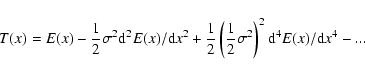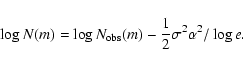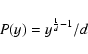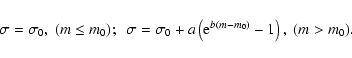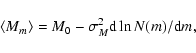A&A 424, 73-78 (2004)
DOI: 10.1051/0004-6361:20040567
P. Teerikorpi
Tuorla Observatory, University of Turku, 21500 Piikkiö, Finland
Received 31 March 2004 / Accepted 11 May 2004
Abstract
We study the influence of the Eddington bias on measured
distributions, in particular counts of galaxies when the accuracy of
magnitude measurements is variable, e.g. when it changes towards fainter
objects.
Numerical experiments using different error laws illustrate the effect
on the measured slope, helping one to decide if the variable Eddington
bias is important, when the simple analytic correction is no longer valid.
Common views on the origin and appearance of the Eddington bias are
clarified and its relation to the classical Malmquist bias is briefly
discussed. We illustrate the "Eddington shift'' approach with the counts
of bright galaxies in the LEDA database.
Key words: galaxies: statistics
Here we study the Eddington bias in a generalized form, keeping in mind applications for galaxy counts if the magnitude accuracy is variable. We assess how much these effects may influence the counts. For example, to be more immune to local structures, the counts of bright galaxies should be all-sky, but these are currently based on data with variable accuracy. In deep counts the accuracy may drop significantly within a few faintest magnitudes. The historical roots of the Eddington bias are in stellar parallaxes, see Sandage & Saha (2002) for an interesting discussion.
We review the classical Eddington bias (Sect. 2) and discuss its origin (Sect. 3) as a background to the more general cases when the sample is made of subsamples with different measurement accuracy (Sect. 5) or when the accuracy systematically depends on the magnitude (Sect. 7). In Sect. 4 "the Eddington shift'' is introduced as a way to treat the data in a special case. Numerical simulations illustrate some cases (Sect. 6) and different systematic error laws (Sect. 8). In Sect. 9 the ideas are applied to the LEDA galaxy sample. Main conclusions are found in Sect. 10. In the Appendices the Eddington and Malmquist biases are considered when they are coupled.
Eddington (1913) posed and briefly discussed
the question:
if the observed or experimental distribution function of quantities X with
measured values x is EX(x), what is the true distribution of errorless
quantities TX(x), when the errors of measurement ![]() are assumed
to have a Gaussian distribution with dispersion
are assumed
to have a Gaussian distribution with dispersion ![]() ? In Eddington
(1940), he studied this issue in some detail,
after a contribution by Dyson (1926).
? In Eddington
(1940), he studied this issue in some detail,
after a contribution by Dyson (1926).
Eddington derived the following general relation between the two distributions:
As a background for the following discussion it is useful to inspect a little closer the origin of the Eddington bias. The reason why the measured distribution differs from the true one is not always clearly appreciated. Sometimes it is overly simply said that it is due to (in the case of magnitudes) the increase of the distribution towards faint magnitudes. Indeed, according to Eq. (1) the bias vanishes when the measured distribution is constant. But it also vanishes for a linearly increasing (or decreasing) distribution, because then the second (and further) derivatives are zero.
One may say that the galaxies
at a fixed measured magnitude originate either from brighter or fainter
true magnitudes, due to the symmetric Gaussian error distribution.
Galaxies originally
at
![]() are lost equally to the right and left.
If the distribution is constant,
it is immediately clear that "incomers'' from the right and the
left compensate
for those losses. But also if the distribution is linear (and
increasing to the right), the smaller number
of incomers from the left are exactly compensated by the larger number
from the right - their sum is the same as the loss
are lost equally to the right and left.
If the distribution is constant,
it is immediately clear that "incomers'' from the right and the
left compensate
for those losses. But also if the distribution is linear (and
increasing to the right), the smaller number
of incomers from the left are exactly compensated by the larger number
from the right - their sum is the same as the loss![]() .
