| Issue |
A&A
Volume 643, November 2020
|
|
|---|---|---|
| Article Number | A142 | |
| Number of page(s) | 12 | |
| Section | The Sun and the Heliosphere | |
| DOI | https://doi.org/10.1051/0004-6361/202037849 | |
| Published online | 17 November 2020 | |
Spatially resolved measurements of the solar photospheric oxygen abundance
1
Instituto de Astrofísica de Canarias (IAC), Avda Vía Láctea s/n, 38200 La Laguna, Tenerife, Spain
e-mail: mcubas_ext@iac.es
2
Departamento de Astrofísica, Universidad de La Laguna, 38205 La Laguna, Tenerife, Spain
Received:
28
February
2020
Accepted:
27
August
2020
Aims. We report the results of a novel determination of the solar oxygen abundance using spatially resolved observations and inversions. We seek to derive the photospheric solar oxygen abundance with a method that is robust against uncertainties in the model atmosphere.
Methods. We use observations with spatial resolution obtained at the Vacuum Tower Telescope to derive the oxygen abundance at 40 different spatial positions in granules and intergranular lanes. We first obtain a model for each location by inverting the Fe I lines with the NICOLE inversion code. These models are then integrated into a hierarchical Bayesian model that is used to infer the most probable value for the oxygen abundance that is compatible with all the observations. The abundance is derived from the [O I] forbidden line at 6300 Å taking into consideration all possible nuisance parameters that can affect the abundance.
Results. Our results show good agreement in the inferred oxygen abundance for all the pixels analyzed, demonstrating the robustness of the analysis against possible systematic errors in the model. We find a slightly higher oxygen abundance in granules than in intergranular lanes when treated separately (log(ϵO) = 8.83 ± 0.02 vs. log(ϵO) = 8.76 ± 0.02), which is a difference of approximately 2-σ. This tension suggests that some systematic errors in the model or the radiative transfer still exist but are small. When taking all pixels together, we obtain an oxygen abundance of log(ϵO) = 8.80 ± 0.03, which is compatible with both granules and lanes within 1-σ. The spread of results is due to both systematic and random errors.
Key words: Sun: abundances / Sun: atmosphere / Sun: photosphere / methods: statistical
© ESO 2020
1. Introduction
In the mid-2000s, Asplund and collaborators published a series of papers (e.g., Allende Prieto et al. 2001; Asplund et al. 2004, 2009; Scott et al. 2006) claiming that the solar chemical composition should be revised to a lower metallicity (Z). The new lower abundances present some advantages, such as a better fit with the interstellar medium; however, this has been questioned by Ecuvillon et al. (2006), who claim that the composition of planet-hosting stars should be considered. On the other hand, these new abundances ruin the existing agreement between the predictions of solar interior models and helioseismic measurements (see Basu & Antia 2008).
Besides the studies of Asplund and collaborators, there were other groups that worked on the solar abundances, such as Caffau and collaborators, who published another series of papers using the CO5BOLD simulations (Freytag et al. 2012). These latter authors obtained much larger abundances (e.g., Caffau et al. 2008, 2010, 2011, 2013), showing that 3D hydrodynamical simulations do not necessarily suggest low metallicity. There is still no clear consensus on what set of abundances is more realistic and the issue of the solar chemical composition remains largely unresolved.
In the meantime, modelers have taken a critical look at solar interior theories to explore possible modifications capable of reconciling the models with low-Z abundances. In doing so, the opacity data used to construct the models were found to be largely outdated. More recent calculations yield significantly higher opacities, which helps to absorb the impact of a lower metallicity (see Christensen-Dalsgaard et al. 2009; Bailey et al. 2015). The issue with opacities has become even more troublesome with new laboratory measurements of iron under a particular set of stellar interior conditions, resulting in values significantly higher than those of the most sophisticated tabulations (Bailey et al. 2015). However, even if one could somehow tune the opacities to come into agreement with a low-Z solar composition, there would still be unresolved conflicts with incompatible solar wind measurements and also with results from neutrino experiments (e.g., von Steiger & Zurbuchen 2016; Haxton & Serenelli 2008).
