There is an extensive literature on the measurement of the projected
galaxy correlation function in deep imaging data
(Efstathiou et al. 1991; Roche et al. 1993; Brainerd et al. 1994; Hudon & Lilly 1996; Woods & Fahlman 1997; McCracken et al. 2000).
Here we will only briefly outline the relevant equations. We have
computed the two-point projected galaxy correlation function using the
Landy & Szalay (1993) (LS) estimator,
The fitted amplitudes quoted in this paper assume a power law slope for
the galaxy correlation function,
![]() ;
however this amplitude must
be adjusted for the "integral constraint'' correction, arising from
the need to estimate the mean density from the sample itself. This can
be estimated as (Roche et al. 1993),
;
however this amplitude must
be adjusted for the "integral constraint'' correction, arising from
the need to estimate the mean density from the sample itself. This can
be estimated as (Roche et al. 1993),
To minimise computational requirements (necessary given the large
numbers of galaxies in our samples, typically 30000 galaxies per
field) we use a sorted linked list method to compute the numbers of
galaxy pairs in each angular bin (and furthermore we have verified that
this method gives the same results as a direct-pair counting approach;
it is, however ![]()
![]() faster). We use polygonal masks to
blank out regions surrounding bright stars, large galaxies, satellite
trails and cosmetic defects. We also discard data from CCD 8 because of
its poor charge transfer properties. Our masking strategy is quite
conservative, and (excluding CCD 8), around
faster). We use polygonal masks to
blank out regions surrounding bright stars, large galaxies, satellite
trails and cosmetic defects. We also discard data from CCD 8 because of
its poor charge transfer properties. Our masking strategy is quite
conservative, and (excluding CCD 8), around ![]() of the total area
is removed. Because the 11 hr and 22 hr fields are composed of two
separate stacks which are rotated relative to each other, are able to
cover the entire
of the total area
is removed. Because the 11 hr and 22 hr fields are composed of two
separate stacks which are rotated relative to each other, are able to
cover the entire
![]() area for these fields. We have
verified that the masks do not bias the determination of
area for these fields. We have
verified that the masks do not bias the determination of
![]() by applying them to randomly generated
catalogues with the same number density as the real catalogues and
verifying that
by applying them to randomly generated
catalogues with the same number density as the real catalogues and
verifying that
![]() is zero at all angular scales. We have
also tested the effect of masks on clustered catalogues generated using
the method of Soneira & Peebles (1978). These tests (which were
carried out using the LS estimator) show that the application of masks
does not change our fitted correlation amplitudes. Note that we do not
apply a stellar dilution correction to our measured correlation
amplitudes as some authors do, as the form of the stellar counts for
high galactic latitude fields is not precisely known. However, this
correction is unlikely to raise the amplitude of the correlation
function by more than
is zero at all angular scales. We have
also tested the effect of masks on clustered catalogues generated using
the method of Soneira & Peebles (1978). These tests (which were
carried out using the LS estimator) show that the application of masks
does not change our fitted correlation amplitudes. Note that we do not
apply a stellar dilution correction to our measured correlation
amplitudes as some authors do, as the form of the stellar counts for
high galactic latitude fields is not precisely known. However, this
correction is unlikely to raise the amplitude of the correlation
function by more than ![]() ,
given that stars outnumber galaxies by
at least an order of magnitude beyond
,
given that stars outnumber galaxies by
at least an order of magnitude beyond
![]() .
.
For each of our four fields, we divide our catalogue into magnitude
limited samples. Each sample reaches one half-magnitude deeper than the
previous, while the bright limit is kept at
IAB=18.5. (As the 14 hr
field is shallower than the other fields,
we do not measure
![]() on this field fainter than
IAB=24.0.) These
samples are extracted from the
on this field fainter than
IAB=24.0.) These
samples are extracted from the ![]() catalogues prepared as outlined
in Sect. 3.1; we have also performed the
same computation on single-band catalogues (i.e., those computed without
using an associated
catalogues prepared as outlined
in Sect. 3.1; we have also performed the
same computation on single-band catalogues (i.e., those computed without
using an associated ![]() image for detection) and find identical
results. Fig. 12 shows the logarithm of the
amplitude of
image for detection) and find identical
results. Fig. 12 shows the logarithm of the
amplitude of
![]() averaged over the four fields of the CFDF
as a function of the logarithm of the angular separation in degrees,
for a number of magnitude-limited samples. In the range
averaged over the four fields of the CFDF
as a function of the logarithm of the angular separation in degrees,
for a number of magnitude-limited samples. In the range
![]() (
(
![]() )
our measurements follow the
expected power-law behaviour very well and at least until
)
our measurements follow the
expected power-law behaviour very well and at least until
![]() there is no evidence of significant excess power on
scales larger than the individual UH8K CCDs (
there is no evidence of significant excess power on
scales larger than the individual UH8K CCDs (![]() 10'), in agreement
with the evidence presented in Sect. 2.5
that the systematic photometric errors in our fields are negligible.