The compensation may be incomplete and the bias
in the counts appears, if the distribution
function is not linear and has its 2nd derivative non-zero at m.
.
The compensation may be incomplete and the bias
in the counts appears, if the distribution
function is not linear and has its 2nd derivative non-zero at m.
One sometimes reads that the Eddington bias is important only close to the magnitude limit. Actually it operates at all magnitudes, as is clear from the explanation above. It is a relative of the classical Malmquist (1920) bias, which also works at all m. A main result of Lutz & Kelker (1973) was that the bias in stellar parallaxes occurs at all parallaxes. In Appendix A we briefly compare the Eddington and Malmquist biases and ask what happens when they work in concert.
The exponential law of counts is convenient mathematically and is of course
expected,
when the number density law is
![]() :
:
![]() ,
where
,
where
![]() .
D = 3 corresponds to a uniform spatial distribution (the well-known
prediction for counts: 100.6m).
Values D < 3 appear e.g. in fractal distributions.
.
D = 3 corresponds to a uniform spatial distribution (the well-known
prediction for counts: 100.6m).
Values D < 3 appear e.g. in fractal distributions.
Consider the observed magnitude interval
![]() .
The galaxies counted
at this magnitude window originate from different true magnitudes.
In the case of an exponential (true) magnitude distribution
.
The galaxies counted
at this magnitude window originate from different true magnitudes.
In the case of an exponential (true) magnitude distribution
![]() it is easy to
calculate (1) the number
it is easy to
calculate (1) the number
![]() of galaxies at
of galaxies at
![]() ,
and
(2) the distribution of the error
,
and
(2) the distribution of the error ![]() ,
when the original true magnitude is
,
when the original true magnitude is
![]() and the
individual measurement errors follow a Gaussian law with
the dispersion
and the
individual measurement errors follow a Gaussian law with
the dispersion ![]() .
.
The result for (1) is essentially Eq. (2):
![]() .
This formula may be used to correct the counts by the constant factor.
Note that the same corrected result is obtained if one increases each observed
magnitude by the quantity
.
This formula may be used to correct the counts by the constant factor.
Note that the same corrected result is obtained if one increases each observed
magnitude by the quantity
![]() and then repeats the counts, i.e.:
and then repeats the counts, i.e.:
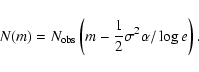 |
(4) |
The result for (2) above, also visible from Eq. (10) in Eddington (1940), is
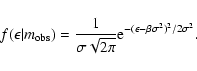 |
(5) |
In practice, things are more complex if the sample is
made from subsamples with different levels of precision, or
standard deviation, ![]() in measured magnitudes. Here
two basic cases appear: 1) on average, the errors do not depend on the
magnitude, or 2) there is a systematic change towards larger errors when
the magnitude increases. We discuss in this section the first case.
in measured magnitudes. Here
two basic cases appear: 1) on average, the errors do not depend on the
magnitude, or 2) there is a systematic change towards larger errors when
the magnitude increases. We discuss in this section the first case.
Assume that one can assign to each galaxy two different mean errors
![]() or
or ![]() and these two classes are similarly (exponentially)
distributed along m. Then one may apply to each magnitude
its own Eddington shift, and then do the counts.
The correction
does not change the slope, but will lead to a more accurate amplitude and
may reduce fluctuations. This may be generalized to the case when there are
several classes with different
and these two classes are similarly (exponentially)
distributed along m. Then one may apply to each magnitude
its own Eddington shift, and then do the counts.
The correction
does not change the slope, but will lead to a more accurate amplitude and
may reduce fluctuations. This may be generalized to the case when there are
several classes with different ![]() .
Also, if a catalogue contains
magnitudes as weighted averages from two independent
sources with different
.
