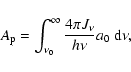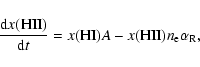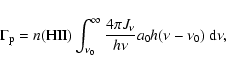A&A 452, 907-920 (2006)
DOI: 10.1051/0004-6361:20053401
E.-J. Rijkhorst1 - T. Plewa2,3 - A. Dubey2,3 - G. Mellema4,1
1 - Sterrewacht Leiden, PO Box 9513, 2300 RA, Leiden, The Netherlands
2 - Center for Astrophysical Thermonuclear Flashes, University of Chicago, 5640 South Ellis Avenue, Chicago, IL 60637, USA
3 - Department of Astronomy & Astrophysics, University of Chicago, 5640 South Ellis Avenue, Chicago, IL 60637, USA
4 - ASTRON, PO Box 2, 7990 AA Dwingeloo, The Netherlands
Received 11 May 2005 / Accepted 7 March 2006
Abstract
We have developed a three-dimensional radiative transfer method designed specifically for use with parallel adaptive mesh refinement hydrodynamics codes.
This new algorithm, which we call hybrid characteristics, introduces a novel form of ray tracing that can neither be classified as long, nor as short characteristics, but which applies the underlying principles, i.e. efficient execution through interpolation and parallelizability, of both.
Primary applications of the hybrid characteristics method are radiation hydrodynamics problems that take into account the effects of photoionization and heating due to point sources of radiation. The method is implemented in the hydrodynamics package FLASH. The ionization, heating, and cooling processes are modelled using the DORIC ionization package. Upon comparison with the long characteristics method, we find that our method calculates the column density with a similarly high accuracy and produces sharp and well defined shadows. We show the quality of the new algorithm in an application to the photoevaporation of multiple over-dense clumps.
We present several test problems demonstrating the feasibility of our method for performing high resolution three-dimensional radiation hydrodynamics calculations that span a large range of scales. Initial performance tests show that the ray tracing part of our method takes less time to execute than other parts of the calculation (e.g. hydrodynamics and adaptive mesh refinement), and that a high degree of efficiency is obtained in parallel execution. Although the hybrid characteristics method is developed for problems involving photoionization due to point sources, and in its current implementation ignores the effects of diffuse radiation and scattering, the algorithm can be easily adapted to the case of more general radiation fields.
Key words: radiative transfer - hydrodynamics - ISM: HII regions - planetary nebulae: general
Current multi-dimensional parallel adaptive mesh refinement (AMR, see Berger & Colella 1989; Berger & Oliger 1984) hydrodynamics codes, include more and more physical processes like (self-) gravity, nuclear burning, and composition dependent equations of state. Furthermore, a wealth of different solvers for relativistic or magneto-hydrodynamics, have become available. These codes are in general implemented as a modular framework, facilitating a rather straightforward inclusion of new physics modules, and are often distributed freely for scientific use (O'Shea et al. 2004; Fryxell et al. 2000; Norman 2000).
Since astrophysical applications are many times dominated by radiative processes, it is highly desirable that radiative transfer in some form is included in these codes. Efforts to solve the full equations of radiative transfer (using the Eddington tensor formalism in combination with short characteristics, see Stone et al. 1992), or in the flux-limited diffusion approximation (Whitehouse & Bate 2004; Turner & Stone 2001), together with the hydrodynamics have been made, but it remains a complex task to create a parallel algorithm which combines radiative transfer and hydrodynamics for multi-dimensional calculations that runs efficiently on todays multi-processor supercomputers (e.g. Hayes & Norman 2003).
For many astrophysical applications however, it is not necessary to solve the full set of radiative transfer equations; for these specific cases it is sufficient to just determine the optical depth due to absorption along a line of sight from the source to a certain location in the computational domain. Note however that such an approach ignores the effects the diffuse field and scattering may have.
For the purpose of our application of ionization calculations, the optical depth is used to determine the photoionization and heating rates. When this is combined with detailed calculations of radiative cooling, many applications come within reach, such as the evolution of planetary nebulae (Frank & Mellema 1994), photoevaporation of cosmological mini-haloes (Shapiro et al. 2004), photoevaporation of cometary knots (Lim & Mellema 2003), the evolution of proplyds (e.g. Richling & Yorke 2000), or even simplified scenarios of explosions of massive stars (Janka & Mueller 1996), to name just a few.
In creating a method that combines radiative transfer and hydrodynamics, one in general starts with an existing hydrodynamics code and adds the necessary radiation processes to it (e.g. Mellema et al. 1998; Heinemann et al. 2005; Whitehouse & Bate 2004; Liebendörfer et al. 2005; Turner & Stone 2001). In this paper we describe the addition of a new radiative transfer algorithm, which we call hybrid characteristics, to the parallel 3D AMR hydrodynamics package FLASH (Fryxell et al. 2000).
Most of the radiative transfer methods that were successfully combined with extant hydrodynamics codes apply some form of ray tracing to find the optical depth at each location in the computational domain. Apart from ray tracing one could also use statistical methods to find the solution to the radiative transfer equations (e.g. Maselli et al. 2003). Yet another approach could be the use of Fourier transforms (Cen 2002), or unstructured grids (Ritzerveld et al. 2004), to determine the radiation field.
For a one-dimensional, non-AMR, serial code, ray tracing becomes a rather straightforward procedure which requires little second thought. Equivalently, the case of a plane parallel radiation field on a Cartesian grid, or a single point-source at the centre of a spherically symmetric grid, for which all rays run parallel to a coordinate axis, can be handled quite easily. Although this type of implementation can readily be used to study a number of interesting astrophysical phenomena, it is still highly desirable to have a code that can treat the more general case of a point source of ionizing radiation on a 3D Cartesian domain. Such more general methods were for example implemented by Lim & Mellema (2003); Raga et al. (2000); Richling & Yorke (2000), but none of these methods was explicitly parallelized for distributed memory machines though.
The aim of this work is to create a characteristics-based radiative transfer method that can handle multiple sources of ionizing radiation in AMR enabled simulations to be run on distributed memory parallel machines. For this, a radical rethink of the concept of ray tracing is necessary, since, for this type of parallel AMR codes, the computational domain is not only sub-divided into a hierarchy of patches, but is also distributed over a number of processors. The first choice one therefore has to make is which flavour of ray tracing one wants to apply: either long or short characteristics. Since these two methods have rather different properties when it comes to efficiency and parallelizability, this choice will determine the success of the final algorithm.
We are aware of a number of other methods that use some form of adaptivity to solve the radiative transfer equations: Abel & Wandelt (2002) designed a method where the ray itself is adaptively split into sub-rays, but the underlying grid is still regular. Steinacker et al. (2002) employed second order finite differencing of the full radiative transfer equations on an oct-tree AMR grid, and, more recently, Juvela & Padoan (2005) implemented a ray tracing method for cell-based AMR. Jessee et al. (1998) presented a radiative transfer method for patch-based AMR that uses the discrete ordinates approach. However, none of these methods resulted in parallel algorithms used in applications in which radiation is coupled to hydrodynamics.
