
regions 3
1000 galaxies and in most distant
regions 3![]() 50 galaxies.
50 galaxies.
The analysis shows that poor superclusters contain 1-2 DF-clusters, i.e. they a similar to the Local and Coma superclusters. In rich superclusters the number of DF-clusters is much higher. The distribution of the multiplicity of superclusters is shown in the right panel of Fig. 4. We see that the distribution is practically independent of the distance. At small distances the number of high-multiplicity superclusters is smaller, but this is a volume effect. What is more important, low-multiplicity superclusters are detected at all distances.
To summarise the preliminary analysis we come to the conclusion that for data samples as 2dFGRS (and SDSS) it is better to use the DF method rather than the FoF method. We define superclusters as contiguous non-percolating regions of the low-resolution luminosity density field above a certain threshold, having a volume above a critical volume, and a minimal number of visible galaxies or groups inside the supercluster volume. As in the FoF method, the supercluster sample is determined by numerical values of selection parameters. These parameters correspond to neighbourhood radius, limiting magnitude, and minimal number of objects in the FoF method. In comparison to previous supercluster catalogues the use of DF-method allows us to determine a number of additional parameters for superclusters, which charecterise the asymmetric and filamentary character of them.
![\begin{figure*}
\par\includegraphics[width=8.4cm,clip]{5296_fig5a.eps}\includegraphics[width=8.4cm,clip]{5296_fig5b.eps}\end{figure*}](/articles/aa/full/2007/05/aa5296-06/img35.gif) |
Figure 5:
Left panel shows the differential luminosity function (the
number of galaxies in absolute magnitude bins of
|
| Open with DEXTER | |
The main goal of our preliminary analysis was to find the optimal way to select superclusters and to calculate their properties. So far we have not yet analysed the influence of the smoothing length to supercluster properties, and the optimal way to define the supercluster center. Also we have not investigated possible biases and errors of supercluster parameters. In the present Section we shall discuss these problems by analysing simulated superclusters. Our preliminary analysis of model superclusters based on Millennium Simulation has shown that properties of model superclusters are very close to similar properties of real superclusters. Simulated superclusters are specially useful in the study of selection effects, since in models we have by definition complete data on superclusters, and introducing selection effects similar to real data allows us to compare "observed'' superclusters with "true'' ones. In supercluster definition luminosity density plays a central role. Thus our first question to be answered is: Is the luminosity-density relation, observed in the real Universe, also incorporated in simulations?
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig6a.eps}\includegraphics[width=8.4cm,clip]{5296_fig6b.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img36.gif) |
Figure 6: The length (maximal diameter) and the number of superclusters are shown in the left and right panels, respectively, as a function of the threshold density D0. Different lines show data using smoothing with an Epanechnikov kernel of radius 8, 6 and 4 h-1 Mpc, and Gaussian kernel of scale 0.5 h-1 Mpc. |
| Open with DEXTER | |
The semi-analytic model of galaxy formation used by Croton et al. (2006) does not use explicitly this relation. The
luminosity-density relation is observed already on group/cluster
scales (brighter galaxies are located near the cluster centre). In
order to find how well this relation is incorporated in the
Millennium Run galaxies, we calculated for every simulated galaxy
the local density at the position of the galaxy, using the density
field smoothed with a Gaussian kernel of the rms scale 0.5 h-1 Mpc.
Further we calculated the number of galaxies in various absolute
magnitude intervals separately for different local density
environments. In magnitudes we used a step
![]() ,
and
for density we used constant intervals in the logarithm of the
density with step
,
and
for density we used constant intervals in the logarithm of the
density with step
![]() ,
starting from density
value 0.1 in units of the mean luminosity density.
,
starting from density
value 0.1 in units of the mean luminosity density.
