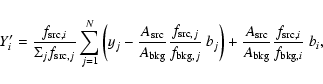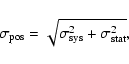A&A 493, 339-373 (2009)
DOI: 10.1051/0004-6361:200810534
M. G. Watson1 - A. C. Schröder1 - D. Fyfe1 - C. G. Page1 - G. Lamer2 - S. Mateos1 - J. Pye1 - M. Sakano1 - S. Rosen1 - J. Ballet3 - X. Barcons4 - D. Barret5 - T. Boller6 - H. Brunner6 - M. Brusa6 - A. Caccianiga7 - F. J. Carrera4 - M. Ceballos4 - R. Della Ceca7 - M. Denby1 - G. Denkinson1 - S. Dupuy5 - S. Farrell5 - F. Fraschetti3 - M. J. Freyberg6 - P. Guillout9 - V. Hambaryan2,16 - T. Maccacaro15 - B. Mathiesen3 - R. McMahon8 - L. Michel9 - C. Motch9 - J. P. Osborne1 - M. Page10 - M. W. Pakull9 - W. Pietsch6 - R. Saxton11 - A. Schwope2 - P. Severgnini7 - M. Simpson1 - G. Sironi1,7 - G. Stewart1 - I. M. Stewart1,13 - A.-M. Stobbart1 - J. Tedds1 - R. Warwick1 - N. Webb5 - R. West1 - D. Worrall12 - W. Yuan8,14
1 - Department of Physics & Astronomy, University of Leicester, Leicester, LE1 7RH, UK
2 -
Astrophysikalisches Institut Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
3 -
AIM, DSM/IRFU/SAp, CEA Saclay, 91191 Gif-sur-Yvette, France
4 -
Instituto de Fisica de Cantabria (CSIC-UC), Avenida de los Castros, 39005 Santander, Spain
5 -
CNRS, Université Paul Sabatier & Observatoire Midi-Pyrénées, 9 avenue du Colonel Roche, 31400 Toulouse, France
6 -
Max-Planck-Institut für Extraterrestrische Physik,
Giessenbachstraße 1, 85748 Garching, Germany
7 -
INAF - Osservatorio Astronomico di Brera, via Brera 28, 20121 Milan, Italy
8 -
Institute of Astronomy, Madingley Road,
Cambridge CB3 0HA, UK
9 -
Observatoire Astronomique, UMR 7550 CNRS, Université Louis Pasteur, 11 rue de l'Université, 67000 Strasbourg, France
10 -
Mullard Space Science Laboratory, University College London, Holmbury St. Mary, Dorking, Surrey RH5 6NT, UK
11 -
ESA/ESAC, Apartado 78, 28691 Villanueva de la Cañada, Madrid, Spain
12 -
H.H. Wills Physics Laboratory, University of Bristol, Tyndall Avenue, Bristol BS8 1TL, UK
13 -
Jodrell Bank Centre for Astrophysics, University of Manchester, Oxford Road, Manchester M13 9PL, UK
14 -
National Astronomical Observatories of China/Yunnan Observatory, Phoenix Hill, PO Box 110, Kunming, Yunnan, PR China
15 -
INAF - Headquarters, via del Parco Mellini 84, 00136 Rome, Italy
16 -
Astrophysikalisches Institut und Universitäts-Sternwarte, Friedrich-Schiller-Universität Jena,
Schillergässchen 3, 07745 Jena, Germany
Received 7 July 2008 / Accepted 14 October 2008
Abstract
Aims. Pointed observations with XMM-Newton provide the basis for creating catalogues of X-ray sources detected serendipitously in each field. This paper describes the creation and characteristics of the 2XMM catalogue.
Methods. The 2XMM catalogue has been compiled from a new processing of the XMM-Newton EPIC camera data. The main features of the processing pipeline are described in detail.
Results. The catalogue, the largest ever made at X-ray wavelengths, contains 246 897 detections drawn from 3491 public XMM-Newton observations over a 7-year interval, which relate to 191 870 unique sources. The catalogue fields cover a sky area of more than 500 deg2. The non-overlapping sky area is ![]() 360 deg2 (
360 deg2 (![]() 1% of the sky) as many regions of the sky are observed more than once by XMM-Newton. The catalogue probes a large sky area at the flux limit where the bulk of the objects that contribute to the X-ray background lie and provides a major resource for generating large, well-defined X-ray selected source samples, studying the X-ray source population and identifying rare object types. The main characteristics of the catalogue are presented, including its photometric and astrometric properties
1% of the sky) as many regions of the sky are observed more than once by XMM-Newton. The catalogue probes a large sky area at the flux limit where the bulk of the objects that contribute to the X-ray background lie and provides a major resource for generating large, well-defined X-ray selected source samples, studying the X-ray source population and identifying rare object types. The main characteristics of the catalogue are presented, including its photometric and astrometric properties
Key words: X-rays: general - catalogs - surveys
Surveys play a key role in X-ray astronomy, as they do in other wavebands, providing the basic observational data for characterising the underlying source populations. Serendipitous X-ray sky surveys, based on the field data from individual pointed observations, take advantage of the relatively wide field of view afforded by typical X-ray instrumentation. Such surveys have been pursued with most X-ray astronomy satellites since the Einstein Observatory. The resulting serendipitous source catalogues (e.g., EMSS: Gioia et al. 1990; Stocke et al. 1991; WGACAT: White et al. 1994; ROSAT 2RXP: Voges et al. 1999; ROSAT 1RXH: ROSAT Team 2000; ASCA AMSS: Ueda et al. 2005) have been the basis for numerous studies and have made a significant contribution to our knowledge of the X-ray sky and our understanding of the nature of the various Galactic and extragalactic source populations.
The XMM-Newton observatory provides unrivalled capabilities for
serendipitous X-ray surveys by virtue of the large field of view of the
EPIC cameras and the high throughput afforded by the heavily nested
telescope modules. This capability guarantees that each XMM-Newton
observation provides a significant harvest of serendipitous X-ray sources
in addition to data on the original target. In addition, the extended
energy range of XMM-Newton (![]() 0.2-12 keV) means that XMM-Newton
detects significant numbers of obscured and hard-spectrum objects that are
absent in many earlier soft X-ray surveys.
0.2-12 keV) means that XMM-Newton
detects significant numbers of obscured and hard-spectrum objects that are
absent in many earlier soft X-ray surveys.
This paper describes the Second XMM-Newton Serendipitous Source Catalogue
(2XMM) which has been created from the serendipitous EPIC data from from
3491 XMM-Newton pointed observations made over a ![]() 7-year interval
since launch in 1999. The XMM-Newton serendipitous source catalogues are
produced by the XMM-Newton Survey Science Centre (SSC), an international
consortium of ten European institutions, led by the University of
Leicester, as a formal project activity performed on behalf of ESA. The
catalogues are based on the EPIC source lists produced by the scientific
pipe-line used by the SSC for the processing of all the XMM-Newton data.
The first serendipitous source catalogue, 1XMM, was released in 2003
(Watson et al. 2003; XMM-SSC 2003). The current 2XMM catalogue
incorporates a wide range of improvements to the data processing, uses the
most up-to-date instrument calibrations and includes a large number of new
parameters. In parallel, the 2XMM catalogue processing also produces a
number of additional data products, for example time-series and spectra for
the brighter individual X-ray sources. A pre-release version of the current
catalogue, 2XMMp (XMM-SSC 2006), was made public in 2006. This included
7-year interval
since launch in 1999. The XMM-Newton serendipitous source catalogues are
produced by the XMM-Newton Survey Science Centre (SSC), an international
consortium of ten European institutions, led by the University of
Leicester, as a formal project activity performed on behalf of ESA. The
catalogues are based on the EPIC source lists produced by the scientific
pipe-line used by the SSC for the processing of all the XMM-Newton data.
The first serendipitous source catalogue, 1XMM, was released in 2003
(Watson et al. 2003; XMM-SSC 2003). The current 2XMM catalogue
incorporates a wide range of improvements to the data processing, uses the
most up-to-date instrument calibrations and includes a large number of new
parameters. In parallel, the 2XMM catalogue processing also produces a
number of additional data products, for example time-series and spectra for
the brighter individual X-ray sources. A pre-release version of the current
catalogue, 2XMMp (XMM-SSC 2006), was made public in 2006. This included
![]() 65% of the fields and
65% of the fields and ![]() 75% of the sky area covered by
2XMM, while
75% of the sky area covered by
2XMM, while ![]() 88% of all 2XMMp sources appear in the 2XMM catalogue.
Around 56% of all 2XMM sources already have an entry in the 2XMMp
catalogue.
88% of all 2XMMp sources appear in the 2XMM catalogue.
Around 56% of all 2XMM sources already have an entry in the 2XMMp
catalogue.
The 2XMM catalogue provides an unsurpassed sky area for serendipitous science and reaches a flux limit corresponding to the dominant extragalactic source contribution to the cosmic X-ray background. The catalogue is part of a wider project to explore the source populations in the XMM-Newton serendipitous survey (the XID project; Watson et al. 2001, 2003) through optical identification of well-defined samples of serendipitous sources (e.g., Barcons et al. 2002, 2007; Della Ceca et al. 2004; Caccianiga et al. 2008; Motch et al. 2002; Schwope et al. 2004; Page et al. 2007; Yuan et al. 2003; Dietrich et al. 2006). Indeed these identification programs were effectively based on less mature versions of the XMM-Newton catalogue data processing. XMM-Newton serendipitous survey results have also been used to study various statistical properties of the populations such as X-ray spectral characteristics, source counts, angular clustering, and luminosity functions (Severgnini et al. 2003; Mateos et al. 2005; Carrera et al. 2007; Caccianiga et al. 2007; Mateos et al. 2008; Della Ceca et al. 2008; Ebrero et al. 2008). Other projects based on XMM-Newton serendipitous data include the HELLAS2XMM survey (Baldi et al. 2002; Cocchia et al. 2007).
The 2XMM serendipitous catalogue described here is complementary to
``planned'' XMM-Newton surveys which provide coverage of much smaller sky
areas, but often with higher sensitivity, thus exploring the fainter end of
the X-ray source population. The deepest such surveys, such as the Lockman
Hole (Hasinger et al. 2001; Brunner et al. 2008) and the CDF-S
(Streblyanska et al. 2004), cover essentially only a single XMM-Newton
field of view, have total integration times ![]() 300-1000 ks and reach
fluxes
300-1000 ks and reach
fluxes ![]() few
few
![]() ,
close to the
confusion limit. XMM-Newton has also carried out contiguous surveys of
various depths covering much larger sky areas utilising mosaics
of overlapping pointed observations to achieve the required sensitivity and
sky coverage. Currently the largest contiguous XMM-Newton survey is the
XMM-LSS (Pierre et al. 2007) covering
,
close to the
confusion limit. XMM-Newton has also carried out contiguous surveys of
various depths covering much larger sky areas utilising mosaics
of overlapping pointed observations to achieve the required sensitivity and
sky coverage. Currently the largest contiguous XMM-Newton survey is the
XMM-LSS (Pierre et al. 2007) covering ![]() 5 deg2 with typical
exposure time 10-20 ks per observation. Other medium-deep surveys of
1-2 deg2 regions include the SXDS (
5 deg2 with typical
exposure time 10-20 ks per observation. Other medium-deep surveys of
1-2 deg2 regions include the SXDS (![]() 1.1 deg2,
50-100 ks exposures; Ueda et al. 2008), the COSMOS surveys
(
1.1 deg2,
50-100 ks exposures; Ueda et al. 2008), the COSMOS surveys
(![]() 2 deg2,
2 deg2, ![]() 80 ks exposures; e.g., Cappelluti et al. 2007; Hasinger et al. 2007), and the Marano field survey (Krumpe et al. 2007). These larger area surveys typically reach limiting fluxes of 10-14 to <
80 ks exposures; e.g., Cappelluti et al. 2007; Hasinger et al. 2007), and the Marano field survey (Krumpe et al. 2007). These larger area surveys typically reach limiting fluxes of 10-14 to <
![]() .
.
We also note that Chandra observations have been used to compile a
serendipitous catalogue including ![]() 7000 point sources (the ChaMP
catalogue; Kim et al. 2007) and plans are underway to compile a
serendipitous catalogue from all suitable Chandra observations (Fabbiano et al. 2007).
7000 point sources (the ChaMP
catalogue; Kim et al. 2007) and plans are underway to compile a
serendipitous catalogue from all suitable Chandra observations (Fabbiano et al. 2007).
The paper is organised as follows. Section 2 introduces the XMM-Newton observatory. Section 3 presents the XMM-Newton observations used to create the catalogue and the characteristics of the fields. Section 4 outlines the XMM-Newton data processing framework and provides a more detailed account of the EPIC data processing, focusing in particular on source detection and parameterisation, astrometric corrections and flux computation. Section 5 provides an account of the automatic extraction of time-series and spectra for the brighter sources, while Sect. 6 outlines the external catalogue cross-correlation undertaken. Section 7 describes the quality evaluation undertaken and some recommendations on how to extract useful sub-samples from the catalogue. Section 8 describes additional processing and other steps taken to compile the catalogue including the identification of unique sources. The main properties and characterisation of the catalogue is presented in Sect. 9. Section 10 summarises access to the catalogue and plans for future updates to 2XMM, and Sect. 11 gives a summary.
To provide the essential context for this paper, the main features of the XMM-Newton observatory are summarised here, with particular emphasis on the EPIC X-ray cameras from which the catalogue is derived.
The XMM-Newton observatory (Jansen et al. 2001), launched in December 1999,
carries three co-aligned grazing-incidence X-ray telescopes, each
comprising 58 nested Wolter-I mirror shells with a focal length of
7.5 m. One of these telescopes focuses X-rays directly on to an EPIC
(European Photon Imaging Camera) pn CCD imaging camera (Strüder et al. 2001). The other two feed two EPIC MOS CCD imaging cameras (Turner et al. 2001) but in these telescopes about half the X-rays are diverted, by
reflection grating arrays (RGA), to the reflection grating spectrometers
(RGS; den Herder et al. 2001) which provide high resolution
(
![]() )
X-ray spectroscopy in the
0.33-2.5 keV range. The EPIC cameras acquire data in the
0.1-15 keV range with a field of view (FOV)
)
X-ray spectroscopy in the
0.33-2.5 keV range. The EPIC cameras acquire data in the
0.1-15 keV range with a field of view (FOV) ![]() 30 arcmin
diameter and an on-axis spatial resolution
30 arcmin
diameter and an on-axis spatial resolution ![]() 5 arcsec FWHM (MOS
being slightly better than pn). The physical pixel sizes for the pn and MOS
cameras is equivalent to
5 arcsec FWHM (MOS
being slightly better than pn). The physical pixel sizes for the pn and MOS
cameras is equivalent to ![]() 1 and
1 and ![]() 4 arcsec,
respectively. The on-axis effective area for the pn camera is approximately 1400 cm2 at 1.5 keV and 600 cm2 at 8 keV while corresponding
MOS effective areas are about 550 cm2 and 100 cm2,
respectively. The energy resolution for the pn camera is
4 arcsec,
respectively. The on-axis effective area for the pn camera is approximately 1400 cm2 at 1.5 keV and 600 cm2 at 8 keV while corresponding
MOS effective areas are about 550 cm2 and 100 cm2,
respectively. The energy resolution for the pn camera is ![]() 120 eV at
1.5 keV and
120 eV at
1.5 keV and ![]() 160 eV at 6 keV (FWHM), while for the MOS camera it
is
160 eV at 6 keV (FWHM), while for the MOS camera it
is ![]() 90 eV and
90 eV and ![]() 135 eV, respectively. The EPIC cameras can
be used in a variety of different modes and with several filters (see
Sect. 3.1). In addition to the X-ray telescopes, XMM-Newton
carries a co-aligned, 30 cm diameter Optical Monitor (OM) telescope (Mason
et al. 2001) which provides an imaging capability in three broad-band
ultra-violet filters and three optical filters, spanning 1800 Å to
6000 Å; two additional grism filters permit low dispersion ultra-violet
and optical-band spectroscopy. The construction of a separate catalogue of
OM sources is in preparation.
135 eV, respectively. The EPIC cameras can
be used in a variety of different modes and with several filters (see
Sect. 3.1). In addition to the X-ray telescopes, XMM-Newton
carries a co-aligned, 30 cm diameter Optical Monitor (OM) telescope (Mason
et al. 2001) which provides an imaging capability in three broad-band
ultra-violet filters and three optical filters, spanning 1800 Å to
6000 Å; two additional grism filters permit low dispersion ultra-violet
and optical-band spectroscopy. The construction of a separate catalogue of
OM sources is in preparation.
A number of specific features of XMM-Newton and the EPIC cameras which are referred to repeatedly in this paper are collected together and summarised in Appendix A together with the relevant nomenclature.
XMM-Newton observations![]() were selected for inclusion in
the 2XMM catalogue pipeline simply on the basis of their public
availability and their suitability for serendipitous science. In practice
this meant that all observations that had a public release date prior to
2007 May 01 were eligible. A total of 3491 XMM-Newton observations (listed
in Appendix B) were included in the catalogue; their sky
distribution is shown in Fig. 1. Only a few observations (83)
were omitted, typically because a valid ODF
were selected for inclusion in
the 2XMM catalogue pipeline simply on the basis of their public
availability and their suitability for serendipitous science. In practice
this meant that all observations that had a public release date prior to
2007 May 01 were eligible. A total of 3491 XMM-Newton observations (listed
in Appendix B) were included in the catalogue; their sky
distribution is shown in Fig. 1. Only a few observations (83)
were omitted, typically because a valid ODF![]() was not available or because
of a few unresolved processing problems. The field of view (FOV) of an
XMM-Newton observation (the three EPIC cameras combined) has a radius
was not available or because
of a few unresolved processing problems. The field of view (FOV) of an
XMM-Newton observation (the three EPIC cameras combined) has a radius
![]() 15 arcmin. The XMM-Newton observations selected for the 2XMM
catalogue cover only
15 arcmin. The XMM-Newton observations selected for the 2XMM
catalogue cover only ![]() 1% of the sky (see Sect. 9.2 for a
more detailed discussion). Certain sky regions have contiguous multi-FOV
spatial coverage, but the largest such region is currently <10 deg2.
1% of the sky (see Sect. 9.2 for a
more detailed discussion). Certain sky regions have contiguous multi-FOV
spatial coverage, but the largest such region is currently <10 deg2.
| |
Figure 1: Hammer-Aitoff equal area projection in Galactic coordinates of the 3491 2XMM fields. |
| Open with DEXTER | |
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{10534f2.ps}\end{figure}](/articles/aa/full/2009/01/aa10534-08/img25.gif) |
Figure 2: Distribution of total good exposure time (after event filtering) for the observations included in the 2XMM catalogue (for each observation the maximum time of all three cameras per observation was used). |
| Open with DEXTER | |
By definition the catalogue observations do not form a homogeneous set of
data. The observations selected have, for example, a wide sky distribution
(see Fig. 1, where ![]() 65% are at Galactic latitude
65% are at Galactic latitude
![]() ), a broad range of integration times (Fig. 2) and
astrophysical content (Sect. 3.2), as well as a mixture of
EPIC observing modes and filters, as follows.
