For the often-studied "SMR'' giant
A&A 379, 917-923 (2001)
DOI: 10.1051/0004-6361:20011380
B. J.Taylor
Department of Physics and Astronomy, N283 ESC, Brigham Young University, Provo, UT 84602-4360, USA
Received 9 February 2001 / Accepted 2 October 2001
Abstract
For the often-studied "SMR'' giant ![]() Leo, Smith & Ruck (2000) have
recently found that [Fe/H]
Leo, Smith & Ruck (2000) have
recently found that [Fe/H] ![]() dex. Their conclusion is tested here in
a "statistical'' paradigm, in which statistical principles are used to select
published high-dispersion
dex. Their conclusion is tested here in
a "statistical'' paradigm, in which statistical principles are used to select
published high-dispersion ![]() Leo data and assign error bars to them. When
data from Smith & Ruck and from Takeda et al. (1998) are added to a
data base compiled in 1999, it is found that conclusions from an earlier
analysis (Taylor 1999c) are essentially unchanged: the mean value of
[Fe/H]
Leo data and assign error bars to them. When
data from Smith & Ruck and from Takeda et al. (1998) are added to a
data base compiled in 1999, it is found that conclusions from an earlier
analysis (Taylor 1999c) are essentially unchanged: the mean value of
[Fe/H]
![]() dex, and values
dex, and values ![]() +0.2 dex are not clearly
ruled out at 95% confidence. In addition, the hypothesis that [Fe/H]
+0.2 dex are not clearly
ruled out at 95% confidence. In addition, the hypothesis that [Fe/H] ![]() dex which emerges from the Smith-Ruck analysis is formally rejected at
98% confidence. The "default paradigm'' which is commonly used to assess
dex which emerges from the Smith-Ruck analysis is formally rejected at
98% confidence. The "default paradigm'' which is commonly used to assess
![]() Leo data is also considered. The basic characteristics of that paradigm
continue to be a) unexplained exclusion of statistical analysis, b)
inadequately explained deletions from an [Fe/H] data base containing accordant
data, and c) an undefended convention that
Leo data is also considered. The basic characteristics of that paradigm
continue to be a) unexplained exclusion of statistical analysis, b)
inadequately explained deletions from an [Fe/H] data base containing accordant
data, and c) an undefended convention that ![]() Leo is to have a metallicity
of about +0.3 dex or higher.
As a result, it seems fair to describe the
Smith-Ruck application and other applications of the default paradigm as
invalid methods of inference from the data.
Leo is to have a metallicity
of about +0.3 dex or higher.
As a result, it seems fair to describe the
Smith-Ruck application and other applications of the default paradigm as
invalid methods of inference from the data.
Key words: stars: abundances - stars: individual: ![]() Leo
Leo
Not long ago, Taylor (1999c, hereafter T99) published a statistical
analysis of published high-dispersion metallicities of ![]() Leo. This K giant
plays a key role in the controversy about "super-metal-rich'' stars that was
begun by Spinrad & Taylor (1969). T99 found that [Fe/H]
Leo. This K giant
plays a key role in the controversy about "super-metal-rich'' stars that was
begun by Spinrad & Taylor (1969). T99 found that [Fe/H] ![]()
![]() dex for
dex for ![]() Leo, and that this datum is not known to exceed +0.2
dex at 95% confidence.
Leo, and that this datum is not known to exceed +0.2
dex at 95% confidence.
Since the appearance of T99, Smith & Ruck (2000, hereafter SR) have
published a high-dispersion analysis of ![]() Leo. Their value of [Fe/H] is
Leo. Their value of [Fe/H] is
![]() dex. At first glance, this result may appear to be similar to
that of T99. However, it is in fact based on a fundamentally different
approach to the
dex. At first glance, this result may appear to be similar to
that of T99. However, it is in fact based on a fundamentally different
approach to the ![]() Leo problem.
Leo problem.
This paper has two aims: 1) to update the T99 analysis, and 2) to show that the T99 approach still yields superior results. The revised T99 analysis is described in Sect. 2 of this paper. The alternative non-statistical approach of SR and others and its results are reviewed in Sect. 3. A brief summary concludes the paper in Sect. 4.
The T99 approach to data analysis will be described here as "the statistical paradigm''. This paradigm is based on the following six rules.
These rules have been used to analyze published data for ![]() Leo
and about 1100 other giants. The result is a catalog of mean values of [Fe/H]
which is described by Taylor (1999a). Further information about the
analysis used to produce the catalog is given by Taylor (1998a,
1999b). This catalog participates in the analysis to be described below.