In order to resolve the current uncertainties discussed above, more robust empirical constraints on the solar chemical composition are needed. In this paper we focus on the case of oxygen abundance, which is both extremely difficult to constrain and crucially important. This difficulty stems from the fact that there are very few spectral lines in the solar spectrum and they are all either weak, blended with other lines, or affected by complex nonlocal thermodynamic equilibrium (NLTE) formation. Oxygen abundance is crucial because: (i) it is the most abundant of all metals in the Universe; (ii) it is one of the main contributors of free electrons and interior opacity; and (iii) some of the other important elements for interior models (especially N, Ne and Ar) cannot be directly measured (or only with much increased difficulty) and are typically measured relative to O. Therefore, the so-called solar oxygen crisis (Ayres 2012) forms a fundamental part of the chemical composition problem. One of the main difficulties is that the abundances determined from the interpretation of stellar spectra require the prescription of a model atmosphere. The older high-Z abundances were obtained with one-dimensional (1D) semi-empirical models (i.e., Grevesse & Sauval 1998). The Asplund et al. low-Z abundances are obtained from a three-dimensional (3D) hydrodynamical simulation of the atmosphere. Ayres (2008) argued that, while 3D is clearly a better choice than 1D, it is not clear that, when one is fitting synthetic spectra to observations, a theoretical ab initio model should be preferred over a semi-empirical model. This is consistent with the observations because the 1D shortcomings would have been absorbed by the fitting parameters. Socas-Navarro (2015) proposed to overcome the dilemma between 1D empirical and 3D theoretical models by using 3D empirical models. In the same paper, he assessed the importance of systematic effects, concluding that they could be responsible of log(ϵO) fluctuations between 8.70 and 8.90 (i.e., from intermediate to high-Z values). Seemingly minor details, such as minuscule variations in the placement of the continuum or slight changes in the absolute wavelength calibration, have a very large impact on the final result. It is therefore very difficult to make conclusive statements on the oxygen abundance. Independent evidence is needed to make progress, ideally from alternative strategies that are less sensitive to the practical details of the data processing or the (prescribed) model atmosphere.
Here we present a new approach to the problem using spatially resolved observations. We carried out slit-spectroscopy observations in Fe I and [O I] spectral lines simultaneously, thus collecting spectral profiles at many different spatial locations, including granules and intergranular lanes, spanning a temperature range of nearly 1000 K in the photosphere. The approach employed here draws the best of both approaches previously discussed: (i) the model is empirical, obtained by fitting the observed Fe I lines, and (ii) the model is 3D because each spatial pixel has its own temperature, density, and velocity stratification. Another novel ingredient in this approach with respect to previous works is that we do not compare with the average solar spectrum from the FTS atlas observation to derive the overall solar oxygen abundance. Instead, we fit each individual profile observed at each pixel using the same instrument and configuration as that used to derive the atmosphere, therefore obtaining an oxygen abundance value for each point.
2. Observations
Our observations were acquired with the Vacuum Tower Telescope (VTT, Schroeter et al. 1985; von der Lühe 1998) at the Observatorio de Izaña, Tenerife, Spain. The VTT is a solar telescope with two coelostat mirrors at the top of a building of approximately 38 m in height. The coelostat mirrors deliver a nonrotating image of the Sun. The telescope primary mirror has a diameter of 70 cm and a focal length of 46 m. The VTT is equiped with an adaptive-optics system (KAOS, Soltau et al. 2002; von der Lühe et al. 2003) with a wavefront sensor, a deformable mirror, and a high-speed camera.
We use the Echelle spectrograph, one of the available optical instruments at the VTT. It consists of a grating spectrograph with a resolving power of R ≈ 106. The slit covers about 200″, equivalent to roughly 145 Mm on the Sun. Moreover, the VTT is equipped with a slit-jaw camera for observations in white light, Ca K, and Hα. For more information on the telescope, see von der Lühe (1998).
The observational data used in this work were acquired on July 15, 2016 starting at 11:34 UTC, with an exposure time per slit position of 200 ms. The scanning time to cover the entire map was around 4 min (plus the overhead time for data saving and slit motion). The observations produce a 3D (x, y, λ) cube with the spectrum for each pixel in the 2D field of view (FOV) in a quiet region adjacent to active region AR12565 (see the rectangle plotted in Fig. 1), located in the solar equator at around 20 Å west of the solar disk center. Pores in the nearby active region were used as targets for the KAOS adaptive optics system to lock onto. Following standard procedures, we also took dark-current and flat-field images. The standard data-reduction procedure was applied, consisting of dark-current subtraction and flat-field normalization to correct for pixel-to-pixel sensitivity variations. The flat-field images are produced, as usual in this facility, by acquiring and summing images while the telescope is moving on the quiet Sun. This produces an image with no spatial structure from which a good flat-field is obtained after removing the spectrum. Wavelength calibration and correction of the prefilter curvature were also applied. Absolute wavelengths were determined by fitting an average disk-center quiet-Sun profile to the FTS atlas (Neckel 1999). The same fit provides the calibration between counts and physical units and an estimate of the amount of stray light in the observations. Continuum rectification is done by fitting a third-order polynomial to a few selected continuum windows. We estimate the noise in the observations to be around 10−3 in units of the continuum intensity.
 |
Fig. 1. Continuum context image of active region AR12565 on July 15, 2016. Image from the HMI instrument onboard SDO (Scherrer et al. 2012). Our observations are represented by the solid rectangle in the image. The area under the dashed line corresponds to the data employed in this work. |
A 2D map at a continuum wavelength in the 6300 Å region and the mean spectrum in the region are plotted in Fig. 2. The spectral lines of interest are, from left to right: the [O I] forbidden line that we use to infer the oxygen abundance, a Sc II line used for the calibration of the missing dynamics in the inversions (see following section), and the three Fe I lines that we used to construct the model atmospheres, the two widely used Fe I lines at 6301.5 Å and 6302.5 Å, and a weak Fe I line at 6303.5 Å. The two narrow spectral lines at 6302.0 Å and 6302.7 Å are telluric contamination from the Earth’s atmosphere.