), a broad range of integration times (Fig. 2) and
astrophysical content (Sect. 3.2), as well as a mixture of
EPIC observing modes and filters, as follows.
The EPIC cameras are operated in several modes of data acquisition. In full-frame and extended full-frame modes the full detector area is exposed, while for the EPIC pn large window mode only half of the detector is read out. A single CCD is used for small window, timing and burst mode (not used for source detection). In the case of MOS the outer ring of 6 CCDs always remain in standard imaging mode while the central MOS CCD can be operated separately: in partial window modes only part of the central CCD is read out, and in fast uncompressed and compressed modes the central CCD is in timing mode and produces no imaging data. In the MOS refreshed frame store mode the central CCD has a different frame time and the CCD is not used for source detection. Table 1 lists all the EPIC camera modes of observations incorporated in the catalogue, while Fig. 3 shows their sky footprints.
Table 1: Data modes of XMM-Newton exposures included in the 2XMM catalogue.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{10534f3.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img27.gif) |
Figure 3:
Typical sky footprints of the different observing modes (the FOV
is |
| Open with DEXTER | |
Each XMM-Newton camera can be used with a different filter: Thick, Medium,
Thin, and Open, the choice depending on the degree of optical blocking![]() desired. Table 2 gives an overview of the data modes and
filter settings used for the 2XMM observations. No Open
filter exposures passed the
selection criteria (cf. Sect. 4.1), while about
20% of pn observations are taken in timing, burst, or small window mode.
desired. Table 2 gives an overview of the data modes and
filter settings used for the 2XMM observations. No Open
filter exposures passed the
selection criteria (cf. Sect. 4.1), while about
20% of pn observations are taken in timing, burst, or small window mode.
Table 2: Characteristics of the 3491 XMM-Newton observations included in the 2XMM catalogue.
The 2XMM catalogue is intended to be a catalogue of serendipitous sources. The observations from which it has been compiled, however, are pointed observations which typically contain one or more target objects chosen by the original observers, so the catalogue contains a small fraction of targets which are by definition not serendipitous. More generally, the fields from which the 2XMM catalogue is compiled may also not be representative of the overall X-ray sky.
To avoid potential selection bias in the use of the catalogue, an analysis to identify the target or targets of each XMM-Newton observation has been carried out. Additionally, an attempt has been made to classify each target or the nature of the field observed; this provides additional information which can be important in characterising their usefulness (or otherwise) for serendipitous science. In practice the task of identifying and classifying the observation target is to some extent subjective and likely to be incomplete (only the investigators of that observation know all the details). Here, the main results of the exercise are summarised. A more detailed description is given in Appendix C.
| |
Figure 4: a) Examples of typical 2XMM EPIC images (north is up). From left to right: (i) medium bright point source; (ii) deep field observation; (iii) shallow field observation with small extended sources; (iv) distant galaxy cluster. |
| Open with DEXTER | |
![\begin{figure}
\addtocounter{figure}{-1}
\par\includegraphics[width=17.5cm,clip]{10534f4b.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img31.gif) |
Figure 4: b) Examples of variation in astrophysical content of 2XMM observations ( north is up); in most of these extreme cases the source detection is problematic. Top row, from left to right: (i) bright extended emission from a galaxy cluster; (ii) emission from a spiral galaxy which includes point sources and extended emission; (iii) very bright extended emission from a SNR; (iv) filamentary diffuse emission. Second row: (v) complex field near the Galactic Centre with diffuse and compact extended emission; (vi) two medium-sized galaxy clusters; (vii) complex field of a star cluster; (viii) bright point source, off-centre. |
| Open with DEXTER | |
| |
Figure 4: c) Examples of instrumental artefacts causing spurious source detection ( north is up). From left to right: (i) bright source with pileup and OOT events; (ii) very bright point source showing obvious pileup, shadows from the mirror spider, and scattered light from the RGA; (iii) the PSF wings of a bright source spread beyond the unused central CCD causing a brightening of the edges on the surrounding CCDs (which may not be well represented in the background map); (iv) obvious noisy CCDs for MOS1 (CCD#4) and for MOS2 (CCD#5) to the top right; (v) numerous and bright single reflections from a bright point source outside the FOV, with a star cluster to the left. See Appendix A for terminology. |
| Open with DEXTER | |
The SSC operates a data-processing system on behalf of ESA for the
processing of XMM-Newton pointed observations. The system, which can be
considered as a ``pipeline'', uses the XMM-Newton Science Analysis Software
(SAS![]() ) to generate high-level
science products from ODFs. These science products are made available to
the principal investigator and ultimately the astronomy community through
the XMM Science Archive (XSA; Arviset et al. 2007). In October 2006, the
SSC began to reprocess every available pointed-observation data-set from
the start of the mission. The aim was to create a uniform set of science
products using an up-to-date SAS and a constant set of XMM-Newton
calibration files
) to generate high-level
science products from ODFs. These science products are made available to
the principal investigator and ultimately the astronomy community through
the XMM Science Archive (XSA; Arviset et al. 2007). In October 2006, the
SSC began to reprocess every available pointed-observation data-set from
the start of the mission. The aim was to create a uniform set of science
products using an up-to-date SAS and a constant set of XMM-Newton
calibration files![]() (the appropriate subset of
calibration files for any given observation was selected based on the
observation date). Of 5628 available observations, 5484 were successfully
processed. These included public as well as (at that time) proprietary
datasets (the data selection for 2XMM observations is discussed in
Sect. 3.1). The complete results of the processing have been made
available through the XSA. The new system incorporated significant
processing improvements in terms of the quality and number of products, as
described below. The remainder of this section details those aspects of the EPIC processing
system which are pertinent to the creation of the 2XMM catalogue.
(the appropriate subset of
calibration files for any given observation was selected based on the
observation date). Of 5628 available observations, 5484 were successfully
processed. These included public as well as (at that time) proprietary
datasets (the data selection for 2XMM observations is discussed in
Sect. 3.1). The complete results of the processing have been made
available through the XSA. The new system incorporated significant
processing improvements in terms of the quality and number of products, as
described below. The remainder of this section details those aspects of the EPIC processing
system which are pertinent to the creation of the 2XMM catalogue.
The main steps in the data-processing sequence are: production of calibrated detector events from the ODF science frames; identification of the appropriate low-background time intervals using a threshold optimised for point-source detection; identification of ``useful'' exposures (taking account of exposure time, instrument mode, etc.); generation of multi-energy-band X-ray images and exposure maps from the calibrated events; source detection and parameterisation; cross-correlation of the source list with a variety of archival catalogues, image databases and other archival resources; creation of binned data products; application of automatic and visual screening procedures to check for any problems in the data products. This description and the schematic flowchart in Fig. 5 provide a rather simplified view of the actual data-processing system. They, and the further detail that follows, are focused on those aspects that are important for an insight into the analysis processes that the EPIC data have undergone to generate the data products. A complete description of the data-processing system and its implementation are outside the scope of this paper.
![\begin{figure}
\par\includegraphics[width=7.5cm,clip]{10534f5.eps}\end{figure}](/articles/aa/full/2009/01/aa10534-08/img33.gif) |
Figure 5: A simplified schematic of the processing flow for EPIC image data. Early processing steps treat the data from each instrument and exposure separately. Source detection and parameterisation are performed simultaneously on one image from each energy band from each instrument. Source-specific products can be made, subsequently, from any suitable exposures in the observation. Observation-level, exposure-level and source-specific products are screened before archiving and use in making the catalogue. |
| Open with DEXTER | |
The criteria employed to select exposures for initial processing and those to be used for subsequent source detection and source-product generation are explained further in Sect. 4.1 but are briefly introduced here. Several suitability tests were applied during processing to limit source detection and source-specific product creation to imaging exposures of suitable quality, mainly by (a) restricting the merging of exposures (and hence source detection) to imaging exposures with a minimum of good-quality exposure time, and (b) limiting the extraction of source-specific products to suitably bright sources.
Most XMM-Newton observations comprise a single exposure with each of the cameras, although a significant number of observations are missing exposures in one or more of the three cameras for a variety of operational and observational reasons. To avoid generating data products of little or no scientific use, exposures for each observation were initially selected for pipeline processing when:
Event-list processing was performed on all initially selected exposures. A number of checks and corrections were applied to the event lists of the individual CCDs before they were merged into a single event list per exposure. Once merged, a further set of checks and corrections was performed. At each stage of the processing, a quality assessment of the event lists decided whether to continue the processing. The main steps in processing the event lists were as follows.
Table 3: Energy bands used in 2XMM processing.
Periods of high background (mostly due to so-called ``soft proton'' flares) can significantly reduce the sensitivity of source detection. Since events caused by such flares are usually much harder than events arising from typical X-ray sources, background variation can be disentangled from possible time variation of the sources in the field by monitoring events at energies higher than the 12 keV upper boundary to the ``science band'', beyond which point contributions from cosmic X-ray sources are rarely significant. A time series of such events, including most of the FOV, was constructed for each exposure. This event rate was used as a proxy for the science-band background rate.
The generation of the background time-series differed in detail between pn and MOS cameras, in particular in terms of the events used to form the time-series. The MOS high-energy background time-series were produced from single-pixel events with energies above 14 keV from the imaging CCDs. The background GTIs were taken to be those time intervals of more than 100 s in duration with a count rate of less than 2 ct ks-1 arcmin-2. The pn high-energy background time-series were produced in the 7.0-15 keV energy range. The background GTIs were taken to be those time intervals of more than 100 s in duration with a count rate of less than 10 ct ks-1 arcmin-2.
These threshold count rates were chosen as a good compromise
between reducing background and preserving exposure for detecting point
sources in the relatively short exposures which make up the bulk of the
XMM-Newton observations. For comparison, the average quiet level in the MOS cameras,
for example, is ![]() 0.5 ct ks-1 arcmin-2.
0.5 ct ks-1 arcmin-2.
For all exposures in imaging mode, images were created for energy bands
1-5, as listed in Table 3, from selected events
filtered by event-list, attitude, and high background GTIs (except where
the sum of all high background GTIs was less than 1000 s in which
case no background filtering was applied). Note that the event-list GTIs
are CCD dependent and the resulting image can have a different exposure
time in each CCD. The events for pn images were selected by pattern ![]() 4(for band 1 a stricter requirement of pattern = 0 was adopted) and a cut in
CCD coordinates (Y > 12) to reduce bright low-energy edges. Events on CCD
columns suffering a particularly large energy scale offset as well as
events outside the FOV were excluded. For MOS images events with pattern
4(for band 1 a stricter requirement of pattern = 0 was adopted) and a cut in
CCD coordinates (Y > 12) to reduce bright low-energy edges. Events on CCD
columns suffering a particularly large energy scale offset as well as
events outside the FOV were excluded. For MOS images events with pattern
![]() 12 were selected and events outside the FOV were excluded. The images
are tangent-plane projections of celestial coordinates and have dimensions
of
12 were selected and events outside the FOV were excluded. The images
are tangent-plane projections of celestial coordinates and have dimensions
of
![]() image pixels, with a pixel size of
image pixels, with a pixel size of
![]() .
.
Exposure maps represent the GTI-filtered on-time multiplied by the (spatially dependent) vignetting function, adjusted to reflect telescope and instrumental throughput efficiency. They were created for each EPIC exposure in imaging mode in energy bands 1-5 using the calibration information on mirror vignetting, detector quantum efficiency, and filter transmission. The exposure maps were corrected for bad pixels, bad columns and CCD gaps (cf. Fig. 3) as well as being multiplied by an OOT factor which is 0.9411 for pn full frame modes, 0.97815 for pn extended full frame modes, and 1.0 for all other pn and MOS modes.
The fundamental inputs to the 2XMM catalogue are the measured source parameters which were extracted from the EPIC image data by the multi-step source detection procedure outlined below. Each step was carried out simultaneously on each image of the five individual bands, 1-5, and of the three cameras. Note that the source counts and rates derived here refer to the fully integrated PSF.
As a first step, a detection mask was made for each camera. This defines the area of the detector which is suitable for source detection. Only those CCDs where the unvignetted exposure map values were at least 50% of the maximum exposure map value were used for source detection.
An initial source list was made using a ``box detection'' algorithm. This
slides a search box (
![]() )
across the image defined
by the detection mask. The size of the box comprises
)
across the image defined
by the detection mask. The size of the box comprises ![]() 50% of the
encircled energy fraction of the on-axis
50% of the
encircled energy fraction of the on-axis![]() PSF. In its first
application (``local mode'') the algorithm derived a local background from a
frame (
PSF. In its first
application (``local mode'') the algorithm derived a local background from a
frame (
![]() wide) immediately surrounding the search box. In each of
the five bands from each of the three cameras, the probability,
wide) immediately surrounding the search box. In each of
the five bands from each of the three cameras, the probability,
![]() ,
and corresponding likelihood, Li, were computed from the
null hypothesis that the measured counts k or more in the search box
result from a Poissonian fluctuation in the estimated background level,
x, i.e.:
,
and corresponding likelihood, Li, were computed from the
null hypothesis that the measured counts k or more in the search box
result from a Poissonian fluctuation in the estimated background level,
x, i.e.:
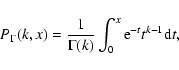
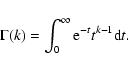
After the first pass to detect sources, a background map was created for
each camera and energy band. Using a cut-out radius dependent on source
brightness in each band (specifically the radius where the source counts
per unit area fell below 0.002 ct arcsec-2), areas of the image where
sources had been detected were blanked out. A
![]() -node spline
surface was fitted to the resulting source-free image to calculate a
smoothed background map for the entire image. For the pn images the
contribution of OOT events was also modelled into the background maps.
-node spline
surface was fitted to the resulting source-free image to calculate a
smoothed background map for the entire image. For the pn images the
contribution of OOT events was also modelled into the background maps.
A second box-source-detection pass was carried out, creating a new source
list, this time using the spline background maps (``map mode'') which
increased the source detection sensitivity compared to the local-mode
detection step. The box size was again set to
![]() .
Source counts were corrected for the part of the PSF falling
outside the detection box. Only sources with a total-band EPIC likelihood,
cf. Eq. (1), above 5 were included in this map-mode
source list.
.
Source counts were corrected for the part of the PSF falling
outside the detection box. Only sources with a total-band EPIC likelihood,
cf. Eq. (1), above 5 were included in this map-mode
source list.
A maximum likelihood fitting procedure was then applied to the sources
emerging from the map-mode detection stage to calculate source parameters
in each input image. This was accomplished by fitting a model to the distribution of counts over
a circular area of radius
![]() .
The energy-dependent model value,
ei, in pixel, i, is given by
.
The energy-dependent model value,
ei, in pixel, i, is given by
For each source, the fitting procedure minimised the C-statistic (Cash
1979)
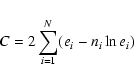
Free parameters of the fit were source position, extent, and source count
rate. Positions and extent were constrained to be the same in all energy
bands and for all cameras while the count rates were fitted separately for
each camera and energy band. The fitting process used the multi-band
exposure maps to take account of various instrumental effects (cf. Sect. 4.3) in deriving the source counts ![]() :
:
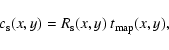
After arriving at those values of the source parameters which minimize C,
the detection likelihood (formally, the probability of the null hypothesis)
for those optimum values is then calculated. Cash's prescription for this
is to form the difference
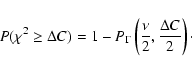
Since the C values are simple sums over all image pixels included in the
fit, one may calculate
![]() for each band i then add the results
together to generate a total-band
for each band i then add the results
together to generate a total-band
![]() without
destroying the
without
destroying the ![]() equivalence: only the number of degrees of freedom
changes. The source detection procedure thus calculates
equivalence: only the number of degrees of freedom
changes. The source detection procedure thus calculates
![]() and
hence Li for each ith band, using
and
hence Li for each ith band, using ![]() (=4 if source extent is
also fitted), then sums the
(=4 if source extent is
also fitted), then sums the
![]() and calculates
and calculates
![]() using
using
![]() ,
where N is the number of bands.
,
where N is the number of bands.
The fitting of the input sources was performed in the order of descending box(map)-detect detection likelihood. After each fit the resulting source model was added to an internally maintained background map used for the fitting of subsequent sources. With this method the background caused by the PSF wings of brighter sources is taken into account when fitting the fainter sources. All sources (as detected by the sliding-box in map mode) with a total-band detection likelihood >6, as determined by the fitting process, were included in the output source list. Note that for individual cameras and energy bands, the fitted likelihood values can be as low as zero.
The calculation of the parameter errors made use of the fact that ![]() follows the
follows the ![]() -distribution. The 68% confidence intervals were
determined by fixing the model to the best-fit parameters and then
subsequently stepping one parameter at a time in both directions until
-distribution. The 68% confidence intervals were
determined by fixing the model to the best-fit parameters and then
subsequently stepping one parameter at a time in both directions until
![]() is reached (while the other free parameters were kept
fixed). The upper and lower bound errors were then averaged to define a
symmetric error. Note that using
is reached (while the other free parameters were kept
fixed). The upper and lower bound errors were then averaged to define a
symmetric error. Note that using
![]() to determine the 68%
confidence intervals is only strictly correct in the case that there is one
parameter of interest. In the case of the fitting performed here, this
requires that the position and amplitude parameters are essentially
independent (i.e. that the cross-correlation terms of the error matrix
are negligible). This has been found through simulations to be an acceptable
approximation in the present case (see also the discussion of the astrometric
corrections in Sect. 4.5).
to determine the 68%
confidence intervals is only strictly correct in the case that there is one
parameter of interest. In the case of the fitting performed here, this
requires that the position and amplitude parameters are essentially
independent (i.e. that the cross-correlation terms of the error matrix
are negligible). This has been found through simulations to be an acceptable
approximation in the present case (see also the discussion of the astrometric
corrections in Sect. 4.5).
Four camera-specific X-ray colours, known as hardness ratios
(HR1-HR4), were obtained for each camera by combining corrected count
rates from energy bands n and n+1:
One of the enhancements incorporated in the 2XMM processing that was not available in 1XMM was information about the potential spatial extent of sources and, where detected, a measure of that extent.
The source extent characterisation was realised by fitting a convolution of
the instrumental PSF and an extent model to each input source. The extent
model was a ![]() -model of the form
-model of the form
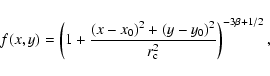
An extent likelihood based on the C-statistic and the best-fit point source
model as null hypothesis was calculated in an analogous way to that used in
the detection likelihood described in Sect. 4.4.3. The
extent likelihood
![]() is related to the probability P that the
detected source is spuriously extended due to Poissonian fluctuation (i.e.,
the source is point-like) by
is related to the probability P that the
detected source is spuriously extended due to Poissonian fluctuation (i.e.,
the source is point-like) by
Since source extent can be spuriously detected by the confusion of two or more point sources, a second fitting stage tested whether a model including a second source further improved the fit. If the second stage found an improvement over the single-source fit, the result could be two point sources or a combination of one point source and one extended source. Note, however, that the previously fitted fainter sources (Sect. 4.4.3) are not re-computed in such cases.
