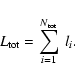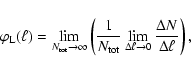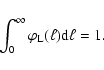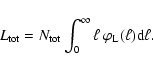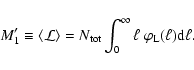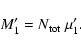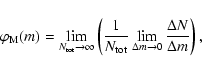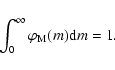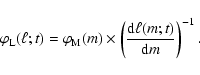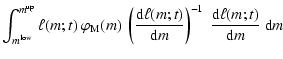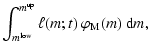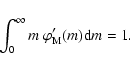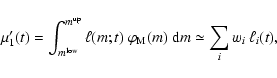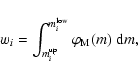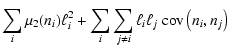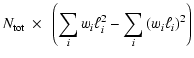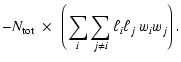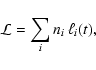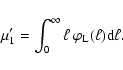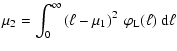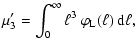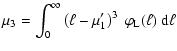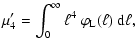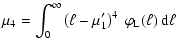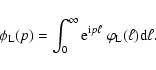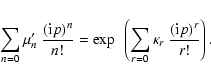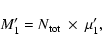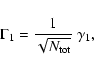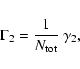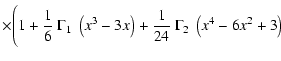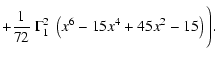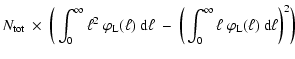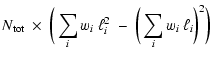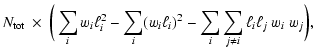A&A 451, 475-498 (2006)
DOI: 10.1051/0004-6361:20053283
M. Cerviño1 - V. Luridiana1
Instituto de Astrofísica de Andalucía (CSIC), Camino bajo de Huétor 50, Apdo. 3004, Granada 18080, Spain
Received 21 April 2005 / Accepted 30 December 2005
Abstract
Context. Synthesis models predict the integrated properties of stellar populations. Several problems exist in this field, mostly related to the fact that integrated properties are distributed. To date, this aspect has been either ignored (as in standard synthesis models, which are inherently deterministic) or interpreted phenomenologically (as in Monte Carlo simulations, which describe distributed properties rather than explain them).
Aims. This paper presents a method of population synthesis that accounts for the distributed nature of stellar properties.
Methods. We approach population synthesis as a problem in probability theory, in which stellar luminosities are random variables extracted from the stellar luminosity distribution function (sLDF).
Results. With standard distribution theory, we derive the population LDF (pLDF) for clusters of any size from the sLDF, obtaining the scale relations that link the sLDF to the pLDF. We recover the predictions of standard synthesis models, which are shown to compute the mean of the luminosity function. We provide diagnostic diagrams and a simplified recipe for testing the statistical richness of observed clusters, thereby assessing whether standard synthesis models can be safely used or a statistical treatment is mandatory. We also recover the predictions of Monte Carlo simulations, with the additional bonus of being able to interpret them in mathematical and physical terms. We give examples of problems that can be addressed through our probabilistic formalism: calibrating the SBF method, determining the luminosity function of globular clusters, comparing different isochrone sets, tracing the sLDF by means of resolved data, including fuzzy stellar properties in population synthesis, among others. Additionally, the algorithmic nature of our method makes it suitable for developing analysis tools for the Virtual Observatory.
Conclusions. Though still under development, ours is a powerful approach to population synthesis. In an era of resolved observations and pipelined analyses of large surveys, this paper is offered as a signpost in the field of stellar populations.
Key words: galaxies: star clusters - galaxies: stellar content - Hertzsprung-Russell (HR) and C-M diagrams - methods: data analysis
The study of stellar populations is one of the most fecund topics in today's astronomy. Understanding the properties of stellar populations is a key element in the solution of a host of fundamental problems, such as the calibration of distances to extragalactic objects, the age determination of clusters and galaxies through color fitting, the characterization of the star-formation history of composite populations, the modeling of the chemical evolution of galaxies, and several more. When tackling these problems, the interaction between theory and observations goes both ways: one may want to predict the properties of a stellar population with given properties, or to recover the basic properties of an observed population from the available observables. In either case, to accomplish the task one needs feasible theoretical models that serve as reliable diagnostic tools.
A traditional approach to building such diagnostic tools has been the computation of synthesis models. Synthesis models allow one to predict the features and the evolution of stellar populations in a highly structured way, one that is apt for routine analysis and quantitative assessments. For example, synthesis models can be used, in combination with other methods, for the determination of stellar population properties of large samples of galaxies in a reasonable time; e.g. the analysis of 50 362 galaxies of the Sloan Digital Sky Survey based on their integrated properties performed by Cid Fernandes et al. (2005).
However, in recent years there has been a growing awareness that synthesis modeling also suffers from severe limitations. In some cases, we know a priori that standard models cannot be applied to a given system, because the properties of the system fall outside the hypothesis space of the models; this is the case, for example, of undersampled populations (Cerviño & Valls-Gabaud 2003; Chiosi et al. 1988). In other cases, we observe a mismatch between the properties of the system inferred from observations of their individual components and those derived from their integrated properties analyzed with synthesis models: e.g. the discrepancy between the age determined from the color-magnitude diagram and the spectroscopic age in NGC 588 (Jamet et al. 2004), or the IMF slope inferred by Pellerin (2006) in undersampled giant H II regions. In these cases, we are facing a crisis in the explanatory power of synthesis models.
Previous attempts to solve this crisis and to understand the
limitations of synthesis models have repeatedly pointed at the necessity
of including statistical considerations in the analysis.
According to this view, the predictive power breaks down because
the traditional synthesis model is essentially a deterministic
tool, whereas the nature of the problem is inherently stochastic.
The clearest example of stochasticity is the mass spectrum of
stellar populations, in which fluctuations (possibly random, although not necessarily so) in the number of stars of each type appear around the mean expected number.
Until now, the efforts to take stochasticity into account in the modeling
of stellar populations have moved in essentially two directions:
the use of Monte Carlo techniques (e.g. Girardi 2002; Bruzual 2002; Santos & Frogel 1997; Cantiello et al. 2003; Cerviño et al. 2000a, among others) and the reinterpretation of traditional models in statistical terms (e.g. González et al. 2004; Cerviño et al. 2002; Buzzoni 1989). Both methods have proved able
to solve some of the problems, or at least point toward possible solutions.
However, they suffer from practical difficulties.
Monte Carlo simulations are expensive (in terms of disk space, CPU time, and
human time required to analyze the results),
while, to date, the statistical reinterpretation of standard models has only
served to establish limits to the use of synthesis models for clusters with moderately undersampled populations (Cerviño et al. 2003; Cerviño & Luridiana 2004), i.e. clusters with total initial masses on the order of
![]() .
.
This limitation brings about a serious impasse for the study of stellar populations by means of their integrated light, since the properties of clusters with lower masses cannot be reliably obtained. This class includes, for example, all of the clusters in our Galaxy (including globular clusters), clusters in the Large Magellanic Cloud (LMC), as well as many clusters in external galaxies. For example, many of the clusters in the "Antennae'' studied by Zhang & Fall (1999) have masses lower than this limit: in Sect. 8.3 we will show that explicit consideration of stochastic effects could alter the conclusions that are drawn on the cluster luminosity function based on these clusters. Furthermore, these limitations will become even more dramatic with the development of Virtual Observatory (VO) technologies, which will make the automatic analysis of large amounts of data possible. It is therefore mandatory to adapt evolutionary synthesis models to the present needs, so that they can be applied to observations.
In the present paper we introduce a theoretical formalism for the
probabilistic analysis of single stellar populations (SSPs). Our formalism yields results that are as accurate as those of large Monte Carlo simulations, but it bypasses the need to perform these simulations: that is, the method is both accurate and economic. By means of our formalism, synthesis models can be applied to clusters of any size and the confidence intervals of the results can be evaluated easily. This makes it possible to estimate the relative weights of different bands for the realistic application of goodness-of-fit criteria like the ![]() test. Finally, the algorithmic nature of our method makes it feasible for implementation in the VO environment.
test. Finally, the algorithmic nature of our method makes it feasible for implementation in the VO environment.
This paper is the fourth in a series (Cerviño et al. 2000a, 2002, 2001) dealing with the statistical analysis of stellar populations. Although it only deals with SSPs, a fifth paper, in preparation, will be devoted to the extension of this formalism to any star formation history scenario. Finally, in Cerviño & Luridiana (2005) we give an extensive review of the uncertainties affecting the results of synthesis models. In addition to these papers, we also recommend the work by Gilfanov et al. (2004): statistical properties of the combined emission of a population of discrete sources: astrophysical implications. This paper, although not directly focused on synthesis models, suggests an alternative point of view of the problem. In some aspects, it has inspired the present paper.