The results of this study are shown in Fig. 5. There are
almost no galaxies in the first density bin (
![]() ). Starting from the second bin each subsequent density bin
contains more brighter galaxies, the number of faint galaxies in
each bin is approximately constant, and the increase of the maximal
luminosity is practically constant, when we move from lower density
bins to higher ones. In other words, the luminosity-density
relation is built in to the galaxy sample, and we can use the sample
to study density sensitive supercluster properties. The integrated
luminosity function for the g and r bands is shown in
the right panel of Fig. 5. Due to very large number of
galaxies in the sample, the functions are very smooth, and only for
the bright end was it necessary to apply a linear interpolation of
the function (in
). Starting from the second bin each subsequent density bin
contains more brighter galaxies, the number of faint galaxies in
each bin is approximately constant, and the increase of the maximal
luminosity is practically constant, when we move from lower density
bins to higher ones. In other words, the luminosity-density
relation is built in to the galaxy sample, and we can use the sample
to study density sensitive supercluster properties. The integrated
luminosity function for the g and r bands is shown in
the right panel of Fig. 5. Due to very large number of
galaxies in the sample, the functions are very smooth, and only for
the bright end was it necessary to apply a linear interpolation of
the function (in
![]() representation), also shown in
Fig. 5. This luminosity function was used instead of the
Schechter law in calculating weights for galaxies according to Eq. (2).
representation), also shown in
Fig. 5. This luminosity function was used instead of the
Schechter law in calculating weights for galaxies according to Eq. (2).
So far in supercluster search with the DF method smoothing length
values (or cell sizes) in the range of 5 ![]() 10 h-1 Mpc have been
used (Basilakos et al. 2001; Erdogdu et al. 2004;
E03a; E03b). In order to have a proper choice of the smoothing length
we constructed supercluster lists for simulated galaxy samples using
the DF method with Epanechnikov kernels of radii 4, 6, and 8 h-1 Mpc.
Respective models are marked in Table 2 as Mill.A4, Mill.A6
and Mill.A8 (A for all galaxies used in calculation of the density
field). For comparison we applied a similar system search also for the
high-resolution density field found with a Gaussian kernel and rms scale 0.5 h-1 Mpc. In the latter case we used a minimal volume of systems 20
10 h-1 Mpc have been
used (Basilakos et al. 2001; Erdogdu et al. 2004;
E03a; E03b). In order to have a proper choice of the smoothing length
we constructed supercluster lists for simulated galaxy samples using
the DF method with Epanechnikov kernels of radii 4, 6, and 8 h-1 Mpc.
Respective models are marked in Table 2 as Mill.A4, Mill.A6
and Mill.A8 (A for all galaxies used in calculation of the density
field). For comparison we applied a similar system search also for the
high-resolution density field found with a Gaussian kernel and rms scale 0.5 h-1 Mpc. In the latter case we used a minimal volume of systems 20
![]() .
As noted above, this smoothing length corresponds to the scale of compact galaxy systems, such as groups and
clusters of galaxies. Only very large systems found with this
smoothing length are similar to conventional superclusters.
.
As noted above, this smoothing length corresponds to the scale of compact galaxy systems, such as groups and
clusters of galaxies. Only very large systems found with this
smoothing length are similar to conventional superclusters.
Superclusters were selected in a wide range of threshold densities
from 1 to 9 in units of the mean luminosity density. The length
(maximal diameter) and the number of systems found are shown in
Fig. 6 for all four subsamples. We have chosen threshold
density values given in Table 2, which correspond to the
diameter of the largest supercluster (![]() 120 h-1 Mpc). If one
wants to get a higher number of superclusters, then a lower threshold
density is to be used, but in this case the size of the largest system
exceeds 200 h-1 Mpc.
120 h-1 Mpc). If one
wants to get a higher number of superclusters, then a lower threshold
density is to be used, but in this case the size of the largest system
exceeds 200 h-1 Mpc.
In addition to the diameter of the box around the supercluster we have
found also the diameter of the sphere equal to the volume of the
superclusters, by counting cells of size 1 h-1 Mpc inside the contour surrounded by threshold density level. We call this
the effective diameter. Mean values of the effective diameters of
superclusters of all samples are shown in Fig. 7 for various
threshold density levels. We see that, in spite of the presence of
very large percolating superclusters at low threshold density levels,
the mean diameters are surprisingly constant. For our accepted
threshold levels they lie between
![]() h-1 Mpc, for
superclusters of samples Mill.A4
h-1 Mpc, for
superclusters of samples Mill.A4 ![]() Mill.A8. The mean diameter of
galaxy systems of the sample Mill.A1 is much lower since a lower
limiting volume was used in the compilation of this sample, as
expected for groups and clusters.
