| Issue |
A&A
Volume 695, March 2025
|
|
|---|---|---|
| Article Number | L17 | |
| Number of page(s) | 6 | |
| Section | Letters to the Editor | |
| DOI | https://doi.org/10.1051/0004-6361/202452924 | |
| Published online | 21 March 2025 | |
Letter to the Editor
Inversely synthesizing the core mass function of high-mass star-forming regions from the canonical initial mass function
1
Max-Planck-Institut für Radioastronomie, Auf dem Hügel 69, 53121 Bonn, Germany
2
Helmholtz-Institut für Strahlen- und Kernphysik (HISKP), Universität Bonn, Nussallee 14–16, 53115 Bonn, Germany
3
Charles University in Prague, Faculty of Mathematics and Physics, Astronomical Institute, V Holešovičkách 2, CZ-180 00 Praha 8, Czech Republic
4
Max-Planck-Institut für Astronomie, Königstuhl 17, 69117 Heidelberg, Germany
⋆ Corresponding authors; jwzhou@mpifr-bonn.mpg.de, pkroupa@uni-bonn.de, dib@mpia.de
Received:
8
November
2024
Accepted:
1
March
2025
Many studies have revealed that the core mass function (CMF) in high-mass star-forming regions is top-heavy. In this work, we start from the canonical initial mass function (IMF) to inversely synthesize the observed CMFs of high-mass star formation regions, taking into account variations in multiplicity and mass conversion efficiency from core to star (ϵcore). To match the observed CMFs, cores of different masses should have varying ϵcore, with ϵcore increasing as the core mass decreases. However, the multiplicity fraction does not affect the synthesized CMFs. To accurately fit the high-mass end of the CMF, it is essential to determine whether the CMF shows a slope transition from the low-mass end to the high-mass one. If the CMF truly undergoes a slope transition but observational biases obscure it, leading to a combined fit with a shallower slope, this could artificially create a top-heavy CMF.
Key words: binaries: general / stars: formation / stars: protostars / ISM: clouds
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1. Introduction
Giant molecular clouds (GMCs) are widely recognized as the primary gas reservoirs that fuel star formation and serve as the birthplaces of nearly all stars. A dense core is a localized fragment or overdensity within a molecular cloud, representing a local minimum in gravitational potential and serving as the precursor to an individual star or stellar system (André et al. 2014). A prestellar core is a dense core that remains starless while being gravitationally bound. In star-forming regions within the solar neighborhood that produce solar-type stars, the prestellar core mass function (CMF) closely resembles the initial mass function (IMF) (Alves et al. 2007; Enoch et al. 2008; André et al. 2014; Könyves et al. 2015; Di Francesco et al. 2020). This similarity has led to the hypothesis that the IMF’s shape may be directly inherited from the CMF. However, the Milky Way includes both low-mass and high-mass star-forming regions. A thorough analysis of large statistical samples of massive protoclusters is essential to observationally determine whether the origin of the IMF is truly independent of cloud properties. Thanks to observations with the Atacama Large Millimeter/submillimeter Array (ALMA), numerous studies have now examined CMFs in high-mass star-forming regions (Motte et al. 2018; Liu et al. 2018; Cheng et al. 2018; Sanhueza et al. 2019; Lu et al. 2020; Sadaghiani et al. 2020; O’Neill et al. 2021; Pouteau et al. 2022; Nony et al. 2023; Louvet et al. 2024), revealing that the CMFs in these regions are flatter than the ones in nearby, low-mass star-forming regions. The excess of high-mass cores in these regions indicates a top-heavy CMF, which may challenge the universality of the IMF. In the literature, the CMF fitting for high-mass star-forming regions typically does not differentiate between core types (such as prestellar or protostellar). However, the differentiation was done in Sanhueza et al. (2019), Nony et al. (2023). Sanhueza et al. (2019) derived a power law index of −2.17 ± 0.10 for the prestellar CMF, which is slightly shallower than the Salpeter IMF. In Nony et al. (2023), on the other hand, the prestellar CMF has a power law index of −2.46 ± 0.15. The protostellar CMF in Nony et al. (2023) is significantly shallower than the Salpeter value, with an index of −1.96 ± 0.09. As is shown in Sect. 3.1, the observed CMF of high-mass star-forming regions may not be robust.