Leo
and about 1100 other giants. The result is a catalog of mean values of [Fe/H]
which is described by Taylor (1999a). Further information about the
analysis used to produce the catalog is given by Taylor (1998a,
1999b). This catalog participates in the analysis to be described below.
The T99 analysis must be expanded to include two data, with one being that of SR and the other being from Takeda et al. (1998). The latter authors also give results for 30 other giants. As a first step in analyzing the Takeda et al. data, the following equations are applied to them:
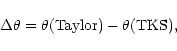 |
(1) |
![\begin{displaymath}\Delta {\rm [Fe/H]} = [{\rm d}{\rm [Fe/H]}/{\rm d}\theta] \times \Delta\theta,
\end{displaymath}](/articles/aa/full/2001/45/aa1136/img11.gif) |
(2) |
and
![\begin{displaymath}{\rm d}{\rm [Fe/H]}/{\rm d}\theta = -8.48 + 5.14\,\mkern2mu {\theta}{\rm (Taylor)}.
\end{displaymath}](/articles/aa/full/2001/45/aa1136/img12.gif) |
(3) |
"TKS'' refers to Takeda et al.,
![]() ,
and
,
and ![]() is effective temperature. Equation (3) is a default relation which
is discussed by Taylor (1998a, Sect. 5.4).
is effective temperature. Equation (3) is a default relation which
is discussed by Taylor (1998a, Sect. 5.4).
The equations are applied only if
![]() .
For smaller values
of
.
For smaller values
of
![]() ,
[Fe/H] corrections are much smaller than the rms errors to
be discussed below. Two required values of
,
[Fe/H] corrections are much smaller than the rms errors to
be discussed below. Two required values of ![]() (Taylor) are derived from
published measurements of V-K (Johnson et al. 1966). The
remaining values of
(Taylor) are derived from
published measurements of V-K (Johnson et al. 1966). The
remaining values of ![]() (Taylor) are from a temperature catalog which
accompanies Taylor's [Fe/H] catalog (see Taylor 1999a).
(Taylor) are from a temperature catalog which
accompanies Taylor's [Fe/H] catalog (see Taylor 1999a).
Taylor (1998a, Table 3) lists a number of other extrinsic corrections that may be considered in the statistical paradigm. None of them appear to be required in this context. As a result, the next step in the analysis is taken by comparing the Takeda et al. values of [Fe/H] to counterparts from the Taylor [Fe/H] catalog. This comparison is performed by using a "comparison algorithm'' derived by Taylor (1991, Appendix B) and described conceptually by Taylor (1999b, Sect. 4.3).
The comparison algorithm yields a statistical correction of the sort referred to in rule (4) (see Sect. 2.1). The equations derived for that correction are as follows:
} = {\rm [Fe/H](TKS)} + Z + S{\theta}{\rm (Taylor)},
\end{displaymath}](/articles/aa/full/2001/45/aa1136/img18.gif) |
(4) |
with
| (5) |
and
| (6) |
A t test shows that ![]() at a confidence level C = 0.995.
It is therefore concluded that a real systematic effect exists in the Takeda et
al. data.
at a confidence level C = 0.995.
It is therefore concluded that a real systematic effect exists in the Takeda et
al. data.
A second result yielded by the comparison algorithm is an rms error for the
Takeda et al. data. The value obtained for
![]() dex.
Equations (4)-(6) may now be applied to the Takeda et al. datum for
dex.
Equations (4)-(6) may now be applied to the Takeda et al. datum for ![]() Leo,
with
Leo,
with ![]() (TKS) being attached to the corrected value. This process
converts the original datum (+0.24 dex) to
(TKS) being attached to the corrected value. This process
converts the original datum (+0.24 dex) to
![\begin{displaymath}{\rm [Fe/H]} = +0.16 \pm 0.061 \mkern6mu {\rm ~dex}.
\end{displaymath}](/articles/aa/full/2001/45/aa1136/img24.gif) |
(7) |
This datum will be used in Sect. 2.4.
When one turns to the SR analysis, two of its features draw immediate
attention. For one thing, SR find that
![]() K for
K for ![]() Leo.
The corresponding datum given in T99 is
Leo.
The corresponding datum given in T99 is
![]() K.
K.
SR assume that the quoted results differ. This inference may be tested by considering data from a set of four papers which will be referred to here as the "SR set.'' In these papers, closely similar analyses of relatively weak lines are described (Drake & Smith 1991; Smith 1998, 1999; SR). Metallicities and temperatures for six giants are considered, with some temperatures being from spectroscopic analysis and others from the infrared flux method.