Mill.A8. The mean diameter of
galaxy systems of the sample Mill.A1 is much lower since a lower
limiting volume was used in the compilation of this sample, as
expected for groups and clusters.
We compared geometrical and physical properties of individual superclusters of subsamples Mill.A8, Mill.A6 and Mill.A4. This comparison shows a good correlation of properties of large superclusters found for different smoothing lengths. The basic difference lies in small superclusters. If we decrease the smoothing length, then many superclusters are split into smaller subunits. These subunits are connected by low-luminosity bridges, which fall below the density threshold, and a galaxy system is considered as consisting of two separate systems.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig7.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img43.gif) |
Figure 7: The mean effective diameter of superclusters as a function of the threshold density D0. Lines and symbols are for samples as in Fig. 6. |
| Open with DEXTER | |
When one uses flux-limited galaxy samples, then at larger distance from the observer fainter galaxies are not visible and bridges between high-density knots cannot be detected. In volume limited samples fainter galaxies are excluded at all distances from the observer. Thus in real galaxy samples faint galaxy bridges disappear at large distance (or everywhere for volume-limited samples). To avoid a too noisy density field it is reasonable to use a larger smoothing length. On the other hand, if a too large smoothing length is used, then it is difficult to find small systems of the Local Supercluster class. Thus we come to the conclusion that the optimal smoothing length is 8 h-1 Mpc.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig8a.eps}\includegraphics[width=8.4cm,clip]{5296_fig8b.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img44.gif) |
Figure 8: The left panel shows the fraction of galaxies in superclusters of 2dF full and volume limited samples, Mill.F8a and Mill.V8a, as a fraction of galaxies of the total sample Mill.A8, for various distance from the observer. The right panel shows relative errors of total luminosities of superclusters of the samples Mill.F8a and Mill.F8b with respect to the luminosities of superclusters of the total sample Mill.A8. |
| Open with DEXTER | |
The major issue in using flux-limited galaxy samples as the 2dFGRS is the magnitude selection effect. Due to a fixed observational window in apparent magnitudes the range of absolute magnitudes of galaxies (and groups selected from the galaxy sample) changes with the distance. At the far side of the observational sample only very bright galaxies fall into the visibility window of the sample. Thus the number-density of galaxies drops with increasing distance dramatically. This makes it difficult to estimate the true number of galaxies and groups in superclusters.
To simulate the influence of the observational selection we
put the observer at the lower left corner of the sample at
coordinates
x = y = z = 0, calculated distances of every galaxy
from the observer, found apparent magnitudes using k-corrections,
and selected galaxies in the observational window of the 2dFGRS
m1
= 14.5,
m2 = 19.35. This subsample is designated as Mill.F8. To
simulate volume-limited galaxy samples we applied a further limit,
-19.5, in absolute magnitudes in photometric system g (close
to system ![]() used in the 2dF Survey); this subsample is
designated Mill.V8 (in the last samples a smoothing radius 8 h-1 Mpc was applied).
used in the 2dF Survey); this subsample is
designated Mill.V8 (in the last samples a smoothing radius 8 h-1 Mpc was applied).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig9a.eps}\includegraphics[width=8.4cm,clip]{5296_fig9b.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img45.gif) |
Figure 9: Left panel: the number of galaxies in superclusters of samples Mill.A8 and Mill.F8a as a function of distance from the observer. The right panel shows luminosities of superclusters of the sample Mill.F8b as a function of distance (crosses). Open gray circles show luminosities of superclusters of the total sample Mill.A8 which have no counterpart in the sample Mill.F8b (missing superclusters). |
| Open with DEXTER | |
We found Mill.F8 superclusters and derived their properties for two cases. In the first case we used the density field of all galaxies Mill.A8, but supercluster luminosities were calculated using galaxy samples Mill.F8 and Mill.V8; we designate these subsamples as Mill.F8a and Mill.V8a. In this case lists of superclusters of samples Mill.A8 and Mill.F8a are identical by definition, and the comparison of luminosities of superclusters of samples Mill.A8 and Mill.F8a gives information on the internal accuracy of supercluster luminosities (accuracy of the restoration of true luminosities using incomplete data and weights of galaxies). In the second case both the density field and supercluster data were found using galaxies of the simulated 2dF samples Mill.F8 and Mill.V8; we designate these subsamples as Mill.F8b and Mill.V8b. This version takes into account the fact that the luminosity density field is determined from incomplete data; this version yields information on possible external errors of supercluster data.