Also, if a catalogue contains
magnitudes as weighted averages from two independent
sources with different ![]() ,
one may use the weighted
,
one may use the weighted ![]() in the
correction.
in the
correction.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0567_f1a.eps}\vspace*{3mm}
\includegraphics[width=8.5cm,clip]{0567_f1b.eps}
\end{figure}](/articles/aa/full/2004/34/aa0567-04/img35.gif) |
Figure 1:
a) Differential counts
for simulated uniform space distribution. Dots: no measurement error.
Open circles: errors with
|
| Open with DEXTER | |
We characterize the true radial space distribution
of galaxies using the parameter D.
It is like the fractal dimension only in the sense that the radial number
density around us is ![]() rD-3, which we generate
with
rD-3, which we generate
with
![]() .
.
If the variable ![]() is randomly and uniformly sampled from the interval (0, 1), then the probability distribution P(y) for the variable
is randomly and uniformly sampled from the interval (0, 1), then the probability distribution P(y) for the variable ![]() (d > 0) is (Kalos & Whitlock 1986):
(d > 0) is (Kalos & Whitlock 1986):
In this way one may generate in a dimensionless distance interval (0, 1)
a number density distribution corresponding to the assumed D. Transformation
to a physical distance range from 0 to
![]() and then to
distance moduli (and, hence, magnitudes)
allows one to study the
and then to
distance moduli (and, hence, magnitudes)
allows one to study the ![]() vs. m distribution, when
one stays a few
vs. m distribution, when
one stays a few ![]() (mag) away from the maximum distance modulus
close to which the counts become distorted
(in real galaxy space there is no such ultimate wall).
We use sufficiently large numbers in these experiments to smooth
out fluctuations.
(mag) away from the maximum distance modulus
close to which the counts become distorted
(in real galaxy space there is no such ultimate wall).
We use sufficiently large numbers in these experiments to smooth
out fluctuations.
Figure 1 shows a test simulation for the uniform distribution,
without
and with measurement error (
![]() mag), on an arbitrary magnitude
scale interval.
The straight lines, actually regression lines, both are very close
to the theoretical slope = 0.6. Note how the counts with measurement error
are distorted at the faint end - this is an artifact - but
along several magnitudes at the bright side they are shifted upwards
by a constant amount in
mag), on an arbitrary magnitude
scale interval.
The straight lines, actually regression lines, both are very close
to the theoretical slope = 0.6. Note how the counts with measurement error
are distorted at the faint end - this is an artifact - but
along several magnitudes at the bright side they are shifted upwards
by a constant amount in ![]() .
This is the classical Eddington bias. Its
size is close to that expected from Eq. (3), or
.
This is the classical Eddington bias. Its
size is close to that expected from Eq. (3), or
![]() .
.
We generate counts for a uniform distribution, using three
different
![]() ,
0.7, and 0.9 mag, randomly and equally likely
chosen for each galaxy. Figure 1b shows that the resulting
counts preserve the original slope. The counts made after
the Eddington shifts (triangles) follow the counts without measurement errors
well. This shows that applying the Eddington shift gives the correct counts.
,
0.7, and 0.9 mag, randomly and equally likely
chosen for each galaxy. Figure 1b shows that the resulting
counts preserve the original slope. The counts made after
the Eddington shifts (triangles) follow the counts without measurement errors
well. This shows that applying the Eddington shift gives the correct counts.
Errors might increase towards faint magnitudes, so that
![]() .
In such a case it is not allowed to use
Eq. (3) or
the Eddington
shifts to correct the magnitudes and the counts,
not even
with
.
In such a case it is not allowed to use
Eq. (3) or
the Eddington
shifts to correct the magnitudes and the counts,
not even
with
![]() .
This is because the
measuring errors at
.
This is because the
measuring errors at
![]() and
and
![]() are important for the
resulting bias at m.
If the errors are smaller at the bright side, then this makes the compensation,
as discussed in Sect. 3, still more incomplete
and thus enhances the Eddington effect and the attempt to correct it
analytically will generally lead to an undercorrection.
This makes numerical experimenting
a necessary and efficient way to study the influence of the Eddington bias
on counts when the error depends on the magnitude and may be large.
are important for the
resulting bias at m.
