A&A 438, 169-185 (2005)
DOI: 10.1051/0004-6361:20042267
M. Lombardi1,2
1 - European Southern Observatory, Karl-Schwarzschild-Straße 2,
85748 Garching bei München, Germany
2 -
University of Milan, Department of Physics, via Celoria 16, 20133
Milan, Italy
Received 27 October 2004 / Accepted 22 March 2005
Abstract
We consider from a general point of view the problem of determining
the extinction in dense molecular clouds. We use a rigorous
statistical approach to characterize the properties of the most
widely used optical and infrared techniques, namely the star count
and the color excess methods. We propose a new maximum-likelihood
method that takes advantage of both star counts and star colors to
provide an optimal estimate of the extinction. Detailed numerical
simulations show that our method performs optimally under a wide
range of conditions and, in particular, is significantly superior to
the standard techniques for clouds with high column-densities and
affected by contamination by foreground stars.
Key words: dust, extinction - methods: statistical - ISM: clouds - infrared: ISM - stars: formation
A detailed comprehension of the structure and physical properties of dark molecular clouds is a critical step to understand fundamental processes such as star and planet formation. Still, after several decades of investigations, very little is known about dark clouds, about their relationship to the diffuse interstellar medium, and about the composition and evolution of the dust grains present in the clouds.
Molecular clouds are composed of approximately ![]() molecular
hydrogen and helium, but due to the absence of a dipole moment these
molecules are virtually undetectable at the low temperature (
molecular
hydrogen and helium, but due to the absence of a dipole moment these
molecules are virtually undetectable at the low temperature (![]()
![]() )
that characterize these objects. As a result, astronomers
have been using different tracers to study the density distribution of
molecular clouds. Historically, the first technique was based on a
statistical analysis of the angular density of stars observed through
a cloud (Wolf 1923; Bok 1937). This
method, known as star counts, uses the dust (which is responsible for
the extinction of light) as a tracer of
)
that characterize these objects. As a result, astronomers
have been using different tracers to study the density distribution of
molecular clouds. Historically, the first technique was based on a
statistical analysis of the angular density of stars observed through
a cloud (Wolf 1923; Bok 1937). This
method, known as star counts, uses the dust (which is responsible for
the extinction of light) as a tracer of ![]() and
and ![]() .
.
More recently, radio observations of carbon monoxide (CO) and its
isotopes have been used to study the spatial distribution and the
physical conditions of molecular clouds, under the assumption that CO
is a reliable tracer of the matter in the cloud, i.e. that the ratio
![]() is
approximately constant. Radio spectroscopy techniques have provided
extremely effective in studying the most dense regions (above
is
approximately constant. Radio spectroscopy techniques have provided
extremely effective in studying the most dense regions (above
![]() )
and, more importantly, give dynamical
information on the cloud structure. However, with the advent of
various dust detectors in the near-infrared (NIR), far infrared,
millimeter, and sub-millimeter bands, it has become clear that several
poorly constrained processes (e.g., deviations from thermodynamic
equilibrium, opacity variations, chemical evolution, and more
importantly depletion of molecules) can significantly affect the
results of analyses based on radio observations
(e.g. Harjunpää et al. 2004; Lada et al. 1994; Alves et al. 1999).
)
and, more importantly, give dynamical
information on the cloud structure. However, with the advent of
various dust detectors in the near-infrared (NIR), far infrared,
millimeter, and sub-millimeter bands, it has become clear that several
poorly constrained processes (e.g., deviations from thermodynamic
equilibrium, opacity variations, chemical evolution, and more
importantly depletion of molecules) can significantly affect the
results of analyses based on radio observations
(e.g. Harjunpää et al. 2004; Lada et al. 1994; Alves et al. 1999).
The reddening of background stars offers a natural method to study the distribution of dust in molecular clouds, and thus the hydrogen column density. This technique can be better applied to the infrared bands, which compared to optical bands are less affected by extinction and are less sensitive to the physical properties of the dust grains (Mathis 1990). Before the advent of large format array cameras, the lack of instrumental sensitivity clogged infrared observations to small, dense clouds (e.g. Casali 1986; Frerking et al. 1982; Jones et al. 1980,1984). More recently, infrared arrays have made it possible to measure thousands of stars and to extend the original technique to entire molecular cloud complexes (Alves et al. 2001; Lada et al. 1999; Lombardi & Alves 2001; Lada et al. 1994). Such measurements are free of the complications that plague molecular-line data and permit a detailed analysis of the cloud density distribution.
Although the success of the NIR color excess method is evident, there is still a need for a deeper understanding of its limitations, statistical biases, and uncertainties. The aim of this paper is twofold: (i) to study in detail the statistical properties of the star count and color excess methods and (ii) to describe a new, optimal method based on a maximum-likelihood analysis. The method is described here for NIR observations, but could equally well be applied to other infrared bands for which the extinction law and the intrinsic color distribution are known with good accuracy. The paper is organized as follows. In Sect. 2 we introduce our formalism and consider from a statistical point of view the extinction of stars by a foreground cloud. The two main techniques used to obtain extinction measurements, namely the star count and the NIR color excess methods, are discussed in Sect. 3. In Sect. 4 we describe the new maximum-likelihood method and show by means of numerical simulations that it performs excellently even in the presence of a significant contamination by foreground stars. Our conclusions are briefly reported in Sect. 5. Finally, in Appendix A we consider the statistical properties of the median and of related estimators used often in infrared studies of dark clouds to remove the effects of foreground stars.
Suppose that N stars with magnitudes (on a given band)
![]() are observed in a given region of the sky (hereafter we will use
the hat
are observed in a given region of the sky (hereafter we will use
the hat ![]() to denote measured quantities). These observed
magnitudes depend on the original, unreddened, absolute star
magnitudes
to denote measured quantities). These observed
magnitudes depend on the original, unreddened, absolute star
magnitudes ![]() ,
on the star distances
,
on the star distances ![]() ,
on the
individual extinctions
,
on the
individual extinctions ![]() ,
and on the photometric errors
,
and on the photometric errors
![]() .
In particular, we have
.
In particular, we have
In order to consider the most general situation in a proper statistical way, we introduce several probability distributions:
We assume that both
pA(A | D) and
![]() are
normalized to unity, i.e.
are
normalized to unity, i.e.
Equation (1) can be used to obtain the probability
distribution of reddened magnitudes pm(m). Using the previous
definitions we find
Equations (6) and (7) are basic equations of this paper. However, in the form they are written, they are by far too general to be useful in practical cases.
In order to make use of the general relations written above we introduce a number of useful simplifications.
First, we note that so far we have considered observations carried out
on a single band. In order to threat multi-band data, we
introduce a reddening law as follows: for any band
![]() ,
the extinction
,
the extinction ![]() is given by
is given by
A second important assumption that we will use regards the functional
form of
![]() .
First, we will assume that this function can be
separated in M and D, i.e. can be written as the product of two
functions, one involving M only, and one involving D only:
.
First, we will assume that this function can be
separated in M and D, i.e. can be written as the product of two
functions, one involving M only, and one involving D only:
![]() .
In practice, this assumption is
equivalent to saying that we observe a single "population'' of stars
at all distances. Since observations show that star number counts are
well approximated by an exponential law of the form
.