Efforts to create a parallel radiation hydrodynamics code were presented by e.g. Hayes & Norman (2003); Nakamoto et al. (2001), and, more recently, a three-dimensional method by Heinemann et al. (2005), who developed a ray tracing algorithm for decomposed domains. However, none of these two methods uses AMR.
Our presentation begins with Sect. 2 in which we describe our new method. This method can not be classified as either short or long characteristics, but does have the desired properties, namely high parallel and computational efficiency, of its two predecessors. We also compare our method to two recent ones which share similar features with ours. Supplemental physics components required by our primary target application (gas ionization, heating, and cooling) are presented in Sect. 3, where we give a brief description of the DORIC routines (Mellema & Lundqvist 2002, and references therein). In Sect. 4 we first compare the accuracy with which our method calculates column densities to results obtained with a standard long characteristics approach. Then we present a pure radiation transport problem aimed at testing the accuracy of the ionization state calculations and shadow casting. This is followed by a coupled radiation hydrodynamics calculation of a photoevaporation flow. Section 5 presents some initial performance results. Discussion of possible extensions and future applications for our method together with the conclusions are given in Sect. 6.
When calculating the effects of ionizing radiation due to a point source, the radiation field is often dominated by this source.
If one ignores the diffuse component of the radiation field due to recombination radiation, the radiative transfer equations assume a particularly simple form, since we can take the total emission coefficient (and thereby the source function) to be equal to zero.
Furthermore, when we also ignore the effects of scattering, the solution to the radiative transfer equations for the specific intensity I at location r is given by
| (1) |
Once the optical depth is known at every location in the computational domain, one can use it to find the ionization, heating, and cooling rates, and calculate the ionization state and temperature of the gas. Since, for finite-volume hydrodynamics codes, the computational domain is discretized into cells, the optical depth, or, equivalently, the column density for a certain cell, is found by adding the contributions from all cells that lie between the source and the destination cell under consideration. This can be achieved by casting a ray, or long characteristic, from the source to the cell, accumulating contributions to the total column density along the way. In case of an AMR hierarchy, the algorithm first needs to identify the patches and cells contained within the patches that are traversed by the ray, and then calculate their local contributions to the total column density.
Although the method of long characteristics is very accurate, it is also rather inefficient, since, the closer a cell is to the source, the more rays cut through (approximately) the same part of the cell, introducing a lot of redundant calculations (see Fig. 1a). A way to eliminate this redundancy is to use the method of short characteristics. Here, the total column density for a certain cell is calculated by interpolating upwind values of column density calculated in a previous step, thereby creating some diffusion, but removing the redundant calculations inherent in the long characteristics method (Fig. 1b). For this to work, the appropriate information from upwind cells needs to be available at all times, which means one needs to sweep the numerical grid outwards from the source. This necessity of having to traverse the grid in a certain order makes this method intrinsically serial, since values of column density in cells now depend on one another. The long characteristics method does not suffer from this restriction, because here contributions to the total column density from cells cut by a ray do not depend on column densities in other cells. Therefore, the long characteristics method is fully parallelizable, since calculations of contributions to the column density along each ray can be performed independently. For our method we combine the desirable qualities of both these approaches; the idea of interpolation is adopted from the short characteristics method, while parallelism is obtained following principles of the long characteristics method.
In what follows, we start with a general description of the algorithm used to trace rays on AMR hierarchies. We explain how the long characteristics method is exploited to make this a parallel algorithm, and where the interpolation comes in to increase the efficiency of the calculation.
Although our algorithm is designed for three dimensions, many features of its implementation can be explained using two-dimensional analogues. Whenever the generalization from two to three dimension is non-trivial, we will supply the full, three-dimensional, description. Since the algorithm is naturally subdivided into a number of steps, we will expand on these separately.
| |
Figure 1: Comparing the long a) and short b) characteristics method. For the long characteristics method, the closer one gets to the source, the more rays pass through (approximately) the same part of a cell, resulting in a large number of redundant calculations. The short characteristics method does not suffer from this, since here column densities are interpolated from cells that have been dealt with previously, so only the contributions to the column density of the short ray sections that pass from cell to cell need to be computed. |
| Open with DEXTER | |
Consider a computational domain that is distributed over ![]() processors (for a two-dimensional example, see Fig. 2).
Rays are traced over these different sub-domains and must therefore be split up into independent ray sections.
Naturally, these sections are in the first place defined by the boundaries of each processor's sub-domain, and in the second place by the boundaries of the patches contained within that sub-domain.
processors (for a two-dimensional example, see Fig. 2).
Rays are traced over these different sub-domains and must therefore be split up into independent ray sections.
Naturally, these sections are in the first place defined by the boundaries of each processor's sub-domain, and in the second place by the boundaries of the patches contained within that sub-domain.
| |
Figure 2:
Two-dimensional example of an AMR hierarchy distributed over two different processors.
Here, each patch contains 4 |
| Open with DEXTER | |
So first each processor calculates for all the patches it owns the local column densities ![]() .
These local contributions are found by tracing ray sections that originate at the patch faces that are located closest to the source, and that terminate at the centres of the cells (see Fig. 3).
Since finding these contributions is a local process, this part of the algorithm is fully parallel, and can be implemented using either the short or long characteristics method.
Details on how the ray tracing for individual patches is implemented are given in Sect. 2.2.
Note however that, before each processor can calculate its
.
These local contributions are found by tracing ray sections that originate at the patch faces that are located closest to the source, and that terminate at the centres of the cells (see Fig. 3).
Since finding these contributions is a local process, this part of the algorithm is fully parallel, and can be implemented using either the short or long characteristics method.
Details on how the ray tracing for individual patches is implemented are given in Sect. 2.2.
Note however that, before each processor can calculate its ![]() ,
it needs to know the physical location of the source, so this information is made available first.
,
it needs to know the physical location of the source, so this information is made available first.
Since in general rays traverse more than one processor domain, exchange of information has to take place at some point in the algorithm. After this communication step has finished, each processor should have available all contributions of column density to the rays that terminate in its domain. By interpolating and accumulating all these contributions for all rays, one ultimately obtains the total column density for each cell (see Sect. 2.3.1 for a more elaborate description of the communication patterns involved). Details on the procedure applied to find the patches cut by a ray, and the way in which their contributions to the total column density are subsequently calculated, are given in Sects. 2.3.2 and 2.3.3, respectively.
| |
Figure 3: Two-dimensional example of ray sections for a single patch. Local contributions to the column density are indicated by ray sections that terminate at cell centres a), whereas contributions that are to be communicated between processors, and are subsequently used in an interpolation step, terminate at cell corners b). The source lies outside of the patch in the direction of the lower left corner. |
| Open with DEXTER | |
In this section we will explain how the contribution to the total column density along a local ray section in a single patch can be calculated (see Figs. 3 and 7). As explained above, each patch can be dealt with independently, which makes this part of the calculation fully parallel.