 |
Fig. 2. Left: continuum map, marking the position of the pixels considered for this study: granules in green and intergranular lanes in pink (40 pixels in total). As standard practice, these pixels were selected for their continuum brightness, choosing the brightest and darkest points in the FOV. Right: average spectrum in the FOV shows the lines of interest in our work. |
3. Model atmospheres
We carry out inversions of the observed spectra using the NICOLE inversion code (Socas-Navarro et al. 2015). The inversions are done independently for all 40 spatial locations, corresponding to those pixels marked in Fig. 2. Granules are marked in green while intergranular lanes are marked in pink. We did not use all pixels of the image to keep computational time within reasonable values but this sample provides results with statistical relevance. The pixels were selected for their brightness in the continuum, choosing them from among the brightest (for granules) and darkest (for lanes) in the FOV. This extreme selection will enhance any possible difference between granules and lanes. With this strategy, we aim to obtain 40 different determinations of the oxygen abundance which can then be compared to one another. As the inversion is done pixel by pixel, the resulting model is assumed to be spatially resolved with a spatial resolution of 0.8″ px−1. The pair of lines at 6301.5 and 6302.5 Å are relatively strong lines. As already pointed out by Socas-Navarro (2015), this induces a reduced sensitivity to the velocity in the lower layers of the atmosphere, near the surface τcont = 1 for continuum wavelengths, precisely where the [O I] line is formed. For that reason, we add the weak Fe I line at 6303.5 Å to constrain the relevant dynamics that might have been missed by the stronger lines. This is an advantage conferred by our observations with respect to those of Hinode used by Socas-Navarro (2015), which did not reveal the weak Fe I line. The atomic data used for all transitions in the spectral range are summarized in Table 1.
Adopted atomic parameters.
The inversions were performed using eight nodes for the temperature and one for the Doppler velocity. We did not invert the magnetic field because our observations do not include polarimetry. As we deal with quiet Sun profiles, we can assume that magnetic fields do not appreciably affect the intensity profiles. This turns out to be a good approximation according to Borrero (2008) and Fabbian & Moreno-Insertis (2015). We use six nodes for the depth stratification of the microturbulence. This turns out to be important because the synthetic Sc II line close to the [O I] feature in inverted models appears too deep when compared with solar atlases. This points to a lack of small-scale dynamics at the base of the photosphere, where these lines are formed. Consequently, adding a depth stratification of the microturbulence in the model accounts for the missing broadening in the deepest layers. The inferred temperature stratifications of all considered models are displayed in Fig. 3. Granular models are shown in green, while those of lanes are displayed in pink. All models share similar temperature stratifications in the range of log τ5000 (with τ5000 the optical depth measured at 5000 Å) between −2.5 and 0.5, which is where the iron lines that are used here are formed. However, we find that granules display slightly higher temperatures than lanes through the O and Ni line-formation region, although a cross-over point is found in the high photosphere (this gives rise to the reverse-granulation effect seen in the cores of strong lines). We note here that our model extends from log τ5000 = −7 to log τ5000 = 2, but information that can be used to constrain regions below τ5000 > 0.5 and τ5000 < −2.5 is scarce in the spectrum. Examples to illustrate the good fit quality are given in Fig. 4.
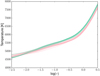 |
Fig. 3. Temperature stratification of each inferred model. The optical depth scale is measured at 5000 Å. |
 |
Fig. 4. Inversions of two spatial pixels. Upper panel: spectral profile of a granule (black) and fit (green). Lower panel: spectral profile of an intergranular lane (black) and fit (pink). Ic is the average quiet Sun continuum intensity. |
Once we have inferred model atmospheres for all 40 pixels, we compute a grid of synthetic spectra by keeping them fixed while modifying the solar oxygen abundance in the range [8.50, 9.20] and the nickel abundance in the range [5.80, 6.36]. Considering the Ni I line is crucial because it is blended with the [O I] line. We included the two major isotopes 58Ni I and 60Ni I in the calculation as in Johansson et al. (2003). We uniformly sample both intervals of abundances with a step of 0.05 for oxygen and 0.04 for nickel. The ranges include high and low abundance values as reported in the literature (e.g., Anders & Grevesse 1989; Grevesse & Sauval 1998; Asplund et al. 2009). We note that this work uses NICOLE (both in inversion and synthesis mode) under LTE conditions. The results of the synthesis are used as a precomputed database to carry out Bayesian inference using a simulator (O’Hagan 2006). This simulator uses a simple bilinear interpolation to synthesize the spectra for arbitrary values of the oxygen and nickel abundances.