In practice, this assumption is
equivalent to saying that we observe a single "population'' of stars
at all distances. Since observations show that star number counts are
well approximated by an exponential law of the form
![]() (where the exponent
(where the exponent
![]() is
approximately independent of the band considered in the NIR), we also
assume that pM(M) follows a similar law. We then write
is
approximately independent of the band considered in the NIR), we also
assume that pM(M) follows a similar law. We then write
Using Eqs. (9) and (8) we can slightly simplify
Eq. (6) by performing the integration over D:
Equation (10) shows an interesting property of extinction
studies: the probability distribution pm(m) depends on
![]() only through
only through
![]() .
This point is particularly
important since it shows an intrinsic limitation of extinction
measurements. Indeed, all observables are derived from
.
This point is particularly
important since it shows an intrinsic limitation of extinction
measurements. Indeed, all observables are derived from
![]() ,
the distribution of observed magnitudes, and this
function depends only on pm(m) (other than observational "limiting
factors'' such as
,
the distribution of observed magnitudes, and this
function depends only on pm(m) (other than observational "limiting
factors'' such as
![]() or
or
![]() ).
Since, as noted above, pm(m) does not depend directly on
).
Since, as noted above, pm(m) does not depend directly on
![]() ,
any estimator based on observed magnitudes
only
,
any estimator based on observed magnitudes
only![]() will not provide any information on
will not provide any information on
![]() directly but (in the best case scenario) only on
directly but (in the best case scenario) only on
![]() .
Since
.
Since
![]() is a sort of convolution of
is a sort of convolution of
![]() ,
in general it is not possible to have a complete
knowledge on
,
in general it is not possible to have a complete
knowledge on
![]() ,
not even if we know the star density
distribution
,
not even if we know the star density
distribution ![]() ;
this limitation, among other things, prevents
us from gathering information on the three-dimensional structure of a
molecular cloud.
;
this limitation, among other things, prevents
us from gathering information on the three-dimensional structure of a
molecular cloud.
A case where, instead, the function
![]() can be
recovered is a deterministic model for the extinction,
i.e. a cloud complex whose extinction
can be
recovered is a deterministic model for the extinction,
i.e. a cloud complex whose extinction ![]() depends directly on the
distance D (and, thus, is not a random variable). In this case we
have
depends directly on the
distance D (and, thus, is not a random variable). In this case we
have
Finally, we consider a very simple deterministic model for
![]() that describes a thin cloud at a
distance D0 with uniform column density
that describes a thin cloud at a
distance D0 with uniform column density ![]() :
:
Above, in Eq. (2), we introduced the completeness function
c(m), which gives the probability to detect a star of
magnitude m. Typically, c(m) is close to unity for bright stars,
and vanishes for very faint stars; note however that c(m) might be
smaller than unity at low m in crowded fields or close to bright
objects. The completeness function c(m) enters naturally in the
definition of the error probability distribution
![]() ,
which can be written as
,
which can be written as
In order to carry out some simplifications (see below
Sect. 4.2), we also consider a different
representation of the completeness function in which the order of the
two random processes described above is swapped: this leads to a
completeness function
![]() defined in terms of the
observed magnitude. In other words, we first generate for
every star the "observed'' magnitude
defined in terms of the
observed magnitude. In other words, we first generate for
every star the "observed'' magnitude ![]() according to
a probability distribution
according to
a probability distribution
![]() ,
and then
decide whether the star is really observed using a second random
process controlled by the completeness function
,
and then
decide whether the star is really observed using a second random
process controlled by the completeness function
![]() .
This implies, among other things, a modification of Eq. (7),
that now becomes
.
This implies, among other things, a modification of Eq. (7),
that now becomes
Although Eqs. (25) and (26) show that the
description of the completeness c(m) in terms of the true reddened
magnitude m is more general than the description
![]() in
terms of the observed magnitude
in
terms of the observed magnitude ![]() ,
we argue that the latter is
more practical to use:
,
we argue that the latter is
more practical to use:
So far we have focused our analysis on single-band measurements. In order to extend the discussion to observations carried out in different bands, we need to generalize the relevant probability distributions.
We denote
![]() the magnitudes
of a star in
the magnitudes
of a star in ![]() different bands; in general, we use bold
symbols such as
different bands; in general, we use bold
symbols such as ![]() to indicate quantities that have different
values in the various bands. We will threat these as vector
quantities; in this way, e.g., the generalization of Eq. (1)
can written as
to indicate quantities that have different
values in the various bands. We will threat these as vector
quantities; in this way, e.g., the generalization of Eq. (1)
can written as
Since we are now working with observations in different bands, we need
also to generalize
![]() .
We define thus
.
We define thus
![]() ,
the probability to have a star with absolute magnitudes
,
the probability to have a star with absolute magnitudes ![]() at
distance D from us. Using this distribution we can rewrite
Eq. (6) as
at
distance D from us. Using this distribution we can rewrite
Eq. (6) as
The integral of
![]() over all admissible values
of
over all admissible values
of
![]() gives the expected local density of stars
gives the expected local density of stars ![]() :
:
When using the alternate completeness functions
![]() expressed in terms of the observed
magnitudes
expressed in terms of the observed
magnitudes
![]() ,
Eq. (30) can be rewritten
as
,
Eq. (30) can be rewritten
as
As for the single-band case, we consider a number of realistic and useful simplifications that will allow us to take advantage of the formalism introduced above in practical cases.
First, we still take
![]() to be separable into
to be separable into
![]() .
Furthermore, we adopt for
.
Furthermore, we adopt for
![]() a simple functional form, which is sufficiently accurate for our
purposes. Since we know that
a simple functional form, which is sufficiently accurate for our
purposes. Since we know that
![]() with
with
![]() approximately independent of the band, and since stars appear
to have a limited scatter in their NIR colors, we write
approximately independent of the band, and since stars appear
to have a limited scatter in their NIR colors, we write
We will describe in this section the star counts and color excess methods in order to better describe the advantages and limitations of them.
In the 18th century the English astronomer William Herschel noted that some regions presented few stars and, following Newton's idea of a perfectly transparent space, interpreted these "holes in the sky'' as a real lack of stars. This misconception survived the discovery of individual dark clouds (Barnard 1919) and had serious consequences on Shapley's calibration of the distance scale for Cepheids. The "discovery'' of dust in our Galaxy took place only in 1930 when Trumpler showed its importance in dimming the light coming from distant open clusters. Finally, in recent decades dust has no longer been seen only as annoying "fog'' obscuring the light of background sources, and has been shown to have a tremendous impact on the evolution of galaxies and on the formation of stars and stellar systems (see Li & Greenberg 2003 for a detailed historical review).
It has long been recognized (Wolf 1923) that measurements of the local density of stars in different regions of the sky can be used to map the extinction. The original technique consisted in comparing the number of stars in magnitude bins in regions subject to extinction with the number of stars in regions where the extinction is (supposedly) negligible. This technique was then improved by Bok (1956) which suggested to use counts up to a limiting magnitude to reduce the error. In the past, the star count technique was mainly applied to optical data (typically visually inspected Smith plates; e.g. Dickman 1978; Mattila 1986; Andreazza & Vilas-Boas 1996). In the last decade, however, near-infrared digital data have been available, and the star count technique has been finally applied to NIR observations (e.g. Cambresy et al. 1997). In this respect, a key role has been played by large NIR surveys such as the Two Micron All Sky Survey (2MASS; Kleinmann et al. 1994) and the Deep NIR southern Sky Survey (DENIS; Epchtein et al. 1997).