The local column density contributions are calculated from
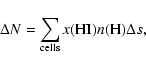 |
(3) |
These contributions are found by casting a ray section from the faces of the patch that are located closest to the source towards each cell centre (see Fig. 3). Column density contributions by the cells that lie inside the patch along each section are calculated using the "fast voxel traversal algorithm'' from Amanatides & Woo (1987) (for more details on this traversal method, see Appendix A). Besides ray sections that terminate at cell centres, we also need to calculate the column density contribution for ray sections that lead to cell corners located at those patch faces that are farthest away from the source (see Fig. 3). These are the contributions to the column density that need to be communicated (Sect. 2.3.1), and interpolated (Sect. 2.3.3) in subsequent steps of the algorithm.
Calculating these ray sections is similar to the method of long characteristics, but since the number of cells per patch is low relative to the effective resolution of the full computational domain, this actually does not impair the performance of the method too much (see Sect. 5 for an analytical comparison of our method with the short and long characteristics one for a regular grid).
We also considered using short instead of long characteristics to ray trace a single patch (see Appendix B for a description of a possible implementation). However, although the short characteristics method executes presumably more efficiently than the long characteristics one, the first requires interpolation, whereas the latter simply adds up column density contributions by individual cells. When the number of cells that need to be traversed is relatively small, as is the case when ray tracing the single patches, these extra calculations may render the short characteristics method even less efficient than the long characteristics one. Furthermore, the interpolation introduces undesirable diffusion. We therefore decided to implement the more accurate and straightforward ray tracing approach of Amanatides & Woo (1987).
As was mentioned above, in AMR hydrodynamics codes, each processor owns a sub-domain of the computational volume which is covered by a collection of patches. In order to obtain the total column density for a certain ray that traverses these sub-domains, individual local contributions by the patches need to be accumulated. This can be interpreted as applying the method of long characteristics, in this case not to add up contributions from individual cells, but instead to add up contributions from individual patches. So here our algorithm does again make use of long characteristics but now at the level of patches.
Since each processor knows the direction of its rays and the co-ordinates where they terminate, it can find the patches cut by these rays and perform the required calculations. For certain flavours of AMR, patches from different refinement levels may partially overlap. In such cases, one would have to make sure that only parts of the patches that contain valid data (i.e., the data from regions resolved to the highest resolution) are considered in the calculation of the column density. One way to eliminate the overlap is to apply a procedure called "grid homogenization'', as described by Kreylos et al. (2002).
For the oct-tree type of AMR implemented in FLASH, patches from different refinement levels do not overlap. Patches are either fully covered by still more refined patches or otherwise contain valid data (the latter are the so-called "leaf patches'' in terminology of FLASH). Therefore, a simple check to see if a patch is a "leaf patch'' is sufficient to determine whether or not it should contribute to the total column density along the ray.
Once the list of patches traversed by a ray is known, we loop through it, and determine the local column density contributed by each patch to the total column density for the ray.
Unless the ray terminates in the patch under consideration, it will in general not exit a patch exactly at a cell corner.
This means that we need to interpolate the values of column density contribution ![]() ,
obtained earlier (using either the short or long characteristics method as described in Sect. 2.2) at that face of the patch where the ray leaves it.
,
obtained earlier (using either the short or long characteristics method as described in Sect. 2.2) at that face of the patch where the ray leaves it.
We would like to emphasize that, although our method makes use of some form of long characteristics, nowhere in the algorithm is a ray traced on a cell-by-cell basis over the full computational domain. To the contrary, ray sections are traced through the cells of each patch and it is these local contributions which are combined through interpolation by performing another ray trace, this time not over cells but over patches, as described in Sect. 2.3.2. This is why we call our algorithm hybrid characteristics.
Below, we first explain how the local column density contributions ![]() ,
obtained with one of the methods from Sect. 2.2, are communicated between processors.
Then we describe how the list of patches traversed by a ray is constructed, after which we show the way in which this list is used to calculate the contributions to the total column density N.
,
obtained with one of the methods from Sect. 2.2, are communicated between processors.
Then we describe how the list of patches traversed by a ray is constructed, after which we show the way in which this list is used to calculate the contributions to the total column density N.
Since, for a parallel AMR hydrodynamics code, the patches are distributed over a number of processors, communication between processors is inevitable at certain points in the algorithm.
In particular, as soon as the local contributions to the column density have been calculated (Sect. 2.2), values of these ![]() located at patch faces that are farthest away from the source are communicated between processors.
In this way, each processor has the information regarding the face values of local column density from all patches in existence (i.e. the so called "gather'' operation is used).
Apart from these face values, all processors also need information about the location and size of each patch and its refinement level in order to determine if a particular ray cuts a patch.
This information is communicated using the "gather'' operation as well.
located at patch faces that are farthest away from the source are communicated between processors.
In this way, each processor has the information regarding the face values of local column density from all patches in existence (i.e. the so called "gather'' operation is used).
Apart from these face values, all processors also need information about the location and size of each patch and its refinement level in order to determine if a particular ray cuts a patch.
This information is communicated using the "gather'' operation as well.
The size of the messages to be communicated and the memory needed for storage of this information is given by
| (4) |
For an initial test of the performance of the algorithm as a whole, and of its communication patterns in particular, see Sect. 5.
A straightforward approach to constructing the list of patches traversed by a ray would be to simply check for all patches whether or not they are cut by the ray under consideration. Since this would have to be done for all rays, and since there are as many rays as there are cells, this approach quickly becomes prohibitively slow. We therefore developed a new, more elaborate, but much faster method to find the list of patches cut by a ray.
First, each processor creates a so called "patch-mapping'' which consists of an integer array representing the full computational domain that stores the id (i.e. a unique integer identifier) of all patches containing valid data. In Fig. 4 we show an example of such a mapping. These local patch-mapping arrays then need to be communicated and merged (using a so called "reduce'' communication operation) after which each processor has the same global patch-mapping corresponding to the full computational domain.
![\begin{figure}
\par\psfrag{processor 0}{\bf processor 0}
\psfrag{processor 1}{\b...
...5}
\psfrag{16}{16}
\includegraphics[width=7.65cm,clip]{3401fg4.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img28.gif) |
Figure 4:
Two-dimensional example of a "patch-mapping'' for a computational domain that is split over two different processors.
In the top row the local ids of the patches on the different processors are shown.
The mapping of these patch ids onto the patch-mapping array is shown in the middle row.
The bottom row shows the global patch-mapping after the local patch-mappings have been communicated.