The positions of X-ray sources were determined during the maximum likelihood fitting of the source. These positions were placed into an astrometric frame determined from the XMM-Newton on-board Attitude & Orbit Control Subsystem (AOCS) which uses XMM-Newton's two star trackers and its ``fine sun sensors''. The overall accuracy of the XMM-Newton astrometric frame (i.e., the difference between the XMM-Newton frame and the celestial reference frame) is typically a few arcseconds although a few observations suffer rather poorer accuracy.
As the mean positions of bright X-ray sources can be determined to a
statistical precision of ![]()
![]() in the XMM-Newton images, and
typical sources to a precision of
in the XMM-Newton images, and
typical sources to a precision of
![]() ,
it is clearly
worthwhile to improve the astrometric precision of the positions. This was
done on an observation by observation basis by cross-correlating the source
list with the USNO B1.0 catalogue (Monet et al. 2003). This approach
depends on the assumptions, usually valid, that a significant number of
XMM-Newton detections will have an optical counterpart in the USNO
catalogue and that the number of random (false) matches is low. The
algorithm used a grid of trial position offsets (in RA and Dec) and
rotations between the XMM-Newton frame and the true celestial frame (as
defined by the USNO objects) and determined the optimum combination of
offset and rotation values which maximised a likelihood statistic related
to the X-ray/optical object separations.
,
it is clearly
worthwhile to improve the astrometric precision of the positions. This was
done on an observation by observation basis by cross-correlating the source
list with the USNO B1.0 catalogue (Monet et al. 2003). This approach
depends on the assumptions, usually valid, that a significant number of
XMM-Newton detections will have an optical counterpart in the USNO
catalogue and that the number of random (false) matches is low. The
algorithm used a grid of trial position offsets (in RA and Dec) and
rotations between the XMM-Newton frame and the true celestial frame (as
defined by the USNO objects) and determined the optimum combination of
offset and rotation values which maximised a likelihood statistic related
to the X-ray/optical object separations.
To determine whether the offset/rotation parameters so determined represented an acceptable solution, an empirically determined condition was used. This was based on a comparison of the likelihood statistic determined from the analysis with that calculated for purely coincidental X-ray/optical matches in a given observation, i.e., if there were no true counterparts.
In practice this approach worked very well at high Galactic latitudes,
resulting in a high success rate (74% of fields with
![]() ),
whilst at low Galactic latitudes (and other regions of high object density)
the success rate was much lower (33% of fields with
),
whilst at low Galactic latitudes (and other regions of high object density)
the success rate was much lower (33% of fields with
![]() ). The
typical derived RA, Dec offsets were a few arcseconds, and a few tenths of
a degree in field rotation, values consistent with the expected accuracy of
the nominal XMM-Newton astrometric frame as noted above.
). The
typical derived RA, Dec offsets were a few arcseconds, and a few tenths of
a degree in field rotation, values consistent with the expected accuracy of
the nominal XMM-Newton astrometric frame as noted above.
The 2XMM catalogue contains equatorial RA and Dec coordinates with the above determined astrometric corrections applied and corresponding coordinates which are not corrected. Where the refined astrometric solution was not accepted, the corrected and uncorrected coordinates are identical.
The catalogue also reports the estimated residual
component of the position errors,
![]()
![]() .
This has the value
.
This has the value
![]() for all detections in a field for which an acceptable
astrometric correction was found and
for all detections in a field for which an acceptable
astrometric correction was found and
![]() otherwise. The values of
otherwise. The values of
![]() in the catalogue are a new determination of the
residual error component based on further analysis undertaken after the
initial compilation of the catalogue was completed. The details of this
analysis are given in Sect. 9.5. Higher initial values of
in the catalogue are a new determination of the
residual error component based on further analysis undertaken after the
initial compilation of the catalogue was completed. The details of this
analysis are given in Sect. 9.5. Higher initial values of
![]() (
(
![]() and
and
![]() ,
respectively) were used in
earlier stages of the catalogue creation, for example in the external
catalogue cross-correlation (see Sect. 6).
,
respectively) were used in
earlier stages of the catalogue creation, for example in the external
catalogue cross-correlation (see Sect. 6).
The fluxes, Fi, given in the 2XMM catalogue have been obtained for each
energy band, i, as
Note that the fluxes given in 2XMM have not been corrected for Galactic absorption along the line of sight. The ECF values used in the 2XMM catalogue are shown in Table 4.
Table 4:
Energy conversion factors used to compute 2XMM catalogue fluxes
(in units of
![]() ).
).
Publicly available response matrices (RMFs) were used in the computation of
the ECFs![]() .
For the pn they were on-axis matrices for single-only events for band 1 and
for single-plus-double events
.
For the pn they were on-axis matrices for single-only events for band 1 and
for single-plus-double events![]() for bands 2-5 (epn_ff20_sY9_v6.7.rmf, epn_ff20_sdY9_v6.7.rmf, respectively).
For the MOS cameras there has been a significant change in the low energy
redistribution characteristics with time, especially for sources close to
the optical axis. In addition, during XMM-Newton revolution 534 the
temperatures of both MOS focal plane CCDs were reduced (from -100 C to -120 C), resulting in an improved spectral response thereafter (mainly in
the energy resolution). To account for these effects, epoch-dependent RMFs
were produced. However, in the computation of MOS ECFs time averaged RMFs
were used (for revolution 534). To be consistent with the event selection
used to create MOS X-ray images, the standard MOS1 and MOS2 on-axis RMFs
for patterns 0-12 were used (m1_534_im_pall.rmf, m2_534_im_pall.rmf).
for bands 2-5 (epn_ff20_sY9_v6.7.rmf, epn_ff20_sdY9_v6.7.rmf, respectively).
For the MOS cameras there has been a significant change in the low energy
redistribution characteristics with time, especially for sources close to
the optical axis. In addition, during XMM-Newton revolution 534 the
temperatures of both MOS focal plane CCDs were reduced (from -100 C to -120 C), resulting in an improved spectral response thereafter (mainly in
the energy resolution). To account for these effects, epoch-dependent RMFs
were produced. However, in the computation of MOS ECFs time averaged RMFs
were used (for revolution 534). To be consistent with the event selection
used to create MOS X-ray images, the standard MOS1 and MOS2 on-axis RMFs
for patterns 0-12 were used (m1_534_im_pall.rmf, m2_534_im_pall.rmf).
Note that for the computation of the ECFs, the effective areas used in the spectral fitting were calculated without the corrections already applied to the source count rates (i.e., instrumental effects including vignetting and bad-pixel corrections, see Sect. 4.3), as well as for the PSF enclosed-energy fraction.
Table 5: Event selection for source products.
The 2XMM processing pipeline was configured to automatically extract source-specific products, i.e., individual time-series (including variability measures) and spectra for the brighter detections. Sources were selected when the following extraction criteria were satisfied: 1) they had
Table 5 shows the event selection criteria for the extraction
of the source products. Instrumental GTIs (stored in the event list) are
always applied, while GTIs for masking out high background flaring (see
Sect. 4.3) were only applied to spectra and the variability
tests. Source data were extracted from a circular region of radius
![]() ,
centred on the detected source position, while the background
extraction region was a co-centred annulus with
,
centred on the detected source position, while the background
extraction region was a co-centred annulus with
![]() .
Circular apertures of radius
.
Circular apertures of radius
![]() were masked from
the background region for any contaminating detection with a likelihood
>15 for that camera. These values represent a compromise choice for data
extraction by avoiding the additional complexity required to implement a
variable extraction radius optimised for each source. Note that the use of
an aperture-photometry background subtraction procedure here differs from
the use of the background maps applied at the detection stage.
were masked from
the background region for any contaminating detection with a likelihood
>15 for that camera. These values represent a compromise choice for data
extraction by avoiding the additional complexity required to implement a
variable extraction radius optimised for each source. Note that the use of
an aperture-photometry background subtraction procedure here differs from
the use of the background maps applied at the detection stage.
For each source meeting the extraction criteria, the pipeline created the
following spectrum-related products: 1) a source+background spectrum
(grouped to 20 ct/spectral-bin) and a corresponding background-subtracted
XSPEC (Dorman & Arnaud 2001) generated plot; 2) a background spectrum; 3)
an auxiliary response file (ARF). Energies below 0.35 keV are considered
to be unreliable for the MOS due to low sensitivity and for the pn due to
the low-energy noise (in particular at the edges of the detector) and, as
such, were marked as ``bad'' in XSPEC terminology. Data around the Cu
fluorescence line for the pn (
![]() keV) were
also marked ``bad''. The publicly available ``canned''
keV) were
also marked ``bad''. The publicly available ``canned''![]() RMF associated with each spectrum is conveyed by a
header keyword. Some examples of the diversity of source spectra contained
amongst the source-specific spectral products are shown in
Fig. 6.
RMF associated with each spectrum is conveyed by a
header keyword. Some examples of the diversity of source spectra contained
amongst the source-specific spectral products are shown in
Fig. 6.
![\begin{figure}
\par\includegraphics[width=8cm,clip]{10534f6.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img100.gif) |
Figure 6:
Examples of auto-extracted 2XMM spectra. Sources are serendipitous objects
and spectra are taken from the EPIC pn unless otherwise stated. Panels: a) a typical extragalactic source (Seyfert I galaxy); b) line-rich spectrum of
a localised region in the Tycho supernova remnant (target); c) MOS2
spectrum of a stellar coronal source (target; H II 1384,
Briggs & Pye 2003), described by two-component thermal spectrum; d) spectrum of the hot intra-cluster gas in a galaxy cluster at z=0.29(Kotov et al. 2006); e) heavily absorbed, hard X-ray
spectrum of the Galactic binary IGR J16318-4848 (target; Ibarra et al. 2007); f) spectrum of a super-soft source with oxygen line emission at
|
| Open with DEXTER | |
Light curves for a given source were created with a common bin-width (per observation) that was an integer multiple of 10 s (minimum width 10 s), determined by the requirement to have at least 18 ct/bin for pn and at least 5 ct/bin for MOS for the exposures used in source detection. All light curves of a given source within an XMM-Newton observation are referenced to a common epoch for ease of comparison.
The light curves themselves can include data taken during periods of background flaring because background subtraction usually successfully removes its effects. However, in testing for potential variability, to minimise the risk of false variability triggers, only data bins that lay wholly inside both instrument GTIs and GTIs reflecting periods of non-flaring background were used.
Two simple variability tests were applied to the separate light curves: 1) a Fast Fourier Transform and 2) a ![]() -test against a null
hypothesis of constancy. While other approaches, e.g., the
Kolmogorov-Smirnov test, maximum-likelihood methods, and Bayesian methods
are potentially more sensitive, the
-test against a null
hypothesis of constancy. While other approaches, e.g., the
Kolmogorov-Smirnov test, maximum-likelihood methods, and Bayesian methods
are potentially more sensitive, the ![]() -test was chosen here as being
a simple, robust indicator of variability. The fundamental formula for
-test was chosen here as being
a simple, robust indicator of variability. The fundamental formula for ![]() is
is
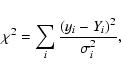
The problem now is that a priori the expectation values
![]() for the background time-series is not known - they
must be estimated, with as low an uncertainty as possible, by forming a
background time-series in an (ideally) fairly large area which is
sufficiently far from the source to avoid cross-contamination. Also, the
average source flux
for the background time-series is not known - they
must be estimated, with as low an uncertainty as possible, by forming a
background time-series in an (ideally) fairly large area which is
sufficiently far from the source to avoid cross-contamination. Also, the
average source flux
![]() is not known, which must also be
estimated from the (necessarily noisy) data at hand. After some algebra it
can be shown that the best estimate for Yi is given by
is not known, which must also be
estimated from the (necessarily noisy) data at hand. After some algebra it
can be shown that the best estimate for Yi is given by
The ![]() values in the
values in the ![]() sum present a problem. In the Pearson
formula appropriate to Poissonian data,
sum present a problem. In the Pearson
formula appropriate to Poissonian data,
![]() is set to Yi. If we
simply substitute
is set to Yi. If we
simply substitute
![]() for Yi here, the resulting
for Yi here, the resulting ![]() values are found via Monte Carlo trials to be somewhat too large. This is
because the use of the random background variate bi in Eq. (4)
introduces extra variance into the numerators of the sum. A formula for
values are found via Monte Carlo trials to be somewhat too large. This is
because the use of the random background variate bi in Eq. (4)
introduces extra variance into the numerators of the sum. A formula for
![]() which takes this into account is
which takes this into account is
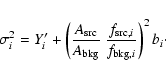
![\begin{figure}
\par\includegraphics[width=8cm,clip]{10534f7.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img113.gif) |
Figure 7: Example auto-extracted 2XMM time-series. Sources are serendipitous objects and the data are taken from the pn unless otherwise stated. Panels: a) MOS1 data for Markarian 335 (Seyfert I - target); b) MOS1 data showing the decay curve of GRB 050326 (target); c) X-ray flares from a previously unknown coronally active star; d) time-series of the emission from a relatively faint cluster of galaxies, showing no significant variability (target); e) time-series of the obscured Galactic binary IGR 16318-4848 (target; Ibarra et al. 2007); f) previously unknown AM Her binary showing several phase-stable periodic features (Vogel et al. 2007); g) highly variable AND periodic object, likely to be a cataclysmic or X-ray binary (Farrell et al. 2008) - the binning results in poor sampling of the intrinsic periodic behaviour; h) source showing clear variability but not flagged as variable in the catalogue (the probability of variability falls below the threshold of 10-5). These last two cases highlight the sensitivity of the variability characterisation on the time bin size. |
| Open with DEXTER | |
As with any automated extraction procedure, a few source products suffer from problems such as low photon statistics, low numbers of bins, background subtraction problems, and contamination.
Spectra with few bins can arise for very soft sources where the total-band counts meet the extraction criteria but the bulk of the flux occurs below the 0.35 keV cut-off (Sect. 5.1). This can also occur if the extraction is for an exposure with a shorter exposure time than those used in the detection stage, especially if the detection was already close to the extraction threshold. Similarly, background over-estimation in the exposure (or underestimation in the original detection exposure) can result in fewer source counts compared to those determined during the detection stage, yielding poorer statistics and low bin numbers for the time-series and spectra. This can occur when spatial gradients across the background region are imperfectly characterised, e.g., where the source lies near strong instrumental features such as OOT events, where there are marked steps in the count-rate levels between adjacent noisy and non-noisy CCDs, or where contaminant source exclusions are biased to one side of a background region that overlaps the wings of a very bright source or bright extended emission. In many cases the automatic (Sect. 7.3) as well as manual flag settings (Sect. 7.4) indicate whether source products are likely to be reliable.
Contamination of the source extraction region (e.g., by another source, OOT
events, or single reflections) can also cause problems if the contamination
is brighter than or of comparable brightness to the extracted source. The
nearest-neighbour column can act as an initial alert in such cases - 19%
of the catalogue sources with spectra have neighbouring detections (of any
brightness) within
![]() (i.e., the extraction radius).
(i.e., the extraction radius).
The extraction process and exposure corrections are optimised for point sources. Absolute fluxes in source-specific products of extended sources, therefore, may not be reliable. However, relative measures such as variability and spectral line detection should still be indicative.
A few products are affected by known processing problems:
As part of the XMM-Newton pipeline, the Astronomical Catalogue Data Subsystem (ACDS) generated products holding information on the immediate surrounding of each EPIC source and on the known astrophysical content of the EPIC FOV, highlighting the possible non-detection of formerly known bright X-ray sources as well as indicating the presence of particularly important astrophysical objects in the area covered by the XMM-Newton observation.
In addition to Simbad![]() and NED
and NED![]() , 202
archival catalogues and article tables were queried from
Vizier
, 202
archival catalogues and article tables were queried from
Vizier![]() . They
were selected on the basis of their assumed high probability to contain the
actual counterpart of the X-ray source. Basically all large area ``high
density'' astronomical catalogues were considered, namely the SDSS-DR3
(Abazajian et al. 2005), USNO-A2.0 (Monet et al. 1998), USNO-B1.0 (Monet
et al. 2003), GSC 2.2 (STScI 2001), and APM-North (McMahon et al. 2000)
catalogues in the optical, the IRAS (Joint Science WG 1988; Moshir et al. 1990), 2MASS (Cutri et al. 2003), and DENIS (DENIS consortium 2005)
catalogues in the infrared, the NVSS (Condon et al. 1998), WISH (de Breuck
et al. 2002), and FIRST (Becker et al. 1997) catalogues at radio
wavelengths, and the main X-ray catalogues produced by Einstein (2E; Harris
et al. 1994), ROSAT: RASS bright and faint source lists (Voges et al. 1999, 2000), RBS (Schwope et al. 2000), HRI (ROSAT Team 2000), PSPC (ROSAT
2000), and WGACAT (White et al. 2000) catalogues of pointed observations),
and XMM-Newton (1XMM; XMM-SSC 2003). Also included
were large lists of homogeneous objects (e.g., catalogues of bright stars,
cataclysmic variables, LMXBs, Be stars, galaxies, etc.). The full list of
archival catalogues queried is included as one of the pipeline products.
. They
were selected on the basis of their assumed high probability to contain the
actual counterpart of the X-ray source. Basically all large area ``high
density'' astronomical catalogues were considered, namely the SDSS-DR3
(Abazajian et al. 2005), USNO-A2.0 (Monet et al. 1998), USNO-B1.0 (Monet
et al. 2003), GSC 2.2 (STScI 2001), and APM-North (McMahon et al. 2000)
catalogues in the optical, the IRAS (Joint Science WG 1988; Moshir et al. 1990), 2MASS (Cutri et al. 2003), and DENIS (DENIS consortium 2005)
catalogues in the infrared, the NVSS (Condon et al. 1998), WISH (de Breuck
et al. 2002), and FIRST (Becker et al. 1997) catalogues at radio
wavelengths, and the main X-ray catalogues produced by Einstein (2E; Harris
et al. 1994), ROSAT: RASS bright and faint source lists (Voges et al. 1999, 2000), RBS (Schwope et al. 2000), HRI (ROSAT Team 2000), PSPC (ROSAT
2000), and WGACAT (White et al. 2000) catalogues of pointed observations),
and XMM-Newton (1XMM; XMM-SSC 2003). Also included
were large lists of homogeneous objects (e.g., catalogues of bright stars,
cataclysmic variables, LMXBs, Be stars, galaxies, etc.). The full list of
archival catalogues queried is included as one of the pipeline products.
The XMM-Newton detections were cross-correlated with the archival entries taking into account positional errors in both the EPIC and the archival entries. The list of possible counterparts did not provide additional information on the relative merits of the cross-correlation or on the probability that the given archival entry was found by chance in the error circle of the X-ray source.