The star count method is easily described using our notation. We
first note that, as for multi-band probability distributions, the
integral of
![]() over
over ![]() gives the local density
of stars
gives the local density
of stars ![]() (cf. Eq. (31)):
(cf. Eq. (31)):
Clearly, a single measurement of
![]() cannot be
used to derive the distribution
cannot be
used to derive the distribution
![]() .
However, in the
simplest case where all stars are background to a thin cloud, so that
.
However, in the
simplest case where all stars are background to a thin cloud, so that
![]() ,
we find the classical relation
,
we find the classical relation
Table 1: The extinction law in different infrared bands (taken from Rieke & Lebofsky 1985 and van de Hulst 1946).
Although the estimator (40) can be applied to thin clouds
only, in principle more general situations can also be handled by
taking advantage of the particular form of Eq. (38). We
first observe that the integral appearing in the r.h.s. of this
equation is reminiscent of a Laplace's transform. Given a real
function f(x) defined for non-negative values x, its Laplace's
transform is defined as
Let us consider, for example, the case of the thin cloud approximation
described in Eq. (17). Since, in general, the fraction fof foreground stars is not known, we want to estimate both ![]() and
f in a given patch of the sky. (Although f can be taken to be
constant in many cases, changes on this quantity have to be expected
for different regions of large cloud complexes because of the geometry
of the cloud and of changes of star densities due to the Galactic
structure.) For this, we insert Eq. (17) in
Eq. (38), thus obtaining a simple generalization of
Eq. (40):
and
f in a given patch of the sky. (Although f can be taken to be
constant in many cases, changes on this quantity have to be expected
for different regions of large cloud complexes because of the geometry
of the cloud and of changes of star densities due to the Galactic
structure.) For this, we insert Eq. (17) in
Eq. (38), thus obtaining a simple generalization of
Eq. (40):
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f01.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img164.gif) |
Figure 1:
The cumulative probability distribution for
|
| Open with DEXTER | |
It is interesting to investigate in more detail the estimator derived
from Eq. (43), i.e.
Further statistical properties of the estimator (44) can be
better evaluated using numerical methods. Figure 1 shows,
as an example, the expected cumulative probability distributions for
![]() for some typical cases. As expected, the cumulative
distributions reach 0.5 around the true value for
for some typical cases. As expected, the cumulative
distributions reach 0.5 around the true value for ![]() ,
but the
expected measurement errors can be very large, especially at high
column densities. The numerical analysis of Eq. (44) also
shows that the estimator is significantly biased. In general, in the
limit
,
but the
expected measurement errors can be very large, especially at high
column densities. The numerical analysis of Eq. (44) also
shows that the estimator is significantly biased. In general, in the
limit
![]() ,
the estimator is biased toward
large values of
,
the estimator is biased toward
large values of
![]() ,
i.e.
,
i.e.
![]() ;
the opposite happens for
;
the opposite happens for
![]() (see
Fig. 2). This change in behavior can be understood by
observing that, if
(see
Fig. 2). This change in behavior can be understood by
observing that, if ![]() is large, then
is large, then
![]() is
small and thus we simply do not have enough background stars to probe
high column densities.
is
small and thus we simply do not have enough background stars to probe
high column densities.
Interestingly, Eq. (46) is a reasonably good approximation of
the true variance of
![]() .
Typically, this approximation
slightly underestimates the true variance of
.
Typically, this approximation
slightly underestimates the true variance of
![]() ,
but again the
opposite happens for low values of
,
but again the
opposite happens for low values of
![]() .
.
The dust present in molecular clouds produces different amounts of obscuration in different color bands (see Table 1), so that background stars appear reddened. Hence, the color excess in the red part of the spectrum of background stars can be used to measure the extinction along the line of sight.
Historically, the color excess technique has been impeded by the limited instrumental sensitivity to small regions (Jones et al. 1980; Frerking et al. 1982; Jones et al. 1984). However, in the early 1990s, with the advent of near-infrared arrays, it became possible to accurately measure the NIR magnitudes of many stars from single pointing observations. This new technology was first exploited by Lada et al. (1994), and since then has been successfully applied to many molecular clouds (e.g. Alves et al. 2001; Horner et al. 1997; Lada et al. 1999).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f02.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img176.gif) |
Figure 2:
The bias (thick lines) and error (thin lines) on
|
| Open with DEXTER | |
Lada's technique (called "near-infrared color excess'' or NICE) is based on measurements of a NIR color (e.g., H - K) of many stars. Since stars have relatively well defined colors in the infrared, a significant intervening extinction can be detected as a reddening. Note that a key point of the NICE method (and of similar methods based on the reddening of stars; see, e.g., Schultheis et al. 1999) is the assumption that all stars belong to a homogeneous population.
The NICE method can be quantitatively described using the
notation introduced so far. In particular, from Eq. (29) we
have
As shown by Lombardi & Alves (2001), one can indeed take full
advantage of observations carried out in different bands to obtain
more accurate column density measurements. The improved technique,
called NICER (NICE Revised) optimally balances the
information from different bands and different stars. As a by-product
of the analysis, NICER also allows us to evaluate the
expected error on the column density map, which is useful to estimate
the significance on the detection of substructures and cores. The
NICER technique can be described using the following simple
argument. Equation (50) written above can be taken to be a
system of
![]() equations to be approximately solved for
equations to be approximately solved for
![]() ,
the approximation being made necessary because we can only
measure
,
the approximation being made necessary because we can only
measure
![]() and
and
![]() with limited accuracy. The "best'' solution for
with limited accuracy. The "best'' solution for ![]() can been obtained by minimizing the chi-square quantity
can been obtained by minimizing the chi-square quantity
Both the NICE and NICER estimators appear
to be unbiased provided that: (i) there are no foreground stars and
(ii) the measured colors
![]() are unbiased estimates of the
true colors
are unbiased estimates of the
true colors
![]() .
.
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f03.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img198.gif) |
Figure 3:
The bias for the NICE method due to the different
completeness at low and high column densities. This plot is
evaluated by generating 100 000 stars for various values of
|
| Open with DEXTER | |
In reality, even if the two conditions considered above are satisfied,
both color excess methods can still be biased because of selection
effects introduced by the completeness function. To understand this
point let us make a simple example. Suppose that we carry out our
observations in two bands, ![]() and
and ![]() ,
and that both
completeness functions
,
and that both
completeness functions
![]() are not vanishing only
on a narrow magnitude range. In this case we would always have
are not vanishing only
on a narrow magnitude range. In this case we would always have
![]() (because a star is observed in both bands
only if m1 and m2 are inside the narrow detection window), and
thus we would always measure
(because a star is observed in both bands
only if m1 and m2 are inside the narrow detection window), and
thus we would always measure
![]() ,
independently of the
real column density. Although unrealistic, this example shows that we
must expect a bias for the NICE method; the argument for the
NICER method is similar and leads to the same conclusion.
,
independently of the
real column density. Although unrealistic, this example shows that we
must expect a bias for the NICE method; the argument for the
NICER method is similar and leads to the same conclusion.
The bias of these two methods depends on the details of the
probability distribution
![]() and of the completeness
functions
and of the completeness
functions
![]() .
However, as an example, we
evaluated the expected bias for various values of the column density
and for the typical probability distributions that we expect for the
2MASS catalog. As shown in Fig. 3, the bias in the case
considered appears to be limited, below 0.2 in
.
