We present a new determination of the time delay of the gravitational lens system HE 1104-1805 ("Double Hamburger'') based on a previously unpublished dataset. We argue that the previously published value of
A&A 381, 428-439 (2002)
DOI: 10.1051/0004-6361:20011523
R. Gil-Merino - L. Wisotzki - J. Wambsganss
Universität Potsdam, Am Neuen Palais 10, 14469 Potsdam, Germany
Received 27 July 2001 / Accepted 25 October 2001
Abstract
We present a new determination of the time
delay of the gravitational lens system HE 1104-1805 ("Double Hamburger'')
based on a previously unpublished dataset. We argue that
the previously published value of
![]() years was affected by a
bias of the employed method. We determine a new value of
years was affected by a
bias of the employed method. We determine a new value of
![]() years
(2
years
(2![]() confidence level), using six different techniques
based on non interpolation methods in the time domain. The result demonstrates
that even in the case of poorly sampled lightcurves, useful information can be
obtained with regard to the time delay. The error estimates were calculated
through Monte Carlo simulations.
With two already existing models for the lens and using its recently determined
redshift, we infer a range of values of the Hubble parameter:
confidence level), using six different techniques
based on non interpolation methods in the time domain. The result demonstrates
that even in the case of poorly sampled lightcurves, useful information can be
obtained with regard to the time delay. The error estimates were calculated
through Monte Carlo simulations.
With two already existing models for the lens and using its recently determined
redshift, we infer a range of values of the Hubble parameter:
![]() (2
(2![]() )
for a singular isothermal ellipsoid (SIE) and
)
for a singular isothermal ellipsoid (SIE) and
![]() (2
(2![]() )
for a constant mass-to-light ratio plus shear model (
)
for a constant mass-to-light ratio plus shear model (
![]() ).
The possibly much larger errors due to systematic uncertainties in
modeling the lens potential are not included in this error estimate.
).
The possibly much larger errors due to systematic uncertainties in
modeling the lens potential are not included in this error estimate.
Key words: gravitational lensing - time delays - quasars: HE 1104-1805 - general: data analysis
The double quasar HE 1104-1805 at a redshift of
![]() was
originally discovered by Wisotzki et al. (1993). The two images
with (original) B magnitudes of 16.70 and 18.64 are separated by
was
originally discovered by Wisotzki et al. (1993). The two images
with (original) B magnitudes of 16.70 and 18.64 are separated by
![]() (Kochanek et al. 1998).
The spectral line ratios and profiles turned out to be almost identical
between the two images, but image A has a distinctly harder continuum.
Wisotzki et al. (1995) report about a dimming of both components over
about 20 months, accompanied by a softening of the
continuum slope of both images.
The lensing galaxy was discovered by Courbin et al. (1998) in the NIR
and by Remy et al. (1998) with HST. The authors tentatively identified
the lensing galaxy with a previously detected damped Lyman alpha system
at z=1.66 (Wisotzki et al. 1993;
Smette et al. 1995; Lopez et al. 1999). This identification, however,
was disputed by Wisotzki et al. (1998).
Using FORS2 at the VLT, Lidman et al. (2000) finally
determined the redshift of the lensing galaxy to
(Kochanek et al. 1998).
The spectral line ratios and profiles turned out to be almost identical
between the two images, but image A has a distinctly harder continuum.
Wisotzki et al. (1995) report about a dimming of both components over
about 20 months, accompanied by a softening of the
continuum slope of both images.
The lensing galaxy was discovered by Courbin et al. (1998) in the NIR
and by Remy et al. (1998) with HST. The authors tentatively identified
the lensing galaxy with a previously detected damped Lyman alpha system
at z=1.66 (Wisotzki et al. 1993;
Smette et al. 1995; Lopez et al. 1999). This identification, however,
was disputed by Wisotzki et al. (1998).
Using FORS2 at the VLT, Lidman et al. (2000) finally
determined the redshift of the lensing galaxy to
![]() .
.
A first determination of the time delay in this system
was published by Wisotzki et al. (1998), based on five years of
spectrophotometric monitoring of HE 1104-1805, in which the
quasar images varied significantly, while the
emission line fluxes appear to have remained constant.
The Wisotzki et al. (1998) value for the time delay was
![]() years (no formal error
bars were reported), but they cautioned that a value as small as 0.3 years
could not be excluded.
years (no formal error
bars were reported), but they cautioned that a value as small as 0.3 years
could not be excluded.