In this work we restate the problem of stellar population synthesis from a new perspective, the one of luminosity distributions, which is a powerful and elegant way to understand stellar populations. We provide several examples of applications to illustrate such power and indicate potential areas of future development. The starting point of the new formalism is the definition of the stellar (i.e. individual) luminosity distribution function (LDF) and of its relation to the central problem of population synthesis (Sect. 2). Section 3 describes the two main variants of synthesis models by means of which the problem has traditionally been tackled: Monte Carlo and standard models. Next, we take the reader on a journey through the no man's land of population synthesis' pitfalls (Sect. 4), and show how these are faced by existing techniques (Sect. 5). This account is necessary to introduce, in Sect. 6, our suggested solution and show its comparative power. Finally, in Sect. 7, we give a few examples of applications of our formalism to current problems. Future developments of the present work are described in Sect. 8, and our main conclusions are summarized in Sect. 9.
This section starts by introducing a few basic definitions. An exhaustive summary of the notation used and its rationale is offered in Appendix A.
The general problem approached by synthesis models is the computation
of the luminosity![]()
![]() emitted by an ensemble of
emitted by an ensemble of
![]() sources - a stellar population.
From a theoretical point of view, this problem can be characterized in three basic ways.
sources - a stellar population.
From a theoretical point of view, this problem can be characterized in three basic ways.
If the luminosities li of the individual sources are known,
the total luminosity
![]() is obtained trivially as the sum of all the li values:
is obtained trivially as the sum of all the li values:
In the more usual situation in which the luminosities of individual
objects cannot be specified on an individual basis,
a different approach must be adopted: in this case a luminosity distribution function (LDF)
![]() is assumed that describes the
distribution of luminosity values in a generic ensemble. Traditionally, the LDF
has been seen as the asymptotic limit of a differential count of stars:
is assumed that describes the
distribution of luminosity values in a generic ensemble. Traditionally, the LDF
has been seen as the asymptotic limit of a differential count of stars:
To avoid confusion, note that the pLDF is not the same as the cluster or galaxy luminosity function (LF) as commonly defined, because galaxy LFs include the effect of a spread in ages and number of stars (or, equivalently, ages and mass), whereas the pLDF defined in this paper represents the luminosity distribution of ensembles of stars with the same physical parameters (age and total number of stars).
In this paper, we are concerned with the properties of the sLDF
and its relation to the pLDF. In particular, we will show that
the total luminosity of a stellar population, ![]() ,
is a distributed quantity,
whose mean value M1' is given by:
,
is a distributed quantity,
whose mean value M1' is given by:
The main goal of synthesis models is to obtain the luminosity of a model stellar population, either by direct count (Eq. (1)) or by an integral including the sLDF (Eqs. (4) and (5)). In the following, we will see how this can be carried out in practice, under the assumption that there has been a star-forming episode in which all the stars have formed simultaneously; this is the scenario assumed by SSP models.
Because stellar luminosities evolve with time, the sLDF is a function of the star's age.
Since the luminosity evolution of a star depends on its initial mass,
we can express the time dependence of the sLDF explicitly
by writing the sLDF as a function of two other functions:
the isochrone ![]() and the initial mass function (IMF)
and the initial mass function (IMF)
![]() .
The isochrone
.
The isochrone ![]() gives the luminosity of a star as
a function of its initial mass m at a given value of the age t.
The IMF gives the probability distribution of initial stellar masses. The IMF
has a status similar to that of the sLDF,
in that it can be either interpreted as the result of a star count:
gives the luminosity of a star as
a function of its initial mass m at a given value of the age t.
The IMF gives the probability distribution of initial stellar masses. The IMF
has a status similar to that of the sLDF,
in that it can be either interpreted as the result of a star count:
Solving this integral is the main task of stellar population synthesis modeling. In the following section we will describe the main types of synthesis models and how they perform this integral.
Once the physical problem is framed, we must translate it into actual computations, a task carried out by evolutionary synthesis codes. These come in two basic flavors, standard and Monte Carlo. Standard simulations are models in which the initial mass mixture is analytically described by the IMF, whereas in Monte Carlo simulations the ensemble of stars is selected by random sampling the mass of each star to be included in the population, and the IMF is used as the weighting function. Therefore, the mass distribution obtained with a standard simulation is univocally determined by the population's parameters, while in Monte Carlo simulations it is not; additionally, the standard distribution is smoother than the Monte Carlo one. Both methods, however, operate on a binned mass spectrum, due to the limited resolution of numerical computation and to the discreteness of the available stellar models. This fact has important consequences, which will be discussed in Sect. 4.2.
Using either of these two approaches, evolutionary synthesis codes
aim to characterize the integrated emission properties of an ensemble of stars as a function of
its physical parameters, such as the age and number of the individual stars
of the ensemble![]() .
Standard codes perform this task by carrying out the integration
of Eq. (10). As described in Sect. 2,
the result can be interpreted in two alternative ways:
either a deterministic one -
.
Standard codes perform this task by carrying out the integration
of Eq. (10). As described in Sect. 2,
the result can be interpreted in two alternative ways:
either a deterministic one - ![]() is the
sum of the luminosities of all the stars included in the ensemble modeled,
normalized to one star -, or a probabilistic one -
is the
sum of the luminosities of all the stars included in the ensemble modeled,
normalized to one star -, or a probabilistic one - ![]() is the mean value of
the sLDF. Although the two interpretations may seem close at first sight,
they are fundamentally different, both from a conceptual
and from a practical perspective:
this point will be furthered in Sect. 6.
We call these two alternative interpretations of standard synthesis
models the deterministic and the statistical one.
Note that these labels do not identify different classes of
models, but rather different interpretations within the same class of
models - standard models. In practice, some codes do not explore
this interpretation, while others acknowledge the distributed
nature of luminosity and compute, in addition to the mean luminosity,
the variance of the distribution. In either case,
is the mean value of
the sLDF. Although the two interpretations may seem close at first sight,
they are fundamentally different, both from a conceptual
and from a practical perspective:
this point will be furthered in Sect. 6.
We call these two alternative interpretations of standard synthesis
models the deterministic and the statistical one.
Note that these labels do not identify different classes of
models, but rather different interpretations within the same class of
models - standard models. In practice, some codes do not explore
this interpretation, while others acknowledge the distributed
nature of luminosity and compute, in addition to the mean luminosity,
the variance of the distribution. In either case, ![]() can eventually be scaled to the size of the ensemble
by multiplying by
can eventually be scaled to the size of the ensemble
by multiplying by
![]() ;
this property will be formally demonstrated in Sect. 6.2.
;
this property will be formally demonstrated in Sect. 6.2.
Note that many codes do not use
![]() in Eq. (10), but rather a proportional function
in Eq. (10), but rather a proportional function
![]() normalized in such a way that:
normalized in such a way that:
As for Monte Carlo models, their task is essentially
the computation of the sum in Eq. (1).
Each time a simulation is run, a particular realization is drawn
from the underlying distribution.
The result of the simulation is the integrated luminosity ![]() of that particular realization.
If many Monte Carlo simulations are available for a fixed set of
input parameters, an estimate for M1' can be obtained as the mean of the
of that particular realization.
If many Monte Carlo simulations are available for a fixed set of
input parameters, an estimate for M1' can be obtained as the mean of the ![]() values.
This implies that the results of Monte Carlo simulations depend not only on the underlying luminosity distribution, but also on the number of simulations used to sample such distribution.
If the set of simulations is sufficiently large,
the Monte Carlo method has also the potential to provide
the actual distribution function of the luminosities of the ensemble.
Hence, an important drawback of the method is that it is intrinsically expensive, because the accuracy of the results increases with the number of simulations.
values.
This implies that the results of Monte Carlo simulations depend not only on the underlying luminosity distribution, but also on the number of simulations used to sample such distribution.
If the set of simulations is sufficiently large,
the Monte Carlo method has also the potential to provide
the actual distribution function of the luminosities of the ensemble.
Hence, an important drawback of the method is that it is intrinsically expensive, because the accuracy of the results increases with the number of simulations.
In summary, the goal of determining the luminosity of stellar populations reduces to the computation of a sum (Eq. (1)) or an integral (Eq. (10)). However straightforward this may seem, this computation is hindered in the practice by several intrinsic features of the problem: these will be the topic of next section.
Our previous discussion has taken place on an abstract level. In the practice of synthesis modeling it is necessary to translate the concepts discussed above into specific prescriptions for the handling of equations, and deal with the limitations imposed by the input ingredients, which have a finite resolution in the parameter space. In this section we will discuss a specific aspect of this task, namely the difficulties inherent to the determination of the mean value of the sLDF. As a first step, let us revisit a few well-known results in terms of the sLDF.
![\begin{figure}
\par\includegraphics[width=8.2cm,clip]{3283f1.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img48.gif) |
Figure 1:
Schematic representation of the of the sLDF
for three different cases: main sequence only ( top), main sequence plus a constant post main sequence ( middle), and main sequence plus a bumpy post main sequence ( bottom). The position of the mean ( |
| Open with DEXTER | |
In synthesis modeling it is a well established fact that the integrated luminosity of the ensemble is dominated by the most massive stars in the cluster. In the following we will illustrate this point by means of three simplified scenarios that are representative of real sLDFs.
These are shown graphically in Fig. 1. In each panel,
the position of the mean ![]() and the region corresponding to
and the region corresponding to
![]() are explicitly marked.
are explicitly marked.