However, as an example, we
evaluated the expected bias for various values of the column density
and for the typical probability distributions that we expect for the
2MASS catalog. As shown in Fig. 3, the bias in the case
considered appears to be limited, below 0.2 in ![]() ,
and has a
characteristic shape: it vanishes for
,
and has a
characteristic shape: it vanishes for
![]() ,
increases quickly for
,
increases quickly for
![]() ,
and finally saturates for
,
and finally saturates for
![]() .
This behavior has
a simple explanation:
.
This behavior has
a simple explanation:
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f04.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img207.gif) |
Figure 4: A graphic explanation of the bias plotted in Fig. 3. At low column densities, we select stars mainly on their K magnitude, while at high column densities we mainly select using their H magnitude. As a result, the average intrinsic color (dotted line) of the observed stars (gray bands) changes toward lower H - K values. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f05.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img208.gif) |
Figure 5:
The bias for the NICE method due to the
contamination by foreground stars. Solid lines represents, for
different fractions of foreground stars, the median of the
distribution of the measured column densities. Dashed lines,
instead show the expectation value for the median of
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f06.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img209.gif) |
Figure 6:
The effect of a foreground star contamination f = 0.1 on the
distribution of column densities for different values of |
| Open with DEXTER | |
For regions with very high column density, it is normally quite easy
to identify and remove foreground stars because of their anomalous
colors with respect to the reddened background stars (see, e.g.,
Alves et al. 2001). Some authors
(e.g. Cambrésy et al. 2002) make use of this information to
also remove stars in less dense regions using the following strategy.
The angular density
![]() of foreground stars is
determined using dense regions (where the foreground/background
identification is easy); then, for any region of the cloud, the kbluer stars are thrown away, where
of foreground stars is
determined using dense regions (where the foreground/background
identification is easy); then, for any region of the cloud, the kbluer stars are thrown away, where
![]() is the expected number of foreground stars in the
analyzed region (deduced from the foreground density measured in the
dense regions). This technique is quite simple and reasonably
effective, but unfortunately introduces a bias at low extinctions.
Consider, indeed, the limiting case where we have a negligible
extinction
is the expected number of foreground stars in the
analyzed region (deduced from the foreground density measured in the
dense regions). This technique is quite simple and reasonably
effective, but unfortunately introduces a bias at low extinctions.
Consider, indeed, the limiting case where we have a negligible
extinction
![]() .
The distinction between foreground and
background stars is in this situation ambiguous, and thus the
.
The distinction between foreground and
background stars is in this situation ambiguous, and thus the
![]() bluer objects will likely include also some background
stars. Hence, the results will be biased toward higher column
density. The exact evaluation of the bias is non trivial, but can be
carried out using the techniques described in
Appendix A. Here we report only an approximated
result valid for
bluer objects will likely include also some background
stars. Hence, the results will be biased toward higher column
density. The exact evaluation of the bias is non trivial, but can be
carried out using the techniques described in
Appendix A. Here we report only an approximated
result valid for
![]() (see Eq. (A.15)),
(see Eq. (A.15)),
From the discussion above, it is clear that both the star count and
the NICE(R) methods can produce unsatisfactory
results. On one hand, the star count technique has a low
signal-to-noise ratio and produces significantly biased results at
high column densities (see Fig. 2). On the other hand, the
color excess technique is more sensitive and has a smaller bias, but
can be severely affected by the contamination of foreground stars,
especially for large values of ![]() .
.
As pointed out by Cambrésy et al. (2002), we can take advantage of the different behavior of the star count and the color excess techniques in the various column density regimes to partially solve the problem of the contamination by foreground stars. In particular, Cambrésy et al. note that it is better to use the color excess method at low column densities because of its higher sensitivity, and to switch to the star count method at very large column densities where the NICE method is completely unreliable. The optimal "turning point'' where we need to change the technique can be evaluated empirically by comparing the individual results of the two methods at different column densities.
The solution proposed by Cambrésy et al. has the significant advantage of being relatively simple to implement and reasonably effective, but clearly is suboptimal in many respects:
Suppose again that in a region of the sky of area
![]() we
observe in various bands N stars with magnitudes
we
observe in various bands N stars with magnitudes
![]() .
Assuming that the area of the sky is small enough so that there
are no significant changes on the relevant parameters of the problem
(such as the unreddened density
.
Assuming that the area of the sky is small enough so that there
are no significant changes on the relevant parameters of the problem
(such as the unreddened density
![]() ,
local expected density
,
local expected density
![]() ,
or the reddening probability distribution
,
or the reddening probability distribution
![]() ),
then we can easily evaluate the joint probability distribution for
such a star configuration. First, we note that the number of stars
inside the region follows a Poisson distribution with average
),
then we can easily evaluate the joint probability distribution for
such a star configuration. First, we note that the number of stars
inside the region follows a Poisson distribution with average
![]() :
:
We implemented the maximum-likelihood estimator using the
simplification described above. In particular, we used the forms
(34) and (35) for the source magnitude probability
distribution
![]() .
A simple calculation gives the following
relationships between the coefficients of Eqs. (34) and (35):
.
A simple calculation gives the following
relationships between the coefficients of Eqs. (34) and (35):
For the following discussion, it is also convenient to introduce a new
vector
![]() ,
and a
,
and a
![]() matrix S defined as
matrix S defined as
In conclusion, the simple implementation of the maximum-likelihood method considered here can be summarized in the following items:
Table 2: The common parameters used for all numerical simulations.
The reliability and effectiveness of the maximum-likelihood approach were assessed through extensive numerical simulations. The simulations were designed to reproduce with reasonable accuracy the 2MASS near-infrared data. We simulated star observations in three bands, J, H, and K, and used the various parameters described in Table 2.
We initially considered an area of the sky
![]() and a thin
cloud characterized by a fraction of foreground stars f (cf.
Eq. (18)) and a reddening
and a thin
cloud characterized by a fraction of foreground stars f (cf.
Eq. (18)) and a reddening ![]() .
We randomly generated there
stars inside this area using the following recipe:
.
We randomly generated there
stars inside this area using the following recipe:
| |
Figure 7:
Log-likelihood surface plot. The plot shows the
logarithmic of the likelihood ratio as a function of the two
unknown parameters |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f08.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img263.gif) |
Figure 8:
The log-likelihood (ratio) as a function of |
| Open with DEXTER | |
We then used this dataset to test the reliability and efficiency of the maximum-likelihood estimator, and to compare it with the other column density estimators considered in Sect. 3. The maximum-likelihood method was implemented as described in Sect. 4.2, and was tested against the data generated as described in the items above.
Figure 7 shows the log-likelihood surface plot obtained in a typical simulation. The surface appears to be very smooth with a well defined minimum, an essential condition for the reliability of the maximum-likelihood approach. Moreover, the log-likelihood function is found to have approximately a parabolic shape, which further simplifies the interpretation of the results obtained. For example, this property allows us to use the likelihood ratio (see, e.g., Eadie et al. 1971) to draw confidence level regions on the parameter space (see the contours of Fig. 7).
Figure 8 represents the log-likelihood as a function of
![]() for three different datasets. The figure was obtained by
minimizing the log-likelihood function with respect to f for each
value of
for three different datasets. The figure was obtained by
minimizing the log-likelihood function with respect to f for each
value of ![]() in the range [5, 15], and by plotting the value of
this function.
in the range [5, 15], and by plotting the value of
this function.