It will be assumed here that temperatures of these two kinds share a common
zero point. That zero point can be checked because the Taylor temperature
catalog contains entries for the same six giants. The comparison algorithm
described above is applied to the two sets of temperatures. The results are
as follows:
| (8) |
and
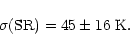 |
(9) |
![]() is the formal correction to the SR temperatures, and it
clearly is not significant at 95% confidence. The derived rms error
is the formal correction to the SR temperatures, and it
clearly is not significant at 95% confidence. The derived rms error
![]() (SR) applies for the data from the SR set.
(SR) applies for the data from the SR set. ![]() (SR) is found to
be consistent with the rms errors of 35-50 K that are quoted in the SR set.
There is therefore no evidence for an inconsistency between the Taylor-catalog
data and those in the SR set.
(SR) is found to
be consistent with the rms errors of 35-50 K that are quoted in the SR set.
There is therefore no evidence for an inconsistency between the Taylor-catalog
data and those in the SR set.
The other issue that draws immediate attention is the zero point of the metallicities in the SR set. SR compare Hyades metallicities from the SR set and from strong-line profiles to a mean Hyades metallicity given by Perryman et al. (1998). The result of that comparison is cited as evidence that their zero point is correct.
A salient feature of this inference is the reliability of the Perryman et al. mean. There are noteworthy problems with that mean which are discussed by Taylor (2000, Appendix B; see especially Table B.1). Those problems may be resolved by using the results of two data reviews: Taylor (1994) has considered Hyades dwarfs, while Taylor (1998b) has considered Hyades giants. An average from those reviews will be adopted below.
Another issue of interest is statistical rigor. If the SR Hyades comparison is done statistically, it does not yield a zero correction with 100% confidence, as SR conclude. Instead, a range of possible corrections is obtained. The extent of that range must be assessed by using rms errors. By analyzing the errors available to SR, one finds that it is unlikely that SR made allowance for them (see Appendix A). This is another reason for a complete reappraisal of the SR zero point.
To begin the reappraisal, three systematic corrections are considered. The
first of them is based on model atmospheres. In the SR set, the
Holweger-Müller (1974) model is adopted for the Sun. In three
papers of the set, MARCS models (Bell et al. 1976) are adopted
for program stars. The fourth paper (Drake & Smith 1991) includes
a MARCS model, an empirical model, and two other models in an analysis of
![]() Gem. Drake & Smith regard the empirical model as the best stellar
counterpart for the Holweger-Müller solar model. If the MARCS model is
used instead, a correction of 0.02 dex should be added to the resulting
value of [Fe/H] (see Sect. 5.1 of Drake & Smith). This correction is applied
here to bring all the data in the SR set to their values for compatible model
atmospheres.
Gem. Drake & Smith regard the empirical model as the best stellar
counterpart for the Holweger-Müller solar model. If the MARCS model is
used instead, a correction of 0.02 dex should be added to the resulting
value of [Fe/H] (see Sect. 5.1 of Drake & Smith). This correction is applied
here to bring all the data in the SR set to their values for compatible model
atmospheres.
To insure that all metallicities are based on completely uniform temperatures,
temperature corrections are applied. To calculate these corrections, Eq. (3)
is modified:
![\begin{displaymath}{\rm d}{\rm [Fe/H]}/{\rm d}\theta = -7.71 + 5.14\theta.
\end{displaymath}](/articles/aa/full/2001/45/aa1136/img31.gif) |
(10) |
With its altered zero point, Eq. (10) adequately reproduces a temperature derivative implied by Table 2 of SR.
A zero-point [Fe/H] adjustment is the third kind of correction to be considered. Here, in contrast to the analysis of the Takeda et al. data, only Z is calculated (recall Eqs. (4)-(6)) because only a few contributing data are available. Moreover, a new problem arises: rms errors are available for Taylor-catalog data (as before), but strict equivalents are not available for data from the SR set. Moreover, the available data are too scant and too noisy to allow those equivalents to be obtained from the comparison algorithm.
In response to this problem, two solutions are performed. For solution 1,
rule (5) is set aside and rms errors quoted in the SR set are adopted. For
solution 2, rule (5) is satisfied by adopting an rms error of 0.106 dex.
This is effectively the error that would have been applied if the SR set
had been available when the Taylor catalogs were compiled![]() .
.