4. Bayesian analysis
In the following we describe the Bayesian models (e.g., Gregory 2005) that we use to obtain information about the oxygen abundance. To this end, we compute the marginal posterior probability distribution of the oxygen abundance in all 40 pixels. The first ingredient that we need to define is the generative model, from which the likelihood function will naturally emerge. We model the observed spectrum by a synthetic spectrum obtained under the LTE approximation in the atmospheric models obtained from the inversion. We augment the parameters of the models with some nuisance parameters:
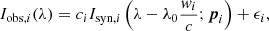
where i = 1, …, N represents the label for each one of the N pixels and λ0 is the central wavelength of the spectral line of interest. The synthesis depends on the set of model parameters pi = {Ti, vi, log(ϵO)i, log(ϵNi)i}. Here, T and v are the temperature and velocity obtained from the inversions, respectively. We also find the oxygen abundance, that we denote log(ϵO), and the nickel abundance, represented by log(ϵNi). Furthermore, we allow for an additional wavelength shift of the line due to inaccuracies in the wavelength scale, which we encode in a Doppler velocity w. Finally, we rescale the continuum by a certain correction factor c which is used to set all profiles to the same continuum level. The synthetic spectrum is perturbed with noise ϵ, which we assume to be Gaussian with diagonal covariance matrix and variance s2. This assumption automatically defines the likelihood for each pixel, which is given by the product of Nλ uncorrelated normal distributions, with Nλ being the number of wavelength points considered in the spectrum:
![$$ \begin{aligned} p(D|{\boldsymbol{p}}_i,&c_i,s_i) = \frac{1}{s^{N_\lambda } (2\pi )^{{N_\lambda }/2}}\\&\prod _{j=1}^{N_\lambda } \exp \left\{ -\frac{1}{2s^2} \left[ I_{{\mathrm{obs},i}}(\lambda _j) - c_i I_{{\mathrm{syn},i}} \left( \lambda _j - \lambda _0 \frac{{ w}_i}{c}; {\boldsymbol{p}}_i \right) \right] \right\} , \end{aligned} $$](/articles/aa/full_html/2020/11/aa37849-20/aa37849-20-eq2.gif)
where D represents all the observed data. All parameters except the oxygen abundance are considered as nuisance parameters and are marginalized out at the end. For computational reasons, we consider the temperature and velocity of the model as fixed quantities and we leave the fully Bayesian approach for a future work. Consequently, we take their priors to be Dirac deltas, which have no effect when marginalized out. The specific priors selected in this work for the rest of parameters are specified in Table 2. Since we have no clear preference for any value of the oxygen abundance, we choose a flat prior. On the contrary, the nickel abundance is very well determined from previous works and we choose a Gaussian prior with a mean that is equal to the consensus value and a small dispersion according to the results of Scott et al. (2009). The posterior distribution, following the Bayes theorem, is:
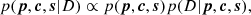
Prior selected for each parameter of our unpooled Bayesian analysis.
where p = {p1, …, pN}, c = {c1, …, cN} and s = {s1, …, sN}. We assume that the prior factorizes for all pixels, meaning that
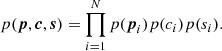
We explore two different Bayesian models for our data. In the first one, each pixel is considered independent of the rest (also known as unpooled model), obtaining the marginal posteriors distribution for the oxygen abundance of each pixel. In the second model, the oxygen abundance is allowed to vary from pixel to pixel but all of them are extracted from a common prior, a hierarchical partial pooling model. As defined in Table 3, this common prior is chosen to be Gaussian, with hyperparameters μO and σO. These parameters are then interpreted as a global estimation of the mean oxygen abundance together with its variability in the pixels that we considered. The advantage of a hierarchical pooling model lies in the fact that we aggregate all pixels while simultaneously allowing for pixel-by-pixel variations, wherever they exist. In this case, the prior for log(ϵO) depends on the hyperparameters μO and σO, meaning that
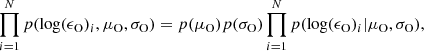
Prior selected for each parameter of the Bayesian analysis using a hierarchical partial pooling model.
and μO and σO are added as parameters during the inference. We note that in this case, the parameter s is also a common prior.
The two probabilistic models are displayed in graphical form in Fig. 5 (upper panel corresponding to the unpooled model and bottom panel to the hierarchical partial pooling model), where all conditional dependences are shown as directed links.
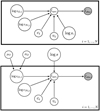 |
Fig. 5. Representation of the parameters for the unpooled model (upper panel) and the hierarchical partial pooling model (bottom panel). For each pixel, we have four parameters that contribute to the shape of the synthetic intensity profile. In addition to those parameters, in the hieararchical partial pooling model, we have two hyperparameters, the mean value and the standard deviation of the Gaussian, which represent the global oxygen distribution. The parameter s accounts for the uncertainties of our model. |
The sampling of the posterior is done with the PyMC3 Python package (Salvatier & Wiecki 2016), which is designed for Bayesian statistical modeling and uses advanced Markov chain Monte Carlo (MCMC) sampling algorithms to generate samples from the posterior distribution. Since the sampling of hierarchical Bayesian models is especially difficult and prone to problems, we relied on the no-U-turn (NUTS, Hoffman & Gelman 2014) Hamiltonian Monte Carlo-type (HMC) method. The NUTS sampler automatically tunes the parameters of the HMC algorithm in order to allow for an efficient sampling of the posterior. It works well on high-dimensional and complex posterior distributions1.