In order to assess more quantitatively the merits of the
maximum-likelihood method, we compared the statistical properties of
various column density estimators. In particular, we simulated a
large number of "observations'' using the technique described above,
and we studied the distribution of the column densities estimated
using the maximum-likelihood method, the NICE, and the
NICER methods. Simulations were carried out using a thin
cloud with true extinction in the range
![]() and with
different values of the foreground fraction f. For the
NICE and NICER estimators we used both the simple
mean and the median of the individual extinction measured for each
star; moreover, assuming that the density of foreground stars
and with
different values of the foreground fraction f. For the
NICE and NICER estimators we used both the simple
mean and the median of the individual extinction measured for each
star; moreover, assuming that the density of foreground stars
![]() could be determined separately, we discarded in
each simulation the
could be determined separately, we discarded in
each simulation the
![]() bluer stars, and
used only the remaining (redder) stars in the analysis. Note that in
some cases, for large values of
bluer stars, and
used only the remaining (redder) stars in the analysis. Note that in
some cases, for large values of ![]() and relatively large values of
f we had no usable star for the NICE and NICER
analysis; in other words, all stars left after the foreground
selection had only one band available (typically the K band). In
this case we just obtained a lower limit on
and relatively large values of
f we had no usable star for the NICE and NICER
analysis; in other words, all stars left after the foreground
selection had only one band available (typically the K band). In
this case we just obtained a lower limit on ![]() by using the redder
usable star (even if this star was originally considered to be in the
foreground).
by using the redder
usable star (even if this star was originally considered to be in the
foreground).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f09.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img267.gif) |
Figure 9:
The bias
|
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f10.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img269.gif) |
Figure 10:
The total error
|
| Open with DEXTER | |
Figures 9 and 10 show, respectively, the bias and
the total error obtained from the three methods considered here for
![]() and f = 0. From these plots it is evident that the
maximum-likelihood estimator does not have any significant bias up to
and f = 0. From these plots it is evident that the
maximum-likelihood estimator does not have any significant bias up to
![]() and a very small one (of the order of 0.1) for larger
column densities. Since for f = 0 we never have foreground stars,
the bias of the NICE and NICER techniques does not
change if we use a mean or a median estimator. Note also that the
bias in Fig. 9 for these two methods is the one discussed in
detail above (cf. Fig. 3). Regarding the total error, we
observe a steady increase of it for large values of
and a very small one (of the order of 0.1) for larger
column densities. Since for f = 0 we never have foreground stars,
the bias of the NICE and NICER techniques does not
change if we use a mean or a median estimator. Note also that the
bias in Fig. 9 for these two methods is the one discussed in
detail above (cf. Fig. 3). Regarding the total error, we
observe a steady increase of it for large values of ![]() .
This can
be explained by noting that, although the average number of stars
.
This can
be explained by noting that, although the average number of stars
![]() is kept constant for all column densities,
when
is kept constant for all column densities,
when ![]() is large most stars are only detected in the K band and
thus do not provide reddening information. Figure 10 also
shows that the maximum-likelihood method is clearly superior, although
NICER (with the mean estimator) also performs well. As
expected, both median estimators are more noisy than the simple mean
(which, for f = 0, is optimal).
is large most stars are only detected in the K band and
thus do not provide reddening information. Figure 10 also
shows that the maximum-likelihood method is clearly superior, although
NICER (with the mean estimator) also performs well. As
expected, both median estimators are more noisy than the simple mean
(which, for f = 0, is optimal).
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f11.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img271.gif) |
Figure 11: As for Fig. 9, but with f = 0.02. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f12.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img272.gif) |
Figure 12: As for Fig. 10, but with f = 0.02. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f13.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img273.gif) |
Figure 13: As for Fig. 9, but with f = 0.05. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f14.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img274.gif) |
Figure 14: As for Fig. 10, but with f = 0.05. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f15.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img275.gif) |
Figure 15: As for Fig. 9, but with f = 0.10. |
| Open with DEXTER | |
The situation changes quite dramatically when f > 0. Figures 11-16 show the bias and the total error of the various methods for increasing values of f. A careful study of these results can reveal several interesting characteristics of the NICE and NICER techniques.
Let us initially focus on the bias plots, shown in Figs. 11,
13, and 15. At low column densities, i.e. for
![]() ,
we find again the bias described in
Sect. 3.2 and plotted in Fig. 3
(see also above Fig. 9 for the case f = 0). At median
column densities, i.e. for
,
we find again the bias described in
Sect. 3.2 and plotted in Fig. 3
(see also above Fig. 9 for the case f = 0). At median
column densities, i.e. for
![]() (or
(or
![]() for f =
0.02), the bias can be explained by the selection effect due to the
correction of foreground stars. As explained above (see
Eq. (54)), removing the
for f =
0.02), the bias can be explained by the selection effect due to the
correction of foreground stars. As explained above (see
Eq. (54)), removing the
![]() bluer stars introduces a systematic error on the
extinction estimate. This bias is positive (i.e. toward larger
extinctions) and can be as large as
bluer stars introduces a systematic error on the
extinction estimate. This bias is positive (i.e. toward larger
extinctions) and can be as large as
![]() in
in ![]() .
Finally, at high column densities (
.
Finally, at high column densities (
![]() )
both methods
systematically underestimate the extinction. This is due to the heavy
contamination by foreground stars present at these large values of
reddening. To better understand this point, we note that the
subtraction of the
)
both methods
systematically underestimate the extinction. This is due to the heavy
contamination by foreground stars present at these large values of
reddening. To better understand this point, we note that the
subtraction of the ![]() bluer stars is a simplistic
approximation because the actual number of foreground stars is not
fixed (it is a Poisson random variable with average
bluer stars is a simplistic
approximation because the actual number of foreground stars is not
fixed (it is a Poisson random variable with average ![]() ).
Depending on the number of foreground stars with respect to
).
Depending on the number of foreground stars with respect to
![]() we can have three different situations:
we can have three different situations:
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267f16.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img280.gif) |
Figure 16: As for Fig. 10, but with f = 0.10. |
| Open with DEXTER | |
Figures 12, 14, and 16 show that the
total error of the NICE and NICER methods increases
very rapidly at large column densities, where the contamination by
foreground stars is very likely; the maximum-likelihood estimator,
instead, has an almost flat error curve. Hence, our novel method is
able to "recognize'' the presence of foreground stars; moreover, the
inclusion of the background density in the likelihood expression
allows this estimator to "switch'' to the number count technique in
regions with large extinction. Figure 12, in particularly,
shows that even in extreme cases with a large foreground star
contamination the maximum-likelihood method is still very reliable and
accurate. To better appreciate this point, we note that, in our
simulations, for
![]() and f = 0.2 on average only one tenth of
the
and f = 0.2 on average only one tenth of
the ![]() 25 stars are background to the cloud.
25 stars are background to the cloud.
The maximum-likelihood approach to the extinction measurements
presents clear advantages with respect to the standard techniques in
the simplified framework considered in this section (uniform ![]() over the cloud patch analysed, thin-cloud approximation, simple model
for the star intrinsic magnitude distribution). One could thus
legitimately ask whether the maximum-likelihood technique is
applicable to more realistic and complex situations.
over the cloud patch analysed, thin-cloud approximation, simple model
for the star intrinsic magnitude distribution). One could thus
legitimately ask whether the maximum-likelihood technique is
applicable to more realistic and complex situations.