HE 1104-1805 shows strong and clear indications of gravitational microlensing, in particular based on the continuum variability with the line fluxes almost unaffected (Wisotzki et al. 1993; Courbin et al. 2000).
Here we present an analysis of previously unpublished photometric monitoring data of HE 1104-1805. First the data and light curves are presented (Sect. 2), then a number of numerically techniques are described and discussed and, as the scope of this paper is a comparison of different techniques in the case of poorly sampled data, we finally applied to this data set, in order to determine the time delay (Sect. 3). A discussion of the results and the implications for the value of the Hubble constant based on this new value of the time delay and on previously avalaible lens models are given in Sect. 4. In Sect. 5 we present our conclusions.
Between 1993 and 1998, we obtained a B band lightcurve of HE 1104-1805
at 19 independent epochs, mostly in the course of a monitoring
campaign conducted at the ESO 3.6 m telescope in service
mode. The main intention of the programme was to follow the spectral
variations by means of relative spectrophotometry, but at each
occasion also at least one frame in the B band was taken.
A continuum lightcurve, derived from the spectrophotometry,
and a first estimate of the time delay were presented by Wisotzki et al. (1998,
hereafter W98);
details of the monitoring will be given in a forthcoming paper
(Wisotzki & López, in preparation). Here we concentrate on the broad band
photometric data which have not been published to date.
Images were taken typically once a month during the visibility period.
The instrument used was EFOSC1 with 512![]() 512 pixels Tektronix
CCD until June 1997, and EFOSC2 with a 2K
512 pixels Tektronix
CCD until June 1997, and EFOSC2 with a 2K![]() 2K Loral/Lesser
chip afterwards. The B band frames (which were also used as
acquisition images for the spectroscopy) were always exposed for
30 s, which ensured that also the main comparison stars were
unsaturated at the best recorded seeing of
2K Loral/Lesser
chip afterwards. The B band frames (which were also used as
acquisition images for the spectroscopy) were always exposed for
30 s, which ensured that also the main comparison stars were
unsaturated at the best recorded seeing of
![]() .
Sometimes
more than one exposure was made, enabling us to make independent
estimates of the photometric uncertainties. A journal of the
observations is presented together with the measured lightcurve
in Table 1.
.
Sometimes
more than one exposure was made, enabling us to make independent
estimates of the photometric uncertainties. A journal of the
observations is presented together with the measured lightcurve
in Table 1.
| Epoch [yrs] |
|
|
|
|
| 1993.19 | 0.000 | 0.009 | 1.920 | 0.022 |
| 1994.82 | 0.397 | 0.009 | 2.282 | 0.019 |
| 1995.16 | 0.529 | 0.008 | 2.236 | 0.028 |
| 1995.96 | 0.399 | 0.012 | 2.140 | 0.014 |
| 1996.11 | 0.436 | 0.008 | 2.207 | 0.017 |
| 1996.23 | 0.454 | 0.005 | 2.176 | 0.013 |
| 1996.30 | 0.486 | 0.009 | 2.171 | 0.023 |
| 1996.45 | 0.500 | 0.008 | 2.115 | 0.019 |
| 1996.88 | 0.383 | 0.007 | 2.074 | 0.012 |
| 1997.04 | 0.389 | 0.007 | 2.054 | 0.016 |
| 1997.12 | 0.533 | 0.009 | 2.031 | 0.013 |
| 1997.21 | 0.428 | 0.016 | 2.007 | 0.015 |
| 1997.27 | 0.392 | 0.007 | 2.055 | 0.012 |
| 1997.33 | 0.403 | 0.008 | 2.089 | 0.014 |
| 1998.00 | 0.252 | 0.017 | 2.029 | 0.018 |
| 1998.08 | 0.279 | 0.004 | 2.006 | 0.011 |
| 1998.16 | 0.292 | 0.004 | 2.004 | 0.011 |
| 1998.33 | 0.531 | 0.006 | 2.100 | 0.011 |
| 1998.40 | 0.441 | 0.007 | 2.054 | 0.030 |
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F1.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img28.gif) |
Figure 1: The new photometric dataset running from 1993 to 1998. The zero point for the relative photometry of HE 1104-1805 is the first data point of component A (see Table 1 for error estimates). |
| Open with DEXTER | |
A first estimation for the time delay in this system resulted in a value of
![]() years (W98), using the dispersion spectra method
developed by Pelt et al. (1994, 1996; hereafter P94 and P96, respectly). Note
that we will express the time delay as
years (W98), using the dispersion spectra method
developed by Pelt et al. (1994, 1996; hereafter P94 and P96, respectly). Note
that we will express the time delay as
![]() (instead of
(instead of
![]() ), since B leads the variability
(see Fig. 1), and thus there appears a minus sign in the result.