Once samples from the posterior are obtained, it is always good practice to produce posterior predictive checks in which the posterior is used to produce synthetic [O I] line profiles. These checks will clearly show whether or not the generative model is a representative model of the observations. Figure 6 displays posterior predictive checks for all pixels in granules in the unpooled model. Correspondingly, Fig. 7 shows the same for intergranular lanes. The noisy observations are displayed in black. The ability of our model to explain the observed [O I] line is remarkable. Similar plots are presented in the appendix for the hierarchical partial pooling model for granules, intergranules, and both granules and intergranules together.
 |
Fig. 6. Observed (black) and synthetic (green) profiles using values extracted from the posterior for the granules in the unpooled model. The continuum taken to normalize the intensity is the mean continuum between granules and lanes pixels. |
 |
Fig. 7. Observed (black) and synthetic (pink) profiles using values extracted from the posterior for the lanes in the unpooled model. The continuum taken to normalize the intensity is the mean continuum between granules and lanes pixels. |
5. Results and discussion
5.1. Unpooled model
The marginal posterior distributions for the oxygen abundance are shown as boxplots in Fig. 8, where the granules are plotted in green (upper panel) and the lanes in pink (bottom panel). As usual in boxplots, the horizontal line inside the colored boxes represents the median value of the marginal posterior distributions, and the colored box covers from the first to the third quartile (amounting to 50% probability). The lines going beyond the box extend to show the distribution up to two standard deviations. The remaining points are determined to be outliers. The horizontal gray line corresponds to the global mean (the mean of the individual means) and the gray area shows one standard deviation.
 |
Fig. 8. Distribution of oxygen abundance for each pixel. Granules are shown in the upper panel and lanes in the bottom panel. The gray horizontal line represents the mean of the means of each pixel and the gray area represents the standard deviation. The horizontal line inside each color box represents the median value of the marginal posterior distribution, and the color box covers the range encompassing 50% of the probability. |
The results show that all 20 independently analyzed granules yield values that are statistically consistent and compatible inside the error bars of each individual determination. This is also the case for the lanes. Moreover, granules and lanes show results that are compatible within approximately 2-σ. This is an indication of robustness, because there is no reason a priori to expect that all 40 spatial locations will give the same abundance. In that sense, this is a consistent determination of the photospheric abundance. The inferred abundance for oxygen in granules is log(ϵO) = 8.83 ± 0.02, while it is log(ϵO) = 8.76 ± 0.02 for intergranular lanes. These values are obtained by computing the means of the individual means in each pixel.
We interpret the small difference between the oxygen abundance obtained in granules and lanes as a consequence of some systematic errors in our study rather than a real abundance difference. For instance, errors in the determination of the temperature and velocity considerably affect the line profile. If the inversions are repeated, changing the number of nodes or some other parameters, the models obtained will be slightly different, resulting in a different oxygen abundance. Furthermore, there are also errors in the atomic parameters and other systematic effects beyond our control. All of these effects could explain the 2-σ tension found between the granules and lanes.
For completeness, Fig. 9 displays the marginal posterior distributions for the nickel abundance. Here, the marginal posterior distributions are very narrow because the data are extremely consistent with the priors and consistent between granules and lanes. The mean of the means of the individual pixels is log(ϵNi) = 6.16 ± 0.01 both for the granules and for the lanes.
 |
Fig. 9. Distribution of nickel abundances for each pixel. The gray horizontal line represents the mean of the means of each pixel and the gray area represents the standard deviation. Granules are shown in the upper panel and lanes in the bottom panel. |
5.2. Hierarchical partial pooling model
The results of the marginal posterior distribution for the oxygen abundance in the partial pooling model are shown in Fig. 10. In this case, the horizontal line represents the mean of the marginal posterior for the hyperparameter μO, while the shaded area represents the range between μO ± σO. The hierarchical model displays a strong shrinkage effect as compared with the previous model, something that is characteristic of hierarchical Bayesian models. The estimated values for the oxygen abundance for all pixels are pulled towards the group mean, with a much smaller dispersion. In this case, we find μO = 8.83 ± 0.01 and μO = 8.77 ± 0.01 for the granules and the lanes, respectively. On the other hand, the σO distribution has a mean of 0.01 for both granules and lanes; where 95% of the distribution has values of up to σO < 0.023 for the granules and σO < 0.025 for the lanes (see Fig. 13).
 |
Fig. 10. Distribution of oxygen abundance for each pixel. The gray horizontal line represents the hyperparameter of oxygen abundance and the gray area covers the probable values within the standard deviation, which is the other hyperparameter. Granules are shown in the upper panel and lanes in the bottom panel. |
The marginal posterior distributions for the nickel abundance in this case are shown in Fig. 11. The mean value obtained is log(ϵNi) = 6.16 ± 0.03, both for the granules and for the lanes. In general, we find similar values in both the unpooled and partially pooled model for the oxygen and nickel abundances, which demonstrates the robustness of our result.