Tracing the depicted ray results in the patch list
|
| Open with DEXTER | |
In order to discern patches that are on different processors we use the following coding for the global patch id:
| (5) |
We then trace the ray, again using the "fast voxel traversal algorithm'' (Amanatides & Woo 1987, see Appendix A), but now to trace through the global patch-mapping array. This results in the list of patches cut by the ray, which is used to accumulate their local contributions, which were already communicated earlier, to arrive at the total column density (as described in Sect. 2.3.3).
Although this approach to ray tracing can be a potential bottle-neck in the algorithm, one needs to keep in mind that the maximum number of patch-mapping entries along a ray is given by
![]() ,
with C3 the total number of cells if the computational domain would be fully refined, and c3 the number of cells per patch.
,
with C3 the total number of cells if the computational domain would be fully refined, and c3 the number of cells per patch.
For a typical three-dimensional oct-tree type AMR simulation with C=512 and c=16, we find a maximum amount of ![]() 55 patch-mapping entries that are cut by a ray.
Note however that this is an upper limit.
The number of entries is drastically smaller when the source and destination of the ray are not located at opposite sides of the domain (which will be the case for most rays).
Note also that, although we have to trace through the patch-mapping entries, the actual number of patches that ends up in the list is strongly reduced due to the adaptive nature of the discretization.
In the example given in Fig. 4, the number of patch-mapping entries visited by the ray is 13, but the number of patches that end up in the list is only 5.
It is this latter number which determines how many interpolations are needed when accumulating the local column density contributions.
55 patch-mapping entries that are cut by a ray.
Note however that this is an upper limit.
The number of entries is drastically smaller when the source and destination of the ray are not located at opposite sides of the domain (which will be the case for most rays).
Note also that, although we have to trace through the patch-mapping entries, the actual number of patches that ends up in the list is strongly reduced due to the adaptive nature of the discretization.
In the example given in Fig. 4, the number of patch-mapping entries visited by the ray is 13, but the number of patches that end up in the list is only 5.
It is this latter number which determines how many interpolations are needed when accumulating the local column density contributions.
Now that we have the list of patches traversed by a ray (Sect. 2.3.2) and the values of local column density at the patch faces located farthest away from the source have been made available to all processors (Sect. 2.3.1), we can proceed and calculate the local contributions to the total column density through interpolation.
| |
Figure 5: Two-dimensional illustration of the linear interpolation scheme used to accumulate local column density contributions. Shown are the ray sections used in the interpolation (see text for further details). |
| Open with DEXTER | |
![\begin{figure}
\par\psfrag{e}{$e$ }
\psfrag{1}{$1$ }
\psfrag{2}{$2$ }
\psfrag{3}...
... }
\psfrag{8}{$8$ }
\includegraphics[width=7.8cm,clip]{3401fg6.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img35.gif) |
Figure 6: Illustration of the interpolation scheme in three dimensions. For clarity we show outlines of cells on patch faces only. In the top image we show a ray r that exits the patch at location e through a cell face, together with the ray sections used in the interpolation that terminate at the corners of this cell face. The image at the bottom shows the cell face in more detail, where we indicated the cell corners by 1, 2, 3, and 4. In addition to these cell corners, ray sections used in the interpolation that terminate at 5, 6, 7, and 8 are also indicated (see text for further details). |
| Open with DEXTER | |
The calculations that need to be performed for a ray r traversing a patch p can be broken up into the following steps (two-dimensional case, see Fig. 5):
| (6) |
| (7) |
| (9) |
In three dimensions (see Fig. 6) it is not straightforward to derive weights that are a generalization of the two-dimensional ones described above. We therefore give a more intuitive derivation of these weights, using a procedure where we apply the weights for the two-dimensional case twice in succession:
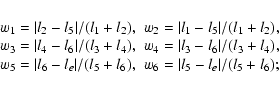 |
(10) |
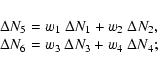 |
(11) |
| (12) |
The main difficulty in finding an interpolation scheme for the three-dimensional case lies in the fact that we need to weigh with the lengths of the ray sections to avoid the errors which will otherwise occur when the ray under consideration enters the patch close to a patch corner. Since in general all these path lengths are different from one another, this introduces quite a number of independent variables into the equations. So, although the two-step procedure just described is not unique, it is simple and fast, and it gives good results in practice.
![\begin{figure}
\par\includegraphics[width=6.7cm,clip]{3401fg7.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img51.gif) |
Figure 7: Summary of steps taken in the hybrid characteristics method. In the top image we show ray sections that represent local contributions to the column density (summary step 3), whereas ray sections that represent values of column density that need to be communicated are shown in the centre image (summary step 4). Note that only those values on patch faces located farthest away from the source need to be communicated. In the bottom image we show an example of the interpolation of these local values for a particular destination cell (summary step 6). Note that there is no need to interpolate the value for the final ray section in the destination patch since its value was already calculated previously (summary step 3). |
| Open with DEXTER | |
The steps taken in the algorithm can be summarized as follows (see Fig. 7):
To conclude this section, we compare our method to two more recent ones that either use some form of adaptivity to trace rays (Juvela & Padoan 2005), or that are parallelized for distributed memory architectures (Heinemann et al. 2005). Unlike ours, these methods are intended to solve for the full radiation field, and therefore need to employ multiple sets of rays to sample the angular parameter space. Depending on the adopted form of the source function, (lambda-)iteration is to be performed as well in order to obtain a converging solution.
Juvela & Padoan (2005) proposed a ray tracing method for cell based AMR intended to be used in calculations of line emission. Their method uses sets of parallel (in the geometrical sense) long characteristics to find the intensity at cell faces, which are then interpolated to get the intensity at the cell centre using a short characteristic. This is repeated for a number of directions after which angle averaged quantities are obtained. This process is then lambda-iterated to get converging line intensities.
Since their method refines on a cell-by-cell basis, and ours employs patches structured in an oct-tree hierarchy, there is a one-to-one correspondence between the procedures of ray tracing used in the two methods: their long characteristics correspond to our ray tracing of the patch-mapping, whereas their short characteristics correspond to our ray tracing of a single patch.
More recently, Heinemann et al. (2005) developed a method for tracing rays through a decomposed computational domain (i.e. sub-domains that are distributed over a number of processors). To sample the radiation field, rays are traced that are either parallel or diagonal to a regular patch. As they mention, this means that there is no need for them to interpolate local values. Furthermore, since their source function acts only locally, their is no need to iterate the solution.
As in our approach, Heinemann et al. (2005) first obtain all local contributions (which they call "intrinsic'') and add these up to arrive at the total solution. However, in contrast to our method, the communication pattern of Heinemann et al. (2005) is intrinsically serial (i.e. processors have to wait for one another, see their Fig. 1). In their case of a decomposed regular domain, the performance penalty due to the serial nature of their algorithm is small, but in case of an AMR type of grid, the performance would be severely degraded. Heinemann et al. (2005) also consider the special case of periodic boundary conditions with rays running only parallel along a coordinate axis. In such a situation, the boundary values are broadcasted and the inter-processor communication is more efficient than in the serial case.