10'), in agreement
with the evidence presented in Sect. 2.5
that the systematic photometric errors in our fields are negligible.
At
![]() we find at fainter magnitudes that
we find at fainter magnitudes that
![]() deviates from the expected power-law behaviour. We have attempted to
investigate the origin of this effect (which is seen in all our fields)
by carrying out an extensive set of simulations. In these simulations
we generate a catalogue with
deviates from the expected power-law behaviour. We have attempted to
investigate the origin of this effect (which is seen in all our fields)
by carrying out an extensive set of simulations. In these simulations
we generate a catalogue with ![]()
![]() objects which have the same
correlation amplitude as the
objects which have the same
correlation amplitude as the
![]() sample. Each of these
objects is assigned a random magnitude in a specified interval and then
added to the data frame. Object detection and photometry is carried out
in a box extracted at this location. A new catalogue is constructed
containing recovered total magnitudes for each object, and a magnitude
cut is then applied to this sample. Objects which are lost in this
process are typically those falling on or near bright stars or
galaxies, or those whose recovered total magnitude falls outside our
magnitude cut. Masks are applied to this catalogue and
sample. Each of these
objects is assigned a random magnitude in a specified interval and then
added to the data frame. Object detection and photometry is carried out
in a box extracted at this location. A new catalogue is constructed
containing recovered total magnitudes for each object, and a magnitude
cut is then applied to this sample. Objects which are lost in this
process are typically those falling on or near bright stars or
galaxies, or those whose recovered total magnitude falls outside our
magnitude cut. Masks are applied to this catalogue and
![]() computed using the same procedures used for the real
data. This procedure is then repeated for progressively fainter
magnitude slices. (In constructing the simulated catalogue, two
simplifying assumptions were made, firstly that the input magnitude
distribution of objects is flat, and secondly we use objects with
Gaussian point-spread functions.)
computed using the same procedures used for the real
data. This procedure is then repeated for progressively fainter
magnitude slices. (In constructing the simulated catalogue, two
simplifying assumptions were made, firstly that the input magnitude
distribution of objects is flat, and secondly we use objects with
Gaussian point-spread functions.)
In Fig. 13 we show the results of two of
these simulations, labelled (b) and (c). The results displayed for (a) show the measured correlations for the
18.5<IAB<24.0 magnitude
slice. In order to display deviations from the power-law behaviour,
each slice has been normalised by the fitted amplitude for the
18.5<IAB<24.0 slice, taking into account the integral constraint
correction and assuming a
![]() power law. These simulations
cannot reproduce the depression in the correlation function found at
scales
power law. These simulations
cannot reproduce the depression in the correlation function found at
scales
![]() .
We have also investigated if the
depression is caused by an excess of objects around bright stars, and
have found no evidence of such an excess. An important aspect of these
simulations, however, is that they confirm that excess power on large
scales only becomes important for the CFDF data for the faintest
magnitude ranges,
24.5<IAB<25.5.
.
We have also investigated if the
depression is caused by an excess of objects around bright stars, and
have found no evidence of such an excess. An important aspect of these
simulations, however, is that they confirm that excess power on large
scales only becomes important for the CFDF data for the faintest
magnitude ranges,
24.5<IAB<25.5.