We shall demonstrate below that the dispersion spectra method is not bias-free.
To facility a better understanding of this claim, we first briefly describe the
method in the following: the two time series Ai and Bj can
be expressed, using the P96 notation, as
), since B leads the variability
(see Fig. 1), and thus there appears a minus sign in the result.
We shall demonstrate below that the dispersion spectra method is not bias-free.
To facility a better understanding of this claim, we first briefly describe the
method in the following: the two time series Ai and Bj can
be expressed, using the P96 notation, as
| (1) | |||
| (2) |
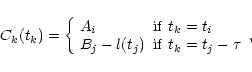 |
(3) |
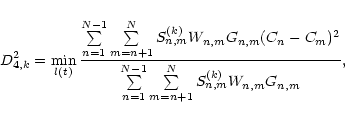 |
(4) |
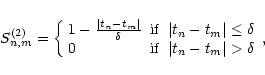 |
(5) |
The new dataset used here has the same sampling as the one used for the
first estimation of the time delay in W98. As the errorbars for individual points
are also very similar, one should expect to obtain a similar time delay. And in
fact this is exactly what happens when applying the dispersion spectra method as
described above.
The original dataset is plotted in Fig. 1. There are 19 observational
points for each component. We apply the dispersion spectra method (P94, P96): the
result is
![]() years, i.e., the same value as the first published
estimation.
years, i.e., the same value as the first published
estimation.
Since W98 did not provide a formal error estimate, we now investigate the goodness of this value and try to estimate the uncertainty, and we also want to check the self-consistency of the method in this case. For this purpose we do a test based on an iterative procedure: after having applied the dispersion spectra method to the whole data set, we make a selection of the data trying to avoid big gaps between the epochs and considering points in both lightcurves that fall in the same time interval once one has corrected the time shift with the derived time delay. This will avoid the so-called border effects, and a time delay close to the initial one should result when the dispersion spectra are recalculated for the selected data. We do this in the next subsection.
We first consider
![]() years as a
first rough estimate of the time delay, in agreement with W98.
It is obvious that using this time delay, the first
point of the whole dataset (epoch 1993.19) of component B has no
close partner in component A. Eliminating this point means avoiding
the big gap of almost two years at the beginning of the lightcurves. Once
this is done, the last five points of the lightcurve B and the first two ones of A
(after eliminating the epoch 1993.19) are not useful anymore for a time delay
determination since they do not cover the same intrinsic time interval.
We also eliminate these points. Now we
have a "clean'' dataset with 16 points from component A and 13 points from component B. The situation is illustrated in Fig. 2,
years as a
first rough estimate of the time delay, in agreement with W98.
It is obvious that using this time delay, the first
point of the whole dataset (epoch 1993.19) of component B has no
close partner in component A. Eliminating this point means avoiding
the big gap of almost two years at the beginning of the lightcurves. Once
this is done, the last five points of the lightcurve B and the first two ones of A
(after eliminating the epoch 1993.19) are not useful anymore for a time delay
determination since they do not cover the same intrinsic time interval.
We also eliminate these points. Now we
have a "clean'' dataset with 16 points from component A and 13 points from component B. The situation is illustrated in Fig. 2,
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F2.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img40.gif) |
Figure 2:
The first point of the whole dataset has been removed and then
the points that do not fall in the same time interval once we have shifted
the A lightcurve with the value of the first time delay estimation,
|
| Open with DEXTER | |
Now we again apply the dispersion spectra method to the "clean'' data set, i.e. a second
iteration is made. The
result is surprising:
![]() years. The technique should
converge to a value near to that of the first result, if the previous estimation was correct and
the technique is self-consistent. For consistency, we repeat this
analysis assuming a time delay of -0.38 years, i.e., a third iteration.
The result is again unexpected: we recover the previous
value of -0.73 years. These results can be seen in Fig. 3,
years. The technique should
converge to a value near to that of the first result, if the previous estimation was correct and
the technique is self-consistent. For consistency, we repeat this
analysis assuming a time delay of -0.38 years, i.e., a third iteration.
The result is again unexpected: we recover the previous
value of -0.73 years. These results can be seen in Fig. 3,
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F3_upper.ps...