The left panel of Fig. 8 shows the fraction of the number of galaxies in superclusters of subsamples Mill.F8a and Mill.V8a with respect to the respective number in the sample Mill.A8. We see that at small distances this fraction for the subsample Mill.F8a is close to unity, i.e. almost all galaxies are present also in the flux-limited subsample. With increasing distance the fraction gradually decreases. The volume-limited subsample Mill.V8a has at large distances from the observer a behaviour similar to the full flux-limited subsample, but on distances less than 400 h-1 Mpc the fraction remains constant at a level about 0.2. Some data-points above the main ridge at large distance are due to misidentification of superclusters in our automated procedure.
In the right panel of Fig. 8 we plot the relative error of the
total luminosity of superclusters as a function of the distance from the
observer. Black symbols show internal errors: the difference of
luminosities of superclusters of subsamples Mill.F8a and Mill.A8 in units of
the luminosity of superclusters of the sample Mill.A8. Gray symbols show
external errors: the difference of luminosities of superclusters of
subsamples Mill.F8b and Mill.A8 in units of the luminosity of superclusters
of the sample Mill.A8. We see that at large distance from the observer
(d> 500 h-1 Mpc) both internal and external errors become large, since the
number of galaxies in superclusters becomes too small. At intermediate
distances
![]() h-1 Mpc internal errors are surprisingly small,
and there are practically no systematic errors. External errors are larger,
and have a negative tail, i.e. luminosities of superclusters determined from
incomplete (flux-limited) data are systematically lower than those calculated
using full data. Partly this difference is due to the fact that some
superclusters of the sample Mill.A8 are split into smaller systems in
the subsample Mill.F8b.
h-1 Mpc internal errors are surprisingly small,
and there are practically no systematic errors. External errors are larger,
and have a negative tail, i.e. luminosities of superclusters determined from
incomplete (flux-limited) data are systematically lower than those calculated
using full data. Partly this difference is due to the fact that some
superclusters of the sample Mill.A8 are split into smaller systems in
the subsample Mill.F8b.
Figure 9 (left panel) shows the number of galaxies in superclusters of samples Mill.A8 and Mill.F8a as a function of distance. We see that the true number of galaxies in superclusters exceeds 200 with only a few exceptions (remember that the galaxy sample of the Millennium Simulation is complete for luminosities exceeding an absolute magnitude -17.4 in the r-band). In superclusters identified using flux-limited galaxy samples the number of galaxies decreases with distance. This decrease follows the same law as the fraction shown in Fig. 8 for simulated 2dFGRS superclusters.
The comparison of lists of superclusters of samples Mill.A8 and Mill.F8b shows that about 200 superclusters of the full sample Mill.A8 have no counterparts in the sample Mill.F8b, based on the flux-limited sample of galaxies. In other words, these superclusters are too weak to meet our selection criterion. We show the distribution of luminosities of missing superclusters as a function of distance in the right panel of Fig. 9 by gray symbols. For comparison luminosities of all detected superclusters are also shown. We see that all missing superclusters have low luminosities. In other words, the luminosity function of superclusters found on the basis of flux-limited galaxy samples is slightly biased. To conclude this analysis we can say that although at large distance only a few per cent of all galaxies are seen in flux-limited samples, the restoration of supercluster total luminosities is surprisingly accurate.
In Abell supercluster catalogues the center of a supercluster was derived as the unweighted mean value of coordinates of member clusters (E97). This definition has the disadvantage that because of multi-branching asymmetrical shapes of typical superclusters the center defined in this way may lie outside the volume occupied by member galaxies of the supercluster. Thus the definition of the supercluster center is a problem.