The cross-correlation was based on the dimensionless variable:
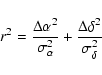
The probability density distribution of position differences between the
X-ray source and its catalogue counterpart due to measurement errors is a
Rayleigh distribution. Hence, the probability of finding the X-ray source
at a distance between r and
![]() from its archival counterpart
is:
from its archival counterpart
is:
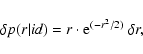
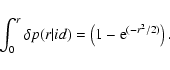
The ACDS results are presented in several interconnected HTML files (together with copies in FITS format). Graphical products are 1) a plot with the position of all quoted archival entries on the EPIC merged image; 2) an overlay of the position of the X-ray sources detected in the EPIC camera and contours of the EPIC merged image on a ROSAT all-sky survey image; and 3) finding charts based on sky pixel data provided by the CDS Aladin image server (Bonnarel et al. 2000).
As part of the quality assurance for the data processing, a number of procedures, both automated and manual, were performed on many of the data products to take note of intrinsic problems with the data as well as to detect software issues. Particular emphasis was given to potential problems with the source detection and characterisation, and quality flags were set accordingly.
The overall visual screening included data products from all three instrument groups (EPIC, RGS, OM) as well as those from the external catalogue cross-correlation (cf. Sect. 6). Only products that could be conveniently assessed were inspected using a dedicated screening script, that is, most HTML pages, all PNG images and all PDF plots (as representatives of data from the FITS files), all EPIC FITS images and maps (including source-location overlays), and the mosaiced OM FITS images with source overlay. For each observation a screening report with standardised comments was created, recording data and processing problems (see, for example, Sect. 5.4), and made available via the XSA.
As a result of the visual screening, two otherwise eligible observations (obtained for experimental mode tests) were excluded from the catalogue since the tested mode was not properly supported by the processing system and the source parametrisation was considered to be unreliable.
Intrinsic features of the XMM-Newton instrumentation combined with some
shortcomings of the detection process have given rise to detections that
are obviously spurious![]() . Possible causes range from bright pixels and segments
to OOT events (in the case of pileup), RGA scattered light, single
reflections from the mirrors, and optical loading (cf. Appendix A
and Fig. 4a). In cases where the spatial background
varied rapidly (e.g., PSF ``spikes'', filamentary extended emission, edges of
noisy CCDs), the spline background map may deviate from the true
background. This could potentially have given rise to spurious source
detections and could also have affected the measured parameters (including
time-series and spectra) of real sources.
. Possible causes range from bright pixels and segments
to OOT events (in the case of pileup), RGA scattered light, single
reflections from the mirrors, and optical loading (cf. Appendix A
and Fig. 4a). In cases where the spatial background
varied rapidly (e.g., PSF ``spikes'', filamentary extended emission, edges of
noisy CCDs), the spline background map may deviate from the true
background. This could potentially have given rise to spurious source
detections and could also have affected the measured parameters (including
time-series and spectra) of real sources.
Extended sources were particularly difficult to detect and parametrise due
to their (often) filamentary or non-symmetric structure as well as the
maximum allowed extent in fitting (
![]() ,
Sect. 4.4.4). This
often led to multiple detections of a large or irregular extended emission
region. On the other hand, multiple point sources (e.g., in a crowded
field) might also be detected as extended (due to computational
restrictions no attempt was made to distinguish more than two
overlapping/confused point sources). See Sect. 9.9 and
Fig. 14 for a discussion of extended sources and some
examples.
,
Sect. 4.4.4). This
often led to multiple detections of a large or irregular extended emission
region. On the other hand, multiple point sources (e.g., in a crowded
field) might also be detected as extended (due to computational
restrictions no attempt was made to distinguish more than two
overlapping/confused point sources). See Sect. 9.9 and
Fig. 14 for a discussion of extended sources and some
examples.
Some of the source detection problems could be identified and quantified so that the processing software could set automated quality warning flags in the source lists. For each detection, four sets of flags (one per camera plus a summary set covering all cameras), each containing twelve entries, were written into the observation source list. Nine of the flags in each set were populated based on other key quantities available in the same source list. The meaning of these flags is summarised in Table 6. The default value of every flag was False; when a flag was set it means it has been changed to True. For each detection, Flags 2-7 were set in a common fashion across all four sets. Flags 1, 8, and 9 are camera-specific, but any set to True were also reflected in the summary set.
Table 6: Description of the automated (Flags 1-9) and manual (Flags 11-12) quality warning flags.
The criteria used to set the flags were determined largely empirically from tests on appropriate sample data-sets (cf. Fig. 4b, for some examples). Flags set to True should be understood mainly as a warning: they identify possible problematic issues for a detection such as proximity to a bright source, a location within an extended source emission, insufficient detector coverage of the PSF of the detection, and known pixels or clustering of pixels that tend to be intrinsically bright at low energies. In all these cases the parameters of a real source may be compromised and there is a possibility that the source is spurious.
Extended sources near bright sources and within larger extended emission are most likely to be spurious and have been flagged as such. In addition, extended detections triggered by hot pixels or bright columns can be identified since their likelihood in one band (of one camera) is disproportionally higher than in the other bands and cameras. However, no attempt has been made to flag spurious extended detections in the general case, that is, in areas where the background changes considerably on a small spatial scale and the spline maps cannot adequately represent this. At the same time, no point sources have been specifically flagged as spurious (see Sect. 7.4 regarding manual flagging) though they are often caused by the same features as the spurious extended detections. The spatial density of real point sources is, in general, much higher than for extended sources and the reliability of such a ``spurious'' flag would be low. Instead, Flags 2, 3, and 9 can be used as a warning that such a source could be spurious.
In addition to the automated quality flags, a more rigorous visual screening of the source detection was performed for the EPIC fields to be used in the catalogue. The outcome of this process was reflected in two flags (11 and 12) as described below and summarised in Table 6.
Images of each field, with source overlay, were inspected visually and
areas with likely spurious detections were recorded (as
ds9-regions; Joye & Mandel 2003). Such regions could be regular (circle,
ellipse, box) or irregular (polygon); in cases where only a single
detection was apparently spurious a small circle of
![]() radius was
used, centred on this detection. It should be stressed that these regions,
except for the latter case, could include both suspected spurious and real
detections. In many cases (especially at fainter fluxes) it was impossible
to visually distinguish between a real source and a spurious detection that
was caused by artefacts on the detector or by insufficient background
subtraction. In addition, the effect of such features on the parameters of
a nearby real source has not been investigated in detail. For example,
single reflections or the RGA scattered-light features were not included in
the background maps and may therefore have affected the source parameters.
On the other hand, as the source parameters are derived by the fitting
process in order of decreasing source brightness, the parameters of fainter
sources take the PSF of nearby bright sources into account
(Sect. 4.4).
radius was
used, centred on this detection. It should be stressed that these regions,
except for the latter case, could include both suspected spurious and real
detections. In many cases (especially at fainter fluxes) it was impossible
to visually distinguish between a real source and a spurious detection that
was caused by artefacts on the detector or by insufficient background
subtraction. In addition, the effect of such features on the parameters of
a nearby real source has not been investigated in detail. For example,
single reflections or the RGA scattered-light features were not included in
the background maps and may therefore have affected the source parameters.
On the other hand, as the source parameters are derived by the fitting
process in order of decreasing source brightness, the parameters of fainter
sources take the PSF of nearby bright sources into account
(Sect. 4.4).
The ds9-regions were converted to EPIC image masks where the bad areas have the value zero and the rest of the field has the value one. These masks are available as catalogue products (Sect. 10); they can be combined with the camera detection masks to study, for example, the sky coverage.
The masks were used to flag sources within the masked areas with
Flag 11. In many cases, the so-called ``originating'' source (a bright point
source, cf. Flag 2, or a large or irregular extended source, cf. Flag 3)
was located within the masked region. Though the brightest source was
fitted before the fainter ones, the contribution of the faint sources to
the fit of the bright source is considered to be negligible
(Sect. 4.4.3). Hence, the ``originating'' point source was
identified by setting its Flag 12![]() to distinguish it from the other detections with Flag 11 in that particular
ds9-region, the parameters of which may be affected by the presence of the
indicated bright source due to imperfections in the PSF used. In the case
of bright extended sources, however, the situation was different: the
extent parameter was obviously affected by nearby spurious detections, and
consequently the brightness was underestimated. Flag 12 was therefore only
set for point sources.
to distinguish it from the other detections with Flag 11 in that particular
ds9-region, the parameters of which may be affected by the presence of the
indicated bright source due to imperfections in the PSF used. In the case
of bright extended sources, however, the situation was different: the
extent parameter was obviously affected by nearby spurious detections, and
consequently the brightness was underestimated. Flag 12 was therefore only
set for point sources.
Table 7: Observation class definitions.
For easier use of the quality-flag information, the catalogue gives a summary flag which combines the flags described above (11 per camera per detection) to give a single, overall quality indication for each detection. Its five possible values are as follows (in order of increasing severity):
The screening flags also offer a means of avoiding source-specific data products with possible problems, noting that of all detections with products a significant fraction have summary flag ![]() 3 indicating potential issues with the spectra and/or time series.
3 indicating potential issues with the spectra and/or time series.
The summary flag assigned to each detection in the catalogue provides an overall classification of each detection included in the catalogue. On the other hand, since about half of all observations in the catalogue are little affected by artefacts and background subtraction problems, an observation classification offers the possibility of selecting good quality fields rather than good quality detections. This classification is based on the fraction of area masked out in the flag mask (Sect. 7.4) as compared to the total area used in the source detection (from the combined EPIC detection mask) for that observation. Six classes of observations were identified. They are listed in Table 7 together with the percentage of observations affected, the fractional area, and the approximate size of the excluded region (note that the flag mask may comprise several regions in various shapes).
The 2XMM catalogue is a catalogue of detections. As such, every row in the 2XMM catalogue represents a single detection of an object from a separate XMM-Newton observation. The construction of the 2XMM catalogue consists of two main steps. The first involves the aggregation of the data of individual detections from the separate observation source lists into a single list of detected objects, adding additional information about each detection and meta-data relating to the observation in which the detection was made. The second step consists of cross-matching detections, identifying resulting unique celestial objects and combining or averaging key quantities from the detections into corresponding unique-source values. Ultimately, the ensemble of data for both detections and unique sources becomes the catalogue.
The primary source of data for the catalogue was the set of 3491 EPIC summary source list files from the maximum-likelihood source-fitting processes (Sect. 4.4.3). Additional information incorporated into the catalogue for each detection includes the detection background levels, the variability information (from the EPIC source time-series files; see below) and the detection flags from the automatic flagging augmented by the manual data screening process (see Sects. 7.4, and 7.5). Ancillary information added to the catalogue entries also includes various observation meta-data parameters (e.g., observation ID, filters and modes used) and the observation classification determined as part of the data screening process (Sect. 7.6). In the final catalogue table each detection is also assigned a unique detection number.
The measured and derived parameters of the detections taken from the
pipeline product files are reflected in the 2XMM catalogue by a number of
columns described in Appendix D.1-D.6. For the
variability information for detections (Appendix D.6), the
variability identifier was set to True for a detection if at least one of
the time-series for this detection (derived from all appropriate exposures)
had a ![]() -probability
-probability ![]() 10-5 based on the null hypothesis that
the source was constant (cf. Sect. 5.2). The probability threshold
was chosen to yield less than one false trigger over the entire set of
time-series. Where the flag was set, the camera and exposure ID with the
lowest
10-5 based on the null hypothesis that
the source was constant (cf. Sect. 5.2). The probability threshold
was chosen to yield less than one false trigger over the entire set of
time-series. Where the flag was set, the camera and exposure ID with the
lowest ![]() -probability were also provided for convenience. No
assessment of potential variability has been made between observations for
those sources detected more than once.
-probability were also provided for convenience. No
assessment of potential variability has been made between observations for
those sources detected more than once.
XMM-Newton observations can yield multiple detections of the same object on the sky where a particular field is the subject of repeat pointings or because of partial overlaps from dedicated mosaic observations or fortuitous overlaps from unrelated pointings. As such, the catalogue production process also sought to identify and collate data for all detections pertaining to unique sources on the sky, providing a unique-source indexing system within the catalogue. In parallel, the catalogue provides a number of derived quantities relating to the unique sources computed from the constituent detections.
To identify unique sources from multiple detections, reliable estimates of
the position error,
![]() ,
of each detection are
essential. The best estimate of the position error was found to be
,
of each detection are
essential. The best estimate of the position error was found to be
Two detections from different observations with respective position errors
of
![]() and
and
![]() were assumed to be potentially
associated with the same celestial source if their separation is
were assumed to be potentially
associated with the same celestial source if their separation is
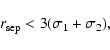
Using these constraints, the detection table was cross-correlated with itself to find all possible pairs of detections having error-circle overlaps. Some detections were found to have as many as 31 such overlaps, since a few areas of sky were observed this many times (generally calibration observations). Resolving this list into a set of unique celestial sources required some experimentation because of potential ambiguity in a few crowded or complex fields. The extreme scenarios were 1) to assume a set of detections was associated with a unique source only if they all overlapped each other - this was considered too conservative; 2) to assume that a set of detections constituted a unique source if each member overlapped at least one other member - this was deemed overly generous, i.e., it would have included a few pairs of detections whose mutual separations would be incompatible with coming from a single source. The algorithm adopted gave priority to those detections with the highest number of overlaps (because they were likely to be near the true source centre) and, this number being equal, to count-rate agreement. The list of overlapping detections was therefore sorted in descending order of the number of overlaps and the EPIC total-band count rate and then processed in that order. Each detection was associated with all its overlapping detections, except those which had already been removed from the list by having been associated with another (better connected or stronger) detection. In the final catalogue the number of detections which might have been associated with a source different from the one actually assigned to them, given a different order of processing, was about one hundred, which was significantly lower than the figure from various alternative algorithms. These ambiguous detections were almost all from observations which the screening process flagged as unreliable, suggesting that further refinements to the algorithm would have been of little practical value.
The algorithm adopted for the identification of unique sources appears to be reliable in the great majority of cases, but there are known to be a few confused areas where the results are likely to be imperfect. The most common cause is where real diffuse or bright objects give rise to (generally spurious) additional detections which happen to approximately coincide spatially in different observations. In most cases it is likely that the sources will have received a manual flag. Incorrect matching can also potentially occur where centroiding is adversely affected by pileup or optical loading, where one or more contributing observations have significant attitude errors which could not be astrometrically rectified (Sect. 4.5), or where a real source is located close to another detection associated with an artefact such as residual OOT events from a strongly piled-up source elsewhere in the image. Where pileup or artefacts are involved, affected sources may have been assigned automatic or manual flags anyway. It should be emphasised, however, that flag information is not used in the source matching process. Based on the extensive visual inspection, incorrect detection matching is believed to be extremely rare (<200 detections affected). Inevitably, in a few cases, the matching process fails to match some detections that belong together.
A number of quantities for unique sources are included in the 2XMM
catalogue, based on error-weighted merging of the constituent detection
values (see Appendix D.7). The IAU name of each unique source
was constructed from its coordinates. Note that an individual detection is
completely specified by its IAU name and its detection identifier.
The unique-source data were augmented with five quantities that were not
based on error-weighted merging: 1) the unique-source detection likelihood
was set to the highest EPIC total-band detection likelihood, i.e., it
reflects the strongest constituent detection of a unique source; 2) a
unique-source extent likelihood was computed as the simple average of the
corresponding EPIC detection values; 3) the reduced ![]() -probability
for the variability of a unique source was taken as the lowest of the
detection values, indicative of the detection with the highest likelihood
of being variable, where variability information was available; 4) where
variability information existed for any of the constituent detections, a
unique-source variability identifier was set to True if any were True and
to False if none were True. Where no variability information was available,
the unique-source flag was set to Undefined; 5) a unique-source summary
flag took the maximum of the detection summary flag values
(Sect. 7.5), i.e., reflecting the worst-case flag from any of
the detections of the source.
-probability
for the variability of a unique source was taken as the lowest of the
detection values, indicative of the detection with the highest likelihood
of being variable, where variability information was available; 4) where
variability information existed for any of the constituent detections, a
unique-source variability identifier was set to True if any were True and
to False if none were True. Where no variability information was available,
the unique-source flag was set to Undefined; 5) a unique-source summary
flag took the maximum of the detection summary flag values
(Sect. 7.5), i.e., reflecting the worst-case flag from any of
the detections of the source.
The 2XMM catalogue was also cross-correlated against the 1XMM and 2XMMp
catalogues during the construction process. For each unique 2XMM source,
the most probable matching 1XMM counterpart and 2XMMp counterpart were
identified and listed in the 2XMM catalogue. The matching algorithm
employed was similar to the one described for identifying unique sources
but the maximum positional offset between the new catalogue and the older
ones was set at
![]() .
This was a rather conservative value but since
a number of sources in 1XMM, especially, have positional errors greater than
this, it ensures that there are very few incorrect matches or ambiguous
cases.
.
This was a rather conservative value but since
a number of sources in 1XMM, especially, have positional errors greater than
this, it ensures that there are very few incorrect matches or ambiguous
cases.
This resulted in ![]() 88% of all 2XMMp sources having a match with 2XMM
sources. Apart from those lying outside the
88% of all 2XMMp sources having a match with 2XMM
sources. Apart from those lying outside the
![]() matching circle,
non-matched sources are found to be either spurious, at the detection
limit, or the observation was not included in 2XMM. Comparison with 1XMM is
not straight forward due to the differences in the detection scheme (e.g.,
the source detection in 1XMM was done per camera) and likelihood cutoffs.
Note, though, that 1XMM comprises only 585 of the 2XMM fields.
matching circle,
non-matched sources are found to be either spurious, at the detection
limit, or the observation was not included in 2XMM. Comparison with 1XMM is
not straight forward due to the differences in the detection scheme (e.g.,
the source detection in 1XMM was done per camera) and likelihood cutoffs.
Note, though, that 1XMM comprises only 585 of the 2XMM fields.
The catalogue contains 246 897 detections drawn from 3491 public
XMM-Newton observations (Fig. 1). These detections relate to
191 870 unique sources. Of these, 27 522 X-ray sources were observed more
than once; some were observed up to 31 times in total due to the fact that
many sky regions are covered by more than one observation. Of the 246 897
X-ray detections, 20 837 are classified as extended. Table 8
shows the number of
detections and unique sources per camera and energy band (split into point sources and extended sources); a
likelihood threshold ![]() has been applied but no selection of detection flags has been made.
has been applied but no selection of detection flags has been made.
The catalogue contains detections down to an EPIC likelihood of 6. Around 90% of the detections have L>8 and
![]() 82% have L>10. Simulations demonstrate that the false detection rate for typical high Galactic latitude fields is
82% have L>10. Simulations demonstrate that the false detection rate for typical high Galactic latitude fields is ![]() [2, 1, 0.5]% for
detections with
L>[6, 8, 10] respectively (Sect. 9.4). We note that the source detection in 2XMM has
a low degree of incompleteness for
[2, 1, 0.5]% for
detections with
L>[6, 8, 10] respectively (Sect. 9.4). We note that the source detection in 2XMM has
a low degree of incompleteness for
![]() .