In the first case let us assume that all the stars are in the main sequence (MS), and that
![]() .
Assuming a power-law IMF with index
.
Assuming a power-law IMF with index ![]() ,
the
sLDF can be expressed as:
,
the
sLDF can be expressed as:
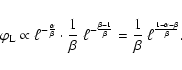 |
(12) |
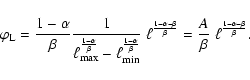 |
(13) |
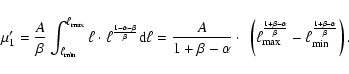 |
(14) |
Let us go a bit further and add a post-main sequence (PMS) contribution to the
sLDF. The sLDF can now be divided in two regimes, corresponding to the MS and to the PMS respectively. As a first approximation, we will assume that the PMS phase gives a constant contribution to the sLDF, implying that any point of the PMS portion of the isochrone is equally probable. The sLDF can be described by the expression:
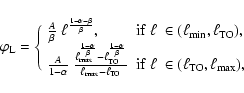 |
(15) |
If we further assume that
![]() ,
the mean value of the sLDF is:
,
the mean value of the sLDF is:
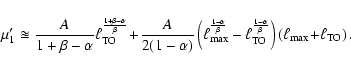 |
(16) |
As a final example, let us assume that the sLDF has a narrow peak in addition to the MS contribution. This scenario describes the case in which PMS stars have all the same luminosity, as in the horizontal branch or in the red giant clump phase; this case can be modeled by adding a pulse function to the MS section of the sLDF.
Since PMS luminosities are larger than MS luminosities, the pulse function is located at
![]() .
The sLDF is therefore:
.
The sLDF is therefore:
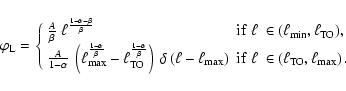 |
(17) |
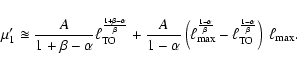 |
(18) |
These three examples illustrate the general fact that the mean luminosity depends strongly on the value of
![]() .
The dependence on
.
The dependence on
![]() would be even stronger for higher-order moments of the distribution.
As Gilfanov et al. (2004) point out, the dependence of the results of synthesis models
on the high-luminosity end of the sLDF
is so strong that, without such a limit, synthesis models could not even be computed!
As a further example of the relevance of the upper limit of the
sLDF, we have shown in a previous paper that it also defines a lower limit for the luminosity of real clusters to be described by standard synthesis models (Cerviño & Luridiana 2004).
would be even stronger for higher-order moments of the distribution.
As Gilfanov et al. (2004) point out, the dependence of the results of synthesis models
on the high-luminosity end of the sLDF
is so strong that, without such a limit, synthesis models could not even be computed!
As a further example of the relevance of the upper limit of the
sLDF, we have shown in a previous paper that it also defines a lower limit for the luminosity of real clusters to be described by standard synthesis models (Cerviño & Luridiana 2004).
These examples also illustrate the following interesting facts:
(i) The mean value does not necessarily give information on the distribution of luminosities, to the extreme that there can be situations in which the probability to find a source in the region around the mean value is zero (Fig. 1, bottom panel). This is the opposite of a Gaussian distribution, in which the mean is also the most probable value.
(ii) Different distributions can have the same mean value but different variances. In fact, this circumstance permits to use surface brightness fluctuations (SBF: the ratio between the variance and the mean value of the luminosity function) to break the age-metallicity degeneracy, which makes clusters with different ages and metallicities have the same ![]() .
(iii) The value of
.
(iii) The value of
![]() is negative in our three examples. This shows clearly that assuming, e.g., that
is negative in our three examples. This shows clearly that assuming, e.g., that
![]() includes
includes ![]() 68% of the elements of the distribution can be grossly mistaken in the case of non-Gaussian distributions.
As we will see later, this can also be the case with the distribution function of the integrated luminosity of an ensemble: this limits the use of goodness-of-fit methods based on the comparison with the mean, such as the
68% of the elements of the distribution can be grossly mistaken in the case of non-Gaussian distributions.
As we will see later, this can also be the case with the distribution function of the integrated luminosity of an ensemble: this limits the use of goodness-of-fit methods based on the comparison with the mean, such as the ![]() test.
test.
Summing up, our schematic but realistic sLDFs show that knowledge of the mean and the variance does not provide a handle on the problem if the shape of the distribution is not known. As Gilfanov et al. (2004) argue, the use of the mean value instead of the most probable one produces a systematic bias in the determination of integrated properties.
Although Eq. (10) is expressed as an integral, synthesis codes approach it through numerical approximations. There are several reasons for this: first, the input data are available in tabular format rather than as analytical relations; e.g., given the enormous complexity of stellar evolution it is not possible to derive stellar properties as analytical functions of, say, initial mass and stellar age. Rather, stellar tracks are computed for a discrete and finite set of mass values, and their properties are conveniently interpolated a posteriori. Furthermore, calculated stellar tracks are generally expressed in tabular form, although there have been sporadic attempts at expressing them in analytical form (e.g. Tout et al. 1996). Second, even if analytical relations existed, their integration would plausibly require numerical methods. Third, the numerical precision of computers is limited. These circumstances force the actual calculations of synthesis models to be numerical rather than analytical: as a consequence, the mass variable must be binned. We will focus here on the implications of mass binning for Eq. (10).
Introducing binning, Eq. (10) can be expressed as:
The statistical strand of standard models was born with the goal of devising statistical tools to be applied to synthesis models. In this context, the binomial probability distribution of stars in individual bins had been approximated by a Poisson distribution to simplify its handling (Cerviño et al. 2002). As is known, the Poisson approximation is accurate only when the number of events N is large and the probability p is vanishingly small, in such a way that Np stays finite: we will show in the following that such approximation is not always accurate enough for our problem.
A first point to consider is that speaking of a distribution of stars in bins only makes sense if a value of
![]() is considered. In both cases considered, Poisson and binomial, the mean value of the number of stars in a bin is
is considered. In both cases considered, Poisson and binomial, the mean value of the number of stars in a bin is
![]()
![]() wi.
Let us now illustrate the difference between the two distributions for the case of
wi.
Let us now illustrate the difference between the two distributions for the case of
![]() .
The probability for the source to fall in the ith mass bin is,
in the Poisson approximation,
.
The probability for the source to fall in the ith mass bin is,
in the Poisson approximation,
![]() .
In the binomial case such probability is
pib(1)=wi, which is the correct value. The difference is non-negligible for large wi values, which is typical for bins at small masses.
.
In the binomial case such probability is
pib(1)=wi, which is the correct value. The difference is non-negligible for large wi values, which is typical for bins at small masses.
Furthermore, when
![]() stars are considered,
the Poisson approximation predicts the ratio M2/M1' of the variance to the
mean to be unity, whereas in Monte Carlo simulations this ratio shows a trend
toward smaller values for small bin masses (Fig. 1 of Cerviño et al. 2002),
revealing the underlying binomial distributions, in which:
stars are considered,
the Poisson approximation predicts the ratio M2/M1' of the variance to the
mean to be unity, whereas in Monte Carlo simulations this ratio shows a trend
toward smaller values for small bin masses (Fig. 1 of Cerviño et al. 2002),
revealing the underlying binomial distributions, in which:
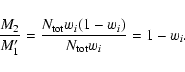 |
(21) |
The difference between the Poissonian approximation and the multinomial description is particularly clear if we compute the variance of the pLDF. Consider the expression for the variance obtained assuming that the number of stars in each bin is described by a Poisson distribution,
and that there is no correlation between bins
(e.g. Cerviño et al. 2002, among others):
These considerations show that the Poisson approximation, motivated by simplicity of handling, may break down in our problem (see also Lucy 2000). While the distinction between the Poisson approximation and the multinomial description is important in order to make sense of Monte Carlo simulations, it is fundamental in view of the discussion on our proposed probabilistic formalism (Sect. 6).
![\begin{figure}
\par\includegraphics[width=8.2cm,clip]{3283f2.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img86.gif) |
Figure 2:
Top: isochrones in the
|
| Open with DEXTER | |
In writing Eq. (9), we have tacitly assumed that the luminosity
is a well-behaved function of the mass so that the isochrone is always defined.
However, this condition is in fact often violated, since
a typical isochrone features shallow sections as well as peaks and discontinuities
in the ![]() plane. Shallow sections correspond to quiescent phases of stellar evolution,
where evolution is slow (e.g. the MS); peaks correspond to faster phases
(e.g. the asymptotic giant branch, AGB);
and discontinuities correspond to abrupt transitions between phases
(e.g. the onset of central helium burning in intermediate mass stars)
or jumps in stellar behavior (the transition between WR and non-WR-type structures).
In the following, peaks and discontinuities will generically be referred to
as fast evolutionary phases.
Some of these cases are illustrated by the comparison of Figs. 2
with 3. In Fig. 2 the isochrones computed by Girardi et al. (2002)
based on the evolutionary tracks by Marigo & Girardi (2001)
plane. Shallow sections correspond to quiescent phases of stellar evolution,
where evolution is slow (e.g. the MS); peaks correspond to faster phases
(e.g. the asymptotic giant branch, AGB);
and discontinuities correspond to abrupt transitions between phases
(e.g. the onset of central helium burning in intermediate mass stars)
or jumps in stellar behavior (the transition between WR and non-WR-type structures).