Although our method is designed to study the effects of ionization due to point sources of radiation, it can be easily adapted to trace sets of parallel rays instead. Depending on the application, a prescription for the source function and (lambda-)iteration would need to be implemented. This would make our method suitable for solving the radiative transfer equation in a more general way, similar to the methods just discussed. The added advantage of such an approach is that our method is highly parallel and coupled to an AMR hydrodynamics code.
When the column density from the source up to each cell face is known, the ionization fractions and temperature can be computed. For this we use a simplified version of the DORIC routines (see Frank & Mellema 1994; Mellema & Lundqvist 2002). In what follows, we summarize the way in which these routines calculate the ionization, heating, and cooling rates (for more details, please refer to Frank & Mellema 1994). Although the DORIC package is capable of handling a large number of species (H, He, C, N, O, and Ne), we use hydrogen as the only gas component in order to keep the complexity of our test cases at a minimum, and we will therefore describe just this case.
The ionization fractions of hydrogen are given by
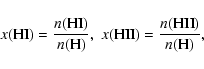 |
(13) |
| (14) |
| (15) |
For hydrogen, the number of photoionizations per second is given by (Osterbrock 1989)
The number of collisional ionizations per second is calculated using
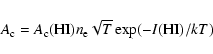 |
(17) |
For the on-the-spot approximation, the radiative recombination rate is given by (cf. Osterbrock 1989)
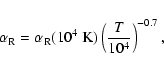 |
(18) |
| (19) |
When one assumes that the electron density is constant, an analytic solution for
![]() can be found, and iterating for
can be found, and iterating for ![]() gives the time dependent solution (Schmidt-Voigt & Koeppen 1987).
Since Ac and
gives the time dependent solution (Schmidt-Voigt & Koeppen 1987).
Since Ac and
![]() are both temperature dependent, the change in temperature due to heating and cooling needs to be recalculated for each iteration step as well.
are both temperature dependent, the change in temperature due to heating and cooling needs to be recalculated for each iteration step as well.
The photoionization heating rate is given by
For calculating the local mean intensity of the radiation field we use a blackbody spectrum, so we have
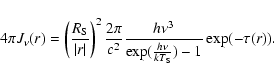 |
(22) |
The hydrodynamics and ionization calculations are coupled through operator splitting. To avoid having to take time steps that are the minimum of the hydrodynamics, ionization, and heating/cooling time scales, we use the fact that the equations for the ionization and heating/cooling can be iterated to convergence, using the analytical solution to Eq. (20) for the electron density as described above. Since these are so called "stiff'' equations (e.g. Press et al. 1992), we use a special iteration scheme (Frank & Mellema 1994). This means that the only restriction on the time step comes from the hydrodynamics (i.e. the Courant condition). See Frank & Mellema (1994) for an assessment of the validity of this approach.
In this section we present a number of tests for our new algorithm. First, we discuss the accuracy with which column densities and ionization fractions are calculated. We compare the results obtained with the hybrid characteristics method to those calculated using long characteristics. Since the interpolation scheme of our method is designed to give the exact result for the HI column density in case of a homogeneous density distribution (Sect. 2.3.3), we also consider its performance in case of a more general density field.
We conclude this section by testing the shadow casting capabilities of our method for one and two sources of ionizing radiation, and apply it to a "real-world'' application of photoevaporating flows. This last test demonstrates the performance of our method when used in combination with hydrodynamics.
We performed two-dimensional calculations where we placed a single point source at the centre of a 1/r2 density distribution, the result of which is shown in Fig. 8.
In order to prevent an under-resolved singularity at the location of the source, we used a constant density sphere with a radius of 5 ![]() 1014 at the source location.
1014 at the source location.
The left panel of Fig. 8 shows the HI column density distribution along a line
![]() cutting through the exact location of the source.
Since for this special case no interpolation is necessary, only very small differences between the two methods are found.
These differences are due to uneven sampling of the 1/r2 density distribution on the adaptive mesh.
The errors increase only slightly (<
cutting through the exact location of the source.
Since for this special case no interpolation is necessary, only very small differences between the two methods are found.
These differences are due to uneven sampling of the 1/r2 density distribution on the adaptive mesh.
The errors increase only slightly (<![]() )
when interpolation is used, as indicated by the results obtained along the
)
when interpolation is used, as indicated by the results obtained along the
![]() line located at 3/4 of the horizontal extent of the domain (the right panel in Fig. 8).
line located at 3/4 of the horizontal extent of the domain (the right panel in Fig. 8).
![\begin{figure}
\par\includegraphics[width=6.5cm,clip]{3401fg8a.eps}\par\vspace*{1.0cm}
\includegraphics[width=6.5cm,clip]{3401fg8b.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img79.gif) |
Figure 8: Test 1: values of HI column density for the case of a single point source in a two-dimensional domain with a 1/r2 density distribution. Shown are one-dimensional cuts along the y-direction through the source located at the centre of the domain ( top two panels) and at 3/4 of the domain ( bottom two panels). In the panels at the first and third row, the solid line indicates the result for the long, whereas the crosses indicate the result for the hybrid characteristics method. In the panels at the second and fourth row, the ratio (hybrid/long) of HI column density values is shown. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{3401fg9a.eps}\par\includeg...
...]{3401fg9c.eps}\par\includegraphics[width=7.5cm,clip]{3401fg9d.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img82.gif) |
Figure 9:
Test 2: values of |
| Open with DEXTER | |
To test the shadow casting capabilities of our algorithm, we calculate the HI column density and HI ionization fraction for a homogeneous environment containing higher density clumps, which are taken to be spherical and neutral. The ionization state is found by iterating the ionization fractions over a period equal to a few recombination time scales, while keeping the temperature fixed.
The computational domain spans the region
(2.0,1.0,1.0) ![]()
![]() .
The ambient medium has a number density
.
The ambient medium has a number density
![]() and a temperature
and a temperature
![]() .
The source of ionizing radiation is located at
(x,y,z)=(0.0,0.5,0.5)
.
The source of ionizing radiation is located at
(x,y,z)=(0.0,0.5,0.5) ![]()
![]() .
It has a luminosity
.
It has a luminosity
![]() and an effective temperature
and an effective temperature
![]() .
The resulting Strömgren sphere has a radius that is larger (
.
The resulting Strömgren sphere has a radius that is larger (![]() 3
3 ![]()
![]() )
than the physical size of the computational domain.
Two identical clumps are placed at a distance of
)
than the physical size of the computational domain.
Two identical clumps are placed at a distance of ![]()
![]() from the source.