The first steps of the correction process are summarized in Table 1. Note the
differences between the Hyades data in the second and third lines of that
table. For solution 1, the small rms errors of the Hyades data lead to a
large weight for the Hyades contribution to the solution for Z. The
resulting value of Z is statistically significant and will be
applied. By contrast, the error adopted in solution 2 for the SR set
dominates that solution. The resulting value of Z is not significant
at 95% confidence and will not be applied. The two values of Z are
given in Table 2, where the solution for the Takeda et al. results is
included for the sake of completeness.
| Entry |
|
|
|
Assumed |
From Smith | 0.106 |
| (1998, 1999) | ||
| Hyades (Smith 1999) |
|
|
| Hyades (Taylor 1998b) |
|
|
|
|
|
| Number | Zero-point | Scale | |||
| Source | of data |
|
|
|
|
| Takeda et al. (1998) | 30 |
|
|
0.995 |
|
| SR solution 1 e | 4 |
|
- | 0.999 |
|
| SR solution 2 e | 4 |
|
- | - |
|
The updated ![]() Leo data base will now be considered. For complete rules and
procedures for assembling and analyzing the data, the reader is invited to
consult Sects. 5 and 7 of T99. The discussion given here will include
explanatory comments referring back to T99.
Leo data base will now be considered. For complete rules and
procedures for assembling and analyzing the data, the reader is invited to
consult Sects. 5 and 7 of T99. The discussion given here will include
explanatory comments referring back to T99.
The first task at hand is to consider data that are set aside before averaging is performed. As is noted in Sect. 2.1, such editing must be derived from numerical evidence. The reasons for deleting data and the list of deleted data have not changed from T99, so the list is not repeated here. The list and its explanation may be found in Table 2 and Sect. 7.1 of T99.
The second task is to assemble accepted data with well-established zero points.
Those data are listed in Table 3, with asterisks flagging results added in this
paper. Note that all data added - including both the solution 1 and solution 2 SR data - fall well within the range of previous results.
| [Fe/H] | |
| Source b | (dex) |
| Gustafsson et al. (1974) |
|
| Oinas (1974) | |
| (Bonnell & Branch 1979) | |
| McWilliam & Rich (1994) |
|
| Gratton & Sneden (1990) |
|
| Branch et al. (1978) |
|
| Cayrel de Strobel (1991) |
|
| SR (Solution 2) |
|
| Williams (1971) |
|
| McWilliam (1990) |
|
| Peterson (1992) |
|
| Blanc-Vaziaga et al. (1973) |
|
| (Cayrel de Strobel 1991) | |
| SR (Solution 1) |
|
| Brown et al. (1989) |
|
| Takeda et al. (1998) |
|
| Luck & Challener (1995) |
|
| Ries (1981), Lambert & Ries (1981) |
|
| Pagel (Bell 1976) |
The T99 procedure includes tests for excessive scatter and wild points. Details of those tests are not given here because they are unchanged from T99: neither excessive scatter nor wild points are found at 95% confidence. The data may therefore be averaged, using reciprocal squares of their rms errors as weights. Results of six trial averages are given in Table 4, which gives details about the way the averages are constructed.
One intended use of the Table 4 entries is to test the hypothesis that [Fe/H]
< +0.2 dex. As in T99, there is at least one result on each side of this
question, so its status remains unchanged. A second use which seems required
by the SR analysis is to find out whether their conclusion that [Fe/H] ![]() dex is defensible in the statistical paradigm
dex is defensible in the statistical paradigm![]() . Using t tests of the Table 4 entries, this
hypothesis is rejected at 98% confidence.
. Using t tests of the Table 4 entries, this
hypothesis is rejected at 98% confidence.
A third possible use of the Table 4 averages is to decide how well the
metallicity of ![]() Leo is known. With the continuing problem with SMR
status acknowledged, it seems fair to say that the metallicity is now known
well enough for most other purposes. In particular, it would be feasible to
use
Leo is known. With the continuing problem with SMR
status acknowledged, it seems fair to say that the metallicity is now known
well enough for most other purposes. In particular, it would be feasible to
use ![]() Leo as a comparison star when high-dispersion analyses of other K
giants with strong absorption features are performed.
Leo as a comparison star when high-dispersion analyses of other K
giants with strong absorption features are performed.
There is a competitor to the analysis described above which may be described as a "default paradigm'' (Taylor 2001). Without using that name, T99 has described the properties of the default paradigm in some detail (see Sects. 2 and 8 of T99). In addition, it has been discussed in Sects. 6 and 7 of Taylor (2001). For that reason, only a brief review of the state of the paradigm before the appearance of SR will be given here.
The default paradigm is used to interpret values of [Fe/H] without statistical
analysis. The paradigm is concerned only with the numbers which emerge from
high-dispersion analyses, and is not concerned with the nature of the analyses
themselves. The character of the default paradigm is effectively defined by
its uses in the literature. The application of the paradigm to ![]() Leo data
is of particular concern at present, but the paradigm is not inherently
limited to data from any given star or group of stars.