...m]
\includegraphics[angle=-90,width=8.8cm,clip]{H3051F3_bottom.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img42.gif) |
Figure 3:
Dispersion spectra: the upper panel shows the result when
all the points are taken into account. In the middle panel, the
result after correcting borders with the first estimation of the time delay,
i.e.
|
| Open with DEXTER | |
This clearly means that the method is not self-consistent when applying it to the current data set. The dispersion spectra method is very sensitive to individual points, and in poorly sampled sets such as this one, these points are critical. It is obvious that we need better techniques for the determination of the time delay. But these techniques must not be interpolating ones because the lightcurves have lots of variability and wide gaps, and any simple interpolation scheme might introduce spurious signals.
Many authors have applied different versions of the DCF since it was introduced by Edelson & Krolik (1988, hereafter EK88). Here we have selected five of them. These techniques take into account the global behavior of the curves, rather than "critical points''. But in order to well apply all these methods one has to eliminate border effects and gaps as described previously. If one does not do this, one will lose signal in the peak of the DCF and secondary peaks could appear, which can bias the final result. We will demonstrate this last point later (Fig. 7, described in Sect. 3.3.4, is used for this purpose).
First we apply the usual form of the DCF to the data set. We briefly recall
the expression, following EK88:
A modification of this method was suggested by Lehár et al. (1992).
A parabolic fit to the peak of the function was proposed to solve the
problem of not resolving the peak. Doing this fit, we obtain a time
delay of
![]() years. These results are shown in Fig. 4.
years. These results are shown in Fig. 4.
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F4.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img50.gif) |
Figure 4: The standard DCF and an added fit are shown in this figure. The peak is located at -0.89 years (-0.91 without fit) using a bin semisize 0.07 years. The continuous lines are the noise levels and the zero level is also plotted. Only two points defining the peak are outside the noise band. |
| Open with DEXTER | |
The locally normalized discrete correlation function was also proposed by Lehár
et al. (1992). Its main difference to the simple DCF is that it computes the means and
variances locally (i.e. in each bin):
![\begin{figure}
\par\includegraphics[angle=-90,width=8.6cm,clip]{H3051F5.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img57.gif) |
Figure 5:
The LNDCF is evaluated with a 0.07 years bin
semisize and the peak is fitted with a parabolic law. The result is a time delay
|
| Open with DEXTER | |
In any case, the poorly defined peak means the technique is again quite sensitive to our poor sampling. We look for a method less sensitive to this problem. The two following techniques are two different ways of trying to solve the problem of not having many points around the prominent peak.
The continuously evaluated bins discrete correlation function was introduced by Goicoechea et al. (1998a). The difference to the standard way of computing the DCF in this method is that the bins are non disjoint (i.e. each bin ovelaps with other adjacent bins, see Sect. 3.3.2 where the bins do not overlap each other). One has to fix the distance between the centers of the bins in addition to their width. In this way it is possible to evaluate the DCF in more points, having a more continuously distributed curve. We will have also more significant points around the peak, i.e. above the noise level, and there is no need for fitting.
Selecting the distance between the centers of the bins is again a matter of
compromise: increasing the distance means needing wider bins and, thus, losing
resolution. The adopted time resolution should depend on the sampling; it seems
reasonable to select a value slightly less then the inverse of the highest frequency
of sampling (
![]() years). We choose 0.05 years as the best value for the
distance between bin centers and two values for bin semisizes:
years). We choose 0.05 years as the best value for the
distance between bin centers and two values for bin semisizes:
![]() and
and
![]() years. The overlapping between bins allows us to consider slightly wider bin sizes.
We plot the results in Fig. 6,
years. The overlapping between bins allows us to consider slightly wider bin sizes.
We plot the results in Fig. 6,
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F6_top.ps}\...
...m]
\includegraphics[angle=-90,width=8.8cm,clip]{H3051F6_bottom.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img59.gif) |
Figure 6:
The CEDCF is a DCF more continuously evaluated. Top panel:
using a bin semize of
|
| Open with DEXTER | |
Now we need a good reason for preferring one over the other bin size. This
reason could be the signal-to-noise ratio of the peak: in the first case
![]() years, S/N = 3.9, and in the second
years, S/N = 3.9, and in the second
![]() yrs, S/N=3.8.
Clearly, the difference of these two values is not high enough to conclude that one
of them is the best.
yrs, S/N=3.8.
Clearly, the difference of these two values is not high enough to conclude that one
of them is the best.