This arises from the fact that the first stage of the source detection
(Sect. 4.4.2) requires that each detection have
.
This arises from the fact that the first stage of the source detection
(Sect. 4.4.2) requires that each detection have ![]() .
As this first stage of the processing is
relatively crude, the incompleteness primarily arises from this preselection of low significance detections.
.
As this first stage of the processing is
relatively crude, the incompleteness primarily arises from this preselection of low significance detections.
The 2XMM catalogue is intended to be a catalogue of serendipitous
sources. The observations from which it has been compiled, however, are of
course pointed observations which typically contain one or more target
objects chosen by the original observers, so the catalogue contains a small
fraction of targets which are by definition not serendipitous.
Appendix C provides details of the target identification and
classification. From this analysis we find that around 2/3 of the intended
targets are unambiguously identified in their XMM-Newton observations but,
allowing for multiple detections, only ![]() 1400 targets are plausibly
associated with 2XMM catalogue sources. This means that <1% of 2XMM
sources are the target of the observation, although in a few observations
(e.g., nearby galaxies) the number of sources associated with the
target can clearly be much greater.
1400 targets are plausibly
associated with 2XMM catalogue sources. This means that <1% of 2XMM
sources are the target of the observation, although in a few observations
(e.g., nearby galaxies) the number of sources associated with the
target can clearly be much greater.
More generally the fields from which the 2XMM catalogue is compiled may also not be representative of the overall X-ray sky. The classification of the XMM-Newton observations (Appendix C and Table D.2) is relevant to avoiding potential selection bias in the use of the catalogue.
Table 8:
Numbers of detections with likelihood ![]() in the 2XMM catalogue.
in the 2XMM catalogue.
To compute the effective sky coverage, the sky was notionally covered by a
grid of pixels using the HEALPix projection (Gorski et al. 2005). Adequate
resolution was obtained using pixels ![]()
![]() across. For each
observation included in 2XMM the exposure times were computed for each
HEALPix pixel taking into account the exposure map for each observation
(i.e., the actual coverage taking into account observing mode, CCD gaps,
telescope vignetting, etc.). From this analysis we find that in total the
catalogue fields cover a sky area of more than 500 deg2. The
non-overlapping sky area is
across. For each
observation included in 2XMM the exposure times were computed for each
HEALPix pixel taking into account the exposure map for each observation
(i.e., the actual coverage taking into account observing mode, CCD gaps,
telescope vignetting, etc.). From this analysis we find that in total the
catalogue fields cover a sky area of more than 500 deg2. The
non-overlapping sky area is ![]() 360 deg2 (
360 deg2 (![]() 1% of the sky).
1% of the sky).
The sensitivity of the 2XMM survey catalogue was estimated empirically
using the method of Carrera et al. (2007). The algorithm presented in
their Appendix A was used to compute sensitivity maps for each instrument
and energy band, using data from the exposure maps and background maps from
each observation. Using a grid of HEALPix pixels in a similar way to that
outlined above, the limiting flux of the most sensitive observation
of each part of the sky was estimated. Figure 8 shows the
sky area against limiting flux for each EPIC camera and energy band
separately. This analysis provides a relatively robust estimate of the
total sky area of the 2XMM catalogue for each of the three EPIC cameras,
although it does not take into account those sky regions which are
effectively useless for serendipitous source detection due to the presence
of bright objects or certain instrumental artefacts (see discussion in
Sect. 3.1 and Fig. 4b and c)![]() .
These area-flux
plots computed for L>10 show that the effective sky coverage for the MOS2
camera is
.
These area-flux
plots computed for L>10 show that the effective sky coverage for the MOS2
camera is ![]() 370 deg2 (for the MOS1 camera it is
370 deg2 (for the MOS1 camera it is
![]() 360 deg2 due to the loss of one of the MOS1 CCDs in March
2005), whilst for the pn camera the area is
360 deg2 due to the loss of one of the MOS1 CCDs in March
2005), whilst for the pn camera the area is ![]() 330 deg2, due
primarily to reduced or zero imaging sky area provided by some of the pn
observing modes. The limiting fluxes vary between camera and energy
band. For the pn camera which provides the highest sensitivity, the minimum
detectable fluxes in the soft (0.5-2 keV), hard (2-12 keV) and hardest
(4.5-12 keV) bands at 10% sky coverage are
330 deg2, due
primarily to reduced or zero imaging sky area provided by some of the pn
observing modes. The limiting fluxes vary between camera and energy
band. For the pn camera which provides the highest sensitivity, the minimum
detectable fluxes in the soft (0.5-2 keV), hard (2-12 keV) and hardest
(4.5-12 keV) bands at 10% sky coverage are ![]() [2, 15, 35
[2, 15, 35
![]() ,
respectively. The fluxes for >90%
sky coverage (i.e., close to complete coverage) in these bands are
,
respectively. The fluxes for >90%
sky coverage (i.e., close to complete coverage) in these bands are ![]() [1, 9, 25
[1, 9, 25
![]() respectively.
respectively.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{10534f8.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img162.gif) |
Figure 8:
Sky area as a function of flux limit for the 2XMM catalogue
computed for sources with a detection likelihood limit |
| Open with DEXTER | |
The distribution of fluxes for the 2XMM catalogue detections is shown in
Fig. 9. This figure illustrates that the typical soft-band
flux for the catalogue sources is
![]()
![]() and is
and is ![]()
![]() in the hard and total
bands. These values correspond quite closely to the fluxes of the sources
which dominate the cosmic X-ray background (where the slope of the
extragalactic source counts breaks), demonstrating the importance of 2XMM
in providing large samples at these fluxes.
in the hard and total
bands. These values correspond quite closely to the fluxes of the sources
which dominate the cosmic X-ray background (where the slope of the
extragalactic source counts breaks), demonstrating the importance of 2XMM
in providing large samples at these fluxes.
Also shown in Fig. 9 is the distribution of total counts in
the combined EPIC images for the same sample of 2XMM detections. As
expected the distribution is dominated by low count sources, with the peak
lying at ![]() 70 counts. This plot also illustrates the effect of the
targets of the XMM-Newton fields themselves which only contribute
significantly, not surprisingly, above
70 counts. This plot also illustrates the effect of the
targets of the XMM-Newton fields themselves which only contribute
significantly, not surprisingly, above ![]() 2000 EPIC counts.
2000 EPIC counts.
We note that it would be possible to combine the survey sensitivity curves
discussed in Sect. 9.2 and the flux distributions discussed here
to construct the source counts (i.e., the
![]() relationship)
for the 2XMM catalogue. In practice, however, the results of this exercise
would have limited value due to the large uncertainties in the correct
area-sensitivity corrections for the substantial number of fields included
in 2XMM which contain, for example, bright objects or are subject to
problematic instrumental effects. A separate paper, Mateos et al. (2008),
presents the
relationship)
for the 2XMM catalogue. In practice, however, the results of this exercise
would have limited value due to the large uncertainties in the correct
area-sensitivity corrections for the substantial number of fields included
in 2XMM which contain, for example, bright objects or are subject to
problematic instrumental effects. A separate paper, Mateos et al. (2008),
presents the
![]() relationship and results for a carefully
selected subset of the 2XMM fields at high Galactic latitudes.
relationship and results for a carefully
selected subset of the 2XMM fields at high Galactic latitudes.
![\begin{figure}
\par\includegraphics[width=8.5cm,clip]{10534f9.eps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img166.gif) |
Figure 9:
Top: distribution of point source fluxes for the 2XMM catalogue
in the soft (red), hard (blue), and total band (green) energy bands. The
targets of the individual XMM-Newton observations are excluded from these
distributions (see Sect. C.1). Detections selected for these
distributions have likelihood |
| Open with DEXTER | |
The significance of the source detection in the 2XMM catalogue is
characterised by the maximum likelihood parameter for the detection, L(cf. Sect. 4.4.3). Although the detection likelihood
values are formally defined in terms of the probability of the detection
occurring by chance, the complexity of the data processing implies that the
computed likelihoods need to be carefully assessed.
To investigate the calibration of the likelihood values and the
expected false detection rate, we thus carried out realistic Monte-Carlo
simulations of the 2XMM catalogue source detection and parameterisation
process. The simulations performed were chosen to represent typical
high-latitude fields without bright sources
or extended X-ray emission apart from the unresolved cosmic X-ray
background. The simulations include a particle background component and a
distribution of X-ray point sources with uniform spectral shape drawn from
a representative extragalactic
![]() relationship (e.g. Hasinger et al. 2001).
The source spectrum assumed is a power law characterised by
relationship (e.g. Hasinger et al. 2001).
The source spectrum assumed is a power law characterised by
![]() with a Galactic
column density
with a Galactic
column density
![]() .
.
The simulation creates images (and exposure maps etc.) in the five
standard energy bands using the appropriate calibration information (i.e.,
energy- and position-dependent PSFs, vignetting, detection efficiency,
etc.). The simulated data are then processed with exactly the same steps
used in the actual 2XMM pipeline (Sect. 4) and the derived
source parameters, such as likelihoods, were compared with the input (i.e.,
simulated) parameters.
![\begin{figure}
\par\includegraphics[angle=270,width=8.5cm,clip]{10534f10.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img167.gif) |
Figure 10:
The number of false detections per field estimated via simulations for
typical high Galactic latitude fields as a function of
|
| Open with DEXTER | |
Figure 10 shows the number of false
detections per field derived from the simulations as a function of the
minimum L for three different exposure times: 12 ks for MOS and
8 ks for pn, corresponding to around 70% of the median exposure, and
three and ten times higher exposure values. Also shown is the expected
false detection number n for an assumed
![]() independent
detection cells per field, calculated simply as
independent
detection cells per field, calculated simply as
![]() .
The value of
.
The value of ![]() of course depends on the effective
``beam-size'' for EPIC observations. The value
of course depends on the effective
``beam-size'' for EPIC observations. The value
![]() we adopt is
based on the area of the search box (
we adopt is
based on the area of the search box (
![]() ,
Sect. 4.4.1), corrected downwards to take into account
the degradation and change of shape of the PSF off-axis. This value is
a factor
,
Sect. 4.4.1), corrected downwards to take into account
the degradation and change of shape of the PSF off-axis. This value is
a factor ![]() times less than would be derived from assuming
the beam-size is of the order the PSF width (e.g. 15
times less than would be derived from assuming
the beam-size is of the order the PSF width (e.g. 15
![]() HEW),
highlighting that this is a poorly defined quantity.
HEW),
highlighting that this is a poorly defined quantity.
The results shown in Fig. 10
demonstrate: (i) the number of false detections per field is low even
for ![]() ;
(ii) the dependence of the number of false detections
on L is much flatter than simple expectations; (iii) the number of
false detections depends on the exposure time.
;
(ii) the dependence of the number of false detections
on L is much flatter than simple expectations; (iii) the number of
false detections depends on the exposure time.
For typical observations included in the catalogue (represented by the
red curve in Fig. 10), the number
of false detections is ![]() [1,0.3, 0.1] per field at likelihood
limits of
[1,0.3, 0.1] per field at likelihood
limits of
![]() respectively. These values increase to
respectively. These values increase to ![]() [4, 2, 1.5] for the longest exposure time represented in
Fig. 10. For each of the three
exposure times adopted, we also compared the numbers of false
detections with the average number of sources detected in
corresponding exposures of typical XMM-Newton high Galactic latitude
fields, i.e.
[4, 2, 1.5] for the longest exposure time represented in
Fig. 10. For each of the three
exposure times adopted, we also compared the numbers of false
detections with the average number of sources detected in
corresponding exposures of typical XMM-Newton high Galactic latitude
fields, i.e. ![]() [60, 100, 200] sources per field, to derive false
detection rates. We find that these rates have only a small
dependence on the exposure time, i.e. the false detection rate is
approximately constant at
[60, 100, 200] sources per field, to derive false
detection rates. We find that these rates have only a small
dependence on the exposure time, i.e. the false detection rate is
approximately constant at ![]() [2, 1, 0.5]% for likelihood limits
[2, 1, 0.5]% for likelihood limits
![]() over the range of exposures investigated.
over the range of exposures investigated.
Our simulation results can be compared with the analysis presented by Brunner et al. (2008), carried out in the
context of the very deep XMM-Newton observation of the Lockman Hole. Their simulations are for a detection approach
similar to that presented here and their results are also broadly similar (cf. their Fig. 4 which shows a qualitatively
similar dependence of false number with likelihood), albeit they are presented for different energy bands. The
number of false detections in their simulations is higher, but of course corresponds to an observation with an
exposure time ![]() 100 times longer. Brunner et al. comment that the significant difference between the simulation
results and simple expectations primarily originates in the multi-step detection procedure (which introduces two
effective detection thresholds) and the
simultaneous multi-band fitting of source positions and fluxes, both of which result in a
reduction of the effective number of independent trials. The fact that the number of false
detections depends on the exposure time is not in line with simple expectations, but is probably a
reflection of a combination of Eddington bias and source confusion effects. The much larger than expected false detection numbers at L>12 may arise from a too stringent matching criterion between the input and output sources in the simulations. Other similar studies of the false detection rate in XMM-Newton observations
include
Loaring et al. (2005) for the relatively deep XMM-Newton 13
100 times longer. Brunner et al. comment that the significant difference between the simulation
results and simple expectations primarily originates in the multi-step detection procedure (which introduces two
effective detection thresholds) and the
simultaneous multi-band fitting of source positions and fluxes, both of which result in a
reduction of the effective number of independent trials. The fact that the number of false
detections depends on the exposure time is not in line with simple expectations, but is probably a
reflection of a combination of Eddington bias and source confusion effects. The much larger than expected false detection numbers at L>12 may arise from a too stringent matching criterion between the input and output sources in the simulations. Other similar studies of the false detection rate in XMM-Newton observations
include
Loaring et al. (2005) for the relatively deep XMM-Newton 13![]() field and
Cappelluti et al. (2007) for the COSMOS field. Both studies determined false detection rates which are
somewhat higher than our estimates for 2XMM, but these can be reconciled with detailed differences in the
assumptions made in these studies.
field and
Cappelluti et al. (2007) for the COSMOS field. Both studies determined false detection rates which are
somewhat higher than our estimates for 2XMM, but these can be reconciled with detailed differences in the
assumptions made in these studies.
We also investigated the sensitivity of the false detection number to
the background and to the assumed spectral shape. The largest differences are an increase by a factor ![]() 2 at the lowest
likelihoods (L<8) for background conditions 3 times higher than typical. Assuming much softer or harder spectral shapes
produces a similar increase in the false detection number, again restricted to the lowest likelihood bins.
2 at the lowest
likelihoods (L<8) for background conditions 3 times higher than typical. Assuming much softer or harder spectral shapes
produces a similar increase in the false detection number, again restricted to the lowest likelihood bins.
In addition to the false detection rate and calibration of the likelihood values, these simulations also provide a means to address the issue of catalogue completeness, i.e. the effects of Poisson noise which produces a probability distribution for source detectability about the sensitivity limit. This study is beyond the scope of the current paper, but we note that completeness corrections relating to these source detection biases are expected to be small except at the lowest fluxes, cf. Georgakakis et al. (2008).
The simulation work also allows us to address the astrometric performance
of the processing. Comparison of the input and output positions shows that:
(i) there is no measurable average offset; (ii) the distribution of
position offsets closely follows the expected statistical form (cf. Sect. 9.5), validating the statistical position error
estimates. This distribution does, however, show offsets that are
statistically too large for simulated sources with position errors
![]()
![]() .
The origin of this effect is unclear, although it may
be related to the discrete sampling of the PSF representation
in the XMM-Newton calibration data.
.
The origin of this effect is unclear, although it may
be related to the discrete sampling of the PSF representation
in the XMM-Newton calibration data.
Full details of the evaluation of the 2XMM catalogue with the simulations will be presented elsewhere (Sakano et al., in preparation).
In order to investigate the overall astrometric accuracy of the 2XMM catalogue, in particular the extent to which the position error estimates
correctly describe the true positional uncertainty, we tested the catalogue
positions against the Sloan Digital Sky Survey (SDSS) DR5 Quasar Catalog
(Schneider et al. 2007) which contains 77 429 objects classified as
quasars by their SDSS optical spectra. The sky density of the Sloan quasars
is ![]() 10 per square degree, and their positional accuracy is better
than
10 per square degree, and their positional accuracy is better
than
![]() ,
making this an excellent astrometric reference set. This
approach has the advantage that XMM-Newton is expected to detect a large
fraction of all Sloan quasars in X-rays (especially at the bright magnitude
limit for SDSS spectroscopy) and thus, a priori, it seems safe to
assume that essentially all positional matches are actually real
associations and that the SDSS provides the true celestial position of the
object.
,
making this an excellent astrometric reference set. This
approach has the advantage that XMM-Newton is expected to detect a large
fraction of all Sloan quasars in X-rays (especially at the bright magnitude
limit for SDSS spectroscopy) and thus, a priori, it seems safe to
assume that essentially all positional matches are actually real
associations and that the SDSS provides the true celestial position of the
object.
To carry out the analysis, the 2XMM catalogue was cross-correlated with the
DR5 Quasar Catalog, keeping all matches within
![]() .
This produced
around 1600 matches, corresponding to 1121 unique 2XMM sources. The total
sky area for the matches (out to
.
This produced
around 1600 matches, corresponding to 1121 unique 2XMM sources. The total
sky area for the matches (out to
![]() radius) was
radius) was
![]() 0.2 deg2. Given the sky density of Sloan quasars this
translates to
0.2 deg2. Given the sky density of Sloan quasars this
translates to ![]() 2 false matches overall, or
2 false matches overall, or ![]() 0.5 false matches
if we use just the inner
0.5 false matches
if we use just the inner
![]() of the distributions. We can thus be
confident that the false match rate is negligible for this
investigation. This is the real advantage of using Sloan quasars over other
comparison catalogues.
of the distributions. We can thus be
confident that the false match rate is negligible for this
investigation. This is the real advantage of using Sloan quasars over other
comparison catalogues.
For the astrometry evaluation a subset of these matches was used with
detection likelihood ![]() ,
summary flag 0, off-axis angle
<
,
summary flag 0, off-axis angle
<
![]() ,
and excluding extended sources. These selections reduce the
total number of detection matches to 1007 (corresponding to 656 unique
sources).
,
and excluding extended sources. These selections reduce the
total number of detection matches to 1007 (corresponding to 656 unique
sources).
Figure 11 shows the distribution of the X-ray/optical position
separations for each match for both the corrected and uncorrected 2XMM
coordinates. As can be seen, the uncorrected separations peak at
![]()
![]() and show a broad distribution out to
and show a broad distribution out to
![]() ,
whereas the corrected separations peak at <
,
whereas the corrected separations peak at <
![]() and show a narrower
spread. This result of course reflects the overall success of the
astrometric rectification carried out as part of the processing
(Sect. 4.5).
and show a narrower
spread. This result of course reflects the overall success of the
astrometric rectification carried out as part of the processing
(Sect. 4.5).