It is now widely accepted that the majority of stars both form and exist on the main sequence with at least one stellar companion; “single stars are the exception, not the rule” (see Offner et al. 2023 and references therein). Goodwin & Kroupa (2005) argued that the short (< 105 yr) dynamical decay times of nonhierarchical multiple systems imply that most stars must form in binary systems or dynamically stable hierarchical higher-order systems to explain the observed very high fraction of binaries in about 1 Myr old star-forming regions. Multiple star systems are formed during the earliest stages of star formation. Observations have offered evidence that the multiplicity fraction of protostars is higher than that of pre-main-sequence and main-sequence stars (Looney et al. 2000; Chen et al. 2013), indicating that most systems initially form as multiples. Observations of multiplicity in the youngest stellar systems are key to understanding their origins (Izquierdo et al. 2018; Olguin et al. 2021, 2022; Tobin et al. 2022; Li et al. 2024). As is shown in Fig. 1 of Offner et al. (2023), the likelihood of massive protostars forming as multiple systems may approach nearly 100%.
The multiplicity of protostars is tightly correlated with the origin of the IMF or the transformation from the CMF to the IMF. Despite the high multiplicity fraction among protostars, it is often assumed that a single core will produce only one star. A core at low resolution may actually consist of multiple smaller-scale cores, which should form a multiple system rather than a single star. Assuming a one-to-one mapping between cores and stars artificially shifts the cores to the higher-mass range, potentially making the CMF appear top-heavy. Apart from the multiplicity, the mass conversion efficiency from core to star (ϵcore) will also have a significant impact on the transformation between the CMF and the IMF. For the cores in star-forming regions within the solar neighborhood, the values of ϵcore are ≈20−40% (Alves et al. 2007; Könyves et al. 2010, 2015; Megeath et al. 2016). In this work, we start from the canonical IMF to inversely synthesize the observed CMF of high-mass star formation regions, taking into account variations in multiplicity and ϵcore.
2. Sample
For three high-mass star-forming regions, W43-MM1&MM2&MM3, we used the core catalogs in Motte et al. (2018), Pouteau et al. (2022), Nony et al. (2023), Louvet et al. (2024). For the same observation in the ALMA-IMF survey (Motte et al. 2022), the core catalogs of W43-MM1&MM2&MM3 are presented in Pouteau et al. (2022), Nony et al. (2023), Louvet et al. (2024). For W43-MM1, there is an independent catalog derived from the observation in Motte et al. (2018). For the same region, different catalogs have different selection criteria and identifications, varying in the number of cores and their mass distribution, which is reflected in the differences in the CMF, as is shown in Fig. 1.
 |
Fig. 1. Complementary cumulative distribution function (CCDF) plot and the linear fitting of the observed CMF in the mass range marked by two vertical dashed lines. β is the slope of the corresponding dN/dM mass function derived from linear fitting of the CCDF. The lower mass of the adopted fitting range corresponds to the observational mass completeness level estimated by Louvet et al. (2024). |
3. Results and discussion
3.1. Observed CMFs
For W43-MM2&MM3, the core catalogs in Nony et al. (2023) were directly selected from those in Pouteau et al. (2022), which only retains a portion of the original lists. The CMFs derived from the core catalogs in Pouteau et al. (2022) and Nony et al. (2023) have similar slopes, but the catalogs in Nony et al. (2023) with fewer cores shift systematically upward. For W43-MM1, three independent identifications in different observations give comparable CMFs. For W43-MM3, two independent identifications in the same observation give quite different CMFs. Therefore, numerous observational constraints affect the CMF, including the calculation of the core’s physical parameters, observational resolution, identification methods, and the completeness of the core population. However, the shallow nature of the CMF slope in W43 seems fairly robust at least.
