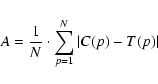A network consists of an input layer, one or two hidden layers and an output
layer. Each layer is made up of several nodes. All the nodes in one layer are
connected to all the nodes in the preceding and/or following layers. These
connections have adaptable "weights", so that each node performs a weighted sum
of all its inputs and passes this sum through a nonlinear transfer function.
That weighted sum is then passed on to the next layer. Before the network can be
used for parametrisation, it needs to be trained, meaning the weights have to be set to
their appropriate values to perform the desired mapping. In this process,
DISPIs together with known stellar parameters as target values are presented
to the network. From these data, the optimum weights are determined by
iteratively adjusting the weights between the layers to minimize an output
error, i.e. the discrepancy between the targets and the network outputs. This
is performed by a multidimensional numerical minimization, in this case with
the conjugate gradients method. When this minimization converges, the weights
are fixed and the network can be used in its "application" phase: now, only the
DISPI input flux vector is presented and the network's outputs produce the
stellar parameters of these DISPIs. Since we used only the central 51 effective pixels of the DISPIs (range 30 to 80, see Figs. 3 and 4), the input layer of
the network was always made up of the same number of nodes, i.e. 51. We found that the
performance was best when using two hidden layers, each containing 7 nodes.
More nodes did not improve the result significantly but increased the training
time considerably. With four output parameters this network then contains
![]() weights (plus 18 bias weights).
weights (plus 18 bias weights).
Since we wanted to classify DISPIs solely based on their shapes, the absolute flux
information was removed by area-normalizing each DISPI, i.e. each flux bin
of a given DISPI was divided by the total number of counts in that DISPI.
Given the non-uniform distribution of the training data over
![]() ,
we classified DISPIs in terms of
log
,
we classified DISPIs in terms of
log
![]() instead of
instead of
![]() .
.
Note that, in our tests, we have not included distance information as it eventually might be done using DIVA parallaxes, since the present goal was to test the retrieval of stellar parameters from DISPIs only.
The parametrization errors given below are the average (over some set of DISPIs) errors for each parameter, i.e.
Copyright ESO 2003