In the following, peaks and discontinuities will generically be referred to
as fast evolutionary phases.
Some of these cases are illustrated by the comparison of Figs. 2
with 3. In Fig. 2 the isochrones computed by Girardi et al. (2002)
based on the evolutionary tracks by Marigo & Girardi (2001)![]() are shown, at selected age values. Figure 3 shows the relation between the initial mass and the luminosity in the V and K bands for the same isochrones,
focusing on fast evolutionary phases.
are shown, at selected age values. Figure 3 shows the relation between the initial mass and the luminosity in the V and K bands for the same isochrones,
focusing on fast evolutionary phases.
![\begin{figure}
\par\includegraphics[width=16.33cm,clip]{3283f3.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img88.gif) |
Figure 3: Details of fast evolutionary phases in the V (solid line, left axis) and K (dotted-line, right axis) bands. Bottom panel: complete isochrones. Middle panels: blow-up of the mass axis, showing details of fast evolutionary phases at three different ages. Top panels: same as middle panels, with a more extreme blow up. The isochrone set is the same of Fig. 2. |
| Open with DEXTER | |
If the mean value of the sLDF is determined through the numerical approximation of Eq. (19), fast evolutionary phases are difficult to handle, because a small difference in initial stellar mass yields a large difference in luminosity, so that the result of the numerical integration crucially depends on which luminosity is chosen to be representative of a given mass bin. In principle, this difficulty can be dealt with by decreasing the width of the mass bin and choosing mass bins that do not go across discontinuities; however, the available resolution in mass is governed by the evolutionary tracks used by the code, and is generally too low to resolve adequately such phases in synthesis models.
This is a severe problem, since fast evolutionary phases are ubiquitous in
post main-sequence evolution, and at certain frequencies
they bear a major weight in the luminosity balance.
Unfortunately, the way in which this problem is tackled is often labeled a "technical
detail'' of the computation and dismissed as unimportant,
and thus the papers describing evolutionary synthesis models
do not generally make any reference to its solution - in spite of
its difficulty and of the potentially disastrous consequences of
incorrect assumptions. Here are a few examples of the ways in which this
problem has been approached: a) in the Starburst99 synthesis
code (Leitherer et al. 1999), for certain metallicity values,
an undocumented stellar track at 1.701 ![]() is added to the tabulated track of 1.70
is added to the tabulated track of 1.70 ![]() by
Schaller et al. (1992) and Schaerer et al. (1993), to avoid the mass bins
going across the discontinuity of the stellar models' behavior
at such mass (C. Leitherer, D. Schaerer, & G. Meynet, private communication); b) to deal with the same problem, additional evolutionary tracks around the same mass range
are used in the computation of the isochrones
by Castellani et al. (2003) and Cariulo et al. (2004) (S. Degl'Innocenti, private communication)
and Brocato et al. (1999) (E. Brocato, private communication);
c) to avoid the intrinsic discontinuity in the isochrones,
the same mass is used twice in the isochrones by Girardi et al. (2002),
namely at the end of the red giant branch and at the beginning of the horizontal branch
(S. Bressan, private communication).
by
Schaller et al. (1992) and Schaerer et al. (1993), to avoid the mass bins
going across the discontinuity of the stellar models' behavior
at such mass (C. Leitherer, D. Schaerer, & G. Meynet, private communication); b) to deal with the same problem, additional evolutionary tracks around the same mass range
are used in the computation of the isochrones
by Castellani et al. (2003) and Cariulo et al. (2004) (S. Degl'Innocenti, private communication)
and Brocato et al. (1999) (E. Brocato, private communication);
c) to avoid the intrinsic discontinuity in the isochrones,
the same mass is used twice in the isochrones by Girardi et al. (2002),
namely at the end of the red giant branch and at the beginning of the horizontal branch
(S. Bressan, private communication).
As a final point, consider that fast evolutionary phases are those stages in which the evolution is rapid in any of the relevant luminosity bands, and not only the bolometric luminosity. Therefore, an isochrone that is adequately sampled in one band is not necessarily so in all the bands.
Traditional synthesis models rely on the possibility to express the luminosity as a function of mass (Eq. (9)), so that the integrals over luminosity are transformed into integrals over mass. However, there are stellar phases in which this is impossible to do, because the luminosity at a given age is not univocally determined by the mass. A few examples are: the thermal pulse phase in AGB stars, which is poorly resolved by stellar evolutionary models; supernova (SN) light curves, in which a star of fixed mass spans a large range of luminosity almost instantaneously; variable stars; rotating stars, in which the luminosity emitted depends on both the rotation velocity and the inclination angle. Partly because of this difficulty, these phenomena are generally not included in synthesis models; whereas approaching the problem from the point of view of distribution functions permits to account for them by including them in the sLDF - provided they can be modeled quantitatively. This point will be developed further in Sect. 7.2. See also Gilfanov et al. (2004) for an example on the inclusion of variability.
Of course, in many cases of interest the modeling of the phenomenon may be a difficulty in itself. For example, modeling rotation is in itself problematic. Rotating stellar models are just beginning to appear on the market, and the distribution of velocities in a stellar population is largely unknown. Stellar rotation is not yet included in synthesis models primarily because of these uncertainties, and not only because synthesis models are not flexible enough. But if stellar rotation or any other distributed stellar behavior is properly understood, or at least satisfactorily modeled, our method will permit to include it in synthesis modeling.
Usually, the available model atmospheres form a coarse grid in the
(log g, log
![]() )
plane, whereas isochrones are
generally continuous in the plane. In order to assign
a model atmosphere to each isochrone location,
one can either choose the nearest atmosphere of the grid,
or interpolate between nearby atmospheres. Assigning the nearest
atmosphere implies a further binning of data and may originate
jumps in the results, although it is often assumed that these jumps
cancel on average when a whole population is considered.
This problem will not be further discussed here; a more extensive discussion
can be found in Cerviño & Luridiana (2005).
)
plane, whereas isochrones are
generally continuous in the plane. In order to assign
a model atmosphere to each isochrone location,
one can either choose the nearest atmosphere of the grid,
or interpolate between nearby atmospheres. Assigning the nearest
atmosphere implies a further binning of data and may originate
jumps in the results, although it is often assumed that these jumps
cancel on average when a whole population is considered.
This problem will not be further discussed here; a more extensive discussion
can be found in Cerviño & Luridiana (2005).
In the next section, we will review the ways in which the basic task of synthesis codes is accomplished, given the difficulties outlined here.
This section outlines the basic ways in which the task of computing the luminosity is specifically performed by standard codes. The first two parts, 5.1 and 5.2, describe techniques implemented in standard models. The third part, 5.3, describes how the Monte Carlo method is put into practice.
The commonest technique to compute the luminosity of stellar populations
is known as isochrone synthesis. Isochrone synthesis
is the numerical integration of the product between the IMF and the isochrone
approximated as in the rightmost part of Eq. (19):
![]() .
The strongest assumption of this numerical approximation is
that each
.
The strongest assumption of this numerical approximation is
that each ![]() is representative of all the stages included in it.
Fast evolutionary phases evidently pose a problem in the integration, since a small
interval in mass can correspond to very different luminosity values.
In isochrone synthesis, the problem is solved
increasing the number of mass bins that map fast evolutionary phases.
However, this strategy eventually requires assuming mass bins narrower
than the precision of the published tracks and isochrones.
It is interesting to note that one of the
main advantages of isochrone synthesis mentioned by Charlot & Bruzual (1991) is
that it produces "smooth'' results; however, this advantage
only hides the problem of fast evolutionary phases, but does not solve it.
is representative of all the stages included in it.
Fast evolutionary phases evidently pose a problem in the integration, since a small
interval in mass can correspond to very different luminosity values.
In isochrone synthesis, the problem is solved
increasing the number of mass bins that map fast evolutionary phases.
However, this strategy eventually requires assuming mass bins narrower
than the precision of the published tracks and isochrones.
It is interesting to note that one of the
main advantages of isochrone synthesis mentioned by Charlot & Bruzual (1991) is
that it produces "smooth'' results; however, this advantage
only hides the problem of fast evolutionary phases, but does not solve it.
As an alternative method, one can avoid using the expression
of Eq. (19), and perform instead the integration in the luminosity domain, that is
integrate
![]() :
in this way, the fast evolution of luminosity is automatically taken care of.
This is the basis of the so-called fuel consumption theorem (FCT):
to understand fully the FCT and its assumptions,
we refer the reader to the original paper
(Renzini & Buzzoni 1986; Buzzoni 1989; see also Maraston 1998).
:
in this way, the fast evolution of luminosity is automatically taken care of.
This is the basis of the so-called fuel consumption theorem (FCT):
to understand fully the FCT and its assumptions,
we refer the reader to the original paper
(Renzini & Buzzoni 1986; Buzzoni 1989; see also Maraston 1998).
Note that isochrone synthesis and the FCT can be coupled: the computation of isochrones can be done so as to fulfill the FCT requirements. We refer to Marigo & Girardi (2001) for an extended discussion on the subject (see also Bressan et al. 1994).