3.2. Clumps and embedded clusters
Clumps are localized high-density structures within a molecular cloud and serve as the primary sites of star formation within the cloud (Urquhart et al. 2018, 2022). Cores are assumed to be overdense regions with respect to their parental clump. Generally, a cloud includes many clumps, and a clump includes many cores. They appear as hierarchical, multiscale hub-filament structures (Kumar et al. 2020; Zhou et al. 2022, 2023, 2024a; Zhou & Davis 2024). To trace the evolution from the CMF to the IMF, the observation should cover the entire clump, as was done in the ALMA-IMF survey. A clump eventually forms an embedded cluster with an IMF (Yan et al. 2017; Zhou et al. 2024b,c). This IMF corresponds to the initial CMF in the clump. Therefore, clumps should be regarded as the fundamental units for studying the origin of the IMF (Kroupa et al. 2024). W43 is a molecular cloud complex. The main star-forming regions in W43 are the clumps. The three subregions of W43 (W43-MM1&MM2&MM3) correspond to three independent clumps displayed in Table 1. They have independent star formation (Zhou et al. 2024d), and thus different CMFs, as is shown in Fig. 1.
Physical parameters of the corresponding ATLASGAL clumps.
The ATLASGAL clumps in Urquhart et al. (2022) corresponding to each region are listed in Table 1. Zhou et al. (2024b,c) systematically studied the relationship between the physical parameters of the embedded clusters within ATLASGAL clumps with HII regions (HII-clumps) and the physical parameters of the clumps themselves. We derived a Mcl − Mecl relation in Zhou et al. (2024c):
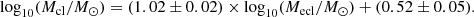
Therefore, according to the clump mass (Mcl), we can directly estimate the embedded cluster mass in stars (Mecl) in the clump. Although this relation is derived from HII-clumps, considering that the clumps in different evolutionary stages have similar mass distributions (Urquhart et al. 2022), it can also be used for younger clumps.
3.3. Initial stellar populations
Based on the recipe described in Appendix B, the initial stellar population in each high-mass star-forming region was generated using the updated McLuster program (Küpper et al. 2011; Wang et al. 2019), according to the embedded cluster mass (Mecl) estimated in Sect. 3.2. Assuming that the average mass of stars in a cluster is 0.5 M⊙, the total number of stars in a cluster (Nstar) is Mecl/(0.5 M⊙). The proportion of binaries in the initial stellar population (fb) is an adjustable parameter in the McLuster code. Since the primary and secondary mass of the binary was selected randomly from the canonical IMF, for each embedded cluster, we ran McLuster 100 times, and overlapped these 100 stellar populations to derive a synthesized core population. For binaries, we summed the masses of each pair corresponding to one core. For single stars, we retained the generated mass. Then the stellar mass was divided by ϵcore to construct the mass distribution of the cores.
To derive the CMF, one common approach is to fit a linear relationship to data that has been grouped into evenly sized bins in logarithmic space. However, binning can lead to substantial information loss, as it aggregates data points into groups rather than using each one individually, which can obscure finer details in the distribution. This issue is especially pronounced in the higher mass range, where bins may contain very few data points, resulting in slope estimates that are often skewed and unreliable (Maíz Apellániz & Úbeda 2005; Maschberger & Kroupa 2009). To address these limitations, Koen (2006) employed a complementary cumulative distribution function (CCDF) plot, which avoids binning and retains more detail than traditional binning methods. Taking mmax = 100 M⊙, equation (A.1) was used to generate mock data of the IMF. According to the theoretical mmax − Mecl relation derived in Zhou et al. (2024c), mmax = 100 M⊙ corresponds to Mecl ≈ 5000 M⊙; thus, the number of stars (Nstar) in the realization is 10 000. Fig. B.1 shows the CCDF plot of the IMF.