Most clouds present clear sign of substructure at different scales and a statistical analysis of the radio and NIR observations seems to indicate the that these objects can be well described in terms of turbulent models (see, e.g.Padoan et al. 1997; Miesch & Bally 1994). In presence of significant inhomogeneities, most methods (including the maximum-likelihood one) are expected to be biased toward low values because the background stars will no longer be randomly distributed in the patch of the sky used to estimate the local extinction value, but will be preferentially detected in low-extinction regions (cf. Eq. (43)). Although a detailed discussion of this effect is behind the scope of this paper, it is worth considering the following points:
In the implementation of the maximum-likelihood technique discussed in
this section, we used the simple model for the magnitude probability
distribution
![]() (cf. Eq. (34)). However, the
functional form of
(cf. Eq. (34)). However, the
functional form of
![]() used can be inaccurate in describing
real data for several reasons:
used can be inaccurate in describing
real data for several reasons:
On of most significant drawback of the maximum-likelihood approach is its speed. The implementation used in this paper is approximately one order of magnitude slower than the NICER method (at least on a typical workstation), and this might prevent large applications of the method proposed here. On the other hand, the fast technological progress in the computer speed justifies the work presented in this paper, in the sense that soon it will be possible to use the maximum-likelihood method on large datasets composed of millions of stars.
Another possible issue related to the technique presented here is the
need for a more detailed knowledge of the properties of the data used.
As a comparison, we note that the original NICE technique
makes use only of the H and K magnitudes of stars and of the
average color
![]() of stars in the control field.
In addition to these data, NICER also requires the estimated
errors of star magnitudes in the NIR bands used. Finally, the
maximum-likelihood method requires a detailed knowledge of the
probability distribution
of stars in the control field.
In addition to these data, NICER also requires the estimated
errors of star magnitudes in the NIR bands used. Finally, the
maximum-likelihood method requires a detailed knowledge of the
probability distribution
![]() ,
of the measurement errors
,
of the measurement errors
![]() of each star, and
of the completeness functions
of each star, and
of the completeness functions
![]() .
In
reality, in the Bayesian approach implicitly adopted in this paper,
the maximum-likelihood method can also be used if an
approximate knowledge of these parameters is available.
Suppose, for example, that the parameters P,
.
In
reality, in the Bayesian approach implicitly adopted in this paper,
the maximum-likelihood method can also be used if an
approximate knowledge of these parameters is available.
Suppose, for example, that the parameters P, ![]() ,
and R that
characterize
,
and R that
characterize
![]() (see Eq. (35)) are only
approximately known from the measurements in the control field. In
this case we can take these parameters as unknowns in the
expression for the likelihood, and we can thus minimize L with
respect to them as well as with respect to the parameters that
characterize
(see Eq. (35)) are only
approximately known from the measurements in the control field. In
this case we can take these parameters as unknowns in the
expression for the likelihood, and we can thus minimize L with
respect to them as well as with respect to the parameters that
characterize
![]() (
(![]() and f in the case considered
here). As customary in standard maximum-likelihood problems, we
include the knowledge on P,
and f in the case considered
here). As customary in standard maximum-likelihood problems, we
include the knowledge on P, ![]() ,
and R as a prior
in the function L. Note that this way the dimension of the space
over which we need to minimize L greatly increases (and this can
pose severe computational problems), but in principle the schema
proposed is applicable to real cases.
,
and R as a prior
in the function L. Note that this way the dimension of the space
over which we need to minimize L greatly increases (and this can
pose severe computational problems), but in principle the schema
proposed is applicable to real cases.
Interestingly, the NICE and NICER technique can be
seen as special cases of the maximum-likelihood method when no prior
knowledge on R is available: the complete lack information on the
normalization of
![]() forces our method to use the only color
information of the stars. Similarly, the number counts method can be
recovered as special case when the knowledge on the average colors
forces our method to use the only color
information of the stars. Similarly, the number counts method can be
recovered as special case when the knowledge on the average colors
![]() is absent (or, equivalently, when the scatter in the colors
Cab is very large; cf. Eq. (34)). This suggests that
the NICE(R)) techniques are not more robust of the
maximum-likelihood one, but just simpler.
is absent (or, equivalently, when the scatter in the colors
Cab is very large; cf. Eq. (34)). This suggests that
the NICE(R)) techniques are not more robust of the
maximum-likelihood one, but just simpler.
Finally, we mention that the presence of young stellar objects (that could be for example embedded in the dense cores) can in principle affect the extinction measurements. Hence, these objects should be "manually'' removed before using any extinction measurement method, including the maximum-likelihood described in this paper.
In this paper we have considered the problem of an accurate determination of the extinction toward a dark molecular cloud. The results obtained here can be summarized in the following items:
In Sect. 4.4.1 we discussed one of the most
serious limitations of NIR color excess studies in molecular clouds,
namely the bias introduced by substructures. In our original
formulation, the maximum-likelihood method can be used not only in the
thin cloud approximation, but in general for any functional form of
![]() .
Hence, as mentioned above, we could implement the
maximum-likelihood method using a more realistic probability
distribution for
.
Hence, as mentioned above, we could implement the
maximum-likelihood method using a more realistic probability
distribution for ![]() ,
such as the one of Eq. (65).
,
such as the one of Eq. (65).
Another possibility offered by the maximum-likelihood approach is the
generalization of the thin-cloud approximation to a multi-layer case,
where two or more (thin) clouds located at different distances are
observed on overlapping areas of the sky. For example, in case of a
double cloud we could write (cf. Eq. (17))
Acknowledgements
We are very grateful to G. Bertin and J. Alves for useful and stimulating discussions, and to the referee, L. Cambresy for providing stimulating comments and for helping us improve the paper significantly.
The goal of this appendix is to derive the probability distribution of the median of n independent identical random variables. This analysis is useful to address some of the issues discussed in Sect. 3.2.
In the following we will often deal with ordered and
unordered n-tuples. The latter can be taken to be a set
of n elements, where typically each element is a random variable or
an element of another tuple; the former can be taken to be a list of
n elements, where thus each element is associated to a position in
the list. Hence, given a positive integer ![]() ,
it makes sense
to talk about the kth element of an ordered n-tuple, while this
is meaningless for an unordered tuple.
,
it makes sense
to talk about the kth element of an ordered n-tuple, while this
is meaningless for an unordered tuple.
We will denote an ordered n-tuple using brackets, as in
![]() ;
instead, we will reserve braces for the unordered
tuples, as in
;
instead, we will reserve braces for the unordered
tuples, as in
![]() .
Note that, for consistency
with the definition, we identify unordered tuples if these differ just
by a permutation of the elements: thus
.
Note that, for consistency
with the definition, we identify unordered tuples if these differ just
by a permutation of the elements: thus
![]() is, for instance, identical to
is, for instance, identical to
![]() .
.
Let us call p(x) the probability distribution for the real random
variable x, and let us consider the generation of unordered
n-tuples
![]() of such variables. Suppose
that, after the random generation of a tuple, we order the tuple such
that
of such variables. Suppose
that, after the random generation of a tuple, we order the tuple such
that
![]() .
We consider now the probability
distribution
pnk(xk) for the kth element of the ordered tuple
.