The Monte Carlo method can be implemented in different ways,
which take advantage of its potential to varying degrees,
so they are not completely equivalent. To understand this point,
consider how a sample of stars selected through a Monte Carlo
mass assignment can be handled: first, the stars can be either followed individually throughout
their evolution, or grouped in mass bins characterized by average properties;
second, in either case an atmosphere, used to transform the bolometric luminosity into
observable quantities, can be assigned by either choosing
the nearest model in the available grid, or interpolating between nearby atmospheres (see Sect. 4.5). Therefore there is a total of four ways in which
a Monte Carlo-selected stellar population![]() can be treated. In the literature, there are examples of at least three of these:
can be treated. In the literature, there are examples of at least three of these:
The conclusions arising from this brief overview of population synthesis can be summarized in the following points:
A note on definitions is due here. Throughout this paper, we adopt the conventional (though often overlooked) distinction between probability theory and statistics. A statistical formulation is one that seeks to intepret a sample of experimental data in terms of an underlying distribution. A probabilistic formulation is one that assumes an underlying distribution and uses it to predict the resulting distribution of experimental data. The traditional Monte Carlo method has followed a statistical approach: conclusions were drawn from the observation of a spread in the results of simulations. The present paper lays the foundations for a probabilistic approach, in that it seeks to give a formal description of the underlying distributions, and to make quantitative predictions based on them. Obviously, the two approaches complement each other and partially overlap; concepts like the one of distribution function belong to both probability theory and statistics, thus we will refer to them as probabilistic or statistical alike. When it comes to define our method with respect to existing ones, however, we will systematically draw a distinction and refer to it as a probabilistic formalism.
As we have seen in Sect. 2, the luminosity of stars can be characterized in terms of an underlying sLDF (Eq. (5)). The exploitation of this approach permits finding an effective solution to the problem of computing the integrated properties of stellar populations. The formalism presented here to this scope is not new in terms of theory of distributions and can be found in any advanced textbook of statistics (e.g. Kendall & Stuart 1977). For completeness, we briefly review here the relevant concepts.
The properties of the sLDF as a distribution can be studied by
computing its moments; the first moment is the mean,
which we already encountered in Eq. (5):
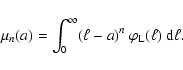 |
(26) |
In the following, we will adopt the notation ![]() to indicate central moments
and the notation
to indicate central moments
and the notation ![]() to indicate raw moments. Let us write down explicitly the expressions for the second central moment (or variance) and the second raw moment of the
sLDF, and their mutual relation:
to indicate raw moments. Let us write down explicitly the expressions for the second central moment (or variance) and the second raw moment of the
sLDF, and their mutual relation:
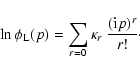 |
(34) |
Finally, the skewness, ![]() ,
and the kurtosis,
,
and the kurtosis, ![]() ,
of the distribution
are defined through ratios of the third and the fourth central moments respectively
to appropriate powers of the variance:
,
of the distribution
are defined through ratios of the third and the fourth central moments respectively
to appropriate powers of the variance:
In the previous section we have characterized the properties
of the luminosity function of individual stars.
Let's see now how the luminosity function of an ensemble of
![]() sources can be computed.
sources can be computed.
As a general rule, the PDF of an ensemble of
variables is obtained as the convolution of the PDFs of
the individual variables. For example, let
![]() be the PDF of a variable x and
be the PDF of a variable x and
![]() the PDF of a variable y independent of x. The probability density of a variable u=x+y is given by the product of the probabilities of
the PDF of a variable y independent of x. The probability density of a variable u=x+y is given by the product of the probabilities of
![]() and
and
![]() summed over all the combinations of x and y such that u=x+y:
summed over all the combinations of x and y such that u=x+y:
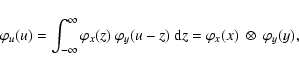 |
(42) |
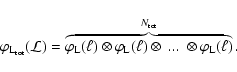 |
(43) |
An alternative solution is making the convolution logarithmically in the Fourier space (see next section). However, the numerical computation of the Fourier transform of a function with an irregular sampling is also difficult and, again, we haven't find any routine to perform it satisfactorily.
Convolutions in the normal space are equivalent to products in the Fourier space, so that:
Thus, probabilistic reasoning confirms the intuitive expectation that
the properties of an ensemble of
![]() stars can be obtained by direct scaling of the properties of the sLDF. This result is fundamental for the interpretation of the output of
synthesis models in terms of real clusters. However, it is clear from
the above derivation that this simple scaling rule only applies to cumulants, not to moments; it is cumulants that hold the scale relations between the properties of the sLDF and the distribution of the total luminosity of an ensemble. But, by virtue of Eqs. (36)-(39), cumulants
can be related to moments:
stars can be obtained by direct scaling of the properties of the sLDF. This result is fundamental for the interpretation of the output of
synthesis models in terms of real clusters. However, it is clear from
the above derivation that this simple scaling rule only applies to cumulants, not to moments; it is cumulants that hold the scale relations between the properties of the sLDF and the distribution of the total luminosity of an ensemble. But, by virtue of Eqs. (36)-(39), cumulants
can be related to moments: ![]() is equal to the first raw moment, and the following
is equal to the first raw moment, and the following ![]() s are equal to the central moments of the same order, which can in turn be expressed in terms of the raw moments: therefore, to characterize a distribution we can refer either to the moments
or to the cumulants.
s are equal to the central moments of the same order, which can in turn be expressed in terms of the raw moments: therefore, to characterize a distribution we can refer either to the moments
or to the cumulants.
It is immediately seen from Eqs. (40) and (41)
that the shape of the distribution of the ensemble, when expressed in normal form (through a transformation of the distribution function to one with zero mean and unit variance:
![]() ), can be easily
related to the shape of the sLDF:
), can be easily
related to the shape of the sLDF:
Although the previous relations are useful to unveil the scale properties of LDFs, knowledge of the moments of a distribution is useful but not sufficient to analyze it if its shape is unknown. For most application, one needs to know whether the distribution can be approximated by a Gaussian, and in case it is not, which its shape is. The following section will deal with the problem of characterizing a distribution by means of its cumulants. The technique suggested can be used to solve two different kind of problems: on one hand, it can be used to generate a theoretical pLDF from a sLDF when the convolution is not feasible. On the other, it can be used to infer the pLDF of an observed population.
Alternative solutions go through obtaining an approximate expression for the pLDF.
A quantitative characterization of the pLDF by means of its cumulants can be obtained by means of approximate expressions.
To this aim, we suggest using the Edgeworth's series, which can be written schematically as:
![$\displaystyle %
\varphi(x) = Z(x) ~ \left[ 1 + \sum_{i=1}^\infty t_i \right],$](/articles/aa/full/2006/20/aa3283-05/img147.gif) |
(50) |
These properties can be used to obtain an explicit description of the distribution and to estimate its degree of gaussianity. The algorithm to be followed is described here and represented in Fig. 4:
![\begin{figure}
\par\includegraphics[width=8cm,clip]{3283f4.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img151.gif) |
Figure 4: Algorithm to obtain an approximate expression for a pLDF based on the Edgeworth's series. |
| Open with DEXTER | |
The algorithm is summarized in the flux diagram of Fig. 4, which permits to find an explicit analytical expression for a pLDF of unknown shape but known cumulants.
As an example, we give here the explicit expression of the Edgeworth's series
truncated to include terms up to n=2:
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{3283f5.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img156.gif) |
Figure 5:
Top: |
| Open with DEXTER | |
Similarly, the bottom panel of Fig. 5 describes the
region satisfying the second test, i.e. the region
where the pLDF can be approximated by a Gaussian within a 10%.
As expected, this region is centered around the point [
![]() ],
where a true Gaussian would lie.
Again, this depends on the range of x considered: the wider this range,
the narrower the range of acceptable
],
where a true Gaussian would lie.
Again, this depends on the range of x considered: the wider this range,
the narrower the range of acceptable ![]() and
and ![]() values.
values.
The extension of the dark-gray region can be used to define a simplified diagnostic test for luminosity functions (Fig. 6).
This test is based on the algorithm of Fig. 4,
but only the first four moments are used, and conventional figures of 10% are used to define whether Edgeworth's approximation is acceptable and the LDF is quasi-Gaussian. Since ![]() and
and ![]() are relatable to the skewness and kurtosis of the sLDF via
are relatable to the skewness and kurtosis of the sLDF via
![]() (Eqs. (48) and (49)), this test can also be used to determine the minimum number of stars necessary to ensure gaussianity in a given band. An example of this technique will be given in Sect. 7.1.
(Eqs. (48) and (49)), this test can also be used to determine the minimum number of stars necessary to ensure gaussianity in a given band. An example of this technique will be given in Sect. 7.1.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{3283f6.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img158.gif) |
Figure 6:
Characterization of a pLDF based on Edgeworth's approximation to the second order and a gaussianity tolerance interval of |
| Open with DEXTER | |
We have seen in Sect. 4.2 that the Poisson distribution
is only an approximation to the distribution of the number of stars in a bin, and that it is not a safe one. The correct alternative is to use the multinomial distribution, which has the additional advantage of keeping track of covariance effects across bins.