It would be natural to identify the centers of superclusters with centres of deepest potential wells inside the supercluster. Rich superclusters have several concentration centres (DF-clusters); the depth of the respective potential wells is different, and only one has the deepest level. In numerical simulations it is relatively easy to identify the dynamical center of the supercluster. The center identification is not so easy in real observational samples. To calculate the potential field the respective density field must be given in a rather large volume. This is difficult in the real Universe, since even the largest modern deep redshift surveys cover only relatively thin slices.
However, it is very easy to identify in real galaxy samples high-density knots of the density field - DF-clusters, and to identify the center of the supercluster with the position of the densest DF-cluster. The problem is: how well do the positions of highest density knots correlate with positions of deepest depressions in the potential field? To study this problem, we calculated the potential field of the Millennium Survey by Fourier-transforming the high-resolution density field (model Mill.A1). Both fields were calculated on a 5123 grid. To have an impression of the fields they were transformed to FITS format and were scrutinized using the DS9 viewer (Smithsonian Astrophysical Observatory Astronomical Data Visualization Application, available for all major operating systems). The comparison of lists of density peaks and potential field depressions shows that practically all high-density knots in the density field can be recognized as depressions in the potential field.
To obtain a more quantitative relationship between maxima (and minima in case of the potential) of these fields we compared catalogues of maxima of the high-resolution density field and minima of the potential field. Also, in our test catalogues of superclusters extrema of both fields were marked. This comparison shows that the number of peaks of both fields in superclusters is close (see Fig. 10), and that in the majority of cases there exists an one-to-one correspondence between peaks of both fields. In the majority of cases the highest density peak corresponds to the deepest potential well. However, in about 10% superclusters the deepest potential well coincides not with the highest density peak, but with one the following peaks. This occurs mostly in cases where the surrounding potential field has a considerable slope (even within the supercluster), so that absolute values of the depth of the potential well do not always represent the strength of the density peak. Our conclusion is that in these cases the highest density peak suits even better as the center of the supercluster.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig10.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img47.gif) |
Figure 10: The number of peaks of the density and potential field for superclusters of the sample Mill.A8. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{5296_fig11a_c.eps}\includegraphics[width=8.4cm,clip]{5296_fig11b_c.eps}\end{figure}](/articles/aa/full/2007/05/aa5296-06/img48.gif) |
Figure 11: Luminosity density distribution in the central area of the 2dF Northern region around the supercluster SCL126 from the E01 list. Left panel shows data in declination interval -1 to 2 degrees, right panel in interval -4 to -1 degrees. As in Fig. 1 coordinates are rotated so that the center of the Northern region is directed toward the y-axis. |
| Open with DEXTER | |
Our supercluster catalogue is determined with the following set of selection parameters. The luminosity density field is calculated using an Epanechnikov kernel with radius 8 h-1 Mpc, and a rectangular grid of cell size 1 h-1 Mpc. We apply a threshold density 4.6 for our final supercluster catalogue. Using this threshold density a few superclusters still have diagonal sizes exceeding 120 h-1 Mpc; these superclusters split into subsystems when a larger threshold density is used. We use a limiting volume of 100 (h-1 Mpc)3. Using this limit we include practically all galaxy systems which exceed the chosen threshold limit into our supercluster list, and exclude only systems which have a very small fraction of their volume above the threshold. At this level noise due to random errors of corrected galaxy luminosities becomes large. Remember that the use of smoothing with 8 h-1 Mpc radius means that all galaxies and groups within this radius are used in the calculation of the density field; thus even the smallest superclusters represent galaxy samples located in a much larger volume than the volume above the density threshold.
To minimize the size of the density field box we treat
Northern and Southern regions of 2dF separately. The coordinate
system was rotated along the vertical axis so that the sample starts
at x-axis:
| (5) |
| (6) |
The lists of all 2dF groups and single galaxies were searched to find members of superclusters. The number of galaxies in superclusters as a function of the distance from the observer is shown in Fig. 4. As expected, this number decreases with distance. In very poor and distant superclusters the number of galaxies detected may fall below 3. These very poor superclusters have been excluded from our supercluster list. Also, as our analysis of simulated superclusters has shown, some parameters of very distant superclusters have rather large statistical uncertainties. For this reason we have divided our supercluster lists into two parts: the main sample (denoted A) contains superclusters up to distance 520 h-1 Mpc, and the supplementary sample (denoted B) has more distant superclusters.