In spite of the insignificant difference in this case, we notice that the
signal-to-noise ratio is an important aspect and it
is here where we justify the need for using "clean'' data sets, i.e.
border effects and gaps corrected. In Fig. 7 we plot the CEDCF
for the original dataset (without any correction):
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F7.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img60.gif) |
Figure 7: Not eliminating borders can be crucial in DCF-based methods. Here the CEDCF has been computed with the original data set, i.e. using all points. There is a peak at -0.90 years, with a signal-to-noise value of 1.95. Other points around a secondary peak located at time zero describe another feature. The great amount of information lost in the main peak is obvious. |
| Open with DEXTER | |
To our knowledge, this technique has not been applied before, but it seems a natural step as a combination of the two former techniques (i.e., the LNDCF and the CEDCF). From the one side, we use Eq. (7) for computing the DCF, i.e., it is a locally normalized discrete correlation function. From the other side, we use the idea of overlapping bins described in Sect. 3.3.4. Thus, the final result is a "continuously evaluated bins and locally normalized discrete correlation function'' (CELNDCF). Again, we fix the distances between the bins and also their width. The result will be a function similar in shape to the LNDCF in Fig. 5 but with more points evaluated.
The method was applied for three different values of the bin semisize: 0.07,
0.14 and 0.21 years. The first value is not a good choice, it gives
relatively large errorbars for the points of the CELNDCF, since the number of
points per bin is low.
Selecting the last two values, i.e.
![]() yrs and
yrs and
![]() yrs,
we obtain Fig. 8.
yrs,
we obtain Fig. 8.
![\begin{figure}
\par\includegraphics[angle=-90,width=8.6cm,clip]{H3051F8_top.ps} \includegraphics[angle=-90,width=8.6cm,clip]{H3051F8_bottom.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img61.gif) |
Figure 8:
Top panel: the CELNDCF is evaluated with
|
| Open with DEXTER | |
The following method, called ![]() ,
was introduced by Goicoechea et al. (1998b)
and Serra-Ricart et al. (1999). Its expression is
,
was introduced by Goicoechea et al. (1998b)
and Serra-Ricart et al. (1999). Its expression is
![\begin{displaymath}\delta^2(\theta)=\frac{1}{N}\sum^N_{i=1}S_i[DCC(\tau_i)-DAC(\tau_i-\theta)]^2
\end{displaymath}](/articles/aa/full/2002/02/aah3051/img63.gif) |
(8) |
We have selected component B for computing the DAC, because component A has more
variability (presumably due to microlensing). We compute ![]() for
different values of the bin
semisize. Adopting a bin semisize
for
different values of the bin
semisize. Adopting a bin semisize
![]() ,
the function shows some
features and reaches its minimum at -0.85 years (see Fig. 9,
solid line).
,
the function shows some
features and reaches its minimum at -0.85 years (see Fig. 9,
solid line).
![\begin{figure}
\par\includegraphics[width=8.6cm,clip]{H3051F9.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img68.gif) |
Figure 9:
The |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F10_upper.p...
...]
\includegraphics[angle=-90,width=8.8cm,clip]{H3051F10_bottom.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img72.gif) |
Figure 10:
Upper panel: both DCC (filled circles) and DAC (open circles)
are plotted. The bin semisize is
|
| Open with DEXTER | |
In order to better study the features in the ![]() function, we plot it
normalized to its minimum in Fig. 11.
function, we plot it
normalized to its minimum in Fig. 11.
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F11.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img73.gif) |
Figure 11:
The minimum of the |
| Open with DEXTER | |
To obtain an estimate for the formal error of this method, we used 1000
Monte Carlo simulations. For each simulation we did the following: for each
epoch ti we associated a value in magnitudes
![]() ,
where
xi is the observed value and
,
where
xi is the observed value and
![]() is a Gaussian random variable with
zero mean and variance equal to the estimated measurement error. The histogram
is presented in Fig. 12.
is a Gaussian random variable with
zero mean and variance equal to the estimated measurement error. The histogram
is presented in Fig. 12.
![\begin{figure}
\par\includegraphics[angle=-90,width=8.8cm,clip]{H3051F12.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img76.gif) |
Figure 12:
Histogram of time delays obtained in 1000 Monte Carlo simulations,
using the |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F13.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img78.gif) |
Figure 13:
The original dataset with the component A shifted by the new
adopted time delay,
|
| Open with DEXTER | |
From the tour through the different techniques we can learn several
useful things. First of all, when only one technique is selected for
deriving a time delay between two signals, it is important to check the internal
consistency of the method and its behaviour with a given data set. We have
demonstrated in Sect. 3.2 that dispersion spectra does not pass
this test at least in this case (see Fig. 3). We have then applied and
discussed the
discrete correlation function and several of its modifications.