![\begin{figure}
\par\includegraphics[width=10cm,clip]{H2798F14.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img124.gif) |
Figure 14:
The logarithm of the fitted amplitude of the angular
correlation
|
In Fig. 14 we plot the fitted amplitude of
![]() at one arcminute,
at one arcminute,
![]() ,
averaged over
all our fields, (filled circles) as a function of the sample median ABmagnitude (
,
averaged over
all our fields, (filled circles) as a function of the sample median ABmagnitude (
![]() ). We have estimated the error bars on
). We have estimated the error bars on
![]() ,
,
![]() ,
using an analytic approximation
introduced by Bernstein (1994) and further developed by
Colombi (Szapudi & Colombi Szapudi & Colombi 1996); see also Arnouts et al., in preparation
for a detailed explanation of the application of this approximation.
The Bernstein estimator relies on a knowledge of
the higher-order moments of the galaxy correlation function, S3 and S4; we have estimated these quantities directly from the CFDF
dataset and they will be presented in a future work (Colombi et al., in
preparation). At bright magnitudes (
,
using an analytic approximation
introduced by Bernstein (1994) and further developed by
Colombi (Szapudi & Colombi Szapudi & Colombi 1996); see also Arnouts et al., in preparation
for a detailed explanation of the application of this approximation.
The Bernstein estimator relies on a knowledge of
the higher-order moments of the galaxy correlation function, S3 and S4; we have estimated these quantities directly from the CFDF
dataset and they will be presented in a future work (Colombi et al., in
preparation). At bright magnitudes (
![]() ),
),
![]() is dominated by the Poisson error component; however,
faintwards of
is dominated by the Poisson error component; however,
faintwards of
![]() ,
the main component of
,
the main component of
![]() in our field consists of cosmic variance (or "finite
volume'') effects. Our analytic estimates of this effect indicate that
the errors estimated empirically from the field-to-field variance of
our four fields may underestimate the total error at these magnitudes
by around
in our field consists of cosmic variance (or "finite
volume'') effects. Our analytic estimates of this effect indicate that
the errors estimated empirically from the field-to-field variance of
our four fields may underestimate the total error at these magnitudes
by around ![]()
![]() .
.
Our fitted amplitudes were computed assuming a -0.8 slope for
![]() (to allow a comparison with the literature), and over
the range
(to allow a comparison with the literature), and over
the range
![]() .
We have also attempted to fit for
.
We have also attempted to fit for ![]() only at larger separations (
only at larger separations (![]()
![]() ), but our survey
fields are not large enough to detect any scale-dependence in the
), but our survey
fields are not large enough to detect any scale-dependence in the
![]() relation. Additionally,
Fig. 14 shows a compilation of recent measurements
of
relation. Additionally,
Fig. 14 shows a compilation of recent measurements
of ![]() from the literature. These literature measurements all
assume a fixed slope of
from the literature. These literature measurements all
assume a fixed slope of
![]() ,
with the exception of the
Postman et al. survey, in which the slope was
allowed to vary with the fit. To allow a fair comparison with the
other authors, and with our work, the
Postman et al. points are not plotted faintwards of
,
with the exception of the
Postman et al. survey, in which the slope was
allowed to vary with the fit. To allow a fair comparison with the
other authors, and with our work, the
Postman et al. points are not plotted faintwards of
![]() ,
where their fitted slopes begin to differ
significantly from -0.8.
,
where their fitted slopes begin to differ
significantly from -0.8.
At bright magnitudes (
![]() )
we find that our
observations are compatible with almost all the data from the
literature compilation. At fainter magnitude ranges, (
)
we find that our
observations are compatible with almost all the data from the
literature compilation. At fainter magnitude ranges, (
![]() ), our observations clearly favour a low amplitude for
), our observations clearly favour a low amplitude for ![]() .
At
.