3.4. Comparison of synthesized and observed CMFs
For all three regions in Fig. 1, the low-mass end of the CMFs does not exhibit the clear transition seen in the IMF, which may be caused by the uncertainty in core mass estimation. As is discussed in Louvet et al. (2024), the primary sources of error in the mass estimates stem from uncertainties in the opacity index and core temperature. To account for these uncertainties, they conducted a Monte Carlo simulation on 330 cores exceeding the 1.64 M⊙ completeness threshold, allowing simultaneous variations in the opacity index, temperature, and source flux. Fig. 6 of Louvet et al. (2024) presents the cumulative CMFs obtained from 103 simulation trials, where we can see a clear slope transition.
According to the observed CMF, we have fixed the mass range of the linear fitting for each clump in Fig. 1. For the synthesized core population of each clump, we strictly follow the fixed mass range to do linear fitting (the dashed black segments in Figs. 2, 3 and 4). A direct comparison between the synthesized and observed CMFs is only meaningful above the estimated mass completeness level of the observed sample. Therefore, for the purpose of direct comparison, all CCDFs (both observed and synthesized) were normalized to 1 at the mass completeness level marked by the left vertical dashed line in Fig. 1.
 |
Fig. 2. Complementary cumulative distribution function (CCDF) plot and the linear fitting of the synthesized CMFs (in cyan) for W43-MM1 by setting fb = 1 and ϵcore = 0.2. (a)–(c) The cases of mmax = 150 M⊙, half the original number of stars (Nstar/2) and twice the original number of stars (Nstar * 2), respectively; (d) The case in which ϵcore decreases with decreasing core mass. ϵcore was randomly selected from the range (0.2, 0.4); (e) The case in which ϵcore increases with decreasing core mass. ϵcore was randomly selected from the range (0.2, 0.4); (f) Same as panel e, but ϵcore is in the range (0.1, 0.3). All selected ϵcore in panels d, e, and f are sorted in descending or ascending order. All CCDFs (both observed and synthesized) were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
 |
Fig. 3. Comparison of the synthesized CMFs for W43-MM1 for fb = 1, 0.5 and 0. All synthesized CCDFs were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
 |
Fig. 4. Same as Fig. 2f for W43-MM1. Here is the comparison of the synthesized CMFs and the observed CMFs for W43-MM2/MM3, assuming that ϵcore increases with decreasing core mass. All CCDFs (both observed and synthesized) were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
In Fig. 2f, there is a noticeable transition region in the synthesized CMFs, where the slope changes from flat to steep; that is, segment “2” in Fig. 5. As is illustrated by the dashed red line in Fig. 5, if the fitting range lies precisely within this transition region, it encompasses both the flat and steep slopes, resulting in an overall flat slope. If an observed CMF truly exhibits such a slope transition but observational biases obscure it, leading to a combined fit with a shallower slope, then the apparent top-heavy CMF would be merely an artifact. To accurately fit the high-mass end of the CMF, it is essential to identify whether the critical masses for the transition – “m1” and “m2” in Fig. 5 – exist. If so, this critical mass, m2, should be used as the starting point for fitting the slope of the high-mass end, which can then be compared to the Salpeter value. These issues appear in Fig. 6 of Louvet et al. (2024), in which a combined fit results in a shallower CMF slope. When focusing only on the high-mass end of this figure, the CMF slope is actually comparable to the Salpeter value.
 |
Fig. 5. The synthesized CMF can be roughly divided into three segments, i.e., “1”, “2”, and “3”. Segment “2” is the transition part. “m1” and “m2” mark the mass range of the transition. Segment “3” is the real CMF of high-mass cores. The dashed red line is the observed CMF, for which observational biases prevent one from distinguishing the transition, resulting in a combined fit of three different segments with a shallower slope. Thus, the observed top-heavy CMF is an artifact. |
By setting fb = 1 and ϵcore = 0.2, in Figs. 2a–c, we explored how the selected mmax and Nstar (or Mecl) influence the synthesized CMFs, and found that the synthesized CMFs are not sensitive to these parameters. A larger mmax will increase the mass at the high-mass end, which is beyond the observed core mass range. For the same reason, we do not consider systems of a higher order than binaries (such as triples and quadruples) in this work. In Fig. 3, the synthesized CMFs with fb = 1 do not provide better fits than those with fb = 0.5 or fb = 0. A high multiplicity fraction in the synthesis is not necessary.