We consider now the probability
distribution
pnk(xk) for the kth element of the ordered tuple
![]() ,
which can be written as
,
which can be written as
The cumulative distribution Pnk(xk) is given by
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267fA1.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img315.gif) |
Figure A.1: The cumulative probability distribution Pnk(xk) as a function of P(x) for n=7 and various values of k (marked close to the relative curves). |
![\begin{figure}
\par\includegraphics[width=8.4cm,clip]{2267fA2.eps} \end{figure}](/articles/aa/full/2005/28/aa2267-04/img316.gif) |
Figure A.2:
The cumulative probability distribution
Pnk(xk) as a
function of P(x) for
|
Figures A.1 and A.2 show the polynomials Pnk(xk) as a function of P(xk) for various values of n and k. These figures suggest a number of properties for Pnk(xk)that can be verified analytically with the help of the equations written above:
The median of the probability distribution of the median estimator of the random variable x is the median of the probability distribution of x.Note that here we use the term "median'' to denote both the usual median of an n-tuple
For our purposes, it is also useful to define and study two
probability distributions closely related to
Pnk(xk). Let us
consider again the ordered n-tuple
![]() ,
where each
element is drawn from a probability distribution p(x). Now let us
retain only the first k elements of the ordered n-tuple, and let
us call
,
where each
element is drawn from a probability distribution p(x). Now let us
retain only the first k elements of the ordered n-tuple, and let
us call
![]() the probability distribution for each
element of the unordered k-tuple
the probability distribution for each
element of the unordered k-tuple
![]() ;
similarly, we call
;
similarly, we call
![]() the probability
distribution for the tuple
the probability
distribution for the tuple
![]() where only the last
(n - k + 1) elements of the original ordered n-tuple are retained.
where only the last
(n - k + 1) elements of the original ordered n-tuple are retained.
The evaluation of the probability distribution
![]() can be
broken into two parts. Consider the (k-1)th element xk-1 of
the tuple
can be
broken into two parts. Consider the (k-1)th element xk-1 of
the tuple
![]() (i.e., the last element discarded);
then, clearly, each element of the (n-k+1)-tuple
(i.e., the last element discarded);
then, clearly, each element of the (n-k+1)-tuple
![]() cannot be smaller than xk-1. Moreover, each element of
this unordered tuple is distributed between xk-1and
cannot be smaller than xk-1. Moreover, each element of
this unordered tuple is distributed between xk-1and ![]() according to the (truncated) original probability
distribution p(x). Finally, by repeating this argument for each
possible value of xk-1 (weighted by pnk-1), we obtain the
expression
according to the (truncated) original probability
distribution p(x). Finally, by repeating this argument for each
possible value of xk-1 (weighted by pnk-1), we obtain the
expression
As usual in this appendix, it is more convenient to consider the
cumulative probability distributions. We can thus integrate
![]() over x and obtain, after a few manipulations, a closed
expression for
over x and obtain, after a few manipulations, a closed
expression for
![]() .
Here, however, we prefer to follow a
different and simpler path.
.
Here, however, we prefer to follow a
different and simpler path.
Let us consider again the tuple
![]() .
Each element
of this ordered tuple follows the probability distribution
pnk(xk) discussed in the previous section. Hence, if we consider
the unordered tuple, the elements
.
Each element
of this ordered tuple follows the probability distribution
pnk(xk) discussed in the previous section. Hence, if we consider
the unordered tuple, the elements
![]() will follow the average distribution
will follow the average distribution
If, instead, k > 1, then using the properties of the binomial
coefficient we find
Similarly, we wish to investigate the cumulative probability
distribution
![]() for the k-tuple
for the k-tuple
![]() .
This quantity is better evaluated using
.
This quantity is better evaluated using
![]() :
:
As an application of the results obtained in this section, we evaluate
the bias introduced in the estimate of the column density when using
the technique described in Sect. 3.2 to
remove foreground stars (see Eq. (54)). Suppose that we
observe stars in a region with no significant extinction, so that both
foreground and background stars have the same distribution in colors.
For simplicity, we assume that the reddening estimates
![]() for
each individual star is a Gaussian distribution with vanishing average
and variance
for
each individual star is a Gaussian distribution with vanishing average
and variance
![]() .
In this situation, if we exclude
the k bluer stars (because they are taken to be foreground), we will
bias the estimate of
.
In this situation, if we exclude
the k bluer stars (because they are taken to be foreground), we will
bias the estimate of ![]() toward large column densities. In
particular, the column densities for the stars left will be
distributed according to
toward large column densities. In
particular, the column densities for the stars left will be
distributed according to
![]() .
The median of this
distribution can be evaluated as follows. At
.
The median of this
distribution can be evaluated as follows. At
![]() we have
we have
![]() ,
while
,
while
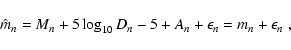
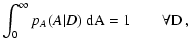
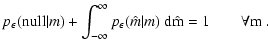
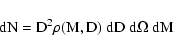
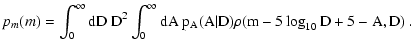
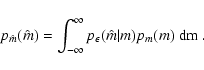
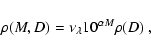
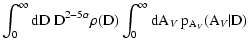
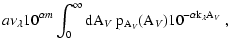
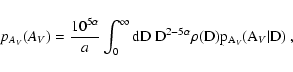
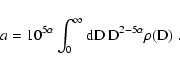
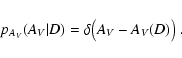
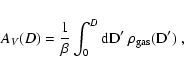
![$\displaystyle \frac{10^{5\alpha}}{a} \bigl[ D(A_{\it V})
\bigr]^{2-5\alpha} \rho\bigl( D(A_{\it V}) \bigr) D'(A_{\it V})$](/articles/aa/full/2005/28/aa2267-04/img89.gif)
![$\displaystyle \frac{10^{5\alpha}}{a} \frac{\rho\bigl( D(A_{\it V}) \bigr)}{3 -
...
...\rm d}{\rm dA_{\it V}} \Bigl[ \bigl[D(A_{\it V})
\bigr]^{3-5\alpha} \Bigr] \; .$](/articles/aa/full/2005/28/aa2267-04/img90.gif)
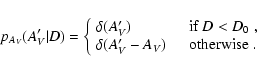
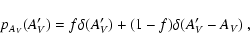
![\begin{displaymath}
f = \biggl[ \int_0^{D_0} \!\! \rm dD ~ D^{2 - 5\alpha} \rho...