If the errors are smaller at the bright side, then this makes the compensation,
as discussed in Sect. 3, still more incomplete
and thus enhances the Eddington effect and the attempt to correct it
analytically will generally lead to an undercorrection.
This makes numerical experimenting
a necessary and efficient way to study the influence of the Eddington bias
on counts when the error depends on the magnitude and may be large.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0567_f2a.eps}\vspace*{3mm}
\includegraphics[width=8.5cm,clip]{0567_f2b.eps}
\end{figure}](/articles/aa/full/2004/34/aa0567-04/img49.gif) |
Figure 2:
|
| Open with DEXTER | |
In addition to the slope 0.6, we illustrate the effect with another input
value 0.44 (such a smaller value is locally expected if
![]() ). How much can systematically varying measurement errors change such slopes in counts?
). How much can systematically varying measurement errors change such slopes in counts?
We first experimented with a linear relation between ![]() and m:
and m:
![]() .
We take
.
We take
![]() ,
and put m0 = 11 mag.
Figure 2a gives an example of the influence of this type of
Eddington bias, when the input slope is 0.44. Inserted in the diagram is
,
and put m0 = 11 mag.
Figure 2a gives an example of the influence of this type of
Eddington bias, when the input slope is 0.44. Inserted in the diagram is
![]() for a = 0.12.
If the true
for a = 0.12.
If the true
![]() ,
then this a leads to an observed slope of 0.50.
,
then this a leads to an observed slope of 0.50.
A more realistic exponential law for the
behaviour of the error leads to a slow increase at the beginning and
a more rapid increase at faint magnitudes:
Furthermore, inspection of Fig. 2
illustrates how the Eddington bias is larger, say, at the magnitude
where the increasing
![]() reaches 0.5 mag than for the case of the constant
reaches 0.5 mag than for the case of the constant
![]() mag in Fig. 1.
If one uses at the end of the magnitude interval (
mag in Fig. 1.
If one uses at the end of the magnitude interval (
![]() )
the simple formula based on Eq. (3)
(cf. Huang et al. 1997)
)
the simple formula based on Eq. (3)
(cf. Huang et al. 1997)
![]() with the constants
with the constants
![]() and
and
![]() to calculate the change of the original slope 0.44, one obtains a too shallow slope of 0.46, instead of 0.53.
to calculate the change of the original slope 0.44, one obtains a too shallow slope of 0.46, instead of 0.53.
The increasing error at the faint magnitude end makes the counts there decline upwards leading to a steeper slope when a straight line is fitted for the whole magnitude range. Within the faintest two magnitudes the slope is still steeper, e.g. in Fig. 2b it approaches 0.55-0.6.
Figure 3 gives an example for the uniform distribution.
Generally one expects a slope larger than 0.6. Vice versa, an observed
slope of 0.6 does not necessarily imply a perfect agreement with a
uniform spatial distribution, unless the measurement errors are quite small.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{0567_f3.eps}
\end{figure}](/articles/aa/full/2004/34/aa0567-04/img61.gif) |
Figure 3:
|
| Open with DEXTER | |
The LEDA extragalactic database currently offers a catalogue
of homogeneous parameters of galaxies for the largest available
sample.
Made from the amalgamation of all available catalogues and
continually being completed with the flow of new data, the
completeness of the LEDA sample has been studied over the
years by inspecting the counts (Paturel et al. 1994; Paturel et al.
1997; Gabrielli et al. 2004; Courtois et al.
2004).
Simultaneusly,
the counts give information about the slope of the bright
end of the galaxy counts, hence on the space density law.
Here we briefly illustrate the above approach to LEDA counts.
We are also interested in seeing if the counts
are consistent with the radial density law
![]() (Teerikorpi et al. 1998).
(Teerikorpi et al. 1998).