However, in Figs. 2a–c, the synthesized CMFs do not align with the observed ones. The reason may be that, in each case, we apply a constant ϵcore for all the synthesized cores. A likely possibility is that cores of different masses have different ϵcore. In Figs. 2d–e, we compare two scenarios in which ϵcore either increases or decreases with decreasing core mass, respectively. In each case, ϵcore was randomly selected from a range, then, all selected ϵcore were sorted in descending or ascending order. We found that in order to match the observed CMFs, ϵcore must increase with decreasing core mass. A possible explanation is that higher-mass cores contain more gas, leading to the formation of more massive stars, and stronger feedback ultimately disperses more gas. This is similar to the observational results at the clump scale (Zhou et al. 2024c), where the star formation efficiency (SFE) is strongly correlated with the clump mass: higher-mass clumps have a lower SFE. Due to observational resolution limitations, many of the so-called high-mass cores may actually be sub-clumps, which eventually form multiple systems, rather than just a single star. Furthermore, we should keep in mind that the cores in high-mass star formation regions can continue to accrete and accumulate mass during the process of star formation. These need to be considered when estimating ϵcore.
To align the synthesized CMF with the observed CMF, we need to assume lower-mass cores that have higher ϵcore, and then adjust the range of ϵcore accordingly. As is shown in Figs. 2f and 4, this approach successfully aligns the synthesized CMFs of W43-MM1/MM2/MM3 with the observed ones. Since the currently observed CMF may be not robust, we do not discuss the selection of optimal parameters further, as this depends on the specific CMF. Ideally, the mass dependence of ϵcore would be directly determined from observations in future work.
In this work, we have assumed a canonical IMF and inversely reconstructed the observed CMFs to investigate potential factors contributing to a top-heavy CMF. The factors discussed in this work may or may not be valid, implying that the top-heavy CMF could be genuine. The variation in the IMF with environmental conditions has been extensively studied (Lee et al. 2009; Gunawardhana et al. 2011; Mor et al. 2019; Dib 2023; Kroupa et al. 2024; del Alcázar-Julià et al. 2025). Rather than asserting the universality of the IMF, this Letter emphasizes potential issues in the CMF fitting that warrant careful consideration.
Acknowledgments
We thank the referee for providing constructive review comments, which have helped to improve and clarify this work. PK thanks the DAAD Eastern European Exchange Programme at Bonn and Charles University for support.
References
- Alves, J., Lombardi, M., & Lada, C. J. 2007, A&A, 462, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- André, P., Di Francesco, J., Ward-Thompson, D., et al. 2014, in Protostars and Planets VI, eds. H. Beuther, R. S. Klessen, C. P. Dullemond, & T. Henning, 27 [Google Scholar]
- Belloni, D., Askar, A., Giersz, M., Kroupa, P., & Rocha-Pinto, H. J. 2017, MNRAS, 471, 2812 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, X., Arce, H. G., Zhang, Q., et al. 2013, ApJ, 768, 110 [Google Scholar]
- Cheng, Y., Tan, J. C., Liu, M., et al. 2018, ApJ, 853, 160 [NASA ADS] [CrossRef] [Google Scholar]
- Dabringhausen, J., Kroupa, P., & Baumgardt, H. 2009, MNRAS, 394, 1529 [Google Scholar]
- del Alcázar-Julià, M., Figueras, F., Robin, A. C., Bienaymé, O., & Anders, F. 2025, A&A, submitted [Google Scholar]
- Dib, S. 2023, ApJ, 959, 88 [NASA ADS] [CrossRef] [Google Scholar]