At
![]() they are least a factor of ten below the value of
they are least a factor of ten below the value of
![]() found by Brainerd & Smail (1998). This work covers a
small area (
found by Brainerd & Smail (1998). This work covers a
small area (![]() 50 arcmin2) and consists of individual unconnected
pointings. As has been suggested before (McCracken et al. 2000) the
discrepancy may be due to field-to-field variance in the galaxy
clustering signal. To provide a more direct answer this question, we
extract 200 regions of 50 arcmin2 from the 22 hr and 11 hr fields
(these two have complete coverage as a consequence of bonette
rotations). On each of these sub-regions we measure
50 arcmin2) and consists of individual unconnected
pointings. As has been suggested before (McCracken et al. 2000) the
discrepancy may be due to field-to-field variance in the galaxy
clustering signal. To provide a more direct answer this question, we
extract 200 regions of 50 arcmin2 from the 22 hr and 11 hr fields
(these two have complete coverage as a consequence of bonette
rotations). On each of these sub-regions we measure ![]() as for
the full sample. In Fig. 15 we show the histogram of
the fitted values for the 11 hr and 22 hr fields; from this we estimate
that a
as for
the full sample. In Fig. 15 we show the histogram of
the fitted values for the 11 hr and 22 hr fields; from this we estimate
that a
![]() error bar indicates a dispersion of
error bar indicates a dispersion of ![]() in
in
![]() .
It is clear that the error bars on
Brainerd & Smail measurement underestimate the true
error by a large amount.
.
It is clear that the error bars on
Brainerd & Smail measurement underestimate the true
error by a large amount.
![\begin{figure}
\par\includegraphics[width=7.7cm,clip]{H2798F15.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img137.gif) |
Figure 15:
The logarithm of the fitted correlation amplitude at
|
We have also determined
![]() in one-magnitude slices,
for instance,
19.5<IAB<20.5,
20.5<IAB<21.5 to the limit of
our survey, as an additional check. These measurements are considerably
more noisy than the integrated measurements presented above because of
the smaller numbers of galaxies in each slice. However, we find that
the derived
in one-magnitude slices,
for instance,
19.5<IAB<20.5,
20.5<IAB<21.5 to the limit of
our survey, as an additional check. These measurements are considerably
more noisy than the integrated measurements presented above because of
the smaller numbers of galaxies in each slice. However, we find that
the derived
![]() relation is very
similar to what is presented in Fig. 14.
relation is very
similar to what is presented in Fig. 14.
The large numbers of galaxies in our survey allows us to make a direct
measurement of ![]() ,
the slope of
,
the slope of
![]() as a function of
sample limiting magnitude. Several attempts at this measurement have
been carried out but with generally inconclusive results.
Neuschaefer & Windhorst (1995) find
as a function of
sample limiting magnitude. Several attempts at this measurement have
been carried out but with generally inconclusive results.
Neuschaefer & Windhorst (1995) find
![]() at g<25 based on two
independent fields each the size of one of our CFDF fields. Shallower
wide-angle surveys like those of Roche & Eales (1999) and
Cabanac et al. (2000) find no evidence for deviation from a slope
of
at g<25 based on two
independent fields each the size of one of our CFDF fields. Shallower
wide-angle surveys like those of Roche & Eales (1999) and
Cabanac et al. (2000) find no evidence for deviation from a slope
of ![]() 0.8. One difficulty in this measurement is that excess power
on large scales, such as can be produced by zero-point variations, can
produce an artificially shallow slope. However, we have already
demonstrated that our magnitude zero-point errors are small across our
mosaics (Fig. 4) and that differential
incompleteness only becomes significant for measurements of
0.8. One difficulty in this measurement is that excess power
on large scales, such as can be produced by zero-point variations, can
produce an artificially shallow slope. However, we have already
demonstrated that our magnitude zero-point errors are small across our
mosaics (Fig. 4) and that differential
incompleteness only becomes significant for measurements of
![]() in the CFDF fields at very faint magnitudes
(Fig. 13). Nevertheless, we adopt a
cautious approach and use two different methods to measure
in the CFDF fields at very faint magnitudes
(Fig. 13). Nevertheless, we adopt a
cautious approach and use two different methods to measure ![]() .
.
Firstly we compute ![]() contours from the average correlation per
angular bin over all the fields (Fig. 12), shown in
Fig. 16. In our second method we compute the slope
independently for each field and measure the field-to-field standard
deviation of this fit, which is shown in Fig. 17,
together with a comparison with the fitted slopes from
Postman et al. (1998), computed for a fitting range of
contours from the average correlation per
angular bin over all the fields (Fig. 12), shown in
Fig. 16. In our second method we compute the slope
independently for each field and measure the field-to-field standard
deviation of this fit, which is shown in Fig. 17,
together with a comparison with the fitted slopes from
Postman et al. (1998), computed for a fitting range of
![]() .