The standard DCF (Fig. 4)
had problems to properly define the peak in the case of very poorly sampled lightcurves;
although a fit was proposed to solve this problem, there were only two points
above the noise level in the best case and the fit was not very plausible. The
LNDCF (Fig. 5), based on locally normalized bins,
had a similar behaviour and although the error bars of each point are smaller,
the peak is not well defined either. The CEDCF (Fig. 6) and the
CELNDCF (Fig. 8) worked better under these circunstances, but we found
the problem of selecting the bin size; in the case of the CEDCF the difference
between the two selected bin sizes was smaller than in the case of the CELNDCF.
Finally applying the ![]() technique, we found a good reason for selecting
one bin size:
the match between the DAC and the DCC. The resulting estimate and its
uncertainty include, as a "byproduct'', the
results of the rest of the techniques for the same bin size (except the dispersion
spectra method which was not self-consistent). This fact is not the same as computing
all the techniques and doing some statistics to obtain an uncertainty. This
frequently appears in the time delay determination literature, although it is
not at all clear which was the weight of each technique when computing the
final result. We note that for consistency we should apply a correction to the
original data set with the final adopted time delay of -0.85 years. Due to the
(very) sparse sampling of our data set, this
correction gives a reduced data set identical to the previous "clean'' data set
obtained with a correction of -0.73 years, so we do not need to repeat the
whole process. The procedure is self-consistent.
technique, we found a good reason for selecting
one bin size:
the match between the DAC and the DCC. The resulting estimate and its
uncertainty include, as a "byproduct'', the
results of the rest of the techniques for the same bin size (except the dispersion
spectra method which was not self-consistent). This fact is not the same as computing
all the techniques and doing some statistics to obtain an uncertainty. This
frequently appears in the time delay determination literature, although it is
not at all clear which was the weight of each technique when computing the
final result. We note that for consistency we should apply a correction to the
original data set with the final adopted time delay of -0.85 years. Due to the
(very) sparse sampling of our data set, this
correction gives a reduced data set identical to the previous "clean'' data set
obtained with a correction of -0.73 years, so we do not need to repeat the
whole process. The procedure is self-consistent.
It is important to notice that we have not meant to establish any general hierarchy between all these techniques. The hierarchy is valid in our particular case study. Nevertheless, the idea, not new, of correcting border effects in the signals with first estimations has been proved to be a good procedure in DCF based techniques.
In some of the techniques we have discussed and applied
here for the data of HE 1104-1805, there appear
secondary peaks/dips located at different values for the
time lags (see Figs. 5, 8 and 11).
Here we investigate two obvious effects that might
cause such behaviour, namely microlensing and sampling.
We do this only as a case study for the
![]() technique, but assume that our conclusions can
be generalized to the other methods as well.
technique, but assume that our conclusions can
be generalized to the other methods as well.
Microlensing affects the two quasar lightcurves differently. That means that the two lightcurves will not be identical copies of each other (modulo offsets in magnitude and time), but there can be minor or major deviations between them. On the other hand, experience from other multiple quasar systems tells us that microlensing cannot dominate the variability, because otherwise there would be no way to determine a time delay at all. In any case, microlensing is a possible source of "noise'' with respect to the determination of the time delay.
A complete analysis of microlensing on this system is beyond the scope
of this article, and will be addressed in a forthcoming paper.
Here we present a simple, but illustrative,
approach to the way microlensing can effect the determination
of the time delay, and in particular its effect on the ![]() technique.
An "extreme'' view of microlensing was investigated by
Falco et al. (1991), who showed for the Q0957+561 system that it is
very unlikely that
microlensing can mimic "parallel'' intrinsic fluctuations
causing completely wrong values for the time delay
correlations.
But strong microlensing clearly affects
the features of the cross-correlation function
(Goicoechea et al. 1998a). Depending on the
exact amplitude and shape of the microlensing
event, the main and secondary peaks of this
function can be distorted,
possibly inducing wrong interpretations.
technique.
An "extreme'' view of microlensing was investigated by
Falco et al. (1991), who showed for the Q0957+561 system that it is
very unlikely that
microlensing can mimic "parallel'' intrinsic fluctuations
causing completely wrong values for the time delay
correlations.
But strong microlensing clearly affects
the features of the cross-correlation function
(Goicoechea et al. 1998a). Depending on the
exact amplitude and shape of the microlensing
event, the main and secondary peaks of this
function can be distorted,
possibly inducing wrong interpretations.