- Dib, S., Kim, J., & Shadmehri, M. 2007, MNRAS, 381, L40 [NASA ADS] [CrossRef] [Google Scholar]
- Di Francesco, J., Keown, J., Fallscheer, C., et al. 2020, ApJ, 904, 172 [NASA ADS] [CrossRef] [Google Scholar]
- Elmegreen, B. G., & Shadmehri, M. 2003, MNRAS, 338, 817 [NASA ADS] [CrossRef] [Google Scholar]
- Enoch, M. L., Evans, N. J., Sargent, A. I., et al. 2008, ApJ, 684, 1240 [Google Scholar]
- Goodwin, S. P., & Kroupa, P. 2005, A&A, 439, 565 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gunawardhana, M. L. P., Hopkins, A. M., Sharp, R. G., et al. 2011, MNRAS, 415, 1647 [NASA ADS] [CrossRef] [Google Scholar]
- Izquierdo, A. F., Galván-Madrid, R., Maud, L. T., et al. 2018, MNRAS, 478, 2505 [NASA ADS] [CrossRef] [Google Scholar]
- Koen, C. 2006, MNRAS, 365, 590 [NASA ADS] [CrossRef] [Google Scholar]
- Könyves, V., André, P., Men’shchikov, A., et al. 2010, A&A, 518, L106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Könyves, V., André, P., Men’shchikov, A., et al. 2015, A&A, 584, A91 [Google Scholar]
- Kroupa, P. 1995, MNRAS, 277, 1507 [NASA ADS] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P. 2011, in Computational Star Formation, eds. J. Alves, B. G. Elmegreen, J. M. Girart, & V. Trimble, IAU Symp., 270, 141 [Google Scholar]
- Kroupa, P., Gjergo, E., Jerabkova, T., & Yan, Z. 2024, ArXiv e-prints [arXiv:2410.07311] [Google Scholar]
- Kumar, M. S. N., Palmeirim, P., Arzoumanian, D., & Inutsuka, S. I. 2020, A&A, 642, A87 [EDP Sciences] [Google Scholar]
- Küpper, A. H. W., Maschberger, T., Kroupa, P., & Baumgardt, H. 2011, MNRAS, 417, 2300 [Google Scholar]
- Lee, J. C., Gil de Paz, A., Tremonti, C., et al. 2009, ApJ, 706, 599 [NASA ADS] [CrossRef] [Google Scholar]
- Li, S., Sanhueza, P., Beuther, H., et al. 2024, Nat. Astron., 8, 472 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, M., Tan, J. C., Cheng, Y., & Kong, S. 2018, ApJ, 862, 105 [CrossRef] [Google Scholar]
- Looney, L. W., Mundy, L. G., & Welch, W. J. 2000, ApJ, 529, 477 [NASA ADS] [CrossRef] [Google Scholar]
- Louvet, F., Sanhueza, P., Stutz, A., et al. 2024, A&A, 690, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lu, X., Cheng, Y., Ginsburg, A., et al. 2020, ApJ, 894, L14 [NASA ADS] [CrossRef] [Google Scholar]
- Maíz Apellániz, J., & Úbeda, L. 2005, ApJ, 629, 873 [CrossRef] [Google Scholar]
- Marks, M., & Kroupa, P. 2012, A&A, 543, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marks, M., Kroupa, P., Dabringhausen, J., & Pawlowski, M. S. 2012, MNRAS, 422, 2246 [NASA ADS] [CrossRef] [Google Scholar]
- Maschberger, T., & Kroupa, P. 2009, MNRAS, 395, 931 [NASA ADS] [CrossRef] [Google Scholar]
- Megeath, S. T., Gutermuth, R., Muzerolle, J., et al. 2016, AJ, 151, 5 [Google Scholar]
- Mor, R., Robin, A. C., Figueras, F., Roca-Fàbrega, S., & Luri, X. 2019, A&A, 624, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Motte, F., Nony, T., Louvet, F., et al. 2018, Nat. Astron., 2, 478 [Google Scholar]
- Motte, F., Bontemps, S., Csengeri, T., et al. 2022, A&A, 662, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nony, T., Galván-Madrid, R., Motte, F., et al. 2023, A&A, 674, A75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Offner, S. S. R., Moe, M., Kratter, K. M., et al. 2023, ASP Conf. Ser., 534, 275 [NASA ADS] [Google Scholar]
- Oh, S., Kroupa, P., & Pflamm-Altenburg, J. 2015, ApJ, 805, 92 [Google Scholar]
- Olguin, F. A., Sanhueza, P., Guzmán, A. E., et al. 2021, ApJ, 909, 199 [NASA ADS] [CrossRef] [Google Scholar]
- Olguin, F. A., Sanhueza, P., Ginsburg, A., et al. 2022, ApJ, 929, 68 [NASA ADS] [CrossRef] [Google Scholar]