However, the multinomial distribution by itself does not tell the whole story.
Additionally, its handling is difficult. We will show here that the adoption of the
probabilistic formulation permits bypassing this problem, because it provides the tools to compute the relevant quantities without the need of making assumptions on the distribution of stars in bins,
except its randomness![]() .
.
As an example, let's use our probabilistic formalism to compute the variance of
the distribution. To do so, we need not make any assumption on the distribution
of the number of stars in bins: we just need to take into account the scale relations
of luminosity functions (Eq. (46))
and the properties of cumulants (Eqs. (36)-(39)):
| (52) |
![\begin{figure*}
\par\includegraphics[width=12.9cm,clip]{3283f7.eps}\end{figure*}](/articles/aa/full/2006/20/aa3283-05/img163.gif) |
Figure 7:
Main parameters of the luminosity function in several photometric bands, obtained from the isochrones by Marigo & Girardi (2001) and adopting the IMF by Salpeter (1955) in the mass range 0.15-120 |
| Open with DEXTER | |
Finally, note that the value of the variance of the pLDF customarily assumed in the literature (Eq. (22)) is biased, with the work by Cantiello et al. (2003) as the only exception we are aware of. Note that in fact, the variance obtained from Eq. (22) is the second raw moment of the pLDF, and not its second central moment.
Unfortunately, the determination of the LDF of an ensemble is hindered by a few technical problems. The first one concerns the stellar LDF: although some aspects of stellar populations (like variability or transient events) would be more easily treated via the luminosity function as compared to the standard method, the modeling of the luminosity evolution during fast evolutionary phases poses the same problems as in standard codes.
A second issue is the contribution of dead stars to the luminosity function. Those stars have no influence on the computation of the moments of the distribution, except for a "normalization factor'' that depends on the age of the population.
In terms of the shape of the luminosity distribution, dead stars show up as a pulse function located at zero luminosity. This can be easily understood in the following terms: let us assume an ensemble with
![]() initial stars. At a given age there is a non-zero probability that all stars are dead; the pLDF, marginalized to such a condition, is a delta centered on zero. There is also a non-zero probability that all but 1 stars are dead: the pLDF corresponding to this case is the sum of a pulse function and the stellar luminosity function, the pulse function having in this case a strength smaller than the delta. Similarly, all but 2 stars can be dead, and the corresponding
pLDF is a pulse function plus the convolution of two stellar luminosity functions. In total, there are
initial stars. At a given age there is a non-zero probability that all stars are dead; the pLDF, marginalized to such a condition, is a delta centered on zero. There is also a non-zero probability that all but 1 stars are dead: the pLDF corresponding to this case is the sum of a pulse function and the stellar luminosity function, the pulse function having in this case a strength smaller than the delta. Similarly, all but 2 stars can be dead, and the corresponding
pLDF is a pulse function plus the convolution of two stellar luminosity functions. In total, there are
![]() + 1 marginalized cases, corresponding to
+ 1 marginalized cases, corresponding to
![]() ,
,
![]() ,
,
![]() ,
..., 2 and 1 dead stars. The LDF of the ensemble should include all these cases, each with a weight given by its relative probability, so that it will have a pulse contribution centered on zero. Although this result seems to contradict the central limit theorem, which states that the asymptotic shape of the LDF of the ensemble is a Gaussian, this is not the case, since the relative pulse contribution becomes smaller and smaller as
,
..., 2 and 1 dead stars. The LDF of the ensemble should include all these cases, each with a weight given by its relative probability, so that it will have a pulse contribution centered on zero. Although this result seems to contradict the central limit theorem, which states that the asymptotic shape of the LDF of the ensemble is a Gaussian, this is not the case, since the relative pulse contribution becomes smaller and smaller as
![]() increases.
increases.
In Sect. 4.1 we showed that knowledge of the mean and the variance is not enough to characterize a LDF. As a rule of thumb, at least the first four cumulants should be taken into consideration, which describe the mean, the dispersion, the asymmetry and the peakedness of the distribution. As a first example of application of the probabilistic
treatment, we will derive a few properties of stellar population from the analysis of its cumulants.
Figure 7 shows the first four cumulants of the sLDF for different bands and ages,
obtained from the isochrones by Marigo & Girardi (2001). We have assumed a Salpeter (1955) IMF in the mass range 0.15-120 ![]() normalized by the total number of stars. For a normalization in mass rather than in number of stars, these results must be multiplied by the mean mass,
normalized by the total number of stars. For a normalization in mass rather than in number of stars, these results must be multiplied by the mean mass,
![]() .
The figure illustrates several interesting facts:
.
The figure illustrates several interesting facts:
The input ingredients used in population synthesis are generally assumed to be fully known but are in fact affected by uncertainties (Cerviño & Luridiana 2005). These uncertainties may either reflect incomplete knowledge or an intrinsic spread in the features of the quantities considered. In either case, they can be included in the sLDF provided they can be modeled quantitatively.
As an example, let's suppose that the mass distribution function depends on a parameter ![]() that is itself distributed, that is let's replace the univocally determined function
that is itself distributed, that is let's replace the univocally determined function
![]() with a parametric function
with a parametric function
![]() .
The parameter
.
The parameter ![]() can be characterized by a probability distribution function such that:
can be characterized by a probability distribution function such that:
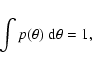 |
(54) |
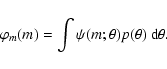 |
(55) |
Let's consider two hypothetical examples. In the first, assume that
![]() and that the power-law index
and that the power-law index ![]() has a rectangular distribution centered on Salpeter's index
has a rectangular distribution centered on Salpeter's index
![]() :
:
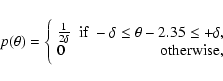 |
(56) |
| |
= | ||
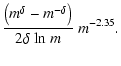 |
(57) |
As a further example, let's assume that
![]() as above,
but that now
as above,
but that now ![]() is Gaussian:
is Gaussian:
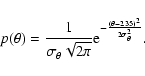 |
(58) |
![\begin{figure}
\par\includegraphics[width=8.2cm,clip]{3283f8.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img195.gif) |
Figure 8:
Salpeter's IMF (solid line) compared to two examples of distributed IMFs: rectangular (dashed,
|
| Open with DEXTER | |
Following this example, any spread in the input ingredients can be included in the modeling and contribute to the shape of the pLDF. In particular, the method outlined above can be used to include transient phases and fuzzy stellar behavior in the modeling (Sect. 4.4). For this to be done, it is just necessary that the phenomenon considered can be described in terms of a parameter of known distribution function. Other uncertainties that can be incorporated in the modeling are those that reflect our imperfect knowledge of the problem: for example, the sLDF could be mixed with a Gaussian distribution to mimic observational errors.
It is important to note that the effect on the pLDF of a spread in the input ingredients cannot be determined a priori, as it depends on how the distribution of the input ingredient affects the sLDF. In particular, it cannot be established whether the inclusion of distributed ingredients will render convergence to gaussianity more or less rapid. It is to be expected that, the further is the sLDF from gaussianity, the slower will the convergence of the pLDF to gaussianity be. For example,
if the distribution of the input ingredient is bimodal, bimodality will persist in the pLDF of small
![]() ,
and a larger number of stars will be required for the pLDF to converge to a Gaussian.
,
and a larger number of stars will be required for the pLDF to converge to a Gaussian.
![\begin{figure}
\par\includegraphics[width=7.35cm,clip]{3283f9.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img196.gif) |
Figure 9:
Monte Carlo simulations of clusters at solar metallicity and 5.5 Ma in the K band for different values of
|
| Open with DEXTER | |
We have shown in Sect. 6.2.1 that obtaining the pLDF through a convolution of the
sLDF is not simple; however, in simple scenarios
it is possible to solve it. In the following, we will consider a simple case
to illustrate this point. Our aim in this experiment is twofold:
first, we will derive an explicit expression for the pLDF at different
![]() 's
to show how its shape is related to the generating sLDF
and how it depends on
's
to show how its shape is related to the generating sLDF
and how it depends on
![]() .
Second, we want to show that, through our method, we are able to reproduce the main features of Monte Carlo simulations for any value of
.
Second, we want to show that, through our method, we are able to reproduce the main features of Monte Carlo simulations for any value of
![]() .
.
Let us assume a stellar luminosity function made up of three Gaussians, representing the dead stars, the MS, and the PMS respectively. The parameters of the three Gaussians are chosen so that the broad features of a set of Monte Carlo simulations for one star are reproduced (upper panels of Fig. 9; the vertical scale is logarithmic in the left panel and linear in the right panel). In particular, the mean and the variance of the triple-Gaussian LDF are constrained to be the same as those of the Monte Carlo simulations. We also confirmed a posteriori that ![]() and
and ![]() are very close, which is expected for similar distributions.
are very close, which is expected for similar distributions.
With a numerical routine, we convolved this sLDF with itself
![]() times. The resulting pLDFs for selected values of
times. The resulting pLDFs for selected values of
![]() are shown in Fig. 9 (solid line).
The features of these pLDFs can be understood qualitatively as follows:
the characteristic function of this sLDF is:
are shown in Fig. 9 (solid line).