In order to study this effect here, we do the following:
we consider the lightcurve of component B
(assumed to reflect only intrinsic quasar variability)
and a copy of it, shifted by 0.85 years, which we shall call B'.
Obviously, any technique will give a time delay value
of
![]() years between B and B'.
In the case of the
years between B and B'.
In the case of the ![]() technique, a very sharp minimum is located
at this lag.
Now we introduce artificial "microlensing'' as a kind of
Gaussian random process with zero mean and a certain standard deviation
technique, a very sharp minimum is located
at this lag.
Now we introduce artificial "microlensing'' as a kind of
Gaussian random process with zero mean and a certain standard deviation
![]() to the lightcurve B'.
We consider three cases:
to the lightcurve B'.
We consider three cases:
![]() mag, 0.075 mag and 0.100 mag.
Although microlensing is in general obviously not a random process (it depends
a bit on the sampling),
we use this simple approximation in order to study whether and
how secondary peaks can appear in time delay determinations.
The resulting
mag, 0.075 mag and 0.100 mag.
Although microlensing is in general obviously not a random process (it depends
a bit on the sampling),
we use this simple approximation in order to study whether and
how secondary peaks can appear in time delay determinations.
The resulting ![]() -functions can be seen in
Fig. 14,
-functions can be seen in
Fig. 14,
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F14.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img82.gif) |
Figure 14:
We calculate the time delay between the lightcurves B and B' with
the |
| Open with DEXTER | |
To make sure that this is not a chance observational
effect of this particular selected lag, we repeat this exercise
for an assumed shift of -0.5 years between the observed lightcurve
and its shifted copy, plus added "artificial microlensing''
with
![]() mag. Again, the correct value
is clearly recovered in all realisations. This is particularly
convincing because a lag of 0.5 years is the "worst case scenario''
with minimal overlap between the two lightcurves.
To summarize, moderate microlensing can be a cause of distortions
of the time delay determination function, but it is unlikely that
microlensing dominates it completely.
mag. Again, the correct value
is clearly recovered in all realisations. This is particularly
convincing because a lag of 0.5 years is the "worst case scenario''
with minimal overlap between the two lightcurves.
To summarize, moderate microlensing can be a cause of distortions
of the time delay determination function, but it is unlikely that
microlensing dominates it completely.
In order to study the effect of sampling on the shape of the
![]() function, we proceed as follows:
again, we consider the lightcurve of component B and an identical
copy of it shifted by 0.85 years, lightcurve B'.
Now we remove some points from lightcurve B'.
Resulting
function, we proceed as follows:
again, we consider the lightcurve of component B and an identical
copy of it shifted by 0.85 years, lightcurve B'.
Now we remove some points from lightcurve B'.
Resulting ![]() functions are shown
in Fig. 15 for three cases.
functions are shown
in Fig. 15 for three cases.
![\begin{figure}
\par\includegraphics[width=8.8cm,clip]{H3051F15.ps} \end{figure}](/articles/aa/full/2002/02/aah3051/img85.gif) |
Figure 15:
We analyse the sampling effect in the |
| Open with DEXTER | |
As above, we also want to check whether the particular
value of the time lag plays an important role, and we again
repeat the simulation exercise with an assumed lag of -0.5 years,
and 4 randomly selected points removed. The result is again
![]() years, recovering the assumed lag
in all cases.
years, recovering the assumed lag
in all cases.
Summarizing, we can state that both microlensing and sampling differences
affect the shape of the time delay determination function. However,
moderate microlensing will have only small effects on these curves,
whereas moderate (and unavoidable!) differences in the sampling
for the two lightcurves can easily introduce effects like secondary
minima.
The primary minimum of the ![]() method in all cases considered was
still clearly representing the actual value of the time delay.
Applied to HE 1104-1805, this means that most likely
microlensing does not affect much the time delay determination,
the features in the time delay determination function can
be easily explained by the sampling differences, and
the primary minimum appears to be a good representation of
the real time delay.
method in all cases considered was
still clearly representing the actual value of the time delay.
Applied to HE 1104-1805, this means that most likely
microlensing does not affect much the time delay determination,
the features in the time delay determination function can
be easily explained by the sampling differences, and
the primary minimum appears to be a good representation of
the real time delay.