- O’Neill, T. J., Cosentino, G., Tan, J. C., Cheng, Y., & Liu, M. 2021, ApJ, 916, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Pouteau, Y., Motte, F., Nony, T., et al. 2022, A&A, 664, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sadaghiani, M., Sánchez-Monge, Á., Schilke, P., et al. 2020, A&A, 635, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sana, H., de Mink, S. E., de Koter, A., et al. 2012, Science, 337, 444 [Google Scholar]
- Sanhueza, P., Contreras, Y., Wu, B., et al. 2019, ApJ, 886, 102 [Google Scholar]
- Tobin, J. J., Offner, S. S. R., Kratter, K. M., et al. 2022, ApJ, 925, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Urquhart, J. S., König, C., Giannetti, A., et al. 2018, MNRAS, 473, 1059 [Google Scholar]
- Urquhart, J. S., Wells, M. R. A., Pillai, T., et al. 2022, MNRAS, 510, 3389 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, L., Kroupa, P., & Jerabkova, T. 2019, MNRAS, 484, 1843 [NASA ADS] [CrossRef] [Google Scholar]
- Yan, Z., Jerabkova, T., & Kroupa, P. 2017, A&A, 607, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yan, Z., Jerabkova, T., & Kroupa, P. 2023, A&A, 670, A151 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhou, J.-W., & Davis, T. 2024, PASA, 41, e076 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, J.-W., Liu, T., Evans, N. J., et al. 2022, MNRAS, 514, 6038 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, J. W., Wyrowski, F., Neupane, S., et al. 2023, A&A, 676, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhou, J. W., Dib, S., Juvela, M., et al. 2024a, A&A, 686, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhou, J. W., Kroupa, P., & Dib, S. 2024b, PASP, 136, 094301 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, J. W., Dib, S., & Kroupa, P. 2024c, PASP, 136, 094302 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, J.-W., Kroupa, P., & Dib, S. 2024d, A&A, 688, L19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Supplementary figures
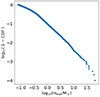 |
Fig. A.1. Complementary cumulative distribution function (CCDF) plot of the IMF in equation A.1 by taking mmax = 100 M⊙ and α3 = 2.3. |
Appendix B: Initial stellar populations
Kroupa (1995) proposed a model for the redistribution of energy and angular momentum within proto-binary systems, which directly results in binary characteristics such as mass ratio, eccentricity and period by the time the dynamical evolution of the star cluster begins to take effect. This process effectively generates the initial binary population (IBP), which serves as the starting point for star cluster simulations. The model has been validated against observational data and has successfully explained the binary properties observed in young clusters, associations, and Galactic field late-type binaries (Kroupa 2011; Marks & Kroupa 2012). The process of transforming birth binaries into initial binaries is commonly referred to as pre-main-sequence eigenevolution (Kroupa 1995), as it takes place during the pre-main-sequence phase of binary stars. The term “birth” refers to all protostars still embedded in circumprotostellar material. In contrast, “initial” refers to pre-main-sequence stars that are no longer embedded in such material, as it has been either accreted or expelled during the redistribution of energy and angular momentum. Over a period of approximately 105 years, this pre-main-sequence eigenevolution converts the birth population into the initial population. Belloni et al. (2017) presents an updated version of pre-main-sequence eigenevolution, with the primary difference being the mass ratio distribution in the initial binary populations.