Leo data
is of particular concern at present, but the paradigm is not inherently
limited to data from any given star or group of stars.
The term "default paradigm'' has not been used in papers in which it has been
applied. For this reason, concern has been expressed to the present author
about the fairness of using such a term. Fortunately, the SR methodology
reinforces the argument that the paradigm merits a label because of its
methodological unity. The following points may be noted.
| SR | C96 | Datum from Luck & | Mean value | |
| solution |
|
Challener (1995) | of [Fe/H] (dex) |
|
| 1 | No | Spectroscopic |
|
0.95 |
| 1 | Yes | Spectroscopic |
|
1.38 |
| 1 | Yes | Physical |
|
1.27 |
| 2 | No | Spectroscopic |
|
1.24 |
| 2 | Yes | Spectroscopic |
|
1.71 |
| 2 | Yes | Physical |
|
1.60 |
| Principal | Principal | ||
| School defined in </I>a |
|
School defined in </I>a |
|
| Harris et al. (1987) </I>c | +0.48 | C96 </I>f | +0.46 |
| Eggen (1989) </I>d |
|
McWilliam (1997) </I>f,g | +0.45 |
| Gratton & Sneden (1990) </I>e | +0.34 | CdS et al. (1999) </I>h | +0.33 |
| McWilliam & Rich (1994) </I>f | +0.42 | SR | +0.29 |
When the SR and Takeda et al. data are added to the data base discussed by
T99, the statistical paradigm yields a result that is essentially unchanged.
One need only add that the hypothesis that [Fe/H] is actually ![]() +0.3 dex
for
+0.3 dex
for ![]() Leo is rejected at 98% confidence. That hypothesis, which emerges
from applications of the default paradigm, rests on a tradition of
invalid
inferences from the
Leo is rejected at 98% confidence. That hypothesis, which emerges
from applications of the default paradigm, rests on a tradition of
invalid
inferences from the ![]() Leo data base which is continued by SR.
Leo data base which is continued by SR.
Note added in proof: Very recently, it has been suggested in a public forum that result quality for ![]() Leo is related to spectral resolution. This hypothesis may be tested by considering 14 Table 3 data for which values of the resolution R are available. A regression of [Fe/H] against log10R yields a slope of
Leo is related to spectral resolution. This hypothesis may be tested by considering 14 Table 3 data for which values of the resolution R are available. A regression of [Fe/H] against log10R yields a slope of
![]() dex. This slope does not come close to significance at the
dex. This slope does not come close to significance at the ![]() level, so there is in fact no evidence that any particular value of R yields distinctive results.
level, so there is in fact no evidence that any particular value of R yields distinctive results.
Acknowledgements
I thank Mike and Lisa Joner for carefully proofreading this paper, and for suggesting a key improvement in the discussion. I also thank J. Ward Moody for suggesting the term "default paradigm''. Page charges for this paper have been generously underwritten by the College of Physical and Mathematical Sciences and the Physics and Astronomy Department of Brigham Young University.
For their mean Hyades result, Perryman et al. (1998) quote an error bar
of 0.05 dex. If the contributing data used by Perryman et al. are examined,
it is found that this error bar is not an rms error of the mean (Taylor
2000, Appendix B). For the sake of argument, however, suppose that SR
did not examine those contributing data and that they treated the Perryman
et al. error bar as an rms error of the mean. Given that error bar alone, the 95% confidence interval for the SR zero-point comparison is then approximately
![]() dex.
dex.
SR compare two Hyades data (from Smith 1999) with the Perryman et al. Hyades mean. Without error bars, the mean of the Smith data is +0.135 dex, while the Perryman et al. mean is +0.14 dex. The two values are "very close'', as SR state. Suppose, however, that the Perryman et al. error bar is now attached to the difference between those two data. In this case, one concludes at once that their apparent agreement is fortuitous.
If allowance is made for the rms errors of the Smith (1999) results, this
conclusion is strengthened. Suppose now that it is exploited by allowing a
correction to the SR ![]() Leo result of -0.1 dex. That result is then about
+0.2 dex. SR describe it as a metallicity enhancement of about a factor of
two, which would seem to require it to be close to +0.3 dex instead. All
told, it appears that SR did not allow for the effect of the Perryman et al.
error bar.
Leo result of -0.1 dex. That result is then about
+0.2 dex. SR describe it as a metallicity enhancement of about a factor of
two, which would seem to require it to be close to +0.3 dex instead. All
told, it appears that SR did not allow for the effect of the Perryman et al.
error bar.