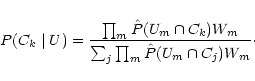The working of the DBNN may be divided into three units. The first
unit computes Bayes' probability and the threshold function for each
of the training examples. The second unit consists of a gradient
descent boosting algorithm that enhances the differences in each of
the examples in an attempt to minimize the number of incorrectly
classified cases. At this stage, boosting is applied to the
connection weights for each of the probability components
![]() of the attribute Um belonging to an example from the
class Ck. Initially all the connection weights are set to
unity. For the correctly classified object, the total probability
of the attribute Um belonging to an example from the
class Ck. Initially all the connection weights are set to
unity. For the correctly classified object, the total probability
![]() ,
computed as the product of component probabilities
will be a maximum for Ck, the class of the object given in the
training set. For the wrongly classified examples, for each of the
component probability values, the associated weights are incremented
by a factor
,
computed as the product of component probabilities
will be a maximum for Ck, the class of the object given in the
training set. For the wrongly classified examples, for each of the
component probability values, the associated weights are incremented
by a factor
![]() which is proportional to the difference in
the total probability of membership of the example in the stated class
and that in the wrongly classified class. The exact value is computed as
which is proportional to the difference in
the total probability of membership of the example in the stated class
and that in the wrongly classified class. The exact value is computed as
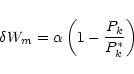
In the implementation of the network, the actual classification is done by selecting the class corresponding to a maximum value for the discriminant function. Since this value is directly related to the probability function, its value is also an estimate of the confidence with which the network is able to do the classification. A low value indicates that the classification is not reliable. Although a network based on back-propagation also gives some probability estimates on the confidence it has on a classification scheme, these are not explicitly dependent on the probabilities of the distribution. Thus while such networks are vulnerable to divergent training vectors that are invariably present in training samples, DBNN is able to assign low probability estimates to such vectors. This is especially significant in astronomical data analysis where one has to deal with variations in the data due to atmospheric conditions and instrumental limitations. Another significance of the approach is the simplicity in the computation. DBNN can be retrained with ease to adapt to the variations in the observations enabling one to generate more accurate catalogs. In the following section, we describe the use of the DBNN technique to differentiate between stars and galaxies in broadband imaging data. We chose to illustrate the capabilities of the DBNN by addressing the star-galaxy classification problem for the following reasons:
Copyright ESO 2002