We take all the galaxies from LEDA satisfying the following conditions:
1) The total B magnitude and its ![]() are given. 2) It is found at
galactic
latitudes
are given. 2) It is found at
galactic
latitudes
![]() deg. 3) Its B-magnitude is in the range
from 9 to 16. The total number of such galaxies is 46 481, about
equally divided between the two Galactic hemispheres.
deg. 3) Its B-magnitude is in the range
from 9 to 16. The total number of such galaxies is 46 481, about
equally divided between the two Galactic hemispheres.
Figure 4a shows the uncorrected counts for two subsamples, for the galaxies with
![]() and for those with
and for those with
![]() (
(![]() may reach 1 mag or even more).
One sees that:
may reach 1 mag or even more).
One sees that:
![\begin{figure}
\par\includegraphics[width=8.6cm,clip]{0567_f4a.eps}\vspace*{3mm}
\includegraphics[width=8.6cm,clip]{0567_f4b.eps}
\end{figure}](/articles/aa/full/2004/34/aa0567-04/img67.gif) |
Figure 4:
a) The counts within
10 < B < 16 for the all-sky LEDA
galaxies with
|
| Open with DEXTER | |
Qualitatively, the steepening of the slope at B > 13.5 is reminiscent of
what happens in
simulations (Fig. 2b). However, for it to be due to the Eddington effect,
the accuracy should decrease significantly in this magnitude range, contrary to
the behaviour of ![]() as given in LEDA.
as given in LEDA.
The shallow slope at brighter magnitudes could reflect either a local
flattened inhomogeneity (Paturel et al. 1994) or more generally a
fractal-like distribution of galaxies, with a fractal dimension
around 2-2.2 (Sylos-Labini et al.
1998; Gabrielli et al. 2004).
This slope is also consistent with the average
radial space density law, derived using
photometric distances to KLUN-galaxies
and a method which accounts for incompleteness,
corresponding to
![]() from 20 Mpc up to about 100 Mpc
(Teerikorpi et al. 1998).
This is in agreement with the fractal analysis of the LEDA galaxies
by Di Nella et al. (1996) who derived D = 2.2 within a
similar scale.
A new method of 2-point conditional density by Baryshev & Bukhmastova
(2004) gave for the LEDA galaxies
from 20 Mpc up to about 100 Mpc
(Teerikorpi et al. 1998).
This is in agreement with the fractal analysis of the LEDA galaxies
by Di Nella et al. (1996) who derived D = 2.2 within a
similar scale.
A new method of 2-point conditional density by Baryshev & Bukhmastova
(2004) gave for the LEDA galaxies
![]() .
.
For the change of the slope,
one may empirically find a typical distance
for
![]() ,
from the radial velocity vs. magnitude
diagram easily generated for the LEDA galaxies. The velocity turns out to be
around 5000 km s-1, which means a distance
100/h50 Mpc.
As the completeness of the sample and the behaviour of the
accuracy at faint magnitudes needs
further study, we leave open the interpretation of this feature (perhaps
we are encountering a wall structure
in the hypergalactic plane; Di Nella & Paturel 1994).
,
from the radial velocity vs. magnitude
diagram easily generated for the LEDA galaxies. The velocity turns out to be
around 5000 km s-1, which means a distance
100/h50 Mpc.
As the completeness of the sample and the behaviour of the
accuracy at faint magnitudes needs
further study, we leave open the interpretation of this feature (perhaps
we are encountering a wall structure
in the hypergalactic plane; Di Nella & Paturel 1994).
If one calculates the regression line up to 16 mag, one obtains a slope of about 0.5 (e.g. Gabrielli et al. 2004; Courtois et al. 2004). The present exercise suggests that at brighter magnitudes the slope is shallower. In particular, there is no evidence for the slope 0.6 in that magnitude range where the old counts by Hubble (1926) and Shapley & Ames (1932) were once regarded as showing an almost uniform distribution.