The features of these pLDFs can be understood qualitatively as follows:
the characteristic function of this sLDF is:
| (59) |
The vertical sequence of panels shows how, increasing
![]() ,
the pLDF progressively becomes smoother and more symmetric, approaching a Gaussian shape.
In the same figure, Monte Carlo simulations with corresponding
,
the pLDF progressively becomes smoother and more symmetric, approaching a Gaussian shape.
In the same figure, Monte Carlo simulations with corresponding
![]() values are also shown (Cerviño & Valls-Gabaud 2003), and these coincide remarkably with the analytical pLDF. This is a consequence of having chosen a sLDF similar to the Monte Carlo distribution function for
values are also shown (Cerviño & Valls-Gabaud 2003), and these coincide remarkably with the analytical pLDF. This is a consequence of having chosen a sLDF similar to the Monte Carlo distribution function for
![]() (which, in turn, maps the underlying sLDF), and shows the power of the method: large Monte Carlo simulations become redundant, in the sense of being predictable, if one can characterize the sLDF and succeeds in convolving it.
(which, in turn, maps the underlying sLDF), and shows the power of the method: large Monte Carlo simulations become redundant, in the sense of being predictable, if one can characterize the sLDF and succeeds in convolving it.
![\begin{figure}
\par\includegraphics[width=7.4cm,clip]{3283f10.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img207.gif) |
Figure 10:
Comparison between the pLDFs obtained through sLDF convolutions (dashed line) and the Edgeworth's approximation (solid line) for clusters with different
|
| Open with DEXTER | |
Figure 10 compares the pLDFs obtained through convolution of the sLDF to their Edgeworth's approximation to the second order (Eq. (51)). Each panel corresponds to a different number of stars; the cluster in the upper panel, with
![]() ,
is the same one of the lower panel of Fig. 9. The Edgeworth's approximation improves visibly across the range of
,
is the same one of the lower panel of Fig. 9. The Edgeworth's approximation improves visibly across the range of
![]() considered: this is expected, because the closer is the pLDF to a Gaussian, the better is it approximated by Edgeworth's expression.
considered: this is expected, because the closer is the pLDF to a Gaussian, the better is it approximated by Edgeworth's expression.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{3283f11.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img209.gif) |
Figure 11:
|
| Open with DEXTER | |
Finally, in Fig. 11 we show a blow-up of Fig. 5 that compares the ![]() s of the pLDF obtained through the three different methods (Monte Carlo simulations, numerical convolution, and the Edgeworth's approximation). Several points deserve to be emphasized here:
s of the pLDF obtained through the three different methods (Monte Carlo simulations, numerical convolution, and the Edgeworth's approximation). Several points deserve to be emphasized here:
As has been pointed out several times, the main result of synthesis models is the mean value of the stellar luminosity function, which can be scaled to clusters of any size. We have also shown that the relative dispersion of the model results (the ratio
![]() )
decreases when
)
decreases when
![]() increases. However,
increases. However,
![]() increases in absolute terms, since it is proportional to
increases in absolute terms, since it is proportional to
![]() ,
a fact that
should be taken into account in the comparison of theoretical data to observed clusters. Furthermore, since each monochromatic luminosity has its own
,
a fact that
should be taken into account in the comparison of theoretical data to observed clusters. Furthermore, since each monochromatic luminosity has its own
![]() ,
they should be weighted differently in fits.
Finally, although some regions of the spectrum may have a quasi-Gaussian distribution, this will not happen in general with all the regions. Hence, not all the
frequencies (either in synthetic or in observed spectra)
are equivalent, or even suitable, to obtain the properties of the observed cluster.
,
they should be weighted differently in fits.
Finally, although some regions of the spectrum may have a quasi-Gaussian distribution, this will not happen in general with all the regions. Hence, not all the
frequencies (either in synthetic or in observed spectra)
are equivalent, or even suitable, to obtain the properties of the observed cluster.
![\begin{figure}
\par\includegraphics[width=8.2cm,clip]{3283f12.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img217.gif) |
Figure 12:
Cumulants of the monochromatic spectral energy distribution for a 1 Ga luminosity function assuming a Salpeter (1955) IMF in the mass range 0.15-120 |
| Open with DEXTER | |
As an example, Fig. 12 shows the first four cumulants of a region of the visual electromagnetic spectrum for the pLDF of a 1 Ga cluster with solar metallicity, obtained from the synthesis code sed@![]() using a Salpeter (1955) IMF in the mass range 0.1-120
using a Salpeter (1955) IMF in the mass range 0.1-120 ![]() .
The results are normalized to mass.
The isochrones used are from Girardi et al. (2002) covering a mass range from 0.15 to 100
.
The results are normalized to mass.
The isochrones used are from Girardi et al. (2002) covering a mass range from 0.15 to 100 ![]() and based on the solar models (Z = 0.019) by Girardi et al. (2000) and Bertelli et al. (1994) that include overshooting and a simple synthetic treatment of the thermal pulses AGB phase (Girardi & Bertelli 1998). The atmosphere models are taken from the high resolution library by González Delgado et al. (2005); Martins et al. (2005) based on PHOENIX (Allar et al. 2001; Hauschildt & Baron 1999), the ATLAS 9 odfnew library (Castelli & Kurucz 2003) computed with SPECTRUM (Gray & Corbally 1994), the
ATLAS 9 library (Kurucz 1991) computed with SYNTSPEC (Hubeny et al. 1995), and TLUSTY (Lanz & Hubeny 2003) at [Fe/H] = 0.0 dex.
and based on the solar models (Z = 0.019) by Girardi et al. (2000) and Bertelli et al. (1994) that include overshooting and a simple synthetic treatment of the thermal pulses AGB phase (Girardi & Bertelli 1998). The atmosphere models are taken from the high resolution library by González Delgado et al. (2005); Martins et al. (2005) based on PHOENIX (Allar et al. 2001; Hauschildt & Baron 1999), the ATLAS 9 odfnew library (Castelli & Kurucz 2003) computed with SPECTRUM (Gray & Corbally 1994), the
ATLAS 9 library (Kurucz 1991) computed with SYNTSPEC (Hubeny et al. 1995), and TLUSTY (Lanz & Hubeny 2003) at [Fe/H] = 0.0 dex.
The figure shows the region around H![]() .
As expected from previous plots at these ages (Fig. 7), the values of
.
As expected from previous plots at these ages (Fig. 7), the values of ![]() and
and ![]() are quite low. However, not all the wavelengths have the same statistical significance. In particular, the H
are quite low. However, not all the wavelengths have the same statistical significance. In particular, the H![]() line shows the largest values of
line shows the largest values of ![]() and
and ![]() ,
so in undersampled clusters its profile will be difficult to fit. On the other hand, the profile of Ca II H + H
,
so in undersampled clusters its profile will be difficult to fit. On the other hand, the profile of Ca II H + H![]() is a quite robust result, with a low relative dispersion and
is a quite robust result, with a low relative dispersion and ![]() and
and ![]() values close to the continuum level. Finally, the Ca II K line, with
values close to the continuum level. Finally, the Ca II K line, with ![]() and
and ![]() values similar to those of the continuum, has a high relative dispersion. Summarizing, fitting the theoretical models of Ca II lines, including their profiles, to observed data would yield more realistic results than fitting either the intensity, the equivalent width or the profile of H
values similar to those of the continuum, has a high relative dispersion. Summarizing, fitting the theoretical models of Ca II lines, including their profiles, to observed data would yield more realistic results than fitting either the intensity, the equivalent width or the profile of H![]() .
Of course, these conclusions depend on the age and metallicity.
.
Of course, these conclusions depend on the age and metallicity.
In this section we will briefly discuss several potential extensions of the formalism that could have a strong impact in the analysis of stellar populations. Details on a few examples will also be given.
Since in this paper we have only considered the case of SSPs, maybe the most important pending issue is the extension to other scenarios of star formation. This topic will be covered in a forthcoming paper.
A current limitation of the formalism is that it only deals with integrated properties that scale linearly with the number of stars in the cluster. In the future, the formalism will be extended to include the case of luminosity ratios. To solve this problem, in addition to the cumulants of the distribution function of the ensemble, it is also necessary to obtain the correlation function of the corresponding quantities.
A further assumption of the formalism in its present stage is that the stellar population
has a fixed number of stars
![]() .
It is our intention to extend the formalism by including
the case of a collection of populations with varying number of stars.
This extended formalism could be applied to several problems,
such as the analysis of stellar populations in pixels,
which requires computing the global distribution resulting from the distribution of stars in each pixel and the distribution of numbers of stars across pixels;
the distribution of luminosities in globular clusters; the estimation
of the difference between luminosity profiles in galaxies inferred by means of a comparison with the mode and the mean respectively; the comparison of theoretical SBF with observed ones;
and the comparison among different Monte Carlo simulations performed with a total fixed mass.
A few of these prospective applications will be discussed further in the remainder of this section.
.
It is our intention to extend the formalism by including
the case of a collection of populations with varying number of stars.