 |
Fig. 11. Distribution of nickel abundance for each pixel. The gray horizontal line represents the mean value of the mean values for the nickel abundance in each pixel and the gray area covers the probable values within the standard deviation. Granules are shown in the upper panel and lanes in the bottom panel. |
A final experiment consists of using a hierarchical partial pooling model with granules and lanes together. The aim is to test whether or not the differences in the results found when granules and lanes are treated separately are model dependent. For this purpose, we use the same prior distribution both for granules and lanes. Figure 12 shows the marginal posteriors. The value inferred for the nickel abundance is still the same as that of previous models, namely log(ϵNi) = 6.16 ± 0.02, with a slightly smaller uncertainty. For the oxygen abundance we obtain a distribution where the mean value is between the values that we obtained for granules and lanes, namely μO = 8.80 ± 0.01 and σO = 0.03 ± 0.01.
 |
Fig. 12. Distribution of oxygen abundance (upper panel) and nickel abundance (bottom panel) for each pixel considering granules and lanes together. For the oxygen abundance, the gray horizontal line represents the hyperparameter of oxygen abundance and the gray area covers the probable values within the standard deviation, which is the other hyperparameter. For the nickel abundance, the gray horizontal line is the mean of the means of nickel abundance in each pixel and the gray area covers the probable values within the standard deviation. |
Finally, Fig. 13 shows the marginal posterior distributions for the hyperparameters of the oxygen abundance prior. The upper panels correspond to the hierarchical model of granules and lanes separately while the lower panels refer to the case in which granules and lanes are considered together. It is clear that the marginal posterior for μO for the lower panel lies somewhere between those of the upper panel. Concerning σO, it is clear that marginal posterior peaks at larger values when both granules and lanes are considered together. However, the width of the posterior seems to be similar in the two inferences.
 |
Fig. 13. Distributions of the hyperparameters for the hiearchical partial pooling model. Left panels: global oxygen abundance and the right panels the standard deviation. Top panels: granules (green) and lanes (pink) as treated separately and the bottom panels the treatment of all the pixels together. |
In summary, our currently recommended value for the oxygen abundance based on the results of this work is that from the hierarchical model in which both granules and lanes are considered together, which gives log(ϵO) = 8.80 ± 0.03. This value is compatible with the results obtained by Grevesse & Sauval (1998) and the results that we achieved in a previous work (see Cubas Armas et al. 2017). Therefore, we infer an oxygen abundance comparable with the old high-Z abundances (see e.g., Grevesse & Sauval 1998).
6. Summary and conclusions
The solar oxygen abundance remains an unresolved and problematic issue in astrophysics, not only because it is a crucial element (very important for the construction of solar interior models and because other elements are measured relative to it) but also because it is extremely difficult to measure with sufficient accuracy. Socas-Navarro (2015) found that, with very minor tweaks in the data processing, it is possible to obtain (from the same observations) a whole range of values as broad as log(ϵO) ∈ [8.7, 8.9], but this latter author did not explore the relative likelihood of all the possible outcomes. Random errors arising from uncertainties in the observations, the atomic parameters, radiative transfer, and calibration (especially wavelength grid and continuum level) are relatively straightforward to estimate. A full Bayesian treatment of these errors was provided in Cubas Armas et al. (2017).
However, the most important challenge is in finding a way to estimate the systematic errors, particularly those introduced by the (prescribed) atmosphere. Thus far, all previous determinations start from a given model atmosphere and then proceed by adjusting the abundances until an optimal fit to the observations is attained. The model is considered perfect and it is impossible to asses to what extent the uncertainties in the model affect the abundances obtained.
This work presents a novel approach, taking advantage of the fact that the solar surface is spatially resolved. We perform 40 independent inferences at different solar locations with varying thermal, dynamic, and magnetic conditions. Ideally, all 40 abundances should converge to the same value. However, imperfections in the modeling will produce a spread in the results from which both random and systematic uncertainties may be estimated. We observe such a spread at a level of 0.03 dex.
The Bayesian analysis with a hierarchical model assimilates all the available data to produce a final result of log(ϵO) = 8.80 ± 0.03, which is consistent with the results of granules and lanes taken separately (8.83 ± 0.02 and 8.76 ± 0.02, respectively). The fact that the most probable values for granules and lanes are slightly different (at the level of 2-σ) is an indication that some systematic errors may still linger in the analysis. Such systematic error might arise from the data calibration, NLTE effects in the FeI lines employed in the inversions, model uncertainties, or even from errors in the atomic parameters.
For a precise definition of the NUTS algorithm, see Neal (2012), Hoffman & Gelman (2014) and Betancourt (2017).
Acknowledgments
We acknowledge financial support from the Spanish Ministerio de Ciencia, Innovación y Universidades through project PGC2018-102108-B-I00 and FEDER funds. M.C.A. acknowledges Fundación la Caixa for the financial support received in the form of a PhD contract. We thank the anonymous referee for helpful comments and suggestions that helped improve an earlier version of the manuscript. This research has made use of NASA’s Astrophysics Data System Bibliographic Services. This work has made use of the VALD database, operated at Uppsala University, the Institute of Astronomy RAS in Moscow, and the University of Vienna. The Vacuum Tower Telescope in Tenerife is operated by the Kiepenheuer-Institut für Sonnenphysik (Germany) in the Spanish Observatorio de Izaña of the Instituto de Astrofísica de Canarias. We acknowledge the community effort devoted to the development of the open-source Python packages that were used in this work.