To make a more detailed comparison of the observed and expected
distributions, we consider the separations normalised by the position
errors. If we define
![]() where
where ![]() is
the angular separation and
is
the angular separation and
![]() is the total position
error, the expected distribution function N(x) takes the form
is the total position
error, the expected distribution function N(x) takes the form
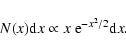
Figure 11 (centre) shows the distribution, for corrected
XMM-Newton coordinates only, of the X-ray/optical position separation
sigmas (i.e.,
![]() )
for the matched detection
sample assuming
)
for the matched detection
sample assuming
![]() .
Although the observed distribution
is reasonably close to the expected form at low x-values, there is a long
tail of outliers at x >3.7 amounting to
.
Although the observed distribution
is reasonably close to the expected form at low x-values, there is a long
tail of outliers at x >3.7 amounting to ![]() 8% of the total sample,
whereas we would expect <0.1% to lie at x >3.7. More detailed
investigation of these outliers shows that they are dominated by sources
with low
8% of the total sample,
whereas we would expect <0.1% to lie at x >3.7. More detailed
investigation of these outliers shows that they are dominated by sources
with low
![]() -values (mostly <
-values (mostly <
![]() ), clearly
indicating the need for an additional component,
), clearly
indicating the need for an additional component,
![]() ,
of
the order
,
of
the order
![]() .
.
![\begin{figure}
\par\includegraphics[angle=270,width=7cm,clip]{10534f11a.ps}\par\...
...ace*{2mm}
\includegraphics[angle=270,width=7cm,clip]{10534f11c.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img187.gif) |
Figure 11:
Top: X-ray/optical position separation for each match for the
corrected (solid histogram) and uncorrected (dashed histogram) XMM-Newton
coordinates. Centre: distribution of separation sigma (x) for
|
| Open with DEXTER | |
We investigated a range of possible values of
![]() and
found that
and
found that
![]() provides the best overall fit
between the observed and expected distributions, as is shown in
Fig. 11 (bottom). For this choice of
provides the best overall fit
between the observed and expected distributions, as is shown in
Fig. 11 (bottom). For this choice of
![]() there
are still more outliers at large x-values than expected if the position
errors were perfectly described, but we find that at least some of these
can be explained on astrophysical grounds (e.g., source confusion, lensed
objects), so regard our choice as the best overall value to represent the
global additional error estimate for the catalogue.
there
are still more outliers at large x-values than expected if the position
errors were perfectly described, but we find that at least some of these
can be explained on astrophysical grounds (e.g., source confusion, lensed
objects), so regard our choice as the best overall value to represent the
global additional error estimate for the catalogue.
A detailed comparison between the observed and expected distributions
(Fig. 11) shows that there is a deficit of points at low
x-values and indeed this is true for any
![]() .
This
indicates that the true value of the statistical position error,
.
This
indicates that the true value of the statistical position error,
![]() ,
is slightly overestimated by the fitting routine.
Attempts to model this effect with a simple rescaling of the
,
is slightly overestimated by the fitting routine.
Attempts to model this effect with a simple rescaling of the
![]() -value were not successful. We note that the typical
error estimate of the rectification of the XMM coordinates is
-value were not successful. We note that the typical
error estimate of the rectification of the XMM coordinates is
![]()
![]() with a spread from
with a spread from
![]() to >
to >
![]() .
This
suggests that most of the additional error component needed is related to
the rectification residuals, with other effects being at a lower
level. An obvious alternative approach is thus to use the explicit values
of the errors determined by the rectification algorithm for
.
This
suggests that most of the additional error component needed is related to
the rectification residuals, with other effects being at a lower
level. An obvious alternative approach is thus to use the explicit values
of the errors determined by the rectification algorithm for
![]() (which thus vary from field to field and indeed from
source to source if the error in the field rotation is taken into account)
instead of the empirically determined - and fixed value - described
above. Overall this approach gives similar results, but gives x-values
which are systematically significantly too low, implying the
uncertainties derived by the rectification algorithm may also be
significantly over-estimated (by up to 50%). We conclude that using a
fixed value of the additional error provides the best empirical description
of the data. On this basis the value
(which thus vary from field to field and indeed from
source to source if the error in the field rotation is taken into account)
instead of the empirically determined - and fixed value - described
above. Overall this approach gives similar results, but gives x-values
which are systematically significantly too low, implying the
uncertainties derived by the rectification algorithm may also be
significantly over-estimated (by up to 50%). We conclude that using a
fixed value of the additional error provides the best empirical description
of the data. On this basis the value
![]() was
adopted for the 2XMM catalogue. The total position error given in the
catalogue,
was
adopted for the 2XMM catalogue. The total position error given in the
catalogue,
![]() ,
combines the statistical and additional
errors in quadrature, see Eq. (5). We note that the effect
described here may be identical to that discovered through the simulation
work described in Sect. 9.4. If this is the case it would
imply that the residual errors associated with the rectification must
indeed be rather lower than the formal estimated values overall.
,
combines the statistical and additional
errors in quadrature, see Eq. (5). We note that the effect
described here may be identical to that discovered through the simulation
work described in Sect. 9.4. If this is the case it would
imply that the residual errors associated with the rectification must
indeed be rather lower than the formal estimated values overall.
Table 9: Summary of the statistical comparison of the 2XMM fluxes from the EPIC cameras.
We repeated the analysis described above for the uncorrected XMM
coordinates to determine the
![]() -value appropriate to
those XMM-Newton fields for which astrometric rectification was not
possible (see Sect. 4.5). For the uncorrected XMM-Newton
coordinates we determine a good fit between the observed and expected
distributions for
-value appropriate to
those XMM-Newton fields for which astrometric rectification was not
possible (see Sect. 4.5). For the uncorrected XMM-Newton
coordinates we determine a good fit between the observed and expected
distributions for
![]() .
This value is adopted in
the catalogue for sources in those fields for which astrometric
rectification was not possible.
.
This value is adopted in
the catalogue for sources in those fields for which astrometric
rectification was not possible.
For completeness we looked for possible correlations between outliers and
the obvious XMM-Newton detection parameters (e.g., detection likelihoods,
off-axis angle). Rather surprisingly no clear correlations were found,
except with off-axis angle where it was noted that detections at very high
off-axis values (>
![]() )
were somewhat more likely to have
statistically too large separations. By no means all high off-axis
detections are affected in this way, however. Essentially this means that
the statistical position error estimates are robust over a very wide range
of detection parameters and a single additional error component provides a
very adequate representation of the data. Finally we note that properties
of the 2XMM/Sloan DR5 Quasar sample are reasonably representative of the
whole 2XMM catalogue. There is a bias towards higher X-ray fluxes and thus
lower statistical position errors, but a significant number of lower flux
objects are included and the full range of total counts and likelihoods is
sampled.
)
were somewhat more likely to have
statistically too large separations. By no means all high off-axis
detections are affected in this way, however. Essentially this means that
the statistical position error estimates are robust over a very wide range
of detection parameters and a single additional error component provides a
very adequate representation of the data. Finally we note that properties
of the 2XMM/Sloan DR5 Quasar sample are reasonably representative of the
whole 2XMM catalogue. There is a bias towards higher X-ray fluxes and thus
lower statistical position errors, but a significant number of lower flux
objects are included and the full range of total counts and likelihoods is
sampled.
We have evaluated the flux cross-calibration of the XMM-Newton EPIC cameras based on the calibration used to compute 2XMM fluxes (see Sect. 4.6). To do this we performed a statistical analysis, comparing the fluxes between cameras for sources common to both, selected from the entire FOV. The parameter used to quantify the difference in flux was defined as (Si-Sj)/Sj, where Si and Sj are the fluxes of the sources in each pair of cameras (i,j).
To minimise the impact of other effects, we performed the following filtering on the comparison samples:
There is an excellent agreement in the measured fluxes between the two MOS
cameras, better that 5% in all 2XMM energy bands. The agreement between
pn-MOS fluxes is also good, better than 10% at energies below 4.5 keV
and ![]() 10-12% above 4.5 keV. These flux differences are in broad
agreement with the results of Stuhlinger et al. (2008) who find a small
excess, 5-10%, of the MOS cameras with respect to pn, using a sample of
very bright on-axis sources. A more detailed analysis will be presented in
Mateos et al. (2008).
10-12% above 4.5 keV. These flux differences are in broad
agreement with the results of Stuhlinger et al. (2008) who find a small
excess, 5-10%, of the MOS cameras with respect to pn, using a sample of
very bright on-axis sources. A more detailed analysis will be presented in
Mateos et al. (2008).
For each 2XMM source there are four X-ray hardness ratios (X-ray ``colours'') which provide a crude representation of the X-ray spectrum (cf. Sect. 4.4.3 for hardness ratio definition). In Fig. 12 we show the hardness ratio density plots for 2XMM catalogue sources at high and low Galactic latitudes. These plots are for the pn camera hardness ratios only, as they typically are better constrained. Density plots are constructed for sources which have detection likelihood L>8 in the energy bands comprising each pair of hardness ratios: this means that the subsample included in each plot differs and there is an inevitable bias towards softer sources for the HR1-HR2 plot and to harder sources for the HR3-HR4 plot. Imposing the same likelihood threshold for all bands would produce a bias towards higher flux sources and in fact would restrict this exercise to relatively small samples from the whole catalogue. We also exclude sources with summary flag 4; a more severe restriction on the flag produces relatively small changes to the overall distributions. Overlaid on these hardness ratio density plots are spectral tracks for representative simple power law and thermal spectral models with a range of absorbing column densities.
These density plots provide an excellent statistical characterisation of the spectral properties of the catalogue sources, thus potentially providing constraints on the overall X-ray population. Although a detailed analysis is beyond the scope of the present paper, we comment here on how these match simple expectations about the underlying source populations.
![\begin{figure}
\par\includegraphics[width=6cm,angle=270]{10534f12a.ps}\includegr...
...0]{10534f12e.ps}\includegraphics[width=6cm,angle=270]{10534f12f.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img213.gif) |
Figure 12:
Top row: EPIC pn X-ray hardness ratio density plots for high
Galactic latitude (
|
| Open with DEXTER | |
For the high latitude regions of the sky, the density plot is dominated by
sources with power-law spectra and column densities
![]() ,
as expected from the dominant population of AGN. The
fraction of AGN in 2XMM with
,
as expected from the dominant population of AGN. The
fraction of AGN in 2XMM with
![]() can be seen
from these plots to be quite low. The high latitude plots also show an
extension to much softer hardness ratios. The main contributors to this are
likely to be coronally active stars and non-active galaxies (see comment
below about the thermal spectra). Due to the bias towards softer (harder)
sources in the HR1-HR2 (HR3-HR4) plots noted above, the power-law tracks
overlaid have different indices to approximately match the observed density
distributions.
can be seen
from these plots to be quite low. The high latitude plots also show an
extension to much softer hardness ratios. The main contributors to this are
likely to be coronally active stars and non-active galaxies (see comment
below about the thermal spectra). Due to the bias towards softer (harder)
sources in the HR1-HR2 (HR3-HR4) plots noted above, the power-law tracks
overlaid have different indices to approximately match the observed density
distributions.
At low Galactic latitudes, in contrast, the plots show a more complex
structure (albeit the sample sizes are smaller). The overall low latitude
density pattern is consistent with a large population of coronally active
stars (particularly evident in the HR1-HR2 plot) with relatively soft
thermal spectra together with a significant population of much more
absorbed objects: background AGN together with distant accreting binaries
in the Galactic plane (e.g., Hands et al. 2004). Sources with very
low-temperature thermal spectra (i.e.,
![]() keV) are only evident
as a small component in the HR1-HR2 plot. We note that the density peak in
the low latitude density plots is not consistent with what is
expected for a distribution of single-temperature thermal spectra with a
range of intrinsic temperatures. Instead the peak is much better matched by
a multi-temperature spectrum which we have here characterised
empirically as a composite three-component model with
kT=[0.3, 1, 3] keV
with equal weighting (emission measure) of the three components. This
finding is broadly consistent with the spectral properties of X-ray
selected active star samples (e.g., Lopez-Santiago et al. 2007, and
references therein) in which such objects typically are best-fit with
two-temperature models with
keV) are only evident
as a small component in the HR1-HR2 plot. We note that the density peak in
the low latitude density plots is not consistent with what is
expected for a distribution of single-temperature thermal spectra with a
range of intrinsic temperatures. Instead the peak is much better matched by
a multi-temperature spectrum which we have here characterised
empirically as a composite three-component model with
kT=[0.3, 1, 3] keV
with equal weighting (emission measure) of the three components. This
finding is broadly consistent with the spectral properties of X-ray
selected active star samples (e.g., Lopez-Santiago et al. 2007, and
references therein) in which such objects typically are best-fit with
two-temperature models with
![]() keV. The fact that our
hardness density plots are better characterised with the ad hoc
addition of a third higher temperature component clearly points to a harder
component being present in a significant number of the objects contributing
to the hardness density plots.
keV. The fact that our
hardness density plots are better characterised with the ad hoc
addition of a third higher temperature component clearly points to a harder
component being present in a significant number of the objects contributing
to the hardness density plots.
In the whole 2XMM catalogue there are 2307 detections indicated as variable
(cf. Sect. 8), which relate to 2001 unique
sources. Evaluation of the frequency distributions of the
![]() -probability,
-probability, ![]() ,
from the time-series analysis reveals no
significant systematic effects and shows the expected behaviour for the
parts of the distributions dominated by random noise. For example, the
frequency distribution of
,
from the time-series analysis reveals no
significant systematic effects and shows the expected behaviour for the
parts of the distributions dominated by random noise. For example, the
frequency distribution of ![]() ,
as shown in Figs. 13b
and c for the pn (the distributions for MOS1 and MOS2 are very similar),
is almost constant per unit interval of probability down to low
probabilities (
,
as shown in Figs. 13b
and c for the pn (the distributions for MOS1 and MOS2 are very similar),
is almost constant per unit interval of probability down to low
probabilities (![]() 0.1). Obviously, a non-variable set of time-series
would have this property across the whole probability range 0.0-1.0.
0.1). Obviously, a non-variable set of time-series
would have this property across the whole probability range 0.0-1.0.
![\begin{figure}
\par\includegraphics[width=4.5cm,angle=270]{10534f13a.ps}\include...
...{10534f13b.ps}\includegraphics[width=4.5cm,angle=270]{10534f13c.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img219.gif) |
Figure 13:
a) Frequency distribution of
|
| Open with DEXTER | |
Figure 13a shows the observed frequency distribution of
![]() compared with a simulated distribution for a
non-variable set of time-series. As there are many detections with less
than the full set of [pn, M1, M2] time-series, it was necessary to
reproduce this incompleteness in the simulation. The numbers of detections
with 3, 2, 1, or 0
compared with a simulated distribution for a
non-variable set of time-series. As there are many detections with less
than the full set of [pn, M1, M2] time-series, it was necessary to
reproduce this incompleteness in the simulation. The numbers of detections
with 3, 2, 1, or 0 ![]() -values are: 14 917, 11 330, 11 917, 156,
respectively. The simulation was conducted by generating three vectors
representing pn, M1, M2, with each element containing a uniform, random
number in the range 0.0-1.0. For each element, a check was performed to
see if there was a valid
-values are: 14 917, 11 330, 11 917, 156,
respectively. The simulation was conducted by generating three vectors
representing pn, M1, M2, with each element containing a uniform, random
number in the range 0.0-1.0. For each element, a check was performed to
see if there was a valid ![]() -value for the associated, real camera
data; if not, the random value was set to NULL (so that the correct `run'
of valid values was mimicked in the simulations). These values simulate the
expected distribution of [pn, M1, M2]-probabilities for the case of no real
variability (see Fig. 13a). As expected, the resulting
distributions are ``flat'' (on a linear scale), as discussed above. A fourth
vector was then computed with the minimum simulated
-value for the associated, real camera
data; if not, the random value was set to NULL (so that the correct `run'
of valid values was mimicked in the simulations). These values simulate the
expected distribution of [pn, M1, M2]-probabilities for the case of no real
variability (see Fig. 13a). As expected, the resulting
distributions are ``flat'' (on a linear scale), as discussed above. A fourth
vector was then computed with the minimum simulated ![]() ,
i.e., a
simulated set of
,
i.e., a
simulated set of
![]() )
over all available values for each
detection.
)
over all available values for each
detection.
Visual inspection of samples of time-series flagged as not variable, indicated a number of cases and types of variability that were likely to have been ``missed'' by the 2XMM variability test, implying that the catalogue is conservative in this respect. These included relatively short-duration increases or decreases, and low-level trends/ramps.
We have compared the fraction of variable sources (or detections) to all
sources (or detections) having time-series as a function of various other
parameters of the catalogue. As a function of flux (specifically EPIC
total-band flux), we find this fraction to be ![]()
![]() %, and 5%
for fluxes
%, and 5%
for fluxes ![]() 10-10,
10-10, ![]() 10-11, and
10-11, and ![]() 10-12,
respectively. This is broadly as expected as the ability to detect
variability falls towards lower fluxes.
10-12,
respectively. This is broadly as expected as the ability to detect
variability falls towards lower fluxes.
We have also carried out an initial evaluation of the variable 2XMM sources
using secure positional matches with objects in the Simbad database. From
this study we estimate that, for serendipitous (i.e., non-target) sources,
![]() 40% are ``normal'' (i.e., non-degenerate) stars,
40% are ``normal'' (i.e., non-degenerate) stars, ![]() 5% are
X-ray binaries,
5% are
X-ray binaries, ![]() 3% are cataclysmic variables and
3% are cataclysmic variables and ![]() 5% are
AGNs, plus lower percentages of objects such as GRBs. Of order 45% could
not be identified from Simbad. The above figures relate primarily to the
5% are
AGNs, plus lower percentages of objects such as GRBs. Of order 45% could
not be identified from Simbad. The above figures relate primarily to the ![]() 1000 sources with quality summary flag values 0-2. Although
this is not a definitive study as the completeness of Simbad for different
object types is highly non-uniform, it does nevertheless provide
confirmation of the utility of the catalogue variability characterisation
to select known types of variable objects efficiently.
1000 sources with quality summary flag values 0-2. Although
this is not a definitive study as the completeness of Simbad for different
object types is highly non-uniform, it does nevertheless provide
confirmation of the utility of the catalogue variability characterisation
to select known types of variable objects efficiently.
The 2XMM catalogue contains more than 20 000 entries of extended detections. The reliable detection and parameterisation of extended sources is significantly more demanding than for point-like sources because there are many more degrees of freedom in the parameter space. The relatively simple analysis approach used in the creation of the catalogue (Sect. 4.4.4) means that the catalogue contains a significant number of extended object detections that are either spurious or at least uncertain (cf. Sects. 7.2 and 7.3). The most common causes of problems with extended sources are summarised below and illustrated in Fig. 14.
![\begin{figure}
\par\includegraphics[width=17.5cm,clip]{10534f14.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img222.gif) |
Figure 14:
Examples of extended source detections. Green circles mark point
source detections. In panels (i)-(vi) the magenta and yellow circles
mark real and spurious extended detections respectively, plotted with
their fitted extent (i.e., core radius, see Sect. 4.4.4). In
panels (vii) and (viii) the yellow ellipses indicate the position of
spurious extended source detections.