This extended formalism could be applied to several problems,
such as the analysis of stellar populations in pixels,
which requires computing the global distribution resulting from the distribution of stars in each pixel and the distribution of numbers of stars across pixels;
the distribution of luminosities in globular clusters; the estimation
of the difference between luminosity profiles in galaxies inferred by means of a comparison with the mode and the mean respectively; the comparison of theoretical SBF with observed ones;
and the comparison among different Monte Carlo simulations performed with a total fixed mass.
A few of these prospective applications will be discussed further in the remainder of this section.
Finally, the formalism developed here for the treatment of luminosity functions can also be applied to stellar yields. All the statistical considerations that we have made about luminosities can be easily translated into equivalent issues in the field of chemical evolution, although in that case the star formation history would have a fundamental role, and the differential equations that describe (deterministically) the chemical evolution would become stochastic differential equations, whose mean would coincide with the results obtained deterministically. As in the present case, comparing the mean against observations can produce a bias that depends strongly on the shape of the distribution.
The following sections will give more details on a few examples among these.
SBF observations from galaxies and globular clusters have been proposed as a test of evolutionary tracks and isochrones (e.g. Cantiello et al. 2003, among others). This test is based on the comparison between the observed variance across pixels in the image of a galaxy and the variance expected on statistical grounds. However, there are several inconsistencies in this method as is applied at present:
In a similar way, the luminosity distributions of globular clusters in galactic halos could be compared to the corresponding distributions obtained theoretically, either in terms of moments or in terms of the explicit shape of the distribution. The possibility of obtaining higher-order moments, such as the skewness, helps constraining the distribution, which is necessary to test evolutionary tracks and isochrones. However, there are drawbacks similar to those of the previous case, with the only exception of the assumption on the validity of a SSP, which in a galactic halo is probably verified.
To pursue the goals sketched above, it is imperative to know the initial distribution of cluster masses. In the following, we will show qualitatively that our method can also contribute toward this goal, by disclosing a potential source of bias in the use of synthesis models for the determination of the mass distribution of globular clusters. Note, however, that a quantitative conclusion cannot yet be reached.
![\begin{figure}
\par\includegraphics[width=7.8cm,clip]{3283f13.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img221.gif) |
Figure 13:
Luminosity distribution functions in V for clusters with the LMC metallicity, approximated by the Edgeworth's series, for several ages and cluster masses: 10
|
| Open with DEXTER | |
In Fig. 13 we show the pLDFs in
![]() for clusters with the LMC metallicity obtained from the isochrones by Girardi et al. (2002) using the Edgeworth's approximation. We have plotted the distributions that correspond to the extremes of the age ranges used by Zhang & Fall (1999). The pLDFs correspond to cluster masses of 10
for clusters with the LMC metallicity obtained from the isochrones by Girardi et al. (2002) using the Edgeworth's approximation. We have plotted the distributions that correspond to the extremes of the age ranges used by Zhang & Fall (1999). The pLDFs correspond to cluster masses of 10
![]() (solid line), 10
(solid line), 10
![]() (dashed line), and 10
(dashed line), and 10
![]() (dotted line). The mean values of the corresponding pLDFs are marked as vertical lines.
(dotted line). The mean values of the corresponding pLDFs are marked as vertical lines.
The figure shows that, given the asymmetry of the stellar luminosity function, most observed clusters will have smaller luminosities than the mean, i.e. smaller luminosities than those predicted by a standard code. The straightforward implication is that the mass of observed clusters inferred by means of a comparison with standard models is, in most cases, underestimated, with a bias larger for smaller clusters (see also Gilfanov et al. 2004) and younger ages.
This effect is highly relevant for young and undersampled clusters. In particular, assuming that the age estimation obtained by Zhang & Fall (1999) is not biased, the figure clearly shows that there can be
a systematic underestimation of the mass of younger clusters, an hence, an overestimation of the number of low-mass clusters. In the cluster mass range considered, this effect is more relevant in the 104 to 10
![]() interval. This fact could
change the shape of the distribution of the initial cluster masses obtained by Zhang & Fall (1999), particularly in the low mass range, making it shallower or even inverting the slope. However, this result is only a qualitative application of the new formalism, and the example above should not be taken literally. To establish a firm conclusion it is necessary to apply the
probabilistic treatment also to the determination of ages.
interval. This fact could
change the shape of the distribution of the initial cluster masses obtained by Zhang & Fall (1999), particularly in the low mass range, making it shallower or even inverting the slope. However, this result is only a qualitative application of the new formalism, and the example above should not be taken literally. To establish a firm conclusion it is necessary to apply the
probabilistic treatment also to the determination of ages.
The individual stars in a resolved population can be used to trace the sLDF. This can be done by comparing the first four cumulants computed by means of current synthesis models to the corresponding observed quantities. Resolved populations have several advantages:
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{3283f14.eps}\end{figure}](/articles/aa/full/2006/20/aa3283-05/img224.gif) |
Figure 14:
Main parameters of the luminosity function for several photometric bands obtained from the isochrones by Marigo & Girardi (2001) (bold lines) and Bertelli et al. (1994); Girardi et al. (2000) (light lines), assuming a Salpeter (1955) IMF in the mass range 0.15-120 |
| Open with DEXTER | |
The method proposed in Sect. 8.4 can also be used to compare the predictions of different sets of isochrones, since it is also sensitive to the number of stars expected in each region of the isochrone (which is almost IMF-independent for PMS stars). A similar method has been proposed by Wilson & Hurley (2003).
To illustrate the point, we show in Fig. 14 the first four cumulants of the
sLDF for different bands and ages using the isochrones by Marigo & Girardi (2001), computed following FCT requirements explicitly, and by Girardi et al. (2000) and Bertelli et al. (1994). We have assumed a Salpeter (1955) IMF in the mass range 0.15-120 ![]() normalized by the total number of stars, and the results have been obtained by a direct integration of the isochrones.
Note that, although the mean values and the
normalized by the total number of stars, and the results have been obtained by a direct integration of the isochrones.
Note that, although the mean values and the
![]() ratios are similar across the isochrone sets, there are large differences in
ratios are similar across the isochrone sets, there are large differences in ![]() and
and ![]() at some ages. This tells us, without even knowing the luminosity distribution function, that there are strong differences between both sets of isochrones, which can be directly related with differences in the treatment of stellar evolution, e.g. differences in the lifetimes of different phases.
at some ages. This tells us, without even knowing the luminosity distribution function, that there are strong differences between both sets of isochrones, which can be directly related with differences in the treatment of stellar evolution, e.g. differences in the lifetimes of different phases.
The method described in this work can be implemented in the VO as an automatized tool for the analysis of observed data, since synthetic models can be given in terms of probability distributions suitable to be used in data mining algorithms or in Bayesian analysis. To achieve this goal, an appropriate theoretical data model is necessary; the definition of such model is a task that is currently being carried out by the Theory interest group of the International Virtual Observatory Alliance (http://www.ivoa.net). In addition, the extension of this probabilistic formalism to distributions of luminosity ratios, which are used in diagnostic diagrams, would be an asset for the development of more robust VO analysis tools.
This paper considers a series of problems in population synthesis that arise as a consequence of the distributed nature of stellar populations, and develops a new probabilistic formalism that takes them into account. With this formalism it is possible to reproduce and explain the features of Monte Carlo simulations without the need of performing them. The new formalism has several advantages with respect to Monte Carlo simulations in terms of generality and reliability. Unlike Monte Carlo simulations, it is not affected by sampling errors in the estimation of the moments. Unfortunately, its exact application requires computing repeated convolutions, and we do not know any computational tool that can perform this task efficiently. Although the formalism is complete for luminosities, it must still be extended to the case of ratios. A summary of our conclusions follows:
Acknowledgements
This work has been the effort of many years of reflection on the sampling problems of the IMF. Therefore, there are lots of people that at some moment or other have contributed to this work with comments and suggestions. First of all, we would like to acknowledge Luis Manuel Sarro Baró, whose incisive questions shed light on the problem of distributions in bins. We also acknowledge useful discussions with Marat Gilfanov. Steve Shore, Juan Betancort, Enrique Pérez, and David Valls-Gabaud made useful suggestions on statistics, while Georges Meynet, Daniel Schaerer, Sandro Bressan, Scilla Degl'Innocenti, Enzo Brocato, and Leo Girardi helped us to understand track interpolation issues. We acknowledge Gabriella Raimondo, Rosa Amelia González, and Gustavo Bruzual for several useful conversations on the subject of SBF and Monte Carlo simulations. We thank Alberto Buzzoni for very instructive discussions of synthesis models. The first draft of the paper was greatly improved thanks to the constructive criticism and encouraging comments of an anonymous referee. Joli Adams, our A&A language editor, displayed infinite patience in helping us find just the right word. N.C.L. acknowledges Carlos, Dario, and Eva for providing experimental facts showing that the application of mean values to individual data is a statistical fallacy.
This work was supported by the Spanish Programa Nacional de Astronomía y Astrofísica through the project AYA2004-02703. MC is supported by a Ramón y Cajal fellowship. VL is supported by a CSIC-I3P fellowship.
This section contains an exhaustive summary of the notation used and its rationale.
All these quantities depend on the total number of stars
![]() in the population, as well as on the age of the population:
in the population, as well as on the age of the population: