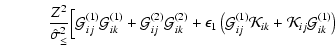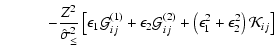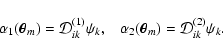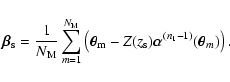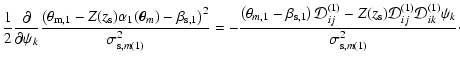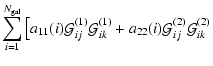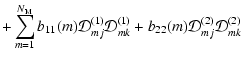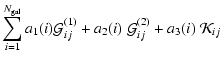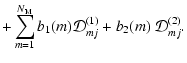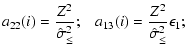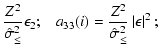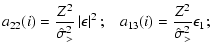A&A 437, 39-48 (2005)
DOI: 10.1051/0004-6361:20042233
M. Bradac1,2,3 - P. Schneider1 - M. Lombardi1,4,5 - T. Erben1
1 - Institut für Astrophysik und Extraterrestrische
Forschung, Auf dem Hügel 71, 53121 Bonn, Germany
2 -
Max-Planck-Institut für Radioastronomie, Auf dem
Hügel 69, 53121 Bonn, Germany
3 -
KIPAC, Stanford University, 2575 Sand Hill Road, Menlo Park, CA 94025, USA
4 -
European Southern Observatory, Karl-Schwarzschild-Str. 2,
85748 Garching bei München, Germany
5 -
Università degli Studi di Milano, v. Celoria 16, 20133
Milano, Italy
Received 22 October 2004 / Accepted 3 March 2005
Abstract
Weak gravitational lensing is considered to be one of the
most powerful tools to study the mass and the mass distribution of
galaxy clusters. However, the mass-sheet degeneracy transformation
has limited its success. We present a novel method for a cluster
mass reconstruction which combines weak and strong lensing
information on common scales and can, as a consequence, break the
mass-sheet degeneracy. We extend the weak lensing formalism to the
inner parts of the cluster and combine it with the constraints from
multiple image systems. We demonstrate the feasibility of the method
with simulations, finding an excellent agreement between the input
and reconstructed mass also on scales within and beyond the Einstein
radius. Using a single multiple image system and photometric
redshift information of the background sources used for weak and
strong lensing analysis, we find that we are effectively able to
break the mass-sheet degeneracy, therefore removing one of the
main limitations on cluster mass estimates. We conclude that with
high resolution (e.g. HST) imaging data the method can more
accurately reconstruct cluster masses and their profiles than
currently existing lensing techniques.
Key words: cosmology: dark matter - galaxies: clusters: general - gravitational lensing
Clusters of galaxies have long been recognised as excellent
laboratories for many cosmological applications. An especially
important diagnostic is their number density as a function of mass and
redshift. This can only be measured if reliable mass estimates of the
observed clusters can be obtained. In addition, in the framework of
the ![]() CDM cosmological model, the dark matter distribution in
clusters likely follows the NFW profile (Navarro et al. 1997).
CDM cosmological model, the dark matter distribution in
clusters likely follows the NFW profile (Navarro et al. 1997).
Weak gravitational lensing is one of the most powerful tools currently available for studying the mass distribution of clusters of galaxies. The first weak lensing detection in clusters has been made by Tyson et al. (1990). However, it was only after the pioneering work by Kaiser & Squires (1993) that the field began to flourish, and since then many cluster mass reconstructions have been carried out (see e.g. Clowe & Schneider 2001,2002; Gavazzi et al. 2004; Lombardi et al. 2005). A disagreement occurring in some cases between the cluster mass estimated from the weak/strong lensing measurements with X-rays is still not well understood, although several scenarios have been proposed to resolve this issue (see e.g. Allen 1998; Ettori & Lombardi 2003).
In the absence of the redshift information, the main limitation for a
precise weak lensing mass estimate is the mass-sheet degeneracy
(Schneider & Seitz 1995). If the redshifts of background sources and/or lens
are not known, the transformation of the surface mass-density
![]() ,
where
,
where
![]() is
an arbitrary constant, leaves the expectation value of measured image
ellipticities unchanged. In Bradac et al. (2004a) we show that this
degeneracy can be lifted using information on individual source
redshifts, however only if the weak lensing reconstruction is extended
to the critical parts of the cluster. Strong lensing is affected by
this transformation as well. Namely, the mass-sheet degeneracy does
not change the image positions (since the source position is not an
observable) and flux ratios and therefore can not be broken if a
single redshift multiple-image system is used. The mass-sheet
degeneracy can in principle be broken using magnification effect
(see Broadhurst et al. 2005,1995). In order to make full use
of this method, the unlensed source counts at a given magnitude
threshold must be known accurately. Given the photometric calibration
uncertainties, which at the faint magnitudes one is usually dealing
with easily amount to
is
an arbitrary constant, leaves the expectation value of measured image
ellipticities unchanged. In Bradac et al. (2004a) we show that this
degeneracy can be lifted using information on individual source
redshifts, however only if the weak lensing reconstruction is extended
to the critical parts of the cluster. Strong lensing is affected by
this transformation as well. Namely, the mass-sheet degeneracy does
not change the image positions (since the source position is not an
observable) and flux ratios and therefore can not be broken if a
single redshift multiple-image system is used. The mass-sheet
degeneracy can in principle be broken using magnification effect
(see Broadhurst et al. 2005,1995). In order to make full use
of this method, the unlensed source counts at a given magnitude
threshold must be known accurately. Given the photometric calibration
uncertainties, which at the faint magnitudes one is usually dealing
with easily amount to
![]() ,
thus an uncertainty of
,
thus an uncertainty of ![]() 10% in the unlensed source counts is typical. As shown by
Schneider et al. (2000), this level of uncertainty removes a great deal of
the power of the magnification method to break the mass-sheet
degeneracy.
10% in the unlensed source counts is typical. As shown by
Schneider et al. (2000), this level of uncertainty removes a great deal of
the power of the magnification method to break the mass-sheet
degeneracy.
Several attempts have been made recently to measure the cluster mass profiles with weak lensing. However, as shown in Clowe & Schneider (2001,2002), it is extremely difficult to distinguish e.g. isothermal from NFW profiles at high significance using weak lensing data alone. The authors also conclude that these difficulties mostly arise as a consequence of the mass-sheet degeneracy transformation. Therefore additional information needs to be included, such as combining the weak lensing data with strong lensing (see e.g. Kneib et al. 2003; Smith et al. 2004). Another example was given by Sand et al. (2004) using combined strong lensing and stellar kinematics data of the dominating central galaxy. This approach offers valuable extra constraints, however a detailed strong-lens modelling is required (Bartelmann & Meneghetti 2004; Dalal & Keeton 2003).
In this paper we use a combined strong and weak lensing mass
reconstruction to determine the mass and the mass distribution of
clusters. We reconstruct the gravitational potential ![]() ,
since it
locally determines both the lensing distortion (for weak lensing) as
well as the deflection (for strong lensing). The method extends the
idea from Bartelmann et al. (1996) and Seitz et al. (1998). Its novel feature
is that we directly include strong lensing information. Further, weak
lensing reconstruction is extended to the critical parts of the
cluster and we include individual redshift information of background
sources as well as of the source(s) being multiply imaged. This allows
us to break the mass-sheet degeneracy and accurately measure the
cluster mass and mass distribution. The method is tested using
simulations, and in Bradac et al. (2005, hereafter
Paper II) we apply it to
the cluster RX J1347.5-1145. In this paper we first briefly present
the basics of gravitational lensing in Sect. 2. In
Sect. 3 we give an outline of the reconstruction method
(detailed calculations are given in the Appendix). We test the method
using N-body simulations, and we present the results in
Sect. 4. The conclusions and summary are the subject of
Sect. 5.
,
since it
locally determines both the lensing distortion (for weak lensing) as
well as the deflection (for strong lensing). The method extends the
idea from Bartelmann et al. (1996) and Seitz et al. (1998). Its novel feature
is that we directly include strong lensing information. Further, weak
lensing reconstruction is extended to the critical parts of the
cluster and we include individual redshift information of background
sources as well as of the source(s) being multiply imaged. This allows
us to break the mass-sheet degeneracy and accurately measure the
cluster mass and mass distribution. The method is tested using
simulations, and in Bradac et al. (2005, hereafter
Paper II) we apply it to
the cluster RX J1347.5-1145. In this paper we first briefly present
the basics of gravitational lensing in Sect. 2. In
Sect. 3 we give an outline of the reconstruction method
(detailed calculations are given in the Appendix). We test the method
using N-body simulations, and we present the results in
Sect. 4. The conclusions and summary are the subject of
Sect. 5.
We start by considering a lens having a projected surface mass
density
![]() ,
where
,
where
![]() denotes the
(angular) position in the lens plane. We define the
dimensionless surface density
denotes the
(angular) position in the lens plane. We define the
dimensionless surface density
![]() for a fiducial
source located at a redshift
for a fiducial
source located at a redshift
![]() and a lens (deflector)
at
and a lens (deflector)
at
![]()
We define the deflection potential
![]()
In the case of weak lensing, the information on the lens potential is
contained in the transformation between the source ellipticity
![]() and image ellipticity
and image ellipticity ![]() .
It is given as a
function of reduced shear
.
It is given as a
function of reduced shear
![]() (see Seitz & Schneider 1997)
(see Seitz & Schneider 1997)
The idea of combining strong and weak lensing constraints is not new,
it has been previously discussed by Abdelsalam et al. (1998),
Kneib et al. (2003), Smith et al. (2004), and others. The method presented
here, however, has some important differences. For example in
Abdelsalam et al. (1998) the authors reconstruct the pixelized version of
the surface mass density ![]() .
A similar method for strong lensing
constraints only has recently also been presented by Diego et al. (2004).
We argue, however, that using the potential
.
A similar method for strong lensing
constraints only has recently also been presented by Diego et al. (2004).
We argue, however, that using the potential ![]() is favourable,
since
is favourable,
since ![]() ,
,
![]() ,
and
,
and
![]() locally depend upon the
potential
locally depend upon the
potential ![]() - cf. Eqs. (3), (4) - and all can be
quantified from the latter.
- cf. Eqs. (3), (4) - and all can be
quantified from the latter. ![]() and
and
![]() ,
on the other
hand, are non-local quantities of
,
on the other
hand, are non-local quantities of ![]() .
In other words, the mass
density on a finite field does not describe the shear and the
deflection angle in this field. If a finite field is used, one usually
employs Fourier analysis; in this case,
.
In other words, the mass
density on a finite field does not describe the shear and the
deflection angle in this field. If a finite field is used, one usually
employs Fourier analysis; in this case, ![]() in fact corresponds
to original
in fact corresponds
to original ![]() plus all its periodic continuations.
plus all its periodic continuations.
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{2233fig1.eps}\end{figure}](/articles/aa/full/2005/25/aa2233-04/img68.gif) |
Figure 1: The outline of the two-level iteration process. |
| Open with DEXTER | |
Further, even though not easy to implement, we decided to keep the parametrisation of the mass-distribution as general as possible. In Kneib et al. (2003) and Smith et al. (2004), on the other hand, the strong and weak lensing constraints were compared in a Bayesian approach in the form of simple, parametrised models. In addition, the weak lensing constraints were not used to the very centre of the cluster and redshifts of individual sources were not included.
The main idea behind the method is to describe the
cluster mass-distribution by a fully general lens,
using the values of the deflection potential
![]() on a regular grid. We then define a penalty function
on a regular grid. We then define a penalty function ![]() and
minimise it with respect to the values of
and
minimise it with respect to the values of ![]() .
The convergence
.
The convergence ![]() ,
the shear
,
the shear ![]() ,
and the deflection angle
,
and the deflection angle
![]() at an arbitrary position in the field are
obtained by finite differencing and bilinear interpolation
methods. The number of grid points we use for
at an arbitrary position in the field are
obtained by finite differencing and bilinear interpolation
methods. The number of grid points we use for ![]() is
is
![]() ;
the extension by one row and one column at
each side is needed to perform the finite differencing
at each inner
;
the extension by one row and one column at
each side is needed to perform the finite differencing
at each inner
![]() grid point.
grid point.
We define the
![]() -function as follows
-function as follows
| |
Figure 2:
The finite differencing coefficients for |
| Open with DEXTER | |
The reconstruction is performed in a two-level iteration process,
outlined in Fig. 1. We will refer to
the iteration process mentioned above for solving the linear system of
equations as inner-level, where steps n1 are repeated until
convergence of ![]() .
The outer-level iteration is performed
for the purpose of regularisation (as described in detail
in Sect. 3.3). In order to penalise small-scale
fluctuations in the surface mass density, we
start the reconstruction with a coarse grid (large cell size).
Then for each n2 step
we increase the number of grid points in the field
and compare the new reconstructed
.
The outer-level iteration is performed
for the purpose of regularisation (as described in detail
in Sect. 3.3). In order to penalise small-scale
fluctuations in the surface mass density, we
start the reconstruction with a coarse grid (large cell size).
Then for each n2 step
we increase the number of grid points in the field
and compare the new reconstructed
![]() with the one from the previous iteration
with the one from the previous iteration
![]() (or with the initial input value
(or with the initial input value
![]() for
n2=0). The
second-level iterations are performed until the final grid size is
reached and convergence is achieved.
for
n2=0). The
second-level iterations are performed until the final grid size is
reached and convergence is achieved.
We use the finite differencing method with
9 grid points to calculate ![]() ,
5 points for
,
5 points for ![]() ,
and 4
points for
,
and 4
points for
![]() (see Abramowitz & Stegun 1972).
The coefficients used for
(see Abramowitz & Stegun 1972).
The coefficients used for ![]() and
and ![]() are given in
Fig. 2, the case of
are given in
Fig. 2, the case of
![]() is discussed in
Appendix A.2. To
evaluate
is discussed in
Appendix A.2. To
evaluate
![]() ,
,
![]() ,
and
,
and
![]() at a position
at a position
![]() within the field, bilinear
interpolation is used.
within the field, bilinear
interpolation is used.
Note, that the dimensionality of the problem is not
![]() .
Because the transformation
.
Because the transformation
![]() leaves
leaves ![]() and
and
![]() invariant, the potential needs to be fixed at three points
(see Seitz et al. 1998; Bartelmann et al. 1996). These thus fix the constant and
linear term in the invariance transformation. If this is not the
case, a minimum in
invariant, the potential needs to be fixed at three points
(see Seitz et al. 1998; Bartelmann et al. 1996). These thus fix the constant and
linear term in the invariance transformation. If this is not the
case, a minimum in ![]() would correspond to a three-dimensional
subspace of possible solutions. The choice of the three points, and
the corresponding values of the potential are arbitrary. Although the
transformation
would correspond to a three-dimensional
subspace of possible solutions. The choice of the three points, and
the corresponding values of the potential are arbitrary. Although the
transformation
![]() changes the deflection angle
changes the deflection angle
![]() ,
it only
causes a translation of the source plane, which is not an
observable. Therefore, even in the presence of strong lensing, three
points of the potential need to be held fixed.
,
it only
causes a translation of the source plane, which is not an
observable. Therefore, even in the presence of strong lensing, three
points of the potential need to be held fixed.
The mass-sheet degeneracy transformation of the potential is given
by
![]() .
However since we aim at lifting this
degeneracy, in contrast to
Seitz et al. (1998) the potential
.
However since we aim at lifting this
degeneracy, in contrast to
Seitz et al. (1998) the potential ![]() ,
is not held fixed at an
additional, fourth point.
The dimensionality of the problem is thus
,
is not held fixed at an
additional, fourth point.
The dimensionality of the problem is thus
![]() .
.
In this section we will describe contributions to the
![]() -function, starting with the statistical weak lensing.
-function, starting with the statistical weak lensing.
For ![]() galaxies with measured
ellipticities
galaxies with measured
ellipticities
![]() we define the
we define the
![]() as
as
In Bradac et al. (2004a)![]() we argue that
we argue that
![]() can give biased results for lenses for which many galaxies have
can give biased results for lenses for which many galaxies have
![]() .
It would be better to work with a log-likelihood
function with a probability distribution that properly describes the
distribution of observed ellipticities. Unfortunately, such an
approach is not viable here (as will become obvious later on).
However, in general clusters do not have a large fraction of galaxies
with
.
It would be better to work with a log-likelihood
function with a probability distribution that properly describes the
distribution of observed ellipticities. Unfortunately, such an
approach is not viable here (as will become obvious later on).
However, in general clusters do not have a large fraction of galaxies
with
![]() and we show in Bradac et al. (2004a) that for
these lenses the
and we show in Bradac et al. (2004a) that for
these lenses the ![]() -minimisation is sufficient.
-minimisation is sufficient.
One of the major strengths of this statistical weak lensing reconstruction
technique is the possibility to simultaneously include
constraints from multiple image systems to the weak lensing data in a
relatively straightforward manner. The simplest approach to strong
lensing is to perform the so-called
"source plane'' modelling; i.e. to
minimise the projected source position difference.
Consider a multiple image system with the source at redshift
![]() and with
and with ![]() images located
at
images located
at
![]() .
We define
.
We define
![]() and the corresponding
and the corresponding ![]() -function is given by
-function is given by
We are aware of the fact that the approach we use is not optimal (see
e.g. Kochanek 2004). If only multiple imaging is used, the
resulting best-fit model is biased towards high magnification factors,
since errors on the source plane are magnified when projected back to
the image plane (this information we do not use). In our case,
however, the model also needs to take into account the constraints
from statistical (weak) lensing and therefore the high magnification
models are in fact discarded. In addition, if e.g. one considers the
errors matrix in the image plane to be diagonal, the corresponding
matrix in the source plane would have large off-diagonal terms.
Throughout this paper we therefore consider the errors in the source
plane to be isotropic, since this may in fact be a better
approximation, as sources are on average more circular than their
lensed images. In practice the location of the multiple images are
usually known very accurately, leading to a very narrow minimum of
![]() in the parameter space. In practice, multiple image
constraints are satisfied nearly perfectly and exact values of errors
on image positions are of lesser importance.
in the parameter space. In practice, multiple image
constraints are satisfied nearly perfectly and exact values of errors
on image positions are of lesser importance.
Since the minimisation of
![]() can lead to a potential
that reconstructs the noise in the data, the solution needs to be
regularised. Even without measurement errors, the intrinsic
ellipticities would still produce pronounced small-scale noise peaks
in the final reconstruction. In addition, the method presented here
has an intrinsic invariance if no multiple imaging information is used
and the weak lensing approximation
can lead to a potential
that reconstructs the noise in the data, the solution needs to be
regularised. Even without measurement errors, the intrinsic
ellipticities would still produce pronounced small-scale noise peaks
in the final reconstruction. In addition, the method presented here
has an intrinsic invariance if no multiple imaging information is used
and the weak lensing approximation
![]() applies. Namely,
we can alternately add/subtract a constant a along diagonals of the
potential (chess-board like structure, as sketched in
Fig. 3). This transformation would on the one hand not
affect
applies. Namely,
we can alternately add/subtract a constant a along diagonals of the
potential (chess-board like structure, as sketched in
Fig. 3). This transformation would on the one hand not
affect ![]() ,
but on the other it would cause a similar change
(with a constant 2a/3) in
,
but on the other it would cause a similar change
(with a constant 2a/3) in ![]() - compare with
Fig. 2. Thus in the
- compare with
Fig. 2. Thus in the
![]() regime, where
regime, where
![]() these stripes would show up in the
resulting
these stripes would show up in the
resulting ![]() -map. This problem can, however, be very efficiently
cured with regularisation.
-map. This problem can, however, be very efficiently
cured with regularisation.
![\begin{figure}
\par\includegraphics[width=4.3cm,clip]{2233fig3.eps}\end{figure}](/articles/aa/full/2005/25/aa2233-04/img112.gif) |
Figure 3:
The intrinsic invariance of the method. If we alternately
add/subtract a constant a along the diagonals the shear |
| Open with DEXTER | |
Since we want to measure the cluster mass, the regularisation should
not influence breaking the mass-sheet degeneracy. For example, one of
the possibilities considered by Seitz et al. (1998) for regularisation
function was
![]() .
However, as the authors mentioned, such regularisation would tend to
flatten the profile and therefore affect the mass-sheet degeneracy
breaking. Their maximum-entropy regularisation with moving prior
(i.e. the prior in the regularisation is not kept constant, but
adapted in the process of minimisation) does not flatten the profile,
however it is very cumbersome to express its derivative in linear
terms of
.
However, as the authors mentioned, such regularisation would tend to
flatten the profile and therefore affect the mass-sheet degeneracy
breaking. Their maximum-entropy regularisation with moving prior
(i.e. the prior in the regularisation is not kept constant, but
adapted in the process of minimisation) does not flatten the profile,
however it is very cumbersome to express its derivative in linear
terms of ![]() .
Motivated by the success of moving prior in
maximum-entropy regularisation, we choose a very simple prescription
for the regularisation function. We start off by a relatively coarse
grid, since if the number of grid points
.
Motivated by the success of moving prior in
maximum-entropy regularisation, we choose a very simple prescription
for the regularisation function. We start off by a relatively coarse
grid, since if the number of grid points
![]() is much smaller
than the number of galaxies, the resulting reconstruction is not able
to follow the noise pattern. In each second-level iteration step we
gradually increase the number of grid points and compare the resulting
is much smaller
than the number of galaxies, the resulting reconstruction is not able
to follow the noise pattern. In each second-level iteration step we
gradually increase the number of grid points and compare the resulting
![]() map
map
![]() with that from the previous iteration
with that from the previous iteration
![]() linearly interpolated on a finer grid, thus
linearly interpolated on a finer grid, thus
![\begin{figure}
\par\includegraphics[width=15.2cm]{2233fig4.ps}\par {\hspace*{4cm}
\bf (a)\hspace*{7.5cm}
\bf (b)\hspace*{4cm}}
\par\end{figure}](/articles/aa/full/2005/25/aa2233-04/img118.gif) |
Figure 4:
The gravitational lensing properties of a simulated cluster
used for generating mock catalogues for statistical weak lensing and
for the multiple image system. a) The surface mass density |
| Open with DEXTER | |
Finally a word on the regularisation constant ![]() .
This parameter
should, in theory, be set such to ensure
.
This parameter
should, in theory, be set such to ensure
![]() .
In practice, however, it is difficult to determine its optimal value
(in the critical lensing regime). As outlined in Geiger & Schneider (1998) the
probability distribution of measured ellipticities is not a Gaussian
and therefore the minimum value of
.
In practice, however, it is difficult to determine its optimal value
(in the critical lensing regime). As outlined in Geiger & Schneider (1998) the
probability distribution of measured ellipticities is not a Gaussian
and therefore the minimum value of ![]() has no particular
meaning. In practice, setting
has no particular
meaning. In practice, setting ![]() such that the resulting
such that the resulting
![]() (where
(where
![]() is in our case the
number of galaxies used for strong and weak lensing) is valid is a
good guess for this parameter. In addition, one adjusts
is in our case the
number of galaxies used for strong and weak lensing) is valid is a
good guess for this parameter. In addition, one adjusts ![]() low
enough for the method to have enough freedom to adapt to the
information in the data and large enough for not allowing the
solutions that follow the noise pattern. As a rule of thumb it is
usually better to set
low
enough for the method to have enough freedom to adapt to the
information in the data and large enough for not allowing the
solutions that follow the noise pattern. As a rule of thumb it is
usually better to set ![]() high and increase the number of
iterations and hence allowing
high and increase the number of
iterations and hence allowing ![]() to change only slowly. Since
the reconstruction is done in a two-level iteration and in addition
multiple-image information is included, the method can successfully
adapt to the data and the results are not very sensitive to the
precise value of
to change only slowly. Since
the reconstruction is done in a two-level iteration and in addition
multiple-image information is included, the method can successfully
adapt to the data and the results are not very sensitive to the
precise value of ![]() .
The resulting smoothness level of the mass
maps should reflect the quality of data. The "smoothing scale''
depends upon the combination of the grid size and regularisation. The
final potential map should be void of any structures on scales smaller
than the mean separation between galaxies used for weak lensing. We
will shortly return to this point in Sect. 4.3.
.
The resulting smoothness level of the mass
maps should reflect the quality of data. The "smoothing scale''
depends upon the combination of the grid size and regularisation. The
final potential map should be void of any structures on scales smaller
than the mean separation between galaxies used for weak lensing. We
will shortly return to this point in Sect. 4.3.
In our case different initial conditions are employed. For the initial
model
![]() we use three different scenarios:
we use three different scenarios:
![]() (and
(and
![]() ,
,
![]() )
across the whole field (hereafter I0),
)
across the whole field (hereafter I0),
![]() taken from the best fit non-singular isothermal
ellipsoid model NIE for the multiple image system described in
Sect. 4.2 (hereafter IM) and a non-singular isothermal
sphere model NIS with scaling and core radius being the same as in
IM (hereafter IC). The same models are used also to obtain
the initial coefficients of the linear system (see Appendix) (for I0 we use
taken from the best fit non-singular isothermal
ellipsoid model NIE for the multiple image system described in
Sect. 4.2 (hereafter IM) and a non-singular isothermal
sphere model NIS with scaling and core radius being the same as in
IM (hereafter IC). The same models are used also to obtain
the initial coefficients of the linear system (see Appendix) (for I0 we use
![]() ). These different initial models help us
to explore the effects of regularisation and the capability of the
reconstruction method to adapt to the data.
). These different initial models help us
to explore the effects of regularisation and the capability of the
reconstruction method to adapt to the data.
We generate mock catalogues using a cluster from the
high-resolution N-body simulation by Springel et al. (2001). The cluster
is taken from the S4 simulation (for details see the aforementioned
paper) and was simulated in the framework of the ![]() CDM
cosmology with density parameters
CDM
cosmology with density parameters
![]() and
and
![]() ,
shape parameter
,
shape parameter
![]() ,
the
normalisation of the power spectrum
,
the
normalisation of the power spectrum
![]() ,
and Hubble
constant
,
and Hubble
constant
![]() .
The cluster
simulation consists of almost 20 million particles, each with a mass
of
.
The cluster
simulation consists of almost 20 million particles, each with a mass
of
![]() and a gravitational softening length
of
and a gravitational softening length
of
![]() .
Due to the high mass resolution, the
surface mass density
.
Due to the high mass resolution, the
surface mass density ![]() -map can be obtained by directly
projecting the particles (in our case along the z-axis) onto a
10242 grid (of a side length
-map can be obtained by directly
projecting the particles (in our case along the z-axis) onto a
10242 grid (of a side length
![]() )
using the NGP
(nearest gridpoint) assignment.
)
using the NGP
(nearest gridpoint) assignment.
In what follows we try to generate the weak and strong lensing data to
resemble as close as possible the data on the cluster RX J1347.5-1145 we will
use in Paper II. The surface mass density of the
cluster is therefore scaled to have a sizeable region where
multiple imaging is possible within a
![]() field, for sources at redshifts
field, for sources at redshifts
![]() and a cluster
at
and a cluster
at
![]() .
The Einstein radius for a fiducial source at
.
The Einstein radius for a fiducial source at
![]() is roughly
is roughly
![]() ,
giving a
line-of-sight integrated mass within this radius of
,
giving a
line-of-sight integrated mass within this radius of
![]() .
The cut-out of the resulting
.
The cut-out of the resulting ![]() map
(for
map
(for
![]() ,
thus Z(z) = 1) we use can be seen in
Fig. 4a.
,
thus Z(z) = 1) we use can be seen in
Fig. 4a.
The lensing properties are calculated as described in detail in
Bradac et al. (2004b). The Poisson equation for the lens potential ![]() - cf. Eq. (3) - is solved on the grid in Fourier space
with a DFT (Discrete Fourier Transformation) method using the FFTW
library written by Frigo & Johnson (1998). The two components of the shear
- cf. Eq. (3) - is solved on the grid in Fourier space
with a DFT (Discrete Fourier Transformation) method using the FFTW
library written by Frigo & Johnson (1998). The two components of the shear
![]() and the deflection angle
and the deflection angle
![]() are obtained by
finite differencing methods applied to the potential
are obtained by
finite differencing methods applied to the potential ![]() .
These
data are then used to generate the weak lensing catalogues as well as
the multiple image systems. The absolute value of the reduced shear
(again for a source with
.
These
data are then used to generate the weak lensing catalogues as well as
the multiple image systems. The absolute value of the reduced shear
(again for a source with
![]() )
is shown in
Fig. 4b.
)
is shown in
Fig. 4b.
The weak lensing data are obtained by placing ![]() galaxies
on a
galaxies
on a
![]() field.
We have simulated two different catalogues, one
with
field.
We have simulated two different catalogues, one
with
![]() galaxies with positions corresponding to those
from R-band weak lensing data of the cluster RX J1347.5-1145 and
one with
galaxies with positions corresponding to those
from R-band weak lensing data of the cluster RX J1347.5-1145 and
one with
![]() galaxies corresponding to the I-band
data used in Paper II.
In this way we simulate the effects
of "holes'', resulting from cluster obscuration and bright stars in
the field.
galaxies corresponding to the I-band
data used in Paper II.
In this way we simulate the effects
of "holes'', resulting from cluster obscuration and bright stars in
the field.
The
intrinsic ellipticities
![]() are drawn from a Gaussian
distribution, each component is characterised by
are drawn from a Gaussian
distribution, each component is characterised by
![]() .
We use the same redshifts as those measured in the R and
I-band data, respectively. The catalogues have average redshifts for
background sources of
.
We use the same redshifts as those measured in the R and
I-band data, respectively. The catalogues have average redshifts for
background sources of
![]() and
and
![]() .
The corresponding cosmological weights are evaluated assuming the
.
The corresponding cosmological weights are evaluated assuming the
![]() CDM cosmology (the same parameters are used as for the cluster
simulations).
CDM cosmology (the same parameters are used as for the cluster
simulations).
The measurement errors
![]() on the observed
ellipticities are drawn from a Gaussian distribution with
on the observed
ellipticities are drawn from a Gaussian distribution with
![]() (each component) and added to the lensed
ellipticities. We considered also the measurement errors on the
redshifts of the galaxies to simulate the use of photometric
redshifts. These have
(each component) and added to the lensed
ellipticities. We considered also the measurement errors on the
redshifts of the galaxies to simulate the use of photometric
redshifts. These have
![]() (see Bolzonella et al. 2000); in adding the errors we ensured that the
resulting redshifts are always positive. We have also simulated the
presence of outliers in the redshift distribution,
(see Bolzonella et al. 2000); in adding the errors we ensured that the
resulting redshifts are always positive. We have also simulated the
presence of outliers in the redshift distribution, ![]() of our
background sources (chosen at random) are considered outliers,
for these we randomly
add/subtract
of our
background sources (chosen at random) are considered outliers,
for these we randomly
add/subtract
![]() to their redshifts (which already include
random errors). The lensed ellipticities are obtained using
Eq. (9) and interpolating the quantities
to their redshifts (which already include
random errors). The lensed ellipticities are obtained using
Eq. (9) and interpolating the quantities ![]() ,
and
,
and ![]() at the galaxy position using bilinear
interpolation, considering the redshifts including errors.
In contrast, for the purpose of reconstruction we then consider
galaxies to be at their "original'' redshifts (thus equal to the
observed redshifts in the data of RX J1347.5-1145).
at the galaxy position using bilinear
interpolation, considering the redshifts including errors.
In contrast, for the purpose of reconstruction we then consider
galaxies to be at their "original'' redshifts (thus equal to the
observed redshifts in the data of RX J1347.5-1145).
The errors on image positions can be conservatively
estimated (for the data we use in Paper II)
to
![]() .
Since we need
errors in the source plane, we set them by a factor of five smaller
(in agreement with the average magnification factor for this system), i.e.
.
Since we need
errors in the source plane, we set them by a factor of five smaller
(in agreement with the average magnification factor for this system), i.e.
![]() for both coordinates (see discussion in Sect. 3.3).
for both coordinates (see discussion in Sect. 3.3).
We also use this system to obtain one of the
![]() models,
needed for the purpose of strong and weak lensing reconstruction. We
perform image plane minimisation and fit an NIE model (Kormann et al. 1994), given by
models,
needed for the purpose of strong and weak lensing reconstruction. We
perform image plane minimisation and fit an NIE model (Kormann et al. 1994), given by
![\begin{figure}
\par\subfigure[{\bf (a1)}]{\includegraphics[width=6cm,clip]{2233f...
...figure[{\bf (c2)}]{\includegraphics[width=6cm,clip]{2233fig5f.ps} }
\end{figure}](/articles/aa/full/2005/25/aa2233-04/img157.gif) |
Figure 5:
|
| Open with DEXTER | |
Table 1:
Reconstructed cluster mass within a cylinder of
![]() radius around the cluster centre from simulations
of mock catalogues resembling I-band ( left) and R-band ( right) weak
lensing data and one 4-image system. Three different initial
conditions are used. We use the best fit model from the multiple
image system IM (see Sect. 4.2), the IC model
(NIS with same scaling and core radius as IM) and I0 with
radius around the cluster centre from simulations
of mock catalogues resembling I-band ( left) and R-band ( right) weak
lensing data and one 4-image system. Three different initial
conditions are used. We use the best fit model from the multiple
image system IM (see Sect. 4.2), the IC model
(NIS with same scaling and core radius as IM) and I0 with
![]() on all grid points. In the last line the input mass
on all grid points. In the last line the input mass
![]() from the simulation is given. The variance of the mass
estimate is given and in brackets we give for
comparison the velocity dispersion of an SIS having the same enclosed
mass within
from the simulation is given. The variance of the mass
estimate is given and in brackets we give for
comparison the velocity dispersion of an SIS having the same enclosed
mass within
![]() .
.