Each clump has a density
from the source.
Each clump has a density
![]() ,
a temperature
,
a temperature
![]() ,
and a radius
,
and a radius
![]()
![]()
![]() .
We used 6 levels of refinement with patches of 163 cells.
The effective resolution in this test was 1024
.
We used 6 levels of refinement with patches of 163 cells.
The effective resolution in this test was 1024 ![]() 5122 cells.
5122 cells.
The results of the shadow casting test are shown in Fig. 9. As one can see, our hybrid characteristics method is capable of casting shadows with very sharp boundaries, indicating a low numerical diffusivity of the scheme. We note that since the initial conditions do not contain any density gradient, HI column densities calculated in this test are identical to the ones one would obtain using a long characteristics method.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{3401f10a.eps}\par\includeg...
...]{3401f10b.eps}\par\includegraphics[width=7.5cm,clip]{3401f10c.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img92.gif) |
Figure 10:
Test 3: two sources in an environment with a homogeneous density distribution containing a neutral clump with higher density. The clump is located at (1,1,1) |
| Open with DEXTER | |
This section describes a test with two sources in a homogeneous environment containing a single dense clump. The computational domain has a size of
(2.0,2.0,2.0) ![]()
![]() .
The ambient medium has a number density
.
The ambient medium has a number density
![]() and a temperature
and a temperature
![]() .
The sources are located at
(x,y,z)=(0,1,1)
.
The sources are located at
(x,y,z)=(0,1,1) ![]()
![]() and
(x,y,z)=(0.5,0,1)
and
(x,y,z)=(0.5,0,1) ![]()
![]() .
They both have a luminosity
.
They both have a luminosity
![]() and an effective temperature
and an effective temperature
![]() .
A single dense clump is located at
(x,y,z)=(1,1,1)
.
A single dense clump is located at
(x,y,z)=(1,1,1) ![]()
![]() .
This clump has a density
.
This clump has a density
![]() ,
a temperature
,
a temperature
![]() ,
and a radius
,
and a radius
![]()
![]()
![]() .
We used 7 levels of refinement with patches of 163 cells, resulting in an effective resolution of 10243 cells.
Like in test 2, the temperature is kept constant throughout the calculation.
.
We used 7 levels of refinement with patches of 163 cells, resulting in an effective resolution of 10243 cells.
Like in test 2, the temperature is kept constant throughout the calculation.
Figure 10 shows the results of this test. The HI column densities for the two different sources are shown seperately in the top two panels, together with the resulting HI ionization fraction. Only a small region behind the clump lies in the shadow of both sources, and is therefore neutral. Also note the slightly lower ionization state of the material in the two "tails'' behind the clump, as compared to the ionization state in the surrounding medium. This is caused by the fact that only direct photons from a single source can penetrate these regions.
To illustrate that our hybrid radiative transfer algorithm can be used efficiently in combination with hydrodynamics, we present a first 3D application of the evolution of over-dense clumps being photoevaporated.
Since we want to follow the effects photo-heating has on the dynamics, the temperature is calculated self-consistently with the ionization fractions using the approach described in Sect. 3.
We use the parameters of the simulation setup described in Sect. 4.2 as initial conditions and follow the dynamical evolution for ![]()
![]() .
This simulation is similar to the ones presented by Lim & Mellema (2003), with this difference that in our simulation both the source and the clumps are inside the computational domain, and that our radiation field is not approximated by parallel rays.
.
This simulation is similar to the ones presented by Lim & Mellema (2003), with this difference that in our simulation both the source and the clumps are inside the computational domain, and that our radiation field is not approximated by parallel rays.
These computations are relevant to the shaping and evolution of cometary knots which are observed in objects like the Helix (NGC 7293), Eskimo (NGC 2392), and Dumbbell (M27) nebula. Another application is the interaction zone that is observed between binary proplyds in HII regions like NGC 3603 (Brandner et al. 2000) and the Orion Nebula (Graham et al. 2002).
Figure 11 shows a sequence of snapshots![]() of the density and HI ionization fraction at different times during the simulation.
One sees that the interaction of the photoevaporation flows coming from the clumps results in a zone of higher density between the clumps, which, as was already found by Lim & Mellema (2003), can explain the excess emission observed between some cometary knots and binary proplyds.
This interaction zone recombines, becomes optically thick, and casts a shadow.
It is interesting to see that the zone, and the shadow region behind it, persist even after the two clumps have been fully evaporated.
This mechanism for creating extra shadows may influence the evolution and survival time of clumps that lie farther away from the star, an effect not taken into account in previous numerical studies.
We are currently investigating further into this kind of flows and will present our findings in a forthcoming publication.
of the density and HI ionization fraction at different times during the simulation.
One sees that the interaction of the photoevaporation flows coming from the clumps results in a zone of higher density between the clumps, which, as was already found by Lim & Mellema (2003), can explain the excess emission observed between some cometary knots and binary proplyds.
This interaction zone recombines, becomes optically thick, and casts a shadow.
It is interesting to see that the zone, and the shadow region behind it, persist even after the two clumps have been fully evaporated.
This mechanism for creating extra shadows may influence the evolution and survival time of clumps that lie farther away from the star, an effect not taken into account in previous numerical studies.
We are currently investigating further into this kind of flows and will present our findings in a forthcoming publication.
![\begin{figure}
\par\includegraphics[height=3.5cm,width=8.3cm,clip]{3401f11a.eps}...
...5cm}
\includegraphics[height=3.5cm,width=8.3cm,clip]{3401f11l.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img102.gif) |
Figure 11:
Test 4: snapshots of the evolution of the |
| Open with DEXTER | |
We start this section by comparing our hybrid characteristics method to the more traditional long and short characteristics methods for regular grids. In order to do this, we distinguish between two types of computations: first we determine how many calculations are needed to arrive at the local contribution each cell makes to the column density along a ray, and second we look at the number of interpolations the different methods have to perform to compute the total column density up to each cell.
Consider a computational domain with a resolution of C3 cells and a source located at one of the corners of the domain.
For the case of a regular grid, the maximum number of cells a long characteristic would encounter is ![]() ,
and, since we assume that a ray is cast to all cells, the number of calculations needed to provide the total column density is therefore
,
and, since we assume that a ray is cast to all cells, the number of calculations needed to provide the total column density is therefore ![]() C4.
C4.
For our hybrid characteristics method, which employs an oct-tree type of AMR grid, the maximum number of cells a local ray section encounters is ![]() ,
where c3 is the number of cells in a single patch (cf. Sect. 2.2).
So in this case, for a fully refined grid, the total number of calculations would amount to
,
where c3 is the number of cells in a single patch (cf. Sect. 2.2).
So in this case, for a fully refined grid, the total number of calculations would amount to ![]() c C3.
But, since in general the domain would be refined by a factor r, with
c C3.