References
- Allende Prieto, C., Lambert, D. L., & Asplund, M. 2001, ApJ, 556, L63 [Google Scholar]
- Anders, E., & Grevesse, N. 1989, Geochim. Cosmochim. Acta, 53, 197 [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., Allende Prieto, C., & Kiselman, D. 2004, A&A, 417, 751 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Ayres, T. R. 2008, ApJ, 686, 731 [NASA ADS] [CrossRef] [Google Scholar]
- Ayres, T. R. 2012, Am. Astron. Soc. Meet. Abstr., 219, 144.08 [Google Scholar]
- Bailey, J. E., Nagayama, T., Loisel, G. P., et al. 2015, Nature, 517, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Basu, S., & Antia, H. M. 2008, Phys. Rep., 457, 217 [NASA ADS] [CrossRef] [Google Scholar]
- Betancourt, M. 2017, ArXiv e-prints [arXiv:1701.02434] [Google Scholar]
- Borrero, J. M. 2008, ApJ, 673, 470 [NASA ADS] [CrossRef] [Google Scholar]
- Caffau, E., Ludwig, H.-G., Steffen, M., et al. 2008, A&A, 488, 1031 [CrossRef] [EDP Sciences] [Google Scholar]
- Caffau, E., Ludwig, H. G., Bonifacio, P., et al. 2010, A&A, 514, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caffau, E., Ludwig, H.-G., Steffen, M., Freytag, B., & Bonifacio, P. 2011, Sol. Phys., 268, 255 [NASA ADS] [CrossRef] [Google Scholar]
- Caffau, E., Ludwig, H. G., Malherbe, J. M., et al. 2013, A&A, 554, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Christensen-Dalsgaard, J., di Mauro, M. P., Houdek, G., & Pijpers, F. 2009, A&A, 494, 205 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cubas Armas, M., Asensio Ramos, A., & Socas-Navarro, H. 2017, A&A, 600, A45 [CrossRef] [EDP Sciences] [Google Scholar]
- Ecuvillon, A., Israelian, G., Santos, N. C., et al. 2006, A&A, 445, 633 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fabbian, D., & Moreno-Insertis, F. 2015, ApJ, 802, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Freytag, B., Steffen, M., Ludwig, H. G., et al. 2012, J. Comput. Phys., 231, 919 [Google Scholar]
- Gray, D. F. 1976, The Observation and Analysis of Stellar Photospheres (Cambridge: Cambridge University Press) [Google Scholar]
- Gregory, P. C. 2005, Bayesian Logical Data Analysis for the Physical Sciences (Cambridge: Cambridge University Press) [Google Scholar]
- Grevesse, N., & Sauval, A. J. 1998, Space Sci. Rev., 85, 161 [Google Scholar]
- Haxton, W. C., & Serenelli, A. M. 2008, ApJ, 687, 678 [CrossRef] [Google Scholar]
- Hoffman, M. D., & Gelman, A. 2014, ArXiv e-prints [arXiv:1111.4246] [Google Scholar]
- Johansson, S., Litzén, U., Lundberg, H., & Zhang, Z. 2003, ApJ, 584, L107 [NASA ADS] [CrossRef] [Google Scholar]
- Neal, R. M. 2012, ArXiv e-prints [arXiv:1206.1901] [Google Scholar]
- Neckel, H. 1999, Sol. Phys., 184, 421 [NASA ADS] [CrossRef] [Google Scholar]
- O’Hagan, A. 2006, Reliab. Eng. Syst. Saf., 91, 1290 [CrossRef] [Google Scholar]
- Salvatier, J., Wiecki, T., & Fonnesbeck, C. 2016, PeerJ Comput. Sci., 2, e55 [Google Scholar]
- Scherrer, P. H., Schou, J., Bush, R. I., et al. 2012, Sol. Phys., 275, 207 [Google Scholar]
- Schroeter, E. H., Soltau, D., & Wiehr, E. 1985, Vist. Astron., 28, 519 [NASA ADS] [CrossRef] [Google Scholar]
- Scott, P. C., Asplund, M., Grevesse, N., & Sauval, A. J. 2006, A&A, 456, 675 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scott, P., Asplund, M., Grevesse, N., & Sauval, A. J. 2009, ApJ, 691, L119 [NASA ADS] [CrossRef] [Google Scholar]
- Socas-Navarro, H. 2015, A&A, 577, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Socas-Navarro, H., de la Cruz Rodríguez, J., Asensio Ramos, A., Trujillo Bueno, J., & Ruiz Cobo, B. 2015, A&A, 577, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soltau, D., Berkefeld, T., von der Lühe, O., Wöger, F., & Schelenz, T. 2002, Astron. Nachr., 323, 236 [NASA ADS] [CrossRef] [Google Scholar]
- Storey, P. J., & Zeippen, C. J. 2000, MNRAS, 312, 813 [Google Scholar]
- von der Lühe, O. 1998, New Astron. Rev., 42, 493 [Google Scholar]
- von der Lühe, O., Soltau, D., Berkefeld, T., & Schelenz, T. 2003, in Innovative Telescopes and Instrumentation for Solar Astrophysics, eds. S. L. Keil, & S. V. Avakyan, SPIE Conf. Ser., 4853, 187 [NASA ADS] [CrossRef] [Google Scholar]
- von Steiger, R., & Zurbuchen, T. H. 2016, ApJ, 816, 13 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Posterior predictive checks for the partial pooling models
Here we show the posterior predictive checks, in which the synthetic [O I] line is obtained from different samples from the posterior in the hierarchical partial pooling models; Figure A.1 for the granules, and Fig. A.2 for the lanes. Finally, Fig. A.3 is for the hierarchical partial pooling model considering the granules and the lanes together.