From the reconstructed maps we estimate the mass within the
![]() radius from the centre of the cluster (for a redshift
radius from the centre of the cluster (for a redshift
![]() this corresponds to
this corresponds to
![]() )
projected along the line-of-sight. For this purpose we generate 10 mock catalogues for each band and did the reconstruction again with
the three different initial models. We list the resulting average mass
obtained from the catalogues in Table 1 for both the
I- and R-band mock catalogues. All the mass estimates are similar;
note, however, that the galaxy catalogues following the I- and R-band
data have galaxies partly in common and the errors are therefore
correlated. We find the enclosed mass of the simulated cluster to be
)
projected along the line-of-sight. For this purpose we generate 10 mock catalogues for each band and did the reconstruction again with
the three different initial models. We list the resulting average mass
obtained from the catalogues in Table 1 for both the
I- and R-band mock catalogues. All the mass estimates are similar;
note, however, that the galaxy catalogues following the I- and R-band
data have galaxies partly in common and the errors are therefore
correlated. We find the enclosed mass of the simulated cluster to be
![]() ,
which is very close to the
input value of
,
which is very close to the
input value of
![]() .
The 1-
.
The 1-![]() error is estimated from the
variance of mass determinations from different mock catalogues.
error is estimated from the
variance of mass determinations from different mock catalogues.
The results show that our method is effectively able to break
the mass-sheet degeneracy and is, as a consequence, very efficient in
reproducing the cluster mass also at radii significantly larger than
the Einstein radius of the cluster. It is also very encouraging that
the results are nearly independent of the initial
![]() used
for the regularisation. Note that a single multiple-image system does
not by itself break this degeneracy, we would need at least two
different redshift multiple image systems to break the mass-sheet
degeneracy with strong lensing data alone. In such a case the strong
lensing gives constraints on the mass enclosed within the Einstein
radius for a given source redshift and since the critical curves
depend on the source redshift, we can constrain mass at two different
radii and the degeneracy is broken. The combiniation of weak and
strong lensing is the more powerful, the more different the redshift
of the source of the multiple images is from the median redshift of
the galaxies from which the weak lensing measurements are obtained,
and the less symmetric the arrangement of multiple images is
w.r.t. the center of the cluster.
used
for the regularisation. Note that a single multiple-image system does
not by itself break this degeneracy, we would need at least two
different redshift multiple image systems to break the mass-sheet
degeneracy with strong lensing data alone. In such a case the strong
lensing gives constraints on the mass enclosed within the Einstein
radius for a given source redshift and since the critical curves
depend on the source redshift, we can constrain mass at two different
radii and the degeneracy is broken. The combiniation of weak and
strong lensing is the more powerful, the more different the redshift
of the source of the multiple images is from the median redshift of
the galaxies from which the weak lensing measurements are obtained,
and the less symmetric the arrangement of multiple images is
w.r.t. the center of the cluster.
Unfortunately we can not resolve both clumps present in the
simulations. This is due to the fact that the number density of
background sources is low and the internal smoothing scale (i.e. the
average distance between two source galaxies) is large; with a number
density of
![]() the
clumps can be easily resolved.
the
clumps can be easily resolved.
We have also performed additional reconstructions in which we
multiplied the original values of ![]() of the simulated cluster by
0.75 and 1.25. This enables us to confirm that the agreement between input
mass and reconstructed mass is not just accidental. We
have generated new multiple image systems and new mock catalogues as
before. We do not, however, perform a new strong-lensing reconstruction,
for
of the simulated cluster by
0.75 and 1.25. This enables us to confirm that the agreement between input
mass and reconstructed mass is not just accidental. We
have generated new multiple image systems and new mock catalogues as
before. We do not, however, perform a new strong-lensing reconstruction,
for
![]() we intentionally use the same (i.e. in this case
"wrong'') initial
conditions as before. The old IM model would not fit the image
positions any longer, since they have changed with the scaling of
we intentionally use the same (i.e. in this case
"wrong'') initial
conditions as before. The old IM model would not fit the image
positions any longer, since they have changed with the scaling of
![]() .
The reconstructed masses of the increased
.
The reconstructed masses of the increased ![]() simulation
are in good agreement with the input values. The differences
between different models are comparable (slightly smaller) to the ones
shown in
Table 1. For the lower
simulation
are in good agreement with the input values. The differences
between different models are comparable (slightly smaller) to the ones
shown in
Table 1. For the lower ![]() simulation, the
reconstructed values are on average the same as the input value, however
the scatter is larger. This is expected, since the lens in this
case is weaker and the breaking of the mass-sheet degeneracy is
difficult in this case (with the quality of data used here).
simulation, the
reconstructed values are on average the same as the input value, however
the scatter is larger. This is expected, since the lens in this
case is weaker and the breaking of the mass-sheet degeneracy is
difficult in this case (with the quality of data used here).
As an additional test we also consider a redshift distribution with
![]() for the sources used for weak lensing and regenerate
the mock catalogues. The accuracy of the determination of the enclosed
mass increases. However, more importantly, we also better reconstruct
the shape of the mass distribution, since
high-redshift galaxies (when their shape is measured reliably)
contribute most to the signal and improve the accuracy of the
reconstruction.
for the sources used for weak lensing and regenerate
the mock catalogues. The accuracy of the determination of the enclosed
mass increases. However, more importantly, we also better reconstruct
the shape of the mass distribution, since
high-redshift galaxies (when their shape is measured reliably)
contribute most to the signal and improve the accuracy of the
reconstruction.
In this paper we develop a new method based on
Bartelmann et al. (1996) to perform a combined weak and strong lensing
cluster mass reconstruction. The particular strength of this method is
that we extend the weak lensing analysis to the critical parts of the
cluster. In turn, this enables us to directly include multiple imaging
information to the reconstruction. Strong and weak lensing
reconstructions are performed on the same scales, in contrast to
similar methods proposed in the past where weak lensing information on
much larger radii than the Einstein radius
![]() was
combined with strong lensing information (see e.g. Kneib et al. 2003).
was
combined with strong lensing information (see e.g. Kneib et al. 2003).