To undergo pre-main-sequence eigenevolution, binaries at birth are formed with specific distributions. The primary mass is selected randomly from the canonical IMF (Kroupa 2001):
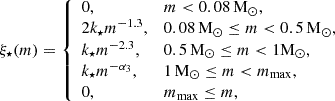
where α3 = 2.3 is the constant Salpeter-Massey index for the invariant canonical IMF but will change for larger ρcl (the density of star-forming clump) to account for IMF variation under star-burst conditions (Elmegreen & Shadmehri 2003; Dib et al. 2007; Dabringhausen et al. 2009; Marks et al. 2012; Dib 2023; Kroupa et al. 2024). As verified in Zhou et al. (2024c), we take α3 = 2.3 in this work. The value of mmax is decided by the theoretical mmax − Mecl relation (Yan et al. 2023; Zhou et al. 2024c). The secondary mass is also randomly drawn from the same IMF, meaning the binary components are paired randomly. It’s important to note that the primary and secondary stars are distinguished only after both stars have been independently chosen from the canonical IMF.
In Kroupa (1995), the pre-main-sequence eigenevolution theory was developed mainly to explain observed properties of Galactic field low-mass binaries (A, F, G, K and M-dwarfs). We note that low-mass binaries in this work correspond to all binaries whose primary mass is smaller than 5 M⊙. Binaries with primary masses greater than this are called high-mass binaries. For high-mass binaries with O and B-dwarfs as primaries (greater than 5 M⊙), we utilize observational distributions derived from O and B-dwarfs in Sana et al. (2012) to generate the birth population. Here we assume that the process of transforming the birth population into the initial population for high-mass binaries has already occurred, and directly utilize observational distributions, since this transformation occurs rapidly for massive stars. The mass ratio distribution of high-mass binaries is a uniform distribution (Oh et al. 2015; Belloni et al. 2017). The eccentricity and period distributions of both low- and high-mass binaries are described in Belloni et al. (2017).
All Tables
All Figures
|
Fig. 1. Complementary cumulative distribution function (CCDF) plot and the linear fitting of the observed CMF in the mass range marked by two vertical dashed lines. β is the slope of the corresponding dN/dM mass function derived from linear fitting of the CCDF. The lower mass of the adopted fitting range corresponds to the observational mass completeness level estimated by Louvet et al. (2024). |
| In the text | |
|
Fig. 2. Complementary cumulative distribution function (CCDF) plot and the linear fitting of the synthesized CMFs (in cyan) for W43-MM1 by setting fb = 1 and ϵcore = 0.2. (a)–(c) The cases of mmax = 150 M⊙, half the original number of stars (Nstar/2) and twice the original number of stars (Nstar * 2), respectively; (d) The case in which ϵcore decreases with decreasing core mass. ϵcore was randomly selected from the range (0.2, 0.4); (e) The case in which ϵcore increases with decreasing core mass. ϵcore was randomly selected from the range (0.2, 0.4); (f) Same as panel e, but ϵcore is in the range (0.1, 0.3). All selected ϵcore in panels d, e, and f are sorted in descending or ascending order. All CCDFs (both observed and synthesized) were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
| In the text | |
|
Fig. 3. Comparison of the synthesized CMFs for W43-MM1 for fb = 1, 0.5 and 0. All synthesized CCDFs were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
| In the text | |
|
Fig. 4. Same as Fig. 2f for W43-MM1. Here is the comparison of the synthesized CMFs and the observed CMFs for W43-MM2/MM3, assuming that ϵcore increases with decreasing core mass. All CCDFs (both observed and synthesized) were normalized to 1 at the mass completeness level marked by the left vertical dashed line. |
| In the text | |
|
Fig. 5. The synthesized CMF can be roughly divided into three segments, i.e., “1”, “2”, and “3”. Segment “2” is the transition part. “m1” and “m2” mark the mass range of the transition. Segment “3” is the real CMF of high-mass cores. The dashed red line is the observed CMF, for which observational biases prevent one from distinguishing the transition, resulting in a combined fit of three different segments with a shallower slope. Thus, the observed top-heavy CMF is an artifact. |
| In the text | |
|
Fig. A.1. Complementary cumulative distribution function (CCDF) plot of the IMF in equation A.1 by taking mmax = 100 M⊙ and α3 = 2.3. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.