If one wants to use the time delay to estimate the Hubble parameter H0, one needs to know the geometry and mass distribution of the system. Accurate astrometry is available from HST images presented by Lehár et al. (2000). There are also several models for the lens in the literature. In W98, two models are described: a singular isothermal sphere with external shear and a singular isothermal ellipsoid without external shear. The first model is similar to Remy et al. (1998) and Lehár et al. (2000). Courbin et al. 2000 also present two models: a singular ellipsoid without external shear and a singular isothermal ellipsoid plus an extended component representing a galaxy cluster centered on the lens galaxy.
The redshift of the lens in this system has been establish by Lidman et al. (2000) to
be
![]() .
Note that HE 1104-1805 is somehow atypical, in the sense that the
brightest component is closer to the lens galaxy. We use the most recents models
by the CASTLES group (Lehár et al. 2000), described by a singular isothermal
ellipsoid (SIE) and a
constant mass-to-light ratio plus shear model (
.
Note that HE 1104-1805 is somehow atypical, in the sense that the
brightest component is closer to the lens galaxy. We use the most recents models
by the CASTLES group (Lehár et al. 2000), described by a singular isothermal
ellipsoid (SIE) and a
constant mass-to-light ratio plus shear model (
![]() ). The derived
value for the Hubble constant using the first model (SIE) is
). The derived
value for the Hubble constant using the first model (SIE) is
![]() with
with ![]() confidence level. A (
confidence level. A (
![]() )
model gives
)
model gives
![]() (
(![]() ),
both for
),
both for
![]() .
The formal uncertainty in these values are very low, due to the low formal
uncertainties both in the time delay estimation and in the models. Nevertheless,
the mass distribution is not well constrained, since a sequence of models can
fit the images positions (Zhao & Pronk 2000). We note that other models
in Lehár et al. (2000) will give very different results for H0, but we did not use
them because no error estimate was reported for them. Moreover, the angular
separation is big enough to expect an additional contribution to
the potential from a group or cluster of galaxies
(Muñoz 2001, priv. comm.).
.
The formal uncertainty in these values are very low, due to the low formal
uncertainties both in the time delay estimation and in the models. Nevertheless,
the mass distribution is not well constrained, since a sequence of models can
fit the images positions (Zhao & Pronk 2000). We note that other models
in Lehár et al. (2000) will give very different results for H0, but we did not use
them because no error estimate was reported for them. Moreover, the angular
separation is big enough to expect an additional contribution to
the potential from a group or cluster of galaxies
(Muñoz 2001, priv. comm.).
We have shown that the existing data allow us to constrain the time delay of
HE 1104-1805 with high confidence between 0.8 and 0.9 years,
slightly higher than the one available previous estimate. We have demonstrated
that the six different techniques employed in this study were not equally suited
for the available dataset. In
fact, this case study has demonstrated that a very careful analysis of each
technique is needed when applying it to a certain set of observations. Such an analysis
becomes even more important in the case of poorly sample lightcurves. In this sense,
the ![]() technique showed the best behaviour against the
poor sampling: unless the lack of information due to sampling is so severe that it
prevents the determination of a well defined DAC and DCC, the minimum of the
technique showed the best behaviour against the
poor sampling: unless the lack of information due to sampling is so severe that it
prevents the determination of a well defined DAC and DCC, the minimum of the ![]() function will be a robust estimator for the time delay.
function will be a robust estimator for the time delay.
Our improved time delay estimate yields a value of the Hubble parameter which now depends mostly on the uncertainties of the mass model. The degeneracies inherent to a simple 2-image lens system such as HE 1104-1805 currently preclude to derive very tight limits on H0. We note, however, that there are prospects to improve the constraints on the model e.g. by using the lensed arclet features visible from the QSO host galaxy. Even now, there seems to be a remarkable trend in favour of a relatively low value of H0, consistent with other recent lensing-based estimates (Schechter 2000).
Acknowledgements
We are especially grateful to Dr. L. J. Goicoechea (Universidad de Cantabria, Spain) for indicating us the best way of applying the
technique and for many comments to a first version of this paper. We also thank Dr. L. Tenorio (MINES, USA) for his useful comments on Monte Carlo and bootstrap simulations and Dr. J. A. Muñoz (IAC, Spain) for enlightening our understanding of lens modeling.
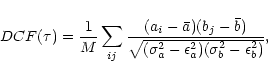
![\begin{displaymath}
LNDCF(\tau)=\frac{1}{M}\sum_{ij}\frac{(a_i-\bar{a}_\ast)(b_j...
..._\ast}-\epsilon^2_a)(\sigma^2_{b_\ast}-\epsilon^2_b)]^{1/2)}},
\end{displaymath}](/articles/aa/full/2002/02/aah3051/img54.gif)