Top row: (i) a compact extended source with a small core radius; (ii) a large, low surface brightness extended source at the edge of the FOV
with low likelihood but high flux (see Fig. 15); (iii) an
object with a point-like core detected both as a point source as well as
an extended source; (iv) a clearly extended source with a spurious
detection nearby (yellow circle) which is smaller and fainter (by a
factor of 45) and which therefore does not significantly affect the
parameters of the real source.
Bottom row: (v) a SNR in the LMC where intrinsic structure is
detected as point sources (note that the core radius is not
representative as the extended emission does not follow the |
| Open with DEXTER | |
Figure 15 illustrates some of the main features of the extended source detections in the catalogue. The plot shows that there is, as expected, an overall correlation of extent likelihood with EPIC flux. The considerable scatter in the plot has three origins: (i) the observations from which the detections are drawn have a considerable range of exposure times and background values; (ii) source extent: sources with larger spatial extent have lower likelihoods at the same integrated flux; (iii) the presence of significant numbers of spurious detections. The detections with Flag 7 set show, as expected, a broader distribution than those without this flag, and a much broader distribution than for the detections with ``best'' summary flags (i.e., summary flag <2). This is, of course, due to the fact that spurious detections will often have implausible likelihoods for the fitted flux or correspond to very large source extent which is rare in genuine detections.
![\begin{figure}
\par\includegraphics[angle=270,width=8.5cm,clip]{10534f15.ps}
\end{figure}](/articles/aa/full/2009/01/aa10534-08/img224.gif) |
Figure 15:
Distribution of extent likelihood as a function of total-band
EPIC flux for the extended source detections in the 2XMM catalogue. Red
dots are potentially spurious detections with Flag 7 = T, yellow dots are
detections with Flag 7 = F, black dots are the ``best'' sample detections with
summary flag <2. Green stars mark the targets of the XMM-Newton
observations classified as extended object types and blue squares targets
which are object types classified as point-like. The vertical
concentrations of target points at flux |
| Open with DEXTER | |
Based on the sample with ``best'' summary flags it is clear that there are
very few reliable extended source detections with extent likelihood above
![]() 1000 or flux above
1000 or flux above ![]()
![]() ,
highlighting the problems that the
detection algorithm has with bright objects
,
highlighting the problems that the
detection algorithm has with bright objects![]() . Indeed the majority of reliable extended objects in
this region of the diagram are the XMM-Newton targets themselves (but note
that many of these have Flag 7 set which would otherwise indicate
potentially spurious detections). At the highest fluxes a large fraction of
the detections relate to very bright point-like targets that are
incorrectly parameterised as being extended due the deficiencies of the
fitting algorithm noted above.
. Indeed the majority of reliable extended objects in
this region of the diagram are the XMM-Newton targets themselves (but note
that many of these have Flag 7 set which would otherwise indicate
potentially spurious detections). At the highest fluxes a large fraction of
the detections relate to very bright point-like targets that are
incorrectly parameterised as being extended due the deficiencies of the
fitting algorithm noted above.
We have investigated a small subset of the extended detections at high
Galactic latitudes covered by SDSS DR6 (excluding targets). We selected
detections with extent likelihood >100 and no warning flags set (i.e.,
summary flag 0) and evaluated their validity by examining the X-ray images
visually and by searching for matches with catalogued objects. We find that
less than 5% of these may be spurious extended source detections, around
40% are clearly associated with catalogued clusters or groups of galaxies
and a few percent are associated with single nearby galaxies. For a
further ![]() 30% of the detections we find convincing evidence of a
previously uncatalogued cluster or group of galaxies at the X-ray source
location from visual inspection of the SDSS DR6 images. These results
demonstrate that the overall reliability of the ``best'' extended source
sample is high, at least at higher likelihoods, and that, as expected, the
extended source sample is dominated by groups and clusters of galaxies. We
have not carried out a similar exercise systematically at low Galactic
latitudes but checks of selected detections demonstrate the expected
associations with SNRs, HII regions, and discrete extended features in the
Galactic Centre region.
30% of the detections we find convincing evidence of a
previously uncatalogued cluster or group of galaxies at the X-ray source
location from visual inspection of the SDSS DR6 images. These results
demonstrate that the overall reliability of the ``best'' extended source
sample is high, at least at higher likelihoods, and that, as expected, the
extended source sample is dominated by groups and clusters of galaxies. We
have not carried out a similar exercise systematically at low Galactic
latitudes but checks of selected detections demonstrate the expected
associations with SNRs, HII regions, and discrete extended features in the
Galactic Centre region.
The 2XMM catalogue table itself is essentially a flat file with 246 897 rows and 297 columns (described in Appendix D). Access to the catalogue file in various formats (FITS and comma-separated-variable [CSV]) is available from the XMM-SSC catalogues web-page: http://xmmssc-www.star.le.ac.uk/Catalogue/. This XMM-SSC web-page is the primary location for information about the 2XMM catalogue. It provides links to the other hosting sites and the documentation for the catalogue. It also provides a ``slimline'', reduced volume version of the 2XMM catalogue, which is based on the 191 870 unique sources and contains just 39 columns. The columns in this version are restricted to just the merged source quantities, together with the 1XMM and 2XMMp cross-correlation counterparts.
Ancillary tables to the catalogue also available from the XMM-SSC web-page include the table of observations incorporated in the catalogue (Appendix B) and the target identification and classification table (Appendix C).
Associated with the 2XMM catalogue itself is an extensive range of data
products such as the EPIC images from each observation and the spectra and
time-series data described in Sect. 5. These products are accessible,
along with the catalogue itself, from ESA's XMM Science Archive
(XSA![]() ), the
LEDAS
), the
LEDAS![]() (LEicester
Database and Archive Service) system and
are being made available through the Virtual Observatory via LEDAS using
AstroGrid
(LEicester
Database and Archive Service) system and
are being made available through the Virtual Observatory via LEDAS using
AstroGrid![]() infrastructure.
infrastructure.
LEDAS also provides access to a single HTML summary page for each detected source in the catalogue. These summary pages provide the key detection parameters and parameters of the corresponding unique source, links to other detections of the same source, thumbnail X-ray images and graphical summaries of the X-ray time-series and spectral data where these exist.
The results of the external catalogue cross-correlation carried out for the
2XMM catalogue (Sect. 6) are available as data products
within the XSA and LEDAS or through a dedicated on-line database system
hosted by the Observatoire de Astrophysique,
Strasbourg![]() .
.
We have presented the 2XMM catalogue, described how the catalogue was produced and discussed the main characteristics of the catalogue. Table 10 provides a summary of its main properties, bringing together information presented elsewhere in this paper.
Table 10: Summary of 2XMM catalogue characteristics.
2XMM is the largest X-ray source catalogue ever produced, containing almost twice as many discrete sources as either the ROSAT survey or ROSAT pointed catalogues. The catalogue complements deeper Chandra and XMM-Newton small area surveys, and probes a large sky area at the flux limit where the bulk of the objects that contribute to the X-ray background lie. The catalogue has very considerable potential, a detailed account of which lies outside the scope of this paper. In particular the catalogue provides a rich resource for generating sizeable, well-defined samples for specific studies, utilising the fact that X-ray selection is a highly efficient (arguably the most efficient) way of selecting certain types of object, notably active galaxies (AGN), clusters of galaxies, interacting compact binaries and active stellar coronae. The large sky area covered by the serendipitous survey, or equivalently the large size of the catalogue, also means that 2XMM is a major resource for exploring the variety of the X-ray source population and identifying rare source types. Although the 2XMM catalogue alone provides a powerful way of studying the X-ray source population, matching the X-ray data with, e.g., optical catalogues can offer an even more effective way to generate considerable samples of particular object types. Projects that exploit some of these characteristics are already underway.
Finally we note that, since the XMM-Newton spacecraft and instruments
remain in good operational health, we can anticipate a substantial growth
in the pool of serendipitous X-ray sources detected, increasing at a rate
of ![]() 35 000 sources/year. With this backdrop, further XMM-Newton
catalogue releases are planned at regular intervals. The first such
incremental release is planned for August 2008.
35 000 sources/year. With this backdrop, further XMM-Newton
catalogue releases are planned at regular intervals. The first such
incremental release is planned for August 2008.
Acknowledgements
We gratefully acknowledge the contributions to this project made by our colleagues at the XMM-Newton Science Operations Centre at ESA's European Space Astronomy Centre (ESAC) in Spain. We thank Steve Sembay for useful comments and the CDS team for their active contribution and support.M. Ceballos, F. Carrera and X. Barcons acknowledge financial support by the Spanish Ministerio de Educacion y Ciencia under projects ESP2003-00812 and ESP2006-13608-C02-01. The French teams are grateful to CNES for supporting this activity. In Germany the XMM-Newton project is supported by the Bundesministerium für Wirtschaft und Technologie/Deutsches Zentrum für Luft und Raumfahrt e.V. (DLR) and the Max Planck Society. Part of this work was supported by the DLR project numbers 50 OX 0201, 50 OX 0001, and 50 OG 0502. The Italian team acknowledges financial support from the Agenzia Spaziale Italiana (ASI), the Ministero dell' Istruzione, Università e Ricerca (MIUR) and the Istituto Nazionale di Astrofisica (INAF) over the last years; they are currently supported by the grant PRIN-MIUR 2006-02-5203 and by the ASI grants n.I/088/06/0 and n.I/023/05/0. UK authors thank STFC for financial support.
This research has made use of the NASA/IPAC Extragalactic Database (NED), which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration. This research has also made use of the SIMBAD database, of the VizieR catalogue access tool, and of Aladin, operated at CDS, Strasbourg, France, and of the Digitized Sky Surveys (produced at the Space Telescope Science Institute under U.S. Government grant NAG W-2166).
Table D.1 presents the observations and exposures included in 2XMM and is available at the CDS as well as at the XMM-SSC catalogue web-page (cf. Sect. 10). The columns in this table are as follows.
Column 1: satellite revolution number (consecutive in time).
Column 2: observation number (10 digit ID).
Column 3: ODF version number.
Columns 4 and 5: nominal field right ascension and declination (J2000) in degrees.
Column 6: target name (20 characters).
Column 7: quality classification of the whole observation based on
the area flagged as bad in the manual flagging process as compared to the
whole detection area, see Sect. 7.4. 0 means nothing has been
flagged; 1 indicates that 0% < area < 0.1% of the total detection
mask has been flagged; 2 indicates that 0.1% ![]() area < 1% has been
flagged; 3 indicates that 1%
area < 1% has been
flagged; 3 indicates that 1% ![]() area < 10% has been flagged; 4
indicates that 10%
area < 10% has been flagged; 4
indicates that 10% ![]() area < 100% has been flagged; and 5 means that
the whole field was flagged as bad.
area < 100% has been flagged; and 5 means that
the whole field was flagged as bad.
Column 8: number of detections in this field.
Column 9: number of detections in this field that have not received manual Flag 11 and are considered to be ``good''.
Column 10: number of the pn exposures merged for the source detection (cf. Sect. 4.1).
Column 11: filter of the pn exposures: Tn1 stands for Thin1, Tn2 for Thin2, Med for Medium, and Tck for Thick.
Column 12: observing mode (cf. Table 1) of the pn exposures.
Column 13: total exposure time of the pn exposures in seconds.
Columns 14-17: same as Cols. 10-13 but for MOS1.
Columns 18-21: same as Cols. 10-13 but for MOS2.
In the following are described the procedures adopted to identify and classify the targets of each XMM-Newton observation included in the 2XMM catalogue. The results of this exercise, summarised in Table D.2, are available at the CDS as well as at the XMM-SSC catalogue web-page (cf. Sect. 10).
As any attempt to identify and classify a target is subjective and likely to be incomplete (only the investigators of that observation know all the details), two different approaches were chosen to give the user a choice regarding detail and reliability: on the one hand some formal information associated with an observation is provided; on the other hand, a manual classification scheme tries to supply interpretation of sometimes ambiguous target names and to directly identify associated 2XMM detections.
There are three kinds of coordinates associated with each observation:
The XSA coordinates are usually near the centre of the field and/or the target but do not represent the target position as well as the proposal position.
The target identification table (Appendix C.5) lists the proposal and XSA positions together with the proposal category and proposal program information as given in the XSA. The latter provide a coarse classification of the target as determined by the observer. Note though, that the proposal category of calibration observations are often meaningless since they are often instrument related for which there is no particular proposal category.
In many ways the target name as given in the proposal gives a better indication of the field content than the coordinates since a target can comprise more than one object or it may be diffuse emission that can only be detected in the spectra of background objects. In other words, if a target name can be resolved by on-line data bases like Simbad and NED one can easily derive more information about that object, e.g., object type, other names, or references.
On the other hand, an XMM-Newton target name can be descriptive or refer to a personal choice of the observer, it can be abbreviated, or additional information is added. It was therefore necessary to ``interpret'' many of the target names before Simbad could recognise them.
The target identification table lists therefore, next to the XMM-Newton
target name, the best estimate of the Simbad-recognisable name where
possible (usually very close to the given target name), together with the
Simbad coordinates![]() and Simbad
object type for classification purposes. In cases where Simbad gives more
than one object type, the one closest to the proposal category was
given. Where no Simbad name could be identified a NED identification may be
given instead, and where possible an estimated object type based on the
proposal information was given.
and Simbad
object type for classification purposes. In cases where Simbad gives more
than one object type, the one closest to the proposal category was
given. Where no Simbad name could be identified a NED identification may be
given instead, and where possible an estimated object type based on the
proposal information was given.
For the use of the catalogue, however, it is most helpful to know which and how many sources are ``targets'' and therefore not serendipitous. The observations are thus classified by their field content (i.e., target classification; see Fig. 4 for some examples), using the following categorisation:
Because neither the formal nor the manual classification can be perfect in every case, the table also lists, for quick reference, an indicator for the positions (proposal or Simbad) which best represents the target (subject to changes and improvements in Simbad). In some cases both positions were deemed to be equally viable (e.g., in field observations or large offsets of extended objects) and no preference is given in the table.
Not all targets fit unambiguously into the field content classes. In a few cases where no decision could be made the target was classified as ``unknown''. Otherwise the following guidelines were used.
In two cases, a ``field'' classification was preferred: observations of the M31 halo and offset pointings of M 33. In both cases the galaxy is considerably larger than the FOV. Note that the observations of the centre of M 31 (often called M 31 core) are classified as ``large extended'' instead since the field includes diffuse emission.
There are 3491 fields in total in the 2XMM catalogue. For 3044 fields (87%) a Simbad name could be found, and in 53 cases (1.5%) a NED identification is given. Of the remaining 394 fields only 56 (1.6%) do not have an estimated object type.
About 10% of the observations were obtained for calibration purposes, and 3% are ToO observations. Table C.1 lists the distribution of the proposal category for 2XMM observations, and Table C.2 gives the same for the field content classes. The ratio of point source to extended source to field observation is roughly 5:3:1.
For best results on identifying target objects in the catalogue, it is recommended to use both the field content class as well as the Simbad object type.
Table C.1: Proposal category given by the XSA.
Table C.2: Target / field content classification.
The columns in Table D.2, which is available at the CDS as well as at the XMM-SSC catalogue web-page (cf. Sect. 10), are as follows.
Column 1: satellite revolution number (consecutive in time).
Column 2: observation number (10 digit ID).
Column 3: a star indicates if there is a note for this observation or for this proposal-ID (first 6 digits of an observation, referring to several observations for this proposal) as detailed below.
Column 4: the source number per observation of the identified target taken from the column SRC_NUM in the catalogue.
Column 5: the detection ID of the identified target taken from the column DETID in the catalogue.
Column 6: field classification as described in Table C.2.
Column 7: coordinate preference between proposal position and Simbad position, depending on which defined the target better; in case of offset positions (usually indicated in the field name from the proposal, Col. 12) no preference is given.
Column 8: proposal category as taken from the XSA as described in Table C.1 (note that some of the calibration observations are not properly classified).
Column 9: proposal program as taken from the XSA: GO stands for Guest Observer, Cal for Calibration, ToO for Targets of Opportunity, Cha for Co-Chandra, ESO for Co-ESO, Trig for Triggered, and Large.
Columns 10 and 11: right ascension and declination (J2000) in degrees as given in the proposal (taken from the RA_OBJ and DEC_OBJ keywords in the attitude time-series file).
Column 12: field name as given in the proposal (taken from the OBJECT keyword in the calibration index file).
Columns 13 and 14: right ascension and declination (J2000) in degrees as extracted from Simbad using the Simbad name given in Col. 16.
Column 15: object type as given by Simbad. If no Simbad object is given a type was estimated. Additional types not recognised by Simbad are: XRN for X-ray reflection nebula, sfr for star forming region, plt for planet, and com for comet.
Column 16: modified field name which Simbad recognises (and can be used in a script), except for 53 cases that have a name recognised by NED (indicated with ``[ned]'' after the name). Modifications include dropping offset indicators, completing coordinates, and adjusting the prefix to a recognised convention as described in Simbad's dictionary of nomenclature.
Columns 17 and 18: right ascension and declination (J2000) in degrees as given in the XSA; they represent the prime instrument viewing direction (median value) and are corrected for the star tracker mis-alignment.
A list of observations (10 digits) or proposal-IDs (6 digits) in numerical order with special remarks as indicated in Col. 3 of the table follows.
The catalogue contains 297 columns. Each detection was observed with up to three cameras. For the source detection, the total energy range (0.2-12 keV) was split into five sub-bands as well as the XID wide-band (0.5-4.5 keV), see Table 3. As a result, some of the source parameters (like count rates or fluxes) are given for each camera and band as well as for the combined cameras (EPIC) and total band. The column names reflect this by using a two-letter prefix to indicate the camera [ca = EP, PN, M1, M2]; in case of parameters that refer to a unique source rather than an individual detection (Sect. 8.1) the prefix [SC] is used (it stands for ``source''). Following the prefix comes an energy band indicator where applicable (b = 1, 2, 3, 4, 5, 8, 9). Entries are NULL when there is no detection with the respective camera (that is, the detector coverage of the detection weighted by the PSF, MASKFRAC, <0.15).
In the following, a description for each column is given. The name is given
in capital letters, the FITS data format in brackets, and the unit in
square brackets. If the column originates from a SAS task![]() , the name of the task follows.
, the name of the task follows.
For easier reference the columns are grouped into seven sections.
Next to the various identifications, cross matches with the 1XMM and 2XMMp catalogues are given here. There are 9 columns in this section.
DETID (J): a consecutive number which identifies each entry (detection) in the catalogue.
SRCID (J): a unique number assigned to a group of catalogue entries
which are assumed to be the same source. To identify members of the same
group the distance in arcseconds between each pair of sources was compared
on the ![]() -level of both positional errors. A maximum distance of
-level of both positional errors. A maximum distance of
![]() was assumed, which was reduced to
was assumed, which was reduced to
![]() DIST_NN
(distance to the nearest neighbour) where necessary. See
Sect. 8.1 for a more detailed description. The combined
parameters for the unique sources are described in Sect. D.7.