We test the performance of the method on simulated data and conclude
that if a quadruply imaged system combined with weak lensing data and
individual photometric redshifts is used, the method can very
successfully reconstruct the cluster mass distribution. With a
relatively low number density of background galaxies,
![]() ,
we are effectively able to reproduce the main
properties of the simulated cluster. In addition, with larger number
densities
,
we are effectively able to reproduce the main
properties of the simulated cluster. In addition, with larger number
densities
![]() of background sources,
accessible by HST, the substructures in the cluster can be resolved
and the mass determination further improved.
of background sources,
accessible by HST, the substructures in the cluster can be resolved
and the mass determination further improved.
We determine the enclosed mass within
![]() of the
simulated cluster to be
of the
simulated cluster to be
![]() ,
which is very close to the input value of
,
which is very close to the input value of
![]() .
We have shown,
that with the data quality we use we are effectively able to break the
mass-sheet degeneracy and therefore obtain the mass and
mass-distribution estimates without prior assumptions on the lensing
potential.
.
We have shown,
that with the data quality we use we are effectively able to break the
mass-sheet degeneracy and therefore obtain the mass and
mass-distribution estimates without prior assumptions on the lensing
potential.
In addition, the reconstruction algorithm can be improved in many ways. First, we use for the multiply imaged system only the information of the image positions. The reconstruction method can, however, be modified to include the morphological information of each extended source. Instead of using a regular grid, one would have to use adaptive grids and decrease the cell sizes around each of these images. This will be a subject of a future work. Second, the photometric redshift determination does not only give the most likely redshift given the magnitudes in different filters, but also the probability distribution for the redshift. This information can be included in the reconstruction. In addition, source galaxies without redshift information can be included and different regularisation schemes can be considered.
Finally, the slight dependence on the initial conditions is getting
weaker the higher the number density of background galaxies and/or
multiple image systems are. In addition, it is of advantage to have a
large spread in the redshift efficiency factors Z of the background
galaxies. For example, deep ACS images of clusters with a usable
number density of
![]() ,
or future
observations with the James Webb Space Telescope will most likely make
the dependence on the initial conditions negligible.
,
or future
observations with the James Webb Space Telescope will most likely make
the dependence on the initial conditions negligible.
In Paper II we will show the application of this method on the cluster RX J1347.5-1145 and confirm that a combination of strong and weak lensing offers a unique tool to pin down the masses of galaxy-clusters as well as their mass distributions.
Acknowledgements
We would like to give special thanks to Volker Springel for providing us with the cluster simulations. We would further like to thank Léon Koopmans and Oliver Czoske for many useful discussions that helped to improve the paper. We also thank our referee for his constructive comments. This work was supported by the International Max Planck Research School for Radio and Infrared Astronomy, by the Bonn International Graduate School, and by the Deutsche Forschungsgemeinschaft under the project SCHN 342/3-3. MB acknowledges support from the NSF grant AST-0206286. This project was partially supported by the Department of Energy contract DE-AC3-76SF00515 to SLAC.
In this section we present details of the method outlined in Sect. 3.
We aim to solve the equation
Following the prescription from the previous section we now write the
deflection angle in a matrix form
The ![]() contribution to strong lensing is given in Eq. (15).
The source position
contribution to strong lensing is given in Eq. (15).
The source position
![]() is kept constant at every
iteration step, and is evaluated using the deflection angle
information
is kept constant at every
iteration step, and is evaluated using the deflection angle
information
![]() from the previous iteration
from the previous iteration
In the previous section we describe how we linearise the
contributions of weak and strong lensing, now we can write the
coefficients in the Eq. (A.2). Note that the contribution of the regularisation term (with
![]() -contribution given in Eq. (16)) is already linear in
-contribution given in Eq. (16)) is already linear in
![]() and therefore the full matrix
and therefore the full matrix
![]() is given in the form
is given in the form
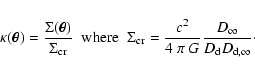
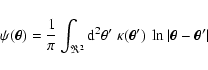
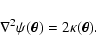
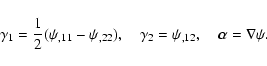
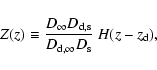
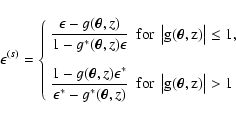
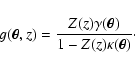
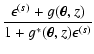
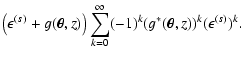
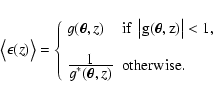
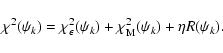
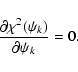
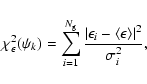
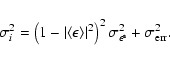
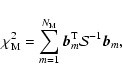
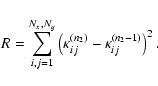
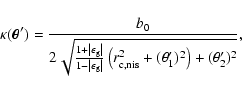
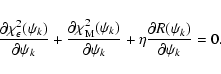
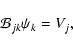
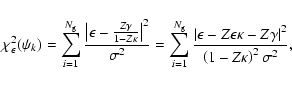
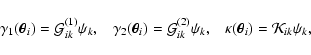
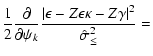
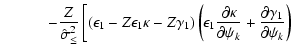
![$\displaystyle \quad\quad\quad+\left. \left( \epsilon_2 -
Z\epsilon_2\kappa -Z
\...
...ppa}{\partial\psi_k}
+ \frac{\partial\gamma_2}{\partial\psi_k} \right)\right] =$](/articles/aa/full/2005/25/aa2233-04/img196.gif)