 |
Fig. A.3. Same as Figs. A.1 and A.2 but considering the granules and the lanes together in the Bayesian inference. |
All Tables
Prior selected for each parameter of the Bayesian analysis using a hierarchical partial pooling model.
All Figures
|
Fig. 1. Continuum context image of active region AR12565 on July 15, 2016. Image from the HMI instrument onboard SDO (Scherrer et al. 2012). Our observations are represented by the solid rectangle in the image. The area under the dashed line corresponds to the data employed in this work. |
| In the text | |
|
Fig. 2. Left: continuum map, marking the position of the pixels considered for this study: granules in green and intergranular lanes in pink (40 pixels in total). As standard practice, these pixels were selected for their continuum brightness, choosing the brightest and darkest points in the FOV. Right: average spectrum in the FOV shows the lines of interest in our work. |
| In the text | |
|
Fig. 3. Temperature stratification of each inferred model. The optical depth scale is measured at 5000 Å. |
| In the text | |
|
Fig. 4. Inversions of two spatial pixels. Upper panel: spectral profile of a granule (black) and fit (green). Lower panel: spectral profile of an intergranular lane (black) and fit (pink). Ic is the average quiet Sun continuum intensity. |
| In the text | |
|
Fig. 5. Representation of the parameters for the unpooled model (upper panel) and the hierarchical partial pooling model (bottom panel). For each pixel, we have four parameters that contribute to the shape of the synthetic intensity profile. In addition to those parameters, in the hieararchical partial pooling model, we have two hyperparameters, the mean value and the standard deviation of the Gaussian, which represent the global oxygen distribution. The parameter s accounts for the uncertainties of our model. |
| In the text | |
|
Fig. 6. Observed (black) and synthetic (green) profiles using values extracted from the posterior for the granules in the unpooled model. The continuum taken to normalize the intensity is the mean continuum between granules and lanes pixels. |
| In the text | |
|
Fig. 7. Observed (black) and synthetic (pink) profiles using values extracted from the posterior for the lanes in the unpooled model. The continuum taken to normalize the intensity is the mean continuum between granules and lanes pixels. |
| In the text | |
|
Fig. 8. Distribution of oxygen abundance for each pixel. Granules are shown in the upper panel and lanes in the bottom panel. The gray horizontal line represents the mean of the means of each pixel and the gray area represents the standard deviation. The horizontal line inside each color box represents the median value of the marginal posterior distribution, and the color box covers the range encompassing 50% of the probability. |
| In the text | |
|
Fig. 9. Distribution of nickel abundances for each pixel. The gray horizontal line represents the mean of the means of each pixel and the gray area represents the standard deviation. Granules are shown in the upper panel and lanes in the bottom panel. |
| In the text | |
|
Fig. 10. Distribution of oxygen abundance for each pixel. The gray horizontal line represents the hyperparameter of oxygen abundance and the gray area covers the probable values within the standard deviation, which is the other hyperparameter. Granules are shown in the upper panel and lanes in the bottom panel. |
| In the text | |
|
Fig. 11. Distribution of nickel abundance for each pixel. The gray horizontal line represents the mean value of the mean values for the nickel abundance in each pixel and the gray area covers the probable values within the standard deviation. Granules are shown in the upper panel and lanes in the bottom panel. |
| In the text | |
|
Fig. 12. Distribution of oxygen abundance (upper panel) and nickel abundance (bottom panel) for each pixel considering granules and lanes together. For the oxygen abundance, the gray horizontal line represents the hyperparameter of oxygen abundance and the gray area covers the probable values within the standard deviation, which is the other hyperparameter. For the nickel abundance, the gray horizontal line is the mean of the means of nickel abundance in each pixel and the gray area covers the probable values within the standard deviation. |
| In the text | |
|
Fig. 13. Distributions of the hyperparameters for the hiearchical partial pooling model. Left panels: global oxygen abundance and the right panels the standard deviation. Top panels: granules (green) and lanes (pink) as treated separately and the bottom panels the treatment of all the pixels together. |
| In the text | |
 |
Fig. A.1. Same as Fig. 6 but for the hierarchical partial pooling model. |
| In the text | |
 |
Fig. A.2. Same as Fig. 7 but for the hierarchical partial pooling model. |
| In the text | |
|
Fig. A.3. Same as Figs. A.1 and A.2 but considering the granules and the lanes together in the Bayesian inference. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.