But, since in general the domain would be refined by a factor r, with
![]() ,
this number reduces to
,
this number reduces to ![]() r c C3.
This means that when
r c C3.
This means that when
![]() ,
our method needs
,
our method needs ![]() C3 calculations to arrive at the local contributions to the column density for each cell, which is of the same order a short characteristics method would need on a regular grid.
However, the local values of column density still need to be communicated and interpolated to arrive at the total column density for each cell.
On the other hand, a short characteristics method also needs to interpolate local values when it sweeps through the grid, whereas a long characteristics method, although it executes a factor C more calculations, does not need to perform any interpolations at all.
C3 calculations to arrive at the local contributions to the column density for each cell, which is of the same order a short characteristics method would need on a regular grid.
However, the local values of column density still need to be communicated and interpolated to arrive at the total column density for each cell.
On the other hand, a short characteristics method also needs to interpolate local values when it sweeps through the grid, whereas a long characteristics method, although it executes a factor C more calculations, does not need to perform any interpolations at all.
The number of interpolations to be performed by our method is determined by the number of patches that are encountered when ray tracing through the patch-mapping (cf. Sects. 2.3.2 and 2.3.3). This number is at most
![]() ,
since, for a fully refined grid, there are C/c patches along a coordinate axis.
For a grid that is not fully refined this number is again reduced by a factor r.
A ray trace through the patch-mapping is to be performed for every cell, which brings the total number of interpolations to
,
since, for a fully refined grid, there are C/c patches along a coordinate axis.
For a grid that is not fully refined this number is again reduced by a factor r.
A ray trace through the patch-mapping is to be performed for every cell, which brings the total number of interpolations to ![]() r2 (C/c) C3, where one factor of r comes from the number of patches cut by a ray, whereas the other factor comes from the total number of cells that exist in the computational domain.
r2 (C/c) C3, where one factor of r comes from the number of patches cut by a ray, whereas the other factor comes from the total number of cells that exist in the computational domain.
A short characteristics method needs to do an interpolation for every cell, so, for a regular grid, the total number of interpolations is C3.
This implies that when
![]() ,
our method needs to compute a similar number of interpolations as a short characteristics one.
Note that we assume that the calculations needed to do the interpolations are comparable in execution speed for the short and hybrid characteristics methods, which may actually not be the case.
,
our method needs to compute a similar number of interpolations as a short characteristics one.
Note that we assume that the calculations needed to do the interpolations are comparable in execution speed for the short and hybrid characteristics methods, which may actually not be the case.
As an example, a typical AMR calculation has C=512, c=16 (i.e. 6 levels of refinement), and r=0.25, which results in rc=4 and r2 C/c = 2. This shows that, for a single processor calculation with a proper choice of the ratio C/c and a reasonable amount of refinement, our hybrid characteristics method is expected to perform equally well as a short characteristics method on a regular grid. It also means that, when our method is used in parallel, a better performance will be obtained when increasing the number of processors.
![\begin{figure}
\par\includegraphics[angle=-90,width=8.5cm,clip]{3401fg12.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img109.gif) |
Figure 12:
Performance of the main components of a radiation hydrodynamics calculation.
Plotted are the total calculation time in seconds for the hydrodynamics (+), AMR ( |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[angle=-90,width=8.5cm,clip]{3401fg13.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img110.gif) |
Figure 13:
Performance of the different steps in the radiation part of the hybrid characteristics method. Plotted are the total calculation time in seconds for the local ray trace (+), communication ( |
| Open with DEXTER | |
To investigate this aspect in some more detail we have conducted a preliminary performance analysis using the photoevaporating clumps test case described in Sect. 4.4 as the underlying physics problem.
We used 5 levels of refinement irrespectively of the number of processor used in the test run (i.e., the problem had a fixed total work).
Calculations have been terminated after reaching ![]() of the nominal simulation time.
Otherwise the simulation parameters were identical to those used in the calculations presented in Sect. 4.4.
All tests were performed on an SGI Origin 3800 system, where each node consists of a 500 MHz R14000 CPU with 1 GB of memory.
of the nominal simulation time.
Otherwise the simulation parameters were identical to those used in the calculations presented in Sect. 4.4.
All tests were performed on an SGI Origin 3800 system, where each node consists of a 500 MHz R14000 CPU with 1 GB of memory.
The results of our performance study are shown in Fig. 12, where we compare the overall performance of the hydrodynamics, AMR, and radiation calculations. Detailed results for the radiation part are presented in Fig. 13, where the timings for the individual components of our hybrid characteristics method (local ray trace, communication, accumulation/interpolation, and ionization) are shown.
Performance data obtained for our realistic test problem indicates that the ray tracing part of the calculation takes less time than either the hydrodynamics or grid adaptation. Furthermore, it shows that most of the computational time during ray tracing is spent in interpolating and accumulating the local contributions to the column density (i.e. step 6, Sect. 2.4). Following the analytical assessment made above, we conclude that in order to reduce the number of interpolations required during calculation one should try to minimize the value of r2 C/c rather than rc when setting up a simulation. This suggest that one should use patches that contain a relatively large number of cells compared to the effective resolution of the computational domain, and, of course, keep the filling factor of the finest AMR level at a minimum.
Figure 13 shows performance results for the radiation module including the ionization package for our fixed size problem.
As one can see, the time required to calculate the column densities is about the same as the time needed to calculate the ionization state of the gas.
Furthermore, both these calculations are local and therefore perform very well.
On the other hand, we notice that the communication part of our algorithm does not perform perfectly. This is somewhat expected since, with the increasing number of processors, the efficiency of our algorithm becomes limited by the efficiency of the global gather operation (used to collect column densities from patch faces).
The results for this specific test indicate that communication is likely to dominate the runtime when more than ![]() 64 processors participate in the computations.
We expect that this limitation becomes less severe when larger patches are used in the simulation.
In this case the cost of communication may still be lower than, for example, the time needed to accumulate and interpolate the column densities.
To determine whether this is indeed the case, more elaborate performance tests involving a larger number of processors (of the order of
64 processors participate in the computations.
We expect that this limitation becomes less severe when larger patches are used in the simulation.
In this case the cost of communication may still be lower than, for example, the time needed to accumulate and interpolate the column densities.
To determine whether this is indeed the case, more elaborate performance tests involving a larger number of processors (of the order of ![]() 1000) are required, and such tests are currently underway.
1000) are required, and such tests are currently underway.
We described a new radiative transfer algorithm for parallel AMR hydrodynamics codes, called hybrid characteristics. We presented details of several aspects of the algorithm: ray tracing, communication, and interpolation. In its current implementation, the method calculates the ionization and heating due to multiple point sources of ionizing radiation, ignoring the effects of the diffuse radiation field and scattering.