...t_0^\infty \!\! \rm dD ~ D^{2 - 5\alpha}
\rho(D) \biggr] \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img95.gif)
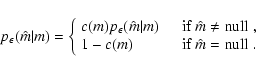
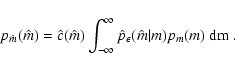
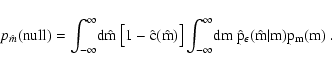
![$\displaystyle \int_{-\infty}^\infty \hat p_\epsilon(\hat m \vert
m) \bigl[ 1 - \hat c(\hat m) \bigr] ~ \rm d\hat m \ .$](/articles/aa/full/2005/28/aa2267-04/img103.gif)
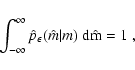
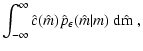
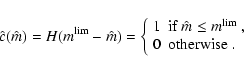
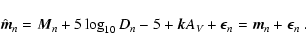
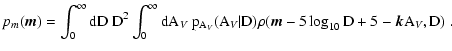
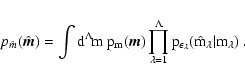
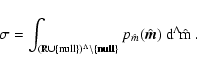
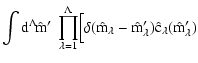
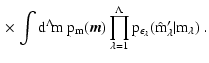
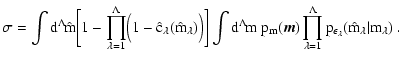
![$\displaystyle p_M(\vec M) = \nu 10^{\alpha M_1}
\exp \left[ -\frac{(M_a - M_1 - \chi_a) C^{-1}_{ab} (M_b -
M_1 - \chi_b)}{2} \right] \; ,$](/articles/aa/full/2005/28/aa2267-04/img139.gif)
![\begin{displaymath}
p_M(\vec M) = \exp \left[ - \frac{\vec M^{\rm T} P \vec M + 2
\vec Q^{\rm T} \vec M + R}{2} \right] \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img141.gif)
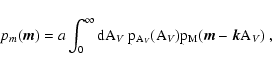
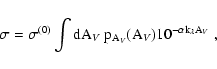
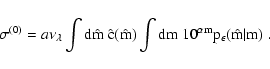
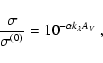
 = \int_0^\infty f(x) \exp( - k x) \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img154.gif)

\; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img156.gif)
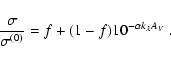
![\begin{displaymath}
\hat A_{\it V} = - \frac{1}{\alpha k_\lambda} \log_{10}\lef...
...gma^{(0)} f}{\mathcal{A} \sigma^{(0)} (1 - f) }
\right] \; ,
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img165.gif)
![\begin{displaymath}
\langle N \rangle = \mathcal{A} \sigma^{(0)} \bigl[ f + (1-f)
10^{-\alpha k_\lambda A_{\it V}} \bigr] \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img167.gif)
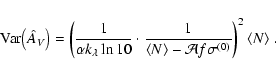
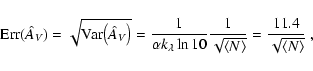
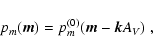
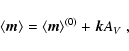
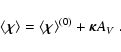
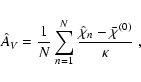
![\begin{displaymath}
\chi^2 = \sum_{n=1}^N \bigl[ \hat{\vec \chi}_n - \bar {\vec...
...n - \bar{\vec \chi}^{(0)} - \vec \kappa A_{\it V} \bigr]
\; ,
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img194.gif)
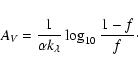
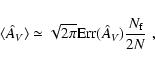
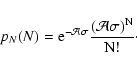
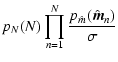
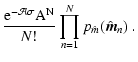
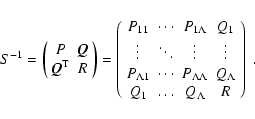
![\begin{displaymath}
p_M(\vec M) = \exp \left[ - \frac{\vec\mu^{\rm T} S^{-1} \vec\mu}{2}
\right] \cdot
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img234.gif)
![\begin{displaymath}
p_\epsilon(\vec\epsilon) = \frac{1}{(2\pi)^{\Lambda/2}
\pr...
...ambda \frac{\epsilon^2_\lambda}{2 v_\lambda^2 }
\biggr] \; ,
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img236.gif)
![\begin{displaymath}
(p_M * \Sigma)(\vec\mu) = \sqrt{\frac{\det S}{\det T}} \exp \left[
-\frac{\vec\mu^{\rm T} T^{-1} \vec\mu}{2} \right] \; ,
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img238.gif)
![\begin{displaymath}
p_{A_{\it V}}(A_{\it V}) = \frac{1}{\sqrt{2 \pi} S A_{\it V...
...p \biggl[ -
\frac{(\ln A_{\it V} - M)^2}{2 S^2} \biggr] \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img288.gif)
![\begin{displaymath}
p^n_k(x_k) = n \left(
\begin{array}{c}
{n-1}\\ {k-1}
\end...
...gl[ P(x_k) \bigr]^{k-1}
\bigl[ 1 - P(x_k) \bigr]^{n - k} \; ,
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img305.gif)
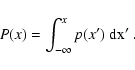
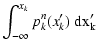
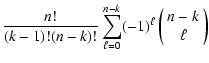
![$\displaystyle {} \times \int_{-\infty}^{x_k} \bigl[P(x'_k) \bigr]^{k-1 +
\ell} p(x'_k) ~ \rm dx'_k$](/articles/aa/full/2005/28/aa2267-04/img312.gif)
![$\displaystyle \sum_{m=k}^{n} (-1)^{m + k}
\left( \begin{array}{c}
n \\ m
\end{...
...\left(
\begin{array}{c}
m-1 \\ k-1
\end{array}\right)
\bigl[ P(x_k) \bigr]^m .$](/articles/aa/full/2005/28/aa2267-04/img313.gif)
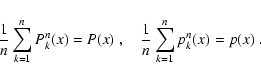
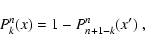
![\begin{displaymath}
P^n_1(x_1) {} = \bigl[ P(x_1) \bigr]^n \; , \quad
P^n_n(x_n) {} = 1 - \bigl[ 1 - P(x_n) \bigr]^n \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img319.gif)
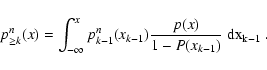
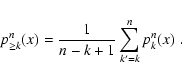
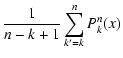
![$\displaystyle \frac{1}{n - k + 1} \sum_{m=k}^n
\left(\begin{array}{c}
n \\
m
\end{array}\right)
\bigl[ P(x) \bigr]^m$](/articles/aa/full/2005/28/aa2267-04/img333.gif)
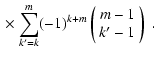
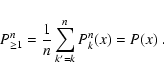
![\begin{displaymath}
P^n_{\ge k}(x) = \frac{1}{n - k + 1} \sum_{m=k}^n (-1)^{m +...
...
m - 2 \\
k - 2
\end{array}\right)
\bigl[ P(x) \bigr]^m .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img336.gif)
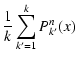
![$\displaystyle \frac{1}{k} \biggl[ \sum_{k'=1}^n P^n_{k'}(x) -
\sum_{k'=k+1}^n P^n_{k'}(x) \biggr]$](/articles/aa/full/2005/28/aa2267-04/img340.gif)
![$\displaystyle \frac{1}{k} \biggl[ n P(x) - (n - k) P^n_{\ge k+1}(x)
\biggr]$](/articles/aa/full/2005/28/aa2267-04/img341.gif)
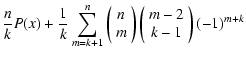
![$\displaystyle \phantom{\frac{n}{k} P(x) + \frac{1}{k} \sum_{m=k+1}^n}
\times \bigl[ P(x) \bigr]^m \; .$](/articles/aa/full/2005/28/aa2267-04/img343.gif)
![\begin{displaymath}
P^n_{\ge k+1}(0) = \frac{1}{n - k} \biggl[ \frac{n}{2} -
\sum_{k'=1}^k P^n_{k'}(1/2) \biggr] \; .
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img347.gif)
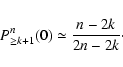
![\begin{displaymath}
x \simeq \left[ \frac{\rm dP^n_{\ge k+1}}{\rm dx}\right]^{-...
...{2} - P^n_{\ge k+1}(0) \right] \simeq \frac{k}{2 n p(0)} \cdot
\end{displaymath}](/articles/aa/full/2005/28/aa2267-04/img351.gif)