An additional complication is that in
both cases our slope-fitting procedure requires an estimation of the
integral constraint (Eq. (5)), which in turn depends on the
slope. To limit these difficulties, we perform the fit only in the
range
.
An additional complication is that in
both cases our slope-fitting procedure requires an estimation of the
integral constraint (Eq. (5)), which in turn depends on the
slope. To limit these difficulties, we perform the fit only in the
range
![]() where the effects of the
integral constraint are expected to be negligible.
where the effects of the
integral constraint are expected to be negligible.
Both methods indicate that at bright magnitudes,
18.5<IAB<22.0,
![]() ;
at fainter magnitudes we detect a slight flattening
of the slope, with
;
at fainter magnitudes we detect a slight flattening
of the slope, with
![]() .
The error bars in
Fig. 17 show the error in
.
The error bars in
Fig. 17 show the error in ![]() for a given value of
for a given value of
![]() ;
from Fig. 16 we see, however, that a slope
of
;
from Fig. 16 we see, however, that a slope
of
![]() is still within
is still within ![]() of our best fit for all
magnitude ranges.
of our best fit for all
magnitude ranges.
For all galaxies in our sample we can measure
(V-I)ABcolours and we can use this to select subsamples by colour. In
Fig. 18 we show
![]() as a
function of
(V-I)AB colour for galaxies with
18.5<IAB<24.0(open pentagons) and
18.5<IAB<23.0 (asterisks). For each of the
four fields, we divide our sample into twelve equally spaced bins in
colour each of width 0.25 in
(V-I)AB. The error bars in
as a
function of
(V-I)AB colour for galaxies with
18.5<IAB<24.0(open pentagons) and
18.5<IAB<23.0 (asterisks). For each of the
four fields, we divide our sample into twelve equally spaced bins in
colour each of width 0.25 in
(V-I)AB. The error bars in
![]() were computed from the field-to-field variance.
Also shown as the dotted and dashed lines is the amplitude of
were computed from the field-to-field variance.
Also shown as the dotted and dashed lines is the amplitude of
![]() for the full-field sample for these two slices.
for the full-field sample for these two slices.
We first note that both these cuts are relatively bright; at
![]() our catalogues are expected to be
our catalogues are expected to be ![]()
![]() complete
(Figs. 6, 9). Additionally, as
shown in Fig. 11, the effect of colour incompleteness
should be minimal, although at
complete
(Figs. 6, 9). Additionally, as
shown in Fig. 11, the effect of colour incompleteness
should be minimal, although at
![]() we may begin to lose some
extremely red objects from our sample.
we may begin to lose some
extremely red objects from our sample.
Our measurements clearly show that redder objects are more strongly
clustered, as has been widely reported for local populations
(Loveday et al. 1995). We find that objects with
![]() have a clustering amplitude at least a factor of ten
higher than the full field population, shown as the dotted and
dashed lines in Fig. 18. Interestingly, we also
find that the bluest objects in our survey, those with
have a clustering amplitude at least a factor of ten
higher than the full field population, shown as the dotted and
dashed lines in Fig. 18. Interestingly, we also
find that the bluest objects in our survey, those with
![]() ,
have a clustering amplitudes marginally higher than the full
sample. Furthermore, we find that none of our colour selected
samples have clustering amplitudes below the full-field value. We
discuss the implications of these results in the following section.
,
have a clustering amplitudes marginally higher than the full
sample. Furthermore, we find that none of our colour selected
samples have clustering amplitudes below the full-field value. We
discuss the implications of these results in the following section.
Copyright ESO 2001
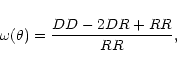
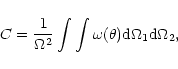
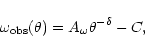
![\begin{figure}
\par\includegraphics[width=7.4cm,clip]{H2798F12.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img119.gif)
![\begin{figure}
\par\includegraphics[width=7.8cm,clip]{H2798F13.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img120.gif)
![\begin{figure}
\par\includegraphics[width=7.7cm,clip]{H2798F17.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img144.gif)
![\begin{figure}
\par\includegraphics[width=7.7cm,clip]{H2798F18.ps} \end{figure}](/articles/aa/full/2001/36/aah2798/img150.gif)