The ray tracing is performed in two steps. First, local long characteristics are used to calculate column density contributions for each patch. A second ray trace is then performed where a so called patch-mapping is used to find the patches cut by each ray. When the list of patches cut by a ray is known, interpolation of local column density values is required to find the total column density up to each cell. For this, one needs the values of local column density contribution at patch faces, which are communicated to all processors. The coefficients used in the interpolation are chosen such that the exact solution for the column density is retrieved when there are no gradients in the density distribution.
For the case where the distribution is not constant but has a 1/r2 profile we find deviations of the order of ![]()
![]() when comparing our method with a long characteristics one.
This high accuracy with which column densities values are calculated results in well defined and sharp shadows.
when comparing our method with a long characteristics one.
This high accuracy with which column densities values are calculated results in well defined and sharp shadows.
We showed that our method can be used efficiently for parallel radiation hydrodynamics calculations in three dimensions on AMR grids. We presented preliminary results for our new method in application to the problem of the photoevaporation of two over-dense clumps due to the ionization by a single source of radiation. The results of this simulation offer a possible explanation for the excess emission observed in between cometary knots seen in for example the Helix Nebula, and the interaction zone observed in binary proplyds found in HII regions like NGC 3603 and the Orion Nebula. These simulations also suggest a possible mechanism for the creation of extra shadows by the high density interaction zone forming between the clumps. This additional shadowing may influence the evolution and survival time of clumps that lie farther away from the source. We are currently investigating further into this kind of interactions between photoevaporating flows, and their consequences for the dynamics, and will report our findings in a future publication.
An initial performance test showed that our method works very well when used for calculations on a parallel machine. For this specific test, the communication part of our algorithm starts to dominate the calculation when more than ![]() 64 processors are used.
However, we showed analytically that a careful choice of the ratio of the number of cells per patch to the total number of cells in the computational domain controls the amount of communication used in the calculation.
This analysis can be used to optimize the design of our method.
More in-depth performance and scaling studies are currently underway, using large (
64 processors are used.
However, we showed analytically that a careful choice of the ratio of the number of cells per patch to the total number of cells in the computational domain controls the amount of communication used in the calculation.
This analysis can be used to optimize the design of our method.
More in-depth performance and scaling studies are currently underway, using large (![]() 1000) number of processors, and these will also be used to further optimize the current implementation.
1000) number of processors, and these will also be used to further optimize the current implementation.
Because of the modular nature of the FLASH code and the DORIC routines, additional elements like more sophisticated cooling or multiple species can easily be added. Also, multiple point sources can be handled by our method, and in principle moving sources could be implemented. Furthermore, it should be straightforward to extend the hybrid characteristics method so that it can be used to solve for a more general radiation field, with the added advantage that our method is already parallelized and coupled to an AMR hydrodynamics code.
Another possible application for our method is the calculation of the propagation of ionization fronts in a cosmological context. For these calculations photon conservation is an important issue. Recently, Mellema et al. (2005) developed a method for following R-type ionization fronts that may move more than one cell per time step, where a special formulation of the equations ensures photon conservation. Although the parallel nature of our algorithm may complicate the implementation of such an approach, we may still benefit from the ideas presented by Mellema et al. (2005).
We intend to make our method publicly available in a future FLASH release.
Acknowledgements
E.J.R. wishes to thank the ASC Flash Center for its hospitality during a very enjoyable and productive visit when most of the work presented in this paper was done, and Vincent Icke for his support throughout this project.
This work is supported in part by the US Department of Energy under Grant No. B523820 to the Center for Astrophysical Thermonuclear Flashes at the University of Chicago.
E.J.R. was sponsored by the National Computing Foundation (NCF) for the use of supercomputer facilities, with financial support from the Netherlands Organization for Scientific Research (NWO), under Grant No. 614.021.016.
The work of G.M. is partly supported by the Royal Netherlands Academy of Arts and Sciences (KNAW).
![\begin{figure}
\par\psfrag{txi}{$t_x^{\rm i}$ }
\psfrag{tyi}{$t_y^{\rm i}$ }
\ps...
...g{Dy}{$\Delta y$ }
\includegraphics[width=5.8cm,clip]{3401fgA1.eps} \end{figure}](/articles/aa/full/2006/24/aa3401-05/img111.gif) |
Figure A.1: Explanation of different quantities used in the fast voxel traversal method. Shown is a single patch with a local long characteristic ray section. |
Here we briefly discuss the "fast voxel traversal algorithm'' from Amanatides & Woo (1987).
We have used this algorithm twice in our method, once to ray trace through the cells ("voxels'') of a single patch (local long characteristics, Sect. 2.2), and once to ray trace the patch-mapping (hybrid characteristics, Sect. 2.3).
The idea behind the algorithm is to keep track of three different ray parameters tx, ty, and tz, one for each co-ordinate direction, and to use these to determine how to step from cell to cell through the patch, ensuring that all cells cut by the ray are visited (see Fig. A.1).
First, values for the increments in ray parameter t needed to step from cell to cell in the x-, y-, and z-direction, indicated by
![]() ,
,
![]() ,
and
,
and
![]() ,
respectively, are determined:
,
respectively, are determined:
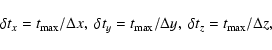 |
(A.1) |
min
(tx,ty,tz)=tx, the next cell the ray will enter lies in the x-direction, and we have to increment the ray parameter for the x-direction accordingly, i.e.
As an alternative to the "fast voxel traversal algorithm'' for ray tracing a single patch as presented in Sect. 2.2, we here briefly describe the short characteristics method, which could be used for the same purpose. Since the method of short characteristics uses interpolation from neighbouring cells, upwind values need to be available at all times, so cells need to be swept in a certain order. This sweeping sequence is determined by the physical location of the patch relative to the source position (see Fig. B.1). Using the known physical location of the source, the geometrical path length of the ray section that crosses a cell is calculated for every cell contained in the patch. The short characteristics method then sweeps the patch in a direction away from the source, interpolating upwind column density contributions for each cell along the way.
For the two-dimensional case, Fig. B.2 illustrates which two cells, indicated by c1 and c2, are used in this interpolation. Simple linear interpolation weights
| (B.1) |
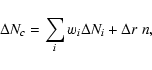 |
(B.2) |
For the three-dimensional case the ray pierces a cell face, so four instead of two quantities need to be interpolated.
The normalized weights are chosen to correspond to the partial areas of the cell face defined by the corners of this face and the location at which the ray leaves the cell (cf. Fig. B.2):
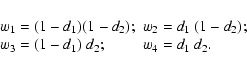 |
(B.3) |
| |
Figure B.2: Illustration of the interpolation scheme for a single cell used in the short characteristics method for the 2D ( left) and 3D ( right) case. |
![\begin{displaymath}%
N(r) = \sum_p \Delta N_e(p) \:\:\: [p\in {\rm list}(r)].
\end{displaymath}](/articles/aa/full/2006/24/aa3401-05/img41.gif)