DIST_NN
(distance to the nearest neighbour) where necessary. See
Sect. 8.1 for a more detailed description. The combined
parameters for the unique sources are described in Sect. D.7.
IAUNAME (21A): the IAU name assigned to the unique SRCID.
SRC_NUM (J), SAS task srcmatch: the (decimal) source number in the individual source list for this observation as determined during the source fitting stage; in the hexadecimal system it identifies the source-specific product files belonging to this detection.
MATCH_1XMM (21A): the IAU name of the closest 1XMM source within
![]() ,
cf. Sect. 8.1.
,
cf. Sect. 8.1.
SEP_1XMM (E) [arcsec]: the distance between this source and the matched 1XMM source, MATCH_1XMM.
SRCID_2XMMP (J): the unique source ID of the closest 2XMMp source
within
![]() ,
cf. Sect. 8.1.
,
cf. Sect. 8.1.
MATCH_2XMMP (22A): the IAU name of the closest 2XMMp source, cf. Sect. 8.1.
SEP_2XMMP (E) [arcsec]: the distance between this source and the matched 2XMMp source, MATCH_2XMMp.
There are 11 columns in this section which covers the meta-data of a detection. Details on XMM-Newton filters and modes can be found in the XMM User Handbook (Ehle et al. 2007).
OBS_ID (10A): the XMM-Newton observation identification.
REVOLUT (4A) [orbit]: the XMM-Newton revolution number.
MJD_START (D) [d]: modified Julian Date (i.e., JD-2 400 000.5) of the start of the observation.
MJD_STOP (D) [d]: modified Julian Date (i.e., JD-2 400 000.5) of the end of the observation.
OBS_CLASS (J): quality classification of the whole observation based
on the area flagged as bad in the manual flagging process as compared to
the whole detection area, see Sect. 7.4. 0 means nothing has been
flagged; 1 indicates that 0% < area < 0.1% of the total detection
mask has been flagged; 2 indicates that 0.1% ![]() area < 1% has been
flagged; 3 indicates that 1%
area < 1% has been
flagged; 3 indicates that 1% ![]() area < 10% has been flagged; 4
indicates that 10%
area < 10% has been flagged; 4
indicates that 10% ![]() area < 100% has been flagged; and 5 means that
the whole field was flagged as bad.
area < 100% has been flagged; and 5 means that
the whole field was flagged as bad.
PN_FILTER (6A): PN filter. The options are Thick, Medium, Thin1, and Thin2, indicating the degree of the optical blocking desired.
M1_FILTER (6A): M1 filter. The options are Thick, Medium, and Thin1, indicating the degree of the optical blocking desired.
M2_FILTER (6A): same as M1_FILTER but for M2.
PN_SUBMODE (23A): PN observing mode. The options are full frame mode with the full FOV exposed (in two sub-modes), and large window mode with only parts of the FOV exposed (Sect. 3.1).
M1_SUBMODE (16A): M1 observing mode. The options are full frame mode with the full FOV exposed, partial window mode with only parts of the central CCD exposed (in different sub-modes), and timing mode where the central CCD was not exposed (``Fast Uncompressed''), see Sect. 3.1.
M2_SUBMODE (16A): same as M1_SUBMODE but for M2.
The catalogue lists rectified (``external'') equatorial and Galactic coordinates as well as uncorrected (``internal'') equatorial coordinates. Two independent error estimates are combined into a third error column. There are 9 columns in this section.
RA (D) [deg], SAS task evalcorr: corrected right ascension of the detection (J2000) after statistical correlation of the emldetect coordinates, RA_UNC and DEC_UNC, with the USNO B1.0 optical source catalogue. In cases where the cross-correlation is determined to be unreliable no correction is applied and this value is therefore the same as RA_UNC (Sect. 4.5).
Dec (D) [deg], SAS task evalcorr: corrected declination of the detection (J2000) after statistical correlation of the emldetect coordinates, RA_UNC and DEC_UNC, with the USNO B1.0 optical source catalogue. In cases where the cross-correlation is determined to be unreliable no correction is applied and this value is therefore the same as DEC_UNC (Sect. 4.5).
POSERR (E) [arcsec]: total position uncertainty calculated by
combining the statistical error, RADEC_ERR, and the ``systematic'' error,
SYSERR, as follows:
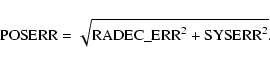
LII (D) [deg], SAS task evalcorr: galactic longitude of the detection corresponding to the (corrected) coordinates RA and Dec.
BII (D) [deg], SAS task evalcorr: galactic latitude of the detection corresponding to the (corrected) coordinates RA and Dec.
RADEC_ERR (E) [arcsec], SAS task emldetect: statistical
![]() -error on the detection position (RA_UNC and DEC_UNC).
-error on the detection position (RA_UNC and DEC_UNC).
SYSERR (E) [arcsec]: the estimated ``systematic'' ![]() -error on the
detection position. It is set to be
-error on the
detection position. It is set to be
![]() if the SAS task eposcorr resulted in a statistically reliable cross-correlation with the
USNO B1.0 optical catalogue, otherwise the error is
if the SAS task eposcorr resulted in a statistically reliable cross-correlation with the
USNO B1.0 optical catalogue, otherwise the error is
![]() (Sect. 4.5).
(Sect. 4.5).
RA_UNC (D) [deg], SAS task emldetect: right ascension of the source (J2000) as determined by the SAS task emldetect by fitting a detection simultaneously in all cameras and energy bands (Sect. 4.4.3).
DEC_UNC (D) [deg], SAS task emldetect: declination of the source (J2000) as determined by the SAS task emldetect by fitting a detection simultaneously in all cameras and energy bands (Sect. 4.4.3).
This section lists 223 columns. The fitted and combined detection parameters as well as auxiliary information are taken directly from the source lists created by the SAS tasks emldetect and srcmatch.
Instead of listing each column, descriptions of the general parameter (and their errors) are given followed by an indicator for which bands and camera combinations this parameter is available. Most parameters were determined by the SAS task emldetect which is described in detail in Sect. 4.4, while some others were derived by the SAS task srcmatch. XID-band parameters are derived in a separate emldetect run and are therefore single-band values which ensures a better handling of the error values.
ca_b_FLUX and ca_b_FLUX_ERR: (E) [erg cm-2 s-1], SAS tasks emldetect, srcmatch: Fluxes are given for all combinations of ca = [EP, PN, M1, M2] and b = [1, 2, 3, 4, 5, 8, 9]; they correspond to the flux in the entire PSF and do not need any further corrections for PSF losses.
For the individual cameras, single-band fluxes are calculated from the respective band count rate using the filter- and camera-dependent energy conversion factors given in Table 4 and corrected for the dead time due to the read-out phase. These can be 0.0 if the detection has no counts. The errors are calculated from the respective band count rate error using the respective energy conversion factors.
Total-band fluxes and errors for the individual cameras are the root-sum-squared values of the fluxes and errors, respectively, from the bands 1-5.
The EPIC flux in each band is the mean of the band-specific detections in
all cameras weighted by the errors, with the error on the weighted mean
given by
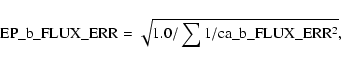
ca_b_RATE and ca_b_RATE_ERR (E) [count/s], SAS task emldetect: Count rates and errors are given for all combinations of ca = [PN, M1, M2] and b = [1, 2, 3, 4, 5, 8, 9] as well for ca = [EP] and b = [8, 9].
The single-band count rate is the band-dependent source counts (see ca_b_CTS) divided by the exposure map, which combines the mirror vignetting, detector efficiency, bad pixels and CCD gaps, and an OOT-factor (Out Of Time) depending on the PN modes. The source counts and with it the count rates were implicitly background subtracted during the fitting process. They correspond to the count rate in the entire PSF and do not need any further corrections for PSF losses. Note that rates can be 0.0 (but not negative) if the source is too faint in the respective band to be detectable.
Total-band count rate for each camera is calculated as the sum of the count rates in the individual bands 1-5.
The EPIC rates are the sum of the camera-specific count rates in the respective band.
ca_b_CTS and ca_b_CTS_ERR (E) [count], SAS task emldetect: Source counts and errors are given for ca = [EP, PN, M1, M2] and b = [8].
The single-band source counts (not given in the catalogue) are derived
under the total PSF (point spread function) and corrected for
background. The PSF is fitted on sub-images of
![]() in each band,
which means that in most cases at least 90% of the PSF (if covered by the
detector) was effectively used in the fit.
in each band,
which means that in most cases at least 90% of the PSF (if covered by the
detector) was effectively used in the fit.
Combined band source counts for each camera are calculated as the sum of the source counts in the individual bands 1-5.
The EPIC counts are the sum of the camera-specific counts.
The error is the statistical ![]() -error on the total source counts of
the detection.
-error on the total source counts of
the detection.
ca_b_DET_ML (E), SAS task emldetect: maximum likelihoods are derived for all combinations of ca = [PN, M1, M2] and b = [1, 2, 3, 4, 5, 8, 9] as well for ca = [EP] and b = [8, 9].
The single-band maximum likelihood values stand for the detection
likelihood of the source,
![]() ,
where P is the probability the
detection is spurious due to a Poissonian fluctuation. While the detection
likelihood of an extended source is computed in the same way, systematic
effects such as deviations between the real background and the model, have
a greater effect on extended sources and thus detection likelihoods of
extended sources are more uncertain.
,
where P is the probability the
detection is spurious due to a Poissonian fluctuation. While the detection
likelihood of an extended source is computed in the same way, systematic
effects such as deviations between the real background and the model, have
a greater effect on extended sources and thus detection likelihoods of
extended sources are more uncertain.
Table D.1: XMM-Newton observations and exposures included in the 2XMM catalogue.
Table D.2: 2XMM catalogue fields and targets identifications.
To calculate the maximum likelihood values for the total band and EPIC the
sum of the individual likelihoods is normalised to two degrees of freedom
using the function
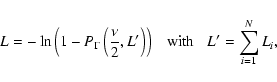
EP_EXTENT and EP_EXTENT_ERR (E) [arcsec], SAS task emldetect: the extent radius (i.e., core radius) and error of a source
detected as extended is determined fitting a beta-model profile to the
source PSF (Sect. 4.4.4). Anything below
![]() is considered
to be a point source and the extent is re-set to zero. To avoid
non-converging fitting an upper limit of
is considered
to be a point source and the extent is re-set to zero. To avoid
non-converging fitting an upper limit of
![]() has been introduced.
has been introduced.
EP_EXTENT_ML (E), SAS task emldetect: the extent likelihood
is the likelihood of the detection being extended as given by
![]() ,
where p is the probability of the extent occurring by
chance.
,
where p is the probability of the extent occurring by
chance.
ca_HRn and ca_HRn_ERR (E), SAS tasks emldetect,
srcmatch: the hardness ratios are given for ca = [EP, PN, M1, M2] and n
= [1, 2, 3, 4]. They are defined as the ratio between the count rates R in bands n and n+1:
Errors are the ![]() -error on the hardness ratio.
-error on the hardness ratio.
EPIC hardness ratios are calculated by the SAS task srcmatch and are averaged over all three cameras [PN, M1, M2]. Note that no energy conversion factor was used and that the EPIC hardness ratios are de facto not hardness ratios but an equivalent parameter helpful to characterise the hardness of a source.
ca_b_EXP (E) [s], SAS task emldetect: the exposure map values
are given for combinations of ca = [PN, M1, M2] and b = [1, 2, 3, 4, 5].
They are the PSF-weighted mean of the area of the sub-images
(
![]() )
in the individual-band exposure maps (cf. Sect. 4.4).
)
in the individual-band exposure maps (cf. Sect. 4.4).
ca_b_BG (E) [count/pixel], SAS task emldetect: the background map values are given for combinations of ca = [PN, M1, M2] and b = [1, 2, 3, 4, 5]; they are derived from the background maps at the given detection position. Note that the source fitting routine uses the background map itself rather than the single value given here. The value is (nearly) zero if the detection position lies outside the FOV.
ca_b_VIG (E), SAS task emldetect: the vignetting values are given for combinations of ca = [PN, M1, M2] and b = [1, 2, 3, 4, 5]. They are a function of energy band and off-axis angle. Note that the source parametrisation uses the vignetted exposure maps instead.
ca_ONTIME (E) [s]: the ontime values, given for ca = [PN, M1, M2], are the total good exposure time (after GTI filtering) of the CCD where the detection is positioned. Note that some source positions fall into CCD gaps or outside of the detector and will have therefore a NULL given.
ca_OFFAX (E) [arcmin], SAS task emldetect: the off-axis
angles, given for ca = [PN, M1, M2], are the distance between the detection
position and the on-axis![]() position on
the respective detector; the off-axis angle for a camera can be greater than
position on
the respective detector; the off-axis angle for a camera can be greater than
![]() when the detection is located outside the FOV of that camera.
when the detection is located outside the FOV of that camera.
ca_MASKFRAC (E), SAS task emldetect: the maskfrac values, given for ca = [PN, M1, M2], are the PSF weighted mean of the detector coverage of the detection. It depends slightly on energy; only band 8 values are given here which are the minimum of the energy-dependent maskfrac values. Sources which have less than 0.15 of their PSF covered by the detector are considered as being not detected.
DIST_NN (E) [arcsec], SAS task emldetect: the distance to
the nearest neighbouring detection; note that there is an internal
threshold of
![]() (before positional fitting) for splitting a source
into two.
(before positional fitting) for splitting a source
into two.
This section lists quality flags as well as flags for the presence of time-series or spectra for a detection. There are 7 columns in this section.
SUM_FLAG (J): The summary flag of the source is derived from the EPIC flag EP_FLAG as explained in detail in Sect. 7.5. They are:
PN_FLAG (12A), SAS task dpssflag: PN flag made of the flags [1-12] (counted from left to right) for the PN source detection. A flag is set to True according to the conditions summarised in Sect. 7.3 for the automatic flags and Sect. 7.4 for the manual flags. In cases where the camera was not used in the source detection a dash is given. In cases where a source was not detected by this camera the flags are all set to False (default). Flag [10] is not used.
M1_FLAG (12A), SAS task dpssflag: same as PN_FLAG but for M1.
M2_FLAG (12A), SAS task dpssflag: same as PN_FLAG but for M2.
TSERIES (L): the flag is set to True if this source has a time-series made in at least one exposure (Sect. 5).
SPECTRA (L): the flag is set to True if this source has a spectrum made in at least one exposure (Sect. 5).
This section lists 7 columns with variability information for those detections for which time-series were extracted.
EP_CHI2PROB (E): the minimum value of the available camera probabilities [PN_CHI2PROB, M1_CHI2PROB, M2_CHI2PROB].
PN_CHI2PROB (E), SAS task ekstest: the ![]() -probability
(based on the null hypothesis) that the source as detected by the PN camera
is constant. The Pearson's approximation to
-probability
(based on the null hypothesis) that the source as detected by the PN camera
is constant. The Pearson's approximation to ![]() for Poissonian data
was used, in which the model is used as the estimator of its own variance
(Sect. 5.2). If more than one exposure (that is, time-series) is
available for this source the lowest value of probability was used.
for Poissonian data
was used, in which the model is used as the estimator of its own variance
(Sect. 5.2). If more than one exposure (that is, time-series) is
available for this source the lowest value of probability was used.
M1_CHI2PROB (E), SAS task ekstest: same as PN_CHI2PROB but for M1.
M2_CHI2PROB (E), SAS task ekstest: same as PN_CHI2PROB but for M2.
VAR_FLAG (L): the flag is set to True if this source was detected as
variable, that is, EPIC ![]() -probability <10-5 (see
EP_CHI2PROB).
-probability <10-5 (see
EP_CHI2PROB).
VAR_EXP_ID (4A): if the source was detected as variable (that is, if
VAR_FLAG is set to True), the exposure ID (``S'' or ``U'' followed by a
three-digit number) of the exposure with the lowest ![]() -probability
is given here.
-probability
is given here.
VAR_INST_ID (2A): if the source was detected as variable (that is, if VAR_FLAG is set to True), the instrument ID [PN, M1, M2] of the exposure given in VAR_EXP_ID is listed here.
This section lists 31 columns with combined parameters for the unique sources (using the prefix ``SC'') together with the total number of detections per source. For a detailed description on how the detections are matched see Sect. 8.1.
SC_RA (D) [deg]: the mean right ascension in degrees (J2000) of all the detections of the source SRCID (see RA) weighted by the positional errors POSERR.
SC_DEC (D) [deg]: the mean declination in degrees (J2000) of all the detections of the source SRCID (see Dec) weighted by the positional errors POSERR.
SC_POSERR (E) [arcsec]: the error of the weighted mean position given in SC_RA and SC_DEC in arcseconds.
SC_EP_b_FLUX and (E) [erg cm-2 s-1]: the mean band b flux of all the detections of the source SRCID (see EP_b_FLUX) weighted by the errors (EP_b_FLUX_ERR), where b = [1, 2, 3, 4, 5, 8, 9].
SC_EP_b_FLUX_ERR (E) [erg cm-2 s-1]: error on the weighted mean band b flux in SC_EP_b_FLUX, where b = [1, 2, 3, 4, 5, 8, 9].
SC_HRn (E): the mean hardness ratio of the bands n and n+1 of all the detections of the source SRCID (see EP_HRn) weighted by the errors (see EP_HRn_ERR), where n = [1, 2, 3, 4].
SC_HRn_ERR (E): error on the weighted mean hardness ratio in SC_HRn.
SC_DET_ML (E): the total-band detection likelihood of the source SRCID is the maximum of the likelihoods of all detections of this source (see EP_8_DET_ML).
SC_EXT_ML (E): the total-band detection likelihood of the extended source SRCID is the average of the extent likelihoods of all detections of this source (see EP_EXTENT_ML).
SC_CHI2PROB (E): the ![]() -probability (based on the null
hypothesis) that the unique source SRCID as detected by any of the
observations is constant, that is, the minimum value of the EPIC
probabilities in each detection (see EP_CHI2PROB) is given.
-probability (based on the null
hypothesis) that the unique source SRCID as detected by any of the
observations is constant, that is, the minimum value of the EPIC
probabilities in each detection (see EP_CHI2PROB) is given.
SC_VAR_FLAG (L): the variability flag for the unique source SRCID is set to VAR_FLAG of the most variable detection of this source.
SC_SUM_FLAG (J): the summary flag for the unique source SRCID is taken to be the maximum flag of all detections of this source (see SUM_FLAG).
N_DETECTIONS (J): the number of detections of the unique source SRCID used to derive the combined values.
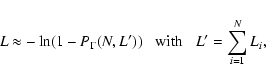
![\begin{displaymath}
Y_i = f_{{\rm src},i} \ A_{\rm src} \ \Delta t \ [\phi_{\rm src}
+ \phi_{{\rm bkg},i}] ,
\end{displaymath}](/articles/aa/full/2009/01/aa10534-08/img103.gif)