We note that only about 1/3 of all galaxies of the 2dF survey are members of superclusters. The remaining galaxies and groups also belong to galaxy systems, but these systems are weaker and form in the density field enhancements with peak density less than our adopted threshold value 4.6.
We also compiled lists of compact high-density peaks of the density field - DF-clusters, using the low-resolution density field and threshold density 5.0 (in units of the mean density). DF-clusters are some equivalent to rich Abell-type clusters. Since luminosities were corrected to take into account galaxies outside the visibility window, DF-clusters form a volume-limited sample. DF-clusters are useful in the further identification of rich clusters of galaxies of the Abell cluster class. The right panel of Fig. 4 shows the distance dependence of the number of DF-clusters in superclusters.
We calculated the luminous mass around the center of DF-cluster in a box containing the parent cell and all surrounding cells (altogether 27 cells). The most luminous group (from the list by T06) in this box was considered as the main group/cluster of the supercluster, and the brightest galaxy of the main cluster was taken as the main galaxy of the supercluster. The center of the supercluster was identified with the center of the main galaxy. Some poor superclusters do not contain peaks above the threshold 5.0 used in the search of DF-clusters. In these cases the most luminous group was considered as the center of the supercluster.
Figure 4 of Paper II shows the distance dependence of the mean luminosity density of the whole 2dFGRS sample, and of the mean number density of superclusters. There are several peaks due to very rich superclusters, but in general the luminosity density is approximately constant. The 2dFGRS samples are wedges and are rather thin at small distances from the observer. In such thin regions identification of superclusters is problematic and hence the spatial density of superclusters at small distances is rather low. This is the only known distance-dependent selection effect in the supercluster sample.
To have an idea of the spatial distribution of luminous matter we can have a look at respective density fields den-Ngr-570-86-ep8.fits and den-Sgr-516-312-ep8.fits on our web-page. These fields can be seen in x,y,z coordinates using the viewer DS9. Cross-sections through one of the most luminous superclusters (SCL126 of the Northern sample) are presented in Fig. 11. This figure and density field plots in Fig. 1 show the multi-nucleus character of most superclusters. Note also the asymmetry of the distribution of galaxies in superclusters.
Table 3: The list of rich 2dF Northern superclusters.
The final catalogue of 2dFGRS superclusters consists of four lists, two for each Galaxy hemisphere, the main lists A for superclusters up to distance 520 h-1 Mpc and supplementary lists B for more distant systems. These lists are given in the electronic supplement of the paper. The lists are ordered according to increasing RA, separately for the Northern and Southern hemispheres, but a common id-numeration for lists A and B. The lists have the following entries
Table 4: The list of rich 2dF Southern superclusters.
In this paper we have used the 2dF Galaxy Redshift Survey to compose a new catalogue of superclusters of galaxies. Our main conclusions are the following.
Acknowledgements
We are pleased to thank the 2dF GRS Team for the publicly available final data release. The Millennium Simulation used in this paper was carried out by the Virgo Supercomputing Consortium at the Computing Centre of the Max-Planck Society in Garching. We thank the referee John Huchra for constructive suggestions. This research has made use of SAOImage DS9, developed by Smithsonian Astrophysical Observatory. The semi-analytic galaxy catalogue is publicly available at http://www.mpa-garching.mpg.de/galform/agnpaper. The present study was supported by Estonian Science Foundation grants Nos. 4695, 5347 and 6104 and 6106, and Estonian Ministry for Education and Science support by grant TO 0060058S98. This work has also been supported by the University of Valencia through a visiting professorship for Enn Saar and by the Spanish MCyT project AYA2003-08739-C02-01. J.E. thanks Astrophysikalisches Institut Potsdam (using DFG-grant 436 EST 17/2/05) for hospitality where part of this study was performed. D.T. was supported by the US Department of Energy under contract No. DE-AC02-76CH03000. A.K. acknowledges funding through the Emmy Noether Programme by the DFG (KN 755/1).