Acknowledgements
I would like to thank Yu. Baryshev, A. Butkevich, H. Courtois, G. Paturel and F. Sylos Labini for inspiring discussions and comments on the manuscript. This study has been supported by the Academy of Finland (project "Fundamental questions of observational cosmology''). We have made use of the Lyon-Meudon Extragalactic Database (LEDA) supplied by the LEDA team at the CRAL-Observatoire de Lyon (France).
It is useful to see how the Eddington bias works with
the classical Malmquist bias (or the Malmquist bias of
the first kind, as termed in Teerikorpi 1997).
In the former case one looks at galaxies through the "magnitude window''
![]() and counts their number. The magnitudes defining
the window have Gaussian errors. However, in the latter case one may regard
the measured magnitudes as without errors, but the galaxies in space
have a Gaussian luminosity function with dispersion
and counts their number. The magnitudes defining
the window have Gaussian errors. However, in the latter case one may regard
the measured magnitudes as without errors, but the galaxies in space
have a Gaussian luminosity function with dispersion ![]() .
Here one
does not primarily count the galaxies, but considers their average absolute
magnitude as seen through the magnitude window. The Malmquist bias
depends on the derivative
.
Here one
does not primarily count the galaxies, but considers their average absolute
magnitude as seen through the magnitude window. The Malmquist bias
depends on the derivative
![]() :
:
A question arises when there are measurement
errors in m. How do these errors affect the initial Malmquist bias?
In the general case when the derivative
![]() is not constant,
the Eddington bias changes it, which causes error in
is not constant,
the Eddington bias changes it, which causes error in
![]() if one uses the observed (measured) distribution of m in Eq. (A.1). In principle one should first restore the original
distribution observed "from the sky'' (by making an Eddington
correction) and only then use the
Malmquist formula. In practice, this may be difficult.
if one uses the observed (measured) distribution of m in Eq. (A.1). In principle one should first restore the original
distribution observed "from the sky'' (by making an Eddington
correction) and only then use the
Malmquist formula. In practice, this may be difficult.
Fortunately, an
exponential distribution of m makes things again much easier. In that case
the derivative in Eq. (A.1) will be constant and at all m the absolute
magnitudes are similarly distributed. As random errors at a true m scatter the galaxies independently of their absolute magnitudes,
the reorganized
![]() distribution
has the same distribution of absolute magnitudes at each
distribution
has the same distribution of absolute magnitudes at each
![]() as
the original one. Thus in this important special case the Eddington bias
does not distort the Malmquist bias.
as
the original one. Thus in this important special case the Eddington bias
does not distort the Malmquist bias.
When one uses the Malmquist bias formula in distance determination,
one calculates the distance modulus
![]() ,
having in mind the correct
values of both m and
,
having in mind the correct
values of both m and
![]() .
As was mentioned in Sect. 4.2, the objects
found at m actually have their true average m fainter, just by the
Malmquist shift. Hence, instead of the apparent distance modulus m-M0,
the Eddington and Malmquist corrected modulus is:
.
As was mentioned in Sect. 4.2, the objects
found at m actually have their true average m fainter, just by the
Malmquist shift. Hence, instead of the apparent distance modulus m-M0,
the Eddington and Malmquist corrected modulus is:
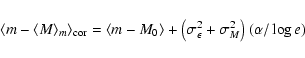 |
(A.2) |
As the difference between the Eddington and Malmquist shifts may still appear
paradoxical, we show here, going backwards, that the individual Gaussians
![]() around
around
![]() (the Malmquist shift) sum up
to the correct total N(m) at the errorless magnitude m (as
predicted by the Eddington shift), when
(the Malmquist shift) sum up
to the correct total N(m) at the errorless magnitude m (as
predicted by the Eddington shift), when
![]() is taken from
is taken from ![]() to
to ![]() and the Gaussians are weighted by the exponential
counts
and the Gaussians are weighted by the exponential
counts
![]() :
:
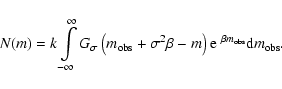 |
(B.1) |
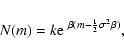 |
(B.2) |
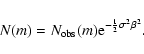 |
(B.3) |